2
Your AI Is a Human
Sarah T. Roberts
Intelligence: What It Is and How to Automate It
This chapter starts out with a polemic in a volume devoted to them (and we are therefore in good company):
Your artificial intelligence on your social media site of choice—what you may have imagined or even described as being “the algorithm,” if you have gotten that far in your thinking about the inner machinations of your preferred platform—is a human.
I say this to provoke debate and to speak metaphorically to a certain extent, but I also mean this literally: in the cases that I will describe herein, the tools and processes that you may believe to be computational, automated, and mechanized are, in actuality, the product of human intervention, action, and decision-making.
Before we go further, your belief that AI, automation, autonomous computation, and algorithms are everywhere is not because you are a naïf or a technological ingenue. It is because you have been led to believe that this is the case, tacitly and overtly, for many years. This is because to fully automate, mimic, outsource, and replace human intelligence at scale is, for many firms, a fundamental aspiration and a goal they have pursued, publicly and otherwise, but have yet to—and may never—achieve. And it is true that algorithmically informed automated processes are present in many aspects of the social media user experience, from serving you up the next video to be viewed, to curating (or restricting) the advertising directed at you, to offering you a constant stream of potential friends to . . . friend.
Just what constitutes AI is slippery and difficult to pin down; the definition tends to be a circular one that repeats or invokes, first and foremost, human intelligence—something that itself has eluded simple definition. In a 1969 paper by John McCarthy and Patrick Hayes considered foundational to the field of artificial intelligence, the authors describe the conundrum by saying:
work on artificial intelligence, especially general intelligence, will be improved by a clearer idea of what intelligence is. One way is to give a purely behavioural or black-box definition. In this case we have to say that a machine is intelligent if it solves certain classes of problems requiring intelligence in humans, or survives in an intellectually demanding environment. This definition seems vague; perhaps it can be made somewhat more precise without departing from behavioural terms, but we shall not try to do so.1
Forty years on, and computer scientists, engineers, and, in the quotation that follows, senior executives at esteemed tech publisher and Silicon Valley brain trust O’Reilly Media are still struggling to adequately define AI without backtracking into tautology and the thorny philosophical problem of what constitutes nonartificial, or human, intelligence in the first place: “Defining artificial intelligence isn’t just difficult; it’s impossible,” they say, “not the least because we don’t really understand human intelligence. Paradoxically, advances in AI will help more to define what human intelligence isn’t than what artificial intelligence is.”2
Perhaps, therefore, more easily apprehended than a definitive description of what constitutes AI are the reasons behind its seemingly universal appeal and constant invocation among tech and social media firms. This is particularly the case for those firms that desire to develop or use it to replace human intelligence, and human beings, with something that can serve as a reasonable stand-in for it in a routinized, mechanical, and ostensibly highly controllable and predictable way.
Some of these reasons are practical and pragmatic—business decisions, if you will. But there is also an underlying presupposition almost always at play that suggests, tacitly and otherwise, that the dehumanized and anonymous decision-making done by computers in a way that mimics—but replaces—that of human actors is somehow more just or fair.
Yet if we can all agree that humans are fallible, why is artificial intelligence based on human input, values, and judgments, then applied at scale and with little to no means of accountability, a better option? In many cases, we can find the justification for this preference for replacing human decision-making and, therefore, the human employees who perform such labor, by properly identifying it as an ideological predisposition fundamental to the very orientation to the world of the firms behind the major social media platforms.
The goal of this ideological orientation is a so-called “lean” workforce both to match the expectations of venture capital (VC) investors and shareholders to keep labor costs low and to align with the fundamental beliefs to which tech firms are adherents: that there is greater efficiency, capacity for scale, and cost savings associated with fewer human employees. And the means to this end is, conveniently, the firms’ stock in trade: technological innovation and automation using computational power and AI, itself a compelling reinforcement of their raison d’être. The myriad benefits of such workforce reduction, from a firm’s or investor’s perspective, are laid bare in this 2016 piece from Forbes magazine, mouthpiece for the investor class:
The benefits many employees enjoy today, like health insurance, unemployment insurance, pensions, guaranteed wage increases, paid overtime, vacation and parental leave have increased the cost of labor significantly. With new work models emerging, these benefits create an incentive for companies to minimize their headcount.
Thanks to technological advancements, it is much easier and efficient today to manage distributed teams, remote workers and contractors. What is the point in housing thousands of workers, often in some of the most expensive areas of our cities, when communication is mostly done through email, phone or Slack anyways?3
But the cost savings don’t stop simply at the reduction in need for office space and health insurance. A cynic such as myself might also note that having fewer direct employees might be seen as a means to control the likelihood of labor organizing or collective action, or at least greatly reduce its impact by virtue of smaller numbers of direct employees and less chance of them encountering each other at a shared work site.
Even when humanlike decision-making can be successfully programmed and turned over to machines, humans are still in the picture. This is because behind a decision, a process, or an action on your platform of choice lies the brainpower of unnamed humans who informed the algorithm, machine learning, or other AI process in the first place. Taking a larger step back, the problems that firms decide to tackle (and those they do not) in this way are also a site of the demonstration of very human values and priorities. In other words, what kinds of problems can, should, and will be turned over to and tackled by automated decision-making is a fundamentally value-laden human decision.
