Chapter 5
Empirical Knowledge about Software Design
A key characteristic of this book is that wherever possible, when discussing issues about software design, the reader is provided with relevant empirical evidence to support the discussion. So this chapter provides a brief outline of what typically constitutes such evidence and how it is acquired.
We begin by discussing some issues related to measurement, since this underpins any discussion of empirical studies. We then go on to discuss something of these studies, what we mean by evidence in this context, and how it might be used to support software design.
What we will see is that acquiring empirical knowledge about software design issues can be quite challenging, and may not always lend itself to providing detailed guidance to the designer. However, empirical studies can often provide considerable insight into design choices, while also forming a more rigorous source of knowledge than ‘expert opinion’.
5.1Measuring software development processes
Empirical knowledge is usually based upon the use of some form of measurement. So, before discussing the forms of empirical study and the types of knowledge that they can provide, it is important to understand the forms of measure commonly used in empirical studies.
Many of our ideas about what constitutes ‘measurement’ stem from disciplines such as physics that involve measuring the properties of real-world phenomena. An important feature of subjects such as physics (as well as most other sciences and technologies) is that they are founded upon a positivist philosophy, embodying the assumption that there are general rules that apply to the phenomena being studied. In the physical world that philosophy is commonly manifested in such assumptions as “all electrons have the same mass and charge”1. A further assumption is that the ‘observer’ who is performing the measurements has no influence upon the values obtained.
Both of these assumptions present a challenge when we seek to study human-centric activities such as designing software. For practical purposes we have to adopt a positivist philosophy, while accepting that this is probably something of an approximation given that people have different abilities. And when designing our studies, we have to plan them so as to minimise the extent to which bias can arise from the involvement of the observer, particularly where any observations may involve an element of interpretation.
5.1.1Measuring physical phenomena
In the physics laboratory, a desirable form of experiment is one where the observer has as little to do with the measurement process as possible. If the measurement can be performed by instruments that (say) count the number of electrons hitting a ‘target’, then although measurement errors cannot be wholly eliminated, they can usually be kept to a very low level.
Often however, it isn't possible to avoid having the involvement of an observer when making measurements. For example, analysing traces that show how much a beam of electrons is deflected by a magnetic field. For this, some errors are likely to occur because the observer didn't have their head in quite the right position to read the relevant point on the scale, or simply made a small error in identifying or recording what the value should be.
Scientists are accustomed to this form of error and its properties. For one thing it is expected that over a large number of measurements there will be roughly as many ‘over-measures’ as ‘under-measures’, and that errors of this type will have a normal distribution, based on the well-known bell-shaped curve. Experimenters will be expected to make an assessment of the magnitude of such errors and to report them. While this will represent a (usually small) degree of uncertainty about the measured value, the important thing is that this uncertainty essentially stems from the limitations of the measurement instruments. Taken together with the original assumption that there is a single ‘right’ value, the expectation will be that any variation that we see in the measured values can be attributed to the way they were obtained.
5.1.2Measuring human reactions
Humans (a category generally accepted as including software developers) introduce a whole new element of complexity when we seek to make measurements related to the consequences arising from their actions.
Human-centric studies take many forms, as we will see in the next section. Usually they involve studying the effects arising from introducing some form of treatment or intervention to some situation. This requires the collection of measurements for one or more dependent variables in order to assess the effects. To explain about the issue of measurement, we focus on two major categories of treatment.
The first is those studies where the human participant is a recipient of the experimental treatment. An important form used for these is the Randomised Controlled Trial (RCT), as used in many branches of medical research. An RCT can be used to make comparison between the effects arising from the application of some form of experimental treatment and what happens when no treatment (or possibly, another treatment) is applied. An RCT uses two groups of human participants. One is the experimental group, whose members receive the treatment being investigated, in whatever form this might be administered, such as the use of tablets. The second is the control group whose members receive what appears to be the same treatment, but where this either employs some form of harmless placebo or consists of using an existing treatment for comparison.
