Kapitel 12. Das C++11-Speichermodell
Die Grundlage für Multithreading ist ein definiertes Speichermodell. Dieses erhält C++11 in Anlehnung an Java.
Grundproblem des konkurrierenden Zugriffs
Das Grundproblem des konkurrierenden Zugriffs auf Variablen lässt sich einfach formulieren. Schreibt ein Thread eine gemeinsam genutzte Variable, während ein anderer diese liest, ist das Verhalten nicht deterministisch.
Der bekannte Programmschnipsel in Abbildung 12.1, der auf Deckers Algorithmus basiert (Dekker, 2011), soll das verdeutlichen, denn am Ende des Programms können sowohl r1 als auch r2 den Wert 0 besitzen.
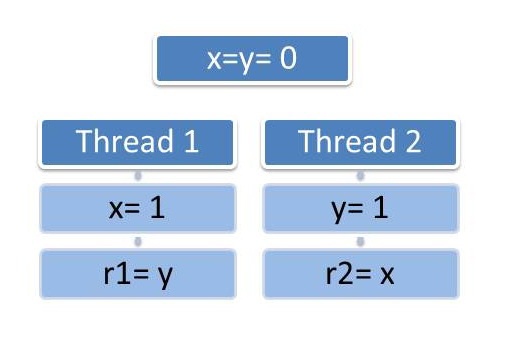
Wie kann das passieren?
Die Antwort für dieses nicht sehr intuitive Verhalten ist, dass durch Optimierung auf Hardwareebene (Schreibpuffer) oder auch Standard-Compiler-Transformationen die Reihenfolge der Operationen des Prozessors nicht der des Programmcodes entsprechen muss. Dieses Verhalten ist ein Bruch der sequenziellen Konsistenz.
C++11 bietet für dieses Problem zwei Lösungen an: Locks und atomare Datentypen.
Schutz der Daten durch Locks
Durch den Lock lock wird der Zugriff auf den kritischen Bereich synchronisiert. Der Thread in Abbildung 12.2, der zuerst den Lock erhält, kann seinen Code zuerst ausführen. Nun sind alle Fälle möglich, einzig das Paar (r1,r2) kann nicht den Fall (0,0) annehmen.
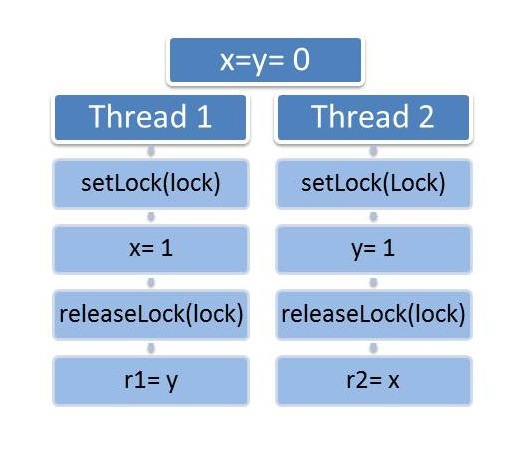
Schutz der Daten durch Atome
Durch Atome werden die Schreibzugriffe auf x und y sofort in beiden Threads sichtbar. Das Ergebnis ist das gleiche wie im Fall der Locks (Abbildung 12.2). (r1,r2) kann wiederum den Fall (0,0) nicht annehmen.
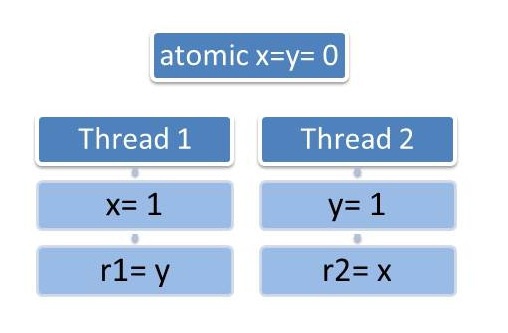
Rund um Wahrheitswerte, Zeichen und Ganzzahlen bringt C++11 verschiedene atomare Datentypen mit. Außerdem lässt sich die Speicherordnung beim Lesen und Schreiben atomarer Datentypen exakt spezifizieren. Der Standard, der auch Grundlage des Beispiels in Abbildung 12.3 war, ist die sequenzielle Konsistenz.
Punkte eines Speichermodells
Auf den Punkt gebracht, muss sich ein Speichermodell mit folgenden Punkten auseinandersetzen:
Atomare Operationen: Operationen, die ohne Unterbrechung ausgeführt werden können.
Partielle Ordnung von Operationen: Reihenfolge von Operationen, die der Compiler nicht verändern darf.
Speichersichtbarkeit: Zeitpunkt, ab dem der gemeinsame Speicher für alle Threads den gleichen Wert besitzt.
Denn das Speichermodell ist die Grundlage für den Compiler, den Code zu optimieren, ohne seine Semantik zu ändern.
Für weitergehende Informationen hat Hans Boehm viele Artikel zum anspruchsvollen C++-Speichermodell unter (Boehm, 2011) zusammengetragen.
Aufgabe 12-1
Watch video!
Sich dem C++11-Speichermodell direkt zu nähern, ist nicht zu empfehlen. Der sichere Weg führt über das Java-Speichermodell. Zu dem Thema gibt es zwei hervorragende Videovorstellungen. Jeremy Manson präsentiert das »Java Memory Model« in der Serie »Advanced Topics in Programming Language« (Manson, 2007) und Bartosz Milewskis »The Java Memory Model« (Bartosz, 2009). Gestählt mit dem Wissen, ist der Angriff auf das C++11-Speichermodell möglich (Boehm, 2011).