Chapter 6
Software Architecture
The idea that a software application might have an architecture has become an important concept in thinking about how applications are composed, and how their operations are organised. As in other domains, its value largely stems from providing a highly abstract and readily visualised perspective on how something is organised and structured, whether it be a building, a ship, or a software application. And the idea of architecture also captures more than the way something is constructed. It also embodies ideas about how it functions (think of how ‘tanker’, ‘car ferry’ relate to a combination of different forms and functions when considering naval architecture).
So, architecture turns out to be a versatile concept: we can describe an application as having ‘an architecture’; use ideas about ‘architectural style’ to categorise architectures; and employ ‘architectural patterns’ when designing an application. These facets are all explored in the rest of this chapter, but first we look a bit more closely at what we mean by the concept itself.
6.1What architecture provides for us
When software applications consisted of programs executed on isolated computers (the ‘pre-internet era’), there was little need for the concept of architecture. Software was largely developed using imperative programming languages (Algol, COBOL, FORTRAN etc.) which used broadly similar structures. Certainly, there were different ways that an application could be organised. It might be structured as a single process with a ‘main’ program invoking sub-programs; or as a database, organised around tables of data; and it might be organised as a sequence of connected processes (through such mechanisms as the Unix ‘pipe’ that provided data-streams for this purpose). An application might even run as a set of concurrent processes interacting across a small local network of computers that shared a common area of memory. But only a limited vocabulary was needed for describing these distinctions.
Various influences played a part in subsequently extending the options available to the software developer. Some arose from developments in implementation technology (objects, services), while others were concerned with the way that the internet introduced new ways for an application to interact with the world. And as these combined and proliferated, so too did the range of forms that software could take, and hence the need to codify the role of ‘architecture’—recognised in the pioneering work of Shaw & Garlan (1996).
Software components interact in many different ways (invocation, uses, inheritance, data transfer etc.). All of these interactions create dependencies or coupling between the components, and this remains as important a concept now as it was when first identified—not least because the range of forms it can take has expanded.
The implication of concepts such as coupling and that of separation of concerns, is that we should seek to make the major parts of our application as independent of one another as possible, both when considering functionality and also information. And it is in finding ways to provide such independence that the choice of an architecture plays a useful role. When designing the architecture of an application we need to devise ways of keeping coupling to a minimum, and the manner in which this should be organised should obviously depend upon the task that is to be performed by the application. So, the way that (say) the components of a compiler are organised, will need to be quite different to the way that we might organise the components of a word processor, or those of an on-line multi-user game.
Other factors may also influence the specific choice of architectural form for an application. One of the earliest discussions of the benefits of thinking of the organisation of an application in terms of architecture was provided in Garlan & Perry (1995). Introducing a collection of papers on software architecture, they described many of the key issues lucidly and concisely. In particular, they argued that the concept of architecture can have a positive impact upon each of the following aspects of software development.
Understanding. Architectural concepts provide a vocabulary that can aid our understanding of an application's high-level design (model).
Reuse. The cost of developing software encourages the reuse of existing code (and designs) wherever possible, and the high-level components comprising a system architecture may assist with identifying where there is scope for reuse.
Evolution. When designing a software application, we need to consider how it might evolve, and facilitate future changes by allocating the elements that we think most likely to change into distinct sub-systems. Doing so also provides a guide for anyone who may later need to change the design of the application—ensuring that any changes conform to the architecture should help retain the overall integrity of the application.
Analysis. The architecture can help with checking for consistency across different characteristics of a design.
Management. Anticipating how an application may evolve is (or should be) a factor in determining its architectural form. Implicitly, making a poor choice can create a technical debt that will constrain future evolution.
The last point captures an important aspect of architecture. For any application, the choice of its architecture is an important and early decision, influencing the later design stages as well as implementation. And not only is this decision made at an early stage in development, it is also one that is difficult to change significantly at a later time since the choice of architecture underpins so many aspects. So thinking about how a system will evolve might be something that is difficult to do, but it is something that is vitally important and that needs to occur right at the outset of the design process (van Vliet & Tang 2016).
Thus far we have confined discussion of architecture mostly to some fairly abstract ideas of what an architecture is and what influence it has. The next step is to consider how we might describe the form of an architecture, and that requires that we employ the idea of an architectural style.
