Chapter 3
Storing big data
The first hard drive, developed and sold by IBM in San Jose, California, had a storage capacity of about 5 Mb, held on fifty disks, each 24 inches in diameter. This was cutting edge technology in 1956. The device was physically massive, weighed over 1 ton, and was part of a mainframe computer. By the time of the Apollo 11 moon landing in 1969, NASA’s Manned Spacecraft Center in Houston was using mainframe computers that each had up to 8 Mb of memory. Amazingly, the onboard computer for the Apollo 11 moon landing craft, piloted by Neil Armstrong, had a mere 64 kilobytes (Kb) of memory.
Computer technology progressed rapidly and by the start of the personal computer boom in the 1980s, the average hard drive on a PC was 5 Mb when one was included, which was not always the case. This would hold one or two photos or images today. Computer storage capacity increased very quickly and although personal computer storage has not kept up with big data storage, it has increased dramatically in recent years. Now, you can buy a PC with an 8 Tb hard drive or even bigger. Flash drives are now available with 1 Tb of storage, which is sufficient to store approximately 500 hours of movies or over 300,000 photos. This seems a lot until we contrast it with the estimated 2.5 Eb of new data being generated every day.
Once the change from valves to transistors took place in the 1960s the number of transistors that could be placed on a chip grew very rapidly, roughly in accordance with Moore’s Law, which we discuss in the next section. And despite predictions that the limit of miniaturization was about to be reached it continues to be a reasonable and useful approximation. We can now cram billions of increasingly faster transistors onto a chip, which allows us to store ever greater quantities of data, while multi-core processors together with multi-threading software make it possible to process that data.
Moore’s Law
In 1965, Gordon Moore, who became the co-founder of Intel, famously predicted that over the next ten years the number of transistors incorporated in a chip would approximately double every twenty-four months. In 1975, he changed his prediction and suggested the complexity would double every twelve months for five years and then fall back to doubling every twenty-four months. David House, a colleague at Intel, after taking into account the increasing speed of transistors, suggested that the performance of microchips would double every eighteen months, and it is currently the latter prediction that is most often used for Moore’s Law. This prediction has proved remarkably accurate; computers have indeed become faster, cheaper, and more powerful since 1965, but Moore himself feels that this ‘law’ will soon cease to hold.
According to M. Mitchell Waldrop in an article published in the February 2016 edition of the scientific journal Nature, the end is indeed nigh for Moore’s Law. A microprocessor is the integrated circuit responsible for performing the instructions provided by a computer program. This usually consists of billions of transistors, embedded in a tiny space on a silicon microchip. A gate in each transistor allows it to be either switched on or off and so it can be used to store 0 and 1. A very small input current flows through each transistor gate and produces an amplified output current when the gate is closed. Mitchell Waldrop was interested in the distance between gates, currently at 14-nanometer gaps in top microprocessors, and stated that the problems of heat generation caused by closer circuitry and how it is to be effectively dissipated were causing the exponential growth predicted by Moore’s Law to falter, which drew our attention to the fundamental limits he saw rapidly approaching.
A nanometre is 10−9 metre, or one-millionth of a millimetre. To put this in context, a human hair is about 75,000 nanometres in diameter and the diameter of an atom is between 0.1 and 0.5 nanometres. Paolo Gargini, who works for Intel, claimed that the gap limit will be 2 or 3 nanometres and will be reached in the not too distant future—maybe as soon as the 2020s. Waldrop speculates that ‘at that scale, electron behaviour will be governed by quantum uncertainties that will make transistors hopelessly unreliable’. As we will see in Chapter 7, it seems quite likely that quantum computers, a technology still in its infancy, will eventually provide the way forward.
Moore’s Law is now also applicable to the rate of growth for data as the amount generated appears to approximately double every two years. Data increases as storage capacity increases and the capacity to process data increases. We are all beneficiaries: Netflix, smartphones, the Internet of Things (IoT; a convenient way of referring to the vast numbers of electronic sensors connected to the Internet), and the Cloud (a worldwide network of interconnected servers) computing, among others, have all become possible because of the exponential growth predicted by Moore’s Law. All this generated data has to be stored, and we look at this next.
