Kapitel 21. Die nächsten C++-Standards
Nach dem Standard ist vor dem Standard. Da stellt sich natürlich die Frage, welche Features der nächste C++-Standard besitzen sollte. Diese ist nicht eindeutig zu beantworten, da zwei neue C++-Standards in Planung sind. So soll es 2014 mit C++14 einen kleinen Standard geben, der die Fehler aus C++11 behebt. Und für 2017 ist mit C++17 ein großer Standard geplant, der C++ um viele neue Feature erweitert. Die Funktionalität des unmittelbar bevorstehenden C++-Standards C++14 ist zum jetzigen Zeitpunkt 2013 schon recht stabil.
C++14
Mit dem aktuellen GCC 4.9 steht ein Compiler zur Verfügung, mit dem sich viele der Verbesserungen des C++14-Standards schon anwenden lassen (C++1y/C++14 Support in Gcc, 2013).
Kernsprache
Mit generischen Lambda-Funktionen und dem vereinfachten Ermitteln des Rückgabetyps einer Funktion bietet C++14 zwei deutliche Verbesserungen gegenüber C++11 an.
Lambda-Funktionen
Lambda-Funktionen in C++14 sollen um zwei Features erweitert werden. Zum einen sollen ihre Parameter mit auto deklariert werden können, sodass sie keinen konkreten Typ benötigen. Zum anderen sollen Lambda-Funktionen ihren Aufrufkontext per move erfassen können. Beide Features zeigt Listing 21.1 in der Anwendung.
auto lambda = [](auto x, auto y) {return x + y;};
auto ptr = std::unique_ptr<int>(10);
auto lambda = [ptr{std::move(ptr)}] {return *ptr;};Schön ist in dem Beispiel zu sehen, dass die Parameter der Lambda-Funktion x und y generisch sind und dass der std::unique_ptr in der Lambda-Funktion verwendet werden kann, obwohl er das Kopieren nicht unterstützt.
Automatischer Rückgabetyp einer Funktion
Mit den zwei Schlüsselwörtern auto und decltype ist es möglich, ein generisches Funktions-Template zu schreiben, das seinen Rückgabetyp automatisch ermittelt. Mit C++14 soll dies deutlich einfacher werden, denn es wird nur noch auto benötigt.
Konstante Ausdrücke
Als konstante Ausdrücke definierte Funktionen werden mit C++14 mächtiger. So können sie Deklarationen enthalten und Schleifenanweisungen.
Variablen-Templates
Neben Funktions- und Klassen-Templates erhält C++14 Variablen-Templates. Variablen-Templates sind Variablen, die mit einem Typ parametrisiert werden. Dies lässt sich am einfachsten anhand des Codes in Listing 21.3 aus dem Entwurf zum Standardtext (Reis, 2013) zeigen.
Standardbibliothek
Nicht nur die Kernsprache in C++14, auch die Standardbibliothek mit der Bibliothek zu optionalen Werten und dem neuen sequenziellen Container std::dynarray bietet sehr interessante Erweiterungen an.
Optionale Werte
C++14 erhält optionale Typen. Diese basieren auf boost::optional (boost, 2013) und enthalten einen oder auch keinen Wert (Listing 21.4).
Benutzerdefinierte Literale
Mit C++11 erhielt C++ benutzerdefinierte Literale, mit C++14 erhält C++ Literale für die Standardbibliothek. So erhält std::basic_string mit dem Suffix »s« ein Literal, und std::chrono::duration erhält mit »h«, »min«, »s«, »ms«, »us« und »ns« Literale.
dynarray
C++14 wird mit std::dynarray um einen neuen sequenziellen Container erweitert. Dieser zeichnet sich durch zwei Punkte gegenüber den etablierten Containern std::array und std::vector aus. Im Gegensatz zum std::array kann seine Länge zur Laufzeit bestimmt werden, und anders als beim std::vector werden seine Elemente auf dem Stack angelegt.
tuple
In C++11 lassen sich die Elemente eines std::tuple über ihren Index referenzieren. Mit C++14 ist es möglich, die Elemente direkt mit ihrem Typ anzusprechen. Dazu muss dieser aber eindeutig sein.
C++17
Neben den Bibliotheken des „Technical Report 2“ (TR2), der in der bewährten Tradition des »Technical Report 1« (TR1) steht, sind natürlich die für C++11 geplanten Features, die nicht in den C++11-Standard aufgenommen wurden, heiße Kandidaten für C++17.
Für C++11 geplant
Mit Modulen, speziellen mathematischen Funktionen und insbesondere Concepts liegt die Messlatte für C++17 sehr hoch.
