Figure 4.1 Characterization of an information need in a TREC evaluation

In writing the introduction to this chapter, one of the authors wanted to use an example taken from a scene in the movie Mission: Impossible, involving a character searching for important information on a computer. Ironically, the author was unable after 15 minutes to find a description of this scene on the internet. It seemed like he was going to have to track it down by watching the movie again. (Luckily, this turned out not to be the case, as discussed below.)
What is the problem here? We know what the name of the movie is and can find all sorts of facts about it (it stars Tom Cruise, came out in 1996, and so on); we know the scene involves searching on a computer; and we know that the internet houses a wealth of information and random movie facts. We know exactly what we are looking for, so why is it so difficult to find what we want?
Unfortunately, the phrase mission impossible is so famous that it is used for a variety of purposes (e.g., a book title Protection against Genocide: Mission Impossible?); the movie features several scenes involving computers, most of which are more famous; and searching for anything related to searching turns up links to web search engines with other results for the movie. Although this example may seem trivial, it is genuine, it corresponds to a real information need, and it reveals some of the problems that can arise when we search the internet.
Consider what the options are for finding the information we want:
There is no single right answer: if you have friends who are movie buffs, asking is good; if you are patient about working through reams of search engine results, that will work; if you are pretty sure you have seen the information in a particular book and more or less know where it is, that may be quickest. For the present problem, a suggestion to look for mission impossible script was what eventually led to finding the reference.
We all know that there are many possible ways to obtain a piece of information, from more traditional resources, such as books and newspapers, to more recent resources like the web and various databases. Finding the information in a hurry, however, is not always a straightforward task, as the example above illustrates. You have to know what resources are available, and how to search through those resources. This chapter provides an overview of different types of searching and different kinds of resources.
We will focus on searching in written texts, but you might also be wondering about the possibility of searching through speech. After all, it would be extremely useful and time-saving to be able to find a particular sentence spoken in an interview, especially if no transcript exists, but only a recording or audio file. Unfortunately, this type of searching is not readily available with current technology.
While this might be a bit disappointing, searching in speech may not be far away. It is already possible to detect the language of a spoken conversation and to detect a new topic being started in a conversation, and it is possible to use speech recognition to provide automatic, if fallible, closed captioning of videos.
We are going to start our tour of searching with a look at so-called structured data. The characteristic of structured data is that it is very orderly. There are fields such as author and title that will certainly be present in every entry. Because care has been taken to bring all the data into a uniform format, it can often be searched very easily.
This type of data is found in every library database that we know of, for example. For instance, there is an entry in the World Cat Library Database for “The White Star timetable, South Island of New Zealand: the official guide of the White Star Tourist Services Ltd., 1924–25”, and we are told its author: “White Star Tourist Services”, language: “English”, and that it includes advertising.
Structured data is extremely useful. If you know you need information on “duck-billed platypuses”, for instance, it will help to look through “zoology” and “animal” topics. The problem with structured data, of course, is that the structure needs to be created and imposed on the data. This takes work, which for many centuries had to be done by librarians, filing clerks, and other human beings. Somebody had to enter all that stuff about the New Zealand bus timetable. Thus, we have much more unstructured data available, most strikingly in the form of the millions of files on the internet. A number of search engines allow us to search for information over the web, for example Google.
After examining structured databases, we will turn to so-called semi-structured data. Not every document will have the same structure or format as every other document, and fields may vary substantially from document to document. For example, in a database of internet movie reviews, some reviews might be based on a four-star system and others on a five-star system. The data contains useful categorizations, but the user may have to work harder to extract information. As we will discover, so-called regular expressions are useful for this type of searching.
Finally, we will turn to smaller, more focused collections of data, using text corpora (i.e., collections of text) as our example. The advantage of using focused databases means that searching can also be more focused, for example in the form of looking for linguistic patterns. Additionally, there is a benefit to small size, which is that a small team of humans can add very rich and detailed special-purpose information about the document. We will illustrate this possibility by showing how linguists use corpus annotation
.
A library catalogue is an excellent example of structured data. To find articles, books, and other library holdings, a library generally has a database containing information on its holdings, and to search through this, each library generally provides a database frontend. For the exercises in this chapter almost any library will do, so long as it has an online search interface, as most now do. Alternatively, you can use WorldCat (http://www.worldcat.org), which is available to anyone with internet access and indexes libraries all over the world. We cannot promise that you will see exactly the same search features for every library, but what we describe here is fairly typical.
A library catalogue is highly structured. Each item is associated with a fixed set of fields – the author, title, keywords, call number, and so on associated with an item. You can select which field you want, and search for the occurrence of literal strings within that field. If you know that a book was written by someone with a last name of “Haddock”, which is not a very common name, an AUTHOR search in a library catalogue may produce a tight set of results that you can easily look through. Doing the same with a simple internet search for the word “Haddock” might produce a much larger and less manageable collection of results, since the search engine would have no way of knowing that you are looking for a book and its author.
At the core of a database search is the task of searching for strings of characters. The literal strings entered as queries are composed of characters, which of course must be in the same character-encoding system (e.g., ASCII, ISO8859-1, UTF-8) as the strings stored in the database.
Online library catalogs have existed for decades, and some were designed to work with old-fashioned Teletype terminals, which did not have lower-case letters. So you may find that your query is quietly converted to upper case before being submitted as a search. It could even be that the accents and diacritics on queries written in foreign languages are dropped or otherwise transformed. If this happens, it is because the software designers are trying to help you by mapping your queries onto something that has a chance of being found in the database.