Storing structured data
Anyone who uses a personal computer, laptop, or smartphone accesses data stored in a database. Structured data, such as bank statements and electronic address books, are stored in a relational database. In order to manage all this structured data, a relational database management system (RDBMS) is used to create, maintain, access, and manipulate the data. The first step is to design the database schema (i.e. the structure of the database). In order to achieve this, we need to know the data fields and be able to arrange them in tables, and we then need to identify the relationships between the tables. Once this has been accomplished and the database constructed we can populate it with data and interrogate it using structured query language (SQL).
Clearly tables have to be designed carefully and it would require a lot of work to make significant changes. However, the relational model should not be underestimated. For many structured data applications, it is fast and reliable. An important aspect of relational database design involves a process called normalization which includes reducing data duplication to a minimum and hence reduces storage requirements. This allows speedier queries, but even so as the volume of data increases the performance of these traditional databases decreases.
The problem is one of scalability. Since relational databases are essentially designed to run on just one server, as more and more data is added they become slow and unreliable. The only way to achieve scalability is to add more computing power, which has its limits. This is known as vertical scalability. So although structured data is usually stored and managed in an RDBMS, when the data is big, say in terabytes or petabytes and beyond, the RDBMS no longer works efficiently, even for structured data.
An important feature of relational databases and a good reason for continuing to use them is that they conform to the following group of properties: atomicity, consistency, isolation, and durability, usually known as ACID. Atomicity ensures that incomplete transactions cannot update the database; consistency excludes invalid data; isolation ensures one transaction does not interfere with another transaction; and durability means that the database must update before the next transaction is carried out. All these are desirable properties but storing and accessing big data, which is mostly unstructured, requires a different approach.
Unstructured data storage
For unstructured data, the RDBMS is inappropriate for several reasons, not least that once the relational database schema has been constructed, it is difficult to change it. In addition, unstructured data cannot be organized conveniently into rows and columns. As we have seen, big data is often high-velocity and generated in real-time with real-time processing requirements, so although the RDBMS is excellent for many purposes and serves us well, given the current data explosion there has been intensive research into new storage and management techniques.
In order to store these massive datasets, data is distributed across servers. As the number of servers involved increases, the chance of failure at some point also increases, so it is important to have multiple, reliably identical copies of the same data, each stored on a different server. Indeed, with the massive amounts of data now being processed, systems failure is taken as inevitable and so ways of coping with this are built into the methods of storage. So how are the needs for speed and reliability to be met?
Hadoop Distributed File System
A distributed file system (DFS) provides effective and reliable storage for big data across many computers. Influenced by the ideas published in October 2003 by Google in a research paper launching the Google File System, Doug Cutting, who was then working at Yahoo, and his colleague Mike Cafarella, a graduate student at the University of Washington, went to work on developing the Hadoop DFS. Hadoop, one of the most popular DFS, is part of a bigger, open-source software project called the Hadoop Ecosystem. Named after a yellow soft toy elephant owned by Cutting’s son, Hadoop is written in the popular programming language, Java. If you use Facebook, Twitter, or eBay, for example, Hadoop will have been working in the background while you do so. It enables the storage of both semi-structured and unstructured data, and provides a platform for data analysis.
When we use Hadoop DFS, the data is distributed across many nodes, often tens of thousands of them, physically situated in data centres around the world. Figure 4 shows the basic structure of a single Hadoop DFS cluster, which consists of one master NameNode and many slave DataNodes.
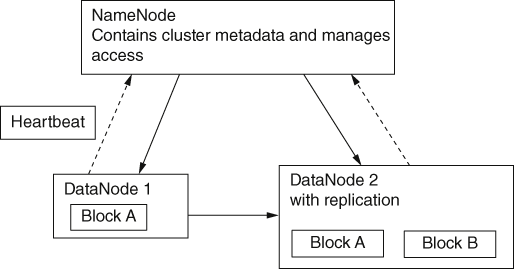
4. Simplified view of part of a Hadoop DFS cluster.
The NameNode deals with all requests coming in from a client computer; it distributes storage space, and keeps track of storage availability and data location. It also manages all the basic file operations (e.g. opening and closing files) and controls data access by client computers. The DataNodes are responsible for actually storing the data and in order to do so, create, delete, and replicate blocks as necessary.