6.2Architectural style
The concept of architectural style is both useful and something that is familiar from other domains. When we describe a building to someone else, we might refer to it as being in a ‘Tudor style’ or a ‘1960s style’. For buildings, descriptions of their style may also be related to the materials used in their construction. So, although we often use such a temporal label to describe a style (and implicitly the materials used in their construction), we also use terms like ‘New England’ or ‘Steel Frame’, reflecting the way that the form of buildings has tended to evolve as new materials for their construction came into use. And as already noted above, in the context of ‘naval architecture’ we tend to use labels that relate to function, such as ‘oil tanker’, ‘car ferry’ etc. For both buildings and ships, the use of such a label gives us an idea of the characteristics that a particular building or ship might have.
For software, the concept of architectural style can similarly be viewed as providing a very abstract description of a set of general characteristics related to the form of an application. When provided with such a description, we will then know something about the general form this has, although there may still be great variation of detail. More specifically, and a point that we will return to, is that this will also tell us something about what might be involved in modifying the resulting application in the future.
For software the sort of label we use may relate to the way that the application is intended to operate. So we might refer to styles using terms such as ‘client-server’ or ‘pipeline’. However, such labels are not a very systematic way of classifying architectural styles, although very useful for easy reference. And as it became realised that the idea of an application's architecture was useful, so ideas emerged about how best to describe and classify this.
In Perry & Wolf (1992), the authors proposed a classification scheme based on the following characteristics:
They categorised elements as being concerned with processing, data or connections, and form as a ‘set of weighted properties and relationships’, while rationale recorded the motivation for particular choices.
The influential book by Shaw & Garlan (1996), that helped to consolidate the idea of architecture and its importance, adopted a rather simpler approach to classification, employing a basic framework based solely upon components and connectors.
A rather more detailed scheme was used in (Shaw & Clements 1997). This categorised architectural style in terms of the following major features.
the kinds of components and connectors used in the style (for example, objects and method calls);
the ways in which control (of execution) is shared, allocated and transferred among the components;
how data is communicated through the system;
how data and control interact;
the type of (design) reasoning that is compatible with the style.
The features described in the last four bullets can be considered as forming the ‘context’ in which an application will execute, and so we can then categorise architectural styles in terms of:
It is also worth noting that while researchers have sought to formalise the description of architectural style using ‘architecture description languages’ (ADLs), this does not seem to have led to anything that is widely used (Ozkaya 2017). Indeed, architectural concepts tend to be rather abstract as well as very diverse, and hence are probably not really easily described using formal notations.
As indicated earlier, applications created in the 1970s and 1980s were usually organised in a self-contained ‘monolithic’ form, with all of the elements residing on the same computer, and having a form such as call-and-return or data-centred-repository. With the advent of the internet in the 1990s new forms evolved (such as client-server), exploiting the ability to distribute the elements of an application. The later evolution of the cloud, and related ideas about services has added further to the choices available to the designer.
Because architectural concepts are relatively abstract, the vocabulary associated with them lacks precision—one of the factors motivating the categorisation process provided in early works such as (Shaw & Garlan 1996).
Table 6.1 summarises the major categories of architectural style identified in (Shaw & Clements 1997). Perhaps not surprisingly, these largely relate to ‘monolithic’ forms of application construction—distributed forms can be hard to classify—and many categories do encompass a variety of styles.
Category |
Characteristics |
Examples of Styles |
|---|---|---|
Data-flow |
Motion of data, with no ‘upstream content control’ by the recipient |
batch sequential; pipe-and-filter |
Call-and-return |
Order of computation with a single thread of control |
main program/sub-programs; ‘classical’ objects |
Interacting-processes |
Communication among independent, concurrent processes |
communicating processes; distributed objects |
Data-centred repository |
Complex central data store |
transactional databases; client-server; blackboard |
Data-sharing |
Direct sharing of data among components |
hypertext; lightweight threads |
One caveat emphasised by Shaw & Clements (1997) and one that we should note, is that applications are not necessarily ‘pure’ in terms of their style and so may possess the characteristics of more than one style. And of course, if a system is classified as being a ‘hybrid’, that doesn't reduce the value of the classification process, indeed it may even render it more important.
