4 Speech Production and Phonological Development
In the last chapter we saw that as babies progress toward their first birthday they gradually unlearn the ability to distinguish all the possible human speech sounds and instead zero in on the ones that matter for their language—the phonemes. Even though the child’s linguistic knowledge is still growing during this phase, in another sense it is a period of pruning, or cutting back. Linguist Roman Jakobson described this transition by saying that “the phonetic richness of the babbling period … gives way to a phonological limitation.” That is, while very young infants can both produce and perceive a wide range of speech sounds, even those not found in the language they will acquire, by the time they begin to learn their first words, their sound system has shrunk. In some cases, in terms of early word production, this means that children fail to produce certain sounds in their language that they may have used in babbling just 6 months earlier. For example, sounds articulated at the back of the vocal tract, such as velar sounds ([k], [g]) can be found in early vocalizations but are rare in children’s first words (Stoel-Gammon, 1989).
In this chapter we’ll look at how this happens: how children’s phonological inventory takes shape, the kinds of phonological patterns and errors we see, and how we can explain those patterns and errors by writing phonological rules or by ordering universal constraints.
4.1 When Are Vocalizations Part of Language?
Just as we considered in the previous chapter the question of when language perception starts, here we can ask when language production begins. When a newborn produces all manner of cries and coos and vocalizations, are these part of language? Probably not. So when is a baby’s sound production really a linguistic sound? It turns out we can distinguish two kinds of vocalizations within the first year of life. The very earliest vocalizations are unstructured and include a wide array of types of sounds: gurgles, coos, clicks, and so forth. The infant’s vocal tract within the first 3 months of life is actually quite different from an adult’s: as shown in figure 4.1, the infant’s larynx is high up in the throat, which allows the baby to drink and breathe at the same time and shortens the pharyngeal cavity (the space between the larynx and the epiglottis). The infant’s tongue is proportionally larger in the mouth than an older child’s or an adult’s. Moreover, infants’ fine motor control abilities, necessary for phonetic articulation, are not quite developed until later (around 7 to 10 months). The vocalizations produced at this early stage are sometimes called simply “phonation” (Oller, 1978, 1980) or “vegetative sounds” (Stark, 1980).
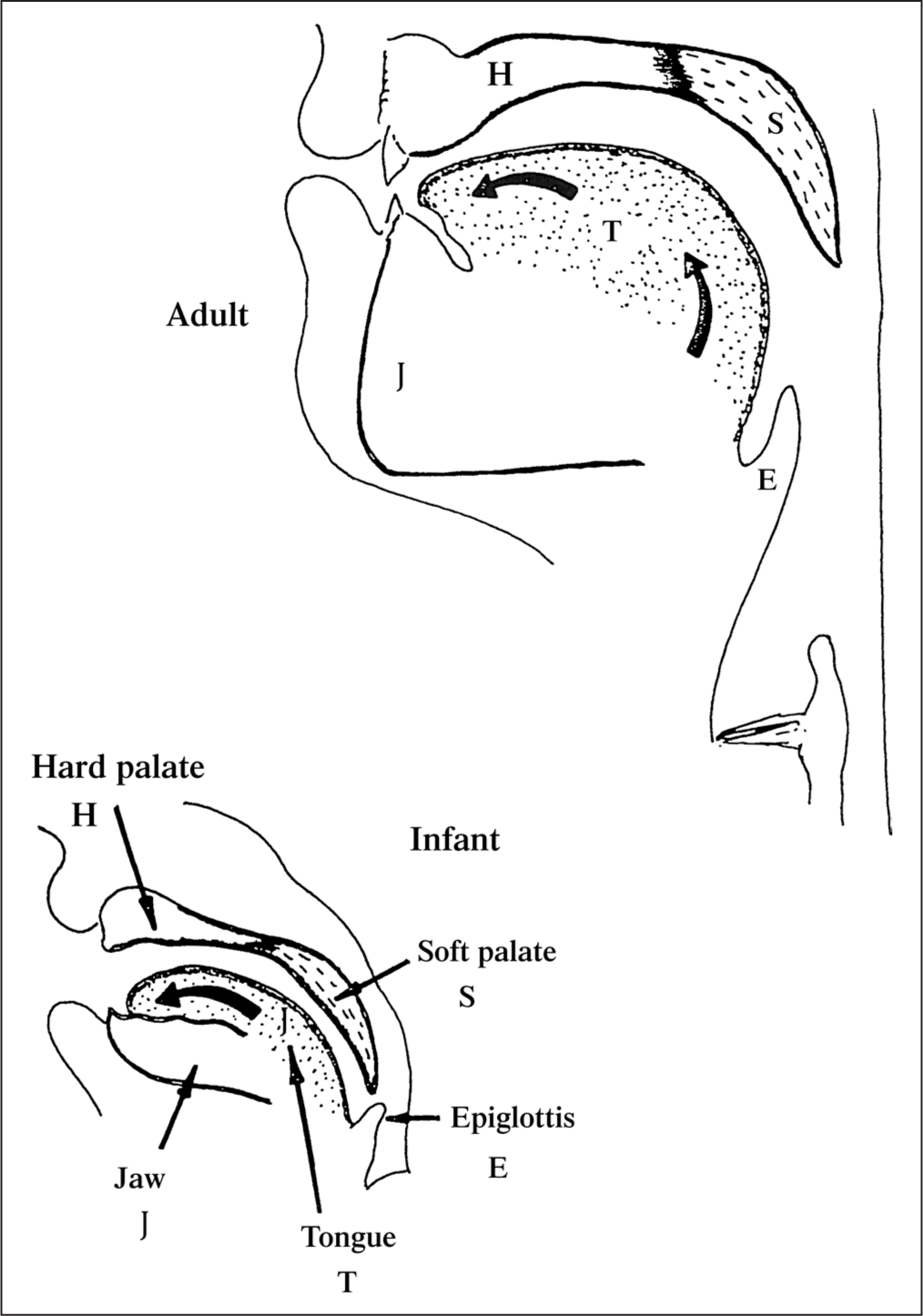
Illustration of adult and infant vocal tracts. (From Kent and Miolo 1995. Reproduced with permission.)
At around 3 to 4 months of age, the vocal tract reconfigures: the larynx drops down into the throat, lengthening the pharyngeal cavity. If you listen to a newborn baby and a 4-month-old baby cry, you’ll notice that they sound quite different from each other. The newborn’s cry has an almost animal-like quality to it, while the slightly older infant’s cry will sound more like a prototypical baby’s.
Sidebar 4.1: What Infant Speech Sounds Like
Listen to the sound files OM2-24-08 and OM3-30-08 to hear what an infant sounds like at 6 weeks and 3 months of age.
Shortly after this time, around 4 to 6 months of age, babies’ vocalizations change in an important way: they become structured units of sound we recognize as syllables. As we saw in chapter 3, a syllable is a unit of sound centered on a “peak of sonority” (Clements and Keyser, 1983). What is a peak of sonority? Usually it’s a vowel (V), and it can have one or more “obstructions” of sound, or consonants (C), on either side of it. In one study of the types of syllables babies used in babbling, the breakdown of syllable types was the following, which accounted for 98% of these children’s vocalizations at about 1 year of age (Kent and Bauer, 1985).
