18
WRITTEN AND COMPUTER-BASED APPROACHES ARE VALUABLE TOOLS TO ASSESS A LEARNER’S COMPETENCE
Reg Dennick
With proper attention to key principles it is possible to create accountable and robust written and online assessment procedures.
Aims and objectives
This chapter is concerned with the use of objective written tests in medical education assessment. By ‘objective’ we mean tests with unambiguous answers that can be dichotomously marked as either correct or incorrect. Objective written tests are predominantly oriented towards the knowledge domain and are mainly of multi-format design using multiple-choice (single best answer), multiple-response (multiple answers), extended matching, fill in the blanks (cloze), drag and drop, script concordance and hotspot image questions. More recently, objective written tests have been created and marked by computers and for the purposes of this chapter they exclude essays or short written answers which cannot yet be marked in this way.
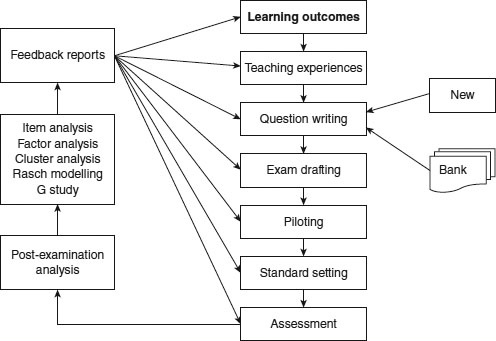
The importance of written objective tests lies in their ubiquitous global use to test knowledge and their increasingly strong association with computer-based assessment systems. There is a common misconception that objective tests can only assess simple recall and understanding, whereas in principle most types of knowledge in Bloom’s taxonomy, from recall through application to problem solving, can be assessed by appropriately constructed questions. Nevertheless, the knowledge that can be tested always needs to be mapped (‘blueprinted’) against the learning outcomes of the course at an appropriate level. Online assessment systems should readily fit into the exam cycle, as shown in Figure 18.1.
Range of assessments
The range of objective written tests that can be marked by computer include:
• multiple-choice questions (MCQs);
• extended matching items (EMIs);
• ranking questions;
• fill in the gap (cloze) and text/number entry;
• script concordance testing;
• image hotspots;
• labelling (‘drag and drop’);
• video.
The key attributes of each of these will be summarised below.
MCQs
The major objective formats are outlined in the guide produced by Case and Swanson (2002). These formats are employed in most conventional types of assessment and can be readily modified for the online environment by including images, sound and video clips.
These objective tests are structured around the format of a question (stem) followed by a series of possible answers with the correct answer embedded or surrounded by a range of incorrect answers or ‘distractors’. For example a ‘single best answer’ might have the correct answer listed with four distractors (Figure 18.2). It is possible to extend this format into the ‘multiple-response’ style of question, where more than one item should be selected from the list. In these cases sufficient distractors should be provided to ensure that the probability of answering the question correctly by chance does not become too high.
EMIs
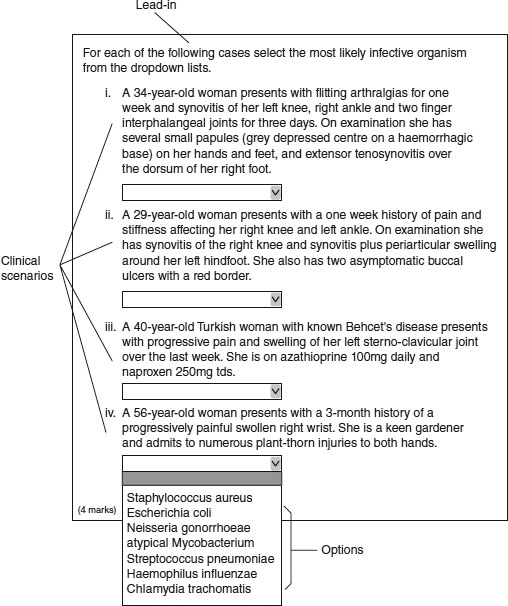
The EMI format is really an extension of the multiple-choice format in which selected items from one list are matched to items in another list. The usual format is that there is a short list of say two to four clinical scenarios or patient descriptions which must be matched to appropriate items in a longer list of, for example, seven to 12 diagnoses, drugs, organisms, investigations or other clinical entities (Figures 18.3 and 18.4). The format can be extended by the use of images containing items for identification. The advantage of this format is that assessors can test the ability of individuals to differentiate between closely related concepts which potentially identify deeper levels of understanding. Both MCQs and EMIs can be associated with problem-solving or data interpretation stems so that application and problem solving can be tested.
