CHAPTER 7
The Thousand Brains Theory of Intelligence
From its inception, Numenta’s goal was to develop a broad theory of how the neocortex works. Neuroscientists were publishing thousands of papers a year covering every detail of the brain, but there was a lack of systemic theories that tied the details together. We decided to first focus on understanding a single cortical column. We knew cortical columns were physically complex and therefore must do something complex. It didn’t make sense to ask why columns are connected to each other in the messy, somewhat hierarchical way I showed in Chapter 2 if we didn’t know what a single column did. That would be like asking how societies work before knowing anything about people.
Now we know a lot about what cortical columns do. We know that each column is a sensory-motor system. We know that each column can learn models of hundreds of objects, and that the models are based on reference frames. Once we understood that columns did these things, it became clear that the neocortex, as a whole, worked differently than was previously thought. We call this new perspective the Thousand Brains Theory of Intelligence. Before I explain what the Thousand Brains Theory is, it will be helpful to know what it is replacing.
The Existing View of the Neocortex
Today, the most common way of thinking about the neocortex is like a flowchart. Information from the senses is processed step-by-step as it passes from one region of the neocortex to the next. Scientists refer to this as a hierarchy of feature detectors. It is most often described in terms of vision, and goes like this: Each cell in the retina detects the presence of light in a small part of an image. The cells in the retina then project to the neocortex. The first region in the neocortex that receives this input is called region V1. Each neuron in region V1 gets input from only a small part of the retina. It is as if they were looking at the world through a straw.
These facts suggest that columns in region V1 cannot recognize complete objects. Therefore, V1’s role is limited to detecting small visual features such as lines or edges in a local part of an image. Then the V1 neurons pass these features on to other regions of the neocortex. The next visual region, called V2, combines the simple features from region V1 into more complex features, such as corners or arcs. This process is repeated a couple more times in a couple more regions until neurons respond to complete objects. It is presumed that a similar process—going from simple features to complex features to complete objects—is also occurring with touch and hearing. This view of the neocortex as a hierarchy of feature detectors has been the dominant theory for fifty years.
The biggest problem with this theory is that it treats vision as a static process, like taking a picture. But vision is not like that. About three times a second our eyes make quick saccadic movements. The inputs from the eyes to the brain completely change with every saccade. The visual inputs also change when we walk forward or turn our head left and right. The hierarchy of features theory ignores these changes. It treats vision as if the goal is to take one picture at a time and label it. But even casual observation will tell you that vision is an interactive process, dependent on movement. For example, to learn what a new object looks like, we hold it in our hand, rotating it this way and that, to see what it looks like from different angles. Only by moving can we learn a model of the object.
One reason many people have ignored the dynamic aspect of vision is that we can sometimes recognize an image without moving our eyes, such as a picture briefly flashed on a display—but that is an exception, not the rule. Normal vision is an active sensory-motor process, not a static process.
The essential role of movement is more obvious with touch and hearing. If someone places an object onto your open hand, you cannot identify it unless you move your fingers. Similarly, hearing is always dynamic. Not only are auditory objects, such as spoken words, defined by sounds changing over time, but as we listen we move our head to actively modify what we hear. It is not clear how the hierarchy of features theory even applies to touch or hearing. With vision, you can at least imagine that the brain is processing a picture-like image, but with touch and hearing there is nothing equivalent.
There are numerous additional observations that suggest the hierarchy of features theory needs modification. Here are several, all related to vision:
• The first and second visual regions, V1 and V2, are some of the largest in the human neocortex. They are substantially larger in area than other visual regions, where complete objects are supposedly recognized. Why would detecting small features, which are limited in number, require a larger fraction of the brain than recognizing complete objects, of which there are many? In some mammals, such as the mouse, this imbalance is worse. Region V1 in the mouse occupies a large portion of the entire mouse neocortex. Other visual regions in the mouse are tiny in comparison. It is as if almost all of mouse vision occurs in region V1.