These vocalizations are known as canonical babbling. They are language-like in a couple of ways: First, they contain syllables. Syllables are what make speech sound “speechy,” as opposed to moans, groans, cries, giggles, whistles, and other nonlinguistic sounds humans can produce. Second, the kinds of syllables we find in canonical babbling are significant: looking at table 4.1 we can see that although babies at this stage produce a lot of vowels alone (60% of their vocalizations are just V syllables), when children do include a consonant it almost invariably precedes the vowel. Thirty-four percent of their productions comprise a CV syllable, its reduplicated form (CVCV), and a VCV sequence. A mere 4% of their productions involve a syllable ending in a consonant. Looking across the adult languages of the world, CV is the most common kind of syllable. The fact that babies’ canonical babbles share this property with adult language suggests that these productions are not just random but instead are part of the child’s budding language system.
|
Predominant vocalizations of 1-year-olds |
||
|---|---|---|
|
Syllable structure |
Frequency |
|
|
V |
60% |
|
|
CV |
19% |
|
|
CVCV |
8% |
|
|
VCV |
7% |
|
|
VC |
2% |
|
|
CVC |
2% |
|
There are some other links between canonical babbling and language. One is that although babies may babble with sounds not found in their target language (e.g., French-acquiring babies may produce [ha] or [hə], even though French does not have the phone [h]), as they progress toward the end of their first year, their babbles come to sound more and more like the target language (de Boysson-Bardies and Vihman, 1991). One study revealed that adults could, to a significant degree, determine the target language of an 8-month-old baby simply on the basis of the baby’s babbles (de Boysson-Bardies, Sagart, and Durand, 1984). In fact, it can be difficult to tell the difference between a babble and a word. When a child acquiring English says [mama], is this simply a reduplicated CVCV babble, or is it the word mama? We normally assume that it is a word only if it has a fixed meaning associated with it (the child uses [mama] to refer to their mother or another person), but it can be surprisingly hard to tell sometimes if a baby is using a “word” with a fixed meaning. One child used the form [mama] to mean any human.1 Another link between babbling and language is that deaf babies who are exposed to sign language in infancy begin to babble with their hands around the same time that hearing babies produce canonical babbles (Pettito, 1991; see chapter 8, section 8.2).
Sidebar 4.2: Changes in Infant Speech
Listen to the sound files OM5-10-08, OM5-29-08, and OM6-29-08. The ages of the baby in these files are 4 months, 4½ months, and 5½ months, respectively. What shift do you notice between the first and second sound files?
4.2 Building a Sound System
4.2.1 What Is a Phoneme?
Once a child starts producing words (as opposed to babbling, as discussed above), we can say that the child is developing an inventory of phonemes. Linguistic sounds are also called segments or phones, but the word phoneme has a special meaning: it is a sound that exists in the speaker’s mental representation. We introduced this concept in chapter 3, but let’s review it briefly. For an example of two different phonemes, think of two words you know that differ only by a single sound, such as bat and pat (linguists call such pairs of words minimal pairs). If you are an English speaker, you recognize these words as being different because the sounds /b/ and /p/ are represented in your mind as different sounds—they are different phonemes, and we say that they contrast with one another. (Recall that linguists write symbols for phonemes between two forward slashes, //, to differentiate the mental representation from the phonetic segment, which is written between square brackets [].)
Now consider two other words that you recognize: pat and spat. As we mentioned in section 3.2, the two /p/ sounds in these words are actually different phones. The /p/ sound at the beginning of pat is aspirated (there’s a tiny puff of air that escapes your lips when you say it), while the /p/ sound in spat is unaspirated (no tiny puff of air, or at least a very much tinier one). If you put your hand in front of your mouth when you say these two words, you should feel the difference. We write that puff of air with a superscript ‘h’ symbol, so writing these words phonetically we have [phæt] and [spæt]. The sounds [ph] and [p] are actually different phones, or segments (recall from chapter 3 that their difference has to do with voice onset time, or VOT), but if you are an English speaker they are the same phoneme—in your mind they are represented as being the same sound (i.e., they are noncontrastive for you).
4.2.2 Early Phoneme Inventory
The shift from perceiving sounds as phones to perceiving sounds as phonemes is a critical step in the development of language. Having a mental representation of a sound means that you can recognize it even when it is spoken in different words, by different speakers, and with different phonetic properties (like in the aspirated versus unaspirated /p/ example). This is just one example of a process we’ll see repeatedly in many domains within language acquisition: the process of generalization. It’s an interesting question to ponder how children arrive at these abstract mental representations of sound. We don’t know exactly how this happens, but we can look at what children’s early phoneme inventories look like and consider what might be possible influences on those inventories.
It turns out that across languages we see a remarkable amount of similarity in children’s early phoneme inventories. Jakobson was one of the first modern linguists to notice that children acquiring various languages all start out with /a/ as their earliest vowel and a labial stop (a sound made with the lips, such as /p/, /b/, or /m/) as their earliest consonant. Soon children begin to develop other consonants that contrast with their first one along one phonetic dimension. For example, children will develop /m/ and /b/ or /p/, which contrast in the [+/- nasal] feature but share the [+ labial] feature, or /t/, /d/, or /n/, which contrast with /p/, /b/, and /m/ in their place of articulation (/p/ is labial; /t/ is coronal—made with the tip or blade of the tongue). Sounds produced much later include velars and palatals (place of articulation), and the early-produced oral stops and nasals are later joined by fricatives and liquids (manner of articulation).
Jakobson claimed that there was a universal order of acquisition of phonemes, and he argued that children adhered to this order because it was a fundamental property of human language that certain classes of sounds were more basic than others, and these sounds had to be acquired first. More recent research has revealed that his claim about the universal order was too strong, but nevertheless there are robust tendencies across children and across languages. For instance, de Boysson-Bardies and Vihman (1991) tallied the places and manners of articulation of consonants produced by babies acquiring English, French, Japanese, and Swedish in these babies’ babbles and first words. In terms of manner of articulation, all of the babies produced many more stops than fricatives, nasals, or liquids. For place of articulation, the English- and French-acquiring babies produced more labials than dentals (sounds made by touching the tongue to the teeth), while the Japanese- and Swedish-acquiring babies produced more dentals than labials; but all babies produced velars (articulated at the soft palate, or velum) at the lowest rate.
Sidebar 4.3: Markedness
The idea of markedness plays a central role in much of generative linguistics. Markedness is the idea that some features of language are extremely common or robust across the world’s languages, while other features are more unusual. Features or properties that are common are unmarked, while features or properties that are rare are marked. In phonology, we can say that certain classes of sounds are unmarked (stops and coronals—sounds articulated with the tip or blade of the tongue) while others are marked (pharyngeals, clicks) and that certain syllable shapes are unmarked (CV) while others are marked (CCCVCCC). As we’ll see in future chapters, markedness surfaces in other parts of linguistics as well. In syntax, for example, certain word orders or sentence constructions can be considered unmarked (SVO and SOV word orders) while others are marked (OVS). Oftentimes unmarked forms are acquired earlier than marked forms, though this is not always the case (e.g., the “verb second” rule in the syntax of some languages is a marked construction, but it is acquired early by children).
Interestingly, children’s order of acquiring phonemes (in production) is not only widespread across child languages; it also shares some patterns that we find in adult language, in that children’s earliest sound features tend to be the most common across adult languages. For example, all known languages of the world have stops, but not all languages have fricatives (Maddieson and Precoda, 1990).2 Likewise, coronal and labial sounds are crosslinguistically extremely common (all consonant inventories have at least one coronal sound, and [m], a labial consonant, is the most widely attested phoneme, found in 95% of the world’s languages [Hyman, 2008; Moran, McCloy, and Wright, 2014]), but palatal sounds are rarer. While it is true that some languages have no labial stops, such as the Iroquois languages, which may have [m] and a labio-velar glide [w] but not [b] or [p], this situation is extremely rare crosslinguistically.
While Jakobson claimed that children’s phonological inventories adhere to a universal hierarchy of sounds, subsequent research has uncovered some variation in how children construct their sound systems. Some of these differences appear to be due to individual variation, such as an English-learning child who uniformly replaces the alveolar /s/ with the alveopalatal [ʃ], even though other speakers of the same language do not do this, or a child who turns word-final /g/ or /k/ into a glottal stop ([ʔ]). Another deviation from Jakobson’s universal order is found more generally in English and other languages; namely, the palatal glide /j/ is produced quite early. Other differences appear to be related to the particular target language. For example, one comparison between toddlers acquiring English and toddlers acquiring Japanese found that while English-acquiring toddlers tend to front /ʃ/ to [s] (this is known as “fronting,” a type of substitution process; see section 4.3.1), Japanese toddlers instead tend to “back” /s/ to [ʃ] (phonetically, the post-alveolar fricative in Japanese is actually [ɕ], but it sounds to English speakers like [ʃ], possibly due to perceptual assimilation [Li, Edwards, and Beckman, 2009]). A study of Finnish-speaking children’s development found that the [d] was produced late in development, while [r] was produced earlier (Itkonen, 1977, cited in Dunbar and Idsardi, 2016).