Database frontends provide different options for searches, allowing more flexibility than simply searching for strings, including the use of special characters. For example, some systems such as WorldCat allow you to abbreviate parts of words. A typical special character is the wildcard, often written as *; this symbol is used to stand in for a sequence of characters. For example, the query art* might find “arts”, “artists”, “artistic”, and “artificial”. There may also be other characters that stand in for a single character or for a particular number of characters, and, in fact, the exact effect of a wildcard may vary from system to system – some only apply at the ends of words, some are restricted to less than five characters, and so on. While special characters are useful and are sometimes the only option you have, we will later see more principled ways of searching with regular expressions (Section 4.4).
Boolean expression operators allow you to combine search terms in different ways. The use of and, or, and parentheses provide the basics. For example, (30a) finds items with both the word “art” and the word “therapy” used somewhere, while (30b) finds anything containing either word, thus returning many more documents. The operator and not functions similarly, but allows words to be excluded. For example, if a search on art is returning too many books about art therapy, one could consider using a query like (30c). When using more than one operator, parentheses are used to group words together. The query (30d) eliminates documents about either “music therapy” or “dance therapy”. With such operators, we can be fairly specific in our searches.
While Boolean expressions are fairly simple in their basic form, they can become overwhelmingly confusing when they are combined to form long and complex queries. There is also an ever-present risk of typing mistakes, which grows as the query gets longer. When learning Boolean expressions, therefore, it pays to test out simple queries before trying more complicated ones. When we need to build a complicated query, we do not usually type directly into the search box. Instead, we type into a text editor, write a simple version of the expression, then paste the result into the search box. If that works, we go back to our text editor, copy the query that we just ran, then create a slightly more complex version. If we mistype, we have a record of what we have done and can backtrack to the last thing that seemed to work. The exercises at the end of the chapter should help you in your progress.
In some respects, unstructured data presents a completely different scenario: there is no explicit categorization of the documents to be retrieved. In other respects, however, the fundamentals are the same: searching through unstructured data is closely related to doing a keyword search in structured data. What distinguishes searching in unstructured data tends to be the sheer scale of the data, with billions of webpages to search through. Some of the searches that providers can easily do with a small, structured database are difficult or impossible at web scale. The consequences of this difference in scale show up in the different operators that are typically offered, in the subtly varying behaviors even of operators that look the same, and in the different actions that users can take in order to improve their search results.
We must make one further point about structure before continuing. When we say that the data is unstructured, what we really mean is that no one has predetermined and precoded the structure of the data for us. We are not saying that structure is entirely absent. Consider the case of trawling the web looking for English translations of Chinese words. There is no field for a webpage labeled English translation, but there are many pages that display a Chinese word followed by an English word in brackets (e.g., [word]). Even better are cases with an explicit marker of a translation (e.g., [trans., word]). There even exist bilingual dictionaries online with the words in column format. Certainly, there is structure in these examples. The point of calling the data unstructured is to draw attention to the facts that the structure is not predetermined; it is not uniformly applied or standardized; and fields, such as Chinese, English, and etymology, are not available for use in queries. If we wanted, we could process the examples, bring them into a uniform structured format, and offer the world a structured interface into our web-derived Chinese–English dictionary. And if we really wanted, we could have a team of bilingual librarians check and edit the structure to make sure that the Chinese words, English words, and other fields have all been correctly identified.
To discuss searching in unstructured data, we need to discuss the concept of information need. The information need, informally, is what the information seeker is really looking for. Before this can be submitted to a search engine, it has to be translated into a query. It is often the case that the query is an imperfect reflection of the information need. Consider, for example, the case where a person is searching for a Russian translation of “table”, as shown in (31). It is obvious what the connection is between the information need and the query, which is russian translation table. Unfortunately, this query is ambiguous: the same query might easily be chosen by someone looking for a table, or chart, of Russian translations. Since the search engine is not able to see into the mind of the searcher, it cannot reliably tell which of these interpretations is correct, so the results will probably not be as focused as the searcher expects.
The concept of information need affects how we view evaluation. One can see this in the evaluations used for the Text REtrieval Conference (TREC, http://trec.nist.gov/), for example, as illustrated in Figure 4.1. To evaluate search technology, they express the information needs in natural language and have written down queries intended to capture those needs. Human beings then compare the documents returned by the information retrieval systems with the descriptions of the information needs. A document is judged relevant if it meets an information need. Systems that place relevant documents high up in the list of results are given high scores.
Figure 4.1 Characterization of an information need in a TREC evaluation
More specifically, TREC defines “right answers” in the following way: “If you were writing a report on the subject of the topic and would use the information contained in the document in the report, then the document is relevant” (http://trec.nist.gov/data/reljudge-eng-html). The definition is fairly open-ended, but it gives guidance for a human to evaluate whether a document is a match or not.
However, that leads to a numerical question: How many pages is the search engine getting right? For a given search engine and query, attempting to match a particular information need, we require some way to measure search engine quality. Two common measures from computational linguistics are worth examining here, as they help to outline the different ways in which search engines do or do not meet our needs (see also Section 5.4.1 in the Classifying Documents chapter). The first measure is precision, which can be phrased as: Of the pages returned by a search engine, how many are the ones we want? Consider the case where an engine returns 400 hits for a query, 200 of which are related to the desired topic. In this case, precision is 50%, or 200 out of 400.
The second measure is recall: Of all the pages in existence on the topic we wanted, how many were actually given? Consider the case where an engine returns 200 pages, all of which we wanted (as above), but there were actually 1,000 pages on that topic on the internet (we missed 800 of them); recall is thus 20% (200/1,000). Note that the numerator (200) is the same for both precision and recall.
Nevertheless, how can we know that there are 1,000 pages out there? In TREC, researchers used fixed collections of documents, so they were able, with effort, to know exactly how many relevant documents were in the collection. But if you are working with the whole of the internet, no one knows for sure how many relevant documents there are. Even if someone were prepared to try to count the number of relevant documents by hand, by the time they were halfway through, many relevant documents may have been added or deleted. So, in practice, while recall is a useful concept, it cannot always be calculated with any certainty. (In medical science, recall is also used, but goes by the name of specificity, as discussed in Section 5.4.1.)
