Chapter 15. Trust
Marc Waldman, Lorrie Faith Cranor, and Avi Rubin, AT&T Labs-Research
Trust plays a central role in many aspects of computing, especially those related to network use. Whether downloading and installing software, buying a product from a web site, or just surfing the Web, an individual is faced with trust issues. Does this piece of software really do what it says it does? Will the company I make purchases from sell my private information to other companies? Is my ISP logging all of my network traffic? All of these questions are central to the trust issue. In this chapter we discuss the areas of trust related to distributed systems—computers that communicate over a network and share information.
Trust in peer-to-peer, collaborative, or distributed systems presents its own challenges. Some systems, like Publius, deliberately disguise the source of data; all of the systems use computations or files provided by far-flung individuals who would be difficult to contact if something goes wrong—much less to hold responsible for any damage done.
Trust in real life, and its lessons for computer networks
In the physical world, when we talk about how much we trust someone, we often consider that person’s reputation. We usually are willing to put great trust in someone whom we have personally observed to be highly capable and have a high level of integrity. In the absence of personal observation, the recommendation of a trusted friend can lead one to trust someone. When looking for someone to provide a service for us in which trust is an issue—whether a doctor, baby-sitter, or barber—we often ask our friends for recommendations or check with a trusted authority such as a childcare referral service. In real life, trust is often increased by establishing positive reputations and networks for conveying these reputations. This is true for computer networks as well. More will be said about this in Chapter 16, and Chapter 17. Once reputations are established, digital certificates and networks like the PGP web of trust (described later in this chapter) can be used to convey reputation information in a trustworthy way.
Information conveyed by a trusted person is itself seen to be trustworthy, especially if it is based on a personal observation by that person. Information conveyed via a long chain of people, trustworthy or not, is generally viewed to be less trustworthy—even if the entire chain is trustworthy, the fact that it was conveyed via a long chain introduces the possibility that somewhere along the way the facts may have been confused. So we may trust all of the people in the chain to be honest, but we may not trust all of them to accurately remember and convey every detail of a story told by someone else. If it is important to us to have confidence in the veracity of a piece of information, we may try to follow the chain back to its source. Essentially, we are able to increase trust by reducing the number of people that must be trusted. This applies to real life situations as well as computer networks.
We can also look at trust from a risk assessment perspective. We tend to be more willing to place trust in people when the risk of adverse consequences should our trust be misplaced is small. Likewise, even if there is high risk, if the potential consequences are not that bad, we may still be willing to trust. Thus, we can also increase trust by reducing risk. Just as in real life we may reduce risk by removing valuable items from a car before leaving it with a parking lot attendant, in a networked environment we may reduce risk by creating protected “sandboxes” where we can execute untrusted code without exposing critical systems to danger.
Sometimes we interact with people whose reputations are unknown to us, but they somehow seem worthy of our trust. We may talk about people who seem to have an honest face or a trustworthy demeanor. In the online world, a web site that looks very professional may also appear to be trustworthy, even if we do not know anything else about it. Clearly there are ways of changing perceptions about trust when our later experiences conflict with our first impressions. Indeed, many companies spend a lot of effort honing a marketing message or corporate image in an effort to convey more of an image of trustworthiness to consumers.
In this chapter, we are concerned less about perceptions of trustworthiness than we are about designing systems that rely as little as possible on trust. Ultimately, we would like to design systems that do not require anyone to trust any aspect of the system, because there is no uncertainty about how the system will behave. In this context, the ideal trusted system is one that everyone has confidence in because they do not have to trust it. Where that is impossible, we use techniques such as reputation building and risk reduction to build trust.
We first examine the issue of downloaded software. For the most part, the software described in this book can be downloaded from the Web. This simple act of downloading software and running it on your computer involves many trust-related issues. We then examine anonymous publishing systems. This discussion uses Publius as an example, but many of these issues apply to other systems as well. The last part of the chapter examines the trust issues involved in file sharing and search engines.
Trusting downloaded software
Trust issues exist even before an individual connects her computer to any network. Installing software supplied with your computer or that perhaps was bought in a retail store implies a level of trust—you trust that the software will work in the manner described and that it won’t do anything malicious. By purchasing it from a “reputable” company, you believe that you know who wrote the software and what kind of reputation is associated with their software products. In addition, you may be able to take legal action if something goes horribly wrong.
The advent of the Internet changes this model. Now software can be downloaded directly onto your computer. You may not know who the author is and whether the software has been maliciously modified or really does what it claims. We have all heard stories of an individual receiving an attachment via email that, when executed, deleted files on the victim’s hard drive.
Ideally, when downloading software from the Internet, we would like to have the same assurances that we have when we purchase the software directly from a store. One might think that simply downloading software from companies that one is already familiar with raises no trust issues. However, you can see from the sampling of potential problems in Table 15.1 this is really not true. The software you are downloading may have been modified by a malicious party before you even begin downloading it. Even if it begins its journey unmodified, it has to travel to you over an untrusted network—the Internet. The software, while it is traveling on the network, can be intercepted, modified, and then forwarded to you—all without your knowledge. Even if this doesn’t happen, your Internet service provider (ISP) or another party could be logging the fact that you are downloading a particular piece of software or visiting a particular web site. This information can, for example, be used to target specific advertising at you. At the very least, this logging is an invasion of privacy. As we shall see there are ways of overcoming each of these problems.[40]
|
Solution |
Trust principle | |
|
Software doesn’t behave as advertised, and may even damage your computer system. |
Only download software from companies or individuals who have established a good reputation, or those you know where to find should a problem occur. |
Look for positive reputations. |
|
Software is modified (on server or in transit). |
Check for digital signature on message digest and verify signature against author’s certificate. |
Use tools that accurately convey reputations. |
|
Your downloads (and other online behavior) are logged by your ISP or other parties. |
Use an anonymity tool so other parties do not get access to information that might link you to a particular download. |
Reduce risk. |
Message digest functions
Almost all of the software described in this book is given away for free. The only way to acquire it is to download it—you can’t walk into your local computer store and purchase it. We would like some way to verify that the downloaded files have not been tampered with in any way. This can be accomplished through the use of a message digest function , which is also known as a cryptographically secure hash function. A message digest function takes a variable-length input message and produces a fixed-length output. The same message will always produce the same output. If the input message is changed in any way, the digest function produces a different output value. This feature makes digest functions ideal for detecting file tampering.