In this way, it becomes difficult to make claims for purely machine-driven processes at all. It may be that such computational purity of perfected AI at a scale not only cannot exist but ought not to be taken for granted as the panacea it is often touted as being. Why is this the case? Because reality calls for a much more complex sociotechnological assemblage of human and machine, procedure and process, decision-making and policy-making that goes well beyond the imagined closed system flow-chart logic solution of algorithms and computational decision-making and interventions operating at scale.4
The Case of Commercial Content Moderation and the Humans behind It
In 2018 Facebook found itself having a tough year. A sharp decline in stock value in late July, resulting in the largest one-day value loss—a jaw-dropping $119 billion—to date in the history of Wall Street, left analysts and industry watchers searching for answers as to what might be happening at the firm.5 While some contended that market saturation in North America and Europe were behind the poor second-quarter performance leading to the sell-off, there were likely deeper problems afoot that pushed investor lack of confidence, including major scandals related to election influence, fake political accounts and Astroturf campaigns, and a seeming inability for the platform to gain control of the user-generated content (UGC) disseminated via its properties, some of it with deadly consequences.6
It is worth noting that Facebook was not alone in seeing loss of value due to flagging consumer confidence; the much more volatile Twitter (having its own moment, of sorts, due to being the favorite bully pulpit of President Donald Trump) has also seen a bumpy ride in its share price as it has worked to purge fake and bot accounts many suspect of unduly influencing electoral politics, thereby vastly reducing its user numbers.7 More recently, YouTube has (finally?) received increased ire due to its recommendation algorithms, favoritism toward high-visibility accounts, and bizarre content involving children.8
Throughout the many episodes of criticism that major, mainstream social media tech firms have faced in recent years, there has been one interesting, if not always noticed, constant: a twofold response of firms—from Alphabet (Google) to Facebook—to their gaffes, scandals, and disasters has been to invoke new AI-based tools at the same time they commit to increasing the number of humans who serve as the primary gatekeepers to guard against bad user behavior in the form of UGC-based abuse. In some cases, these increases have been exponential, with particular firms committing to doubling the total number of human employees evaluating content in various forms on their platforms while at the same time assuring the public that soon computational tools using AI will be able to bridge any remaining gaps between what humans are capable of and what went undone.

Figure 2.1 YouTube to World: YouTube’s early slogan, “Broadcast Yourself!,” suggested an unencumbered, uninterrupted relationship of user to platform to world. The reality has proven to be more complex, in the form of automation, regulation, and humans.
Perhaps what is most interesting about these developments is that they serve as an acknowledgment of sorts on the part of the firms that, until this recent period, was often absent: the major social media platforms are incapable of governing their properties with computational, AI-based means alone. Facebook and its ilk operate on a user imagination of providing a forum for unfettered self-expression, an extension of participatory democracy that provides users a mechanism to move seamlessly from self to platform to world. As YouTube once famously exclaimed, “Broadcast yourself!” and the world has responded at unprecedented scale and scope (see fig. 2.1).
That scope and scale has been, until recently, the premise and the promise of the social media platforms that have connected us to friends, family, high school classmates, exes, work colleagues, former work colleagues, and people we met once, friended, and forgot about yet remain connected to, all of whose self-expression has been made available to us, seemingly without intervention.
Yet the case is not that simple for user-generated content (UGC), the primary currency of mainstream social media platforms and the material upon which they rely for our continued engagement—and perhaps it never was. As a researcher, I have been attempting to locate the contours and parameters of human intervention and gatekeeping of UGC since 2010, after reading a small but incredibly important article in the New York Times that unmasked a call center in rural Iowa specializing in the practice.9 Immediately upon reading the article, I—then seventeen years into being a daily social internet user, computing professional, and current grad student in those areas—asked myself a two-part question: “Why have I never thought of the ceaseless uploading of user content on a 24/7/365 basis from anyone in the world as a major problem for these platforms before?” followed quickly by, “Don’t computers deal with that?”
What I discovered, through subsequent research of the state of computing (including various aspects of AI, such as machine vision and algorithmic intervention), the state of the social media industry, and the state of its outsourced, globalized low-wage and low-status commercial content moderation (CCM) workforce10 was that, indeed, computers did not do that work of evaluation, adjudication, or gatekeeping of online UGC—at least hardly by themselves. In fact, it has been largely down to humans to undertake this critical role of brand protection and legal compliance on the part of social media firms, often as contractors or other kinds of third-party employees (think “lean workforce” here again).
While I have taken up the issue of what constitutes this commercial, industrialized practice of online content moderation as a central point of my research agenda over the past decade and in many contexts,11 what remained a possibly equally fascinating and powerful open question around commercial content moderation was why I had jumped to the conclusion in the first place that AI was behind any content evaluation that may have been going on.
And I wasn’t the only one who jumped to that conclusion. In my early days of investigation, I did a great deal of informal polling of classmates, colleagues, professors, and researchers about the need for such work and how, to their best guess, it might be undertaken.
In each case, without fail, the people that I asked—hardly technological neophytes—responded with the same one-two reaction I had: first, that they had never thought about it in any kind of significant way, and second, that, in any case, computers likely handled such work. I was not alone in my computational overconfidence, and the willingness and ease with which both my colleagues and I jumped to the conclusion that any intermediary activity going on between our own UGC uploads and their subsequent broadcasting to everyone else was fueled by AI engines was a fascinating insight in its own right. In other words, we wanted to believe.