The goal of a search engine is to provide 100% recall (so that we find everything we want) and 100% precision (so that we do not have to wade through unhelpful pages). These are often competing priorities: you can get 100% recall by returning every single webpage in existence, but this would be overwhelming. On the other hand, a search returning one webpage could have 100% precision, but at the cost of lack of coverage.
The most familiar form of unstructured data is the web, which contains billions of webpages and very little in the way of categorization. To find information on the web, a user goes to a search engine, a program that matches documents to a user’s search requests, and enters a query, or a request for information. In response to this query, the search engine returns a list of websites that might be relevant to the query, and the user evaluates the results, picking a website with the information they were looking for or reformulating the query.
As web pages are typically uncategorized, the main thing that search engines must rely on is the content of each webpage. They attempt to match a query to a page based primarily on words found in the document. This can be difficult, given the common problem of (lexical) ambiguity; that is, a single word having multiple meanings. The presence of a word like “Washington”, for example, does not tell us whether this is the author of the webpage, the location of the webpage (or which exact Washington location), a page about the first president, a listing of all last names in the USA, and so on.
Some webpages do contain some degree of structure, which can be exploited by a search engine. For example, web designers can offer useful information by including metadata – additional, structured information that is not shown in the webpage itself, but is available for a search engine. An example of a meta tag is something like < META name = “keywords” content = “travel,Malta”>. This information is present in the HTML text that the web designer creates, but is not displayed by web browsers. HTML is the raw material of the internet. Some web designers use a text editor to write HTML directly; others use word processors or other authoring tools to create the webpage, then save it as HTML when it is ready for the website. If you are unfamiliar with HTML, see Under the Hood 6.
Most of what we say in this chapter is true of all search engines, but each search engine has its own special features designed to make life easier for the user, and these can vary. For instance, search engines may differ in the details of what they count as a word. They may differ in whether they treat words with the same stems (e.g., bird and birds) as the same, or as different. They may treat words with differing capitalization (e.g., trip and Trip) as the same or not. And, of course, any of the four possible ways of combining capitalization and stemming is a possibility. Search engines use a simple criterion to decide about these and other options: they analyze search behavior and try to predict whether a policy will help searchers.
Most current search engines do collapse upper- and lower-case letters together. We just tried a search for BLUEFISH on a famous search engine, and it produces exactly the same results as a search for bluefish. They do not seem to do the same for stemming: our search for fish does not produce the same results as for fishes. We can be pretty sure that this policy is not accidental, but is based on careful observation of what seems to work well for the majority of search users. What works for the majority may not be perfect for the minority, however. For example, searches for Tubingen, Tübingen and Tuebingen all produce the same search results, even though only the second two are correct spellings of the German city of “Tübingen”. The search engine apparently has a policy of mapping English characters to relevant non-English characters, because it knows that this will help people not used to German. People who are used to German may be confused by this behavior, and those who are trying to use web search to study the ways in which people tend to type German words will definitely hate the policy.
Additionally, search engines have user-selectable options, and they differ in which options they support in the query. For example, Google allows users to request results written in a particular (human) language. Most web pages do not explicitly declare what language they are written in (they could do this, using metadata, but they usually do not), so the search engine has to make an informed guess (see Chapter 5 on Classifying Documents for ideas about how this might be done).
Search engines also try to present their results in a convenient way. For example, search engines can offer ways to cluster pages – in other words, to group similar results together. Instead of presenting a long list of very similar results, the search engine can show the user one representative of each of the important clusters. For example, a search for tricks currently produces five top-level results: a cluster for bar tricks, another cluster for magic tricks, an encyclopedia definition of a hat trick, a similar definition of a trick-taking game, and finally an Urban Dictionary entry for various slang usages of the term. The first two are genuine clusters, with a representative page, and little links to other members of the cluster. The last three are somewhat special, because the search engine in question knows that search users often have information needs that are satisfied by encyclopedia and dictionary entries. Because the web lacks explicit structure, the search engine once again has to make an informed guess about which pages are similar. The decisions about how to satisfy search users will be made on the basis of careful experimentation, data collection, and analysis. The rapid progress of modern search engines is due in large measure to the fact that search engine companies have learned how to automate this work, making it possible to apply the scientific method, in real time, to the complex and changing desires of search users.
Perhaps most importantly, search engines differ in how search results are ranked. As we hinted when discussing clusters, a search engine’s success depends on how it ranks the results that are returned in response to a query. When a search query has been entered, the webpages matching this query are returned as an ordered list based on guesses about each page’s relevance to the query. But how can a search engine, which does not understand language, determine the relevance of a particular page?
There are a number of general factors that search engines can use to determine which webpages are the most likely responses to a query. First, there is comparison of the words in the document against the words in the query. Clearly, pages that mention the words in the query are likely to be better than ones that do not. Pages that mention the query words a lot are probably even better. And pages that mention query words near the top of the document, or even in a title, may be best of all. Search engines deal with this by weighting words according to their position, the number of times that they appear on the page, and so on. Highly weighted words strongly affect the ranking of the page, less highly weighted words have a lesser effect. Depending on the nature of the page, words mentioned in its metadata may need to receive a special weight: either high, if the search engine believes the metadata to be trustworthy, or very low, if the search engine judges that the metadata is an attempt to mislead it. (See the section on Search engine indexing for more details on how words are used.)
Estimating a page’s quality can be much more sophisticated and is usually done by counting the number of links to and from a page because these are an effective measure of how popular a page is. There is a balance to be struck here: an engine that relied entirely on popularity estimates might make it nearly impossible to find pages that are either new or relevant only to a small minority of search users. We will discuss this more in the section on How relevance is determined. Relatedly, search engines can measure how often users click on a result, called the click-through measurement; the more users who click on a link, the more likely it is that the page at the other end of the link is of interest.
