Operating a Cloud
Abstract
The goal of operating a cloud is to deliver cloud services efficiently, reliably, cost-effectively, and securely. This can be difficult to achieve and success depends on several supporting activities. Overall, though, the way an organization benefits from cloud computing will depend on how it assesses its information and communication resources and how it envisions its transition to cloud computing. Although private clouds can achieve immense scale and can serve many internal customers, most private clouds will likely be on the small side. This gives public clouds several advantages in terms of return on investment for tools and security capabilities that are expensive or require an investment in expertise to properly implement and operate. Earlier chapters surveyed current cloud services and delivery models and examined cloud security and architecture. This chapter picks up on the knowledge imparted in those earlier chapters, and focuses on operating a cloud from a security perspective.
Keywords
planning; architecture; operations; ICT; ITIL; training; SOC; release; threat; incident
Chapter Points
Throughout this book and in several ways, we have stated that cloud computing is an evolution in IT models, the adoption of which has far-reaching consequences. On one hand, we gain advantages such as ease and speed of deployment along with radically lower capital costs. Therefore, cloud adopters can face lower risks for new IT projects. Using a public cloud, anyone with an idea that requires IT infrastructure can act on it without actually acquiring infrastructure or hiring a staff. If you have an Internet connection, a laptop, and a credit card, you can gain access to unprecedented amounts of virtual IT infrastructure—and with a wait time that is measured in minutes rather than the weeks or months that it takes to acquire and install traditional infrastructure.
On the other hand, the downside of public cloud adoption largely has to do with the reduced flexibility inherent in public cloud services, along with concerns related to giving up physical control over information resources. And there is the roach motel, or lock-in, factor as well, since not all public cloud services will make it easy for a customer to move data to another provider.
Too often, traditional IT does not enjoy a synergistic relationship with other business functions. It often seems that other business departments coerce IT into bending over backward to deliver a botanical garden of unique and difficult-to-deliver or -sustain solutions. At other times, powerful IT departments push back against even reasonable business requests by either delaying or denying requests. But cloud computing is forcing change here, and the catalog of services needs to be clearly defined, as will associated SLAs. Consumers of cloud resources won’t be filling out triplicate forms only to wait weeks or months for a server to be delivered. Not exactly. In the realm of private clouds, consumers of IT services will expect to get their virtual servers from a private cloud as fast as they can from a public cloud.
With these transitions and with the nature of the self-service contract for cloud services, IT will need to become a greater partner of the business overall—showing the larger organization how to get more for less. But we should also expect that the rise of cloud computing and the changes it brings will likely trend toward an overall reduction in infrastructure IT personnel. That is only natural, given the degree of automation in the way IT services are delivered with clouds.
In earlier chapters, we defined cloud computing and surveyed current cloud services and delivery models. We investigated security concerns and issues with cloud computing, and we addressed many of those by closely examining cloud security and architecture. At various points, we touched on the importance of security operations and the relationship between architecture, implementation, and ongoing security costs. This chapter is focused on the operation of a cloud from a security perspective.
The goal of operating a cloud is to deliver cloud services in an efficient, reliable, cost-effective, and secure manner. This goal can be very difficult to achieve, and it depends on many supporting activities. Architecture drives implementation and ongoing costs, including operational security costs. Efficient and secure operation is predicated on sound planning. Reactive security measures are a disruptive and costly consequence of ineffective planning. Figure 7.1 depicts this overall relationship.
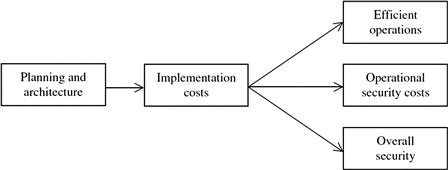
Unfortunately, upfront planning and architecture are often given short shrift due to a combination of factors. One common excuse is that it is too expensive in terms of time and resources and perhaps unnecessary if you already know what you need to do. But experience generally shows that investment in planning and architecture can pay back savings, not only in operational costs but in protecting schedules from otherwise unanticipated issues that arise. In an imperfect world, there seem to be two choices: Spend too much time planning and delay efforts from the start, or spend insufficient time planning and experience delays or crisis later in the schedule. Rarely does a team follow a Goldilocks path.
From Architecture to Efficient and Secure Operations
Security is a key factor that is associated with all aspects of cloud operations. Long before a security engineer deactivates a former employee’s various infrastructure accounts, reviews vulnerability scan results, or puzzles out which Snort events warrant concern, the efficiencies around these eventual actions are already constrained. The foundation of subsequent operational processes is cast when the architecture of the cloud is defined.
It is certainly true that a small prototype or department-level cloud can be designed and subsequently made operational with modest effort. With a small number of users and modest VM and storage resources, such a cloud will not present the efficiency demands on its operators that an enterprise-level or public cloud will. But even a prototype or department-level cloud will evidence security issues in the absence of ample planning before the cloud is made operational. These security issues can easily escalate and will demand increasing attention and resources when cloud implementations become larger.
To complicate matters, VM management alone can quickly devolve into virtual server sprawl, and valuable resources and work can become lost or destroyed as a larger cloud progresses from its initial state into an operational one whereby resource usage flexes and control is lost over virtual and even real IT assets.
Just as architecture casts the foundation for subsequent operational processes, so does the implementation and configuration of infrastructure. A cloud is a highly complex and dynamic composition that rides on various enabling technologies and components. The way these are designed, implemented, and even configured will go a long way toward enabling efficient and secure operations.
The Scope of Planning
It makes perfect sense to start the design and architecture phases of planning for a cloud by outlining the operational activities that will take place after the cloud is brought online. Planning for security operations is best done in conjunction with planning other aspects of operations. Security operations not only involve realms such as configuration management, service desk, problem management, capacity management, and service delivery, but security operations are often tightly coupled with these other aspects of operations.
