
The job of managing a web server and service is often completely separate from the job of designing and managing content on the website. While the previous chapter offered tools geared primarily toward web developers and other content managers, this chapter shows how to analyze web server log files, mirror websites, and monitor network health.
If you’re running Apache or a similar web server that uses the Common Log Format, you can do quite a bit of quick statistical analysis with a shell script. In a standard configuration, the server writes access_log and error_log files for the site (generally in /var/log, but this can be system dependent). If you’ve got your own server, you should definitely be archiving this valuable information.
Table 10-1 lists the fields in an access_log file.
Table 10-1: Field Values in the access_log File
Column |
Value |
1 |
IP of host accessing the server |
2–3 |
Security information for HTTPS/SSL connections |
4 |
Date and time zone offset of the specific request |
5 |
Method invoked |
6 |
URL requested |
7 |
Protocol used |
8 |
Result code |
9 |
Number of bytes transferred |
10 |
Referrer |
11 |
Browser identification string |
A typical line in access_log looks like this:
65.55.219.126 - - [04/Jul/2016:14:07:23 +0000] "GET /index.rdf HTTP/1.0" 301 310 "-" "msnbot-UDiscovery/2.0b (+http://search.msn.com/msnbot.htm)""
The result code (field 8) of 301 indicates that the request was considered a success. The referrer (field 10) indicates the URL of the page that the user was visiting immediately before the page request. Ten years ago, this would have been the URL of the previous page; now it’s generally "-", as you see here, for privacy reasons.
The number of hits to the site can be determined by doing a line count on the log file, and the date range of entries in the file can be ascertained by comparing the first and last lines.
$ wc -l access_log 7836 access_log $ head -1 access_log ; tail -1 access_log 69.195.124.69 - - [29/Jun/2016:03:35:37 +0000] ... 65.55.219.126 - - [04/Jul/2016:14:07:23 +0000] ...
With these points in mind, the script in Listing 10-1 produces a number of useful statistics from an Apache-format access_log file. This script expects the scriptbc and nicenumber scripts we wrote in Chapter 1 to be in the PATH.
#!/bin/bash
# webaccess--Analyzes an Apache-format access_log file, extracting
# useful and interesting statistics
bytes_in_gb=1048576
# You will want to change the following to match your own hostname
# to help weed out internally referred hits in the referrer analysis.
host="intuitive.com"
if [ $# -eq 0 ] ; then
echo "Usage: $(basename $0) logfile" >&2
exit 1
fi
if [ ! -r "$1" ] ; then
echo "Error: log file $1 not found." >&2
exit 1
fi
➊ firstdate="$(head -1 "$1" | awk '{print $4}' | sed 's/\[//')"
lastdate="$(tail -1 "$1" | awk '{print $4}' | sed 's/\[//')"
echo "Results of analyzing log file $1"
echo ""
echo " Start date: $(echo $firstdate|sed 's/:/ at /')"
echo " End date: $(echo $lastdate|sed 's/:/ at /')"
➋ hits="$(wc -l < "$1" | sed 's/[^[:digit:]]//g')"
echo " Hits: $(nicenumber $hits) (total accesses)"
➌ pages="$(grep -ivE '(.gif|.jpg|.png)' "$1" | wc -l | sed 's/[^[:digit:]]//g')"
echo " Pageviews: $(nicenumber $pages) (hits minus graphics)"
totalbytes="$(awk '{sum+=$10} END {print sum}' "$1")"
/bin/echo -n " Transferred: $(nicenumber $totalbytes) bytes "
if [ $totalbytes -gt $bytes_in_gb ] ; then
echo "($(scriptbc $totalbytes / $bytes_in_gb) GB)"
elif [ $totalbytes -gt 1024 ] ; then
echo "($(scriptbc $totalbytes / 1024) MB)"
else
echo ""
fi
# Now let's scrape the log file for some useful data.
echo ""
echo "The 10 most popular pages were:"
➍ awk '{print $7}' "$1" | grep -ivE '(.gif|.jpg|.png)' | \
sed 's/\/$//g' | sort | \
uniq -c | sort -rn | head -10
echo ""
echo "The 10 most common referrer URLs were:"
➎ awk '{print $11}' "$1" | \
grep -vE "(^\"-\"$|/www.$host|/$host)" | \
sort | uniq -c | sort -rn | head -10
echo ""
exit 0
Listing 10-1: The webaccess script
Let’s consider each block as a separate little script. For example, the first few lines extract the firstdate and lastdate ➊ by simply grabbing the fourth field of the first and last lines of the file. The number of hits is calculated by counting lines in the file using wc ➋, and the number of page views is calculated by simply subtracting requests for image files (that is, files with .gif, .jpg, or .png as their extension) from the hits. Total bytes transferred are calculated by summing up the value of the 10th field in each line and then invoking nicenumber to present it attractively.
To calculate the most popular pages, first we extract just the pages requested from the log file, and then we screen out any image files ➌. Next we use uniq -c to sort and calculate the number of occurrences of each unique line. Finally, we sort one more time to ensure that the most commonly occurring lines are presented first. In the code, this whole process is at ➍.
Notice that we do normalize things a little bit: the sed invocation strips out any trailing slashes to ensure that /subdir/ and /subdir are counted as the same request.
Similar to the section that retrieves the 10 most requested pages, the section at ➎ pulls out the referrer information.