The key issue here is that the experimenters expect to observe considerable variation when measuring the reactions of the participants in the two groups. This is because humans are complex and different and while everyone in the trial will have been selected because they have some condition that could potentially be affected by the treatment, this may occur in different degrees, and they may also have other conditions, possibly unknown, that could affect the outcomes.
Some people in the experimental group may therefore respond well to the treatment, but others less so, or even negatively. As a result the measured outcomes will vary between participants, and to a much greater degree than would arise from measurement errors alone.
So it can't be assumed that any measurements across each group will be spread in a normal distribution. This makes it necessary to use reasonably large groups of participants for such studies, together with statistical tests to determine whether or not the spread of results arises from the treatment, or could have been produced at random (that is, with the treatment not being the cause of any observed effects).
The second category contains those studies where the treatment involves the participants in performing some form of activity. This is of course what arises in software development, where the activities may involve using a particular test strategy to debug a block of code, or revising a design that was produced using a specific technique. The use of RCTs is clearly impractical for this type of study, since participants can hardly be unaware of which group they are in. Although experiments and quasi-experiments2 can sometimes be used to make comparisons, it may well be difficult to identify a suitable form of activity for the control group. So in order to study such activities we often end up using observational forms of study. (The study of designer behaviour by Adelson & Soloway (1985) described in Chapter 4 is an example of an observational study.)

An RCT compares the effects experienced by two groups
Since everyone taking part in such a study comes along with their own experience and opinions, together with their natural ability, it can be expected that there will again be significant variation in the values for any outcome measurements of the way that the participants react to the intervention (or its absence), such as the time to complete a task, or the sort of ‘solutions’ produced. Again though, measurement of what appears to be a relatively simple choice of dependent variable (the time to complete a task) can be confounded by the ill-structured nature of such tasks, since it may well be difficult to define exactly what constitutes ‘completion’.

When we do perform some form of experimental study, we often plot the results using something like the box plot illustrated in Figure 5.1. This shows both the distribution of the results, as well as such aspects as ‘skew’ (where results are biased to the positive or negative side). And although it appears that, with a few exceptions, most people perform the task more quickly using the experimental tool, the task of determining whether this means that we are seeing a real effect or not still has to depend upon a statistical analysis.
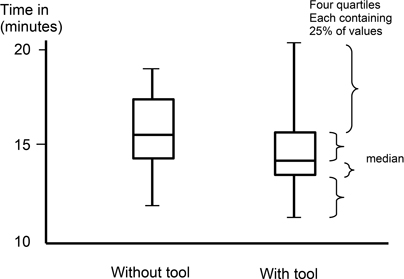
Figure 5.1: Using a boxplot to summarise the outcomes of a study
Why do we need to know about these things in a book about software design? Well, firstly to understand that conducting empirical studies that investigate design activity are by no means simple to perform. nor are the properties that we are interested in necessarily easy to measure. Secondly, to appreciate that the naturally-occurring variations that arise in the measured values will mean that any findings from such studies are unlikely to be clear-cut. That isn't to say that there won't be any useful findings, but rather that the findings will be subject to some sort of ‘confidence’ assessment, based upon the extent to which those conducting the study can be sure that the effects that they have observed stem from the ‘treatment’ employed in the study, and not from other confounding factors that are not controlled by the investigators.
5.2Empirical studies in software engineering
When software engineering first emerged as a distinct sub-discipline of computing, empirical knowledge was largely acquired from experiences gained during the creation of software applications ‘in the field’, and was codified by identifying those practices that seemed to work well. This was assisted by the way that many software applications used a limited set of architectural forms for their implementation. Writing down guidelines so that others could benefit from these experiences was therefore unquestionably useful, but such experience reports did lack rigour and might fail to record and report all of the relevant factors.
Through the 1990s, there was a growing interest in performing more rigorous empirical studies to investigate how software engineers performed a range of tasks. Much of this was concerned with trying to understand how they acquired and used the knowledge needed to underpin their activities and decisions. This might seem strange, as the obvious comment is “didn't they know that”. However, as noted in the previous chapter, expert decision-making draws upon many forms of knowledge, much of which may be tacit, to the point where an expert cannot explain the exact reasons for making a particular choice.