Bass, Clements & Kazman (2013) describe how thinking about architecture has subsequently evolved. Many of the original ideas are still there, but they are apt to be expressed differently. Rather than categorising styles in terms of their elements and the connections between them, they argue that architecture should be viewed in terms of three different structures, which in turn relate to different sets of decisions that occur during the process of design.
Module structures consist of the blocks of code or data that will form the application, and relate to design decisions about how responsibility is allocated, the ways that the modules depend upon each other (the forms of coupling), and the use of external modules.
Component-and-connector structures are more concerned with how the application will behave when it executes and how the different elements will interact during execution. Whereas module structures are essentially static, these are concerned with system execution.
Allocation structures are concerned with where different modules will reside, and from where external resources will be sourced.
While this can be simplified to a model of ‘component-connector-context’ it goes much further and relates much more closely to the decision-making processes involved in architectural design.
To help illustrate the concepts involved, we now look briefly at the forms of three widely used architectural styles. Other styles such as object-oriented and service-oriented architecture will be discussed in later chapters, and these examples have been chosen simply to illustrate the variety that can occur.
6.2.1Pipe-and-filter architectural style
An application based upon this style is one in which a sequence of transformations are performed upon data, typically by a series of processes. Each process performs its allocated task and then passes the data on to the next one. As a style it emphasises separation of concerns, where the concerns are provided by the transformations embodied in the individual processes. It is organised around flow of data. Table 6.2 summarises the main characteristics of the style using the classification scheme from (Shaw & Clements 1997).
Feature |
Instantiation in pipe-and-filter |
|---|---|
Components |
Data transformation processes. |
Connectors |
Data transfer mechanisms (e.g. Unix pipes, files etc.). |
Control of execution |
Typically asynchronous. Control is transferred by the arrival of data at the input to a process. |
Data communication |
Data is generally passed with control. |
Control/data interaction |
Control and data generally share the same topology and control is achieved through the activity of transferring data. |
Design reasoning |
Tends to employ a bottom-up approach based upon function due to the emphasis placed upon the filters (components). Fits well with incremental development forms. |
Figure 6.1 illustrates the use of the Unix ‘pipe’ mechanism, introduced in the early 1970s, to provide an example of an application that uses this style. The pipes provide data streams linking the ‘standard output’ and ‘standard input’ of successive processes (the ‘filters’), labelled as P1, P2 and P3 in the figure. An example of the type of application well-suited to this style is a simple compiler, in which a succession of operations gradually transforms the data stream from input text to output code. So here, P1 might be a lexical analyser, used to separate the ‘tokens’ in the input program; P2 could be a syntactic checker, ensuring that the tokens obeyed the syntax rules for the language; and P3 might perform a semantic analysis of the stream of tokens, leading on to further processes to generate and optimise code.

Figure 6.1: Unix pipe and filter using three processes: P1 | P2 | P3
As an architectural style this is more versatile than the example might imply and is well suited for use with data-driven operations. Data transfer does not necessarily have to be asynchronous, and the topology is not confined to linear sequences of processes. It also provides scope for strong separation of concerns as far as processing is concerned, since each process usually occupies its own unique address space with no shared data. (However, knowledge about the form(s) of the data does need to be shared.) There is also ready scope for reuse of processes, because of the strong decoupling. It is also well suited to a development approach based on prototyping, and offering scope to perform this incrementally, with each process being developed and integrated in turn.
6.2.2Call-and-return architectural style
This architectural style is one that closely mirrors the way that the underlying computer operates, using an ordered and hierarchical transfer of control between different processing tasks. Again it is based upon a philosophy of separation of concerns, but unlike pipe-and-filter, the main emphasis lies upon the transfer of control between processing activities, rather than transfer of data, and so the ‘concerns’ being partitioned are essentially those related to function. Imperative programming languages (such as Pascal, C. and many others) provide structures that implement this form, whereby a ‘main’ program element transfers control to a network of sub-programs. Typically, sub-programs either access data through the passing of parameters (arguments) or through the use of static global variables that are visible to all sub-programs. Object-oriented languages such as Java often use this as an underpinning mechanism, and so can also be used to write software in this style.
Figure 6.2 shows a simple illustration of an application structured in this style, with a main program unit (which sequences the calls to the sub-programs), and a hierarchical set of sub-programs that perform the tasks. Here the arrows indicate transfer of control by a conventional sub-program invocation mechanism, and further annotation can be used to show transfer of data via sub-program parameters.