What is it about individual languages that yields these differences? An important study by Pye, Ingram, and List (1987) looked at the phoneme inventories of children acquiring K’iche’, a Mayan language, and asked whether the frequency with which particular sounds occurred in the target language might be related to the order in which they were acquired: more frequently occurring sounds might be acquired earlier. These researchers discovered some interesting differences between the early inventories of the K’iche’-speaking children as compared to English-speaking children at the same age. Restricting their study to word-initial consonants, they found that K’iche’ children began to produce the affricate [tʃ], glottal stop [ʔ], and [l] earlier than English-speaking children, while English-speaking children began producing [s] and [n] earlier than the K’iche’-speaking children. Pye, Ingram, and List suggested that these crosslinguistic differences could be due to the relative frequency with which certain sounds appear in the target language. For example, the affricate /tʃ/ is more frequent in K’iche’ than in English, and it is also produced earlier by K’iche’-speaking children than English-speaking children; conversely, /s/ is more frequent in English speech than in K’iche’ speech, and it is produced earlier by English-speaking children.
On the other hand, we know that frequency of occurrence in the input cannot be the sole (or even the main) explanation for why children acquire sounds in the order they do. In the de Boysson-Bardies and Vihman (1991) study described above in this section, the English target words contained more dentals than labials, but the English-acquiring babies still produced more labial sounds. Moreover, according to one ranking of the frequencies of phonemes in spoken English, some of the most frequent consonants include [r], [l], and [ð], all of which are produced fairly late, while some of the earliest-acquired sounds, such as [p] and [b], are relatively less frequent.3
To summarize, children’s development of their productive sound inventory exhibits certain orderings, such as the widespread acquisition of front sounds (labials and dentals) and stops before back sounds and non-stops (fricatives, affricates, liquids). To the extent that these orderings are found crosslinguistically, we can see children’s development as adhering to universal markedness scales. However, variation is also to be found within and across languages.
4.3 Common Phonological Processes
When listening to small children speak their first words and sentences, it is easy to observe that they do not sound exactly like adults—they alter the phonological form of many words. These alterations are found from the time children begin producing words around age 1 year into the beginning of their third year. Many of them resolve by age 2;6 or 3. The following are examples of mispronunciations or phonological “errors”:
(1) cup [tʌp]
water [wawa]
banana [nænə]
Children’s phonological errors are sometimes cute or funny, but what’s interesting about them is that they are highly regular. That is, we see very consistent patterns across children acquiring the same or different languages, and we also see evidence that children apply their alterations in an across-the-board way. For example, if a child pronounces /k/ as [t] at the beginning of one word (e.g., cup as [tʌp]), they are very likely to pronounce /k/ as [t] at the beginning of other words, too (e.g., coffee as [tafi]).
Due to the strong regularity of children’s mispronunciations, we can identify a number of patterns that we call phonological processes (Ingram, 1979). There are three main categories of phonological processes: substitutions, assimilations, and syllabic processes. Within each category we can then identify a number of specific subtypes.
4.3.1 Substitutions
Children may substitute one sound for another, where the two sounds involved usually share several features but differ in either the place or manner of articulation. One very common type of substitution is stopping. Stopping involves substituting a stop for a fricative or other non-stop sound, such as a liquid. Another very common substitution is fronting, in which a more back sound, such as a velar or palatal consonant, is replaced with a more front sound, such as an alveolar consonant. Examples are given in table 4.2. Fronting and stopping are extremely common processes across many child languages.
|
Examples of children’s substitution phonological processes |
||||||
|---|---|---|---|---|---|---|
|
Phonological process |
Target word |
Child’s pronunciation |
Sounds involved |
|||
|
Stopping |
sea /si/ |
[ti] |
/s/ → [t] |
|||
|
that /ðæt/ |
[dæt] |
/ð/ → [d] |
||||
|
fleur ‘flower’ /fløχ/ (French) |
[pø] |
/f/ → [p] |
||||
|
Fronting |
shop /ʃap/ |
[sap] |
/ʃ/ → [s] |
|||
|
Katharina /kataʁina/ (German) |
[tataʁina] |
/k/ → [t] |
||||
|
cassé ‘broken’ /kase/ (French) |
[tase] |
/k/ → [t] |
||||
|
Gliding |
yellow /jɛloʊ/ |
[jɛjoʊ] |
/l/ → [j] |
|||
|
room /ɹu:m/ |
[wu:m] |
/r/ → [w] |
||||
|
raha ‘money’ /raha/ (Estonian) |
[jaha] |
/r/ → [j] |
||||
|
robe ‘dress’ /ʁɔb/ (Québec French) |
[wɔb] |
/ʁ/ → [w] |
||||
|
Vocalization |
bottle /batəl/ |
[babu] |
/l/ ([ɫ]) → [u] |
|||
|
apple /æpəl/ |
[apo] |
/l/ ([ɫ]) → [o] |
||||
Another kind of substitution process we observe is gliding. Gliding involves a liquid (/l/ or /r/) being replaced with a glide ([j] or [w]), as in yellow being pronounced [jɛjoʊ] or room being pronounced [wuːm]. The rhotic liquids (the ‘r’ sounds) can vary quite a bit from language to language (some are alveolar sounds like Spanish or Estonian /r/; some are central approximants like English /ɹ/, and some are uvular trills or fricatives like French /ʁ/). With respect to children’s phonological alterations, sometimes these phonetically distinct sounds nevertheless function similarly in the phonological system, as we see in table 4.2. However, some differences can also be found across languages: the alveolar trill /r/ is often replaced with the lateral liquid [l], or in some cases the stop [d] (Tessier, 2016).
Finally, sometimes a vowel is substituted for a consonant, often a liquid or glide (these classes of sounds are more similar to vowels—they are more sonorant—than certain other consonants, like stops or fricatives). This kind of substitution is called vocalization. Note that in the examples in table 4.2 (bottle pronounced [babu] and apple pronounced [apo]), it is a velarized /l/ (phonetically, [ɫ]) that is being vocalized.
4.3.2 Assimilations
Sometimes children alter a feature of a sound to make it more similar to a neighboring sound; this is called assimilation. Some examples are given in table 4.3. Here we’ll discuss consonant assimilation (or consonant harmony), which can involve place assimilation (e.g., duck pronounced [gʌk]) or manner assimilation (e.g., the French word mouton [mutõ] ‘sheep’ pronounced as [potõ]). In this latter case, the first consonant takes on the voicing feature ([-voice]) of the second consonant; when [m] loses voicing, it also loses its nasality and becomes [p].
|
Examples of children’s assimilation phonological processes |
||||||
|---|---|---|---|---|---|---|
|
Phonological process |
Target word |
Child’s pronunciation |
Sounds involved |
|||
|
Consonant assimilation (place) |
duck /dʌk/ |
[gʌk] |
/d/ → [k] |
|||
|
tape /teɪp/ |
[beɪp] |
/t/ → [b] |
||||
|
Consonant assimilation (manner) |
mouton ‘sheep’ /mutõ/ (French) |
[potõ] |
/m/ → [p] |
|||
|
Voicing |
pig /pɪg/ |
[bɪk] |
/p/ → [b] and /g/ → [k] |
|||
|
bed /bɛd/ |
[bɛt] |
/d/ → [t] |
||||
Another process that is considered an assimilatory process involves voicing. However, the voicing process in child language is not straightforwardly assimilatory the way consonant and vowel harmony are. Instead, children generally voice word-initial consonants (or produce them as voiceless unaspirated consonants if they are stops) and devoice word-final consonants. For example, pig can be pronounced [bɪk] and bed would be pronounced [bɛt].
