Amazon’s Simple Storage Service (S3) provides unlimited online storage space for files or data of any kind. Information stored in S3 is accessible from anywhere you have an Internet connection and is maintained in a highly scalable and reliable system. You can use S3 to securely store your personal data, to cheaply distribute content to the general public, or as a data storage component in a distributed web application architecture.
Amazon offers a Service Level Agreement for S3 that makes users eligible for service credits should the S3 uptime percentage fall below 99.9%. To claim these credits, users of the service must track any faults experienced by their applications due to S3 downtime, and they must provide Amazon with detailed logging documentation to corroborate the claim. For more information, refer to the Amazon S3 Service Level Agreement at http://www.amazon.com/gp/browse.html?node=379654011.
S3’s data model is very simple, comprising only two kinds of storage resource: objects and buckets. Objects store data and metadata, and buckets are containers that can hold an unlimited number of objects. The simplicity of the system means it is very flexible and easily adapted to suit a range of purposes, but it also means that if you need to perform complex tasks, you may have to create more intelligent programs to make up for the lack of features in the storage model.
In addition to data storage, S3 provides access control mechanisms that allow you to keep your information private or make it public and accessible to anyone on the Internet. Access control settings are configured using a list of rules that describe who will be granted access to a resource and the kinds of access that will be permitted. Access control settings can be applied to both bucket and object resources.
Resources in S3 are identified using standard Universal Resource Identifiers (URIs). This means that publicly accessible objects can be downloaded from a URI resembling any standard web site location, such as http://s3.amazonaws.com/bucket-name/object-name. S3 also allows resources to be accessed using alternative domain names. This feature allows you to publish links to your resources based on your own domain name, such as http://www.mysite.com/object-name, instead of the default S3-service domain name.
The S3 is built on a distributed architecture within Amazon. Your data is stored redundantly within this architecture, spread across multiple physical servers and across multiple data centers in different locations. If you wish you can specify a geographical location where your buckets will be stored. When this book was written, Amazon provided S3 data-center locations in the United States and Europe.
This storage strategy provides huge benefits in terms of redundancy, reliability, and scalability, but it also leads to some drawbacks that you must consider when building applications that use S3.
- S3 Objects cannot be manipulated like standard files
Although S3 can be used as a storage system for files, the API operations the service provides are not designed to perform the kinds of file manipulation tasks you might expect. Unlike a file on a disk, an object cannot be renamed or relocated within S3. It is also not possible to modify a small portion of an object’s data. If you need to modify an object, the only way to do so is to upload the entire modified file and replace the existing object with this data. This limitation is discussed in more detail in Objects Are Immutable” later in this chapter.
- Changes take time to propagate
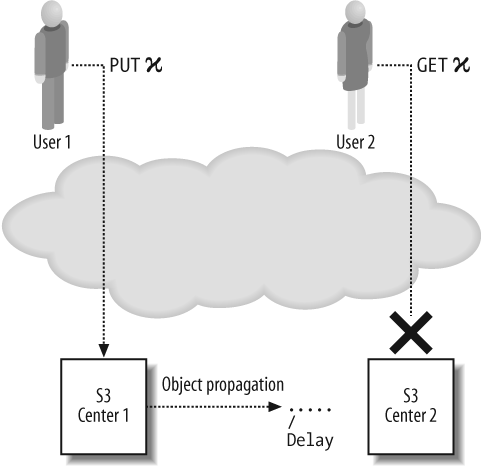
Because your S3 data is distributed over multiple servers and data centers, it can take some time for changes you make to propagate to all these locations. For example, when you upload a large file to S3, it will be stored immediately in the data center you uploaded it to, but there may be a delay before the file is sent to the other data centers.
This propagation latency means that you cannot be sure that an object you have created or updated in S3 will be immediately available to other S3 users, because their requests may be directed to a data center that has not yet been updated (see Figure 3-1). Furthermore, you cannot be sure that you will be able to retrieve the latest version of an object yourself, because there is no guarantee that all of your S3 requests will be directed to the same location.
The latency inherent in the S3 system has two main consequences:
You cannot assume that the data you have stored in S3 is immediately available to other users. This is especially the case if the other users are in a different location and therefore more likely to be served by a different S3 data center.
You cannot be certain that the data you retrieve from S3 is the latest version. If it is vital that you only use the latest version of an S3 object, you will have to implement your own data-versioning mechanisms.
In practice, there is only a small delay between creating or updating objects in S3 and these changes being propagated throughout all the S3 data centers. The latency you will experience can depend on a range of factors, including the kind of change you have performed, how much load S3 is experiencing, and how smoothly the service is running at the time.
- S3 requests will fail occasionally
S3 will occasionally fail to process requests and will instead return an Internal Server Error response message (HTTP error code 500). These failures are a regrettable but deliberate feature of the service’s architecture, and a small failure rate is to be expected in day-to-day use of the service.
Client applications that use S3 should be designed to handle these failures gracefully, much as they should handle intermittent networking glitches. The recommended action for an S3 client to take when it receives an Internal Server Error response is to retry the request after pausing for a short time. A particularly persistent client would retry the request a number of times, pausing for a longer period after each attempt, and only giving up when it becomes obvious the request is not going to succeed.