While using a search engine is usually straightforward, you may have noticed some curious functionality sometimes. For example, a search engine such as Google returns a list of results and provides a brief excerpt from the webpage; an example of searching for indiana linguistics is provided in Figure 4.2. Occasionally, when you click on a link, the page is gone or the content is radically different.
Figure 4.2 A Google search result for indiana linguistics

It would be nice to know why these links die: What is going on in the background to make this happen? To understand this, we need to know that most of the work associated with satisfying a query is done ahead of time, long before the user has even thought of carrying out the search.
Specifically, it works like this: at some point in time, the engine crawls the web, following links and finding every webpage it can. It stores a copy of all web pages (this takes a lot of space, which is why search engines need huge data centers), and it also creates an index of all the pages it crawls. This index is used to provide efficient access to information about a large number of pages (e.g., Google currently searches over 1 trillion pages, http://googleblog.blogspot.com/2008/07/we-knew-web-was-big.html). The search engine determines the relevance of each page using only the record of the page’s contents that is stored in the index. The index is also used to construct the so-called snippets, the little extracts that are provided along with the search results. There is no guarantee that the page is still there: all that the engine really knows is that the index contains information about the way the page looked at the moment the index was built.
The indices of real-world search engines are pretty complicated, and they do far more than simply maintaining a list of words. They will also track the position of words on a page, note whether the words are in the title, contain information about the metadata and its trustworthiness, and so on. Nevertheless, the basic ideas are simple, and it is to these that we now turn.
Search engines need to store data in a way that enables them to have efficient access to it later on. Think about it: if you have one trillion pieces of information, you cannot store them just anywhere and hope to find what you want quickly; the pages need to be indexed, so that the search engine can find what it needs quickly later on. Conceptually, this is similar to the index at the back of a book: it helps us find terms quickly. In this section, we are going to examine the basics of how to index data, basing our discussion on Manning, Raghavan, and Schütze (2008).
To begin with, as a search engine crawls the web, it builds a term-by-document matrix. The term-by-document matrix shows which terms (i.e., words) appear in which documents (in this case, webpages). We can get a sense of what happens by looking at part of a term-by-document matrix for a few mystery novels in Figure 4.3. We use words here, but lemmas or stems may also be used.
Figure 4.3 Excerpt from term-by-document matrix for mystery novels
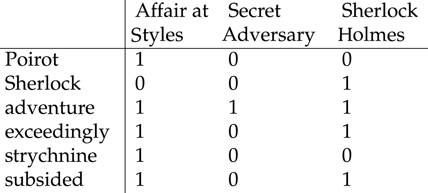
In Figure 4.3 terms are listed in the left-hand column, and for each novel (e.g., Agatha Christie’s The Mysterious Affair at Styles), a 1 denotes that the word appears in that document, and a 0 denotes that it does not.
In this process, common words may be left out; these are often referred to as stop words. This means that words like “I” or “the” are not always included in the index or subsequently in searching. There are two benefits to this: first, it saves time and effort if you ignore words and do not need to store them; secondly, these words are uninformative, because they appear in almost every document, and are very unlikely to make a difference to judgments about the relevance of a particular document.
Recall that this matrix building is done offline; that is, before the search engine is queried. Thus, we can afford to do extra work to make the search process efficient. Specifically, we can take the term-by-document matrix and derive a representation that is faster for page lookup, namely what is called an inverted index. If we assume that every document has a unique ID, in this case a number (e.g., Secret Adversary = 2), then we can see an example of part of an inverted index in Figure 4.4. Each term now points to a list of documents in which it appears. This is a very efficient structure: if the query contains the word strychnine, for example, a single access into the inverted index gives us a list of all the documents in which that word appears.
Figure 4.4 Excerpt from inverted index for mystery novels

When someone searches for adventure AND strychnine, we need to combine information from two different lines of the inverted index. This is quite straightforward: simply take the intersection of the two document lists to which “adventure” and “strychnine” point. In this case, the intersection will certainly contain at least documents 1 and 15, and possibly others not shown in Figure 4.4.
For even more complex queries, there are steps that can be taken to ensure that query processing is efficient. Consider if someone searches for poirot AND adventure AND strychnine. In this case we have to intersect three lists. We know that the result of intersecting three lists is the same as first intersecting two lists, then intersecting the result with the third list. It is up to us to decide which two lists should be handled first, and which list should be left until last. This choice is not going to affect the final result, but can it affect the efficiency of the process of getting to the result?
To answer this, we need to understand that the task of intersecting lists takes longer the longer the lists are. For example, “adventure” has a long list of documents, as mystery novels seem frequently to reference adventures. If we take another frequent word, such as “murder”, the result will be another long list, and it is likely that their intersection will be lengthy, too; that is, they have much in common. But “strychnine” is less common, and “poirot” tends only to appear in Agatha Christie books, so these lists are shorter. For efficiency, we can intersect the shortest lists first. This will probably be effective, because the intersection of two short lists is likely to be short. Thus, internally, the search engine looks at the query words, finds the length of their document lists, and reworks the query to specify the order of operations. In this case, for example, poirot AND adventure AND strychnine becomes (poirot AND strychnine) AND adventure. Strictly speaking, this strategy does not guarantee optimal efficiency, because it could turn out that the intersection of two lists that are short but very similar will be longer than the intersection of two other lists that are long but very dissimilar. Nevertheless, in practice, the strategy of doing the shortest lists first is a very good one, and saves a great deal of time and effort.
Figure 4.5 An excerpt of web source code from English Wikipedia (accessed July 13, 2009)

Figure 4.6 Basic HTML tags

Now that we know a little more about what goes on in the background, we can begin to look at how search engines are able to match queries to content on webpages with a high degree of precision. And we have the tools to understand how search engines can group pages into meaningful clusters.