4.3.3 Syllabic Processes
A third way that children modify the phonological shape of words is by changing their syllable structure. First, let’s review basic syllable structure. As we saw in chapter 3 (section 3.3.2), we can represent the syllable, symbolized with the Greek letter σ (sigma), as a hierarchical structure.
(2)

In many adult languages the onset and/or the coda can contain multiple segments. English allows this, as we see in the example in 3, which gives the syllable structure for the word streets.
(3)

One very common syllabic process is consonant cluster reduction (CCR). CCR can happen either in onset or coda position, and it involves a complex onset or coda (more than one consonant) being reduced to a single segment. It is important to remember that sounds such as [θ] as in think, [ð] as in that, and [ʃ] as in ship are single phonemes, not clusters. So when a child pronounces that as [dæt] or ship as [sɪp], these are not examples of cluster reduction.
Sidebar 4.4: Phonological Processes
Which phonological process or processes apply when a child pronounces that as [dæt] or ship as [sɪp]?
Sometimes a coda is deleted altogether, which is called coda deletion. Onsets are not deleted as frequently as codas, though this does sometimes occur. One child pronounced lollipop as [alɛbap], deleting the word-initial consonant /l/.
Two other syllabic processes can be identified: weak syllable deletion and reduplication. Weak syllable deletion involves a multisyllabic word, in which an unstressed syllable is deleted. For example, banana might be pronounced [nænə]. Sometimes a feature or segment of the deleted syllable is retained, so that banana could also be pronounced [bænə]. Reduplication involves the doubling of a syllable. Examples of all these syllabic processes are given in table 4.4.
|
Examples of children’s syllabic phonological processes |
||||||
|---|---|---|---|---|---|---|
|
Phonological process |
Target word |
Child’s pronunciation |
Sound change involved |
|||
|
Consonant cluster reduction (onset) |
clown /klaʊn/ |
[kaʊn] |
/kl/ → [k] |
|||
|
prune /pɹun/ |
[pun] |
/pr/ → [p] |
||||
|
Consonant cluster reduction (coda) |
box /baks/ |
[bak] |
/ks/ → [k] |
|||
|
desk /dɛsk/ |
[gɛk] |
/sk/ → [k] |
||||
|
Coda deletion |
egg yolk /ɛg jok/ |
[ɛ jok] |
/g/ → ∅ |
|||
|
more /mɔɹ/ |
[mɔ] |
/ɹ/ → ∅ |
||||
|
Weak syllable deletion |
banana /bənænə/ |
[nænə] |
/bə/ → ∅ |
|||
|
Rapunzel /ɹəpʌnzəl/ |
[pãzow] |
/ɹə/ → ∅ |
||||
|
Reduplication |
water /watɚ/ |
[wawa] |
||||
|
raisins /ɹezɪnz/ |
[ɹiɹi] |
|||||
|
vache ‘cow’ /vaʃ/ (French) |
[vava] |
|||||
Most of these phonological processes are found widely, both across children acquiring the same language and across children acquiring different languages. But does this mean that all children the world over acquire their phonological systems in exactly the same way? Just as we saw that there is some variation across children, and across languages, in the order in which children acquire their phoneme inventories, there is some individual and crosslinguistic variation in the phonological processes children apply in their speech (see table 4.5). For example, according to Ingram (1979), French-speaking children are more likely to simply delete a later liquid /l/ than replace it with a glide, as in lapin [lapẽ] ‘rabbit’ pronounced [apẽ]. In addition, certain substitutions are found in some languages but not others. Children acquiring English tend to replace the interdental fricative [ð] with [d] (this is stopping, as in that pronounced as [dæt]), but Greek-speaking children instead replace [ð] with [l], and children acquiring Spanish tend to replace it with either [l] or [r]. Another difference we find in substitution patterns is that while English-speaking children often substitute [r] with [w] and [l] with [j], children acquiring K’iche’ substitute [r] with [l].
|
Crosslinguistic substitution patterns |
||||
|---|---|---|---|---|
|
Language |
Target sound |
Substituted sound |
||
|
English |
ð |
d |
||
|
r |
w |
|||
|
l |
j |
|||
|
Greek |
ð |
l |
||
|
Spanish |
ð |
l, r |
||
|
K’iche’ |
r |
l |
||
4.3.4 Covert Contrasts
It is important to bear in mind that children’s phonological “errors” may not always be true errors. That is, children may produce two sounds in such a way that adult listeners cannot perceive a difference between them, but an acoustical analysis reveals that the two sounds, which sound identical to adults, are actually phonetically distinct. When such phonetic differences are statistically reliable, even if they are not perceivable by listeners, they are known as covert contrasts. Many studies of children’s pronunciations rely on human transcribers, who by definition cannot accurately represent covert contrasts, but in some studies a finer-grained acoustical analysis has been done.
For example, Li et al.’s (2009) study of English-speaking and Japanese-speaking toddlers (see section 4.2.2) found that some of the English-speaking children who appeared to neutralize /s/ and /ʃ/ (pronouncing both sounds as [s]) actually showed a statistically significant difference between the two sounds at a phonetic level. Similarly, some of the Japanese-speaking children who appeared to neutralize both of their fricatives (pronouncing both /s/ and /ʃ/ as [ʃ]) exhibited a measurable acoustical difference between their two sounds, even if this difference was not audible to human listeners.
These findings suggest that at least some of children’s apparent mispronunciations may be more adultlike than they appear. The notion that children’s representations of sounds are actually quite adultlike will be further supported in the sections below.
4.4 Accounting for Patterns: Phonological Rules
We’ve just seen that some of children’s apparent phonological errors may not be as far off the mark as we might at first think. However, in many cases when a child mispronounces a word, they truly omit or substitute a sound, resulting in a non-adultlike or non-target-like pronunciation. Putting aside the possibility of covert contrasts for a moment, we must try to explain children’s mispronunciations. Are children unable to hear the target (adultlike) form or to tell the difference between their own pronunciation and the target one? Are children simply incapable of articulating certain sounds? There is a third possibility: children represent a word’s phonological form correctly (i.e., the adult way) and may be capable of articulating the adult sound, but they alter it through the application of phonological rules. In this sense, children’s errors arise not from problems with hearing or articulation but rather from their phonological grammar (Smith, 1973).
Sidebar 4.5: Imitating Mom
Listen to the sound file LM12.1.12pepper.WMA. How does the child respond to her mother’s imitations of her word pepper? (Try to ignore the older sibling’s playful productions.)
A couple of kinds of evidence support this view. One is that children often reject adults’ attempts at reproducing the child’s own pronunciation. In the following exchange between linguist Neil Smith and his son, Amahl, notice that Amahl does not perceive his father’s [sɪp] as corresponding to [ʃɪp], even though [sɪp] is Amahl’s own pronunciation of /ʃɪp/ (Smith, 1973).
(4) Father: What’s a [sɪp]?
Amahl: When you drink.
Father: What else does [sɪp] mean?
Amahl: (puzzled, suggests zip)
Father: No; it goes in the water.
Amahl: A boat.
Father: Say it.
Amahl: No. I can only say [sɪp].
Amahl may have an unusual degree of awareness of his own pronunciations (compared to children whose parents are not linguists), but crucially, he does not hear his father’s production of [sɪp] as equivalent to his own pronunciation of /ʃɪp/, even though phonetically they are the same.
That children’s phonological “errors” do not arise (at least, not exclusively) from articulatory problems is evidenced by the fact that sometimes a particular phonetic form that the child appears unable to produce is produced for another lexical target. At age 2;1 Neil Smith’s son, Amahl, produced the following words:
|
Word |
Target |
Child’s form |
||
|---|---|---|---|---|
|
puddle |
/pʌdəl/ |
[pʌgəl] |
||
|
puzzle |
/pʌzəl/ |
[pʌdəl] |
||
|
thick |
/θɪk/ |
[fɪk] |
||
|
sick |
/sɪk/ |
[θɪk] |
Given these pronunciations, could you argue that Amahl’s nontarget pronunciations of puddle and thick were due to an inability to pronounce the segments [d] and [θ] in the target environments? What problem would such an argument encounter?
