Chapter 5. Introduction to Object-Oriented Design in Java
In this chapter, we’ll look at how to work with Java’s objects,
covering the key methods of Object, aspects of object-oriented design,
and implementing exception handling schemes. Throughout the chapter, we
will be introducing some design patterns—essentially best practices
for solving some very common situations that arise in software design.
Toward the end of the chapter, we’ll also consider the design of safe
programs—those that are designed so as not to become inconsistent over
time. We’ll get started by considering the subject of Java’s calling and
passing conventions and the nature of Java values.
Java Values
Java’s values, and their relationship to the type system, are quite straightforward. Java has two types of values—primitives and object references.
Note
There are only eight different primitive types in Java and new primitive types cannot be defined by the programmer.
The key difference between primitive values and references is that
primitive values cannot be altered; the value 2 is always the same value.
By contrast, the contents of object references can usually be
changed—often referred to as mutation of object contents.
Also note that variables can only contain values of the appropriate type.
In particular, variables of reference type always contain a reference to the memory location holding the object—they do not contain the object contents directly.
This means that in Java there is no equivalent of a dereference operator or a struct.
Java tries to simplify a concept that often confused C++ programmers: the difference between “contents of an object” and “reference to an object.” Unfortunately, it’s not possible to completely hide the difference, and so it is necessary for the programmer to understand how reference values work in the platform.
The fact that Java is pass by value can be demonstrated very simply. The
following code shows that even after the call to manipulate(), the
value contained in variable c is unaltered—it is still holding a
reference to a Circle object of radius 2. If Java was a
pass-by-reference language, it would instead be holding a reference to a
radius 3 Circle:
publicvoidmanipulate(Circlecircle){circle=newCircle(3);}Circlec=newCircle(2);manipulate(c);System.out.println("Radius: "+c.getRadius());
If we’re scrupulously careful about the distinction, and about referring to object references as one of Java’s possible kinds of values, then some otherwise surprising features of Java become obvious. Be careful—some older texts are ambiguous on this point. We will meet this concept of Java’s values again when we discuss memory and garbage collection in Chapter 6.
Important Methods of java.lang.Object
As we’ve noted, all classes extend, directly or indirectly,
java.lang.Object. This class defines a number of useful methods that
were designed to be overridden by classes you write.
Example 5-1 shows a class that overrides
these methods. The sections that follow this example document the
default implementation of each method and explain why you might want to
override it.
Example 5-1 uses a lot of the extended features of the type system that
we introduced in Chapter 4. First, this example implements a parameterized, or generic,
version of the Comparable interface. Second, it uses the
@Override annotation to emphasize (and have the compiler verify) that
certain methods override Object.
Example 5-1. A class that overrides important Object methods
// This class represents a circle with immutable position and radius.publicclassCircleimplementsComparable<Circle>{// These fields hold the coordinates of the center and the radius.// They are private for data encapsulation and final for immutabilityprivatefinalintx,y,r;// The basic constructor: initialize the fields to specified valuespublicCircle(intx,inty,intr){if(r<0)thrownewIllegalArgumentException("negative radius");this.x=x;this.y=y;this.r=r;}// This is a "copy constructor"--a useful alternative to clone()publicCircle(Circleoriginal){x=original.x;// Just copy the fields from the originaly=original.y;r=original.r;}// Public accessor methods for the private fields.// These are part of data encapsulation.publicintgetX(){returnx;}publicintgetY(){returny;}publicintgetR(){returnr;}// Return a string representation@OverridepublicStringtoString(){returnString.format("center=(%d,%d); radius=%d",x,y,r);}// Test for equality with another object@Overridepublicbooleanequals(Objecto){// Identical references?if(o==this)returntrue;// Correct type and non-null?if(!(oinstanceofCircle))returnfalse;Circlethat=(Circle)o;// Cast to our typeif(this.x==that.x&&this.y==that.y&&this.r==that.r)returntrue;// If all fields matchelsereturnfalse;// If fields differ}// A hash code allows an object to be used in a hash table.// Equal objects must have equal hash codes. Unequal objects are// allowed to have equal hash codes as well, but we try to avoid that.// We must override this method because we also override equals().@OverridepublicinthashCode(){intresult=17;// This hash code algorithm from the bookresult=37*result+x;// Effective Java, by Joshua Blochresult=37*result+y;result=37*result+r;returnresult;}// This method is defined by the Comparable interface. Compare// this Circle to that Circle. Return a value < 0 if this < that// Return 0 if this == that. Return a value > 0 if this > that.// Circles are ordered top to bottom, left to right, and then by radiuspublicintcompareTo(Circlethat){// Smaller circles have bigger ylongresult=(long)that.y-this.y;// If same compare l-to-rif(result==0)result=(long)this.x-that.x;// If same compare radiusif(result==0)result=(long)this.r-that.r;// We have to use a long value for subtraction because the// differences between a large positive and large negative// value could overflow an int. But we can't return the long,// so return its sign as an int.returnLong.signum(result);}}
toString()
The purpose of the toString() method is to return a textual
representation of an object. The method is invoked automatically on
objects during string concatenation and by methods such as
System.out.println(). Giving objects a textual representation can be
quite helpful for debugging or logging output, and a well-crafted
toString() method can even help with tasks such as report generation.