Nevertheless, it has been argued that these types of questions, where the correct answer is essentially given as a choice that can be recognised, are intrinsically easier than having to recall the answer from memory without prompting. Evidence suggests that in the case of single best answer formats there is a significant enhancement in marks between recognition and recall (Newble et al. 1979). There is no doubt that there is a cognitive price to pay but the feasibility of this system has led to its almost universal adoption.
Ranking questions
It is possible to create a question format in which students have to correct the rank or place in order a list of items (Figure 18.5). This might be testing their knowledge of the frequency of occurrence of clinical entities or testing their ability to place a sequence of clinical actions into the correct temporal sequence.
Fill in the gap (cloze) and text/number entry
These are related systems that involve the student entering single words, phrases or numbers into a section of text or a designated text/numerical box. ‘Cloze’ is the technical term for inserting deleted words into a section of text in order to complete it correctly, and hence for assessing recall of factual information (Taylor 1953). Single words, phrases or numbers can be inserted into designated boxes as answers to a variety of question types (Figure 18.6). The effectiveness of solutions to the problems of error trapping the input and recognising correct answers from all possible inputs is a limiting factor in the use of this question format.
Script concordance testing
Script concordance testing is increasingly being used to design questions that test clinical reasoning. The standard approach is to construct a question based around, for example, the interpretation of history taking, physical examination or investigations and to ask the student if the results of these processes influence differential diagnostic decisions according to a rating scale (Figure 18.7). The student’s response is compared to the consensual decision from a panel of experts and marked accordingly.
Image hotspots
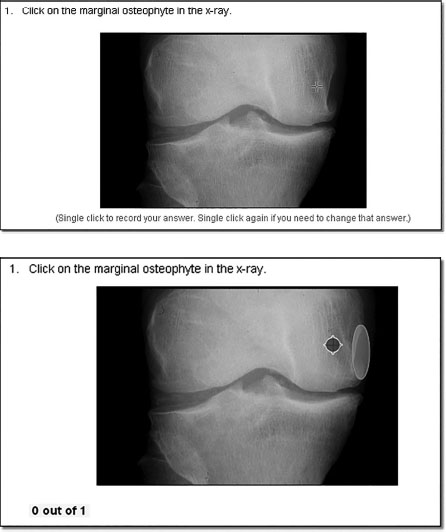
Image hotspot questions are good for assessing visual knowledge that would be difficult to achieve though an MCQ or other textual question type. They have a second advantage in that there are no visual cues as to where the correct answer lies, there are no discrete distractors to choose from, and each pixel is a potentially correct or incorrect answer. Questions have to be constructed by outlining the area on an image that must be identified correctly (Figure 18.8). There will inevitably be boundary issues associated with this procedure (what is ‘in’, what is ‘out’), but nevertheless these type of questions can be made highly reliable.
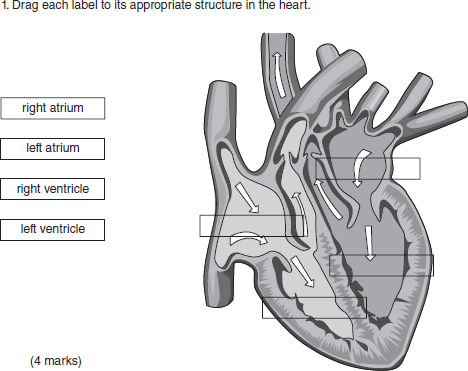
Labelling (drag and drop)
Labelling questions, like image hotspots, are ideally suited to assessing visual knowledge, and differ in the cues they provide. With a labelling question a number of ‘place holders’, the empty rectangles (Figure 18.9), are pre-displayed over the image of interest. The examinee must drag labels from the left and drop them into the relevant place holders. Sometimes a larger number of labels than place holders, acting as distractors, are used to make the question more difficult.
Figure 18.8 An example of an ‘image hotspot’ question. The top image shows what the student sees and the cursor which must select the correct area of the image. The bottom image shows the area selected by the assessor (large oval) in which the cursor must be placed. (Courtesy of Rogo, an open-source program produced by the University of Nottingham.)
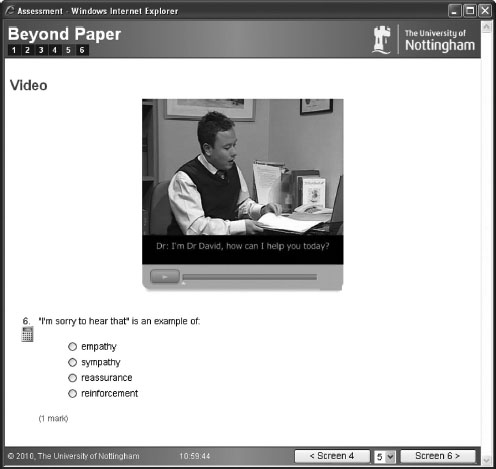
Video
The ability to deliver video or moving images to a student during an assessment considerably extends the scope of question formats. Videos of patients, doctor–patient interactions, procedures, consultations and communications can all be used to create appropriate assessment scenarios that have high content validity (Figure 18.10). Video can be used to set up a scenario which can be subsequently assessed by means of the formats described above.