• The feature-detecting neurons in V1 were discovered when researchers projected images in front of the eyes of anesthetized animals while simultaneously recording the activity of neurons in V1. They found neurons that became active to simple features, such as an edge, in a small part of the image. Because the neurons only responded to simple features in a small area, they assumed that complete objects must be recognized elsewhere. This led to the hierarchical features model. But in these experiments, most of the neurons in V1 did not respond to anything obvious—they might emit a spike now and then, or they might spike continuously for a while then stop. The majority of neurons couldn’t be explained with the hierarchy of features theory, so they were mostly ignored. However, all the unaccounted-for neurons in V1 must be doing something important that isn’t feature detection.
• When the eyes saccade from one fixation point to another, some of the neurons in regions V1 and V2 do something remarkable. They seem to know what they will be seeing before the eyes have stopped moving. These neurons become active as if they can see the new input, but the input hasn’t yet arrived. Scientists who discovered this were surprised. It implied that neurons in regions V1 and V2 had access to knowledge about the entire object being seen and not just a small part of it.
• There are more photoreceptors in the center of the retina than at the periphery. If we think of the eye as a camera, then it is one with a severe fish-eye lens. There are also parts of the retina that have no photoreceptors, for example, the blind spot where the optic nerve exits the eye and where blood vessels cross the retina. Consequentially, the input to the neocortex is not like a photograph. It is a highly distorted and incomplete quilt of image patches. Yet we are unaware of the distortions and missing pieces; our perception of the world is uniform and complete. The hierarchy of features theory can’t explain how this happens. This problem is called the binding problem or the sensor-fusion problem. More generally, the binding problem asks how inputs from different senses, which are scattered all over the neocortex with all sorts of distortions, are combined into the singular non-distorted perception we all experience.
• As I pointed out in Chapter 1, although some of the connections between regions of the neocortex appear hierarchical, like a step-by-step flowchart, the majority do not. For example, there are connections between low-level visual regions and low-level touch regions. These connections do not make sense in the hierarchy of features theory.
• Although the hierarchy of features theory might explain how the neocortex recognizes an image, it provides no insight into how we learn the three-dimensional structure of objects, how objects are composed of other objects, and how objects change and behave over time. It doesn’t explain how we can imagine what an object will look like if rotated or distorted.
With all these inconsistencies and shortcomings, you might be wondering why the hierarchy of features theory is still widely held. There are several reasons. First, it fits a lot of data, especially data collected a long time ago. Second, the problems with the theory accumulated slowly over time, making it easy to dismiss each new problem as small. Third, it is the best theory we have, and, without something to replace it, we stick with it. Finally, as I will argue shortly, it isn’t completely wrong—it just needs a major upgrade.
The New View of the Neocortex
Our proposal of reference frames in cortical columns suggests a different way of thinking about how the neocortex works. It says that all cortical columns, even in low-level sensory regions, are capable of learning and recognizing complete objects. A column that senses only a small part of an object can learn a model of the entire object by integrating its inputs over time, in the same way that you and I learn a new town by visiting one location after another. Therefore, a hierarchy of cortical regions is not strictly needed to learn models of objects. Our theory explains how a mouse, with a mostly one-level visual system, can see and recognize objects in the world.
The neocortex has many models of any particular object. The models are in different columns. They are not identical, but complementary. For example, a column getting tactile input from a fingertip could learn a model of a cell phone that includes its shape, the textures of its surfaces, and how its buttons move when pressed. A column getting visual input from the retina could learn a model of the phone that also includes its shape, but, unlike the fingertip column, its model can include the color of different parts of the phone and how visual icons on the screen change as you use it. A visual column cannot learn the detent of the power switch and a tactile column cannot learn how icons change on the display.
Any individual cortical column cannot learn a model of every object in the world. That would be impossible. For one, there is a physical limit to how many objects an individual column can learn. We don’t know yet what that capacity is, but our simulations suggest that a single column can learn hundreds of complex objects. This is much smaller than the number of things you know. Also, what a column learns is limited by its inputs. For example, a tactile column can’t learn models of clouds and a visual column can’t learn melodies.