The IT Infrastructure Library (ITIL1) is recognized for the demonstrated value it offers in terms of the detailed descriptions of the primary IT practices that an IT organization will likely face in operation. ITIL is all about capturing and organizing best practices around the full scope of IT services management, IT development, and IT operations. Hence, ITIL makes for an excellent starting point for any organization that is in the planning or early design phases of a cloud build. Of course, the focus of ITIL is on the operation and management of IT, but it has great value when we are planning and building infrastructure and defining processes that will soon form the cornerstone of daily operations.
ITIL Security Management is derived from the ISO/IEC 27002 code of practice for information security management. The goal of Security Management is to ensure appropriate information security; in other words, ensuring confidentiality, integrity, and availability of information resources. ITIL is published as a series of books, each of which covers specific practices. The overall collection is organized into eight logical sets that are grouped according to related process guidelines. In its present form, ITIL, version 2, is organized as follows:
Although security does have its own section, planning and architecting for security also require understanding the other areas. Going further, sound security entails mature security practices that are integrated with other practice areas. A mature and effective operations team appreciates this on a daily basis and leverages the synergies gained by cross-domain teams. In other words, when security team members contribute their expertise to multiple teams, they gain valuable understanding of activities and issues beyond security.
Physical Access, Security, and Ongoing Costs
To take operational costs to their lowest possible levels, physical access to the cloud IT infrastructure must be constrained on the basis of a documented need. Since every individual with access represents additional risk to the organization, the number of individuals who should have regular access to a datacenter should be kept low.
Unescorted access should be limited to individuals who have undergone equivalent employment screening as regular cloud staff with physical access. But even escorted access invites unnecessary risk; for example, allowing tours of visitors in close proximity to cabling, power cords, cute little buttons, and blinking lights is inviting an accidental cable loosening brush or minor outage. What is really interesting here is that when the cloud infrastructure is designed and built out for operational efficiencies, then all physical access should be fairly limited for even operational personnel—physical access simply should not be necessary on a daily basis; lights-out operations should be the goal.
Datacenters are equipped with extensive video surveillance and a foundation of environmental sensors that will detect water, smoke, humidity, and temperature. These can be further augmented with additional sensors and high-resolution cameras that can be remotely trained on critical gear to serve as a means to remotely view visual diagnostic lights or displays. Reducing the need for operations personnel to have constant physical presence will lower operations costs, high-resolution cameras are an investment that supports minimal visits to the datacenter, and the recordings from these cameras can serve as a legal record if needed. The longer the retention of video data, the better, because at least one operations team has found it necessary to review the past month of video surveillance to determine whether a backup tape was removed from an archive cage when written records were neglected by personnel.
Logical and Virtual Access
As important as physical access controls are, given that clouds are managed over the network, limiting access controls to the physical realm would be profoundly silly. No number of sophisticated multifactor physical locks or high-resolution video cameras will prevent or record operations personnel as they engage in their work managing network devices, servers, and storage devices. The use of an identity system to define and manage access by personnel to specific devices and functions is an effective way to centralize access control data. But logical controls alone are not ample to limit access to servers and other cloud infrastructure. The use of network isolation between different realms within the cloud infrastructure will go a long way toward not only limiting the reach of a hacker, but isolation will also limit the scope that authorized operations personnel have. Putting it differently: Security controls form the lowest layer of protection, and network isolation provides a second protection mechanism. These reinforce each other and provide a degree of insurance against ham handing configuration in either realm.
Personnel Security
Not only must physical and logical access to a cloud be limited to personnel with an operational need for access, but all such individuals must also meet personnel policies. Personnel must be screened before being granted clearance for access, access lists must be maintained in a disciplined manner, periodic reviews of continuing access needs must be made, and all operations personnel with either physical or logical access should undergo at least annual certification and refresher training. Likewise, all personnel policies and procedures should be subject to continuous evaluation, especially in terms of user access rights and privileges. When personnel leave the operations team, their access must be immediately revoked; doing that effectively entails the use of centralized identify management.
It is worthwhile adding that while personnel security is necessary it will not stop insider threats. What can be done about that? For instance, security administrators should have their work independently tested against expected outcomes. This is yet another example of the mosaic of activities that together form an ecosystem that encourages and enables security.
Training
Specific training for IT personnel is important for all staff, especially the cloud operations support personnel—which includes not only infrastructure staff but also the various administrators and staff associated with other aspects of operations. The cloud operations staff should have appropriate training to ensure that they adhere to all company policies, including security policies. With a potentially large number of virtualized servers, the potential to compromise multiple servers or inadvertently perform a denial of service is high. This will apply not just when the service is fully operational, but in the initial and ongoing buildup as well. The complexity and scope of a large cloud demand that personnel be more broadly and more deeply experienced than the typical enterprise systems administrator commonly is.
Categories of Cloud Security Staff
In general terms, the following types of security personnel are associated with the operation of a cloud:
■ Physical security or datacenter facility staff
■ Security analysts responsible for monitoring or associated with a physical or virtual Security Operations Center (SOC)
■ Scanning or penetration-testing staff
■ Security systems architects and engineers
■ Chief security officer and other security management roles
■ Security research analysts, security automation developers, and security content developers
From the Physical Environment to the Logical
The physical datacenter environment serves as the underlying support structure for a cloud. This is as true for a small cloud that resides in a server closet as it is for a large infrastructure cloud or for a public cloud that spans several physical datacenter locations. This physical support environment must be secure and safe if the cloud is to be reliable and secure. That alone represents a series of problems that must be addressed if power, Internet connectivity, other communications, and physical access are going to be reliable and safe.
The amount of advance planning that needs to be done for the datacenter alone is significant—in fact, it is the rare datacenter that gets all the physical components right, as evidenced by gaps that are exposed in contingency plans when things go wrong. This forms the physical security boundary, inside of which one manages the cloud enabling IT infrastructure.