Now that we have message digest functions, it looks like all of our tamper problems are solved—the author of a piece of software just places the value of the file’s hash on the same web page that contains the file download link. After the user downloads the file, a separate program finds the digest of the file. This digest is then compared with the one on the web page. If the digests don’t match the file has been tampered with; otherwise it is unchanged. Unfortunately things are not that simple. How do we know that the digest given on the web page is correct? Perhaps the server administrator or some malicious hacker changed the software and placed the digest of the modified file on the web page. If someone downloaded the altered file and checked the replaced digest everything would look fine. The problem is that we do not have a mechanism to guarantee that the author of the file was the one who generated the particular digest. What we need is some way for the author to state the digest value so that someone else cannot change it.
Digital signatures
Public key cryptography and digital signatures can be used to help identify the author of a file. Although the mathematics behind public key cryptography are beyond the scope of this book, suffice it to say that a pair of keys can be generated in such a way that if one key is used to sign some piece of data, the other key can be used to verify the signed data. Keys are essentially large numbers that are needed for the signature and verification operations. One of these keys is kept secret and is therefore called the private key. The other key is made available to everyone and is called the public key. Someone can send you an authenticated message simply by signing the message with his private key. You can then use his public key to verify the signature on the message.
So it looks like our problem is almost solved. The author of the software generates a public and private key. The author then computes the digest of the software package. This digest is then signed using a private key. A file containing the signed digest is placed on the same web page as the file to be downloaded (the software package). After downloading the software an individual finds its digest. The signed digest file is downloaded from the web site and verified using the author’s public key.
Digital certificates
The problem with the scheme is that we have no way of verifying the author’s public key. How do we know that someone didn’t just generate a public/private key pair, modify the file, and sign its digest with the private key just generated? The public key on the web site cannot necessarily be trusted. We need a way to certify that a particular public key does indeed belong to the author of the software. Digital certificates are meant to provide this binding of public keys to individuals or organizations.
Digital certificates are issued by companies called certifying authorities (CAs). These are organizations that mint digital certificates for a fee; they are often called trusted third parties because both you and your correspondent trust them. An individual or corporation requesting a certificate must supply the CA with the proper credentials. Once these credentials have been verified, the CA mints a new certificate in the name of the individual or corporation. The CA signs the certificate with its private key and this signature becomes part of the certificate. The CA signature guarantees its authenticity.
The certificate creation process just described is a simplification of the actual process. Different classes of certificates exist corresponding to the type of credentials presented when applying for the certificate. The more convincing the credentials, the more verification work is created for the CA, and therefore it assesses a higher annual fee on the individual or corporation applying for the certificate. Therefore, certain types of certificates are more trustworthy than others.
Signature verification
Now all the pieces are in place. The author of some software applies to a CA for a certificate. This certificate binds her to a public key—only she knows the associated private key. She signs her software using the method described above. The signed digest and a link to the software are placed on the author’s web page. In addition, a link to the author’s certificate is added to the web page. At some later time, an individual downloads the software and author’s certificate. The digest function is performed on the file. The author’s certificate is verified using the CA’s public key, which is available on the CA’s web page. Once verified, the author’s public key is used to verify the signature on the digest. This digest is compared to the one just performed on the file. If the digests match, the file has not been tampered with. See Figure 15.1 for an illustration of the process.
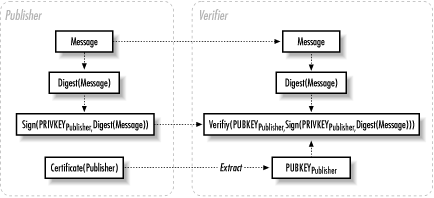
This verification process provides assurance that the downloaded software is signed by someone who has a private key that was issued to a software author with a particular name. Of course, there is no guarantee that the software author did not let someone else use her key, or that the key was not stolen without her knowledge. Furthermore, if we don’t know anything about the reputation of this particular software author, knowing her name may not give us any confidence in her software (although if we have confidence in the CA, we may at least believe that it might be possible to track her down later should her software prove destructive).
The previously described verification process is not performed by hand. A number of software products are available that automate the task.
Pretty Good Privacy (PGP) is a well-known tool for encrypting files and email. It also allows individuals to sign and verify files. Rather than having to trust a third party, the CA, PGP allows individuals to create their own certificates. These certificates by themselves are not very helpful when trying to verify someone’s identity; however, other people can sign the certificates. People that know you can sign your certificate, and you in turn can sign their certificates. If you receive a certificate from someone you don’t trust, you can check the signatures on the certificate and see if you trust any of them. Based on this information you can decide if you wish to trust the certificate. This is a trust system based on intermediaries, and it forms what is called the "web of trust.” The web of trust can be thought of as a peer-to-peer certification system. No centralized certifying authority is needed. A free version of PGP is available for download at http://web.mit.edu/network/pgp.html.
Unfortunately, digital certificates and signatures don’t solve all of our problems. Not all software packages are signed. An author’s private key can become compromised, allowing others to sign any piece of software with the compromised key. Just because software is signed doesn’t mean that it doesn’t have malicious intent. So one must still be vigilant when it comes to downloaded software.
Open source software
Much of the software available for download is available as source code, which needs to be compiled or interpreted in order to run on a specific computer. This means that one can examine the source code for any malicious intent. However, this is really practical only for rather small programs. This naturally leads to the question of whether it is possible to write a program that examines the source code of another program to determine if that program really does what it claims to do. Unfortunately, computer scientists have shown that, in general, it is impossible to determine if a program does what it claims to do.[41] However, we can build programs to monitor or constrain the behavior of other programs.