The likelihood of an S3 request failing with one of these errors is generally quite small, though never nil. Retrying a failed request once or twice is generally enough to get a successful result.
Note
The most likely requests to fall victim to Internal Server Errors are data upload (PUT) requests. These requests may fail immediately, or at any time during the upload process. If you intend to implement a client that automatically retries failed requests, be sure to regenerate the request’s authentication signature before each attempt, because the original signature’s 15 minute validity period may otherwise expire.
- S3’s IP addresses may change over time
To ensure S3 remains highly available, the IP addresses associated with S3 DNS names, such as s3.amazonaws.com, may be updated over time as the service responds to changing usage patterns and data-center loads. S3 client programs that run for long periods of time should periodically re-resolve the service’s DNS names to obtain the latest IP addresses. Depending on the client platform, the client may have to be specially configured to avoid caching the results of DNS lookups for too long. Ideally, client programs should not cache the results of DNS lookups against the S3 service for longer than five minutes.
S3 is a powerful storage system with a very simple data model. Do not think of it as a simple drop-in replacement for a standard hard disk, or you will find yourself fighting against the very simplicity the service seeks to achieve. If you appreciate the capabilities and limitations of the service before you build your application on top of it, you can design your application to take advantage of the service’s capabilities and minimize its limitations.
S3 account holders are billed monthly for their usage of the service. The service charges are based on three aspects of your S3 usage: the storage space consumed, the volume of data transferred to or from S3, and the number of API request operations that have been performed on your account. The fees can vary depending on the geographical location where you have chosen to store your data.
- Storage
Storage space in S3 is charged at 15¢ per GB/Month for data stored in the United States, and 18¢ per GB/Month for data stored in Europe.
S3 measures how many bytes are stored in your account each hour and records this as your Byte/Hours usage, and at the end of the month these measurements are accumulated into the GB/Month total. The number of hours in a month varies according to the number of days in that month, so some months will include more hourly totals than others.
The service calculates the amount of storage space consumed by your objects by adding the size of the objects’ content, metadata, and key names.
For example, let us calculate the price for data storage in S3 if you stored 3 GB for 12.5 days then added another 2 GB of data for the remainder of a 30 day month. The storage for this month will be broken into two periods: the first 300 hours (12.5 days) and the second 420 hours (17.5 days).
First period (12.5 days with 3GB) (12.5 days × 24 hours) × (3 GB × 10243 bytes) = 966,367,641,600 Byte/Hours Second period (17.5 days with 5GB) (17.5 days × 24 hours) × (5 GB × 10243 bytes) = 2,254,857,830,400 Byte/Hours Total Byte/Hours in Month 3,221,225,472,000 Total GB/Hours in Month 3,221,225,472,000 Byte/Hours ÷ 10243 bytes = 3,000 GB/Hours Hours in Month 30 days × 24 hours = 720 hours Total GB/Months 3,000 Gigabyte/Hours ÷ 720 hours in month = 4.166 GB/Months Cost per GB/Month (United States) $0.15 Total cost (United States) 4.166 GB/Months × 0.15 dollars = 62.5¢ (63¢ rounded up) Cost per Gigabyte/Month (Europe) $0.18 Total cost (Europe) 4.166 GB/Months × 0.18 dollars = 74.99¢ (75¢ rounded up) In this scenario you would pay 75¢ in data storage fees for data located in a European data center, or 63¢ for data stored in the United States. The U.S. fee is 63¢ instead of 62.5¢, because fractions of a cent are rounded up.
- Data transferred
Data sent to S3 costs 10¢ per GB uploaded. Data retrieved from S3 is charged on a sliding scale, depending on how much data was downloaded during the month: 18¢/GB for the first 10 TB downloaded, 16¢/GB for the next 40 TB (between 10 TB and 50 TB), and 13¢/GB for any additional data (over 50 TB).
There are no charges for data transferred between Amazon’s EC2 environment and S3 buckets located in the United States. Data transferred between EC2 and S3 buckets located in Europe incur the standard data-transfer charges.
- Request messages
You are also charged based on the number of API request messages S3 processes on your behalf. You must pay per-request fees for the requests performed by your own application, as well as requests made by others when they download data you have made available from your account. Request charges are divided into three tiers, based on the operation the request performs.
Operation Price (U.S.) Price (Europe) Delete an object or bucket Free Free Create or replace an object or bucket 1¢ per 1,000 requests 1.2¢ per 1,000 requests List your buckets 1¢ per 1,000 requests 1.2¢ per 1,000 requests List the objects in a bucket 1¢ per 1,000 requests 1.2¢ per 1,000 requests Update the ACL settings for a bucket or object 1¢ per 1,000 requests 1.2¢ per 1,000 requests All other requests (e.g., download an object) 1¢ per 10,000 requests 1.2¢ per 10,000 requests
The S3 cost structure can be a little confusing. To help run some numbers and estimate the cost of S3 for various scenarios, Amazon provides an online tool called the “AWS Simple Monthly Calculator,” available online at http://calculator.s3.amazonaws.com/calc5.html.