5.2.1The empirical spectrum
Empirical studies take a wide range of forms. However, for our purpose we can identify two important groups of studies as follows.
Studies of individuals that try to elicit the basis on which an individual makes decisions (that is, why they make them as they do). Primarily these are qualitative studies that involve making detailed observations, and are usually conducted with a small number of experts as the participants. Analysis of qualitative studies is likely to involve categorisation, narrative reporting, and interpretation of what the participants say. Such studies are also likely to be field studies in which any observations are made in the workplace when the participants are working normally.
Comparisons between groups of participants where the members of a group have (preferably) similar levels of expertise, possibly for the purpose of comparing expert and novice behaviours. Often these are quantitative studies, drawing upon the positivist assumption that many individuals will behave in a similar manner when faced with a particular problem. Data collection will involve some form of counting and analysis is likely to employ statistical techniques. Quantitative studies are likely to be more concerned with what is done than with why it is done. Such studies are more likely to take place in the laboratory, where conditions can be controlled. However, this does introduce an artificial element to the context, and usually limits the duration of a study.
Empirical software engineering draws upon various other disciplines for its research practices, adapting them as necessary (Kitchenham et al. 2015). In this section, we focus upon those characteristics that will help us understand what the outcomes from different studies might mean.
5.2.2The research protocol
Empirical studies in software engineering are commonly human-centric, studying how software developers undertake the various activities involved in creating and updating software systems. An important role in this type of study is that of the observer, who is often called upon to make interpretations of what they observe, not least because participants do not always behave quite as anticipated.
One of the hazards of such interpretations is that, since the observer will be aware of what the study is investigating, they may be unconsciously biased or influenced by this when making their interpretations. To help avoid, or at least reduce, the degree of any resulting bias, it is common practice to develop a comprehensive plan for conducting and analysing an empirical study, which is known as the research protocol.
The research protocol may well be quite a substantial and detailed document, but inevitably it may still not anticipate every situation. For example, when faced with a particular choice as part of a study, the protocol might expect that participants will usually make one of three fairly obvious choices, and so the task of the analyst will be to determine how to categorise each participant's actions against these. However, when the study is performed, it may well be that a small number of participants make another, and significantly different, choice. In that case, the research team may agree to create a fourth category for purposes of analysis, and this decision is then recorded and reported as a deviation from the protocol. Deviations may occur for all sorts of reasons, including errors that the experimenters make in conducting the study, but may also occur as a result of encountering unanticipated participant actions.
So the purpose of the research protocol is to help ensure that the study is conducted rigorously, and that in analysing the results, the experimenters do not ‘fish’ for interesting results.
5.2.3Qualitative studies
Qualitative studies are apt to be observational in their nature and concentrate upon gaining insight into the reasoning that lies behind the activities of an individual designer. Here we provide two examples of the ways that such studies might be conducted (they are by no means the only ones).
Interviews. One way of finding out what designers think about what they do (and why they do it that way) is to talk with them. An interview lets the researcher probe into issues that look promising, but equally it needs to be kept under control. A commonly-used procedure for organising this is the semi-structured interview, in which the interviewer has a set of questions developed in advance, but can deviate from these to pursue issues that arise, as and when necessary.
Think-aloud. This is really one element in the technique known as Protocol Analysis developed for knowledge elicitation in psychological studies (Ericsson & Simon 1993). It involves asking the participant to undertake some task and to describe their thinking verbally as they perform it (think-aloud). A transcript of their verbal ‘utterances’ is then analysed, those utterances that are not directly relevant to the task are discarded, and a model is developed around the others. In practice, think-aloud is by no means easy to perform (among other problems, participants tend to ‘dry up’ when they are concentrating), but it can provide valuable insight into the basis for their actions, including identifying where this involves the use of tacit knowledge (Owen, Budgen & Brereton 2006).
A challenge when conducting qualitative studies is to be able to analyse the outcomes in as rigorous and unbiased a manner as possible, particularly since an element of human interpretation is usually required. To help reduce the risk of bias, good practice involves using more than one person to analyse the data, with the analysts working independently and then checking for consistency of interpretation between them. And of course, the analysis should be planned in advance as part of the research protocol.