Data replication is an essential feature of the Hadoop DFS. For example, looking at Figure 4, we see that Block A is stored in both DataNode 1 and DataNode 2. It is important that several copies of each block are stored so that if a DataNode fails, other nodes are able to take over and continue with processing tasks without loss of data. In order to keep track of which DataNodes, if any, have failed, the NameNode receives a message from each, called a Heartbeat, every three seconds, and if no message is received it is assumed that the DataNode in question has ceased to function. So if DataNode 1 fails to send a Heartbeat, DataNode 2 will become the working node for Block A operations. The situation is different if the NameNode is lost, in which case the inbuilt backup system needs to be employed.
Data is written to a DataNode only once but will be read by an application many times. Each block is usually only 64 Mb, so there are a lot of them. One of the functions of the NameNode is to determine the best DataNode to use given the current usage, ensuring fast data access and processing. The client computer then accesses the data block from the chosen node. DataNodes are added as and when required by the increased storage requirements, a feature known as horizontal scalability.
One of the main advantages of Hadoop DFS over a relational database is that you can collect vast amounts of data, keep adding to it, and, at that time, not yet have any clear idea of what you want to use it for. Facebook, for example, uses Hadoop to store its continually growing amount of data. No data is lost, as it will store anything and everything in its original format. Adding DataNodes as required is cheap and does not require existing nodes to be changed. If previous nodes become redundant, it is easy to stop them working. As we have seen, structured data with identifiable rows and columns can be easily stored in a RDBMS while unstructured data can be stored cheaply and readily using a DFS.
NoSQL databases for big data
NoSQL is the generic name used to refer to non-relational databases and stands for Not only SQL. Why is there a need for a non-relational model that does not use SQL? The short answer is that the non-relational model allows us to continually add new data. The non-relational model has some features that are necessary in the management of big data, namely scalability, availability, and performance. With a relational database you cannot keep scaling vertically without loss of function, whereas with NoSQL you scale horizontally and this enables performance to be maintained. Before describing the NoSQL distributed database infrastructure and why it is suitable for big data, we need to consider the CAP Theorem.
CAP Theorem
In 2000, Eric Brewer, a professor of computer science at the University of California Berkeley, presented the CAP (consistency, availability, and partition tolerance) Theorem. Within the context of a distributed database system, consistency refers to the requirement that all copies of data should be the same across nodes. So in Figure 4, for example, Block A in DataNode 1 should be the same as Block A in DataNode 2. Availability requires that if a node fails, other nodes still function—if DataNode 1 fails, then DataNode 2 must still operate. Data, and hence DataNodes, are distributed across physically separate servers and communication between these machines will sometimes fail. When this occurs it is called a network partition. Partition tolerance requires that the system continues to operate even if this happens.
In essence, what the CAP Theorem states is that for any distributed computer system, where the data is shared, only two of these three criteria can be met. There are therefore three possibilities; the system must be: consistent and available, consistent and partition tolerant, or partition tolerant and available. Notice that since in a RDMS the network is not partitioned, only consistency and availability would be of concern and the RDMS model meets both of these criteria. In NoSQL, since we necessarily have partitioning, we have to choose between consistency and availability. By sacrificing availability, we are able to wait until consistency is achieved. If we choose instead to sacrifice consistency it follows that sometimes the data will differ from server to server.
The somewhat contrived acronym BASE (Basically Available, Soft, and Eventually consistent) is used as a convenient way of describing this situation. BASE appears to have been chosen in contrast to the ACID properties of relational databases. ‘Soft’ in this context refers to the flexibility in the consistency requirement. The aim is not to abandon any one of these criteria but to find a way of optimizing all three, essentially a compromise.