Writing questions
The construction of objective written questions requires some skill. The fundamental issue is to ensure that the question is valid and unambiguous and does not contain information that will allow an individual to identify any element of it as either correct or incorrect without using the knowledge constructs that the question is aimed at. Distractors in particular have to be plausibly incorrect and homogeneous with the correct answer, otherwise they can easily be eliminated without the student necessarily knowing the correct answer. There need to be sufficient distractors so that the question cannot easily be answered by chance alone. In the case of single best answers this probability should not usually be greater than 1 in 5 or 20 per cent. With multiple-response questions more distractors are required to maintain this level of probability. (The creation of plausible distractors is often the most difficult aspect of good item writing.)
Grammatical issues in sentence construction can also allow the ‘test-wise’ candidate to identify implausible distractors. Anything that provides inappropriate information will reduce the reliability of the question and the test; it will generate ‘noise’. A useful reference work for writing good-quality items is Case and Swanson (2002).
There are a number of key criteria that can be used to characterise assessments, including validity, reliability and feasibility, and these can easily be satisfied by objective written tests.
Validity
In general, assessment validity is concerned with whether an assessment measures what it is designed to measure and can be subdivided into a variety of different types (Dent and Harden 2013):
• Content validity: does the test measure and sample relevant learning objectives or outcomes?
• Construct validity: does the test measure an underlying cognitive trait, e.g. intelligence?
• Concurrent validity: does the test correlate with the results of an established test?
• Predictive validity: does the test predict future performance?
• Face validity: does it seem like a fair test to the candidates?
For the purposes of this chapter the most important elements that might be influenced by being online would be content validity and possibly the related concept of construct validity. However, Schuwirth and van der Vleuten (2006) argue that assessments must also have face validity for students. This is an important issue, particularly when introducing online e-assessment for the first time to students who may be unfamiliar with its processes and may require reassurance.
Certainly content validity can be enhanced and expanded by means of online assessment technology. For example, the following additional features can be added to online questions:
• animations, video and sound (if headphones are used in the examination room);
• ‘hotspot’ questions which require students to place a mark anywhere on an image or diagram;
• dragging labels directly over an image.
In all these cases the online nature and technological aspects of the assessment can significantly influence the authenticity of questions that can be created in comparison to other forms of paper-based assessment media (Sim et al. 2005). Evidence for increased validity can be found in an evaluation of multimedia online examinations by Liu et al. (2001). They investigated student and staff attitude to multimedia exams and found very strong support for their use. For example they found that:
• assessment more closely matched the material that was being taught;
• the presentation of more than one medium of information seemed to aid the students’ recall;
• questions reflected real-world situations more accurately;
• students seemed to learn more in these assessments, which helped them as they continued their studies.
Reliability
The reliability of an assessment refers to its ability to give the same measure of learning consistently when used repeatedly despite sampling error. The most common cause of unreliability in objective testing is poorly constructed questions that are ambiguous, too easy or too hard. In the sort of objective testing we are describing here, where objective criteria are decided beforehand, questions are constructed avoiding the problems described above and questions are marked electronically, this type of reliability problem can be diminished.
A well-known measure of reliability is the internal consistency of the assessment task, usually measured by correlating individual item scores to other items or to the global test score which can be processed to give a value of reliability, such as Cronbach’s alpha statistic (Tavakol and Dennick 2011b). Because with online assessments it is possible to supply a different set of questions from a question bank to different individuals in the same examination, or to generate different numerical values for calculations or problem-solving items within a question, the questions delivered to individuals can vary slightly. Provided the range of these variables is within agreed boundaries overall, the reliability of the test should not be greatly compromised.
In the case of computer-based tests reliability can also be influenced how easily individuals are fatigued by using a visual display unit (VDU). Guidance recommends that online tests should last no longer than 2 hours.
Feasibility
Online assessment is not necessarily cheaper than alternative forms simply because a whole cohort can be marked in a matter of seconds. The following costs need to be taken into consideration:
• large numbers of computers are required for a simultaneous start;
• additional invigilators will be required if these machines are located in different computer rooms;
• dedicated assessment servers are required to minimise failure risk;
• assessment software will be required;
• departmental/institutional staff are required to support the system;
• educationalists are required, advising on pedagogic approach and assessment strategies;
• programmers’ salaries need to be factored in;
• trainers familiar with the assessment software are required;
• IT support technicians are required.