To be fair, since I made those first inquiries (and certainly even more so in recent years), much has changed, and AI tools used in commercial content moderation have grown exponentially in their sophistication, hastened by concomitant exponential and continuous growth in computational performance, power, and storage (this latter observation a rough paraphrasing of Moore’s Law12). Furthermore, a variety of mechanisms that could be considered to be blushes of AI have long been in use alongside human moderation, likely predating that practice’s industrialization at scale. These include but are not limited to:
- • A variety of what I would describe as “first-order,” more rudimentary, blunt tools that are long-standing and widely adopted, such as keyword ban lists for content and user profiles, URL and content filtering, IP blocking, and other user-identifying mechanisms;13
- • More sophisticated automated tools such as hashing technologies used in products like PhotoDNA (used to automate the identification and removal of child sexual exploitation content; other engines based on this same technology do the same with regard to terroristic material, the definitions of which are the province of the system’s owners);14
- • Higher-order AI tools and strategies for content moderation and management at scale, examples of which might include:
-
- ◦ Sentiment analysis and forecasting tools based on natural language processing that can identify when a comment thread has gone bad or, even more impressive, when it is in danger of doing so;15
- ◦ AI speech-recognition technology that provides automatic, automated captioning of video content;16
- ◦ Pixel analysis (to identify, for example, when an image or a video likely contains nudity);17
- ◦ Machine learning and computer vision-based tools deployed toward a variety of other predictive outcomes (such as judging potential for virality or recognizing and predicting potentially inappropriate content).18
Computer vision was in its infancy when I began my research on commercial content moderation. When I queried a computer scientist who was a researcher in a major R&D site at a prominent university about the state of that art some years ago and how it might be applied to deal with user-generated social media content at scale, he gestured at a static piece of furniture sitting inside a dark visualization chamber and remarked, “Right now, we’re working on making the computer know that that table is a table.”
To be sure, the research in this area has advanced eons beyond where it was in 2010 (when the conversation took place), but the fundamental problem of how to make a computer “know” anything (or whether this is possible at all) remains. What has improved is the ability of computers, through algorithms and AI, to make good guesses through pattern recognition and learning from a database of material. Yet when you catch a computer scientist or a member of industry in an unguarded moment, you may learn that:
- • All the tools and techniques described above are subject to failure due to either being overbroad, blunt, or unable to reliably identify nuanced or ambiguous material;
- • They are also subject to and largely a representation of the quality and reliability of the source material used to train the algorithms and AI, and the inputs that have informed the tools (that is, the work of humans on training sets). The old computer science adage of “garbage in, garbage out,” or GIGO, applies here—and we are once again back to pulling back a curtain to find, at key points of origin, decidedly human perspectives in every aspect of the creation of these tools, whether speccing their functionality or actually training them, via data sets, to replicate decisions that individuals have made and that are then aggregated;19
- • The likelihood of these tools and processes ever being so sophisticated as to fully take over without any human input or oversight is close to zero. I have never heard anyone claim otherwise, and I stand by this claim, based on almost a decade of asking about the possibility and evaluating the state of a variety of AI applications for CCM work—from industry members as well as academic computer scientists and engineers.
There are a number of factors that play into the last statement, but two of the most overarching and most intractable, in terms of all automation all the time, are scale, on the one hand, and liability, on the other. These two factors are intertwined and interrelated, and worthy of their own discussion alongside a third factor: regulation. All of them go to the true heart of the matter, which is to question what social media platforms are, what they do, and who gets to decide. These are matters that I take up in the next section.
Social Media’s Identity Crisis
Now able to count a vast portion of the global populace among the ranks of their user base (a scale unprecedented for most other media, past or present), the mainstream social media firms emanating from Silicon Valley face an identity crisis that is not entirely self-driven. Rather, questions from outside the firms have provoked a reevaluation of how they are regarded. This reevaluation is far from trivial and has social, technological, and legal impacts on what the firms are able to do, what claims they are able to make, and to whom they are beholden.
To a large extent, they have been able to self-define, over and over again in the past decade and a half (see Nathan Ensmenger’s extensive treatment, in this volume, of Amazon’s positioning of itself as an excellent case in point). Typically, when allowed to do so (or when queried), they invariably self-describe as “tech firms” first and foremost. Perhaps this is where free speech is best implemented by the platforms, in their own self-identification practices. What they are sure to claim, in almost every case, is that they are not media companies. In fact, on the very rare occasions in which Facebook founder and CEO Mark Zuckerberg has said that Facebook might bear some similarity to a media company,20 the utterance has been so unusual as to be newsworthy. At other points, Zuckerberg has referred to Facebook as “the service,” harkening back to the era of internet service providers, or ISPs, which mostly predate Facebook itself.
Being “not a media company” goes beyond social media firms’ wish to distance themselves from dinosaur old-media antecedents (see fig. 2.2). Indeed, there are a number of significant and very pragmatic reasons that Silicon Valley–based social media firms do not want to be seen as media companies, at least not in the traditional broadcast media sense. There are two key regulatory and legal reasons for this. The first is the ability of these self-identified not-media companies to avoid regulation and limits on, and responsibility for, content placed on broadcast television or radio companies by the US Federal Communications Commission.21 The late comedian George Carlin made an entire career of lampooning, and loudly using in his standup act, the words banned from the television airwaves by the FCC.