The version of toString() inherited from Object returns a string
that includes the name of the class of the object as well as a
hexadecimal representation of the hashCode() value of the object
(discussed later in this chapter). This default implementation provides
basic type and identity information for an object but is not usually
very useful. The toString() method in
Example 5-1 instead returns a human-readable
string that includes the value of each of the fields of the Circle
class.
equals()
The == operator tests two references to see if they refer to the
same object. If you want to test whether two distinct objects are equal
to one another, you must use the equals() method instead. Any class
can define its own notion of equality by overriding equals(). The
Object.equals() method simply uses the == operator: this default
method considers two objects equal only if they are actually the very
same object.
The equals() method in Example 5-1
considers two distinct Circle objects to be equal if their fields are
all equal. Note that it first does a quick identity test with == as an
optimization and then checks the type of the other object with
instanceof: a Circle can be equal only to another Circle, and it
is not acceptable for an equals() method to throw a
ClassCastException. Note that the instanceof test also rules out
null arguments: instanceof always evaluates to false if its
lefthand operand is null.
hashCode()
Whenever you override equals(), you must also override hashCode().
This method returns an integer for use by hash table data structures.
It is critical that two objects have the same hash code if they are
equal according to the equals() method.
It is important (for efficient
operation of hash tables) but not required that unequal objects have
unequal hash codes, or at least that unequal objects are unlikely to
share a hash code. This second criterion can lead to hashCode()
methods that involve mildly tricky arithmetic or bit manipulation.
The Object.hashCode() method works with the Object.equals() method
and returns a hash code based on object identity rather than object
equality. (If you ever need an identity-based hash code, you can access
the functionality of Object.hashCode() through the static method
System.identityHashCode().)
Tip
When you override equals(), you must always override hashCode() to
guarantee that equal objects have equal hash codes. Failing to do this
can cause subtle bugs in your programs.
Because the equals() method in Example 5-1
bases object equality on the values of the three fields, the
hashCode() method computes its hash code based on these three fields
as well. It is clear from the code that if two Circle objects have the
same field values, they will have the same hash code.
Note that the hashCode() method in Example 5-1 does not simply add the three fields and return their sum. Such an
implementation would be legal but not efficient because two circles with
the same radius but whose x and y coordinates were reversed would
then have the same hash code. The repeated multiplication and addition
steps “spread out” the range of hash codes and dramatically reduce the
likelihood that two unequal Circle objects have the same code.
Tip
In practice, modern Java programmers will typically autogenerate hashCode(), equals(), and toString() from within their IDE.
Effective Java by Joshua Bloch (Addison Wesley) includes a helpful recipe for constructing efficient hashCode() methods, if the programmer chooses not to autogenerate.
Comparable::compareTo()
Example 5-1 includes a compareTo()
method. This method is defined by the java.lang.Comparable interface
rather than by Object, but it is such a common method to implement
that we include it in this section. The purpose of Comparable and its
compareTo() method is to allow instances of a class to be compared to
each other in a similar way to how the <, <=, >, and >= operators
compare numbers.
If a class implements Comparable, we can call methods to allow us to say that one instance is less than, greater than, or equal to another instance.
This also means that instances of a Comparable class can be sorted.
Note
The method compareTo() sets up a total ordering of the objects of the type. This is referred to as the natural order of the type, and the method is called the natural comparison method.
Because compareTo() is not declared by the Object class, it is up to
each individual class to determine whether and how its instances should
be ordered and to include a compareTo() method that implements that
ordering.
The ordering defined by Example 5-1
compares Circle objects as if they were words on a page. Circles are
first ordered from top to bottom: circles with larger y coordinates
are less than circles with smaller y coordinates. If two circles have
the same y coordinate, they are ordered from left to right. A circle
with a smaller x coordinate is less than a circle with a larger x
coordinate. Finally, if two circles have the same x and y
coordinates, they are compared by radius. The circle with the smaller
radius is smaller. Notice that under this ordering, two circles are
equal only if all three of their fields are equal. This means that the
ordering defined by compareTo() is consistent with the equality
defined by equals(). This is very desirable (but not strictly
required).
The compareTo() method returns an int value that requires further
explanation. compareTo() should return a negative number if the this
object is less than the object passed to it. It should return 0 if the
two objects are equal. And compareTo() should return a positive number
if this is greater than the method argument.
clone()
Object defines a method named clone() whose purpose is to return
an object with fields set identically to those of the current object.
This is an unusual method for two reasons. First, it works only if the
class implements the java.lang.Cloneable interface. Cloneable does
not define any methods (it is a marker interface), so implementing it is
simply a matter of listing it in the implements clause of the class
signature. The other unusual feature of clone() is that it is declared
protected. Therefore, if you want your object to be cloneable by other
classes, you must implement Cloneable and override the clone()
method, making it public.