Even within a single sensory modality, such as vision, columns get different types of input and will learn different types of models. For example, there are some vision columns that get color input and others that get black-and-white input. In another example, columns in regions V1 and V2 both get input from the retina. A column in region V1 gets input from a very small area of the retina, as if it is looking at the world through a narrow straw. A column in V2 gets input from a larger area of the retina, as if it is looking at the world through a wider straw, but the image is fuzzier. Now imagine you are looking at text in the smallest font that you can read. Our theory suggests that only columns in region V1 can recognize letters and words in the smallest font. The image seen by V2 is too fuzzy. As we increase the font size, then V2 and V1 can both recognize the text. If the font gets larger still, then it gets harder for V1 to recognize the text, but V2 is still able to do so. Therefore, columns in regions V1 and V2 might both learn models of objects, such as letters and words, but the models differ by scale.
Where Is Knowledge Stored in the Brain?
Knowledge in the brain is distributed. Nothing we know is stored in one place, such as one cell or one column. Nor is anything stored everywhere, like in a hologram. Knowledge of something is distributed in thousands of columns, but these are a small subset of all the columns.
Consider again our coffee cup. Where is knowledge about the coffee cup stored in the brain? There are many cortical columns in the visual regions that receive input from the retina. Each column that is seeing a part of the cup learns a model of the cup and tries to recognize it. Similarly, if you grasp the cup in your hands, then dozens to hundreds of models in the tactile regions of the neocortex become active. There isn’t a single model of coffee cups. What you know about coffee cups exists in thousands of models, in thousands of columns—but, still, only in a fraction of all the columns in the neocortex. This is why we call it the Thousand Brains Theory: knowledge of any particular item is distributed among thousands of complementary models.
Here is an analogy. Say we have a city with one hundred thousand citizens. The city has a set of pipes, pumps, tanks, and filters to deliver clean water to every household. The water system needs maintenance to stay in good working order. Where does the knowledge reside for how to maintain the water system? It would be unwise to have only one person know this, and it would be impractical for every citizen to know it. The solution is to distribute the knowledge among many people, but not too many. In this case, let’s say the water department has fifty employees. Continuing with this analogy, say there are one hundred parts of the water system—that is, one hundred pumps, valves, tanks, etc.—and each of the fifty workers in the water department knows how to maintain and repair a different, but overlapping, set of twenty parts.
OK then, where is knowledge of the water system stored? Each of the hundred parts is known by about ten different people. If half the workers called in sick one day, it is highly likely that there would still be five or so people available to repair any particular part. Each employee can maintain and fix 20 percent of the system on their own, with no supervision. Knowledge of how to maintain and repair the water system is distributed among a small number of the populace, and the knowledge is robust to a large loss of employees.
Notice that the water department might have some hierarchy of control, but it would be unwise to prevent any autonomy or to assign any piece of knowledge to just one or two people. Complex systems work best when knowledge and actions are distributed among many, but not too many, elements.
Everything in the brain works this way. For example, a neuron never depends on a single synapse. Instead, it might use thirty synapses to recognize a pattern. Even if ten of those synapses fail, the neuron will still recognize the pattern. A network of neurons is never dependent on a single cell. In the simulated networks we create, even the loss of 30 percent of the neurons usually has only a marginal effect on the performance of the network. Similarly, the neocortex is not dependent on a single cortical column. The brain continues to function even if a stroke or trauma wipes out thousands of columns.
Therefore, we should not be surprised that the brain does not rely on one model of anything. Our knowledge of something is distributed among thousands of cortical columns. The columns are not redundant, and they are not exact copies of each other. Most importantly, each column is a complete sensory-motor system, just as each water department worker is able to independently fix some portion of the water infrastructure.
The Solution to the Binding Problem
Why do we have a singular perception if we have thousands of models? When we hold and look at a coffee cup, why does the cup feel like one thing and not thousands of things? If we place the cup on a table and it makes a sound, how does the sound get united with the image and feel of the coffee cup? In other words, how do our sensory inputs get bound into a singular percept? Scientists have long assumed that the varied inputs to the neocortex must converge onto a single place in the brain where something like a coffee cup is perceived. This assumption is part of the hierarchy of features theory. However, the connections in the neocortex don’t look like this. Instead of converging onto one location, the connections go in every direction. This is one of the reasons why the binding problem is considered a mystery, but we have proposed an answer: columns vote. Your perception is the consensus the columns reach by voting.