Between the physical perimeter of the datacenter and this IT gear are multiple layers of physical access controls. Likewise, the typical complex computing and storage infrastructure will also evidence a number of layers of logical separation. Each of these physical and logical boundaries is an impediment to efficiency in operating the cloud, but they exist to prevent and to isolate the scope of damage that unauthorized access could otherwise lead to. These boundaries should be designed not only for protection, but also with ongoing costs in mind. Inefficiencies in design and associated operational processes will undermine the cost efficiencies of managing a highly dynamic cloud. If a cloud is going to deliver on its promises of improved efficiencies, even physical boundaries must be well designed.
Bootstrapping Secure Operations
It would be unrealistic to assume that a cloud can be operated securely without verifying the origin and security of most of the components that comprise that cloud. By example, if a piece of software to control cloud infrastructure is introduced into the infrastructure without vetting its security, we clearly risk compromising the infrastructure with malware. Since much software used today is open source, there is a real potential for installing software by downloading it directly from the Internet, without effective control over authenticity or security. That is simply not appropriate when we’re building a system for production. The bottom line is that security operations depend on processes and procedures that support security—even before a cloud is placed in operation.
Efficiency and Cost
In security operations, there are several kinds of activities that consume time and yet are largely avoidable. There are other security operations activities that are not avoidable but that can be streamlined. As to the first category (time consuming and avoidable), the ability of human beings to invent unnecessary work can only explain part of the problem. Identifying, assessing, tracking, remediating, and reporting on vulnerabilities are somewhat akin to wildfire fighting. Several strategies are possible: We can seek to reduce flammable underbrush (vulnerabilities), or we can employ fire spotters to identify an outbreak of fire. Clearly, it will be impossible to prevent all fires, but if we do not invest in some forms of prevention, we will spend more time identifying and reporting on a larger number of fires.
Every computing environment will periodically discover newly exposed vulnerabilities. Removing all vulnerabilities as they are discovered may seem appropriate, yet it is not universally possible or always reasonable. Some may be mitigated by other factors (or by compensating controls), and some are sometimes unavoidable when specific functionality is necessary. However, experience has shown that the equivalent of clearing out the underbrush in computing environments is not only possible but a best practice. What does this practice look like?
Code scanning for vulnerabilities early in the development cycle is a proven approach to reduce ongoing security costs. Likewise, developing reasonable guidelines and standards for development, for implementation, and for operations brings enduring value by preventing the accumulation of flammable tinder in the code base, in the infrastructure, and in operations overall. Getting back to the previous point about inventing unnecessary work, if we do not aggressively reduce this sort of combustible material in a cloud implementation, we may find that management will demand report after detailed report as to the number and kind of residual vulnerabilities and the planned schedule for remediating each of them. Isn’t it wiser to avoid some problems like this to begin with?
This should be especially evident with cloud computing, where our collective desire to drive down operating costs should inculcate an aversion toward anything that leads to repeated and avoidable risk, work, and cost. It turns out that if you strive toward greater efficiency in cost, you will cast a cost-saving eye toward the cloud computing infrastructure and operations teams. And once your gaze settles on the headcount there, you should be thinking about how to not only grow your business but also to reduce your costs by making your operations more effective. Limiting ongoing costs is highly correlated with the need to avoid situations that are avoidable to begin with.
As stated, other security operations activities may not be avoidable, but many can be streamlined and made more efficient. By example, one of the periodic and necessary activities that security operations will perform is vulnerability scanning. After each scan, the results must be assessed, which involves several discrete steps, including identifying false positives. This entire process can be managed as an unstructured series of activities, or the process can be made more mature and streamlined.
One way to do that is to generate vulnerability information in a machine-readable format or at the least in a representation that can be managed in a semiautomated manner. Figure 7.2 depicts such an integrated approach in managing vulnerability scan data. Note that the first step of the process is the selection of scanning parameters that are appropriate for the environment and the scan target. If the scan is to be performed against a pure test environment, the gloves can be taken off and the scanner can throw everything in its arsenal at the target—since it is not a production target, destructive testing will reveal valuable information that can be applied to the analogous production environment in order to harden it and avoid a production outage. If the target has been scanned previously, it is reasonable to start with scan parameters that were previously used—unless, of course, new tests are available since the last scan. As Figure 7.2 shows, the next steps are to initiate the scan and collect scan results. These results will include not only vulnerability data and associated results but also a measure of how long the scan took to run. This itself is useful information to collect over many scans as the target itself changes. The scan results are then converted or captured in a database in order to perform analysis of the current results and to assess any changes from previous results. This is relatively easy to do with a database and is otherwise too time consuming and detailed to perform effectively manually.
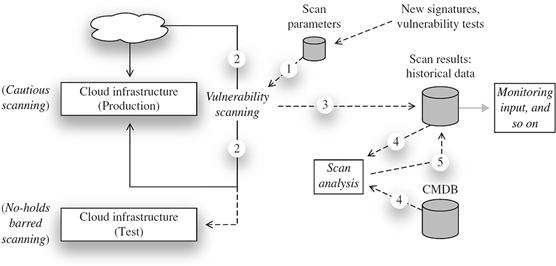
Once captured and analyzed, such vulnerability data is scrubbed and assessed, and it can be reported on using either canned report routines or ad hoc queries. It should be noted that the analysis that can be performed can be greatly enhanced if the database routines also have access to CMDB-managed information about the cloud infrastructure itself (as further discussed in the next section). In this manner, information associated with an IP address can be used to supply the context behind a specific alert, and an alert associated with a Web server can be categorized as a false positive, whereas the same alert associated with a directory server would be verified as critical.