The Circle class of Example 5-1 does not
implement Cloneable; instead it provides a copy constructor for
making copies of Circle objects:
Circleoriginal=newCircle(1,2,3);// regular constructorCirclecopy=newCircle(original);// copy constructor
It can be difficult to implement clone() correctly, and it is usually
easier and safer to provide a copy constructor.
Aspects of Object-Oriented Design
In this section, we will consider several techniques relevant to object-oriented design in Java. This is a very incomplete treatment and merely intended to showcase some examples—we encourage you to consult additional resources, such as the aforementioned Effective Java by Joshua Bloch.
We start by considering good practices for defining constants in Java, before moving on to discuss different approaches to using Java’s object-oriented capabilities for modeling and domain object design. At the end of the section, we conclude by covering the implementation of some common design patterns in Java.
Constants
As noted earlier, constants can appear in an interface definition. Any class that implements an interface inherits the constants it defines and can use them as if they were defined directly in the class itself. Importantly, there is no need to prefix the constants with the name of the interface or provide any kind of implementation of the constants.
When a set of constants is used by more than one class, it is tempting
to define the constants once in an interface and then have any classes
that require the constants implement the interface. This situation might
arise, for example, when client and server classes implement a network
protocol whose details (such as the port number to connect to and listen
on) are captured in a set of symbolic constants. As a concrete example,
consider the java.io.ObjectStreamConstants interface, which defines
constants for the object serialization protocol and is implemented by
both ObjectInputStream and ObjectOutputStream.
The primary benefit of inheriting constant definitions from an interface
is that it saves typing: you don’t need to specify the type that defines
the constants. Despite its use with ObjectStreamConstants, this is not
a recommended technique. The use of constants is an implementation
detail that is not appropriate to declare in the implements clause of
a class signature.
A better approach is to define constants in a class and use the
constants by typing the full class name and the constant name. You can
save typing by importing the constants from their defining class with
the import static declaration. See
“Packages and the Java Namespace” for details.
Interfaces Versus Abstract Classes
The advent of Java 8 has fundamentally changed Java’s object-oriented programming model. Before Java 8, interfaces were pure API specification and contained no implementation. This could often lead to duplication of code if the interface had many implementations.
In response, a coding pattern developed. This pattern takes advantage of the fact that an abstract class does not need to be entirely abstract; it can contain a partial implementation that subclasses can take advantage of. In some cases, numerous subclasses can rely on method implementations provided by an abstract superclass.
The pattern consists of an interface that contains the API spec for the
basic methods, paired with a primary implementation as an abstract
class. A good example would be java.util.List, which is paired with
java.util.AbstractList. Two of the main implementations of List
that ship with the JDK (ArrayList and LinkedList) are subclasses of
AbstractList. As another example:
// Here is a basic interface. It represents a shape that fits inside// of a rectangular bounding box. Any class that wants to serve as a// RectangularShape can implement these methods from scratch.publicinterfaceRectangularShape{voidsetSize(doublewidth,doubleheight);voidsetPosition(doublex,doubley);voidtranslate(doubledx,doubledy);doublearea();booleanisInside();}// Here is a partial implementation of that interface. Many// implementations may find this a useful starting point.publicabstractclassAbstractRectangularShapeimplementsRectangularShape{// The position and size of the shapeprotecteddoublex,y,w,h;// Default implementations of some of the interface methodspublicvoidsetSize(doublewidth,doubleheight){w=width;h=height;}publicvoidsetPosition(doublex,doubley){this.x=x;this.y=y;}publicvoidtranslate(doubledx,doubledy){x+=dx;y+=dy;}}
The arrival of default methods in Java 8 changes this picture considerably. Interfaces can now contain implementation code, as we saw in “Default Methods”.
This means that when defining an abstract type (e.g., Shape) that you expect to have many subtypes (e.g., Circle, Rectangle, Square), you are faced with a choice between interfaces and abstract classes.
As they now have potentially similar features, it is not always clear which to use.
Remember that a class that extends an abstract class cannot extend any other class, and that interfaces still cannot contain any nonconstant fields. This means that there are still some restrictions on how we can use object orientation in our Java programs.
Another important difference between interfaces and abstract classes has to do with compatibility. If you define an interface as part of a public API and then later add a new mandatory method to the interface, you break any classes that implemented the previous version of the interface—in other words, any new interface methods must be declared as default and an implementation provided. If you use an abstract class, however, you can safely add nonabstract methods to that class without requiring modifications to existing classes that extend the abstract class.
Note
In both cases, adding new methods can cause a clash with subclass methods of the same name and signature—with the subclass methods always winning. For this reason, think carefully when adding new methods—especially when the method names are “obvious” for this type, or where the method could have several possible meanings.
In general, the suggested approach is to prefer interfaces when an API specification is needed. The mandatory methods of the interface are nondefault, as they represent the part of the API that must be present for an implementation to be considered valid. Default methods should be used only if a method is truly optional, or if they are really only intended to have a single possible implementation.
Finally, the older technique of documenting which methods of an
interface are considered “optional” and throwing a
java.lang.UnsupportedOperationException if the programmer does not
want to implement them is fraught with problems, and should not be used
in new code.
Can Default Methods Be Used as Traits?
Before Java 8, the strict single inheritance model was clear.