As mentioned, search engines use many different kinds of information to determine webpage relevance. One method in particular has become increasingly influential over the years, and it is referred to as PageRank. This algorithm was developed by Larry Page and Sergey Brin and was used as the basis of their start-up company in the late 1990s: Google. It relies heavily on the idea that when a person bothers to make a link to some other page, the page is probably somehow noteworthy, at least for the person making the link.
We will sketch out the ideas behind the PageRank algorithm here, by looking at a particular example of page linking. Consider Figure 4.7, where each square represents a webpage. In this case, pages X, Y, and Z all link to page A. The question is whether these links are any better or worse than those that link to page B, shown in Figure 4.8.
The way PageRank determines which pages are better is to reason about the relationship between links and popularity. If a site has a large number of incoming links, it must be well-known, and this could be because people like it.
Thus, we calculate importance based on popularity, where popularity is estimated based on how many sites link to a website and how popular each one of those is. In order to compare how popular website A is compared to website B, we can add up how popular each incoming site is. It might help to think of the situation like this: each site that links to A gets to vote for A, and each of them gets a different number of votes based on how popular each of them is.
Figure 4.7 Weblinking: X, Y, and Z all link to A
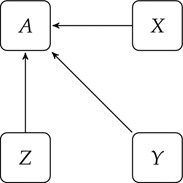
Figure 4.8 Weblinking: V, W, and X all link to B
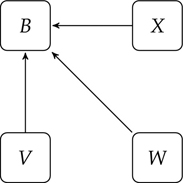
If you are bothered by the idea that Google is based on a popularity contest, you can replace the word popular with the word authoritative in the discussion above. And if you do not like that, you can just use the term PageRank instead. The algorithm does not care what we call our measure of quality, only that every page has a score, and that the score of a page is related to the score of the pages that provide its incoming links.
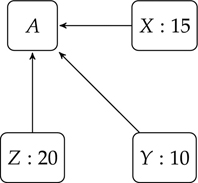
To see how the calculations are done, consider Figure 4.9. Here, X casts 15 votes for A, Y casts 10, and Z casts 20. This may make intuitive sense, but we are stuck with an immediate problem: the website A now has 45 votes, and that is clearly too many. After all, the most popular incoming site only had a score of 20. This way of adding will lead to ever-increasing popularity scores.
Figure 4.9 Pages with weights
We want a solution that distributes votes from pages in a sensible way. The solution PageRank uses is to spread out each page’s votes through all the pages to which it links. Viewing this as a voting process, it means that each webpage must split its votes among all the pages to which it links. In Figure 4.10, for example, the webpage X has 15 votes, and it links to 3 pages. Thus, it casts 5 votes for each of those pages.
Figure 4.10 Dividing the weights
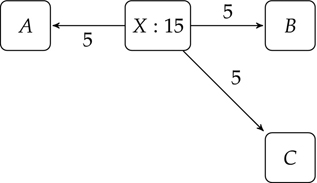
Let us assume, then, that after spreading votes out among their different webpages, A’s final score is 12. Which leads us to ask: 12 of what? What does it mean to have a score of 12? Is that good or bad?
Truth be told, scores on their own do not mean much. We need to compare the score to other websites to determine a relative rank. If website B’s score is 10 and A’s is 12, we can say that A is preferred, and we may want to call it authoritative. If, when the search engine analyzes the words on the pages, two pages seem to be equally relevant in their content, then the page rank score can be used to determine which webpage is placed nearer to the top of the results list.
To sum up so far, there are two main factors to consider when calculating a ranking for a website based on its weblinks: links coming into a website, and links going out of a website. The formula (at least for Google) captures these properties. It can be seen in (32) for webpage A with three pages linking to it: we use R(X) to mean the rank of page X and C(X) to refer to the number of pages going out of page X.
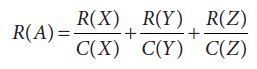
Let us make sure that this formula represents what we want it to. First, we add up the scores of the different pages coming into A (e.g., R(X)) because, in order to know how popular A is, we need to know how popular everyone else thinks it is. Secondly, we divide each score by the number of pages going out of X, Y, and Z (e.g., C(X)) because we are spreading out their weights among all the pages to which they link. And this tells us how popular a site is, one factor used in ranking results.
As mentioned in the introduction to this chapter, semi-structured data contains some categorization, but is not fully structured. Wikipedia entries and the Internet Movie Database (http://www.imdb.com) are good examples: since users add much of the content, the way the sites are structured and categorized varies from user to user. Yet there is structure there, even if it takes a little more work to uncover.
Looking at the Internet Movie Database, let us compare the pages of two different actresses, namely Nancy Cartwright and Yeardley Smith, who are the voices for Bart and Lisa Simpson, respectively, from the popular television show The Simpsons. (If you are unfamiliar with The Simpsons, we fear that you may also not know what a television is.) On October 27, 2011, the page for Nancy Cartwright listed her as Nancy Cartwright (1) since there are multiple actresses with that name, yet Yeardley Smith had no such designation; implicitly, it is Yeardley Smith (1). Additionally, Yeardley Smith’s bio page listed a Mini Biography, while Nancy Cartwright’s bio page only listed Trivia.
Looking at their biography/trivia information, consider how the information is written down, as illustrated in Figure 4.11.
Figure 4.11 Some snippets of trivia about Yeardley Smith
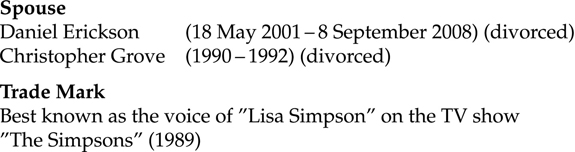
Note, first of all, that if we are searching for dates, they come in different formats with different information: “1990” vs. “18 May 2001”. It is likely that there are also dates listed on imdb in the format “May 18 2001” or “May 18, 2001”. Secondly, note that there is no field for voice (at least on the bio page), just as there is often no information distinguishing an actor’s role as a lead role, supporting role, or cameo – yet the information is often there to be had.