Let’s go back to the paper map analogy. Recall that you have a set of maps for different towns. The maps are cut into little squares and mixed together. You are dropped off in an unknown location and see a coffee shop. If you find similar-looking coffee shops on multiple map squares, then you can’t know where you are. If coffee shops exist in four different towns, then you know you must be in one of four towns, but you can’t tell which one.
Now let’s pretend there are four more people just like you. They also have maps of the towns and they are dropped off in the same town as you but in different, random locations. Like you, they don’t know what town they are in or where they are. They take their blindfolds off and look around. One person sees a library and, after looking at his map squares, finds libraries in six different towns. Another person sees a rose garden and finds rose gardens in three different towns. The other two people do the same. Nobody knows what town they are in, but they all have a list of possible towns. Now everyone votes. All five of you have an app on your phone that lists the towns and locations you might be in. Everyone gets to see everyone else’s list. Only Town 9 is on everyone’s list; therefore, everyone now knows they are in Town 9. By comparing your lists of possible towns, and keeping only the towns on everybody’s list, you all instantly know where you are. We call this process voting.
In this example, the five people are like five fingertips touching different locations on an object. Individually they can’t determine what object they are touching, but together they can. If you touch something with only one finger, then you have to move it to recognize the object. But if you grasp the object with your entire hand, then you can usually recognize the object at once. In almost all cases, using five fingers will require less movement than using one. Similarly, if you look at an object through a straw, you have to move the straw to recognize the object. But if you view it with your entire eye, you can usually recognize it without moving.
Continuing with the analogy, imagine that, of the five people dropped off in the town, one person can only hear. That person’s map squares are marked with the sounds they should hear at each location. When they hear a fountain, or birds in trees, or music from a cantina, they find the map squares where those sounds might be heard. Similarly, let’s say two people can only touch things. Their maps are marked with the tactile sensations they expect to feel at different locations. Finally, two people can only see. Their map squares are marked with what they can expect to see at each location. We now have five people with three different types of sensors: vision, touch, and sound. All five people sense something, but they can’t determine where they are, so they vote. The voting mechanism works identically as I described before. They only need to agree on the town—none of the other details matter. Voting works across sensory modalities.
Notice that you need to know little about the other people. You don’t need to know what senses they have or how many maps they have. You don’t need to know if their maps have more or fewer squares than your maps, or if the squares represent larger or smaller areas. You don’t need to know how they move. Perhaps some people can hop over squares and others can only move diagonally. None of these details matter. The only requirement is that everyone can share their list of possible towns. Voting among cortical columns solves the binding problem. It allows the brain to unite numerous types of sensory input into a single representation of what is being sensed.
There is one more twist to voting. When you grasp an object in your hand, we believe the tactile columns representing your fingers share another piece of information—their relative position to each other, which makes it easier to figure out what they are touching. Imagine our five explorers are dropped into an unknown town. It is possible, indeed likely, that they see five things that exist in many towns, such as two coffee shops, a library, a park, and a fountain. Voting will eliminate any possible towns that don’t have all these features, but the explorers still won’t know for certain where they are, as several towns have all five features. However, if the five explorers know their relative position to each other, then they can eliminate any towns that don’t have the five features in that particular arrangement. We suspect that information about relative position is also shared among some cortical columns.
How Is Voting Accomplished in the Brain?
Recall that most of the connections in a cortical column go up and down between the layers, largely staying within the bounds of the column. There are a few well-known exceptions to this rule. Cells in some layers send axons long distances within the neocortex. They might send their axons from one side of the brain to the other, for example, between the areas representing the left and right hands. Or they might send their axons from V1, the primary visual region, to A1, the primary auditory region. We propose that these cells with long-distance connections are voting.
It only makes sense for certain cells to vote. Most of the cells in a column don’t represent the kind of information that columns could vote on. For example, the sensory input to one column differs from the sensory input to other columns, and therefore cells that receive these inputs do not project to other columns. But cells that represent what object is being sensed can vote and will project broadly.
The basic idea of how columns can vote is not complicated. Using its long-range connections, a column broadcasts what it thinks it is observing. Often a column will be uncertain, in which case its neurons will send multiple possibilities at the same time. Simultaneously, the column receives projections from other columns representing their guesses. The most common guesses suppress the least common ones until the entire network settles on one answer. Surprisingly, a column doesn’t need to send its vote to every other column. The voting mechanism works well even if the long-range axons connect to a small, randomly chosen subset of other columns. Voting also requires a learning phase. In our published papers, we described software simulations that show how learning occurs and how voting happens quickly and reliably.