Module
Module stellen einen Mechanismus dar, Bibliotheken zusammenzupacken und ihre Implementierung zu kapseln. Damit soll die klassische Trennung von Übersetzungseinheit und Header-Datei in C++ aufgehoben werden, da Module an einer Stelle definiert werden können. Ursprünglich für C++11 angedacht, sollen sie in den nächsten Technical Report aufgenommen werden. David Vandevoorde stellt in dem Vorschlag (Proposal) »Modules in C++« (Vandevoorde, 2007) ihre drei primären Ziele dar:
Signifikant schnellere Übersetzungszeit von großen Projekten (Significantly improve build times of large projects).
Sie erlauben eine bessere Trennung von Interface und Implementierung. (Enable a better separation between interface and implementation.)
Sie bieten einen tragfähigen Migrationspfad für bestehende Bibliotheken an. (Provide a viable transition path for existing libraries.)
Darüber hinaus sollen Module bekannte Probleme in C++ wie die Initialisierungsreihenfolge von Variablen lösen und dem Compiler weiteres Optimierungspotenzial an die Hand geben.
Spezielle mathematische Funktionen
Die speziellen mathematischen Funktionen sind der Teil aus dem TR1, der nicht in den C++11-Standard übernommen wurde. Dies wird sich wohl mit C++17 ändern. Die 23 Funktionen, die in überladenen Formen für float, double und long double angeboten werden, besitzen einen speziellen Fokus auf naturwissenschaftliche Disziplinen. Ohne ins Detail zu gehen, folgt ein kleiner Überblick.
Polynome von Laguerre, Legendre und Hermite
elliptische und exponentielle Integrale
hypergeometrische, Beta-, Gamma-, Bessel-, Zeta-, Legendre- und Neumann-Funktionen
Die genauen Formeln und weiterführende Erläuterungen sind auf der TR1-Wikipedia-Seite dargestellt (C++ Technical Report 1, 2011).
Concepts
Es war schon eine große Überraschung, als im Juli 2009 Concepts aus dem C++11-Standard (Stroustrup, The C++0x “Remove Concepts” Decision, 2009) entfernt wurden. Dies geschah beim ISO C++-Standard Komitee Meeting in Frankfurt und war umso überraschender, da die Concepts als das wichtigste Feature für die generische Programmierung in C++ angesehen wurden – wichtig, um die Programmierung mit Templates auf eine theoretische Basis zu stellen, wichtig, um die Verwendung von Templates für den alltäglichen Gebrauch zu verbessern.
Was sind Concepts? Concepts sind ein Typsystem für Templates. Sie leisten in ähnlicher Weise das für die generische Programmierung, was Vererbung für die objektorientierte Programmierung tut. Ein Datentyp muss ein definiertes Interface anbieten, um in einem Algorithmus verwendet werden zu können. Wem die Typklassen von Haskell (The Haskell Programming Language, 2011) oder Scala bekannt sind, der wird viele Ähnlichkeiten zu den Concepts in C++ entdecken. Das kleine Listing 21.6 soll aufzeigen, welches Problem Concepts beim generischen Programmieren adressieren sollen.
concepts.cpp
01 template<typename T>
02 const T& getMinimum(const T& l, const T& r){
03 return (l<r) ? l : r;
04 }
05
06 class MyInt{
07 public:
08 MyInt(int i):val(i){}
09 int getVal() const {
10 return val;
11 }
12 private:
13 int val;
14 };
15
16 int main(){
17
18 int a=0;
19 int b=1;
20
21 int min1= getMinimum(a,b);
22
23 MyInt c(min1);
24 MyInt d(0);
25
26 getMinimum(c,d);
27
28 }Wird Listing 21.6 übersetzt, moniert der Compiler das (Abbildung 21.1) sofort.
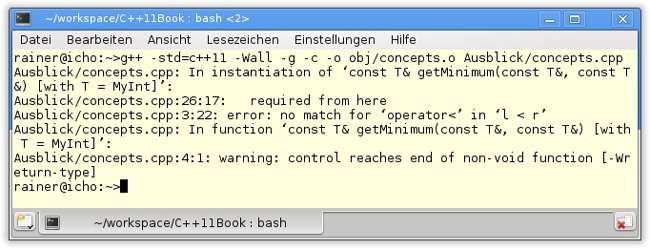
Der Compiler weist in diesem Fall direkt auf den Fehler hin. Für den Datentyp MyInt ist kein kleiner Operator operator < definiert. Klar, er fehlt ja auch. Die Idee von Concepts ist es nun, dass der generische Algorithmus getMinimum die Bedingungen an seine Typparameter stellt.
template<std::LessThanComparable T>
const T& getMinimum(const T& l, const T& r){
return (l<r) ? l : r;
}Damit drückt die Signatur des Templates std::LessThanComparable explizit aus, welche Bedingungen ein Typparameter erfüllen muss, um verwendet werden zu können. Die Fehlermeldung soll dadurch deutlich einfacher zu lesen sein. Die Ist-Situation ist und bleibt aber, dass die Template-Implementierung im Fehlerfall daraufhin analysiert werden muss, welche Operation der konkrete Datentyp nicht unterstützt.