Social media platforms are greater than the sum of their technological parts. They are more than just their tool set, more than just their content, and more than just their engineering infrastructure and code. They are a dynamic assemblage of functionality, relationship creation and maintenance, policies, and governance that are always in flux and seldom visible in their totality to the user. They aggregate data, track behavior, determine, and even influence tastes and habits, capture attention, and package all of these things as commodities for advertisers. Zuckerberg may be right that this is not a “traditional” media company in the vein of television or film studios, for example, in that they rely largely on the production of material from average people—but even that isn’t the whole story. That is where the second key reason for steadfast avoidance of the “media” label comes in.
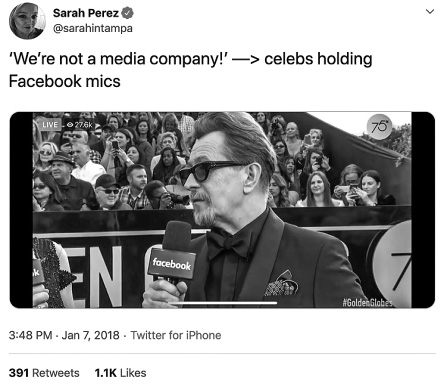
Figure 2.2 “Not a media company”: An identity crisis is more than just what’s in a name or how platforms self-define in the market, as this Twitter user lampoons (https://t.co/KkpMWKMgKl).
Unlike television and radio broadcasters in the United States, who can be held liable and fined for the material they allow to pass over their channels, social media firms have been traditionally afforded a very specific legal status that both largely grants them immunity in terms of responsibility for the content they host and disseminate and also affords them the discretion to intervene upon that content as they see fit.22 This particular legal status of “internet intermediary” dates to the Communications Decency Act of 1996 and to its Section 230, in particular.23 Specifically, this portion of the CDA has set the tone for how internet intermediaries such as ISPs, search engines, and now social media platforms have been defined in the law for liability purposes. The Electronic Frontier Foundation, a major supporter of Section 230, describes its history as such:
Worried about the future of free speech online and responding directly to Stratton Oakmont, Representatives Chris Cox (R-CA) and Ron Wyden (D-OR) introduced an amendment to the Communications Decency Act that would end up becoming Section 230. The amendment specifically made sure that “providers of an interactive computer service” would not be treated as publishers of third-party content. Unlike publications like newspapers that are accountable for the content they print, online services would be relieved of this liability. Section 230 had two purposes: the first was to “encourage the unfettered and unregulated development of free speech on the Internet,” as one judge put it; the other was to allow online services to implement their own standards for policing content and provide for child safety.24
Yet not all agree that Section 230 has been a harmless tool for self-expression. As legal scholar Mary Graw Leary describes, just who receives the greatest benefit from Section 230 may depend on whom you ask or who you are. She contextualizes Section 230 as having primarily benefited the tech companies themselves, explaining, “In Reno v. ACLU the Supreme Court struck down as vague some of the more controversial criminal provisions of the CDA, such as the prohibition on the transmission of ‘indecent material.’ However, §230 was not challenged, and this protection remains effective law to this day.”25
Indeed, this outcome has largely been seen as an unqualified win for contemporary tech companies and, assuredly, those to come in the future—in fact, Section 230 may well have been key to their founding and growth. Says Leary, “Tech companies arguably achieved the best of both worlds. After Reno, much of the CDA that tech companies opposed was eliminated, but the provision that was designed to protect them remained. Thus, when the dust settled, tech companies enjoyed increased protections without the regulations.”26 The resulting power over speech resting with the platforms and their parent firms led law professor Kate Klonick to describe them as nothing short of “the new governors.”27
Despite being legally immune for what they transmit over their platforms, most prominent mainstream firms have expressed, at various times, a moral obligation in many cases to protect people from harmful content, even beyond what US law may have mandated. But there is another compulsion that drives the need for gatekeeping that is less tangible and also difficult to separate, and it is related to brand protection practices, curation, and the platform’s desire to create and maintain its user base—by providing that group with whatever content it is that keeps them engaged and coming back. The firms therefore rely on a never-ending, massive influx of UGC to keep existing users engaged and to draw new ones to the platforms, with the details of what needs to be removed sitting in second place after the race to always have new content to supply. The adjudication and removal falls in part to users, who report troubling material when they encounter it,28 and certainly to CCM workers, with or without their AI tools to assist.
That social media platforms function legally more like libraries than newspapers, as an oft-repeated legal analogy goes, has assuredly given rise to the user base’s comfort to upload and transmit its personal content, and has in turn created and supported notions of “free speech” that are synonymous with these acts. In this regard, Section 230 has done an excellent job of ensuring that one particular kind of speech, in the form of social media UGC on American-based platforms, flourishes. This is not incidental to the firms themselves, who have taken up that UGC as their stock in trade, monetized, and extracted value from it in many different ways. Without a user sensibility that an uploaded bit of UGC constitutes something other than one’s own free self-expression first and foremost, it is unlikely that this model would have proliferated to the lucrative extent that it has.
The global business model of many of these major firms is now causing friction: as many social media giants are discovering, “free speech” in the form of users’ social media sharing serves as a compelling enticement to current and potential users but is largely a principle that cannot be successfully operationalized on a global scale, considering that Section 230 and the CDA in its entirety is technically only pertinent to US jurisdiction (a fact divorced from the global reality of the internet’s materiality, user base, and politics, as vividly described by Kavita Philip later in this book). Perhaps even more problematic, however, is that “free speech” is not a universally held principle, nor is it interpreted in the same way around the world.