Security Operations Activities
There is a direct relationship among release management, configuration management, change management, and security. However, this relationship often falls prey to sloppy procedures, a lack of formal controls, or ineffective reviews of proposed changes. CM and change control demand a degree of discipline in process that includes security involvement, not only for approvals but in planning. The earlier that security engineers are involved in planning, the less chance there is that such changes will bring unintended security risks.
Security engineers or architects can identify specific steps and procedures that can greatly improve not only security but also operational reliability. In many ways, in operations, security is a set of qualities that contribute to availability and integrity. One of the hallmarks of effective security is an economy of functionality that is best expressed by the saying keep it simple. Complex steps and procedures are generally not optimized, and by their nature, they present greater opportunity for error and failure. By contrast, simpler and more atomic steps can be more robust and reliable.
Server Builds
Most environments have a number of different standards for server builds. For instance, with a Microsoft Windows Server build, you may face a number of server options that start with 32 or 64 bits, and from there you may install one or more from among Internet Information Server (IIS), anonymous File Transfer Protocol (FTP) server, Microsoft Silverlight, Dynamic Host Configuration Protocol (DHCP), and Domain Name System (DNS). The options go on, and although you could have a server build with all the options installed, this does not result in a hardened build or optimum security. Having unlimited options also makes for greater operational work, so with a standard server build, you need to find a balance between flexibility and security. But this should easily be able to be kept to a small number of builds.
For a private cloud, you might want to set guidelines for the use of the environment. For instance, a set of standard operating system builds should be considered; these can be developed and tested to ensure that users can easily and quickly deploy them. These may well be a mix of Linux and Microsoft Windows servers, such as:
■ Linux build: Red Hat with MySQL Server
■ Linux build: Ubuntu with Apache Web Server
Each of these can be prebuilt and installed with the standard applications that your enterprise requires, such as antivirus, patch updates, auditing software, and so on. If you are deploying a production and development environment, these rules might be less stringent for the development environment, but any build outside the norm for your enterprise may need to be formally approved.
A brief aside about development environments: There is simply no excuse for perpetrating the disconnect between development and production environments. Cloud computing is an effective answer to this persistent problem. There is simply no reason for a development environment to be anything less than production from day one. The developers are restricted in the same ways they will be restricted in production and can manage their ways of doing things to leverage cloud advantages (such as always rolling new replacement versions of software forward and never back-patching).
Each server instance should be scaled to ensure that it falls within limits that you have set. Putting too many virtual instances on a single CPU server that all require a large CPU utilization will not yield satisfactory results. Asking the user for an indication of CPU and memory load and storage volumes anticipated without setting limits or charging is unlikely to be successful. If you offer a virtual instance on either a 32-bit platform with 2GB of memory or on a 64-bit platform with 6GB of memory, the user will likely choose the higher-performing form unless there is a cost associated. The cost needs to be sensible; otherwise, users will opt for the lower-performing instance, and this might end up causing local denial-of-service issues due to the overloaded server. The bottom line? There need to be hard restrictions on all virtual resources.
Server Updates
No matter what platform your servers run, there will be regular updates to the operating system and the applications. Operational procedures should specify how and when you perform updates on servers. Depending on the cloud architecture and the method of provisioning, you may have a lot of servers to patch. However, with a virtual environment, it makes far more sense to migrate applications from an older VM to a new updated VM. The stage is then set for proper testing of the new version before deployment, availability recovery is automatically tested, and the serious problems that regularly occur (and are always underestimated) during patching are eliminated. And it’s not just the virtual environments that should be managed this way. It might take a bit longer, but automated provisioning (again, started in development) will allow the same kind of management of the base OSs and/or hypervisors.
Users and operators may well consider it easier to deploy and manage applications on an individual basis, particularly those that are known to have a defined life. At the end of life, these virtual servers can just be removed and the application terminates with no interaction with any other server. This can also make the internal cloud work in a similar manner as the external cloud by turning applications on and off as needed, which will improve the overall performance of the cloud.
As you are deploying a cloud infrastructure, the inference is that you have a relatively large number of servers to deploy. The deployment of patches will therefore require thought and discussion. The overall security of the cloud needs to be maintained, but this does not mean that each and every patch that is released has to be deployed. Taking Microsoft as an example, the company releases a set of patches on the second Tuesday of each month. These patches are rated by Microsoft as critical, important, and so on; however, the patches may be rated differently by your company due to many possible factors. Updates that are consider essential will need to be rolled out, possibly with a goal of a few days for your entire landscape of servers.
Depending on the virtualization software you are using, various automated patch management tools can be used to can enable the updating process. Using VMware (www.vmware.com), for instance, you can deploy patch management tools by VMware to manage the patching of the host and the virtual instance. If the investment you are making in the internal cloud infrastructure is for a long period of time with sufficient numbers of servers, some form of automation in the update process will likely be cost effective.
Business Continuity, Backup, and Recovery
To ensure that cloud services will be available to customers and users, we employ business continuity, a term that refers to a broad set of activities that are performed on an ongoing basis to maintain services and availability. Business continuity is predicated on standards, policies, guidelines, and procedures that allow for continued operation, regardless of the circumstances. Disaster recovery is a subset of business continuity and is focused on IT systems and data.
From an operational standpoint, the activities that are associated with business continuity will be woven into other operational procedures and processes, including the performance of both continual backups and data mirroring to offsite recovery systems. Creating backups should be seen as a form of ongoing insurance. Although backup data may be safely stored offsite, it may be very time consuming to reconstitute a system from such storage. What is more effective from a time-to-recover perspective is the use of multiple instances that both share the processing load but that have excess capacity to allow for any one site or instance to be taken offline, either for maintenance or when due to a service interruption. If such excess capacity is to serve as a failover capacity, the data that is associated with processing at the affected site must be continuously mirrored to such additional sites or instances.