Some of the costs of online assessment are considerable, for example, server hardware, large computer labs and the licence cost of the assessment software itself. Less tangible costs include members of IT support staff spending more time maintaining systems. However, once the investment is made in online testing it rapidly becomes the most feasible and efficient method of assessing knowledge-based examinations.
Question banks and adaptive testing
Collaboration between medical schools in the UK has produced the Medical School Council Assessment Alliance (MSC-AA), an arrangement between UK medical schools in which questions can be banked and shared. Metadata can be attached to items to provide information on the learning objectives being tested and item difficulty and discrimination. Banked questions can be used to generate adaptive test papers in which questions of increasing difficulty or challenge are presented to learners in response to their answers to previous questions.
Standard setting, external examining and online feedback
Online objective test papers can readily be made available to groups of examiners and external examiners so that they can engage in online standard setting (Figure 18.11). For example, using the Angoff method, each question can be evaluated for the probability that a ‘borderline’ student will answer it correctly (Angoff 1971). By collating the online evaluations a consensus cut score can be obtained.
Online systems mark items immediately, although it is wise to allow some time for moderation and checking before releasing marks to students. Such systems also allow students to be given rapid feedback on their answers (Figure 18.12). When tests are used formatively, students can revisit the online paper and see which questions they answered correctly and which they did not. Feedback to answers can be attached to items, leading to an ‘assessment for learning’ environment. In the case of high-stakes summative examinations, when items need to be reused, learning objective metadata for each item can be used to generate a more generic form of feedback that does not allow items to be displayed again.
Psychometric analysis
Online objective assessment systems can be configured to process data using a variety of psychometric methods. As well as mean marks, item difficulty and discrimination can be calculated, in addition to Cronbach’s alpha statistic (Tavakol and Dennick 2011b).
Computer-based testing in practice
The following case study from India highlights some of the key issues associated with implementing computer-based testing (CBT) and discusses the process undertaken by the National Board of Examiners (NBE) in India.
Case study 18.1 Computer-based testing – a paradigm shift in student assessment in India
Bipin Batra
Billions of examinations and assessments are administered every year across the globe. In recent times, CBT has drawn the attention of assessment institutions as a new approach to deliver tests and assess performance of candidates or rank them on their abilities.
Conventionally, medical entrance examinations have been conducted as paper-based testing (PBT), in which a booklet containing a predetermined number of questions is provided to the candidates. On testing day candidates have to mark their responses on the optical mark reader (OMR) sheets. PBT, though simple in approach and implementation, is plagued with a multitude of problems such as the possibility of leakage of confidential material/information, the unfair use of electronic gadgets, impersonations and cheating by the examinees and logistics-related issues in transporting the question paper.
The NBE, India, is an organisation in the field of medical education that conducts various types of student assessment. Concerned with relative weakness and threats to the PBT, NBE introduced computer-based testing for entrance examinations. CBT is an IT-driven process which requires computer labs equipped with servers, secure wide-area network connectivity, firewalls, trained human resources and appropriate software and hardware. A CBT significantly enhances the scope of items to use in the test and enhances the test blueprint. The NBE conducted one of the largest tests using CBT, the National Eligibility cum Entrance Test, with 90,377 examinees in December 2012 and the steps undertaken are outlined below.
Prior to test
• The plan was tested.
• The details of estimated candidates and resources required, especially test centres, IT labs, questions/item bank and faculty support required, were mapped.
• Engagement of all stakeholders towards the impending change from PBT to CBT was undertaken by social media, internet discussions and direct communications.
• The test blueprint was prepared, the size of item bank required was estimated and the requisite numbers of items for use in the test were generated and transferred to the item banking software at specially convened item-writing workshops.
• Candidate registration and test centre scheduling were performed through web-based application.
• Computer labs with predefined technical requirements and hardware specifications were arranged at required locations with appropriate seating capacity.
• Pilot administration was undertaken 2 days before the actual test.
Testing phase
• Test administration was undertaken, with test forms released on the wide-area network immediately before onset of the test.
• Examinee feedback was undertaken on a structured questionnaire.
• After completion of the test, the responses of examinees were uploaded to the server.
Post-test phase
• Items analysis was performed through computation of difficulty and discriminatory index on two parameter models.
• Post-test form validation workshop was undertaken to review the difficulty and discriminatory indices.
• Item response theory and generation of equated score were applied to ensure comparability of different test forms used.