This extracts field 11 from the log file, screening out entries that were referred from the current host as well as entries that are "-", the value sent when the web browser is blocking referrer data. Then the code feeds the result to the same sequence of sort|uniq -c|sort -rn|head -10 to get the 10 most common referrers.
To run this script, specify the name of an Apache (or other Common Log Format) log file as its only argument.
The result of running this script on a typical log file is quite informative, as Listing 10-2 shows.
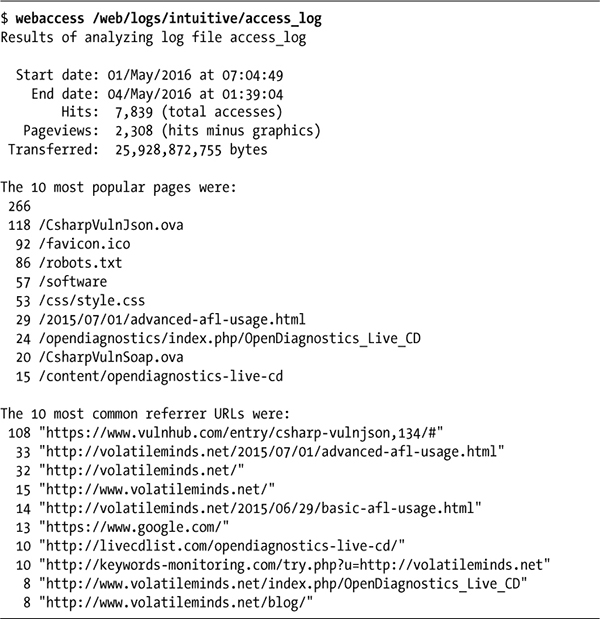
Listing 10-2: Running the webaccess script on an Apache access log
One challenge of analyzing Apache log files is that there are situations in which two different URLs refer to the same page; for example, /custer/ and /custer/index.html are the same page. Calculating the 10 most popular pages should take this into account. The conversion performed by the sed invocation already ensures that /custer and /custer/ aren’t treated separately, but knowing the default filename for a given directory might be a bit trickier (especially since this can be a special configuration on the web server).
You can make the 10 most popular referrers more useful by trimming referrer URLs to just the base domain name (e.g., slashdot.org). Script #74, coming up next, explores additional information available from the referrer field. The next time your website gets “slashdotted,” you should have no excuse for not knowing!
Script #73 can offer a broad overview of some of the search engine queries that point to your site, but further analysis can reveal not only which search engines are delivering traffic but also what keywords were entered by users who arrived at your site via search engines. This information can be invaluable for understanding whether your site has been properly indexed by the search engines. Moreover, it can provide the starting point for improving the rank and relevancy of your search engine listings, though, as we mentioned earlier, this additional information is slowly being deprecated by Apache and web browser developers. Listing 10-3 details the shell script for retrieving this information from your Apache logs.
#!/bin/bash
# searchinfo--Extracts and analyzes search engine traffic indicated in the
# referrer field of a Common Log Format access log
host="intuitive.com" # Change to your domain, as desired.
maxmatches=20
count=0
temp="/tmp/$(basename $0).$$"
trap "$(which rm) -f $temp" 0
if [ $# -eq 0 ] ; then
echo "Usage: $(basename $0) logfile" >&2
exit 1
fi
if [ ! -r "$1" ] ; then
echo "Error: can't open file $1 for analysis." >&2
exit 1
fi
➊ for URL in $(awk '{ if (length($11) > 4) { print $11 } }' "$1" | \
grep -vE "(/www.$host|/$host)" | grep '?')
do
➋ searchengine="$(echo $URL | cut -d/ -f3 | rev | cut -d. -f1-2 | rev)"
args="$(echo $URL | cut -d\? -f2 | tr '&' '\n' | \
grep -E '(^q=|^sid=|^p=|query=|item=|ask=|name=|topic=)' | \
➌ sed -e 's/+/ /g' -e 's/%20/ /g' -e 's/"//g' | cut -d= -f2)"
if [ ! -z "$args" ] ; then
echo "${searchengine}: $args" >> $temp
➍ else
# No well-known match, show entire GET string instead...
echo "${searchengine} $(echo $URL | cut -d\? -f2)" >> $temp
fi
count="$(( $count + 1 ))"
done
echo "Search engine referrer info extracted from ${1}:"
sort $temp | uniq -c | sort -rn | head -$maxmatches | sed 's/^/ /g'
echo ""
echo Scanned $count entries in log file out of $(wc -l < "$1") total.
exit 0
Listing 10-3: The searchinfo script
The main for loop ➊ of this script extracts all entries in the log file that have a valid referrer with a string length greater than 4, a referrer domain that does not match the $host variable, and a ? in the referrer string, indicating that a user search was performed.
The script then tries to identify the domain name of the referrer and the search value entered by the user ➋. An examination of hundreds of search queries shows that common search sites use a small number of common variable names. For example, search on Yahoo! and your search string is p=pattern. Google and MSN use q as the search variable name. The grep invocation contains p, q, and the other most common search variable names.
The invocation of sed ➌ cleans up the resultant search patterns, replacing + and %20 sequences with spaces and chopping out quotes, and the cut command returns everything that occurs after the first equal sign. In other words, the code returns just the search terms.
The conditional immediately following these lines tests whether the args variable is empty. If it is (that is, if the query format isn’t a known format), then it’s a search engine we haven’t seen, so we output the entire pattern rather than a cleaned-up, pattern-only value.