Epic Fail
In the early 1980s, in a classified datacenter located in the Pentagon, a night-shift computer operator set about his duties of backing up a critical system. This was the day of washing machine–sized disk drives with motorcycle tire–sized removable disks. The way the backup process was designed, the system to be backed up would first be taken offline. Then a backup disk would be mounted into a second drive, and the backup program (DSC on the Digital Equipment PDP 11/70) was run. As DSC ran, the contents of the source disk would be copied to the target or backup disk. When the process was completed, the original source disk would be unmounted and put on a storage shelf (for backup). Then the system would be rebooted with the backup disk. The primary purpose of this system was to verify that the backup was complete and resulted in a viable copy.
Unfortunately, on one occasion the process failed, and the system could not be booted from the backup disk. Thinking that the backup had failed, the operator removed the nonbooting backup disk from the drive, replaced it with the original source disk, and attempted to boot that. This also failed. Thinking that there might be a problem with the drive itself, the operator then took the original disk and mounted it in the other drive and attempted to boot from that device. This also failed.
The operator then went to the storage shelf and retrieved the next most recent backup disk, mounted it in one of the two drives, and attempted to boot it. This also failed. The operator went back to the storage shelf and tried the same thing with the next most recent backup.
At around this point, the shift supervisor arrived and saw about 10 disks scattered on the floor. What had happened was that the original backup had failed due to a relatively rare head crash. That generation of disk drive technology was not completely sealed from dust, as are drives from the past few decades. A small hair or large piece of dust could be introduced as the disk was inserted into the drive. Since the gap between the drive heads (which float over the surface of the rapidly spinning disk) and the surface of the disk was smaller than the thickness of a human hair, a piece of hair would on occasion lead to a head crash. A head crash would physically scrape the surface of the disk platter, leaving very fine magnetic dust inside the drive.
Everything the operator did was in error. By replacing a disk that was unbootable with another one, he exposed the second disk to the same crashed heads. By switching a disk from a drive that had a crashed head to another drive, he introduced a damaged and gouged platter full of magnetic dust into the second drive, which now also became damaged. By retrieving and placing the next most recent disk and then the one older than that into the same damaged drives, the operator was methodically destroying all recent backups for the past several days.
Managing Changes in Operational Environments
A cloud provider will periodically need to revise services offerings and underlying functionality on which services are built. Before a new release can be deployed, it must be tested in as near an operational environment as possible. This can be a tall order, since an operational cloud can require many discrete components for cloud management. Such components include carrier-grade switches, routers, directory servers, security infrastructure, provisioning, and other infrastructure. All in all, the technology footprint can be extensive and expensive. A public cloud especially will not have the luxury of a prolonged outage to upgrade the infrastructure.
Several strategies can be employed in achieving a safe and predictable system upgrade. The most straightforward approach is to have completely separate development, test, staging, and operational environments. Development environments can be quite modest in terms of supporting infrastructure, but expect them to require some quality time during development—if only for brief periods—with access to larger blocks of computing and storage resources. Once a release is ready for broader testing, a dedicated testing environment will be required. Depending on the nature of the release, this testing environment may require dedicated use of some of the more expensive infrastructure—such as the ingress router or a large storage instance. However, generally the need for dedicated test environments should not entail sacrificing significant revenue-generating percentages of the infrastructure. For a private enterprise cloud, the same kinds of issues will exist, although more likely at a lower overall technology footprint.
Moving a release from testing to production will expose all manner of errors in configuration files, scripts, and procedures. Unless a release is a minor variation on a previously repeated series of enhancements, expect to run into showstoppers or debugging marathons. For this reason alone, the operations team should have at least one staging environment available where new releases and upgrades can be tested in as near to a final operational mode as possible. If the staging environment is virtually identical to the operational environment, a new release can be staged and tested with a subset of final computing and storage resources. When it is time to go live, the remainder of computing and storage can be switched over to staging in a hopefully seamless and nearly transparent manner.
But there is another set of reasons that operations really do need a staging and/or testing environment that can be configured identically to production: security testing and scanning. Rather than performing destructive security scanning against production, it should be performed against a sandboxed staging or testing environment that, except for resources, is identical to production. The same is true for other security testing and such as may be necessary for verifying the integrity and correctness of patches and other fixes.
Release Management
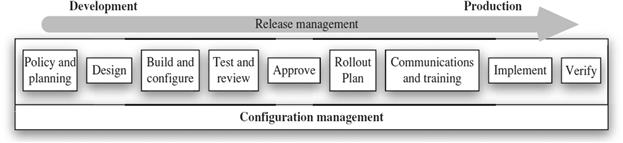
Release management for a cloud is intended to ensure that proper versions of hardware and software, configuration files, licenses, and associated supporting processes are in place and correctly and reliably rolled into production. The goals of release management include effective management of all phases from planning a release to developing procedures that will be used in the rollout, along with managing customer expectations during the rollout. Figure 7.3 depicts common steps within release management and indicates the underlying need for configuration management to support a new release.
Successful release management depends on discipline in process, the use of formal procedures, and numerous checks and acceptance gateways. Figure 7.4 depicts the relationship between release management and operations, note that operational activities such as incident response and analysis can contribute to the need for changes to a cloud.
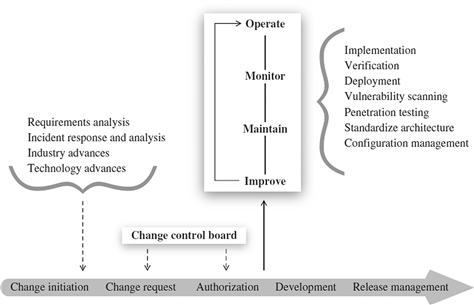
Releases can involve either major or minor software or hardware changes as well as emergency fixes. Emergency fixes are usually limited to addressing a small number of identified problems or security patches.
Information About the Infrastructure: Configuration Management
A complex cloud implementation will have several different categories of information about it. These will range from planning and design information to information about the configuration of the cloud to near-real-time data about the cloud. These different kinds of data will probably be found in completely separate realms and will likely have different representations.