Sandboxing and wrappers
Programs that place limits on the behavior of other programs existed before the Internet. The most obvious example of this type of program is an operating system such as Unix or Windows NT. Such an operating system, for example, won’t allow you to delete a file owned by someone else or read a file owned by another user unless that user has granted you permission. Today, programs exist that can constrain the behavior of programs you download while surfing the Web. When a web page contains a Java applet, that applet is downloaded and interpreted by another program running on your computer. This interpreter prevents the applet from performing operations that could possibly damage your computer, such as deleting files. The term used to describe the process of limiting the type of operations a program can perform is called sandboxing. The applet or other suspicious program is allowed to execute only in a small sandbox. Thus the risk of damage is reduced substantially. Programs called wrappers allow the behavior of CGI scripts to be constrained in a similar manner.
Trust in censorship-resistant publishing systems
We now examine trust issues specific to distributed file-sharing and publishing programs. We use Publius as an example; however, the problems and solutions discussed are applicable to many of the other programs discussed in this book.
Publius is a web-based publishing system that allows people to publish documents in such a way that they are resistant to censorship. For a full description of Publius, see Chapter 11.
Publius derives its censorship resistance in part from a collection of independently owned web servers. Each server donates a few hundred megabytes of disk space and runs a CGI script that allows it to store and retrieve Publius files. Since each server is independently owned, the server administrator has free rein over the server. This means the administrator can arbitrarily read, delete or modify any files on the server including the Publius files. Because the Publius files are encrypted, reading a file does not reveal anything interesting about the file (unless the server administrator knows the special Publius URL).
Publius in a nutshell
Before describing the trust issues involved in Publius, we briefly review the Publius publication process. When an individual publishes a file, the Publius client software generates a key that is used to encrypt the file. This key is split into a number of pieces called shares. Only a small number of these shares are required to reconstruct the key. For example, the key can be split into 30 shares such that any 3 shares are needed to reconstruct the document.
A large number of Publius servers—let’s say 20—then store the file, each server taking one share of the key along with a complete copy of the encrypted file. Each server stores a different share, and no server holds more than one share. A special Publius URL is generated that encodes the location of the encrypted file and shares on the 20 servers. In order to read the document, the client software parses the special URL, randomly picks 3 of these 20 servers, and downloads the share stored on each of them. In addition, the client software downloads one copy of the encrypted file from one of the servers.
The client now combines the shares to form the key and uses the key to decrypt the file. A tamper check is performed to see if the file was changed in any way. If the file was changed, a new set of three shares and a new encrypted document are retrieved and tested. This continues until a file passes the tamper check or the system runs out of different encrypted file and share combinations.
Risks involved in web server logging
Most web servers keep a log of all files that have been requested from the server. These logs usually include the date, time, and the name of the file that was requested. In addition, these logs usually hold the IP address of the computer that made the request. This IP address can be considered a form of identification. While it may be difficult to directly link an individual to a particular IP address, it is not impossible.
Even if your IP address doesn’t directly identify you, it certainly gives some information about you. For example, an IP address owned by an ISP appearing in some web server log indicates that an individual who uses that ISP visited the web site on a certain date and time. The ISP itself may keep logs as to who was using a particular IP address during a particular date and time. So while it may not be possible to directly link an individual to a web site visit, an indirect route may exist.
Web servers almost always log traffic for benign reasons. The company or individual who owns the server simply wishes to get an idea how many requests the web server is receiving. The logs may answer questions central to the company’s business. However, as previously stated, these logs can also be used to identify someone. This is a problem faced by Publius and many of the other systems described in this book.
Why would someone want to be anonymous on the Internet? Well, suppose that you are working for a company that is polluting the environment by dumping toxic waste in a local river. You are outraged but know that if you say anything you will be fired from your job. Therefore you secretly create a web page documenting the abuses of the corporation. You then decide you want to publish this page with Publius. Publishing this page from your home computer could unwittingly identify you. Perhaps one or more of the Publius servers are run by friends of the very corporation that you are going to expose for its misdeeds. Those servers are logging IP addresses of all computers that store or read Publius documents. In order to avoid this possibility you can walk into a local cyber café or perhaps the local library and use their Internet connection to publish the web page with Publius. Now the IP address of the library or cyber café will be stored in the logs of the Publius servers. Therefore there is no longer a connection to your computer. This level of anonymity is still not as great as we would like. If you are one of a very few employees of the company living in a small town, the company may be able to figure out you leaked the information just by tracing the web page to a location in that town.
Going to a cyber café or library is one option to protect your privacy. Anonymizing software is another. Depending on your trust of the anonymity provided by the cyber café or library versus your trust of the anonymity provided by software, you may reach different conclusions about which technique provides a higher level of anonymity in your particular situation. Whether surfing the Web or publishing a document with Publius, anonymizing software can help you protect your privacy by making it difficult, if not impossible, to identify you on the Internet. Different types of anonymizing software offer varying degrees of anonymity and privacy protection. We now describe several anonymizing and privacy-protection systems.
Anonymizing proxies
The simplest type of anonymizing software is an anonymizing proxy. Several such anonymizing proxies are available today for individuals who wish to surf the Web with some degree of anonymity. Two such anonymizing proxies are Anonymizer.com and Rewebber.de. These anonymizing proxies work by acting as the intermediary between you and the web site you wish to visit. For example, suppose you wish to anonymously view the web page with the URL http://www.oreilly.com. Instead of entering this address into the browser, you first visit the anonymizing proxy site (e.g., http://www.anonymizer.com). This site displays a form that asks you to enter the URL of the site you wish to visit. You enter http://www.oreilly.com, and the anonymizing proxy retrieves the web page corresponding to this URL and displays it in your browser. In addition, the anonymizing proxy rewrites all the hyperlinks on the retrieved page so that when you click on any of these hyperlinks the request is routed through the anonymizing proxy. Any logs being kept by the server http://www.oreilly.com will only record the anonymizing proxy’s IP address, as this is the computer that actually made the request for the web page. The process is illustrated in Figure 15.2.
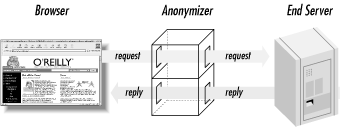
The anonymizing proxy solves the problem of logging by the Publius servers but has introduced the problem of logging by the anonymizing proxy. In other words, if the people running the proxy are dishonest, they may try to use it to snare you.