If children’s phonological “errors” are not the result of problems hearing the way adults pronounce words or the result of problems articulating those sounds, then what accounts for children’s mispronunciations? Many linguists believe that children actually store a mental representation of sounds the same way adults do. That is, their phonemic representation matches the adult’s phonemic representation (so, even if a child pronounces sick as [θɪk], their own stored form is /sɪk/). But children apply a series of phonological rules that convert their underlying phonemic form into a phonetic form that is slightly different. So, what are those rules? First, let’s review what a phonological rule looks like. Here is its basic form:
(5) /phonemic form/ → [phonetic form] / (preceding environment) ____ (following environment)
The blank corresponds to the sound that is getting changed by the rule. Depending on the rule, we may need to specify just the preceding environment, just the following environment, or both. For example, consider the following two lists of English words and one child’s pronunciation of these words (from Smith, 1973).
|
(6) a. stamp [dɛp] |
b. window [wɪnuː] |
|---|---|
|
bump [bʌp] |
handle [ɛŋu] |
|
drink [gɪk] |
finger [wɪŋə] |
|
tent [dɛt] |
angry [ɛŋiː] |
|
uncle [ʌgu] |
hand [ɛn] |
|
empty [ɛbiː] |
band [bɛn] |
|
thank you [gɛguː] |
Consider first the words in 6a. Several different processes may be going on within each word in this set, but notice that in all of the words there is a nasal consonant getting deleted. If we had to write a rule for the whole set, we could write a “nasal deletion” rule—that is, a rule that specifies the environment in which a nasal sound is deleted. What is the environment in which it is getting deleted? If we look at the preceding environment (the sound preceding the nasal), we don’t see anything interesting: in every case the preceding sound is a vowel, but these vowels do not form any kind of natural class. That is, they are not all high vowels or all back vowels, for example. In some words, there is a consonant preceding that vowel (as in tent), but not in all cases (as in empty), so that is not helpful for our rule either. Now consider the environment following the nasal in each word. Do these sounds have anything in common? Yes! They are all stops. Do they have anything else in common? Yes! They are voiceless stops. Does it matter that they are voiceless? We don’t know yet, without looking at more data.
Now consider the words in 6b. These words contain nasal consonants too, but this time the nasals are not getting deleted. Rather, something else is getting deleted. What is it? Stops! And where are the stops being deleted? After nasals! But we just saw a set of words in which a nasal followed by a stop resulted in the nasal being deleted. Why isn’t that happening here?
If you noticed that the stops that get deleted are all voiced, you are very observant. Now we can see that in the 6a list, when a nasal is followed by a voiceless stop, the nasal is deleted. But in the 6b list, when a nasal is followed by a voiced stop, the (nonnasal) stop is deleted. We can now write our rules as in 7.
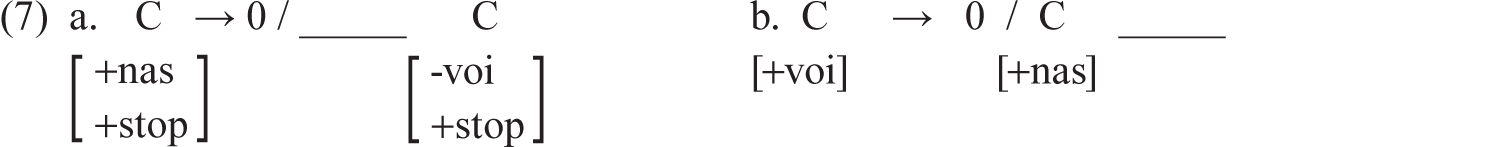
In some cases, it is not the immediately preceding or following phoneme that conditions the rule but rather the position in the word or syllable in which the sound in question appears. For example, if a child produces the following pronunciations,
(8) a. sun [dʌn]
b. scissors [dɪdə]
c. soon [duːn]
we could write a rule stating that /s/ becomes [d] at the beginning of a word (we use the ‘#’ symbol to mean a word boundary).
(9) /s/ → [d] / # _____
This rule simply says that the phoneme /s/ becomes the phonetic form [d] when it occurs right after a word boundary (i.e., at the beginning of a word).
Sometimes linguists come up with a rule that covers some data, only to discover other data that requires making the rule more precise. Suppose we now discover that the same child who produced the words in 8 also produces these forms:
(10) a. sing [gɪŋ]
b. sock [gɔk]
Here we see an /s/ at the beginning of the word that does not become [d]; rather, it becomes [g]. What could account for this difference? Think about the types of consonants that occur at the ends of these words, compared to the words in 8. What is their place of articulation? What place of articulation does the /s/ take on in the phonetic form?
By thinking about sounds in terms of their features, we can recognize that in the words in 8, /s/ is becoming an alveolar stop ([d]) when the next consonant in the word is alveolar, but in 10 it becomes a velar stop ([g]) when the next consonant in the word is velar. Thus, we can recognize what’s happening here as a combination of stopping (the fricative /s/ becomes a stop) and place assimilation (it assimilates to the place of articulation of the next consonant; we notate the intervening vowel with V but leave out the vowel’s place features, since it doesn’t seem to matter which vowel intervenes). We can either write two rules, like in 11a, or we can use the convention shown in 11b, where the ‘α’ symbol simply means “whichever place variable” the following consonant (C) has.
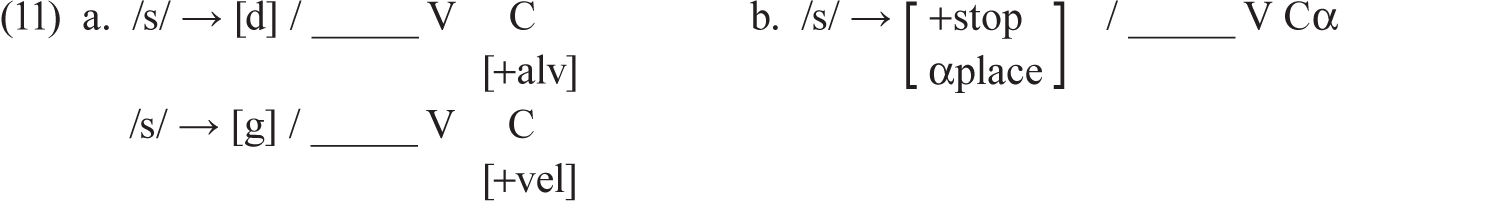
An important property of rule-based phonology is that rules must be ordered in a particular way. That is, if one rule alters the conditioning environment for another rule, ordering the rules the wrong way will result in one of the rules failing to apply. Consider the following two rules, one of which we saw above in 7.

The first rule says “a voiced stop consonant is deleted after a nasal consonant” (this accounts for why hand was pronounced [ɛn], for example). The second rule says “an obstruent (fricative, affricate, or stop) becomes voiceless at the end of a word.” This rule accounts for words like bed being pronounced as [bɛt]. Given Amahl’s pronunciation of the words hand as [ɛn] and mend as [mɛn], how do these two rules need to be ordered with respect to each other?
4.5 Accounting for Patterns: Constraints
Phonological rules allow us a means of explaining how children could store sounds with an adultlike representation yet pronounce words so differently from adults. Rules also help us to detect patterns in children’s pronunciations; for example, when a child applies a given rule to a sound in one word, the same rule will apply when the same sound appears in another word, provided the conditioning environment is the same. Finally, rules are helpful because they show the striking similarities between a child’s mental grammar and an adult’s: children are not employing a radically different mechanism to produce language than adults use. Instead, the same sorts of rules apply (deletion rules, insertion rules, assimilation rules, and so on), and they apply to the same classes of sounds (nasals, stops, fricatives, high vowels, and so on) as in adult language.
