Amazon’s SimpleDB service provides reliable storage of structured textual data and a query language to locate the information you need. It allows you to store, modify, query and retrieve data sets without the need to run and maintain a traditional database server.
The service is designed to minimize the complexity and administrative overhead of data management. SimpleDB does not require a predefined schema; instead, it allows you to alter the structure and content of your information whenever you need to. The service also automatically indexes every piece of information stored within it to ensure queries will run as quickly as possible without the need for performance tuning. SimpleDB’s data management features are intended to complement the other infrastructure services provided by Amazon, which makes it possible to build your application with less reliance on your own physical infrastructure.
Note
The database features provided by SimpleDB are radically different from those offered by traditional relational database management systems (RDBMS). These differences will make your life easier in some cases, but they may force you to completely rethink your data storage and retrieval strategy in others. Above all, you must not assume that SimpleDB will be always be a workable replacement for an RDBMS database; it is, after all, a simple database service, not a complete one.
The SimpleDB service provides three main resources: domains, items, and attributes.
- Domains
A domain is a named container for related data. You use domains to partition data sets that are logically distinct, much as you might create multiple, separate databases within a single relational database server. SimpleDB queries can only search for results within a single domain, you cannot use them to perform cross-domain searches.
- Items
An item is a named collection of attributes that represents a data object, much like a row entry in a relational database. Each item has a name that uniquely identifies it within the domain. You can create, modify, or delete an entire item at one time, or you can manipulate individual attributes within an item.
The main difference between items in SimpleDB and rows in a relation database is that items do not need to comply with a preexisting table schema definition, and they can contain more than one value for each of the attributes stored within them.
- Attributes
An attribute is an individual category of information that is stored within an item. Each attribute has a name that uniquely identifies it within the item, and it has one or more text string values associated with this name. An attribute only exists while it is associated with at least one string value; if all its values are removed, the attribute ceases to be. You can think of an attribute as a category of multiple values, where each distinct value in the category is uniquely identified by the combined attribute name and value.
An attribute is similar to a column in a relational database table, except that it can be associated with multiple values, and it cannot contain a
NULLvalue. Attributes can be added to a SimpleDB item, updated, or removed at any time. Because SimpleDB does not require a data schema, you can freely change and rearrange attributes as necessary.
If you intend to use SimpleDB in your application, it is vital that you approach the service on its own terms and that you try to avoid thinking of the service as a relational database system. There are a number of major differences between this service and an RDBMS that may prove to be benefits or drawbacks, depending on your application’s requirements. Here is a brief summary of the key differences between SimpleDB and a traditional database.
- Items are stored in a hierarchical structure, not a table
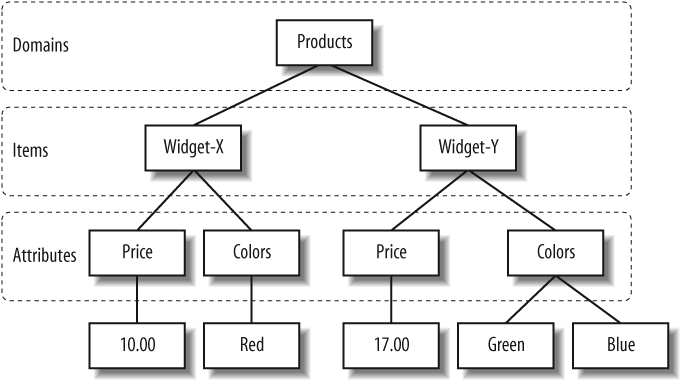
Items stored in a SimpleDB domain can contain multiple attributes, each of which may have multiple values. The relationship between these resources is best visualized as a hierarchical tree structure rather than as a rigid, predefined table structure. Figure 13-1 shows the hierarchy for a simple database of widgets.
Because there are no predefined database or table schemas, any item can have a different set of attributes from the other items in a domain. You are free to rearrange the attribute and value portions of this tree as you add new data elements or as your application’s needs change. The only “schema” embodied in the data is the ad-hoc schema you impose through your own attribute-naming conventions.
Although this feature provides benefits such as simplicity and flexibility, it can also put the unwary developer in considerable danger. When you use SimpleDB to store your data, it is entirely up to you to ensure that all your items comply with the schema you intend. If you forget to include an important attribute when you store an item, or if you misspell the attribute’s name, subsequent queries will not be able to find the item, and it will become lost in the service.
In SimpleDB you are working without the safety net of a predefined schema, and the service will not alert you if you make a mistake. Without a safety net, it could prove to be very painful if you fall.