The architecture of NoSQL databases
The name NoSQL derives from the fact that SQL cannot be used to query these databases. So, for example, joins such as the one we saw in Figure 4 are not possible. There are four main types of non-relational or NoSQL database: key−value, column-based, document, and graph—all useful for storing large amounts of structured and semi-structured data. The simplest is the key−value database, which consists of an identifier (the key) and the data associated with that key (the value) as shown in Figure 5. Notice that ‘value’ can contain multiple items of data.

5. Key−value database.
Of course, there would be many such key−value pairs and adding new ones or deleting old ones is simple enough, making the database highly scalable horizontally. The primary capability is that we can look up the value for a given key. For example, using the key ‘Jane Smith’ we are able to find her address. With huge amounts of data, this provides a fast, reliable, and readily scalable solution to storage but it is limited by not having a query language. Column-based and document databases are extensions of the key−value model.
Graph databases follow a different model and are popular with social networking sites as well as being useful in business applications. These graphs are often very large, particularly when used by social networking sites. In this kind of database, the information is stored in nodes (i.e. vertices) and edges. For example, the graph in Figure 6 shows five nodes with the arrows between them representing relationships. Adding, updating, or deleting nodes changes the graph.
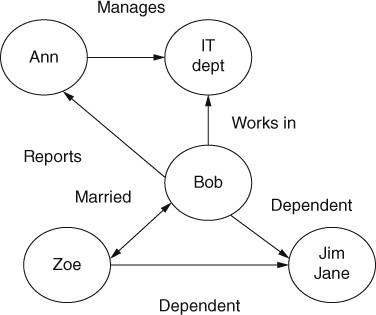
6. Graph database.
In this example, the nodes are names or departments, and the edges are the relationships between them. Data is retrieved from the graph by looking at the edges. So, for example, if I want to find ‘names of employees in the IT department who have dependent children’, I see that Bob fulfils both criteria. Notice that this is not a directed graph—we do not follow the arrows, we look for links.
Currently, an approach called NewSQL is finding a niche. By combining the performance of NoSQL databases and the ACID properties of the relational model, the aim of this latent technology is to solve the scalability problems associated with the relational model, making it more useable for big data.
Cloud storage
Like so many modern computing terms the Cloud sounds friendly, comforting, inviting, and familiar, but actually ‘the Cloud’ is, as mentioned earlier, just a way of referring to a network of interconnected servers housed in data centres across the world. These data centres provide a hub for storing big data.
Through the Internet we share the use of these remote servers, provided (on payment of a fee) by various companies, to store and manage our files, to run apps, and so on. As long as your computer or other device has the requisite software to access the Cloud, you can view your files from anywhere and give permission for others to do so. You can also use software that ‘resides’ in the Cloud rather than on your computer. So it’s not just a matter of accessing the Internet but also of having the means to store and process information—hence the term ‘Cloud computing’. Our individual Cloud storage needs are not that big, but scaled up the amount of information stored is massive.
Amazon is the biggest provider of Cloud services but the amount of data managed by them is a commercial secret. We can get some idea of their importance in Cloud computing by looking at an incident that occurred in February 2017 when Amazon Web Services’ Cloud storage system, S3, suffered a major outage (i.e. service was lost). This lasted for approximately five hours and resulted in the loss of connection to many websites and services, including Netflix, Expedia, and the US Securities and Exchange Commission. Amazon later reported human error as the cause, stating that one of their employees had been responsible for inadvertently taking servers offline. Rebooting these large systems took longer than expected but was eventually completed successfully. Even so, the incident highlights the susceptibility of the Internet to failure, whether by a genuine mistake or by ill-intentioned hacking.
Lossless data compression
In 2017, the widely respected International Data Corporation (IDC) estimates that the digital universe totals a massive 16 zettabytes (Zb) which amounts to an unfathomable 16 x 1021 bytes. Ultimately, as the digital universe continues to grow, questions concerning what data we should actually save, how many copies should be kept, and for how long will have to be addressed. It rather challenges the raison d’être of big data to consider purging data stores on a regular basis or even archiving them, as this is in itself costly and potentially valuable data could be lost given that we do not necessarily know what data might be important to us in the future. However, with the huge amounts of data being stored, data compression has become necessary in order to maximize storage space.