But one thing that is slightly odd about conceiving of children’s phonology this way is that it implies that a child’s mental grammar contains a lot of extra stuff that is then lost as the child matures and develops into an adult speaker. That is, the rules that apply to the child’s grammar to yield their pronunciations do not apply to the adult language. The same kinds of rules found in child phonology are found in various adult languages (assimilation rules, deletion rules, and so on), but the whole reason we needed to propose these particular rules in section 4.3 was to explain why children sound different from adults. Therefore, these particular rules can’t apply in the child’s particular target language.
There is another way of approaching phonology that doesn’t require us to impute young children with extra knowledge that they have to unlearn. Phonologists studying adult sound systems using a rule-based system began to notice that there were crosslinguistic similarities that were not adequately captured by these rules. They began to notice that languages around the world employed the same kinds of rules (deletion rules, assimilation rules, and so forth) but not the same exact rules. Phonologists wondered if there was a way to capture these global similarities in the kinds of things human language sound systems were trying to achieve.
The framework that developed out of this effort is known as Optimality Theory (Prince and Smolensky, 1993). Optimality Theory proposes a set of universal constraints on how words can be phonologically structured. The idea is that all languages share these universal constraints, but different languages rank the constraints differently. An example of a constraint is *CODAVOICE, which means “a coda cannot be voiced” (the ‘*’ symbol means “not allowed,” just like in syntax). This constraint captures the fact that some languages require final consonants to be voiceless. For example, in German this constraint is ranked quite highly, meaning it applies robustly in the language: German obstruents (stops and fricatives) are always voiceless when they occur at the end of a word (e.g., Rad ‘wheel’ is pronounced [ʁat]), but they remain voiced before a vowel (Räder ‘wheels’ is [ʁedɐ], not *[ʁetɐ]). But in other languages, like English, this constraint is not highly ranked, which simply means it doesn’t have much effect. English freely allows consonants to be voiced in coda position (e.g., bed [bɛd], please [pliz]). (We can sometimes see minor effects of such constraints, however: even in English there is sometimes a tendency to devoice final consonants, especially voiced fricatives like /z/ [Smith, 1997].)
The idea behind Optimality Theory is that for each word in the lexicon there is a set of possible phonological forms the word could have. These forms (called candidates) compete with one another, and the candidate that violates the lowest ranked constraints (the least important ones for that language) is the optimal form; this is the form that is actually pronounced. Let’s look at a concrete example. In English we have the word bed, which has a final consonant that is voiced. Imagine if this word were borrowed into a language that did not allow voiced codas—how would it be pronounced? In principle, language allows a number of options. The coda could be devoiced, yielding [bɛt], the coda could be deleted altogether ([bɛ]), or we could insert (epenthesize) a vowel so that the [d] is no longer the final sound in the word, yielding [bɛdɛ] or [bɛdə]. In this example, we say that /bɛd/ is the input form, or underlying form, and the options for pronunciation ([bɛt], [bɛ], [bɛdɛ]) are the candidate forms—the possible pronunciations. We then rank the universal constraints mentioned above, like *CODAVOICE, in such a way that the winning candidate is the one that is actually produced.
The constraints are designed to reflect the kinds of patterns and preferences we actually see in the world’s languages. There are two main types of constraints. One type is called markedness constraints. These constraints favor phonological forms that are very unmarked. We know that the least marked syllable type is CV, so constraints that either disallow codas, weaken codas by devoicing them, or disallow complex onsets or codas are markedness constraints. We also know that languages prefer syllables with single onsets that exhibit the maximum contrast with a vowel—the least vowel-like consonant is a stop consonant. So constraints that disallow more vowel-like onsets (like liquids or glides) would also be markedness constraints.
We also need constraints that put the brakes on too much deletion or insertion, or else every word would just consist of V or CV syllables with no codas and no complex onsets. There are languages in which this is actually how words and syllables must be formed (such as Hawaiian), but many languages, like English, allow more complex syllable types. The second main type of constraint is faithfulness constraints, which favor candidates that are very similar to the underlying form of the word along some phonological dimension. So if the underlying form of the word (/bɛd/ in our example above) has a coda, a voiced coda, or a complex onset, a highly ranked faithfulness constraint would rule out forms that added or deleted sounds or changed features in order to make less marked syllables.
Let’s propose some constraints to evaluate the different possible pronunciations of bed we saw earlier.
(13) Markedness constraint: *CODAVOICE
Faithfulness constraints: IDENTVOICE, MAX, DEP
The markedness constraint should be fairly transparent: *CODAVOICE means “don’t have a voiced coda.” The faithfulness constraints require a little more explanation. IDENTVOICE means “each segment should have the same voicing feature as the corresponding underlying segment.” In other words, don’t change the voicing of any segments in the word. MAX means “don’t delete anything,” and DEP means “don’t insert anything.”
While the process of doing rule-based phonology involves figuring out which rules apply in a particular case and how those rules must be ordered, doing phonology in Optimality Theory involves figuring out how we need to rank the constraints. Remember, all languages are assumed to have all the same constraints; they are just ranked differently (they have different degrees of importance) in different languages. In section 4.4 we wrote a rule that accounted for final devoicing; the rule in 12b is repeated here:
(12) b. C → [-voi] / _____ #
[-son]
How could we account for this same pattern using Optimality Theory (OT)?
To figure this out we set up a table (called a tableau in OT terminology) with the candidates going down the left side and the constraints going across the top. The constraint in the leftmost constraint column is the highest ranked, and the constraint in the rightmost column is the lowest ranked. The ordering of the candidates from top to bottom doesn’t matter, and we indicate the winning candidate with the ![]() symbol. The constraint ranking in the tableau below reflects the phonology of adult English, and the winning candidate is the pronunciation English speakers use for the underlying form. For this small example let’s just consider two candidates, one with a voiced coda and one with a voiceless coda.
symbol. The constraint ranking in the tableau below reflects the phonology of adult English, and the winning candidate is the pronunciation English speakers use for the underlying form. For this small example let’s just consider two candidates, one with a voiced coda and one with a voiceless coda.

As noted above, this ranking reflects adult English phonology. We ended up with this result because we ranked the constraints so that the constraint that the winning form violates, the markedness constraint *CODAVOICE, is the lowest ranked. And the constraint that the other candidate violates, the faithfulness constraint IDENTVOICE, is ranked more highly.
But now suppose we want to model the way a child pronounces a word. We saw in section 4.2.2 that children sometimes alter the voicing of target sounds. In particular, they tend to voice onsets and devoice codas. So this time we want to model the fact that a child pronounces the word bed as [bɛt]. How can we rerank our constraints to make [bɛt] the optimal form?

Notice what we did in order to get [bɛt] as the winning candidate: we made the markedness constraint (*CODAVOICE) more important (higher-ranked) and the faithfulness constraint (IDENTVOICE) less important (lower-ranked). In fact, we can make a fairly broad generalization about children’s phonology: their errors tend to involve producing less marked forms than those found in the adult grammar. Going back to one of our motivations for explaining children’s phonology using constraints, what is different about children versus adults is the relative ranking of these families of constraints. Children generally have their markedness constraints ranked highly in their grammar and faithfulness constraints ranked lower. Optimality Theory demonstrates that, unlike the rule-based approach, children do not have extra rules in their grammar they need to unlearn; rather, as they grow they must simply rerank their constraints so that the (relevant) markedness constraints end up lower and the faithfulness constraints end up higher. This is how children come to have an adultlike pronunciation of words and an adultlike phonological system (Tesar and Smolensky, 1998; Boersma and Hayes, 2001).