To run this script, simply specify the name of an Apache or other Common Log Format log file on the command line (see Listing 10-4).
NOTE
This is one of the slowest scripts in this book because it’s spawning lots of subshells to perform various tasks, so don’t be surprised if it takes a while to run.
$ searchinfo /web/logs/intuitive/access_log
Search engine referrer info extracted from access_log:
771
4 online reputation management akado
4 Names Hawaiian Flowers
3 norvegian star
3 disneyland pirates of the caribbean
3 disney california adventure
3 colorado railroad
3 Cirque Du Soleil Masks
2 www.baskerballcamp.com
2 o logo
2 hawaiian flowers
2 disneyland pictures pirates of the caribbean
2 cirque
2 cirqu
2 Voil%C3%A0 le %3Cb%3Elogo du Cirque du Soleil%3C%2Fb%3E%21
2 Tropical Flowers Pictures and Names
2 Hawaiian Flowers
2 Hawaii Waterfalls
2 Downtown Disney Map Anaheim
Scanned 983 entries in log file out of 7839 total.
Listing 10-4: Running the searchinfo script on Apache logs
One way to tweak this script is to skip the referrer URLs that are most likely not from search engines. To do so, simply comment out the else clause at ➍.
Another way to approach this task would be to search for all hits coming from a specific search engine, entered as the second command argument, and then compare the search strings specified. The core for loop would change, like so:
for URL in $(awk '{ if (length($11) > 4) { print $11 } }' "$1" | \
grep $2)
do
args="$(echo $URL | cut -d\? -f2 | tr '&' '\n' | \
grep -E '(^q=|^sid=|^p=|query=|item=|ask=|name=|topic=)' | \
cut -d= -f2)"
echo $args | sed -e 's/+/ /g' -e 's/"//g' >> $temp
count="$(( $count + 1 ))"
done
You’ll also want to tweak the usage message so that it mentions the new second argument. Again, this script is going to eventually just report blank data due to changes in how web browsers—and Google in particular— report the Referer info. As you can see, of the matching entries in this log file, 771 reported no referrer and therefore no useful information about keyword usage.
Just as Script #73 on page 235 reveals the interesting and useful statistical information found in the regular access log of an Apache or Apache-compatible web server, this script extracts the critical information from the error_log file.
For those web servers that don’t automatically split their logs into separate access_log and error_log components, you can sometimes split a central log file into these components by filtering based on the return code (field 9) of each entry in the log:
awk '{if (substr($9,0,1) <= "3") { print $0 } }' apache.log > access_log
awk '{if (substr($9,0,1) > "3") { print $0 } }' apache.log > error_log
A return code that begins with a 4 or a 5 is a failure (the 400s are client errors and the 500s are server errors), and a return code beginning with a 2 or a 3 is a success (the 200s are success messages and the 300s are redirects).
Other servers that produce a single central log file containing both successes and errors denote the error message entries with an [error] field value. In that case, the split can be done with a grep '[error]' to create the error log and a grep -v '[error]' to create the access log.
Whether your server automatically creates an error log or you have to create your own error log by searching for entries with the '[error]' string, just about everything in the error log is different from the content of the access log, including the way the date is specified.
$ head -1 error_log
[Mon Jun 06 08:08:35 2016] [error] [client 54.204.131.75] File does not exist:
/var/www/vhosts/default/htdocs/clientaccesspolicy.xml
In the access log, dates are specified as a compact one-field value with no spaces; the error log takes five fields instead. Furthermore, rather than a consistent scheme in which the word/string position in a space-delimited entry consistently identifies a particular field, entries in the error log have a meaningful error description that varies in length. An examination of just those description values reveals surprising variation, as shown here:
$ awk '{print $9" "$10" "$11" "$12 }' error_log | sort -u
File does not exist:
Invalid error redirection directive:
Premature end of script
execution failure for parameter
premature EOF in parsed
script not found or
malformed header from script
Some of these errors should be examined by hand because they can be difficult to track backward to the offending web page.
The script in Listing 10-5 focuses on the most common problems—in particular, File does not exist errors—and then produces a dump of all other error log entries that don’t match well-known error situations.
#!/bin/bash
# weberrors--Scans through an Apache error_log file, reports the
# most important errors, and then lists additional entries
temp="/tmp/$(basename $0).$$"
# For this script to work best, customize the following three lines for
# your own installation.
htdocs="/usr/local/etc/httpd/htdocs/"
myhome="/usr/home/taylor/"
cgibin="/usr/local/etc/httpd/cgi-bin/"
sedstr="s/^/ /g;s|$htdocs|[htdocs] |;s|$myhome|[homedir] "
sedstr=$sedstr"|;s|$cgibin|[cgi-bin] |"
screen="(File does not exist|Invalid error redirect|premature EOF"
screen=$screen"|Premature end of script|script not found)"
length=5 # Entries per category to display
checkfor()
{
grep "${2}:" "$1" | awk '{print $NF}' \
| sort | uniq -c | sort -rn | head -$length | sed "$sedstr" > $temp
if [ $(wc -l < $temp) -gt 0 ] ; then
echo ""
echo "$2 errors:"
cat $temp
fi
}
trap "$(which rm) -f $temp" 0
if [ "$1" = "-l" ] ; then
length=$2; shift 2
fi
if [ $# -ne 1 -o ! -r "$1" ] ; then
echo "Usage: $(basename $0) [-l len] error_log" >&2
exit 1
fi
echo Input file $1 has $(wc -l < "$1") entries.