However, because of the highly dynamic nature of a cloud and because of the greater degree of automation in IT operation, these kinds of data about a cloud should be expected to converge or at least become more accessible to management processes as cloud computing matures. Focusing on the physical infrastructure itself (the hardware that comprises computing and storage resources along with networking), one might be tempted to use a complex computer-aided design (CAD) program to represent the servers, storage, and networking—along with power cables and associated physical infrastructure. But that’s just crazy—or is it? If a cloud infrastructure was designed the way complex buildings are designed with CAD systems that produce building information models, each physical element would be reflected in the model. What would this buy you in terms of operations, and would it be worthwhile to invest in the tools and the time to develop and maintain such models? It is hard to gauge this at this point since the upfront cost of such tools is probably too high for any but very large cloud providers to be able to effectively benefit from the investment. But this notion does point in the direction of the greater control we can achieve if we have accurate and current information about the infrastructure.
Earlier, we discussed the role of a CMDB in managing knowledge about the authorized configuration of components, their attributes, and relationships. As discussed then, a CMDB offers tremendous advantages to the operation of a cloud. Not only can a CMDB be used to reflect the current state of the physical elements of a cloud, but it can enable tracking and even managing virtual cloud elements as well. The CMDB itself does not need to store information of virtual resources, but it does need to bridge knowledge and management of virtual resources to the physical and traditional CMDB realm. Doing so will enable automation in operations that encompasses the constant provisioning and deprovisioning VMs, virtualized networking, and security. To begin, the CMDB maintains contextual information about the physical infrastructure that security systems are reporting on and monitoring. Orchestration and VM management services maintain contextual information about the virtual infrastructure—what is left is to make all this information available to the security monitoring and assessment systems that are responsible for detecting and alerting security relevant situations as they unfold. Doing this will entail advances in the cloud management arena, but these advances and such integrated analysis and management capabilities will go far in further reducing ongoing operational costs, and they will bring greater security for customers. In such a view, security monitoring will itself evolve from alerting and reporting to automated security response. In a realm where attacks are automated, and at the scale of a cloud, this is necessary.
Change Management
Everything in the datacenter should be covered by a change management process, which prevents any change without correct authorization and approved. This should apply to both hardware and software to ensure that there is a smooth operation of the datacenter. A change made in one area could inadvertently affect other areas. For instance, upgrading firmware in a router may be done without realizing that some application relies on a specific firmware version. Likewise, any updates to an operating system may be required by policy but must still be put through change management, since some applications may require specific builds.
The change management process should have access to the CMDB to both verify and assess change requests and to update the CMDB after a change is completed. In this manner, changes that are made to the cloud are recorded and can be reviewed in the future for any number of reasons—including debugging.
Information Security Management
An information security management system (ISMS) is a necessity for a medium-sized to large-scale cloud. Every organization that builds a cloud of this size should have a comprehensive set of policies and procedures documents. One of the most common security certifications for a company to achieve is ISO 27002, which identifies and details the best practices for companies that are implementing and maintaining their ISMSs. Suffice it to say that the focus of this standard is the ongoing security of systems and that security in operations is a key aspect of that. ISO 27002 calls for certain activities to be in place prior to a system being operated. These activities include the following: a risk assessment, a security policy and associated standards, asset management, personnel security, and physical and environmental security. Equally important are activities that fall into operation of a cloud, such as communications and operations management, access control, incident management, and business continuity management.
Vulnerability and Penetration Testing
Penetration and vulnerability testing of cloud infrastructure should be performed on a regular basis. In many cases, operations and security personnel may not possess the specialized skills and expertise to perform these activities, in which case this may need to be outsourced to a third party. If that happens, you should ensure that the third party is professional and has demonstrable skills in this area. Although the majority of the skills and techniques used to test a cloud infrastructure are the same as testing a single application, you want to be certain that testers have a firm understanding of virtualization and cloud orchestration. Penetration testing should be aimed at the whole cloud infrastructure, not just individual servers or components. Security is only as good as the weakest link, and it is pointless if you verify the security of one server and leave others unverified. In addition, network components that enable the cloud environment need to be tested to ensure that these are securely configured. Routers and switches can have exploitable vulnerabilities, and if they are not configured correctly, they can route traffic in ways that are counter to the need for cloud security.
A penetration test and vulnerability scanning may discover a multitude of vulnerabilities, not all of which must be or can be fixed. Discovered vulnerabilities need to be graded (as simply as critical/high/medium/low). As a rule of thumb, any vulnerability that is classed as a critical or high should be remediated to ensure that the security of the entire cloud is maintained. On the other hand, low- and medium-level vulnerabilities may be accepted as reasonable risks, but this has to be determined for each cloud. Vulnerabilities that are not remediated need to have the residual risk assessed and then accepted by the business. Addressing efficiency in security operations, if you find that you have the same vulnerability across all your servers with the same build, this should be fixed in a golden image for multiple server builds.
It does need to be pointed out that many of the vulnerabilities that are discovered by scanning or penetration testing stem from poor development and coding practices. Where commercial software is the culprit, little can be done before introducing such components into an operational environment—but when the software is developed by the cloud organization itself, better coding practices can prevent the introduction of vulnerabilities into operation. This is far more cost effective than addressing poor code after it is fully developed or even in operation. Best practices here include having developers follow secure coding guidelines and security testing their code as it is developed. What can security operations do toward that goal? To begin with, operations can publish guidelines for code development and enforce acceptance tests and standards to put the responsibility for vulnerability avoidance squarely on development organizations.
Security Monitoring and Response
Overall monitoring can be split into two main areas: physical and cyber. Clearly there is a security need for monitoring of a datacenter. A well-run datacenter will be fully monitored continuously and will have defined procedures in the event of an alarm. As you grow your cloud infrastructure, so too will the need for monitoring increase as well as the complexity to undertake this task. Depending on the size and location of the cloud facility, you may require extra staff and specialized equipment to be installed.