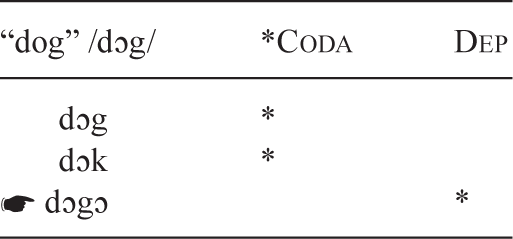
One advantage of explaining children’s phonology using an OT approach is that it gives us an easy way of accounting for the variation we find across children in their pronunciations. While the processes and rankings we’ve talked about are quite widespread, we do find some individual differences, even across children acquiring the same language. In the bed example above, we had to rank the *CODAVOICE constraint very high in order to get [bɛt] as the optimal form, since that is the way one child (the child we were trying to model) pronounced it. But another child acquiring English had such a strong dispreference for codas in general that he epenthesized a vowel at the end of every word that ended in a consonant. Thus, he produced forms like [baga] for bag, [buku] for book, and [dɔgɔ] for dog. So for this child, the DEP constraint (“don’t insert anything”) must be ranked extremely low, and we would need to introduce another markedness constraint, *CODA (“don’t have a coda”), which would be ranked very highly, higher than his DEP constraint. In this child’s grammar, then, it is better to insert a vowel in order to avoid having a coda than to remain faithful to the target form and allow a coda. The following tableau illustrates how we could rank our constraints to yield this child’s pronunciation as the winning candidate.4
4.6 Summary
In this chapter we have seen that children go through quite uniform stages of phonological development in speech production, from developing their phoneme inventories along similar trajectories to applying similar phonological processes to their early words. While there is some variation across languages (note differences in the early phoneme inventories of children acquiring K’iche’ and children acquiring English) and variation across individuals acquiring the same language, variation is found to be of limited scope. Taking a cue from Grammont (1902, cited in Jakobson, 1971), “[the] child undoubtedly misses the mark, but he always deviates from it in the same fashion.” These uniform deviations in children’s phonological systems can be linked to principles of adult phonological grammar: broadly speaking, children tend to produce unmarked, or less marked, forms (stops, labials, CV syllables) and take longer to incorporate more marked forms into their language.
4.7 Further Reading
- De Boysson-Bardies, Benedicte. 1999. How Language Comes to Children: From Birth to Two Years. Cambridge, MA: MIT Press.
- Tessier, Anne-Michelle. 2016. Phonological Acquisition: Child Language and Constraint-Based Grammar. New York: Macmillan Education, Palgrave.
- Vihman, Marilyn May. 1996. Phonological Development: The Origins of Language in the Child. Oxford: Blackwell.
4.8 Exercises
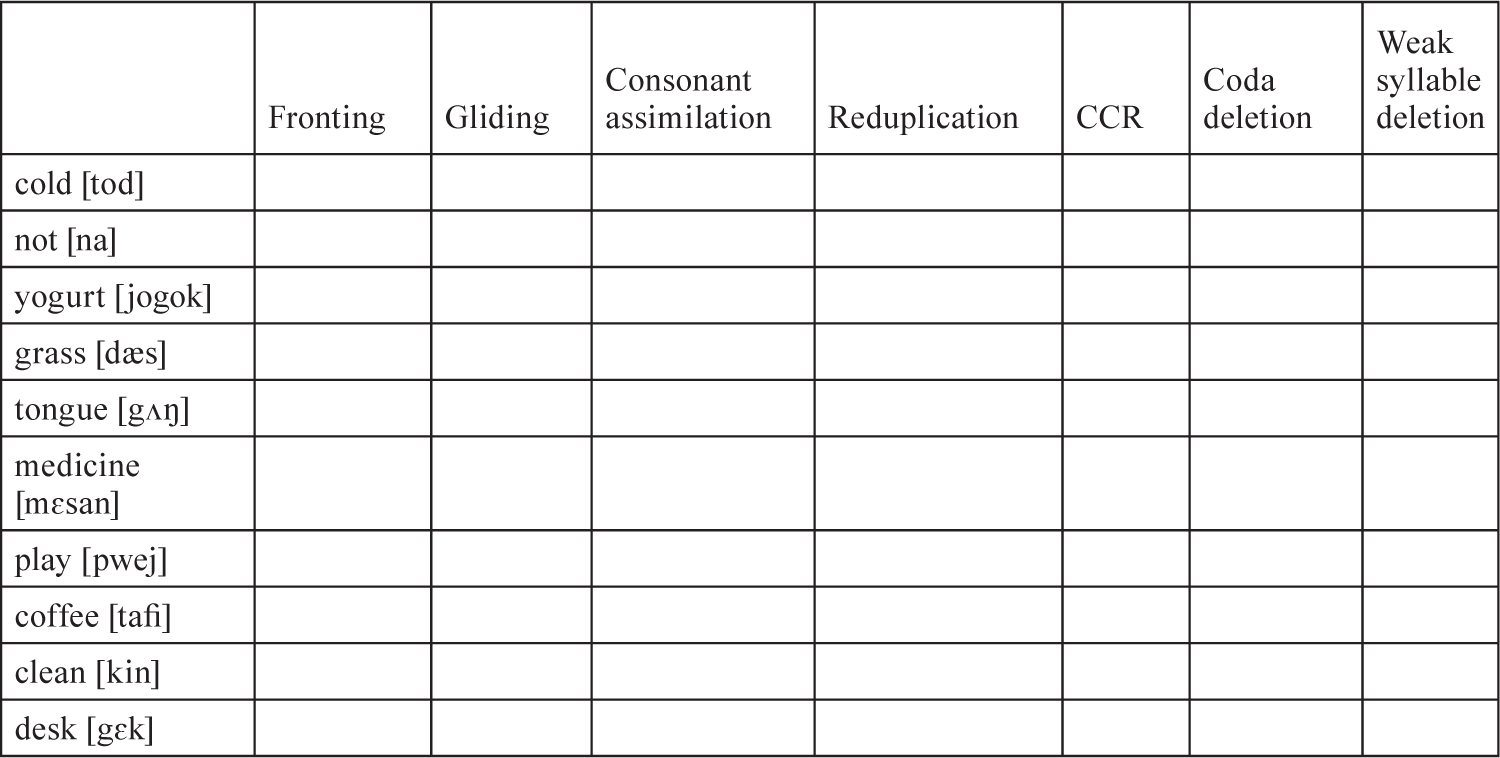
1. In the following table, put a check in the squares under the phonological process or processes that apply in each case. (CCR = consonant cluster reduction)
2. Consider the following lists of words. For each list, come up with a single phonological rule that captures what all of the words in that list have in common.
|
a. handle [ɛŋu] |
b. ball [bɔː] |
c. biscuit [bɪgɪk] |
d. dark [gaːk] |
|||
|---|---|---|---|---|---|---|
|
pedal [bɛgu] |
bell [bɛ] |
escape [geip] |
drink [gɪk] |
|||
|
beetle [biːgu] |
trowel [dau] |
skin [gɪn] |
leg [gɛk] |
|||
|
bottle [bɔgu] |
bolt [bɔːt] |
Smith [mɪt] |
ring [gɪŋ] |
|||
|
elbow [ɛbuː] |
spoon [buːn] |
singing [gɪŋɪŋ] |
||||
|
milk [mɪk] |
scream [giːm] |
snake [ŋeːk] |
||||
|
swing [wɪŋ] |
stuck [gʌk] |
|||||
|
taxi [gɛgiː] |
3. Adult Japanese has a rule that turns alveolar stop consonants into affricates when they occur before a high vowel ([i] or [ɯ]; [ɯ] is a high, back, unrounded vowel). Thus, /t/ becomes [tʃ] before [i], and it becomes [ts] before [ɯ]. No other stops are affected by this rule. Look at the following pronunciations of a child acquiring Japanese, and consider what underlying representations of sounds are pronounced as [t] (data cited in Fromkin, 2000, p. 669).
|
Target form |
Child’s form |
Gloss (meaning) |
||
|---|---|---|---|---|
|
[tama] |
[tama] |
ball |
||
|
[terebi] |
[terebi] |
TV |
||
|
[mikã] |
[mitã] |
orange |
||
|
[nɛko] |
[nɛto] |
cat |
||
|
[matʃi] |
[matʃi] |
city |
||
|
[tsɯta] |
[tsɯta] |
ivy |
||
|
[aki] |
[ati] |
fall |
||
|
[kɯma] |
[tɯma] |
bear |
Does this child have two different mental representations for /t/ and /k/ as adult Japanese speakers do? Or just a single underlying representation /t/? How can you tell?