• Equated score was scaled using linear transformation.
• Results were published.
The NBE deployed the latest IT infrastructure to capture examinee biometrics and video record the testing phase. For 58 per cent of examinees this was their first exposure to CBT: 95 per cent of examinees felt the CBT of December 2012 met their expectations.
The conversion from PBT to CBT involved stakeholder acceptance and it was important to engage faculty, students and academic leadership at institutions and universities in the process at all stages. Medical teachers were appropriately sensitised towards use of psychometric tools and underlying principles of assessment. A sound test blueprint and adherence to principles of assessment supported with psychometric tools, ensuring stakeholder confidence and meticulous planning, were the keys to success.
Technical issues
System requirements
When an online exam begins, all the computers that the students are using will send their requests back to a single web server which holds the exam paper. The main drawback of this system is that it introduces a single point of failure, which must be addressed by appropriate security and backup systems. Testing of online exam systems should be routine and, where possible, a dedicated assessment server should be used which is independent of other systems.
Going live
The live delivery of an online summative exam, under conventional exam conditions, is the most crucial phase of the process. There is an international standard produced by the British Standards Institution entitled A Code of Practice for the Use of Information Technology (IT) in the Delivery of Assessments (BS ISO/IEC 23988 2007) which covers many aspects of exam delivery in generic terms.
Security
External security risks are possible with any server attached to the internet. Hackers anywhere worldwide are constantly using methods and software systems to root out vulnerable servers. Firewall systems should be robustly utilised to control requests and protocols accepted and transmitted by a server, and all software subsystems should be patched and kept up to date. Internal security should ensure that online test papers can only be accessed by authorised individuals. Segregating groups of students for consecutive sittings of an exam when computer screens are a limiting factor is essential. Preventing cheating by students in online exams requires configuring computers to allow access only to the exam and to provide visual barriers between screens.
For further information the interested reader is referred to Dennick et al. (2009).
Take-home messages
• Objective tests can be used to assess a wide variety of knowledge at different levels of complexity.
• Objective tests must be carefully constructed using valid and unambiguous items with plausible and homogeneous distractors to increase reliability and eliminate ‘noise’.
• Images and other media can be added to objective tests to extend the range of knowledge tested using hotspots, drag and drop and video.
• Objective tests are ideally suited to computer-based platforms and a variety of online systems can now reliably and securely deliver high-stakes assessments to individuals.
• Online objective test systems can provide psychometric analysis of exam results which can be mapped to learning outcomes and provide feedback to learners.
Bibliography
Angoff, W.H. (1971) ‘Norms, scales, and equivalent scores’. In R.L. Thorndike (ed.) Educational measurement (2nd edn), Washington, DC: American Education on Education.
British Standards Institution (2007) BS ISO/IEC 23988 Information technology – A code of practice for the use of information technology (IT) in the delivery of assessments, London: British Standards Institution.
Case, S.M. and Swanson, D.B. (2002) Constructing written test questions for the basic and clinical sciences (3rd edn), Philadelphia, PA: National Board of Medical Examiners.
Dennick, R.G., Wilkinson, S. and Purcell, N. (2009) Online eAssessment. AMEE guide no. 39. Association for Medical Education in Europe, Medical Teacher, 31(3): 192–206.
Dent, J.A. and Harden, R.M. (2013) A practical guide for medical teachers (4th edn), Edinburgh: Elsevier.
Liu, M., Papathanasiou, E. and Hao, Y. (2001) ‘Exploring the use of multimedia examination formats in undergraduate teaching: Results from the fielding testing’, Computers in Human Behaviour, 17(3): 225–48.
Newble, D.I., Baxter, B. and Elmslie, R.G. (1979) ‘A comparison of multiple-choice tests and free-response tests in examinations of clinical competence’. Medical Education, 13, 263–8.
Schuwirth, L.W.T. and van der Vleuten, C.P.M. (2006) Understanding medical education guides. How to design a useful test: The principles of assessment, Association for the Study of Medical Education, Edinburgh: ASME.
Sim, G., Strong, A. and Holifield, P. (2005) The design of multimedia assessment objects, Proceedings for 9th CAA Conference, Loughborough.
Tavakol, M. and Dennick, R.G. (2011a) ‘Post-examination analysis of objective tests’, Medical Teacher, 33(6): 447–458.
Tavakol, M. and Dennick, R.G. (2011b) ‘Making sense of Cronbach’s alpha’, International Journal of Medical Education, 2: 53–5.
Taylor, W.L. (1953) ‘Cloze procedure: A new tool for measuring readability’, Journalism Quarterly, 30: 415–33.