- All data is stored as text
The SimpleDB data model is very simple and has no notion of data types beyond text strings. Because all the data in the service are textual data, SimpleDB is limited to comparing attributes based on case-sensitive, lexicographical (alphabetical) ordering. It cannot recognize data types such as integers, floating-point numbers, or dates, and therefore cannot compare data of this kind based on numerical or chronological ordering. If you need to perform queries based on the order of attribute values, you must encode these data types into sortable strings such that the lexicographical ordering is the same as the intended ordering of the data. For a discussion on encoding common data types into sortable strings, see Representing Data in SimpleDB.”
It is your responsibility to encode your data and ensure that it can be sorted correctly. You also need to be careful to avoid ruining the integrity of your database by introducing data that is not encoded or that is encoded differently than existing attribute values. Because there is no predefined schema in the service, no mechanism exists to enforce type correctness, so SimpleDB will not complain if you provide an integer value for an attribute that should only contain dates.
- Limited query capabilities
The query language provided by SimpleDB is much simpler than SQL or similar, traditional query languages, so you may have to code your application to make up for the lack of power in this language. For example, SimpleDB does not support the sorting of query results, the inclusion of attribute values in a result set, or the comparison of one attribute against another within the same item. For a complete summary of the features and shortcomings of the SimpleDB query language, see SimpleDB Query Expression Syntax.”
- Data consistency may suffer due to propagation delays
SimpleDB only guarantees eventual consistency for your data, which means that the data you retrieve from the service at any particular time may be slightly out of date.
The service is implemented as a distributed system, in which information is stored redundantly across multiple physical servers and potentially across multiple data centers. This strategy ensures that your data are kept safe and readily accessible, but it also means there will be a delay before any addition, alteration, or deletion operation you perform is propagated through the entire SimpleDB system. Your data will eventually be globally consistent, but until then, you could potentially retrieve outdated information from the service.
Amazon states that global consistency is usually achieved “within seconds”; however, this timeframe can depend on the processing and the network load the service is under when you make a change. If data consistency is important to your application, you may need to consider adding an intermediate caching layer that can respond to changes more quickly. For an example of how to use the memcached tool as a cache for the service, see Caching SimpleDB with Memcached.”
- Limited attribute sizes
The maximum size for any attribute value in SimpleDB is only 1024 bytes. This limit is clearly far too small to store binary data, such as images or files. This severe data-storage size restriction is deliberate, because Amazon intends that you store large data items in the S3 service, rather than in SimpleDB. The recommended way to integrate your SimpleDB database with content in S3 is to store a reference to an object’s bucket and key names in SimpleDB, then retrieve this object’s data from S3 when it is needed.
This arrangement makes more efficient use of Amazon’s storage resources and will end up saving you money: the SimpleDB data storage expenses are ten times higher than those in S3. However, this means your application must perform an extra step to integrate small pieces of data from SimpleDB with larger pieces from S3.
SimpleDB account holders are billed monthly for their service usage based on three criteria: the amount of storage they have used, the amount of data transferred into or out of the service, and the the number of hours of machine utilization time their operations have consumed.
- Storage
Storage space in SimpleDB is charged at $1.50 per GB/Month. In addition to the storage space consumed by your own data, you will be charged for the space required to store the indexing information the service automatically generates for your data. The space overhead for index information is 45 bytes for each item, attribute name, and attribute value you store. This is illustrated in Table 13-1.
Table 13-1. Storage space for an example item
Item Name Attribute Name Value Data Storage Index Overhead Item-01 7 bytes 45 bytes Description 11 bytes 45 bytes Béret 6 bytes
(2 bytes per non-ASCII character)
45 bytes Colors 6 bytes 45 bytes Green 5 bytes 45 bytes Purple 6 bytes 45 bytes Total data size: 41 bytes Total with overheads: 311 bytes To estimate the amount of storage your SimpleDB database consumes, add the total number of bytes of your own data plus an extra 45 bytes for every item, attribute name, and attribute value in your data set.
- Data transferred
Data received by SimpleDB when you store information costs 10¢ per gigabyte. Fees for data sent by SimpleDB in response to queries or data retrieval requests are charged on a sliding scale, depending on the volume of data transferred during the month: 18¢/GB from 0 to 10 TB, 16¢/GB from 10 to 50 TB, and 13¢/GB for any amount over 50 TB.
- Machine utilization
Amazon tracks the machine utilization for each SimpleDB operation you perform and charges 14¢ per machine hour you consume. The usage measurements are normalized to the hourly capacity of a circa 2007 1.7 GHz Xeon processor. The machine utilization value of each operation is returned in the response message, so you can monitor your usage on a per-request basis (see Service Response Messages”).
The machine usage for each request tends to depend on the volume of data processed in the request. The more attributes you upload, retrieve, or query, the higher the usage is likely to be. The exceptions to this rule are the operations for creating and deleting domains; these operations consume a relatively constant, and large, amount of machine time.