In addition to concern over logging, one must also trust that the proxy properly transmits the request to the destination web server and that the correct document is being returned. For example, suppose you are using an anonymizing proxy and you decide to shop for a new computer. You enter the URL of your favorite computer company into the anonymizing proxy. The company running the anonymizing proxy examines the URL and notices that it is for a computer company. Instead of contacting the requested web site, the proxy contacts a competitor’s web site and sends the content of the competitor’s web page to your browser. If you are not very familiar with the company whose site you are visiting, you may not even realize this has happened. In general, if you use a proxy you must just resolve to trust it, so try to pick a proxy with a good reputation.
Censorship in Publius
Now that we have a possible solution to the logging problem, let’s look at the censorship problem. Suppose that a Publius server administrator named Eve wishes to censor a particular Publius document. Eve happened to learn the Publius URL of the document and by coincidence her server is storing a copy of the encrypted document and a corresponding share. Eve can try a number of things to censor the document.
Upon inspecting the Publius URL for the document she wishes to censor, Eve learns that the encrypted document is stored on 20 servers and that 3 shares are needed to form the key that decrypts the document. After a bit of calculation Eve learns the names of the 19 other servers storing the encrypted document. Recall that Eve’s server also holds a copy of the encrypted document and a corresponding share. If Eve simply deletes the encrypted document on her server she cannot censor the document, as it still exists on 19 other servers. Only one copy of the encrypted document and three shares are needed to read the document. If Eve can convince at least 17 other server administrators to delete the shares corresponding to the document then she can censor the document, as not enough shares will be available to form the key. (This possibility means that it is very difficult, but not impossible, to censor Publius documents. The small possibility of censorship can be viewed as a limitation of Publius. However, it can also be viewed as a “safety” feature that would allow a document to be censored if enough of the server operators agreed that it was objectionable.)
Using the Update mechanism to censor
Eve and her accomplices have not been able to censor the document by deleting it; however, they realize that they might have a chance to censor the document if they place an update file in the directory where the encrypted file and share once resided. The update file contains the Publius URL of a file published by Eve.
Using the Update file method described in Chapter 11, Eve and her accomplices have a chance, albeit a very slim one, of occasionally censoring the document. When the Publius client software is given a Publius URL it breaks up the URL to discover which servers are storing the encrypted document and shares. The client then randomly chooses three of these servers from which to retrieve the shares. The client also retrieves the encrypted document from one of these servers. If all three requests for the share return with the same update URL, instead of the share, the client follows the update URL and retrieves the corresponding document.
How successful can a spoofed update be? There are 1,140 ways to choose 3 servers from a set of 20. Only 1 of these 1,140 combinations leads to Eve’s document. Therefore Eve and her cohorts have only a 1 in 1,140 chance of censoring the document each time someone tries to retrieve it. Of course, Eve’s probability of success grows as she enlists more Publius server administrators to participate in her scheme. Furthermore, if large numbers of people are trying to retrieve a document of some social significance, and they discover any discrepancies by comparing documents, Eve could succeed in casting doubt on the whole process of retrieval.
A publisher worried about this sort of update attack has the option of specifying that the file is not updateable. This option sets a flag in the Publius URL that tells the Publius client software to ignore update URLs sent from any Publius server. Any time the Publius client receives an update URL, it simply treats it as an invalid response from the server and attempts to acquire the needed information from another server. In addition to the “do not update” option, a “do not delete” option is available to the publisher of a Publius document. While this cannot stop Eve or any other server administrator from deleting files, it does protect the publisher from someone trying to repeatedly guess the correct password to the delete the file. This is accomplished by not storing a password with the encrypted file. Because no password is stored on the server, the Publius server software program refuses to perform the Delete command.
As previously stated, the Publius URL also encodes the number of shares required to form the key. This is the same as the number of update URLs that must match before the Publius client retrieves an update URL. Therefore, another way to make the update attack more difficult is to raise the number of shares needed to reconstruct the key. The default is three, but it can be set to any number during the Publish operation. However, raising this value increases the amount of time it takes to retrieve a Publius document because more shares need to be retrieved in order to form the key.
On the other hand, requiring a large number of shares to reconstruct the document can make it easier for an adversary to censor it. Previously we discussed the possibility of Eve censoring the document if she and two friends delete the encrypted document and its associated shares. We mentioned that such an attack would be unsuccessful because 17 other shares and encrypted documents exist. If the document was published in such a way that 18 shares were required to form the key, Eve would have succeeded in censoring the document because only 17 of the required 18 shares would be available. Therefore, some care must be taken when choosing the required number of shares.
Alternatively, even if we do not increase the number of shares necessary to reconstruct a Publius document, we could develop software for retrieving Publius documents that retrieves more than the minimum number of required shares when an update file is discovered. While this slows down the process of retrieving updated documents, it can also provide additional assurance that a document has not been tampered with (or help the client find an unaltered version of a document that has been tampered with).
The attacks in this censorship section illustrate the problems that can occur when one blindly trusts a response from a server or peer. Responses can be carefully crafted to mislead the receiving party. In systems such as Publius, which lack any sort of trust or reputation mechanism, one of the few ways to try to overcome such problems is to utilize randomization and replication. By replication we mean that important information should be replicated widely so that the failure of one or a small number of components will not render the service inoperable (or, in the case of Publius, easy to censor). Randomization helps because it can make attacks on distributed systems more difficult. For example, if Publius always retrieved the first three shares from the first three servers in the Publius URL, then the previously described update attack would always succeed if Eve managed to add an update file to these three servers. By randomizing share retrieval the success of such an attack decreases from 100% to less than 1%.
Publius proxy volunteers
In order to perform any Publius operation one must use the Publius client software. The client software consists of an HTTP proxy that intercepts Publius commands and transparently handles non-Publius URLs as well. This HTTP proxy was designed so that many people could use it at once—just like a web server. This means that the proxy can be run on one computer on the Internet and others can connect to it. Individuals who run the proxy with the express purpose of allowing others to connect to it are called Publius proxy volunteers.