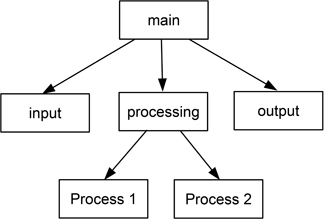
Figure 6.2: Call and return using a main program and sub-programs
Table 6.3 summarises the main characteristics of this architectural style. While this is a simple and convenient form to employ for constructing monolithic applications, and likely to produce efficient code because of the way that it ‘mirrors’ the underlying computer mechanisms, it provides limited scope for reuse beyond employing a ‘library’ of sub-programs. However, it is quite versatile and widely employed—for example, it could be used to structure the internal forms of the processes used in Figure 6.1.
Feature |
Instantiation in call-and-return |
|---|---|
Components |
Sub-program units. |
Connectors |
Invocation of sub-programs. |
Control of execution |
Sequencing of calls is organised by the algorithms in the components that form the invocation hierarchy. |
Data communication |
Data can be passed through parameters and may also be shared using a global storage mechanism (variables declared in the main component). |
Control/data interaction |
This is largely limited to the passing of parameters and the return of data through function calls. |
Design reasoning |
Because the ‘concerns’ (functions) are sub-divided, it is usually associated with top-down thinking. Many traditional plan-driven design approaches produce design models that have this form. Use of global data structures can constrain the effective separation of concerns. |
6.2.3Data-centred repository architectural style
This style encompasses those applications for which the key element is some central mechanism that is used for the persistent storage of information (not necessarily a database management system), so that the information can then be manipulated by a set of external processing units. So for this architectural style, the ‘concerns’ are related to data and its use. However, it also offers scope to provide an element of information hiding regarding the way that the information is actually stored.
Obvious examples of applications in this category are database systems and blackboard-style expert systems (here the blackboard itself provides the central mechanism). Shaw & Clements (1997) argue that client-server systems also come into this general category, on the basis that the server acts as a central repository, and may well include a database. Figure 6.3 provides an illustration of the general form of a client-server system (whether the server is ‘local’ or in the cloud is not important, since it is the role that matters).
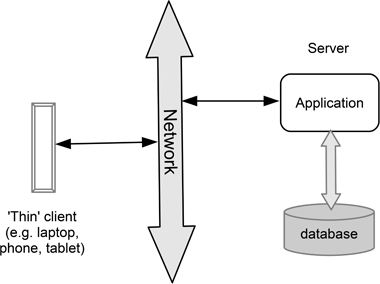
Figure 6.3: Data-centred repository: a simple client-server model
When the repository is an actual database, the central mechanism is likely to be concerned with providing one or more forms of indexed access to a potentially large volume of data. Blackboard systems and object-oriented databases can provide a less highly structured form of repository, which may well be used to acquire, aggregate, and record a variety of forms of ‘knowledge’. Table 6.4 summarises the characteristics of this architectural style.
Feature |
Instantiation in data-centred repository |
|---|---|
Components |
Storage mechanisms and processing units. |
Connectors |
Transactions, queries, direct access (blackboard). |
Control of execution |
Operations are usually asynchronous and may also occur in parallel. |
Data communication |
Data is usually passed through some form of parameter mechanism. |
Control/data interaction |
This varies quite widely. For a database or a client-server system, these may be highly synchronised, whereas in the case of blackboard there may be little or no interaction. |
Design reasoning |
The strong focus on data usually means that modelling the data is an important element. The variety of forms such systems take tends to mean that design logic may also vary extensively. |
6.3Architectural patterns
The concept of using some form of abstract ‘pattern’ to transfer knowledge about useful design models that could be used to ‘solve’ issues that are repeatedly encountered across a range of applications emerged in the 1990s, and has been realised in a number of ways. It has been widely adopted for use in object-oriented software development, as a means of describing solutions to recurring challenges that might face the designer (Gamma, Helm, Johnson & Vlissides 1995), usually involving particular parts of a system or application. It has also been suggested that patterns could be adapted to perform a similar role in the design of service-oriented applications (Erl 2009). We will discuss the pattern concept in much more detail in Chapter 15, but in this section we discuss how the concept can be used to describe the overall form of a system, by making use of architectural design patterns, a concept proposed by Buschmann, Meunier, Rohnert, Sommerlad & Stal (1996).