start="$(grep -E '\[.*:.*:.*\]' "$1" | head -1 \
| awk '{print $1" "$2" "$3" "$4" "$5 }')"
end="$(grep -E '\[.*:.*:.*\]' "$1" | tail -1 \
| awk '{print $1" "$2" "$3" "$4" "$5 }')"
/bin/echo -n "Entries from $start to $end"
echo ""
### Check for various common and well-known errors:
checkfor "$1" "File does not exist"
checkfor "$1" "Invalid error redirection directive"
checkfor "$1" "Premature EOF"
checkfor "$1" "Script not found or unable to stat"
checkfor "$1" "Premature end of script headers"
➊ grep -vE "$screen" "$1" | grep "\[error\]" | grep "\[client " \
| sed 's/\[error\]/\`/' | cut -d\` -f2 | cut -d\ -f4- \
➋ | sort | uniq -c | sort -rn | sed 's/^/ /' | head -$length > $temp
if [ $(wc -l < $temp) -gt 0 ] ; then
echo ""
echo "Additional error messages in log file:"
cat $temp
fi
echo ""
echo "And non-error messages occurring in the log file:"
➌ grep -vE "$screen" "$1" | grep -v "\[error\]" \
| sort | uniq -c | sort -rn \
| sed 's/^/ /' | head -$length
exit 0
Listing 10-5: The weberrors script
This script works by scanning the error log for the five errors specified in the calls to the checkfor function, extracting the last field on each error line with an awk call for $NF (which represents the number of fields in that particular input line). This output is then fed through sort | uniq -c | sort -rn ➋ to make it easy to extract the most commonly occurring errors for that category of problem.
To ensure that only those error types with matches are shown, each specific error search is saved to the temporary file, which is then tested to make sure it isn’t empty before a message is output. This is all neatly done with the checkfor() function that appears near the top of the script.
The last few lines of the script identify the most common errors not otherwise checked for by the script but that are still in standard Apache error log format. The grep invocations at ➊ are part of a longer pipe.
Then the script identifies the most common errors not otherwise checked for by the script that don’t occur in standard Apache error log format. Again, the grep invocations at ➌ are part of a longer pipe.
This script should be passed the path to a standard Apache-format error log as its only argument, shown in Listing 10-6. If invoked with a -l length argument, it will display length number of matches per error type checked rather than the default of five entries per error type.
$ weberrors error_log
Input file error_log has 768 entries.
Entries from [Mon Jun 05 03:35:34 2017] to [Fri Jun 09 13:22:58 2017]
File does not exist errors:
94 /var/www/vhosts/default/htdocs/mnews.htm
36 /var/www/vhosts/default/htdocs/robots.txt
15 /var/www/vhosts/default/htdocs/index.rdf
10 /var/www/vhosts/default/htdocs/clientaccesspolicy.xml
5 /var/www/vhosts/default/htdocs/phpMyAdmin
Script not found or unable to stat errors:
1 /var/www/vhosts/default/cgi-binphp5
1 /var/www/vhosts/default/cgi-binphp4
1 /var/www/vhosts/default/cgi-binphp.cgi
1 /var/www/vhosts/default/cgi-binphp-cgi
1 /var/www/vhosts/default/cgi-binphp
Additional error messages in log file:
1 script '/var/www/vhosts/default/htdocs/wp-trackback.php' not found
or unable to stat
1 script '/var/www/vhosts/default/htdocs/sprawdza.php' not found or
unable to stat
1 script '/var/www/vhosts/default/htdocs/phpmyadmintting.php' not
found or unable to stat
And non-error messages occurring in the log file:
6 /usr/lib64/python2.6/site-packages/mod_python/importer.py:32:
DeprecationWarning: the md5 module is deprecated; use hashlib instead
6 import md5
3 [Sun Jun 25 03:35:34 2017] [warn] RSA server certificate CommonName
(CN) `Parallels Panel' does NOT match server name!?
1 sh: /usr/local/bin/zip: No such file or directory
1 sh: /usr/local/bin/unzip: No such file or directory
Listing 10-6: Running the weberrors script on Apache error logs
Whether or not you have a comprehensive backup strategy, it’s a nice insurance policy to back up a few critical files with a separate off-site archive system. Even if it’s just that one key file with all your customer addresses, your invoices, or even emails from your sweetheart, having an occasional off-site archive can save your proverbial bacon when you least expect it.
This sounds more complex than it really is, because as you’ll see in Listing 10-7, the “archive” is just a file emailed to a remote mailbox, which could even be a Yahoo! or Gmail mailbox. The list of files is kept in a separate data file, with shell wildcards allowed. Filenames can contain spaces, something that rather complicates the script, as you’ll see.