4. Consider the following pronunciations by a child acquiring German.
|
Target form |
Child’s form |
Gloss (meaning) |
||
|---|---|---|---|---|
|
[dʀɛk] |
[glɛk] |
dirt |
||
|
[andʀejas] |
[æŋgleːəs] |
Andreas (name) |
Two sets of features are trading places in sounds in these words. What are those features and which sounds are changed? Instead of writing a rule, describe what processes lead to the child’s pronunciation of these two words. (Hint: Think of both place and manner features.)
5. Consider the following pronunciations by a 2-year-old English-speaking child (Gnanadesikan, 2004):
(1) a. clean [kin]
b. sleep [sip]
c. slip [sɪp]
d. grow [go]
e. please [piz]
f. friend [fɛn]
g. draw [da]
h. cream [kim]
Focusing on the onsets, we can see that this child deletes one of the consonants in the cluster to yield a singleton onset. Which one does she delete and which does she preserve? What manner feature is shared by the deleted consonants? What manner features do the preserved sounds have?
(i) Write a phonological rule to account for this child’s process of onset consonant cluster reduction.
(ii) If you read section 4.5 on Optimality Theory, use the following constraints to construct a tableau to account for the data in exercise 1 above.
(a) *COMPLEXONSET: An onset contains only a single consonant
(b) MAX: Don’t delete any segments
4.9 References
- Boersma, Paul, and Bruce Hayes. 2001. Empirical tests of the gradual learning algorithm. Linguistic Inquiry 32: 45–86.
- Braunwald, Susan. 1978. Context, word and meaning: Toward a communicational analysis of lexical acquisition. In Andrew Lock (ed.), Action, Gesture and Symbol: The Emergence of Language, pp. 485–527. New York: Academic Press.
- Butcher, Andrew. 2006. Australian Aboriginal languages: Consonant-salient phonologies and the “place-of-articulation imperative.” In Jonathan Harrington and Marija Tabain (eds.), Speech Production: Models, Phonetic Processes and Techniques, pp. 187–210. New York: Psychology Press.
- Clements, George N., and Samuel Jay Keyser. 1983. CV Phonology: A Generative Theory of the Syllable, 1–191. Linguistic Inquiry Monographs 9. Cambridge, MA: MIT Press.
- De Boysson-Bardies, Benedicte, Laurent Sagart, and Catherine Durand. 1984. Discernable differences in the babbling of infants according to target language. Journal of Child Language 11: 1–15.
- De Boysson-Bardies, Benedicte, and Marilyn Vihman. 1991. Adaptation to language: Evidence from babbling and first words in four languages. Language 67: 297–319.
- Dunbar, Ewan, and William Idsardi. 2016. The acquisition of phonological inventories. In Jeffrey Lidz, William Snyder, and Joe Pater (eds.), The Oxford Handbook of Developmental Linguistics, pp. 7–26. Oxford: Oxford University Press.
- Fromkin, Victoria (ed.). 2000. Linguistics: An Introduction to Linguistic Theory. Malden, MA: Blackwell Publishers.
- Gnanadesikan, Amalia. 2004. Markedness and faithfulness constraints in child phonology. In René Kager, Joseph Pater, and Wim Zonneveld (eds.), Fixing Priorities: Constraints in Phonological Acquisition, pp. 73–108. Cambridge: Cambridge University Press.
- Hyman, Larry. 2008. Universals in phonology. The Linguistic Review 25: 83–137.
- Ingram, David. 1979. Phonological patterns in the speech of young children. In Paul Fletcher and Michael Garman (eds.), Language Acquisition: Studies in First Language Development, pp. 133–148. Cambridge: Cambridge University Press.
- Itkonen, Terho. 1977. Huomioita lapsen äänteistön kehityksestä. Virttäjä, 279–308.
- Jakobson, Roman. 1971. Studies on Child Language and Aphasia. The Hague: Mouton.
- Kent, Ray, and Harold R. Bauer. 1985. Vocalizations of one-year-olds. Journal of Child Language 12: 491–526.
- Kent, Ray, and Giuliana Miolo. 1995. Phonetic abilities in the first year of life. In Paul Fletcher and Brian MacWhinney (eds.), The Handbook of Child Language, pp. 303–334. Cambridge, MA: Blackwell Publishers.
- Li, Fang-fang, Jan Edwards, and Mary E. Beckman. 2009. Contrast and covert contrast: The phonetic development of voiceless sibilant fricatives in English and Japanese toddlers. Journal of Phonetics 37: 111–124.
- Macken, Marlys, and David Barton. 1980. The acquisition of the voicing contrast in English: A study of the voice onset time in word-initial stop consonants. Journal of Child Language 7: 41–74.
- Maddieson, Ian, and Kristin Precoda. 1990. UPSID-PC: The UCLA Phonological Segment Inventory Database. http://
www .linguistics .ucla .edu /facilities /sales /software .htm. - Moran, Steven, Daniel McCloy, and Richard Wright (eds.). 2014. PHOIBLE Online. http://
www .phoible .org. - Munson, Benjamin, Jan Edwards, Mary E. Beckman, Abigail C. Cohn, Cécile Fougeron, and Marie K. Huffman. 2011. Phonological representations in language acquisition: Climbing the ladder of abstraction. Handbook of Laboratory Phonology, pp. 288–309.
- Oller, D. Kimbrough. 1978. Infant vocalizations and the development of speech in infancy. Allied Health and Behavioral Science 1: 523–549.
- Oller, D. Kimbrough. 1980. The emergence of the sounds of speech in infancy. In G. H. Yeni-Komshian, J. F. Kavanagh, and C. A. Ferguson (eds.), Child Phonology. New York: Academic Press.
- Pettito, Laura-Ann. 1991. Babbling in the manual mode: Evidence for the ontogeny of language. Science 251: 1493–1496.
- Prince, Alan, and Paul Smolensky. 1993. Optimality theory: Constraint interaction in Generative Grammar. Unpublished manuscript, Rutgers Center for Cognitive Science.
- Pye, Clifton, David Ingram, and Helen List. 1987. A comparison of initial consonant acquisition in English and Quiche’. In Keith E. Nelson and Anne van Kleek (eds.), Children’s Language, vol. 6, pp. 175–190. Hillsdale, NJ: Lawrence Erlbaum Associates.
- Smith, Caroline. 1997. The devoicing of /z/ in American English: Effects of local and prosodic contexts. Journal of Phonetics 25: 471–500.
- Smith, Neil V. 1973. The Acquisition of Phonology: A Case Study. Cambridge: Cambridge University Press.
- Stark, Rachel E. 1980. Stages of speech development in the first year of life. In Grace H. Yeni-Komshian, James F. Kavanagh, and Charles A. Ferguson (eds.), Child Phonology, vol. 1: Production, pp. 73–92. New York: Academic Press.
- Stoel-Gammon, Carol. 1989. Prespeech and early speech development of two late talkers. First Language 9: 207–223.
- Tesar, Bruce, and Paul Smolensky. 1998. Learnability in Optimality Theory. Linguistic Inquiry 29: 229–268.
- Tessier, Anne-Michelle. 2016. Phonological Acquisition: Child Language and Constraint-Based Grammar. New York: Macmillan Education, Palgrave.
Notes
1. Braunwald (1978) reported that one child at age 11 months used the word [baʊwaʊ] to mean dog but also in reference to the sound of barking, the sound of an airplane or a car engine, birds, or any outside noise she could hear from inside the house.
2. Aboriginal languages of Australia are particularly known for lacking fricatives. For more information about the phonological systems of Australian languages, see Butcher (2006).
3. This ranking was obtained from cmloegcmluin.wordpress.com/2012/11/10/relative-frequencies-of-english-phonemes.
4. We assume that the other constraints (*CODAVOICE, IDENTVOICE, and so forth) are still operational, but if we can’t determine how they would be ranked in a given example, we can omit them from the tableau. In this case, since this particular child avoids all codas, we can’t tell whether his IDENTVOICE constraint should be ranked higher or lower than his *CODA constraint.