We will examine a number of outcomes derived from such studies as we progress through the following chapters, and some of the studies described in the previous chapter such as (Curtis et al. 1988) employed qualitative forms.
Qualitative studies tend to use ordinal or ‘ranking’ forms of measurement scale. So, when making measurements, the observer (or participants) will typically rank (say) issues or preferences in terms of their perceived importance, with no sense that the elements are equally spaced.
5.2.4Quantitative studies
Because quantitative studies are more likely to be laboratory-based and use statistical techniques for analysis, they usually need larger numbers of participants than qualitative studies, in order to provide an appropriate level of confidence in the results. Two of the more widely-used tools of quantitative studies are experiments (and quasi-experiments), and surveys.
Experiments and quasi-experiments take a range of forms, but are usually comparative in form. The purpose is to test a hypothesis and to establish where this is true or not. More precisely, the aim is to establish whether the hypothesis or the alternate hypothesis is true. For example, a hypothesis to be tested might be that design models created by using the observer design pattern (described in Chapter 15) will produce larger classes than those that do not use patterns. The alternate (or null) hypothesis will then be that there will be no differences in terms of the sizes of class involved.
Experiments are similar to RCTs, but less rigorous, because the participants cannot be blinded about their role. Most experiments performed on software engineering topics are actually quasi-experiments. This is because participants can rarely be randomly assigned to groups, as this is often done on the basis of experience (Sjøberg, Hannay, Hansen, Kampenes, Karahasanovic, Liborg & Rekdal 2005).
As an example, an experiment may be used to investigate whether inexperienced developers can make specific modifications to code more easily when the code has been structured using a particular design pattern. To reduce any bias that might arise from the choice of the experimental material, each participant may be asked to make changes to several different pieces of code, although this then complicates the analysis!
Surveys provide what may be a more familiar tool. However, it can be difficult to recruit enough participants who have relevant expertise. For example, if a survey seeks to ask participants who have appropriate expertise with object-oriented design to rank a set of different object inheritance notations, then recruiting a sufficiently large set of participants who have the time and inclination to do this will be difficult, as will determining just what comprises ‘sufficient expertise’. As a result, the design and conduct of a survey can be just as challenging as designing an experiment (Fink 2003, Zhang & Budgen 2013).
As indicated in the previous section, there are many factors that may influence individual choices and decisions, and when studying software design, one limitation with using quantitative forms is that they provide little explanation of why particular decisions are made. Their positivist nature also assumes that a degree of commonality in reasoning lies behind the particular decisions made by the participants, which in many ways conflicts with the whole ethos of designing something being considered as an exercise in individual skill.

Quantitative studies usually employ ‘counting’ forms of measurement scale (ratio measurements). In the example of a survey given above, this might involve counting how many times each notation appeared as the top choice for a participant.
5.2.5Case studies
In recent years, the case study, long regarded as a major research tool for the social sciences, has become more widely used in software engineering (Runeson, Höst, Rainer & Regnell 2012, Budgen, Brereton, Williams & Drummond 2018). However, the term is sometimes used by authors in a rather informal way, so some care is needed to determine the degree of rigour involved in an individual case study.
A case study can be viewed as a structured form of observational study. When conducting an experiment the researcher aims to get many repeated measures of the same property. For example, the amount of time participants need to complete a design task when using a particular strategy. Since we can expect that this will vary considerably for different people, we need to measure the time for many participants. In contrast, a case study seeks to measure many different variables related to a particular ‘case’, which might be a software development project, and then to triangulate the knowledge provided by the different measures to see how well they provide mutual reinforcement about some particular characteristic.

Triangulation aggregates different measures
While many social scientists consider case studies to be an interpretivist form of study, with any findings only applying to that particular case, others do consider that the findings of different case studies may be combined, so providing a positivist interpretation. Robert K Yin has been a major proponent of the positivist approach to case study research, and the use of case studies in software engineering has largely been based upon his work (Yin 2014).
Yin suggests that case studies can be particularly useful when addressing three types of research question, as described below.
An explanatory case study is concerned with examining how something works or is performed, and identifying any conditions that determine why it is successful or otherwise.