Stability of Perception
Column voting solves another mystery of the brain: Why does our perception of the world seem stable when the inputs to the brain are changing? When our eyes saccade, the input to the neocortex changes with each eye movement, and therefore the active neurons must change too. Yet our visual perception is stable; the world does not appear to be jumping about as our eyes move. Most of the time, we are completely unaware that our eyes are moving at all. A similar stability of perception occurs with touch. Imagine a coffee cup is on your desk and you are grasping it with your hand. You perceive the cup. Now you mindlessly run your fingers over the cup. As you do this, the inputs to the neocortex change, but your perception is that the cup is stable. You do not think the cup is changing or moving.
So why is our perception stable, and why are we unaware of the changing inputs from our skin and eyes? Recognizing an object means the columns voted and now agree on what object they are sensing. The voting neurons in each column form a stable pattern that represents the object and where it is relative to you. The activity of the voting neurons does not change as you move your eyes and fingers, as long as they are sensing the same object. The other neurons in each column change with movement, but the voting neurons, the ones that represent the object, do not.
If you could look down on the neocortex, you would see a stable pattern of activity in one layer of cells. The stability would span large areas, covering thousands of columns. These are the voting neurons. The activity of the cells in other layers would be rapidly changing on a column-by-column basis. What we perceive is based on the stable voting neurons. The information from these neurons is spread broadly to other areas of the brain, where it can be turned into language or stored in short-term memory. We are not consciously aware of the changing activity within each column, as it stays within the column and is not accessible to other parts of the brain.
To stop seizures, doctors will sometimes cut the connections between the left and right sides of the neocortex. After surgery, these patients act as if they have two brains. Experiments clearly show that the two sides of the brain have different thoughts and reach different conclusions. Column voting can explain why. The connections between the left and right neocortex are used for voting. When they are cut, there is no longer a way for the two sides to vote, so they reach independent conclusions.
The number of voting neurons active at any time is small. If you were a scientist looking at the neurons responsible for voting, you might see 98 percent of the cells being silent and 2 percent continuously firing. The activity of the other cells in cortical columns would be changing with the changing input. It would be easy to focus your attention on the changing neurons and miss the significance of the voting neurons.

The brain wants to reach a consensus. You have probably seen the image above, which can appear as either a vase or two faces. In examples like this, the columns can’t determine which is the correct object. It is as if they have two maps for two different towns, but the maps, at least in some areas, are identical. “Vase town” and “Faces town” are similar. The voting layer wants to reach a consensus—it does not permit two objects to be active simultaneously—so it picks one possibility over the other. You can perceive faces or a vase, but not both at the same time.
Attention
It is common that our senses are partially blocked, such as when you look at someone standing behind a car door. Although we only see half a person, we are not fooled. We know that an entire person is standing behind the door. The columns that see the person vote, and they are certain this object is a person. The voting neurons project to the columns whose input is obscured, and now every column knows there is a person. Even the columns that are blocked can predict what they would see if the door wasn’t there.
A moment later, we can shift our attention to the car door. Just like the bistable image of the vase and faces, there are two interpretations of the input. We can shift our attention back and forth between “person” and “door.” With each shift, the voting neurons settle on a different object. We have the perception that both objects are there, even though we can only attend to one at a time.
The brain can attend to smaller or larger parts of a visual scene. For example, I can attend to the entire car door, or I can attend to just the handle. Exactly how the brain does this is not well understood, but it involves a part of the brain called the thalamus, which is tightly connected to all areas of the neocortex.
Attention plays an essential role in how the brain learns models. As you go about your day, your brain is rapidly and constantly attending to different things. For example, when you read, your attention goes from word to word. Or, looking at a building, your attention can go from building, to window, to door, to door latch, back to door, and so on. What we think is happening is that each time you attend to a different object, your brain determines the object’s location relative to the previously attended object. It is automatic. It is part of the attentional process. For example, I enter a dining room. I might first attend to one of the chairs and then to the table. My brain recognizes a chair and then it recognizes a table. However, my brain also calculates the relative position of the chair to the table. As I look around the dining room, my brain is not only recognizing all the objects in the room but simultaneously determining where each object is relative to the other objects and to the room itself. Just by glancing around, my brain builds a model of the room that includes all the objects that I attended to.