#!/bin/bash
# remotebackup--Takes a list of files and directories, builds a single
# compressed archive, and then emails it off to a remote archive site
# for safekeeping. It's intended to be run every night for critical
# user files but not intended to replace a more rigorous backup scheme.
outfile="/tmp/rb.$$.tgz"
outfname="backup.$(date +%y%m%d).tgz"
infile="/tmp/rb.$$.in"
trap "$(which rm) -f $outfile $infile" 0
if [ $# -ne 2 -a $# -ne 3 ] ; then
echo "Usage: $(basename $0) backup-file-list remoteaddr {targetdir}" >&2
exit 1
fi
if [ ! -s "$1" ] ; then
echo "Error: backup list $1 is empty or missing" >&2
exit 1
fi
# Scan entries and build fixed infile list. This expands wildcards
# and escapes spaces in filenames with a backslash, producing a
# change: "this file" becomes this\ file, so quotes are not needed.
➊ while read entry; do
echo "$entry" | sed -e 's/ /\\ /g' >> $infile
done < "$1"
# The actual work of building the archive, encoding it, and sending it
➋ tar czf - $(cat $infile) | \
uuencode $outfname | \
mail -s "${3:-Backup archive for $(date)}" "$2"
echo "Done. $(basename $0) backed up the following files:"
sed 's/^/ /' $infile
/bin/echo -n "and mailed them to $2 "
if [ ! -z "$3" ] ; then
echo "with requested target directory $3"
else
echo ""
fi
exit 0
Listing 10-7: The remotebackup script
After the basic validity checks, the script processes the file containing the list of critical files, which is supplied as the first command line argument, to ensure that spaces embedded in its filenames will work in the while loop ➊. It does this by prefacing every space with a backslash. Then it builds the archive with the tar command ➋, which lacks the ability to read standard input for its file list and thus must be fed the filenames via a cat invocation.
The tar invocation automatically compresses the archive, and uuencode is then utilized to ensure that the resultant archive data file can be successfully emailed without corruption. The end result is that the remote address receives an email message with the uuencoded tar archive as an attachment.
NOTE
The uuencode program wraps up binary data so that it can safely travel through the email system without being corrupted. See man uuencode for more information.
This script expects two arguments: the name of a file that contains a list of files to archive and back up and the destination email address for the compressed, uuencoded archive file. The file list can be as simple as this:
$ cat filelist
*.sh
*.html
Listing 10-8 details running the remotebackup shell script to back up all HTML and shell script files in the current directory, and then printing the results.
$ remotebackup filelist taylor@intuitive.com Done. remotebackup backed up the following files: *.sh *.html and mailed them to taylor@intuitive.com $ cd /web $ remotebackup backuplist taylor@intuitive.com mirror Done. remotebackup backed up the following files: ourecopass and mailed them to taylor@intuitive.com with requested target directory mirror
Listing 10-8: Running the remotebackup script to back up HTML and shell script files
First off, if you have a modern version of tar, you might find that it has the ability to read a list of files from stdin (for example, GNU’s tar has a -T flag to have the file list read from standard input). In this case, the script can be shortened by updating how the file list is given to tar.
The file archive can then be unpacked or simply saved, with a mailbox trimmer script run weekly to ensure that the mailbox doesn’t get too big. Listing 10-9 details a sample trimmer script.
#!/bin/bash
# trimmailbox--A simple script to ensure that only the four most recent
# messages remain in the user's mailbox. Works with Berkeley Mail
# (aka Mailx or mail)--will need modifications for other mailers!
keep=4 # By default, let's just keep around the four most recent messages.
totalmsgs="$(echo 'x' | mail | sed -n '2p' | awk '{print $2}')"
if [ $totalmsgs -lt $keep ] ; then
exit 0 # Nothing to do
fi
topmsg="$(( $totalmsgs - $keep ))"
mail > /dev/null << EOF
d1-$topmsg
q
EOF
exit 0
Listing 10-9: The trimmailbox script, to be used in conjunction with the remotebackup script
This succinct script deletes all messages in the mailbox other than the most recent ones ($keep). Obviously, if you’re using something like Hotmail or Yahoo! Mail for your archive storage, this script won’t work and you’ll have to log in occasionally to trim things.
One of the most puzzling administrative utilities in Unix is netstat, which is too bad, because it offers quite a bit of useful information about network throughput and performance. With the -s flag, netstat outputs volumes of information about each of the protocols supported on your computer, including TCP, UDP, IPv4/v6, ICMP, IPsec, and more. Most of those protocols are irrelevant for a typical configuration; usually the protocol you want to examine is TCP. This script analyzes TCP protocol traffic, determining the percentage of packet transmission failure and including a warning if any values are out of bounds.
Analyzing network performance as a snapshot of long-term performance is useful, but a much better way to analyze data is with trends. If your system regularly has 1.5 percent packet loss in transmission, and in the last three days the rate has jumped up to 7.8 percent, a problem is brewing and needs to be analyzed in more detail.
As a result, this script is two parts. The first part, shown in Listing 10-10, is a short script that is intended to run every 10 to 30 minutes, recording key statistics in a log file. The second script (Listing 10-11) parses the log file, reporting typical performance and any anomalies or other values that are increasing over time.
WARNING
Some flavors of Unix can’t run this code as is (though we’ve confirmed it’s working on OS X as is)! It turns out that there is quite a variation in the output format (many subtle whitespace changes or slight spelling) of the netstat command between Linux and Unix versions. Normalizing netstat output would be a nice script unto itself.