Why would someone elect to use a remote proxy rather than a local one? The current Publius proxy requires the computer language Perl and a cryptographic library package called Crypto++. Some individuals may have problems installing these software packages, and therefore the remote proxy provides an attractive alternative.
The problem with remote proxies is that the individual running the remote proxy must be trusted, as we stated in Section 15.3.3 earlier in this chapter. That individual has complete access to all data sent to the proxy. As a result, the remote proxy can log everything it is asked to publish, retrieve, update, or delete. Therefore, users may wish to use an anonymizing tool to access the Publius proxy.
The remote proxy, if altered by a malicious administrator, can also perform any sort of transformation on retrieved documents and can decide how to treat any Publius commands it receives. The solutions to this problem are limited. Short of running your own proxy, probably the best thing you can do is use a second remote proxy to verify the actions of the first.
Third-party trust issues in Publius
Besides trusting the operators of the Publius servers and proxies, users of Publius may have to place trust in other parties. Fortunately some tools exist that reduce the amount of trust that must be placed in these parties.
Other anonymity tools
While not perfect, anonymizing proxies can hide your IP address from a Publius server or a particular web site. As previously stated, the anonymizing proxy itself could be keeping logs.
In addition, your Internet service provider (ISP) can monitor all messages you send over the Internet. An anonymizing proxy doesn’t help us with this problem. Instead, we need some way of hiding all communication from the ISP. Cryptography helps us here. All traffic (messages) between you and another computer can be encrypted. Now the ISP sees only encrypted traffic, which looks like gibberish. The most popular method of encrypting web traffic is the Secure Sockets Layer (SSL) Protocol.
SSL
SSL allows two parties to create a private channel over the Internet. In our case this private channel can be between a Publius client and a server. All traffic to and from the Publius client and server can be encrypted. This hides everything from the ISP except the fact that you are talking to a Publius server. The ISP can see the encrypted channel setup messages between the Publius client and server. Is there a way to hide this piece of information too? It turns out there is.
Mix networks
Mix networks are systems for hiding both the content and destination of a particular message on the Internet.[42] One of the best-known mix networks is discussed in Chapter 7.
A mix network consists of a collection of computers called routers that use a special layered encryption method to hide the content and true destination of a message. To send a message, the sender first decides on a path through a subset of the mixes. Each mix has an associated public and private key pair. All users of the mix network know all the public keys. The message is repeatedly encrypted using the public keys of the routers on the chosen path. First the message is encrypted with the public key of the last router in the chosen path. This encrypted message is then encrypted once again using the public key of the next-to-last router. This is repeated until the message is finally encrypted with the public key of the first router in the chosen path. As the encrypted message is received at each router, the outer layer of encryption is removed by decrypting it with the router’s private key. This reveals only the next router in the mix network to receive the encrypted message. Each router can only decrypt the outer layer of encryption with its private key. Only the last router in the chosen path knows the ultimate destination of the message; however, it doesn’t know where the message originated. The layers of encryption are represented in Figure 15.3.
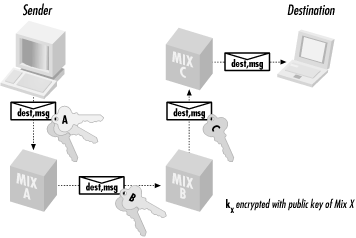
Mix networks are also used to try to thwart traffic analysis. Traffic analysis is a method of correlating messages emanating from and arriving at various computers or routers. For instance, if a message leaves one node and is received by another shortly thereafter, and if the pattern is immediately repeated in the other direction, a monitor can guess that the two systems are engaged in a request and acknowledgment protocol. Even when a mix network is in use, this type of analysis is feasible if all or a large percentage of the mix network can be monitored by an adversary (perhaps a large government). In an effort to combat this type of analysis, mix networks usually pad messages to a fixed length, buffer messages for later transmission, and generate fake traffic on the network, called covering traffic. All of these help to complicate or defeat traffic analysis.
Researchers at the U.S. Department of Defense developed an implementation of mix networks called Onion Routing (http://www.onion-router.net) and deployed a prototype network. The network was taken offline in January 2000. Zero-Knowledge Systems developed a commercial implementation of mix networks in a product called Freedom—see http://www.freedom.net for more information.
Crowds
Crowds is a system whose goals are similar to that of mix networks but whose implementation is quite different. Crowds is based on the idea that people can be anonymous when they blend into a crowd. As with mix networks, Crowds users need not trust a single third party in order to maintain their anonymity. A crowd consists of a group of web surfers all running the Crowds software. When one crowd member makes a URL request, the Crowds software on the corresponding computer randomly chooses between retrieving the requested document or forwarding the request to a randomly selected member of the crowd. The receiving crowd member can also retrieve the requested document or forward the request to a randomly selected member of the crowd, and so on. Eventually, the web document corresponding to the URL is retrieved by some member of the crowd and sent back to the crowd member that initiated the request.
Suppose that computers A, B, C, D, E, and F are all members of a crowd. Computer B wants to anonymously retrieve the web page at the URL http://www.oreilly.com. The Crowds software on computer B sends this URL to a random member of the crowd, say computer F. Computer F decides to send it to computer C. Computer C decides to retrieve the URL. Computer C sends the web page back to computer F. Computer F then sends the web page back to computer B. Notice that the document is sent back over the path of forwarding computers and not directly from C to B. All communication between crowd members is encrypted using symmetric ciphers. Only the actual request from computer C to http://www.oreilly.com remains unencrypted (because the software has to assume that http://www.oreilly.com is uninterested in going along with the crowd). The structure of the system is shown in Figure 15.4.
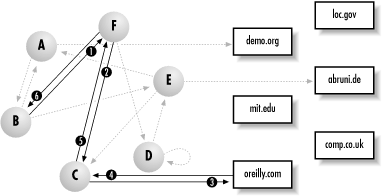
Notice that each computer in the crowd is equally likely to make the request for the specific web page. Even though computer C’s IP address will appear in the log of the server http://www.oreilly.com, the individual using computer C can plausibly deny visiting the server. Computer C is a member of the crowd and therefore could have been retrieving the page for another member of the crowd. Notice that each crowd member cannot tell which other member of the crowd requested the particular URL. In the previous example, computer B sends the URL to computer F. Crowd member F cannot tell if the URL request originated with B or if B was simply an intermediary forwarding the request from another crowd member. This is the reason that the retrieved web page has to be passed back over the list of crowd members that forwarded the URL.