There is considerable variability in the quality of the data collected electronically and so before it can be usefully analysed it must be pre-processed to check for and remedy problems with consistency, repetition, and reliability. Consistency is clearly important if we are to rely on the information extracted from the data. Removing unwanted repetitions is good housekeeping for any dataset, but with big datasets there is the additional concern that there may not be sufficient storage space available to keep all the data. Data is compressed to reduce redundancy in videos and images and so reduce storage requirements and, in the case of videos, to improve streaming rates.
There are two main types of compression—lossless and lossy. In lossless compression all the data is preserved and so this is particularly useful for text. For example, files with the extension ‘.ZIP’, have been compressed without loss of information so that unzipping them returns us to the original file. If we compress the string of characters ‘aaaaabbbbbbbbbb’ as ‘5a10b’ it is easy to see how to decompress and arrive at the original string. There are many algorithms for compression but it is useful first to consider how data is stored without compression.
ASCII (American Standard Code for Information Interchange) is the standard way of encoding data so that it can be stored in a computer. Each character is designated a decimal number, its ASCII code. As we have already seen, data is stored as a series of 0s and 1s. These binary digits are called bits. Standard ASCII uses 8 bits (also defined as 1 byte) to store each character. For example, in ASCII the letter ‘a’ is denoted by the decimal number 97 which converts to 01100001 in binary. These values are looked up in the standard ASCII table, a small part of which is given at the end of the book. Upper-case letters have different ASCII codes.
Consider the character string ‘added’ which is shown coded in Figure 7.

7. A coded character string.
So ‘added’ takes 5 bytes or 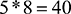 bits of storage. Given Figure 7, decoding is accomplished using the ASCII code table. This is not an economical way of encoding and storing data; 8 bits per character seems excessive and no account is taken of the fact that in text documents some letters are used much more frequently than others. There are many lossless data compression models, such as the Huffman algorithm, which uses less storage space by variable length encoding, a technique based on how often a particular letter occurs. Those letters with the highest occurrence are given shorter codes.
bits of storage. Given Figure 7, decoding is accomplished using the ASCII code table. This is not an economical way of encoding and storing data; 8 bits per character seems excessive and no account is taken of the fact that in text documents some letters are used much more frequently than others. There are many lossless data compression models, such as the Huffman algorithm, which uses less storage space by variable length encoding, a technique based on how often a particular letter occurs. Those letters with the highest occurrence are given shorter codes.
Taking the string ‘added’ again we note that ‘a’ occurs once, ‘e’ occurs once, and ‘d’ occurs three times. Since ‘d’ occurs most frequently, it should be assigned the shortest code. To find the Huffman code for each letter we count the letters of ‘added’ as follows:
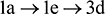
Next, we find the two letters that occur least frequently, namely ‘a’ and ‘e’, and we form the structure in Figure 8, called a binary tree. The number 2 at the top of the tree is found by adding the number of occurrences of the two least frequent letters.
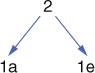
8. A binary tree.
In Figure 9, we show the new node representing three occurrences of the letter ‘d’.
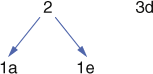
9. The binary tree with a new node.
Figure 9 shows the completed tree with total number of letter occurrences at the top. Each edge of the tree is coded as either 0 or 1, as shown in Figure 10, and the codes are found by following the paths up the tree.

10. Completed binary tree.
So ‘added’ is coded as 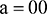 ,
, 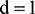 , ,
, , 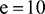 , , which gives us 0011101. Using this method we see that 3 bits are used for storing the letter ‘d’, 2 bits for letter ‘a’, and 2 bits for letter ‘e’, giving a total of 7 bits. This is a big improvement on the original 40 bits.