#!/bin/bash
# getstats--Every 'n' minutes, grabs netstats values (via crontab)
logfile="/Users/taylor/.netstatlog" # Change for your configuration.
temp="/tmp/getstats.$$.tmp"
trap "$(which rm) -f $temp" 0
if [ ! -e $logfile ] ; then # First time run?
touch $logfile
fi
( netstat -s -p tcp > $temp
# Check your log file the first time this is run: some versions of netstat
# report more than one line, which is why the "| head -1" is used here.
➊ sent="$(grep 'packets sent' $temp | cut -d\ -f1 | sed \
's/[^[:digit:]]//g' | head -1)"
resent="$(grep 'retransmitted' $temp | cut -d\ -f1 | sed \
's/[^[:digit:]]//g')"
received="$(grep 'packets received$' $temp | cut -d\ -f1 | \
sed 's/[^[:digit:]]//g')"
dupacks="$(grep 'duplicate acks' $temp | cut -d\ -f1 | \
sed 's/[^[:digit:]]//g')"
outoforder="$(grep 'out-of-order packets' $temp | cut -d\ -f1 | \
sed 's/[^[:digit:]]//g')"
connectreq="$(grep 'connection requests' $temp | cut -d\ -f1 | \
sed 's/[^[:digit:]]//g')"
connectacc="$(grep 'connection accepts' $temp | cut -d\ -f1 | \
sed 's/[^[:digit:]]//g')"
retmout="$(grep 'retransmit timeouts' $temp | cut -d\ -f1 | \
sed 's/[^[:digit:]]//g')"
/bin/echo -n "time=$(date +%s);"
➋ /bin/echo -n "snt=$sent;re=$resent;rec=$received;dup=$dupacks;"
/bin/echo -n "oo=$outoforder;creq=$connectreq;cacc=$connectacc;"
echo "reto=$retmout"
) >> $logfile
exit 0
Listing 10-10: The getstats script
The second script, shown in Listing 10-11, analyzes the netstat historical log file.
#!/bin/bash
# netperf--Analyzes the netstat running performance log, identifying
# important results and trends
log="/Users/taylor/.netstatlog" # Change for your configuration.
stats="/tmp/netperf.stats.$$"
awktmp="/tmp/netperf.awk.$$"
trap "$(which rm) -f $awktmp $stats" 0
if [ ! -r $log ] ; then
echo "Error: can't read netstat log file $log" >&2
exit 1
fi
# First, report the basic statistics of the latest entry in the log file...
eval $(tail -1 $log) # All values turn into shell variables.
➌ rep="$(scriptbc -p 3 $re/$snt\*100)"
repn="$(scriptbc -p 4 $re/$snt\*10000 | cut -d. -f1)"
repn="$(( $repn / 100 ))"
retop="$(scriptbc -p 3 $reto/$snt\*100)";
retopn="$(scriptbc -p 4 $reto/$snt\*10000 | cut -d. -f1)"
retopn="$(( $retopn / 100 ))"
dupp="$(scriptbc -p 3 $dup/$rec\*100)";
duppn="$(scriptbc -p 4 $dup/$rec\*10000 | cut -d. -f1)"
duppn="$(( $duppn / 100 ))"
oop="$(scriptbc -p 3 $oo/$rec\*100)";
oopn="$(scriptbc -p 4 $oo/$rec\*10000 | cut -d. -f1)"
oopn="$(( $oopn / 100 ))"
echo "Netstat is currently reporting the following:"
/bin/echo -n " $snt packets sent, with $re retransmits ($rep%) "
echo "and $reto retransmit timeouts ($retop%)"
/bin/echo -n " $rec packets received, with $dup dupes ($dupp%)"
echo " and $oo out of order ($oop%)"
echo " $creq total connection requests, of which $cacc were accepted"
echo ""
## Now let's see if there are any important problems to flag.
if [ $repn -ge 5 ] ; then
echo "*** Warning: Retransmits of >= 5% indicates a problem "
echo "(gateway or router flooded?)"
fi
if [ $retopn -ge 5 ] ; then
echo "*** Warning: Transmit timeouts of >= 5% indicates a problem "
echo "(gateway or router flooded?)"
fi
if [ $duppn -ge 5 ] ; then
echo "*** Warning: Duplicate receives of >= 5% indicates a problem "
echo "(probably on the other end)"
fi
if [ $oopn -ge 5 ] ; then
echo "*** Warning: Out of orders of >= 5% indicates a problem "
echo "(busy network or router/gateway flood)"
fi
# Now let's look at some historical trends...
echo "Analyzing trends..."
while read logline ; do
eval "$logline"
rep2="$(scriptbc -p 4 $re / $snt \* 10000 | cut -d. -f1)"
retop2="$(scriptbc -p 4 $reto / $snt \* 10000 | cut -d. -f1)"
dupp2="$(scriptbc -p 4 $dup / $rec \* 10000 | cut -d. -f1)"
oop2="$(scriptbc -p 4 $oo / $rec \* 10000 | cut -d. -f1)"
echo "$rep2 $retop2 $dupp2 $oop2" >> $stats
done < $log
echo ""
# Now calculate some statistics and compare them to the current values.
cat << "EOF" > $awktmp
{ rep += $1; retop += $2; dupp += $3; oop += $4 }
END { rep /= 100; retop /= 100; dupp /= 100; oop /= 100;
print "reps="int(rep/NR) ";retops=" int(retop/NR) \
";dupps=" int(dupp/NR) ";oops="int(oop/NR) }
EOF
➍ eval $(awk -f $awktmp < $stats)
if [ $repn -gt $reps ] ; then
echo "*** Warning: Retransmit rate is currently higher than average."
echo " (average is $reps% and current is $repn%)"
fi
if [ $retopn -gt $retops ] ; then
echo "*** Warning: Transmit timeouts are currently higher than average."
echo " (average is $retops% and current is $retopn%)"
fi
if [ $duppn -gt $dupps ] ; then
echo "*** Warning: Duplicate receives are currently higher than average."
echo " (average is $dupps% and current is $duppn%)"
fi
if [ $oopn -gt $oops ] ; then
echo "*** Warning: Out of orders are currently higher than average."
echo " (average is $oops% and current is $oopn%)"
fi
echo \(Analyzed $(wc -l < $stats) netstat log entries for calculations\)
exit 0
Listing 10-11: The netperf script, to be used with the getstats script
The netstat program is tremendously useful, but its output can be intimidating. Listing 10-12 shows just the first 10 lines of output.