A descriptive case study is more concerned with performing a detailed observation of the case and therefore “providing a rich and detailed analysis of a phenomenon and its context”. Essentially it is concerned with identifying what occurs.
An exploratory case study forms a preliminary investigation of some effect, laying the groundwork for a later (fuller) study of some form.
Case studies can use a mix of qualitative and quantitative data, and both explanatory and descriptive case studies may usefully make use of one or more propositions that direct attention to some aspect that should be investigated. Propositions can be considered to be a less formal equivalent to the hypothesis used to pose the research question for an experiment.
Case studies are a particularly useful way to conduct field studies that involve experienced industrial practitioners working in their own environment, rather that in a laboratory context (as occurs with experiments). Their use overcomes the practical difficulty involved in having enough practitioners available to perform an experiment, and makes it possible to conduct larger scale investigations, often over a relatively long period of time (‘longitudinal’ studies). An analysis of the ‘primary’ studies used in a set of systematic reviews in software engineering over the period 2004-2015, suggests that many of these can be classified as case studies (Budgen, Brereton, Williams & Drummond 2018), although many authors did not give a clear definition for exactly what they classified as being a case study.
5.3Systematic reviews
The forms of study described so far are all examples of what we term primary studies. Primary studies directly study the issue of interest in a particular context. This section examines the use of systematic reviews, sometimes termed systematic literature reviews, which are a form of secondary study that seeks to locate all of the ‘primary studies’ that are relevant to its research question and then aggregates and synthesises their results in order to provide a more comprehensive answer to that question.

A systematic review synthesises the findings of many primary studies
Systematic reviews provide an increasingly important source of knowledge about software engineering practices. The concept of the systematic review was originally developed in the domain of clinical medicine, where it forms a major source of clinical knowledge for a wide range of healthcare interventions and the basis for what is termed Evidence-Based Medicine (EBM). They have since been adopted and adapted for a whole range of other disciplines, including Evidence-Based Software Engineering (EBSE) (Kitchenham et al. 2015).
The procedures followed in performing a systematic review are intended to reduce the variation in the outcomes and produce findings that are less susceptible to bias than those from individual studies. The ‘systematic’ aspect is especially important when planning and performing such a review (and like all empirical studies, a systematic review requires a detailed research protocol).
Two elements where the systematic aspect plays a major role are in the process of searching for primary studies, and also when performing the activity of inclusion/exclusion that determines which primary studies will be included in the review on the basis of their relevance and quality. Performing these tasks systematically helps to overcome one of the problems of ‘expert reviews’, in which an expert synthesises the primary studies that they think are relevant to a topic (which may well be those that agree with their opinions of course).
As might be expected, there are differences between the use of systematic reviews in software engineering and their role in clinical studies. The use of RCTs for clinical studies, and the role of participants in these as recipients of a treatment, make it possible to use statistical techniques such as meta-analysis to synthesise the outcomes of multiple studies. This strengthens the confidence that can be placed in the findings of a systematic review. In software engineering, systematic reviews often have to use rather weaker forms of synthesis to combine a range of primary study forms (Budgen, Brereton, Drummond & Williams 2018), making the findings correspondingly less authoritative.
When used in software engineering, systematic reviews can involve synthesising both quantitative and qualitative forms of primary study. When used to synthesise quantitative studies, they may be employed in a role that is somewhat closer to how they are used in clinical medicine, being used to address research questions that are comparative in form (such as ‘does use of treatment A result in fewer errors per object than the use of treatment B?’). Whereas systematic reviews that involve synthesising qualitative studies tend to address more open research questions such as ‘what are the problems encountered in adopting practice X within a company?’.
In clinical medicine, education, and other disciplines that employ systematic reviews, these are apt to be commissioned by government departments, health agencies and the like, to help provide advice about practice and policy. However, in software engineering they have so far largely been driven by the interests of researchers. One consequence is that they are less likely to provide findings that are relevant to, and directly usable by, practitioners. A study seeking reviews with outcomes that were useful for teaching and practice found only 49 systematic reviews published up to the end of 2015 that had ‘usable’ findings, from 276 reviews that were analysed. (Most systematic reviews were concerned with analysing research trends rather than practice.) However, as the use of systematic reviews in software engineering matures, this should begin to change (Budgen, Brereton, Williams & Drummond 2020).