Die Funktionalität von Concepts umfasst die folgenden Bereiche:
Durch C++11 vordefinierte und selbst definierte Concepts.
Binden eines Datentyps an ein Concept durch
concept_map.Axiome, um die Bedeutung von Concepts auszudrücken. Damit besitzt der Compiler weitreichende Optimierungsmöglichkeiten.
Wer einen genaueren Einstieg in Concepts sucht, findet ihn auf Wikipedia (Concepts (C++), 2011).
Die entscheidende Frage, die noch im Raum steht, ist, was mit den Concepts passiert. Der Tenor in der C++-Community ist, dass sie in einer leichtgewichtigeren Form Bestandteil des C++17-Standards sein werden.
Technical Report 2
Viele Erweiterungen der Standardbibliothek von C++11 haben ihren Ursprung im Technical Report 1. Der Technical Report 1 wiederum bestand aus Bibliotheken der Boost-Bibliothek (boost, 2013), die schon länger im Einsatz waren. Dieses Verfahren hat sich bewährt und wird sich wohl nach C++11 fortsetzen. Der Technical Report 2 (TR2) umfasst schon einige etablierte Bibliotheken, die wiederum aus dem Boost-Umfeld stammen.
Boost
Boost, das im Jahr 2000 von Mitgliedern des C++-Standardisierungskomitees gegründet wurde, umfasst gut 100 freie C++-Bibliotheken. Diese zeichnen sich durch die folgenden Punkte aus. Sie
sind von weltweit anerkannten C++-Experten programmiert,
durchlaufen einen formalen Qualitätssicherungsprozess,
müssen auf den gängigen Plattformen lauffähig sein,
werden weltweit von vielen Programmierern eingesetzt,
werden regelmäßig auf den alten und neuen Compilern getestet und
müssen eine Lizenz besitzen, die weder den kommerziellen noch den nicht kommerziellen Gebrauch einschränkt.
Der Aufruf für neue Vorschläge für den Technical Report 2 startete bereits 2005. Die Schwerpunkte in dem Proposal von Howard Hinnant, Beman Dawes und Matt Austern (Hinnant, Dawes, & Austern, 2005) sind:
Unicode
XML und HTML
Netzwerk
Benutzerfreundlichkeit für Einsteiger und Gelegenheitsprogrammierer
Aus diesem Aufruf zu Vorschlägen sind einige konkrete Proposals hervorgegangen, die Bestandteil des Technical Report 2 sind. Die folgenden Vorschläge haben ihre Ursprünge in der Boost-Bibliothek. Sie sind alle schon länger im Einsatz und haben damit ihre erste Bewährungsprobe mit Bravour bestanden.
Erweiterte Thread-Funktionalität
Der Vorschlag zur erweiterten Thread-Bibliothek 2005 von Kevlin Henney (Henney, Preliminary Threading Library Proposal for TR2, 2005) wurde mittlerweile in Form von C++11 von der Realität eingeholt. Der Vorschlag umfasst drei Stufen von Thread-Unterstützung in C++11:
Ein C++-Speichermodell, atomare Datentypen und Lock-freie Operationen auf einfachen Datentypen.
Die Standardwerkzeuge, um Threads zu starten, zu verwalten und zu synchronisieren. Diese Stufe setzt Stufe 1 voraus.
Einen abstrakteren Zugang zum Umgang mit Threads als in Stufe 2 in Form von Message Queues und Threads Pools.
Dem aufmerksamen Leser wird es nicht entgangen sein: Die ersten beiden Punkte sind bereits im C++11-Standard enthalten. Sieht man von asynchronen Tasks ab, beschränkt sich die neue Thread-Funktionalität auf den abstrakteren Umgang mit Threads.