Crowds is itself an example of a peer-to-peer system.
Denial of service attacks
Publius relies on server volunteers to donate disk space so others can publish files in a censorship-resistant manner. Disk space, like all computer resources, is finite. Once all the disks on all the Publius servers are full, no more files can be published until others are deleted. Therefore an obvious attack on Publius is to fill up all the disks on the servers. Publius clients know the locations of all the servers, so identifying the servers to attack is a simple matter. Attacks with the intention of making resources unavailable are called denial of service attacks.
Systems that blindly trust users to conserve precious resources are extremely vulnerable to this kind of attack. Therefore, non-trust based mechanisms are needed to thwart such attacks.
Can systems be designed to prevent denial of service attacks? The initial version of Publius tried to do so by limiting the size of any file published with Publius to 100K. While this certainly won’t prevent someone from trying to fill up the hard drives, it does make this kind of attack more time consuming. Other methods such as CPU payment schemes, anonymous e-cash payment schemes, or quota systems based on IP address may be incorporated into future versions of Publius. While these methods can help deter denial of service attacks, they cannot prevent them completely.
Quota systems
Quota systems based on IP address could work as follows. Each Publius server keeps track of the IP address of each computer that makes a Publish request. If a Publius client has made more than ten Publish requests to a particular server in the last 24 hours, subsequent Publish requests will be denied by that server. Only after a 24-hour time period has elapsed will the server once again honor Publish requests from that Publius client’s IP address.
The problem with this scheme is that it is not foolproof. An attacker can easily fake IP addresses. In addition, the 10-file limit may unfairly limit individuals whose IP addresses are dynamically assigned. For example, suppose someone with an IP address from AOL publishes ten files on some server. If later in the day someone else is assigned that same IP address, the individual will be unfairly excluded from publishing on that particular server.
CPU-based payment schemes
CPU-based payment schemes are used to help prevent denial of service attacks by making it expensive, in terms of time, to carry out such an attack. In Publius, for example, before the server agrees to publish a file, it could ask the publishing client to solve some sort of puzzle. The client spends some time solving the puzzle and then sends the answer to the server. The server agrees to publish the file only if the answer is correct. Each time the particular client asks to publish a file the server can make the puzzle a bit harder—requiring the client to expend more CPU time to find the puzzle answer.
While this scheme makes denial of service attacks more expensive, it clearly does not prevent them. A small Publius system created by civic-minded individuals could be overwhelmed by a large company or government willing to expend the computing resources to do the necessary calculations.
By design, Publius and many other publishing systems have no way of authenticating individuals who wish to publish documents. This commitment to anonymous publishing makes it almost impossible to stop denial of service attacks of this sort.
Anonymous e-cash payment schemes
Another way of preventing denial of service attacks is to require publishers to pay money in order to publish their documents with Publius. An anonymous e-cash system could allow publishers to pay while still remaining anonymous. Even if a well-funded attacker could afford to pay to fill up all available Publius servers, the fees collected from that attacker could be used to buy more disks. This could, of course, result in an arms race if the attacker had enough money to spend on defeating Publius. Chapter 16 discusses CPU- and anonymous e-cash-based payment schemes in more detail.
Legal and physical attacks
All of the methods of censorship described so far involve using a computer. However, another method of trying to censor a document is to use the legal system. Attackers may try to use intellectual property law, obscenity laws, hate speech laws, or other laws to try to force server operators to remove Publius documents from their servers or to shut their servers down completely. However, as mentioned previously, in order for this attack to work, a document would have to be removed from a sufficient number of servers. If the Publius servers in question are all located in the same legal jurisdiction, a single court order could effectively shut down all of the servers. By placing Publius servers in many different jurisdictions, such attacks can be prevented to some extent.
Another way to censor Publius documents is to learn the identity of the publishers and force them to remove their documents from the Publius servers. By making threats of physical harm or job loss, attackers may “convince” publishers to remove their documents. For this reason, it may be especially important for some publishers to take precautions to hide their identities when publishing Publius documents. Furthermore, publishers can indicate at the time of publication that their documents should never be deleted. In this case, no password exists that will allow the publishers to delete their documents—only the server operators can delete the documents.
Trust in other systems
We now examine issues of trust in some popular file-sharing and anonymous publishing systems.
Mojo Nation and Free Haven
Many of the publishing systems described in this book rely on a collection of independently owned servers that volunteer disk space. As disk space is a limited resource, it is important to protect it from abuse. CPU-based payment schemes and quotas, both of which we mentioned previously, are possible deterrents to denial of service attacks, but other methods exist.
Mojo Nation uses a digital currency system called Mojo that must be paid before one can publish a file on a server. In order to publish or retrieve files in the Mojo Nation network, one must pay a certain amount of Mojo.
Mojo is obtained by performing a useful function in the Mojo Nation network. For example, you can earn Mojo by volunteering to host Mojo content on your server. Another way of earning Mojo is to run a search engine on your server that allows others to search for files on the Mojo Nation network.
The Free Haven project utilizes a trust network. Servers agree to store a document based on the trust relationship that exists between the publisher and the particular server. Trust relationships are developed over time and violations of trust are broadcast to other servers in the Free Haven network. Free Haven is described in Chapter 12.
The Eternity Service
Publius, Free Haven, and Mojo Nation all rely on volunteer disk space to store documents. All of these systems have their roots in a theoretical publishing system called the Eternity Service.[43] In 1996, Ross Anderson of Cambridge University first proposed the Eternity Service as a server-based storage medium that is resistant to denial of service attacks.
An individual wishing to anonymously publish a document simply submits it to the Eternity Service with an appropriate fee. The Eternity Service then copies the document onto a random subset of servers participating in the service. Once submitted, a document cannot be removed from the service. Therefore, an author cannot be forced, even under threat, to delete a document published on the Eternity Service.