Every class, except Object had exactly one direct superclass, and method implementations could only either be defined in a class, or be inherited from the superclass hierarchy.
Default methods change this picture, because they allow method implementations to be inherited from multiple places—either from the superclass hierarchy or from default implementation provided in interfaces.
Note
This is effectively the Mixin pattern from C++, and can be seen as a form of the trait language feature that appears in some languages.
In the Java case, any potential conflicts between different default methods from separate interfaces will result in a compile-time error. This means that there is no possibility of conflicting multiple inheritance of implementation, as in any clash the programmer is required to manually disambiguate. Not only that, but there is also no multiple inheritance of state.
However, the official view from Java’s language designers is that default methods fall short of being full traits.
However, this view is somewhat undermined by the code that ships within the JDK—even the interfaces within java.util.function (such as Function itself) behave as simple traits.
For example, consider this piece of code:
publicinterfaceIntFunc{intapply(intx);defaultIntFunccompose(IntFuncbefore){return(inty)->apply(before.apply(y));}defaultIntFuncandThen(IntFuncafter){return(intz)->after.apply(apply(z));}staticIntFuncid(){returnx->x;}}
It is a simplified form of the function types present in java.util.function—it removes the generics and only deals with int as a data type.
This case shows an important point for the functional composition methods present: these functions will only ever be composed in the standard way, and it is highly implausible that any sane override of the default compose() method could exist.
This is, of course, also true for the function types present in java.util.function, and shows that within the limited domain provided, default methods can be treated as a form of stateless trait.
Instance Methods or Class Methods?
Instance methods are one of the key features of object-oriented programming. That doesn’t mean, however, that you should shun class methods. In many cases, it is perfectly reasonable to define class methods.
Tip
Remember that in Java, class methods are declared with the static
keyword, and the terms static method and class method are used
interchangeably.
For example, when working with the Circle class you might find that
you often want to compute the area of a circle with a given radius but
don’t want to bother creating a Circle object to represent that
circle. In this case, a class method is more convenient:
publicstaticdoublearea(doubler){returnPI*r*r;}
It is perfectly legal for a class to define more than one method with
the same name, as long as the methods have different parameters. This
version of the area() method is a class method, so it does not have an
implicit this parameter and must have a parameter that specifies the
radius of the circle. This parameter keeps it distinct from the instance
method of the same name.
As another example of the choice between instance methods and class
methods, consider defining a method named bigger() that examines two
Circle objects and returns whichever has the larger radius. We can
write bigger() as an instance method as follows:
// Compare the implicit "this" circle to the "that" circle passed// explicitly as an argument and return the bigger one.publicCirclebigger(Circlethat){if(this.r>that.r)returnthis;elsereturnthat;}
We can also implement bigger() as a class method as follows:
// Compare circles a and b and return the one with the larger radiuspublicstaticCirclebigger(Circlea,Circleb){if(a.r>b.r)returna;elsereturnb;}
Given two Circle objects, x and y, we can use either the instance
method or the class method to determine which is bigger. The invocation
syntax differs significantly for the two methods, however:
// Instance method: also y.bigger(x)Circlebiggest=x.bigger(y);Circlebiggest=Circle.bigger(x,y);// Static method
Both methods work well, and, from an object-oriented design standpoint, neither of these methods is “more correct” than the other. The instance method is more formally object oriented, but its invocation syntax suffers from a kind of asymmetry. In a case like this, the choice between an instance method and a class method is simply a design decision. Depending on the circumstances, one or the other will likely be the more natural choice.
A word about System.out.println()
We’ve frequently encountered the method System.out.println()—it’s
used to display output to the terminal window or console. We’ve never
explained why this method has such a long, awkward name or what those
two periods are doing in it. Now that you understand class and instance
fields and class and instance methods, it is easier to understand what
is going on: System is a class. It has a public class field named
out. This field is an object of type java.io.PrintStream, and it
has an instance method named println().
We can use static imports to make this a bit shorter with
import static java.lang.System.out;—this will enable us to refer to
the printing method as out.println() but as this is an instance
method, we cannot shorten it any further.
Composition Versus Inheritance
Inheritance is not the only technique at our disposal in object-oriented design. Objects can contain references to other objects, so a larger conceptual unit can be aggregated out of smaller component parts; this is known as composition. One important related technique is delegation, where an object of a particular type holds a reference to a secondary object of a compatible type, and forwards all operations to the secondary object. This is frequently done using interface types, as shown in this example where we model the employment structure of software companies:
publicinterfaceEmployee{voidwork();}publicclassProgrammerimplementsEmployee{publicvoidwork(){/* program computer */}}publicclassManagerimplementsEmployee{privateEmployeereport;publicManager(Employeestaff){report=staff;}publicEmployeesetReport(Employeestaff){report=staff;}publicvoidwork(){report.work();}}
The Manager class is said to delegate the work() operation to
their direct report, and no actual work is performed by the Manager
object. Variations of this pattern involve some work being done in the
delegating class, with only some calls being forwarded to the delegate
object.