$ netstat -s -p tcp | head
tcp:
51848278 packets sent
46007627 data packets (3984696233 bytes)
16916 data packets (21095873 bytes) retransmitted
0 resends initiated by MTU discovery
5539099 ack-only packets (2343 delayed)
0 URG only packets
0 window probe packets
210727 window update packets
74107 control packets
Listing 10-12: Running netstat to get TCP information
The first step is to extract just those entries that contain interesting and important network performance statistics. That’s the main job of getstats, and it does this by saving the output of the netstat command into the temp file $temp and going through $temp to calculate key values, such as total packets sent and received. The line at ➊, for example, gets the number of packets sent.
The sed invocation removes any nondigit values to ensure that no tabs or spaces end up as part of the resulting value. Then all of the extracted values are written to the netstat.log log file in the format var1Name=var1Value; var2Name=var2Value; and so forth. This format will let us later use eval on each line in netstat.log and have all the variables instantiated in the shell:

The netperf script does the heavy lifting, parsing netstat.log and reporting both the most recent performance numbers and any anomalies or other values that are increasing over time. The netperf script calculates the current percentage of retransmits by dividing retransmits by packets sent and multiplying this result by 100. An integer-only version of the retransmission percentage is calculated by taking the result of dividing retransmissions by total packets sent, multiplying it by 10,000, and then dividing by 100 ➌.
As you can see, the naming scheme for variables within the script begins with the abbreviations assigned to the various netstat values, which are stored in netstat.log at the end of the getstats script ➋. The abbreviations are snt, re, rec, dup, oo, creq, cacc, and reto. In the netperf script, the p suffix is added to any of these abbreviations for variables that represent decimal percentages of total packets sent or received. The pn suffix is added to any of the abbreviations for variables that represent integer-only percentages of total packets sent or received. Later in the netperf script, the ps suffix denotes a variable that represents the percentage summaries (averages) used in the final calculations.
The while loop steps through each entry of netstat.log, calculating the four key percentile variables (re, retr, dup, and oo, which are retransmits, transmit timeouts, duplicates, and out of order, respectively). All are written to the $stats temp file, and then the awk script sums each column in $stats and calculates average column values by dividing the sums by the number of records in the file (NR).
The eval line at ➍ ties things together. The awk invocation is fed the set of summary statistics ($stats) produced by the while loop and utilizes the calculations saved in the $awktmp file to output variable=value sequences. These variable=value sequences are then incorporated into the shell with the eval statement, instantiating the variables reps, retops, dupps, and oops, which are average retransmit, average retransmit timeouts, average duplicate packets, and average out-of-order packets, respectively. The current percentile values can then be compared to these average values to spot problematic trends.
For the netperf script to work, it needs information in the netstat.log file. That information is generated by having a crontab entry that invokes getstats with some level of frequency. On a modern OS X, Unix, or Linux system, the following crontab entry will work fine, with the correct path to the script for your system of course:
*/15 * * * * /home/taylor/bin/getstats
It will produce a log file entry every 15 minutes. To ensure the necessary file permissions, it’s best to actually create an empty log file by hand before running getstats for the first time.
$ sudo touch /Users/taylor/.netstatlog $ sudo chmod a+rw /Users/taylor/.netstatlog
Now the getstats program should chug along happily, building a historical picture of the network performance of your system. To analyze the contents of the log file, run netperf without any arguments.
First off, let’s check on the .netstatlog file, shown in Listing 10-13.

Listing 10-13: The last three lines of the .netstatlog that results from a crontab entry running the getstats script on a regular interval
It looks good. Listing 10-14 shows the results of running netperf and what it has to report.
$ netperf
Netstat is currently reporting the following:
52170128 packets sent, with 16927 retransmits (0%) and 2722 retransmit timeouts (0%)
20290926 packets received, with 129910 dupes (.600%) and 18064 out of order (0%)
39841 total connection requests, of which 123 were accepted
Analyzing trends...
(Analyzed 6 netstat log entries for calculations)
Listing 10-14: Running the netperf script to analyze the .netstatlog file
You’ve likely already noticed that rather than using a human-readable date format, the getstats script saves entries in the .netstatlog file using epoch time, which represents the number of seconds that have elapsed since January 1, 1970. For example, 1,063,983,000 seconds represents a day in late September 2003. The use of epoch time will make it easier to enhance this script by enabling it to calculate the time elapsed between readings.
There are many times when it’s useful to change the priority of a task, whether a chat server is supposed to use only “spare” cycles, an MP3 player app is not that important, a file download has become less important, or a real-time CPU monitor needs an increase in priority. You can change a process’s priority with the renice command; however, it requires you to specify the process ID, which can be a hassle. A much more useful approach is to have a script like the one in Listing 10-15 that matches process name to process ID and automatically renices the specified application.