Anderson envisioned a system in which servers were spread all over the world, making the system resistant to legal attacks as well as natural disasters. The distributed nature of the Eternity Service would allow it to withstand the loss of a majority of the servers and still function properly.
Anderson outlined the design of this ambitious system, but did not provide the crucial details of how one would construct such a service. Over the years, a few individuals have described in detail and actually implemented scaled-down versions of the Eternity Service. Publius, Free Haven, and the other distributed publishing systems described in this book fit into this category.
Eternity Usenet
An early implementation of a scaled-down version of the Eternity Service was proposed and implemented by Adam Back. Unlike the previously described publishing systems, this system didn’t rely on volunteers to donate disk space. Instead, the publishing system was built on top of the Usenet news system. For this reason the system was called Eternity Usenet.
The Usenet news system propagates messages to servers all over the world and therefore qualifies as a distributed storage medium. However, Usenet is far from an ideal long-term storage mechanism. Messages posted to a Usenet newsgroup can take days to propagate to all Usenet servers. Not all Usenet news servers subscribe to all Usenet newsgroups. In fact, any system administrator can locally censor documents by not subscribing to a particular newsgroup. Usenet news posts can also become the victims of cancel or supercede messages. They are relatively easy to fake and therefore attractive to individuals who wish to censor a particular Usenet post.
The great volume of Usenet traffic necessitates the removal of old Usenet articles in favor of newer ones. This means that something posted to Usenet today may not be available two weeks from now, or even a few days from now. There are a few servers that archive Usenet articles for many years, but because there are not many of these servers, they present an easy target for those who wish to censor an archived document.
Finally, there is no way to tell if a Usenet message has been modified. Eternity Usenet addresses this by allowing an individual to digitally sign the message.
File-sharing systems
Up until now we have been discussing only systems that allow an individual to publish material on servers owned by others. However, Napster, a program that allows individuals to share files residing on their own hard drives, has been said to have started the whole peer-to-peer revolution. Napster allows individuals to share MP3 files over the Internet. The big debate concerning Napster is whether this file sharing is legal. Many of the shared MP3 files are actually copied from one computer to another without any sort of royalty being paid to the artist that created the file. We will not discuss this particular issue any further as it is beyond the scope of this chapter. We are interested in the file-sharing mechanism and the trust issues involved.
Napster
Let’s say Alice has a collection of MP3 files on her computer’s hard drive. Alice wishes to share these files with others. She downloads the Napster client software and installs it on her computer. She is now ready to share the MP3 files. The list of MP3 files and associated descriptions is sent to the Napster server by the client software. This server adds the list to its index of MP3 files. In addition to storing the name and description of the MP3 files, the server also stores Alice’s IP address. Alice’s IP address is necessary, as the Napster server does not actually store the MP3 files themselves, but rather just pointers to them.
Alice can also use the Napster client software to search for MP3 files. She submits a query to the Napster server and a list of matching MP3 files is returned. Using the information obtained from the Napster server, Alice’s client can connect to any of the computers storing these MP3 files and initiate a file transfer. Once again the issue of logging becomes important. Not only does Alice have to worry about logging on the part of the Napster server, but she also has to worry about logging done by the computer that she is copying files from. It is this form of logging that allowed the band Metallica to identify individuals who downloaded their music.
The natural question to ask is whether one of our previously described anonymizing tools could be used to combat this form of logging. Unfortunately the current answer is no. The reason for this is that the Napster server and client software speak a protocol that is not recognized by any of our current anonymizing tools. A protocol is essentially a set of messages recognized by both programs involved in a conversation—in this case the Napster client and server. This does not mean that such an anonymizing tool is impossible to build, only that current tools won’t fit the bill.
Gnutella
Gnutella, described in Chapter 8, is a pure peer-to-peer file-sharing system. Computers running the Gnutella software connect to some preexisting network and become part of this network. We call computers running the Gnutella software Gnutella clients. Once part of this network, the Gnutella client can respond to queries sent by other members of the network, generate queries itself, and participate in file sharing. Queries are passed from client to client and responses are passed back over the same set of clients that the requests originated from. This prevents meaningful logging of IP addresses and queries, because the client attempting to log the request has no way of knowing which client made the original request. Each client is essentially just forwarding the request made by another member of the network. Queries therefore remain for the most part anonymous. The individual that made the query is hidden among the other members of the peer-to-peer network, as with the Crowds system.
File transfer in Gnutella is done directly instead of via intermediaries. This is done for performance reasons; however, it also means that file transfer is not anonymous. The individual copying the file is no longer hidden among the other network members. The IP address of the client copying the file can now be logged.
Let’s say that client A wishes to copy a file that resides on client B. Gnutella client A contacts client B and a file transfer is initiated. Client B can now log A’s IP address and the fact that A copied a particular file. Although this sort of logging may seem trivial and harmless, it led to the creation of the web site called the Gnutella Wall of Shame. This web site lists the IP addresses and domain names of computers that allegedly downloaded a file that was advertised as containing child pornography. The file did not actually contain child pornography, but just the fact that a client downloaded the file was enough to get it placed on the list. Of course, any web site claiming to offer specific content could perform the same violation of privacy.
Freenet
Freenet, described in Chapter 9, is a pure peer-to-peer anonymous publishing system. Files are stored on a set of volunteer file servers. This set of file servers is dynamic—servers can join and leave the system at any time. A published file is copied to a subset of servers in a store-and-forward manner. Each time the file is forwarded to the next server, the origin address field associated with the file can be changed to some random value. This means that this field is essentially useless in trying to determine where the file originated. Therefore, files can be published anonymously.
Queries are handled in exactly the same way—the query is handed from one server to another and the resulting file (if any) is passed back through the same set of servers. As the file is passed back, each server can cache it locally and serve it in response to future requests for that file. It is from this local caching that Freenet derives its resistance to censorship. This method of file transfer also prevents meaningful logging, as each server doesn’t know the ultimate destination of the file.
Content certification
Now that we have downloaded a file using one of the previously described systems, how do we know it is the genuine article? This is exactly the same question we asked at the beginning of this chapter. However, for certain files we may not really care that we have been duped into downloading the wrong file. A good example of this is MP3 files. While we may have wasted time downloading the file, no real harm was done to our computer. In fact, several artists have made bogus copies of their work available on such file-sharing programs as Napster. This is an attempt to prevent individuals from obtaining the legitimate version of the MP3 file.