Physical monitoring will include:
These activities are typically the responsibility of datacenter security staff. You should have well-defined procedures in place to ensure that the logs from door access systems and video recordings are kept to meet policy requirements. These procedures should be reviewed and tested when a risk assessment is undertaken, and all the perceived physical risks should then be mitigated.
Typically, video cameras are now readily available to work across a Transmission Control Protocol/Internet Protocol (TCP/IP) network, with wireless-enabled cameras becoming more common. The way these devices are incorporated into the network is important, both from a security point of view and from the viewpoint of the network bandwidth, since video feeds are notorious for consuming large amounts of network bandwidth. If these are connected into the same network segments as data is transported over, then given a number of cameras there is a likely bandwidth contention or saturation issue. A better approach is to have a security network for all such out-of-band traffic and to prioritize traffic on that network according to site needs.
Cyber monitoring can be broken into three areas:
Housekeeping
Housekeeping monitoring includes monitoring of all the servers to ensure they are up-to-date in terms of patches, antivirus updates, CPU and RAM utilization, and so on. Here again, a CMDB presents the opportunity to increase efficiencies in operation. Rather than scanning each system and identifying systems that require a patch, all version and associated information can be maintained in the CMDB itself, making for a quick search or lookup.
Periodically, it is important to verify that the CMDB accurately reflects the physical and logical environment on which it maintains information. Doing this for the entire cloud would be a daunting task, but it should be done for the components that comprise the management infrastructure. In addition, we can selectively sample and audit computing servers and VMs that are repeated hundreds or thousands of times. One way to perform a periodic audit against the logical environment is to use cataloging software. Nessus is a good example that is familiar to most security engineers. The key is to perform an authenticated scan and to collect and convert the results into a format (such as a database) that can be used to perform a comparison against the CMDB.
Threat monitoring and incident response comprise a significant security area; both aspects have to be well designed to be effective. Each is dependent on the other, and the whole process is flawed if they are not both present.
Threat Monitoring
The monitoring of the threats within your architecture will likely be a mix of manual and automated methods. At the base level, you need to collect the event and alert data from IDS/IPS sensors, antivirus logs, system logs from the various devices in your architecture, and others, as have been described in various parts of this chapter. With a medium-sized to large datacenter, the sheer amount of data would overwhelm operations personnel if they are solely using a manual method to collect and assess them. As the amount of data increases, the manual method will require a lot of extra heads, or the chance of a threat passing unnoticed will increase sharply. The bottom line is that manual methods are not in the same time domain as threats and exploits operate in, so even if they could be performed, they are simply not a reasonable approach.
Numerous automated tools can assist in this area. These tools span threat correlation engines and various security event management capabilities or systems. Chapter 6 went into detail on this topic. Basically, these tools will be able to reduce the number of false positives that appear in the raw event stream, more likely identifying more sophisticated attacks as well as alerting to any sensors that fail. The operator is thus able to concentrate on a smaller number of threats and decide whether these are real or allowed. Additionally, these tools can be tailored such that alerts are sent to the appropriate groups: virus alert to one group and failure of an IDS sensor to another group, for instance. These tools can collect data from many different sensors and then consolidate and correlate this data in one place.
The number of threat correlation engines has grown over the last few years, and there are a variety of approaches for collection, consolidation, correlation, and analysis. An assessment of these engines is outside the scope of this book; if you need one, an internal review should be held to consider your needs and compare them against the various commercial and open-source tools. The security community can also be very helpful in terms of identifying tools and relating experiences; every one of these comes with some sort of cost, and perfection has yet to be achieved.
In the past, monitoring the amount of IT that comprises a cloud would entail a dedicated network operations center (NOC) and maybe a security operations center (SOC). But today, this can largely be done virtually using secured Web-based consoles that allow a security team to operate from around the world’s time zones in order to have full coverage 24/7. A NOC and SOC are still reasonable, but the scale of the infrastructure or the risk needs to justify such an investment.
Incident Response
Monitoring and detecting a potential threat is only the start. After confirming that this is a not a false positive, you need to have an incident response plan in place. This plan will have a number of different levels, depending on the severity of the incident. These will be labeled in a variety of ways—low/medium/high; major/minor; and so on—and will have an appropriate response for each.
At the lowest level, incidents can be dealt with by the operations staff as part of the day-to-day activities and will typically not need to be escalated. Obviously, these need to be tracked to ensure that there is no overall pattern and to ensure that any follow-up work (such as installing critical patches) is undertaken.
The next level of incident would be when something impacts one or a small number of servers, such as a failure of the power supply into a whole rack or network failure to one segment of your network. Although the operations staff may fix these problems, it is likely that some form of communication will need to be sent out to affected staff and tracking of the incident undertaken. Furthermore, you need to decide whether a root-cause analysis (RCA) needs to be initiated to ascertain what went wrong and whether any change to the policy and procedures, infrastructure, detection sensors, and so on needs to occur to prevent it happening in the future.
At the top level, we may encounter major incidents that affect a large percentage of the user base, or such incidents may involve a security compromise or otherwise impact our reputation. Again, planning is the key to successfully responding to such incidents. Response will often involve a broader range of people than just the operations staff and require careful and skillful management of the incident. Communications will be necessary across a range of levels, from technical to management, and will need to occur on a continuing basis.
For many incidents, it may be expedient to have a dedicated team of people who are trained to undertake incident response. This will typically be a subset of operations and management. Having a dedicated team undertake this responsibility will be especially important if the response requires that forensics be undertaken. Evidence will need to be preserved (chain of custody), and evidence can be easily destroyed or made irrelevant if the correct steps are not taken. In addition, when incidents increase from those that are easy to fix to the more complicated, you might want to have the next tier of support staff working on them to ensure they are corrected properly.