Where nation-state gatekeepers demand compliance with restrictive speech laws to enter a marketplace, many firms quickly and coldly capitulate; one 2018 report describes where Facebook censors the most “illegal content,” and Turkey heads the list—because Turkey has some of the most expansive, draconian laws on what constitutes “illegal content” in the first place.29 Whereas Section 230 had long been the principle under which Silicon Valley–based social media firms approached their content obligations to the world, this privilege is no longer afforded to them in a variety of contexts. For social media firms wishing to enter a given marketplace, demonstrating a willingness and ability to respond to local norms, mores, and legal obligations when deciding what is allowed to stand and what is removed has become important, and not doing so can come at a significant financial cost. More and more, state actors are asserting their expectation that their local jurisdictional authority be recognized, and they are willing to impose fines, restrict business, and even block an entire platform or service as they see fit.
Whether the purpose is to restrict the speech of political dissidents in Turkey or to stop the flow of Nazi glorification in Germany,30 these local laws are straining the firms’ capacity to continue the status quo: to operate as they wish, aligned with their ideologies and with those enshrined in Section 230. Otherwise deeply regulation-avoidant, social media firms have developed intensely complex frameworks of internal policies (Klonick’s “new governance”31) and the processes, technological mechanisms, and labor pools to enact them—an assemblage that, critically, has operationalized ideologies, large and small. These ideologies are identifiable on a Silicon Valley–wide scale but also reflect the particular flavor of a given platform and its permissiveness, restrictiveness, and branding relative to its peers.
The resulting enmeshments of policy, tech, and operations have largely grown up over time and internally to the firms, which have simultaneously worked to render outward-facing traces of such human values and interventions invisible on its social media platforms and sites. I have described this phenomenon elsewhere as a “logic of opacity”:
Obfuscation and secrecy work together to form an operating logic of opacity around social media moderation. It is a logic that has left users typically giving little thought to the mechanisms that may or may not be in place to govern what appears, and what is removed, on a social media site. The lack of clarity around policies, procedures and the values that inform them can lead users to have wildly different interpretations of the user experience on the same site.32
The invocation of AI as a means to resolve legal and regulatory demands is therefore an additional mechanism that firms use to promise compliance with these new standards while creating another layer of obfuscation, confusion, and technological complication that leaves users filling in the blanks, if they know they’re there at all.33 Communication scholar Sarah Myers West demonstrated this in her recent study on internet takedowns and how users who experience them tend to develop “folk theories” surrounding both the reasons for and the mechanisms of their content’s deletion.34
If AI tools, which I hope by now to have convinced you are best thought of as some form of human-computer hybrid, continue to be invoked as the primary solution to social media’s increasing content problems, then we will see much more reference to and reliance upon them going forward. Yet the black box nature surrounding the creation of tools themselves35—how they are built and what they do, and where human engagement with them begins and ends—will assuredly foster the kinds of folk theories unveiled by Myers West that will deliver us this artificial artificial intelligence while simultaneously denying any human behind the curtain, pulling levers and appealing to our collective assumptions that tech firms tech, never fake it, and that we are all the better for it.36 Ironically, it may be that the proliferation of such computational interventions will be the very thing that leads to generalized, unquestioning acceptance of their encroachment into our collective experience of digital technology, a normalization process bolstering and bolstered by a fantasy sold to us by an industry that fundamentally benefits from it (see fig. 2.3).
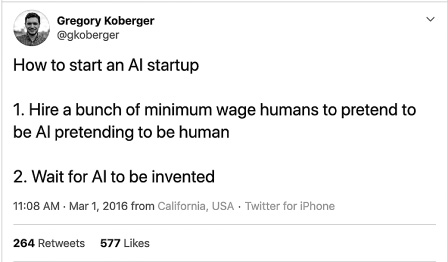
Figure 2.3 Fake AI tweet: As reported in the Guardian (Olivia Solon, “The Rise of ‘Pseudo-AI’”), a Twitter user’s clever take on how to start an AI-reliant firm.
Humans and AI in Symbiosis and Conflict
First, what we can know: AI is presently and will always be both made up of and reliant upon human intelligence and intervention. This is the case whether at the outset, at the identification of a problem to be solved computationally; a bit later on, with the creation of a tool based in algorithmic or machine-learning techniques; when that tool is informed by, improved upon, or recalibrated over time based on more or different human inputs and intervention;37 or whether it is simply used alongside other extant human processes to aid, ease, speed, or influence human decision-making and action-taking, in symbiosis or perhaps, when at odds with a human decision, in conflict.
This sometimes-symbiosis-sometimes-conflict matters when it comes to social media. In addition to regulatory and legal concerns that vary greatly around the globe and are delineated by jurisdiction (as well as by less tangible but deeply important cultural and political norms), the speech that flows across social media platforms in the form of images, text postings, videos, and livestreams is subject to a vast patchwork of internal rules and other opaque policies decided by mid- and high-level employees but often implemented by a global workforce of precarious low-paid laborers. When algorithms and deep machine-learning-based tools may be present at some points in the system, even they are informed by the platform policies and the workers’ decisions, captured and then redeployed as AI. In short, human beings and their traces are present across the social media production chain. Where humans stop and machines start is not always clear, and it is not always even possible to know. But that the human agents have been largely disavowed and rendered invisible by the platforms for which they labor has been no accident as firms continue to appeal to the public’s assumptions and to avoid, or respond to, regulation by invoking AI.