Another useful, related technique is called the decorator pattern. This provides the capability to extend objects with new functionality, including at runtime. The slight overhead is some extra work needed at design time. Let’s look at an example of the decorator pattern as applied to modeling burritos for sale at a taqueria. To keep things simple, we’ve only modeled a single aspect to be decorated—the price of the burrito:
// The basic interface for our burritosinterfaceBurrito{doublegetPrice();}// Concrete implementation-standard size burritopublicclassStandardBurritoimplementsBurrito{privatestaticfinaldoubleBASE_PRICE=5.99;publicdoublegetPrice(){returnBASE_PRICE;}}// Larger, super-size burritopublicclassSuperBurritoimplementsBurrito{privatestaticfinaldoubleBASE_PRICE=6.99;publicdoublegetPrice(){returnBASE_PRICE;}}
These cover the basic burritos that can be offered—two different sizes, at different prices. Let’s enhance this by adding some optional extras—jalapeño chilies and guacamole. The key design point here is to use an abstract base class that all of the optional decorating components will subclass:
/** This class is the Decorator for Burrito. It represents optional* extras that the burrito may or may not have.*/publicabstractclassBurritoOptionalExtraimplementsBurrito{privatefinalBurritoburrito;privatefinaldoubleprice;protectedBurritoOptionalExtra(BurritotoDecorate,doublemyPrice){burrito=toDecorate;price=myPrice;}publicfinaldoublegetPrice(){return(burrito.getPrice()+price);}}
Note
Combining an abstract base, BurritoOptionalExtra, and a
protected constructor means that the only valid way to get a
BurritoOptionalExtra is to construct an instance of one of the
subclasses, as they have public constructors (which also hide the setup
of the price of the component from client code).
Let’s test the implementation out:
Burritolunch=newJalapeno(newGuacamole(newSuperBurrito()));// The overall cost of the burrito is the expected $8.09.System.out.println("Lunch cost: "+lunch.getPrice());
The decorator pattern is very widely used—not least in the JDK utility classes. When we discuss Java I/O in Chapter 10, we will see more examples of decorators in the wild.
Field Inheritance and Accessors
Java offers multiple potential approaches to the design issue of the
inheritance of state. The programmer can choose to mark fields as
protected and allow them to be accessed directly by subclasses
(including writing to them). Alternatively, we can provide accessor
methods to read (and write, if desired) the actual object fields,
while retaining encapsulation and leaving the fields as private.
Let’s revisit our earlier PlaneCircle example from the end of
Chapter 9 and explicitly show the field
inheritance:
publicclassCircle{// This is a generally useful constant, so we keep it publicpublicstaticfinaldoublePI=3.14159;protecteddoubler;// State inheritance via a protected field// A method to enforce the restriction on the radiusprotectedvoidcheckRadius(doubleradius){if(radius<0.0)thrownewIllegalArgumentException("radius may not < 0");}// The non-default constructorpublicCircle(doubler){checkRadius(r);this.r=r;}// Public data accessor methodspublicdoublegetRadius(){returnr;}publicvoidsetRadius(doubler){checkRadius(r);this.r=r;}// Methods to operate on the instance fieldpublicdoublearea(){returnPI*r*r;}publicdoublecircumference(){return2*PI*r;}}publicclassPlaneCircleextendsCircle{// We automatically inherit the fields and methods of Circle,// so we only have to put the new stuff here.// New instance fields that store the center point of the circleprivatefinaldoublecx,cy;// A new constructor to initialize the new fields// It uses a special syntax to invoke the Circle() constructorpublicPlaneCircle(doubler,doublex,doubley){super(r);// Invoke the constructor of the superclassthis.cx=x;// Initialize the instance field cxthis.cy=y;// Initialize the instance field cy}publicdoublegetCentreX(){returncx;}publicdoublegetCentreY(){returncy;}// The area() and circumference() methods are inherited from Circle// A new instance method that checks whether a point is inside the// circle; note that it uses the inherited instance field rpublicbooleanisInside(doublex,doubley){doubledx=x-cx,dy=y-cy;// Pythagorean theoremdoubledistance=Math.sqrt(dx*dx+dy*dy);return(distance<r);// Returns true or false}}
Instead of the preceding code, we can rewrite PlaneCircle using
accessor methods, like this:
publicclassPlaneCircleextendsCircle{// Rest of class is the same as above; the field r in// the superclass Circle can be made private because// we no longer access it directly here// Note that we now use the accessor method getRadius()publicbooleanisInside(doublex,doubley){doubledx=x-cx,dy=y-cy;// Distance from centerdoubledistance=Math.sqrt(dx*dx+dy*dy);// Pythagorean theoremreturn(distance<getRadius());}}
Both approaches are legal Java, but they have some differences. As we discussed in “Data Hiding and Encapsulation”, fields that are writable outside of the class are usually not a correct way to model object state. In fact, as we will see in “Safe Java Programming” and again in “Java’s Support for Concurrency”, they can damage the running state of a program irreparably.
It is therefore unfortunate that the protected keyword in Java allows
access to fields (and methods) from both subclasses and classes in the
same packages as the declaring class. This, combined with the ability
for anyone to write a class that belongs to any given package (except
system packages), means that protected inheritance of state is
potentially flawed in Java.