Best Practices
In the 1990s, the Information Security Forum (ISF) published the Standard of Good Practice (SoGP), which identified a comprehensive set of information security best practices. This set continued to be updated until 2007 (a new version was available in late 2010). The SoGP was developed from comprehensive research and review of best practices around security and incident handling. The SoGP is often used in conjunction with other guidance or standards, such as ISO/IEC 27002 and COBIT.
In 1996, Marianne Swanson and Barbara Guttman produced the NIST Special Publication 800-14 (SP 800-14), Generally Accepted Principles and Practices for Securing Information Technology Systems.1 They identified the following eight principles:
■ Computer security supports the mission of the organization.
■ Computer security is an integral element of sound management.
■ Computer security should be cost-effective.
■ Systems owners have security responsibilities outside their own organizations.
■ Computer security responsibilities and accountability should be made explicit.
■ Computer security requires a comprehensive and integrated approach.
These principles have enduring value and can be adapted for managing cloud security. As SP 800-14 stated: “These principles are intended to guide … personnel when creating new systems, practices, or policies. They are not designed to produce specific answers.”2
Resilience in Operations
Increasingly, security is difficult to define without including business continuity and governance. Where business continuity is oriented toward overcoming any substantial service interruption (and its consequences), IT governance is a form of command and control over IT. Governance aligns the business in a strategic manner to support enterprise IT evolution so that it will bring continuing and consistent business value. Governance is a process or series of actions and functions that are oriented toward delivering desired IT results.
Organizations face numerous barriers in making security into an effective enabling factor to achieve an organization’s overall goals. To begin with, most systems are not really able to withstand even trivial failures without some degree of service interruption.
As stated in a report by Carnegie Mellon University (CMU):
Supporting operational resiliency requires a core capability for managing operational risk—the risks that emanate from day-to-day operations. Operational risk management is paramount to assuring mission success. For some industries like banking and finance, it has become not only a necessary business function but a regulatory requirement. Activities like security, business continuity, and IT operations management are important because their fundamental purpose is to identify, analyze, and mitigate various types of operational risk. In turn, because they support operational risk, they also directly impact operational resiliency.3
One of the goals of resilience in IT is to reduce the effect of failures and disasters. Reducing the likelihood of disaster is a primary objective, but equally important is the ability to recover from disasters.
Summary
Depending on how you adopt the cloud model (as a private, community, public, or hybrid resource) and depending on how you deliver cloud-based services (IaaS, PaaS, and SaaS), cloud computing brings different opportunities for change. As a new model for IT, cloud computing will be used to various advantages by competitors in the same industry, by vendors and providers of cloud services, and by consumers and subscribers.
The way an organization benefits from cloud computing will depend on how the organization assesses its present information and communications resources and how it envisions the transition to this model of computing. Already we can see this unfolding, with success being dependent on an organization’s ability to grasp the opportunities and to navigate changes to existing and emerging technologies, products, and concepts—and embracing the cloud as the new model for IT.
Although private clouds can achieve immense scale and serve many internal customers, most private clouds will likely be smaller. This gives public clouds several advantages in terms of return on investment for tools and security capabilities that are inherently expensive or that require an investment in expertise to properly implement and operate.
One of the IT advantages with the cloud model is that once infrastructure is in place, most of the typical IT physical hardware and networking activities are no longer performed as a matter of course. Clearly, physical subportions of the infrastructure can be carved out—but on an ongoing basis, this is not how a cloud is cost-effectively provisioned. Cut out of the whole cloth of infrastructure, the private cloud (or clouds) and such services as SaaS, PaaS, or IaaS will be provisioned at a virtual level. From a procedural perspective, this means that the deployment and operation of a private cloud is somewhat different than normal IT operations and that you will likely need to modify existing operational procedures.
If a cloud is implemented with security along with security reinforcing operational practices and processes (from the datacenter up to expressed services), there is really no reason why cloud security can’t be equal to any other implementation. In fact, as we have seen at several points in the book, due to the scale of large clouds, effective security can be far less expensive because it is spread over more tenants/users. This is due to the efficiency of scale or, to put it differently, it can be attributed to the relationship between massive scale and the lower average entry cost of better security components (from products through operational practices and monitoring).
By adopting cloud computing as a model for IT, organizations can continue to move away from more traditional device-centric perspectives toward information and services-based strategies. Clouds offer many benefits that go beyond the overall leaner IT infrastructure that they use more effectively than do other models. There are clear trade-offs that involve control over data and applications, compliance with laws and regulations, and even security. The cloud model also brings greater scalability, and by its use of fail in place, the cloud also brings greater reliability and redundancy. The change from a capital-heavy model of IT spending toward an operating model that is subscription-based brings new opportunities for a broader set of users and tenants to place larger bets with lower risk. Finally, the cloud model also reduces the overall energy footprint of computing, making it one of the greenest IT approaches.
The combined need for computational power, data storage, and bandwidth continues to drive demand for more highly capable systems. Data-intensive applications depend on access to increasing scales of storage. Petabyte-scale storage requirements are eclipsing terabyte-scale ones, and soon exabyte-scale storage may eclipse petabyte-scale. In addition to its other benefits, the cloud computing model makes such large-scale storage implementations more possible than is typically the case with other models.
Endnotes
1. Swanson M., Guttman B. NIST SP 800-14, “Generally Accepted Principals and Practices for Securing Information Technology Systems,” National Institute of Standards and Technology, Technology Administration; 1996.
2. Ibid.
3. Caralli R., Stevens J., Wallen C., Wilson W. Sustaining Operational Resiliency: A Process Improvement Approach to Security Management. CMU Networked Systems Survivability Program; 2006.
1ITIL and IT Infrastructure Library are registered trademarks of the United Kingdom’s Office of Government Commerce (OGC).