Netzwerkunterstützung
Der Vorschlag von Christopher Kohloff (Kohloff, 2007) hat seinen Ursprung in der Boost.Asio-Bibliothek (Kohlhoff, 2011). Boost.Asio unterstützt asynchronen IO, und so soll es auch die Technical Report 2-Bibliothek erlauben. Einen einfachen Überblick über die angedachte Funktionalität geben die folgenden Stichpunkte:
TCP, UDP und Multicast-Funktionalität
Client- und Serveranwendungen,
Skalierbarkeit, um mehrere Verbindungen gleichzeitig zu verwalten
IPv4- und IPv6-Unterstützung
Namensauflösung (DNS)
Zeitgeber
Signale und Slots
Signale und Slots, um Objekte einfach über Nachrichten miteinander kommunizieren zu lassen, sind sicher dem einen oder anderen aus der GUI-Programmierung mit dem Framework Qt (Qt (Bibliothek), 2011) bekannt. Basierend auf der Boost.signals-Bibliothek (Douglas, Boost.Signals, 2004), ist der Vorschlag zu Signal und Slots von Douglas Gregor (Douglas, Signal and Slots for Libary TR2, 2006) Bestandteil des Technical Report 2.
Das Listing 21.10 von (Douglas, Boost.Signals, 2004) zeigt in einfacher Weise, wie ein Signal mit einem Slot durch die Funktion connect so verbunden wird, dass das Auslösen des Signals die Aktion im Slot anstößt.
struct HelloWorld
{
void operator()() const
{
std::cout << "Hello, World!" << std::endl;
}
};
// ...
// Signal with no arguments and a void return value
boost::signal<void ()> sig;
// Connect a HelloWorld slot
HelloWorld hello;
sig.connect(hello);
// Call all of the slots
sig();Dateisystem-Bibliothek
Basierend auf der Boost-Dateisystem-Bibliothek von Dawes Beman (Dawes, Filesystem Library Version 3, 2011), soll der neue Standard ebenfalls eine Dateisystem-Bibliothek (Dawes, Filesystem Library Update for TR2 (Preliminary), 2011) erhalten. Damit wird es in C++ möglich, Pfade, Dateien und Verzeichnisse abzufragen und zu manipulieren.
Boost.Any-Bibliothek
Boost.Any von Kevlin Henney (Henney, Boost.Any, 2009) erlaubt einen typsicheren generischen Container für einzelne Werte verschiedenen Typs. Diese Boost-Bibliothek wird häufig eingesetzt, sodass eine Any-Bibliothek (Henney & Dawes, Any Library Proposal for TR2, 2006) ein weiterer Kandidat für den Technical Report 2 ist.
In Listing 21.11 aus (Henney, Boost.Any, 2009) wird der Container mit Variablen verschiedener Typen befüllt. Dabei wird das Argument implizit oder explizit nach boost::any konvertiert.
#include <list>
#include <boost/any.hpp>
using boost::any_cast;
typedef std::list<boost::any> many;
void append_int(many & values, int value)
{
boost::any to_append = value;
values.push_back(to_append);
}
void append_string(many & values, const std::string & value)
{
values.push_back(value);
}
void append_char_ptr(many & values, const char * value)
{
values.push_back(value);
}
void append_any(many & values, const boost::any & value)
{
values.push_back(value);
}
void append_nothing(many & values)
{
values.push_back(boost::any());
}Bibliothek zur lexikalischen Konvertierung
Genauso häufig wie die Boost.Any-Bibliothek (siehe vorherige Seite) ist die Bibliothek zur lexikalischen Textkonvertierung von Kevlin Henney (Henney, Lexical Cast) bereits im Einsatz. Sie bietet über das boost::lexical_cast-Funktions-Template eine bequeme und konsistente Konvertierung von und zu beliebigen Datentypen, solange sie als Text repräsentiert werden.
In Listing 21.12 ist Code aus der Boost-Bibliothek (Henney, Lexical Cast) zu sehen, in der numerische Kommandozeilenargumente in den Datentyp short umgewandelt werden.
int main(int argc, char * argv[])
{
using boost::lexical_cast;
using boost::bad_lexical_cast;
std::vector<short> args;
while(*++argv)
{
try
{
args.push_back(lexical_cast<short>(*argv));
}
catch(bad_lexical_cast &)
{
args.push_back(0);
}
}
...
}Neue String-Algorithmen
In Interpreter-Sprachen wie Python oder Perl geht die String-Verarbeitung viel leichter von der Hand als in C++. Mit dem neuen C++11-Standard erhielt C++11 eine Bibliothek für reguläre Ausdrücke für die anspruchsvolleren Anwendungsfälle. Für einfache Anwendungsfälle sollen die neuen String-Algorithmen die Fähigkeiten von C++ erweitern. Der Vorschlag von Pavol Droba (Droba, Proposal for new string algorithms in TR2, 2006) geht aus der Boost-String-Algorithmen-Bibliothek (Droba, String Algorithms Library, 2010) hervor. Die folgenden Bereiche sollen mit den neuen Algorithmen adressiert werden.
String-Manipulation und -Erzeugung
Teilstring-Extrahierung
Suchen und Ersetzen
Transformation
Parsen und Formatieren
Trimming und Padding
String-Prädikate