Tip
Java does not provide a mechanism for a member to be visible only in the declaring class and its subclasses.
For all of these reasons, it is usually better to use accessor methods
(either public or protected) to provide access to state for
subclasses—unless the inherited state is declared final, in which case
protected inheritance of state is perfectly permissible.
Singleton
The singleton pattern is another well-known design pattern. It is intended to solve the design issue where only a single instance of a class is required or desired. Java provides a number of different possible ways to implement the singleton pattern. In our discussion, we will use a slightly more verbose form, which has the benefit of being very explicit in what needs to happen for a safe singleton:
publicclassSingleton{privatefinalstaticSingletoninstance=newSingleton();privatestaticbooleaninitialized=false;// ConstructorprivateSingleton(){super();}privatevoidinit(){/* Do initialization */}// This method should be the only way to get a reference// to the instancepublicstaticsynchronizedSingletongetInstance(){if(initialized)returninstance;instance.init();initialized=true;returninstance;}}
The crucial point is that for the singleton pattern to be effective, it
must be impossible to create more than one of them, and it must be
impossible to get a reference to the object in an uninitialized state
(see later in this chapter for more on this important point). To achieve
this, we require a private constructor, which is only called once. In
our version of Singleton, we only call the constructor when we
initialize the private static variable instance. We also separate out
the creation of the only Singleton object from its
initialization—which occurs in the private method init().
With this mechanism in place, the only way to get a reference to the
lone instance of Singleton is via the static helper method,
getInstance(). This method checks the flag initialized to see if the
object is already in an active state. If it is, then a reference to the
singleton object is returned. If not, then getInstance() calls
init() to activate the object, and flicks the flag to true, so that
next time a reference to the Singleton is requested, further
initialization will not occur.
Finally, we also note that getInstance() is a synchronized method.
See Chapter 6 for full details of what this means,
and why it is necessary, but for now, know that it is present to guard
against unintended consequences if Singleton is used in a
multithreaded program.
Tip
Singleton, being one of the simplest patterns, is often overused. When used correctly, it can be a useful technique, but too many singleton classes in a program is a classic sign of badly engineered code.
The singleton pattern has some drawbacks—in particular, it can be hard
to test and to separate out from other classes. It also requires care
when used in mulithreaded code. Nevertheless, it is important that
developers are familiar with it, and do not accidentally reinvent it. The
singleton pattern is often used in configuration management, but modern
code will typically use a framework (often a dependency injection) to
provide the programmer with singletons automatically, rather than via an
explicit Singleton (or equivalent) class.
Object-Oriented Design with Lambdas
Consider this simple lambda expression:
Runnabler=()->System.out.println("Hello World");
The type of the lvalue is Runnable, which is an interface type.
For this statement to make sense, the rvalue must contain an instance of some class type (because interfaces cannot be instantiated) that implements Runnable.
The minimal implementation that satisfies these constraints is a class type (of inconsequential name) that directly extends Object and implements Runnable.
Recall that the intention of lambda expressions is to allow Java programmers to express a concept that is as close as possible to the anonymous or inline methods seen in other languages.
Furthermore, given that Java is a statically typed language, this leads directly to the design of lambdas as implemented.
Tip
Lambdas are a shorthand for the construction of a new instance of a class type that is essentially Object enhanced by a single method.
A lambda’s single extra method has a signature provided by the interface type, and the compiler will check that the rvalue is consistent with this type signature.
Lambdas Versus Nested Classes
The addition of lambdas to the language in Java 8 was relatively late, as compared to other programming languages. As a consequence, the Java community had established patterns to work around the absence of lambdas. This manifests in a heavy usage of nested (aka inner) classes to fill the niche that lambdas usually occupy.
In modern Java projects that are developed from scratch, developers will typically use lambdas wherever possible. We also strongly suggest that, when refactoring old code, you take some time to convert inner classes to lambdas wherever possible. Some IDEs even provide an automatic conversion facility.
However, this still leaves the design question of when to use lambdas and when nested classes are still the correct solution.
Some cases are obvious—for example, when extended from a default implementation (e.g., for a Visitor pattern), like this file reaper for deleting a whole subdirectory and everything in it:
publicfinalclassReaperextendsSimpleFileVisitor<Path>{@OverridepublicFileVisitResultvisitFile(Pathp,BasicFileAttributesa)throwsIOException{Files.delete(p);returnFileVisitResult.CONTINUE;}@OverridepublicFileVisitResultvisitFileFailed(Pathp,IOExceptionx)throwsIOException{Files.delete(p);returnFileVisitResult.CONTINUE;}@OverridepublicFileVisitResultpostVisitDirectory(Pathp,IOExceptionx)throwsIOException{if(x==null){Files.delete(p);returnFileVisitResult.CONTINUE;}else{throwx;}}}
This is an extension of an existing class—and of course lambdas can only be used for interfaces, not for classes (even abstract classes with a single abstract method). As a result, this is a clear use case for an inner class, not a lambda.
Another major use case to consider is that of stateful lambdas. As there is nowhere to declare any fields, it would appear at first glance that lambdas cannot directly be used for anything that involves state—the syntax only gives the opportunity to declare a method body.