Often, the models you learn are temporary. Say you sit down for a family meal in the dining room. You look around the table and see the various dishes. I then ask you to close your eyes and tell me where the potatoes are. You almost certainly will be able to do this, which is proof that you learned a model of the table and its contents in the brief time you looked at it. A few minutes later, after the food has been passed around, I ask you to close your eyes and again point to the potatoes. You will now point to a new location, where you last saw the potatoes. The point of this example is that we are constantly learning models of everything we sense. If the arrangement of features in our models stays fixed, like the logo on the coffee cup, then the model might be remembered for a long time. If the arrangement changes, like the dishes on the table, then the models are temporary.
The neocortex never stops learning models. Every shift of attention—whether you are looking at the dishes on the dining table, walking down the street, or noticing a logo on a coffee cup—is adding another item to a model of something. It is the same learning process if the models are ephemeral or long-lasting.
Hierarchy in the Thousand Brains Theory
For decades, most neuroscientists have adhered to the hierarchy of features theory, and for good reasons. This theory, even though it has many problems, fits a lot of data. Our theory suggests a different way of thinking about the neocortex. The Thousand Brains Theory says that a hierarchy of neocortical regions is not strictly necessary. Even a single cortical region can recognize objects, as evidenced by the mouse’s visual system. So, which is it? Is the neocortex organized as a hierarchy or as thousands of models voting to reach a consensus?
The anatomy of the neocortex suggests that both types of connections exist. How can we make sense of this? Our theory suggests a different way of thinking about the connections that is compatible with both hierarchical and single-column models. We have proposed that complete objects, not features, are passed between hierarchical levels. Instead of the neocortex using hierarchy to assemble features into a recognized object, the neocortex uses hierarchy to assemble objects into more complex objects.
I discussed hierarchical composition earlier. Recall the example of a coffee cup with a logo printed on its side. We learn a new object like this by first attending to the cup, then to the logo. The logo is also composed of objects, such as a graphic and a word, but we don’t need to remember where the logo’s features are relative to the cup. We only need to learn the relative position of the logo’s reference frame to the cup’s reference frame. All the detailed features of the logo are implicitly included.
This is how the entire world is learned: as a complex hierarchy of objects located relative to other objects. Exactly how the neocortex does this is still unclear. For example, we suspect that some amount of hierarchical learning occurs within each column, but certainly not all of it. Some will be handled by the hierarchical connections between regions. How much is being learned within a single column and how much is being learned in the connections between regions is not understood. We are working on this problem. The answer will almost certainly require a better understanding of attention, which is why we are studying the thalamus.
Earlier in this chapter, I made list of problems with the commonly held view that the neocortex is a hierarchy of feature detectors. Let’s go through that list again, this time discussing how the Thousand Brains Theory addresses each problem, starting with the essential role of movement.
• The Thousand Brains Theory is inherently a sensory-motor theory. It explains how we learn and recognize objects by moving. Importantly, it also explains why we can sometimes recognize objects without moving, as when we see a brief image on a screen or grab an object with all our fingers. Thus, the Thousand Brains Theory is a superset of the hierarchical model.
• The relatively large size of regions V1 and V2 in primates and the singularly large size of region V1 in mice makes sense in the Thousand Brains Theory because every column can recognize complete objects. Contrary to what many neuroscientists believe today, the Thousand Brains Theory says that most of what we think of as vision occurs in regions V1 and V2. The primary and secondary touch-related regions are also relatively large.
• The Thousand Brains Theory can explain the mystery of how neurons know what their next input will be while the eyes are still in motion. In the theory, each column has models of complete objects and therefore knows what should be sensed at each location on an object. If a column knows the current location of its input and how the eyes are moving, then it can predict the new location and what it will sense there. It is the same as looking at a map of a town and predicting what you will see if you start to walk in a particular direction.