#!/bin/bash
# renicename--Renices the job that matches the specified name
user=""; tty=""; showpid=0; niceval="+1" # Initialize
while getopts "n:u:t:p" opt; do
case $opt in
n ) niceval="$OPTARG"; ;;
u ) if [ ! -z "$tty" ] ; then
echo "$0: error: -u and -t are mutually exclusive." >&2
exit 1
fi
user=$OPTARG ;;
t ) if [ ! -z "$user" ] ; then
echo "$0: error: -u and -t are mutually exclusive." >&2
exit 1
fi
tty=$OPTARG ;;
p ) showpid=1; ;;
? ) echo "Usage: $0 [-n niceval] [-u user|-t tty] [-p] pattern" >&2
echo "Default niceval change is \"$niceval\" (plus is lower" >&2
echo "priority, minus is higher, but only root can go below 0)" >&2
exit 1
esac
done
shift $(($OPTIND - 1)) # Eat all the parsed arguments.
if [ $# -eq 0 ] ; then
echo "Usage: $0 [-n niceval] [-u user|-t tty] [-p] pattern" >&2
exit 1
fi
if [ ! -z "$tty" ] ; then
pid=$(ps cu -t $tty | awk "/ $1/ { print \\$2 }")
elif [ ! -z "$user" ] ; then
pid=$(ps cu -U $user | awk "/ $1/ { print \\$2 }")
else
pid=$(ps cu -U ${USER:-LOGNAME} | awk "/ $1/ { print \$2 }")
fi
if [ -z "$pid" ] ; then
echo "$0: no processes match pattern $1" >&2
exit 1
elif [ ! -z "$(echo $pid | grep ' ')" ] ; then
echo "$0: more than one process matches pattern ${1}:"
if [ ! -z "$tty" ] ; then
runme="ps cu -t $tty"
elif [ ! -z "$user" ] ; then
runme="ps cu -U $user"
else
runme="ps cu -U ${USER:-LOGNAME}"
fi
eval $runme | \
awk "/ $1/ { printf \" user %-8.8s pid %-6.6s job %s\n\", \
\$1,\$2,\$11 }"
echo "Use -u user or -t tty to narrow down your selection criteria."
elif [ $showpid -eq 1 ] ; then
echo $pid
else
# Ready to go. Let's do it!
/bin/echo -n "Renicing job \""
/bin/echo -n $(ps cp $pid | sed 's/ [ ]*/ /g' | tail -1 | cut -d\ -f6-)
echo "\" ($pid)"
renice $niceval $pid
fi
exit 0
Listing 10-15: The renicename script
This script borrows liberally from Script #47 on page 150, which does a similar mapping of process name to process ID—but that script kills the jobs rather than just lowering their priority.
In this situation, you don’t want to accidentally renice a number of matching processes (imagine renicename -n 10 "*", for example), so the script fails if more than one process matches. Otherwise, it makes the change specified and lets the actual renice program report any errors that may have been encountered.
You have a number of possible options when running this script: -n val allows you to specify the desired nice (job priority) value. The default is specified as niceval=1. The -u user flag allows matching processes to be limited by user, while -t tty allows a similar filter by terminal name. To see just the matching process ID and not actually renice the application, use the -p flag. In addition to one or more flags, renicename requires a command pattern, which will be compared to the running process names on the system to ascertain which of the processes match.
First off, Listing 10-16 shows what happens when there is more than one matching process.
$ renicename "vi"
renicename: more than one process matches pattern vi:
user taylor pid 6584 job vi
user taylor pid 10949 job vi
Use -u user or -t tty to narrow down your selection criteria.
Listing 10-16: Running the renicename script with a process name with multiple process IDs
We subsequently quit one of these processes and ran the same command.
$ renicename "vi"
Renicing job "vi" (6584)
We can confirm that this worked and our vi process was prioritized by using the -l flag to ps with the process ID specified, shown in Listing 10-17.
$ ps –l 6584 UID PID PPID F CPU PRI NI SZ RSS WCHAN S ADDR TTY TIME CMD 501 6584 1193 4006 0 30 1➊ 2453832 1732 - SN+ 0 ttys000 0:00.01 vi wasting.time
Listing 10-17: Confirming the process has been niced appropriately
It’s hard to read this super-wide output format from the ps command, but notice that field 7 is NI and that for this process its value is 1 ➊. Check any other process you’re running, and you’ll see they’re all priority 0, the standard user priority level.
An interesting addendum to this script would be another script that watches for any time-critical programs that are launched and automatically renices them to a set priority. This could be helpful if certain internet services or applications tend to consume a lot of CPU resources, for example. Listing 10-18 uses renicename to map process name to process ID and then checks the process’s current nice level. It issues a renice if the nice level specified as a command argument is higher (a lesser priority) than the current level.
#!/bin/bash
# watch_and_nice--Watches for the specified process name and renices it
# to the desired value when seen.
if [ $# -ne 2 ] ; then
echo "Usage: $(basename $0) desirednice jobname" >&2
exit 1
fi
pid="$(renicename -p "$2")"
if [ "$pid" == "" ] ; then
echo "No process found for $2"
exit 1
fi
if [ ! -z "$(echo $pid | sed 's/[0-9]*//g')" ] ; then
echo "Failed to make a unique match in the process table for $2" >&2
exit 1
fi
currentnice="$(ps -lp $pid | tail -1 | awk '{print $6}')"
if [ $1 -gt $currentnice ] ; then
echo "Adjusting priority of $2 to $1"
renice $1 $pid
fi
exit 0
Listing 10-18: The watch_and_nice script
Within a cron job, this script could be used to ensure that certain apps are pushed to the desired priority within a few minutes of being launched.