However, a lambda can refer to a variable defined in the scope that the lambda is created in, so we can create a closure, as discussed in Chapter 4, to fill the role of a stateful lambda.
Lambdas Versus Method References
The question of when to use a lambda and when to use a method reference is largely a matter of personal taste and style. There are, of course, some circumstances where it is essential to create a lambda. However, in many simple cases, a lambda can be replaced by a method reference.
One possible approach is to consider whether the lambda notation adds anything to the readability of the code.
For example, in the streams API, there is a potential benefit in using the lambda form, as it uses the -> operator.
This provides a form of visual metaphor—the stream API is a lazy abstraction that can be visualized as data items “flowing through a functional pipeline.”
For example:
List<kathik.Person>ots=null;doubleaveAge=ots.stream().mapToDouble(o->o.getAge()).reduce(0,(x,y)->x+y)/ots.size();
The idea that the mapToDouble() method has an aspect of motion, or transformation, is strongly implied by the usage of an explicit lambda.
For less experienced programmers, it also draws attention to the use of a functional API.
For other use cases (e.g., dispatch tables) method references may well be more appropriate. For example:
publicclassIntOps{privateMap<String,BinaryOperator>table=Map.of("add",IntOps::add,"subtract",IntOps::sub);privatestaticintadd(intx,inty){returnx+y;}privatestaticintsub(intx,inty){returnx-y;}publicinteval(Stringop,intx,inty){returntable.get(op).apply(x,y);}}
In situations where either notation could be used, you will come to develop a preference that fits your individual style over time. The key consideration is whether, when returning to reread code written several months (or years) ago, the choice of notation still makes sense and the code is easy to read.
Exceptions and Exception Handling
We met checked and unchecked exceptions in “Checked and Unchecked Exceptions”. In this section, we discuss some additional aspects of the design of exceptions, and how to use them in your own code.
Recall that an exception in Java is an object. The type of this object
is java.lang.Throwable, or more commonly, some subclass of
Throwable that more specifically describes the type of exception that
occurred. Throwable has two standard subclasses: java.lang.Error and
java.lang.Exception. Exceptions that are subclasses of Error
generally indicate unrecoverable problems: the virtual machine has run
out of memory, or a class file is corrupted and cannot be read, for
example. Exceptions of this sort can be caught and handled, but it is
rare to do so—these are the unchecked exceptions previously mentioned.
Exceptions that are subclasses of Exception, on the other hand,
indicate less severe conditions. These exceptions can be reasonably
caught and handled. They include such exceptions as
java.io.EOFException, which signals the end of a file, and
java.lang.ArrayIndexOutOfBoundsException, which indicates that a
program has tried to read past the end of an array. These are the
checked exceptions from Chapter 2 (except for
subclasses of RuntimeException, which are also a form of unchecked
exception). In this book, we use the term “exception” to refer to any
exception object, regardless of whether the type of that exception is
Exception or Error.
Because an exception is an object, it can contain data, and its class
can define methods that operate on that data. The Throwable class and
all its subclasses include a String field that stores a human-readable
error message that describes the exceptional condition. It’s set when
the exception object is created and can be read from the exception with
the getMessage() method. Most exceptions contain only this single
message, but a few add other data. The java.io.InterruptedIOException,
for example, adds a field named bytesTransferred that specifies how
much input or output was completed before the exceptional condition
interrupted it.
When designing your own exceptions, you should consider what other
additional modeling information is relevant to the exception object.
This is usually situation-specific information about the aborted
operation, and the exceptional circumstance that was encountered (as we
saw with java.io.InterruptedIOException).
There are some trade-offs in the use of exceptions in application design. Using checked exceptions means that the compiler can enforce the handling (or propagation up the call stack) of known conditions that have the potential of recovery or retry. It also means that it’s more difficult to forget to actually handle errors—thus reducing the risk that a forgotten error condition causes a system to fail in production.
On the other hand, some applications will not be able to recover from
certain conditions—even conditions that are theoretically modeled by
checked exceptions. For example, if an application requires a config
file to be placed at a specific place in the filesystem and can’t
locate it at startup, it may have no option but to print an
error message and exit—despite the fact that
java.io.FileNotFoundException is a checked exception. Forcing
exceptions that cannot be recovered from to be either handled or
propagated is, in these circumstances, bordering on perverse.
When designing exception schemes, there are some good practices that you should follow:
-
Consider what additional state needs to be placed on the exception—remember that it’s also an object like any other.
-
Exceptionhas four public constructors—under normal circumstances, custom exception classes should implement all of them—to initialize the additional state or to customize messages. -
Don’t create many fine-grained custom exception classes in your APIs—the Java I/O and reflection APIs both suffer from this and it needlessly complicates working with those packages.
-
Don’t overburden a single exception type with describing too many conditions; for example, the Nashorn JavaScript implementation (new with Java 8) originally had overly coarse-grained exceptions, although this was fixed before release.