• The binding problem is based on the assumption that the neocortex has a single model for each object in the world. The Thousand Brains Theory flips this around and says that there are thousands of models of every object. The varied inputs to the brain aren’t bound or combined into a single model. It doesn’t matter that the columns have different types of inputs, or that one column represents a small part of the retina and the next represents a bigger part. It doesn’t matter if the retina has holes, any more than it matters that there are gaps between your fingers. The pattern projected to region V1 can be distorted and mixed up and it won’t matter, because no part of the neocortex tries to reassemble this scrambled representation. The voting mechanism of the Thousand Brains Theory explains why we have a singular, non-distorted perception. It also explains how recognizing an object in one sensory modality leads to predictions in other sensory modalities.
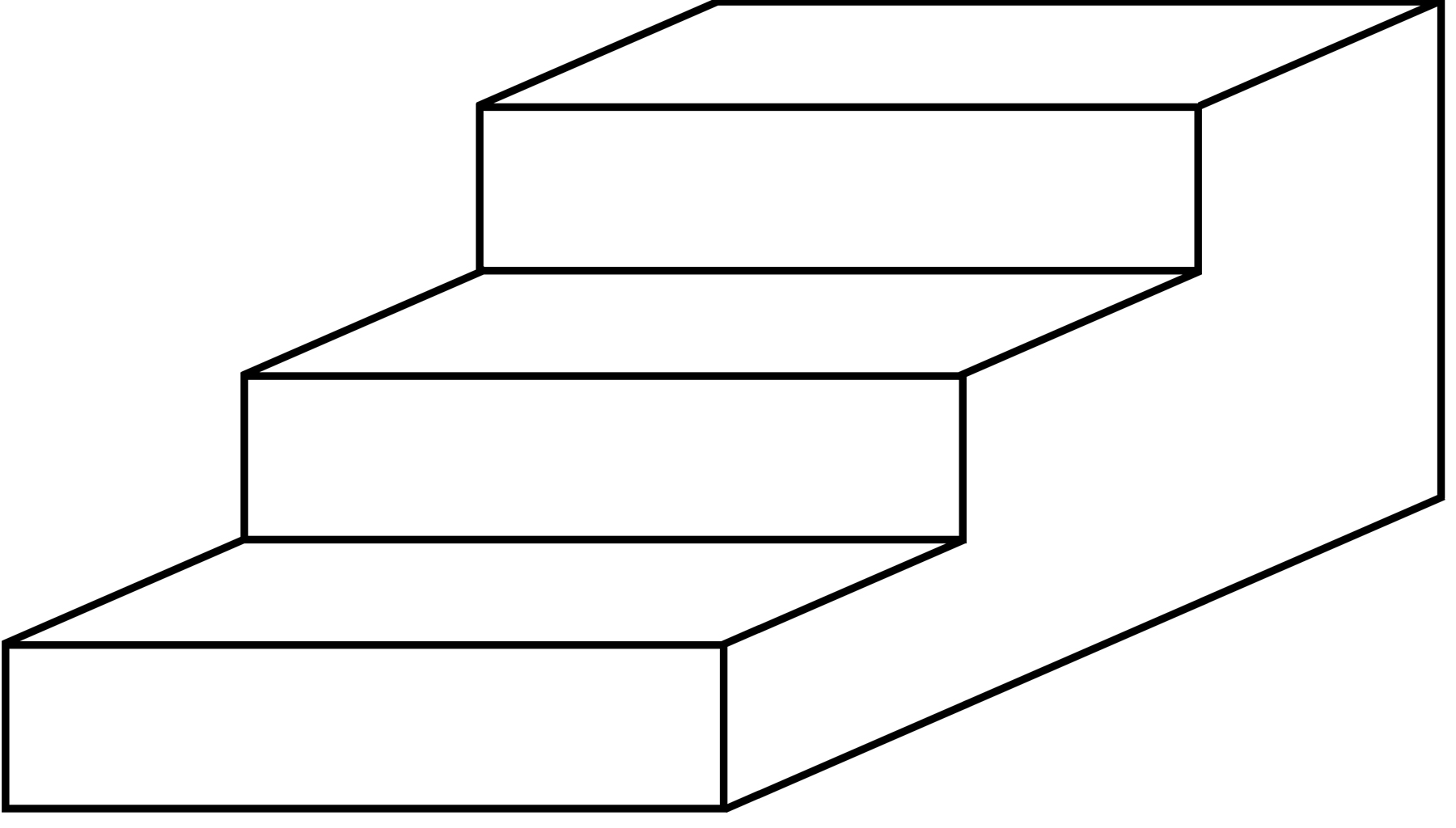
• Finally, the Thousand Brains Theory shows how the neocortex learns three-dimensional models of objects using reference frames. As one more small piece of evidence, look at the following image. It is a bunch of straight lines printed on a flat surface. There is no vanishing point, no converging lines, and no diminishing contrasts to suggest depth. Yet you cannot look at this image without seeing it as a three-dimensional set of stairs. It doesn’t matter that the image you are observing is two-dimensional; the models in your neocortex are three-dimensional, and that is what you perceive.