The important thing about empirical studies in general, and systematic reviews in particular, is that not only can they provide more rigorously derived empirical knowledge about software engineering practices, they can also help would-be adopters of these practices to assess how useful the practices may be to them.
5.4Using empirical knowledge
Each of the chapters following this one has a short section discussing the available empirical evidence related to the topic of the chapter. (Well, Chapter 18 doesn't, but there is a discussion in each section instead!) Most of this evidence comes from the findings of systematic reviews.
Where a systematic review performed in software engineering provides findings that can be used to advise practice, the empirical knowledge derived from its findings is often presented in one of three forms (or a combination of these).
Knowledge that has been derived from the experiences of others, usually in the form of ‘lessons’ related to what works (or doesn't) when doing something. A good example of this is the benefits of reuse in industry studies by Mohagheghi & Conradi (2007).
A list of factors to consider when using some practice (a more structured form of experience). Again, a good illustration of this is the study of pair programming in agile development by Hannay, Dybå, Arisholm & Sjøberg (2009).
Ranking of knowledge about different options to help with making choices between them. The study of aspect-oriented programming by Ali, Babar, Chen & Stol (2010) provides an example of this form of knowledge classification.
All three forms are relevant to studies of design, as demonstrated by the examples, although systematic reviews that explicitly address design topics are still relatively uncommon. There may be several reasons for this, but one is certainly the shortage of primary studies (Zhang & Budgen 2012). However, it is worth noting that many practically-oriented systematic reviews in software engineering do tend to make the most of the available material synthesising the findings from a variety of forms of primary study, including case studies.
An interesting analysis of the use of evidence in another discipline (management research) by Joan van Aken (2004) makes a useful distinction between the ways that research knowledge is used in different disciplines.
Description-driven research is commonly used in the ‘explanatory’ sciences, such as the natural sciences, for which the purpose is to “describe, explain and possibly predict observable phenomena within its field”.
Design sciences research such as performed in engineering, medical science and other health-related disciplines, for which the purpose is to “develop valid and reliable knowledge to be used in designing solutions to problems”.
So, where does the use of systematic reviews in software engineering research fit into these categories? Well, researchers would probably view their use as performing a form of description-driven research, while practitioners would probably prefer to be provided with findings from design sciences research. For the purpose of this book, it is definitely the latter group that is of interest.
Of the 276 systematic reviews analysed in Budgen et al. (2020), the bulk, described earlier as being focused on studying research trends, really fit into the first category and can be considered as largely description-driven research. The 49 that were considered to have findings relevant to teaching and practice probably mostly fit into the second category of design sciences research, in the sense that they provide some guidance for problem-solving. And as new studies emerge there should be a growing corpus of useful guidance derived from empirical knowledge.

Key take-home points about empirical knowledge
This chapter has introduced concepts about measurement and empirical studies that are important when seeking to understand the nature and form of design knowledge that can be obtained through the use of empirical research.
Variation is to be expected in the measurements that are obtained when performing the sort of human-centric studies used to answer questions about software engineering and its practice. This variation is natural, and arises because each participant draws upon individual experience and different levels of expertise when performing the experimental tasks.
Empirical studies of software design activities are challenging to perform, and so any findings should be associated with some level of ‘confidence’, based on the procedures followed in conducting the study.
The research protocol is an essential element when undertaking a rigorous empirical study. The protocol should incorporate plans for performing the study and analysing the results, and should be produced in advance of undertaking the study.
Both quantitative and qualitative studies have value for research into software design issues. They respectively address questions related to what occurs and why something occurs.
The use of systematic reviews can help overcome the effects of bias that can arise in the findings of individual ‘primary’ studies and hence can provide the most reliable sources of evidence for making design decisions or selecting a design strategy. The empirical knowledge provided by such evidence can be presented for use in a number of ways, including: summary of experience; lists of factors to consider; and comparative ranking of techniques.