Finally, two exception-handling antipatterns that you should avoid:
// Never just swallow an exceptiontry{someMethodThatMightThrow();}catch(Exceptione){}// Never catch, log, and rethrow an exceptiontry{someMethodThatMightThrow();}catch(SpecificExceptione){log(e);throwe;}
The former of these two just ignores a condition that almost certainly required some action (even if just a notification in a log). This increases the likelihood of failure elsewhere in the system—potentially far from the original, real source.
The second one just creates noise. We’re logging a message but not actually doing anything about the issue; we still require some other code higher up in the system to actually deal with the problem.
Safe Java Programming
Programming languages are sometimes described as being type safe; however, this term is used rather loosely by working programmers. There are a number of different viewpoints on and definitions for type safety, not all of which are mutually compatible. The most useful view for our purposes is that type safety is the property of a programming language that prevents the type of data being incorrectly identified at runtime. This should be thought of as a sliding scale—it is more helpful to think of languages as being more (or less) type safe than each other, rather than a simple binary property of safe/unsafe.
In Java, the static nature of the type system helps prevent a large
class of possible errors, by producing compilation errors if, for
example, the programmer attempts to assign an incompatible value to a
variable. However, Java is not perfectly type safe, as we can perform a
cast between any two reference types—this will fail at runtime with a
ClassCastException if the value is not compatible.
In this book, we prefer to think of safety as inseparable from the broader topic of correctness. This means that we should think in terms of programs, rather than languages. This emphasizes the point that safe code is not guaranteed by any widely used language, and instead considerable programmer effort (and adherence to rigorous coding discipline) must be employed if the end result is to be truly safe and correct.
We approach our view of safe programs by working with the state model abstraction as shown in Figure 5-1. A safe program is one in which:
-
All objects start off in a legal state after creation
-
Externally accessible methods transition objects between legal states
-
Externally accessible methods must not return with objects in an inconsistent state
-
Externally accessible methods must reset objects to a legal state before throwing
In this context, “externally accessible” means public,
package-private, or protected. This defines a reasonable model for
safety of programs, and as it is bound up with defining our abstract
types in such a way that their methods ensure consistency of state, it’s
reasonable to refer to a program satisfying these requirements as a
“safe program,” regardless of the language in which such a program is
implemented.
Warning
Private methods do not have to start or end with objects in a legal state, as they cannot be called by an external piece of code.
As you might imagine, actually engineering a substantial piece of code so that we can be sure that the state model and methods respect these properties can be quite an undertaking. In languages such as Java, in which programmers have direct control over the creation of preemptively multitasked execution threads, this problem is a great deal worse.
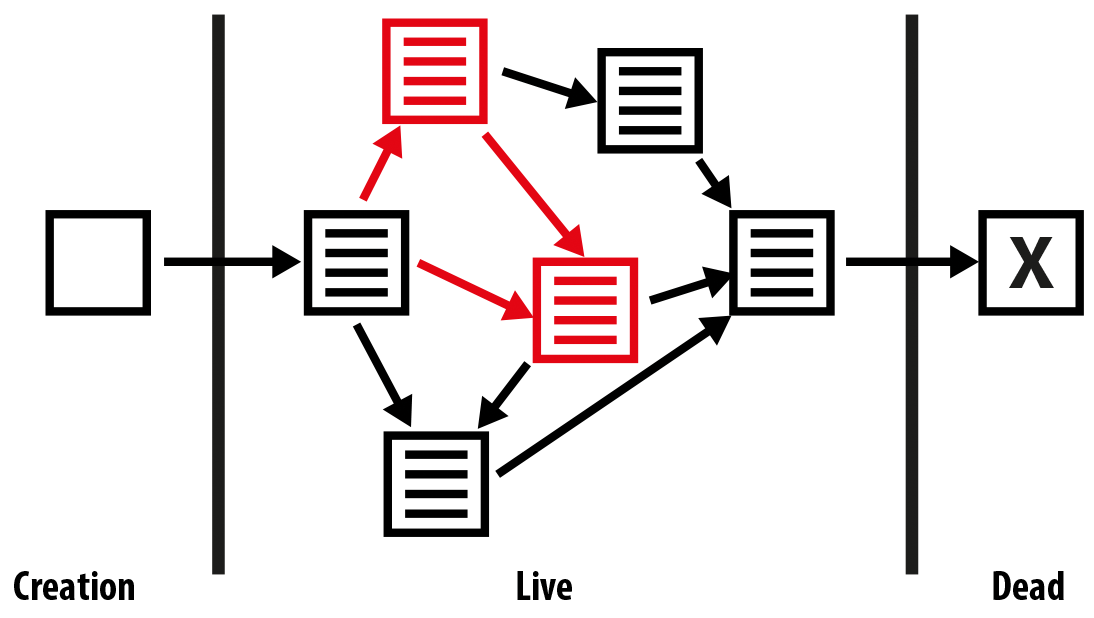
Figure 5-1. Program state transitions
Moving on from our introduction of object-oriented design, there is one final aspect of the Java language and platform that needs to be understood for a sound grounding. That is the nature of memory and concurrency—one of the most complex of the platform, but also one that rewards careful study with large dividends. It is the subject of our next chapter and concludes Part I.