A major challenge over the next five years or so will therefore be to recognize, acknowledge, and map the contours of these relationships, with particular attention to the dangers of overemphasizing their abilities or benefits, minimizing their shortcomings, or disavowing the value-ladenness of the tools themselves and their computational outcomes. Langdon Winner, in his field-defining 1980 essay, “Do Artifacts Have Politics?,” demonstrated that technological innovation is hardly always synonymous with progress and is frequently not in everyone’s best interest, distributing its benefits and harms unevenly and unequally.38 These observations have been taken up in the internet era by numerous scholars (many of whom are present in this very volume) and by a more recent assertion that platforms, too, have politics.39
What, then, are the values of an algorithm? What are the politics of AI mechanisms? How can we know? To put it plainly: AI reflects, and endeavors to replicate or improve upon, human problem-solving in human contexts. When these goals and hoped-for outcomes are made plain, what becomes clear is that all human problems and all human contexts do not lend themselves equally successfully to computational interventions, and to apply such tools to some of these processes would not only be inappropriate, the outcomes could even be dangerous—often more so to those already impacted by structural or historical discrimination.40
Even if one were to stipulate that such problem-solving could be rendered value-free, surely the reentry of the results of such processes into their social, cultural, and political contexts make such claims difficult to take seriously. Yet this cautionary approach to AI and its potential for biases is rarely met with concern from those who celebrate it as a solution to a panoply of human ills—or build toward those ostensible goals. Beyond the case of social media UGC and commercial content moderation, examples of this would be the call to quickly resolve a multitude of social problems with technical solutions in which AI is often invoked in the context of the latter.
Predictive policing, and the tools being built around it, are being programmed using data and assuming a relationship to police that is the same for all people, under the best of circumstances; what happens when inaccurate, outdated, or racially biased information is fed into the predictive engine?41 Tools designed to remove “terroristic content” using hashing algorithms do a great job of seeking and matching for known bad material, but who decides what constitutes terrorism and how can we know?42 And what person or persons should be held responsible for the algorithmically determined Google search engine results that lead users to racist and false information, such as that which influenced Dylann Roof, the killer of nine African-American parishioners in a Charleston church in 2015?43
Rather than reflecting what is either technologically possible or socially ideal at present or in the near- to midterm, this solutionist disposition toward AI everywhere is aspirational at its core. The abstractions that algorithms and other AI tools represent suggest a means to quickly and easily solve for a solution and bypass the more difficult and troubling possibility of having to cast a larger net or to acknowledge the even more frightening reality that perhaps not every human dilemma or social problem can be solved in this way.
What is the goal of the AI turn in . . . everything? Certainly, in the case of social media platforms, the legal implications of being unable to invoke one or even a group of humans as being responsible for decisions rendered is one powerful benefit, if not the point in and of itself. How does one hold AI tools to account? The hope may be that no one can, and that is a position considerably balanced in favor of the firms who create and control them.
Movements to demand fairness, accountability, and transparency in algorithmic endeavors are gaining ground, not only in important works from social scientists who have traditionally critiqued social media platforms and digital life and its unequal distribution of power44 but also from others in disciplines such as computer science and engineering—the province of the makers of the tools themselves. Entire conferences,45 academic working groups,46 and cross-disciplinary and cross-sector institutes joining academe and industry47 have been constituted to tackle these issues and demand that they be addressed. The AI Now Institute’s 2017 report issued a clarion call to this effect, saying:
AI systems are now being adopted across multiple sectors, and the social effects are already being felt: so far, the benefits and risks are unevenly distributed. Too often, those effects simply happen, without public understanding or deliberation, led by technology companies and governments that are yet to understand the broader implications of their technologies once they are released into complex social systems. We urgently need rigorous research that incorporates diverse disciplines and perspectives to help us measure and understand the short and long-term effects of AI across our core social and economic institutions.48
The ability of regulators, advocates, and the public to meaningfully engage with AI tools, processes, and mechanisms will be predicated on the ability to see them, however, and to know when they are, and are not, invoked. To give these actors the ability to see through the AI illusion will be the first, and possibly most difficult, task of all.
Notes
1. John McCarthy and Patrick J. Hayes, “Some Philosophical Problems from the Standpoint of Artificial Intelligence,” in Machine Intelligence 4, ed. B. Meltzer and D. Michie (Edinburgh: Edinburgh University Press, 1969), 463–502, https://doi.org/10.1016/B978-0-934613-03-3.50033-7.
2. Mike Lorica and Ben Loukides, “What Is Artificial Intelligence?,” OReilly.com (June 29, 2016), https://www.oreilly.com/ideas/what-is-artificial-intelligence.
3. Martin Strutz, “Freelancers and Technology Are Leading the Workforce Revolution,” Forbes (November 10, 2016), https://www.forbes.com/sites/berlinschoolofcreativeleadership/2016/11/10/free-lancers-and-technology-are-leading-the-workforce-revolution/.
4. Arnold Pacey, The Culture of Technology (Cambridge, MA: MIT Press, 1985).
5. Aimee Picchi, “Facebook Stock Suffers Largest One-Day Drop in History, Shedding $119 Billion,” CBS Moneywatch (July 26, 2108), https://www.cbsnews.com/news/facebook-stock-price-plummets-largest-stock-market-drop-in-history/.