The idea of using patterns to help with transferring knowledge about design ‘solutions’ is rooted in the work of the architect Christopher Alexander (Alexander, Ishikawa, Silverstein, Jacobson, Fiksdahl-King & Angel 1977), and has been described by him in the following words.
Essentially, a pattern provides a generic description of, and ‘solution’ to, a problem, and being generic, it will always need to be instantiated in a way that addresses the specific situation that the designer is actually facing. (This fits in with the concept of ‘design as adaptation’ introduced in Chapter 1 and Figure 1.2.)
Couched in terms of knowledge transfer, a pattern identifies a particular design problem that might be encountered, together with a strategy for addressing that problem. We also expect that the description of a pattern will identify some possible consequences of adopting the pattern, since the choice of whether or not to use a pattern may well involve making trade-offs between different aspects of the design model.
In some ways using patterns has similarities to the sort of learning involved in the traditional master/apprentice relationship. Learning about patterns involves learning about possible problems that a designer may face as well as about how these might be resolved—usually involving relatively manageable ‘chunks’ of knowledge. Patterns also have to be learned (an issue that we return to when considering the use of object-oriented design patterns). The idea of a pattern also fits well with some of the observed practices of designers, such as the notion of ‘labels for plans’ that was observed by Adelson & Soloway (1985), whereby a designer would note the presence of a sub-problem for which they already had a solution strategy, (again, reflecting the idea of designing by adaptation).
At the architectural level of software design the pattern concept is used slightly differently. Here, patterns offer models for the general structure that the application should take, rather than for a part of the design solution. The ideas involved in architectural patterns do overlap with architectural styles to some degree—some patterns can be realised using a variety of styles, whereas others are implicitly linked to the idea of using a particular type of design element (the most obvious example of such an overlap is that of ‘pipes-and-filters’ which is essentially a pattern that can be employed with processes).
Architectural patterns provide different ways of ‘separating the concerns’ for an application, aiming to organise its structure so that future changes can be made with a minimum impact from any side-effects. However, to do so successfully does implicitly assume that the designer (system architect) is able to envisage the ways in which the application may later evolve—and a possible risk is that the architectural pattern adopted may not be well suited to what actually does happen. So, while patterns do offer benefits, the adoption of any architectural pattern, like the adoption of an architectural style, does create the potential for generating technical debt.
Table 6.5 summarises the roles provided by a selection of the patterns introduced in (Buschmann et al. 1996). In the rest of this section we examine two examples from this set in order to illustrate the idea more fully.
Pattern |
Description of Role |
|---|---|
Model-view-controller |
Provides a structure for decoupling the various elements of an interactive system. |
Layers |
Used where an application can be organised as a hierarchy of sub-tasks performed at different levels of abstraction. |
Pipes-and-filters |
For systems that process a stream of data (this is rather similar to the architectural style). |
Broker |
Used to structure the interaction of distributed systems with highly decoupled components, where the choice of components may be made ‘on the fly’ when the application executes. |
Reflection |
Intended to support dynamic adaptation of the structure for a system. |
6.3.1Model-view-controller (MVC)
This is a widely encountered pattern used to structure the sort of applications in which end-users will interact with some form of ‘data repository’, performing updates to the data and viewing different projections from it. As an example of where it could be used, it is well suited for use with applications which involve extensive user interaction with a dataset, such as a spreadsheet or word processor.
This pattern is motivated by the principle of separation of concerns, and is concerned with keeping the details of the model (the data repository) independent from the elements that need to interact with it, namely the views and controllers. Essentially the model is encapsulated in such a way that its details (and format) are not directly visible to the views and controllers (the link to designing with objects may be fairly obvious here, since both place emphasis upon information hiding through the encapsulation of data).
Figure 6.4 shows the idea of MVC in a rather abstract way. It is worth noting that a wide variety of such diagrams exist, often providing slightly different interpretations of the elements making up MVC and how they interact. The roles for the elements are as follows.
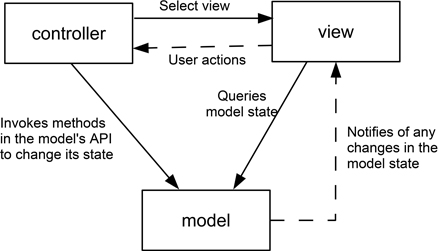
Figure 6.4: The MVC pattern
Model. This provides the core functionality of the application (that is, the operations performed upon the data) and the associated data.