Or consider this snippet of trivia about Nancy Cartwright: “Attended Ohio University from 1976–1978 as an interpersonal communication major and was awarded the Cutler Scholarship for academic excellence and leadership.” What if we want to find out where different actors went to school? We would have to find patterns such as X University, Y College, or University of Z, as well as misspelled variants of these. Then, there are references such as this one from Parker Posey’s bio: “Parker attended high school at R. H. Watkins High School in Laurel, Mississippi, and college at the prestigious SUNY Purchase.” Here, “university” is only found as a U within an abbreviation. If we also wanted to search for an actor’s major, we would have to search for studied X at Y, majored in X, a(n) X major, and so forth. In both cases, we are describing a search not just for specific strings, but for patterns in the data.
We are starting to see the need for searching over more complex patterns of words and text. Think also about the following scenarios: (i) In a large document you want to find addresses with a zip code starting with 911 (around Pasadena, CA); you clearly do not want to also find emergency phone numbers in the document. (ii) You want to find all email addresses that occur in a long text. You cannot just search for a few words; you need to specify patterns.
Any time we have to match a complex pattern, regular expressions are useful. A regular expression is a compact description of a set of strings. So, a regular expression can compactly describe the set of strings containing all zip codes starting with 911 (in this case, the regular expression is /911[0-9][0-9]/, which is explained below).
Regular expressions have been extensively studied and their properties are well known (see Under the Hood 7 on finite-state automata and their relation to regular expressions). In formal language theory, language is treated mathematically, and a set of strings defines a language. For instance, English is defined as the set of all legitimate English sentences. As in other formalisms, regular expressions as such have no linguistic content; they are simply descriptions of a set of strings encoding a natural language text. While some patterns cannot be specified using regular expressions (see Under the Hood 4 on the complexity of grammar), regular expressions are quite suitable for our purposes.
Regular expressions are used throughout the computer world, and thus there are a variety of Unix tools (grep, sed, etc.), editors (Emacs, jEdit, etc.), and programming languages (Perl, Python, Java, etc.) that incorporate regular expressions. There is even some support for regular expression usage on Windows platforms (e.g., wingrep). The various tools and languages differ with respect to the exact syntax of the regular expressions they allow, but the principles are the same. Implementations are very efficient so that large text files can be searched quickly, but they are generally not efficient enough for web searching.
We can now turn to how regular expressions are used to describe strings. In this section we will discuss the basics of the syntax, and in the next section we will walk through the use of regular expressions with one particular tool. Note that while some of the symbols are the same as with basic search operators (e.g., *), as outlined in section 4.2, they often have different meanings. Unlike search operators – whose definitions can vary across systems – regular expressions have a mathematical grounding, so the definition of operators does not change.
In fact, regular expressions can consist of a variety of different types of special characters, but there is a very small set of them. In their most basic form, regular expressions have strings of literal characters; examples include /c/, /A100/, /natural language/, and /30 years!/. In other words, we can search for ordinary strings just as we would expect, by writing them out. One note on putting regular expressions between forward slashes: this is a common representation, but in the next section we will see that each application has its own way of referring to regular expressions.
To allow for different possibilities, we can add disjunction. There is ordinary disjunction, as in /devoured|ate/ and /famil(y|ies)/, which allows us to find variants of words – “devoured” and “ate” in the former case, and “family” and “families” in the latter – and there are character classes, defined in brackets, to specify different possibilities. /[Tt]he/, for example, matches either “The” or “the”; likewise, /bec[oa]me/ matches “become” or “became”. Finally, we can specify ranges, as in /[A–Z]/, which matches any capital letter. For our earlier problem of finding all zip codes starting with “911”, then, we can specify / 911[0–9][0–9]/, which nicely excludes “911” when followed by a space.
In addition to disjunction, we can use negation, to specify characters that we do not want to see. We use the character class notation ([. . .]), with ^ denoting that it is not this class. For example, /[^a]/ refers to any symbol but a, and /[^A–Z0–9]/ indicates something that is not an uppercase letter or number.
Regular expressions begin to display their full range of power in the different counters available. These counters allow us to specify how often an item should appear. First, we can specify optionality through the ? operator; ? means that we can have zero or one of the previously occurring item. For example, /colou?r/ matches either “color” or “colour”. Secondly, we have what is called the Kleene star (*), which allows for any number of occurrences of the previous item (including zero occurrences), for instance /[0–9]* years/. The third and final counter is very similar, but it stands for one or more occurrences of the previous element and is represented by +. So /[0–9] + dollars/ requires there to be at least one digit, but possibly more.
Another operator that allows us to specify different possibilities is the period (.), a wildcard standing for any character. Thus, the query /beg.n/ designates that there can be any (single) character between “beg” and “n” (begin, began, beg!n, etc.).
Because we have defined special uses for a variety of characters, we also want a way to search for those actual characters. For example, how can we search for a question mark (?) when it has a special meaning? To do this, we use escaped characters, which allow us to specify a character that otherwise has a special meaning, and we notate this with a backslash: \*,\+,\?,\(,\),\|,\[,\].