, , which gives us 0011101. Using this method we see that 3 bits are used for storing the letter ‘d’, 2 bits for letter ‘a’, and 2 bits for letter ‘e’, giving a total of 7 bits. This is a big improvement on the original 40 bits.
A way of measuring the efficiency of compression is to use the data compression ratio, which is defined as the uncompressed size of a file divided by its compressed size. In this example, 45/7 is approximately equal to 6.43, a high compression rate, showing good storage savings. In practice these trees are very large and are optimized using sophisticated mathematical techniques. This example has shown how we can compress data without losing any of the information contained in the original file and it is therefore called lossless compression.
Lossy data compression
In comparison, sound and image files are usually much larger than text files and so another technique called lossy compression is used. This is because, when we are dealing with sound and images, lossless compression methods may simply not result in a sufficiently high compression ratio for data storage to be viable. Equally, some data loss is tolerable for sound and images. Lossy compression exploits this latter feature by permanently removing some data in the original file so reducing the amount of storage space needed. The basic idea is to remove some of the detail without overly affecting our perception of the image or sound.
For example, consider a black and white photograph, more correctly described as a greyscale image, of a child eating an ice-cream at the seaside. Lossy compression removes an equal amount of data from the image of the child and that of the sea. The percentage of data removed is calculated such that it will not have a significant impact on the viewer’s perception of the resulting (compressed) image—too much compression will lead to a fuzzy photo. There’s a trade-off between the level of compression and quality of picture.
If we want to compress a greyscale image, we first divide it into blocks of 8 pixels by 8 pixels. Since this is a very small area, all the pixels are generally similar in tone. This observation, together with knowledge about how we perceive images, is fundamental to lossy compression. Each pixel has a corresponding numeric value between 0 for pure black and 255 for pure white, with the numbers between representing shades of grey. After some further processing using a method called the Discrete Cosine Algorithm, an average intensity value for each block is found and the results compared with each of the actual values in a given block. Since we are comparing these actual values to the average most of them will be 0, or 0 when rounded. Our lossy algorithm collects all these 0s together, which represent the information from the pixels that is less important to the image. These values, corresponding to high frequencies in our image, are all grouped together and the redundant information is removed, using a technique called quantization, resulting in compression. For example if out of sixty-four values each requiring 1 byte of storage, we have twenty 0s, then after compression we need only 45 bytes of storage. This process is repeated for all the blocks that make up the image and so redundant information is removed throughout.
For colour images the JPEG (Joint Photographic Experts Group) algorithm, for example, recognizes red, blue, and green, and assigns each a different weight based on the known properties of human visual perception. Green is weighted greatest since the human eye is more perceptive to green than to red or blue. Each pixel in a colour image is assigned a red, blue, and green weighting, represented as a triple <R,G,B>. For technical reasons, <R,G,B> triples are usually converted into another triple, <YCbCr> where Y represents the intensity of the colour and both Cb and Cr are chrominance values, which describe the actual colour. Using a complex mathematical algorithm it is possible to reduce the values of each pixel and ultimately achieve lossy compression by reducing the number of pixels saved.
Multimedia files in general, because of their size, are compressed using lossy methods. The more compressed the file, the poorer the reproduction quality, but because some of the data is sacrificed, greater compression ratios are achievable, making the file smaller.
Following an international standard for image compression first produced in 1992 by the JPEG, the JPEG file format provides the most popular method for compressing both colour and greyscale photographs. This group is still very active and meets several times a year.
Consider again the example of a black and white photograph of a child eating an ice-cream at the seaside. Ideally, when we compress this image we want the part featuring the child to remain sharp, so in order to achieve this we would be willing to sacrifice some clarity in the background details. A new method, called data warping compression, developed by researchers at Henry Samueli School of Engineering and Applied Science, UCLA, now makes this possible. Those readers interested in the details are referred to the Further reading section at the end of the book.
We have seen how a distributed data file system can be used to store big data. Problems with storage have been overcome to the extent that big data sources can now be used to answer questions that previously we could not answer. As we will see in Chapter 4, an algorithmic method called MapReduce is used for processing data stored in the Hadoop DFS.