6. Elizabeth Dwoskin and Annie Gowen, “On WhatsApp, Fake News Is Fast—and Can Be Fatal,” Washington Post (July 23, 2018), https://www.washingtonpost.com/business/economy/on-whatsapp-fake-news-is-fast--and-can-be-fatal/2018/07/23/a2dd7112-8ebf-11e8-bcd5-9d911c784c38_story.html; Lauren Frayer, “Viral WhatsApp Messages Are Triggering Mob Killings in India,” NPR (July 18, 2018), https://www.npr.org/2018/07/18/629731693/fake-news-turns-deadly-in-india.
7. Reuters staff, “Twitter Shares Fall after Report Says Account Suspensions to Cause . . . ,” Reuters (July 9, 2018), https://www.reuters.com/article/us-twitter-stocks/twitter-shares-fall-after-report-says-account-suspensions-to-cause-user-decline-idUSKBN1JZ20V.
8. Zeynep Tufekci, “YouTube Has a Video for That,” Scientific American (April 2019), https://doi.org/10.1038/scientificamerican0419-77; Charlie Warzel and Remy Smidt, “YouTubers Made Hundreds of Thousands Off of Bizarre And Disturbing Child Content,” BuzzFeed News (December 11, 2017), https://www.buzzfeednews.com/article/charliewarzel/youtubers-made-hundreds-of-thousands-off-of-bizarre-and.
9. Brad Stone, “Concern for Those Who Screen the Web for Barbarity,” New York Times (July 18, 2010), http://www.nytimes.com/2010/07/19/technology/19screen.html?_r=1.
10. See Sreela Sarkar’s chapter in this volume, “Skills Will Not Set You Free,” describing a New Delhi–based computer “skills” class aimed at low-income Muslim women that may be preparing them more for the deskilling jobs outsourced from the Global North’s IT sector, if that at all.
11. Sarah T. Roberts, Behind the Screen: Content Moderation in the Shadows of Social Media (New Haven: Yale University Press, 2019).
12. Chris A. Mack, “Fifty Years of Moore’s Law,” IEEE Transactions on Semiconductor Manufacturing 24, no. 2 (May 2011): 202–207, https://doi.org/10.1109/TSM.2010.2096437; Ethan Mollick, “Establishing Moore’s Law,” IEEE Annals of the History of Computing 28, no. 3 (July 2006): 62–75, https://doi.org/10.1109/MAHC.2006.45.
13. Ronald Deibert, Access Denied: The Practice and Policy of Global Internet Filtering (Cambridge, MA: MIT Press, 2008); Steve Silberman, “We’re Teen, We’re Queer, and We’ve Got E-Mail,” Wired (November 1, 1994), https://www.wired.com/1994/11/gay-teen/; Nart Villeneuve, “The Filtering Matrix: Integrated Mechanisms of Information Control and the Demarcation of Borders in Cyberspace,” First Monday 11, no. 1 (January 2, 2006), https://doi.org/10.5210/fm.v11i1.1307.
14. Hany Farid, “Reining in Online Abuses,” Technology & Innovation 19, no. 3 (February 9, 2018): 593–599, https://doi.org/10.21300/19.3.2018.593.
15. Ping Liu et al., “Forecasting the Presence and Intensity of Hostility on Instagram Using Linguistic and Social Features,” in Twelfth International AAAI Conference on Web and Social Media (2018), https://www.aaai.org/ocs/index.php/ICWSM/ICWSM18/paper/view/17875.
16. Hank Liao, Erik McDermott, and Andrew Senior, “Large Scale Deep Neural Network Acoustic Modeling with Semi-Supervised Training Data for YouTube Video Transcription,” in 2013 IEEE Workshop on Automatic Speech Recognition and Understanding (2013), 368–373, https://doi.org/10.1109/ASRU.2013.6707758.
17. A. A. Zaidan et al., “On the Multi-Agent Learning Neural and Bayesian Methods in Skin Detector and Pornography Classifier: An Automated Anti-Pornography System,” Neurocomputing 131 (May 5, 2014): 397–418, https://doi.org/10.1016/j.neucom.2013.10.003; Vasile Buzuloiu et al., Automated detection of pornographic images, United States US7103215B2, filed May 7, 2004, and issued September 5, 2006, https://patents.google.com/patent/US7103215B2/en.
18. Sitaram Asur and Bernardo A. Huberman, “Predicting the Future with Social Media,” in Proceedings of the 2010 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology—Volume 01, WI-IAT ’10 (Washington, DC: IEEE Computer Society, 2010), 492–499, https://doi.org/10.1109/WI-IAT.2010.63; Lilian Weng, Filippo Menczer, and Yong-Yeol Ahn, “Predicting Successful Memes Using Network and Community Structure,” in Eighth International AAAI Conference on Weblogs and Social Media (2014), https://www.aaai.org/ocs/index.php/ICWSM/ICWSM14/paper/view/8081.
19. Reuben Binns et al., “Like Trainer, Like Bot? Inheritance of Bias in Algorithmic Content Moderation,” ArXiv:1707.01477 [Cs] 10540 (2017): 405–415, https://doi.org/10.1007/978-3-319-67256-4_32.
20. John Constine, “Zuckerberg Implies Facebook Is a Media Company, Just ‘Not a Traditional Media Company,’” TechCrunch (December 21, 2016), http://social.techcrunch.com/2016/12/21/fbonc/
21. Federal Communications Commission, “The Public and Broadcasting (July 2008 Edition)” (December 7, 2015), https://www.fcc.gov/media/radio/public-and-broadcasting.