Table 4.1 Summary of Regular Expression Operators
| Operator | Notation |
| 1.Parentheses | (…) |
| 2.Counters | ? , *, + |
| 3.Literals | a, b, c, … |
| Escaped characters | \?, \*, \[, … |
| Wildcard | . |
| 4.Disjunction | |, […] |
| Negation | [^…] |
With a variety of different operators, there can sometimes be confusion about which applies first. But there are rules of operator precedence, just like in arithmetic, where, for example, in evaluating 4 + 5 × 6, we obtain 34 because multiplication has precedence over addition. Likewise, there is a precedence for regular expressions, as summarized in Table 4.1. From highest to lowest, this precedence is: parentheses, counters (* + ?), character sequences, and finally disjunction ( | ). So if we see, for example /ab|cd/, this matches either ab or cd, because character sequences have precedence over disjunction. (If disjunction had higher precedence, we would match abd or acd.)
To illustrate fully how regular expressions work, we are going to walk through a tool used on a variety of platforms to find sequences in text. This tool is called grep, and it is a powerful and efficient program for searching in text files using regular expressions. It is standard on Unix, Linux, and Mac OSX, and there also are various translations for Windows. The version of grep that supports the full set of operators mentioned above is generally called egrep (for extended grep). By the way, grep stands for “global regular expression print.”
We list a variety of examples below. For each, we assume a text file f.txt containing, among other strings, the ones that we mention as matching. The purpose of grep or egrep is to return the lines that contain a string matching the regular expression.
Strings of literal characters egrep ‘and’ f.txt
matches lines with:
and, Ayn Rand, Candy, standalone, …
Character classes: egrep ‘the year [0-9][0-9][0-9][0-9]’ f.txt
matches lines with:
the year 1776, the year 1812a.d., the year 2112, …
Escaped characters: egrep ‘why\?’ f.txt
matches lines with:
why?, …
but does not match lines with:
why so serious, …
Disjunction (|): egrep ‘couch |sofa’ f.txt
matches lines with:
couch, w sofa, couched, …
Grouping with parentheses: egrep ‘un(interest |excit)ing’ f.txt
matches lines with:
uninteresting, unexciting
but does not match lines with:
uninterested, super-exciting
Any character (.): egrep ‘o.e’ f.txt
matches lines with:
ore, one, sole, project, …
Kleene star (*): egrep ‘sha(la)*’ f.txt
matches lines with:
sha, shala, shalala, …
but does not match lines with:
shalaaa, shalashala, …
One or more (+): egrep ‘john + y’ f.txt
matches lines with:
johny, johnny, johnnny, …
but does not match lines with:
johy
Optionality (? ): egrep ‘joh?n’ f.txt
matches lines with:
jon, john, jones, …
This should give you a flavor for regular expressions and a good sense of what they can accomplish. We have a few exercises at the end of the chapter to get you more acquainted with regular expressions, but to use them in your daily life, you should look for a tutorial online or exercises in a book, as regular expressions take practice to master. Although they may be new to you, regular expressions are useful in a variety of purposes, including searching for linguistically interesting patterns, an issue we turn to below. There are thus a range of regular expression resources to play with!
Figure 4.12 A first automaton
Figure 4.13 A second automaton
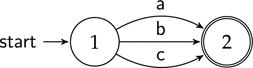
Figure 4.14 An automaton with a loop
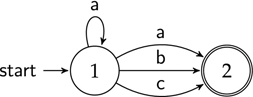
Figure 4.15 An automaton with three states

Figure 4.16 Viewing an automaton as a flight path

Figure 4.17 A one-state automaton with a loop
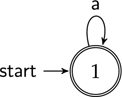
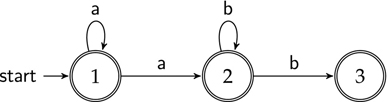
Figure 4.18 An automaton for /a*b*/
The final type of searching context we will examine is searching through corpora (singular form = corpus), which are collections of text. There are a variety of corpora available, containing the works of various writers, newspaper texts, and other genres. Once these documents have been collected and electronically encoded, we can search these texts to find particular expressions (see Under the Hood 8 on Searching for linguistic patterns), and the bigger the corpus, the more likely we are to find what we want. Luckily, corpora can be quite large. The British National Corpus (BNC, http://www.natcorp.ox.ac.uk), for example, is a 100-million-word collection representing a wide cross-section of contemporary written and spoken British English, and there is also a similar American National Corpus (ANC, http://www.americannationalcorpus.org). Another example of a useful large corpus is the European Parliament Proceedings Parallel Corpus 1996–2006 (http://www.statmt.org/europarl/), which has 11 languages and 50 million words for each language.
Both the BNC and the European Parliament corpus can be searched using online web forms, and these generally allow the use of regular expressions for advanced searching. To provide efficient searching in large corpora, in these search engines regular expressions over characters are sometimes limited to single tokens (i.e., words).
If all we want are large datasets, why not just use web searches all the time? After all, the web is the largest data source we have. While this is true, there are some downsides to using web data. To begin with, if there is any case in which we want uncorrupted data – or data that has been edited or proofread – then the web is clearly not a good source. Certainly, there is “clean” data on the web, such as newspaper websites, but we cannot easily determine the type of language being used (see Chapter 5, though, on Classifying Documents). Furthermore, there often are duplicate documents on the internet, for instance stories distributed by Associated Press and posted on multiple news websites. If we search for something and find it 10,000 times, how can we ensure that 500 of those times were not duplicates?
Consider another issue: What if we are interested in what people in the USA think about a particular topic? Which websites are written by people in America? Suffixes of website names (e.g., .edu) give some clues, but these are not foolproof, as, for example, Americans studying abroad may maintain a website hosted on their school’s computer (e.g., .uk). If we want to ask what women in America say about a topic or what Southern women say about a topic, we are in a deeper quagmire using the internet, with its lack of classified webpages.
So, although bigger data is generally better, there are times we only want relevant and classified data. This is especially true if we want to make scientific generalizations on the basis of some set of data: we need to have the data collected in such a way that we know what its properties are, in order to know how any results may be generalized. Because corpora are usually carefully collected bodies of text, they allow us to draw more solid conclusions.