View. Each view provides a different way of presenting knowledge about the model, obtained from the model, to the user.
Controller A controller handles user input, and each view is likely to have a distinct controller associated with it.
The views and controllers make up the user interface and are largely independent of the model, beyond sharing knowledge of the data types making up the model. The model may well also need to provide updates to the views and controllers when changes are made to it (or at least, provide them with information that an update is available). An important characteristic of this design structure is that it makes it possible to provide quite different ‘look and feel’ forms of interaction without a need to modify the model itself.
6.3.2Layers
Opportunities to employ the Layers pattern occur less commonly than those for using MVC. However, as an example, it illustrates a different way of thinking about how to organise the separation of concerns within the structure of an application, placing greater emphasis upon function.
This pattern structures an application by separating its functionality into different groups of operations, with each group performing its tasks at a different level of abstraction within a hierarchy. A classic illustration of this is the way that networking software is usually organised. Figure 6.5 shows a simple illustration of this for the OSI model, highlighting how each layer provides more abstract operations by performing its tasks by using operations from the layer beneath it.
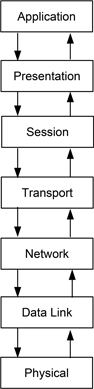
Figure 6.5: Layers pattern
As an example, when Layer 4 (Transport) splits a message into a series of packets, and ensures that these are delivered to the recipient, it does so by drawing upon the services of Layer 3 (Network), to organise the route(s) by which the packets are delivered.
The use of Layers makes it easy to isolate the effects that can arise from making changes at the lower levels. A simple example concerns a change in the underlying network form. To move from using (say) an ethernet implementation to using a slotted ring as the network medium only involves changes to the very lowest layers. The higher layers have no knowledge of the nature of the actual transport mechanism being used.
Many operating systems use a similar model (for example, Unix applications sit above the ‘shell’, which in turn makes use of the system layers below it). Again, a different interface can be provided by simply changing the shell, and hence a single computer can readily have a situation where different users are working with different interfaces, but are still able to share files and other resources when necessary.
While clearly Layers is a particularly useful pattern to use for ‘system’ software, in principle it is by no means restricted to such applications. However, it is likely that most designers will encounter this as a pattern that is already established for a software system, and their concern will be to develop applications that conform to it.
6.4Empirical knowledge about architecture
The nature of software architecture makes it difficult to perform empirical studies, since for each application, the choice of a suitable architecture is rather entwined with the unique nature of the application itself. Hence systematic reviews in this area are relatively uncommon, and those that are available, mainly look at the ‘robustness’ of architectures when changes need to be made.
An example of this is the systematic review by Williams & Carver (2010) that focused upon assessing the impact of proposed changes to a system's architecture. A further example is provided by Breivold, Crnkovic & Larsson (2012), that looks at the effect of architecture upon software evolution, and at the different approaches that have been proposed to help address this.
A somewhat different and interesting perspective is provided in the systematic review by Shahin, Liang & Babar (2014). This examines some of the forms used for visualising software architecture, as well as different elements (such as patterns), and the ways that these are used. They particularly observed that these were often used to help with different aspects of recovery of architectural knowledge about existing applications as well as to help with evolution.
Key take-home points about software architecture
The concept of software architecture offers a high-level perspective upon the way that a software application is structured and organised. Some key issues related to this include the following.
Separation of concerns. The major elements of a system will address different ‘concerns’ and choice of a suitable architecture will reduce the likelihood of side-effects arising from interactions between the elements as well as providing a way to reduce future technical debt.
Composition. The architecture of a system is concerned with how this is to be composed from a (possibly diverse) set of elements.
Vocabulary. Architectural concepts provide a useful vocabulary that can be used to aid understanding and discussion related to the high-level structure of an application. This may also help identify how it might evolve in the future as well as what scope there is to reuse elements.
Categorisation. A useful way to think of an architectural style is in terms of its components, the connectors that map the dependencies between the components, and the context that describes how the elements execute and relate to each other.
Architectural patterns. These describe some commonly used ways to organise the top-level form of an application.
Empirical knowledge. Such knowledge is mainly concerned with the interplay between the choice of an architecture and the ease of making changes to a system.