22. This immunity is typically known as freedom from “intermediary liability” in legal terms, but it is not all-encompassing, particularly in the context of child sexual exploitation material. See Mitali Thakor’s chapter in this volume, “Capture Is Pleasure,” for a more in-depth discussion of the parameters and significance of laws governing such material on social media platforms and firms’ responsibility to contend with it.
23. Jeff Kosseff, The Twenty-Six Words That Created the Internet (Ithaca, NY: Cornell University Press, 2019). For an extended treatment of the origin and impact of Section 230, see Kosseff’s monograph on the subject, which he calls a “biography” of the statute.
24. Electronic Frontier Foundation, “CDA 230: Legislative History” (September 18, 2012), https://www.eff.org/issues/cda230/legislative-history.
25. Mary Graw Leary, “The Indecency and Injustice of Section 230 of the Communications Decency Act,” Harvard Journal of Law & Public Policy 41, no. 2 (2018): 559.
26. Leary, “The Indecency and Injustice of Section 230 of the Communications Decency Act,” 559.
27. Kate Klonick, “The New Governors: The People, Rules, and Processes Governing Online Speech,” Harvard Law Review 131 (2018): 1598–1670.
28. Kate Crawford and Tarleton Gillespie, “What Is a Flag For? Social Media Reporting Tools and the Vocabulary of Complaint,” New Media & Society 18, no. 3 (2016): 410–428.
29. Hanna Kozlowska, “These Are the Countries Where Facebook Censors the Most Illegal Content,” Quartz (May 16, 2018), https://qz.com/1279549/facebook-censors-the-most-illegal-content-in-turkey/
30. “Reckless Social Media Law Threatens Freedom of Expression in Germany,” EDRi (April 5, 2017), https://edri.org/reckless-social-media-law-threatens-freedom-expression-germany/.
31. Klonick, “The New Governors.”
32. Sarah T. Roberts, “Digital Detritus: ‘Error’ and the Logic of Opacity in Social Media Content Moderation,” First Monday 23, no. 3 (March 1, 2018), http://firstmonday.org/ojs/index.php/fm/article/view/8283.
33. Jenna Burrell, “How the Machine ‘Thinks’: Understanding Opacity in Machine Learning Algorithms,” Big Data & Society 3, no. 1 (June 1, 2016), https://doi.org/10.1177/2053951715622512.
34. Sarah Myers West, “Censored, Suspended, Shadowbanned: User Interpretations of Content Moderation on Social Media Platforms,” New Media & Society 20, no. 11 (2018), 4366–4383, https://doi.org/10.1177/1461444818773059.
35. Frank Pasquale, The Black Box Society: The Secret Algorithms That Control Money and Information (Cambridge, MA: Harvard University Press, 2015).
36. Olivia Solon, “The Rise of ‘Pseudo-AI’: How Tech Firms Quietly Use Humans to Do Bots’ Work,” Guardian (July 6, 2018, sec. Technology), http://www.theguardian.com/technology/2018/jul/06/artificial-intelligence-ai-humans-bots-tech-companies; Maya Kosoff, “Uh, Did Google Fake Its Big A.I. Demo?,” Vanity Fair: The Hive (May 17, 2018), https://www.vanityfair.com/news/2018/05/uh-did-google-fake-its-big-ai-demo.
37. Cade Metz, “A.I. Is Learning from Humans. Many Humans,” New York Times (August 16, 2019), https://www.nytimes.com/2019/08/16/technology/ai-humans.html.
38. Langdon Winner, “Do Artifacts Have Politics?,” Daedalus 109, no. 1 (1980): 121–136.
39. Tarleton Gillespie, “The Politics of ‘Platforms,’” New Media & Society 12, no. 3 (May 1, 2010): 347–364, https://doi.org/10.1177/1461444809342738.
40. See Safiya Noble’s discussion of digital redlining in her chapter in this volume, and the work of Chris Gilliard on this subject.
41. Ali Winston and Ingrid Burrington, “A Pioneer in Predictive Policing Is Starting a Troubling New Project,” The Verge (April 26, 2018), https://www.theverge.com/2018/4/26/17285058/predictive-policing-predpol-pentagon-ai-racial-bias.
42. “How CEP’s EGLYPH Technology Works,” Counter Extremism Project (December 8, 2016), https://www.counterextremism.com/video/how-ceps-eglyph-technology-works.
43. Safiya Umoja Noble, Algorithms of Oppression: How Search Engines Reinforce Racism (New York: NYU Press, 2018).
44. Siva Vaidhyanathan, Antisocial Media: How Facebook Disconnects Us and Undermines Democracy (New York: Oxford University Press, 2018); Virginia Eubanks, Automating Inequality: How High-Tech Tools Profile, Police, and Punish the Poor (New York: St. Martin’s Press, 2018).
45. “ACM FAT*,” accessed August 1, 2018, https://fatconference.org/.
46. “People—Algorithmic Fairness and Opacity Working Group,” accessed August 1, 2018, http://afog.berkeley.edu/people/.
47. “AI Now Institute,” accessed August 1, 2018, https://ainowinstitute.org/.
48. Alex Campolo et al., “AI Now 2017 Report” (AI Now, 2017), https://ainowinstitute.org/AI_Now_2017_Report.pdf.