Corpora have also been good places to find various types of annotation; that is, mark-up of different properties of the text. To think about what kind of annotation is useful for different tasks, let us start by considering what kind of annotation we would like to have in webpages.
We mentioned in Section 4.3.4 that the PageRank algorithm works by taking linking relationships between webpages and deducing how reliable each page is. But using weblinks is a very coarse way of determining the relationship between two pages. It would be good if humans could specify not just the fact that two webpages are related, but how they are related.
The Semantic Web is a recent innovation that helps address this issue by incorporating more information about a webpage’s content. The framework of the Semantic Web allows web designers to specify how concepts and webpages are related to one another. For example, a webpage can be annotated with a description like car. If a hatchback is specified as a subclass of car, and another webpage states that ToyotaMatrix represents a type of hatchback, then we can infer that ToyotaMatrix represents a type of car. Such hierarchical groupings can assist in determining whether a search for, for instance, the term hatchback should return the Toyota’s page. A company like Toyota, Mercedes-Benz, or whoever else might be prepared to put effort into such annotation so that consumers can easily find out information about its products.
The relations we are describing form a hierarchy of data, where words are synonyms, hypernyms, and hyponyms of each other (see also Section 7.6). The OWL Web Ontology Language makes specific what kinds of relations can be defined. This allows web designers to create an ontology, specifying the concepts within a world and their relationships. For marketing research firms (e.g., J.D. Power and Associates), such ontologies are important for articulating the relationships between consumer goods, especially big-ticket items such as cars. Another way of stating what the Semantic Web does is that it makes explicit some of the structure that is already present in this unstructured web data.
As it turns out, mark-up conveying semantic properties is used frequently with language data, in order to annotate different linguistic properties. As just mentioned, such information can improve searching by knowing the content of a document. But annotating linguistic properties has a wider reach. Consider the fact that knowing a word’s part of speech can help us differentiate between one use of a word and another (e.g., for plant). If we have a corpus annotated with grammatical properties such as part of speech, then this can help us build tools that can automatically mark part of speech. This gets us into corpus linguistics, which is the study of language and linguistics through the use of corpus data.
Linguistic annotation can come in many different forms: morphological annotation (subword properties like inflection, derivation, and compounding), morphosyntactic annotation (part-of-speech tags), syntactic annotation (noun phrases, etc.), semantic annotation (word senses, verb argument annotation, etc.), and discourse annotation (dialog turns, speech acts, etc.).
Annotation is useful not just for providing information to, for example, search engines, but for training natural language processing (NLP) tools: the technology can learn patterns from corpus annotation. Corpus annotation is also useful for finding linguistic examples. Questions such as the following can be most easily answered if we have different kinds of morphosyntactic annotation, for example:
Let us consider the case of part-of-speech (POS) annotation and look at an example of how to represent it. For POS annotation, we need to associate a POS tag with every word, as in Figure 4.19.
Figure 4.19 POS annotation

An example of syntactic annotation is given in Figure 4.20. This is the same tree as in Figure 2.9, but represented differently. Importantly, the bracketing given here is systematic and completely text-based, so that computers can easily process it. Other annotation types include those for word sense, semantic predicate-argument structure, discourse relations, and so on.
Figure 4.20 Syntactic annotation

After reading the chapter, you should be able to:
Looking at the list of queries below, which of the subject numbers do they match? For example, rock AND bomb matches 3, 8, 9, and 11.
The rules for googlewhacking are:
Attempt to find a googlewhack, or as few hits as possible, using only two words without quotation marks. In doing so, discuss the following:
Assume that we initially assign every page a score of 1.
We will walk through how to search through this document using a Mac. For Windows, you will have to use something like WinGrep, but the principles are the same. Versions of grep for Windows can be found in a number of places such as http://purl.org/lang-and-comp/grep1, http://purl.org/lang-and-comp/grep2, or http://purl.org/lang-and-comp/grep3.
Open up Terminal (often found in Applications → Utilities). If movies.txt was saved in the directory, type cd Downloads. (If it was saved in another directory, substitute that directory name for Downloads to change to the right directory.)
To view the file, type: less movies.txt (to quit viewing just type q).
To use egrep, type: egrep “REGULAR-EXPRESSION” movies.txt
For example, if I wanted to find all titles containing the letters a or b, I would type: egrep “[ab]” movies.txt
Note that egrep returns the whole line containing the matching pattern. If you just want to see the exact part that matches, type in: egrep -o “[ab]” movies.txt
Write regular expressions to find the movie titles matching the following descriptions. For each one, try to write the shortest regular expression you can. Use egrep to verify that your regular expression finds the right movie titles.
Further reading
A good, though technical, introduction to the field of information retrieval is Manning, Raghavan, and Schütze (2008), which thoroughly covers modern techniques needed for retrieving information from massive amounts of data. If you want details on Google’s PageRank algorithm et al. you might even want to try reading the paper that describes it (Page et al., 1999).
For more information on Boolean expressions and logical thinking, you can consult a number of textbooks on basic symbolic logic. To obtain more of a focus on logic in the realm of linguistics, look for books on mathematical or formal linguistics, such as Partee, ter Meulen, and Wall (1990).
For corpus linguistics, there are also a number of good textbooks to consult, for example McEnery, Xiao, and Tono (2006), and several excellent websites, such as David Lee’s extensive Bookmarks for Corpus-based Linguistics (http://tiny.cc/corpora).
Web as corpus research is growing, and if you are interested in using web data, take a look at the Special Interest Group on the Web as Corpora (SIGWAC): www.sigwac.org.uk/. You might also want to read through papers that give an overview the methodology of using the web as a corpus (e.g., Baroni and Bernardini, 2004; Baroni and Kilgarriff, 2006; Sharoff, 2006). For a word of warning about using web counts, see Kilgarriff (2007).