The brain is complex. The details of how place cells and grid cells create reference frames, learn models of environments, and plan behaviors are more complex than I have described, and only partially understood. We are proposing that the neocortex uses similar mechanisms, which are equally complex and even less understood. This is an area of active research for both experimental neuroscientists and theorists like ourselves.
To go further on these and other topics, I would have to introduce additional details of neuroanatomy and neurophysiology, details that are both difficult to describe and not essential for understanding the basics of the Thousand Brains Theory of Intelligence. Therefore, we have reached a border—a border where what this book explores ends, and where what scientific papers need to cover begins.
In the introduction to this book, I said that the brain is like a jigsaw puzzle. We have tens of thousands of facts about the brain, each like a puzzle piece. But without a theoretical framework, we had no idea what the solution to the puzzle looks like. Without a theoretical framework, the best we could do was attach a few pieces together here and there. The Thousand Brains Theory is a framework; it is like finishing the puzzle’s border and knowing what the overall picture looks like. As I write, we have filled in some parts of the interior of the puzzle, whereas many other parts are not done. Although a lot remains, our task is simpler now because knowing the proper framework makes it clearer what parts are yet to be filled in.
I don’t want to leave you with an incorrect impression that we understand everything the neocortex does. We are far from that. The number of things we don’t understand about the brain in general, and the neocortex in particular, is large. However, I don’t believe there will be another overall theoretical framework, a different way to arrange the border pieces of the puzzle. Theoretical frameworks get modified and refined over time, and I expect the same will be true for the Thousand Brains Theory, but the core ideas that I presented here will, I believe, mostly remain intact.

Before we leave this chapter and Part 1 of the book, I want to tell you the rest of the story about the time I met Vernon Mountcastle. Recall that I gave a speech at Johns Hopkins University, and at the end of the day I met with Mountcastle and the dean of his department. The time had come for me to leave; I had a flight to catch. We said our goodbyes, and a car was waiting for me outside. As I walked through the office door, Mountcastle intercepted me, put his hand on my shoulder, and said, in a here-is-some-advice-for-you tone of voice, “You should stop talking about hierarchy. It doesn’t really exist.”
I was stunned. Mountcastle was the world’s foremost expert on the neocortex, and he was telling me that one of its largest and most well-documented features didn’t exist. I was as surprised as if Francis Crick himself had said to me, “Oh, that DNA molecule, it doesn’t really encode your genes.” I didn’t know how to respond, so I said nothing. As I sat in the car on the way to the airport, I tried to make sense of his parting words.
Today, my understanding of hierarchy in the neocortex has changed dramatically—it is much less hierarchical than I once thought. Did Vernon Mountcastle know this back then? Did he have a theoretical basis for saying that hierarchy didn’t really exist? Was he thinking about experimental results that I didn’t know about? He died in 2015, and I will never be able to ask him. After his death, I took it upon myself to reread many of his books and papers. His thinking and writing are always insightful. His 1998 Perceptual Neuroscience: The Cerebral Cortex is a physically beautiful book and remains one of my favorites about the brain. When I think back on that day, I would have been wise to chance missing my flight for the opportunity to talk to him further. Even more, I wish I could talk to him now. I like to believe he would have enjoyed the theory I just described to you.
Now, I want to turn our attention to how the Thousand Brains Theory will impact our future.