The “problem” with many of the publishing systems described in this book is that we don’t know who published the file. Indeed this is actually a feature required of anonymous publishing systems. Anonymously published files are not going to be accompanied by a digital certificate and signature (unless the signature is associated with a pseudonym). Some systems, such as Publius, provide a tamper-check mechanism. However, just because a file passes a tamper check does not mean that the file is virus-free and has actually been uploaded by the person believed by the recipient to have uploaded it.
Trust and search engines
File-sharing and anonymous publishing programs provide for distributed, and in some cases fault tolerant, file storage. But for most of these systems, the ability to store files is necessary but not sufficient to achieve their goals. Most of these systems have been built with the hope of enabling people to make their files available to others. For example, Publius was designed to allow people to publish documents so that they are resistant to censorship. But publishing a document that will never be read is of limited use. As with the proverbial tree falling in the forest that nobody was around to hear, an unread document makes no sound—it cannot inform, motivate, offend, or entertain. Therefore, indexes and search engines are important companions to file-sharing and anonymous publishing systems.
As previously stated, all of these file-sharing and anonymous publishing programs are still in their infancy. Continuing this analogy, we can say that searching technologies for these systems are in the embryonic stage. Unlike the Web, which now has mature search engines such as Google and Yahoo!, the world of peer-to-peer search engines consists of ad hoc methods, none of which work well in all situations. Web search engines such as Google catalogue millions of web pages by having web crawlers (special computer programs) read web pages and catalogue them. This method will not work with many of the systems described in this book. Publius, for example, encrypts its content and only someone possessing the URL can read the encrypted file. It makes no sense for a web crawler to visit each of the Publius servers and read all the files stored on them. The encrypted files will look like gibberish to the web crawler.
The obvious solution is to somehow send a list of known Publius URLs to a special web crawler that knows how to interpret them. Of course, submitting the Publius URL to the web crawler would be optional, as one may not wish to widely publicize a particular document.
Creating a Publius web crawler and search engine would be fairly straightforward. Unfortunately this introduces a new way to censor Publius documents. The company or individual operating the Publius web crawler can censor a document by simply removing its Publius URL from the crawler’s list. The owners of the search engine can not only log your query but can also control exactly what results are returned from the search engine.
Let us illustrate this with a trivial example. You go to the Publius search engine and enter the phrase “Windows 95.” The search engine examines the query and decides to send you pages that only mention Linux. Although this may seem like a silly example, one can easily see how this could lead to something much more serious. Of course, this is not a problem unique to Publius search engines—this problem can occur with the popular web search engines as well. Indeed, many of the popular search engines sell advertisements that are triggered by particular search queries, and reorder search results so that advertisers’ pages are listed at the top.
Distributed search engines
The problem with a centralized search engine, even if it is completely honest, is that it has a single point of failure. It presents an enticing target to anyone who wishes to censor the system. This type of attack has already been used to temporarily shut down Napster. Because all searches for MP3 files are conducted via the Napster server, just shut down the server and the system becomes useless.
This dramatically illustrates the need for a distributed index, the type of index that we find in Freenet. Each Freenet server keeps an index of local files as well as an index of some files stored in some neighboring servers. When a Freenet server receives a query it first checks to see if the query can be satisfied locally. If it cannot, it uses the local index to decide which server to forward the request to. The index on each server is not static and changes as files move through the system.
One might characterize Gnutella as having a distributed index. However, each client in the network is concerned only with the files it has stored locally. If a query can be satisfied locally, the client sends a response. If not, it doesn’t respond at all. In either case the previous client forwards its query to other members of the network. Therefore, one query can generate many responses. The query is essentially broadcast to all computers on the Gnutella network.
Each Gnutella client can interpret the query however it sees fit. Indeed, the Gnutella client can return a response that has nothing at all to do with the query. Therefore, the query results must be viewed with some suspicion. Again it boils down to the issue of trust.
In theory, an index of Publius documents generated by a web crawler that accepts submissions of Publius URLs could itself be published using Publius. This would prevent the index from being censored. Of course, the URL submission system and the forms for submitting queries to the index could be targeted for censorship.
Note that in many cases, indexes and search engines for the systems described in this book can be developed as companion systems without changing the underlying distributed system. It was not necessary for Tim Berners-Lee (the inventor of the World Wide Web) to build the many web search engines and indexes that have developed. The architecture of the Web was such that these services could be built on top of the underlying infrastructure.
Deniability
The ability to locate Publius documents can actually be a double-edged sword. On the one hand, being able to find a document is essential for that document to be read. On the other hand, the first step in censoring a document is locating it.
One of the features of Publius is that server administrators cannot read the content stored on their servers because the files are encrypted. A search engine could, in some sense, jeopardize this feature. Armed with a search engine, Publius administrators could conceivably learn that their servers are hosting something they find objectionable. They could then go ahead and delete the file from their servers. Therefore, a search engine could paradoxically lead to greater censorship in such anonymous publishing systems.
Furthermore, even if server administrators do not wish to censor documents, once presented with a Publius URL that indicates an objectionable document resides on their servers, they may have little choice under local laws. Once the server operators know what documents are on their servers, they lose the ability to deny knowledge of the kinds of content published with Publius.
Some Publius server operators may wish to help promote free speech but may not wish to specifically promote or endorse specific speech that they find objectionable. While they may be willing to host a server that may be used to publish content that they would find objectionable, they may draw the line at publicizing that content. In effect, they may be willing to provide a platform for free speech, but not to provide advertising for the speakers who use the platform.
Table 15.2 summarizes the problems with censorship-resistant and file sharing systems we have discussed in this chapter.
|
Risk |
Solution |
Trust principle |
|
Servers, proxies, ISPs, or other “nodes” you interact with may log your requests (making it possible for your actions to be traced). |
Use a secure channel and/or an anonymity tool so other parties do not get access to information that might link you to a particular action. |
Reduce risk, and reduce the number of people that must be trusted. |
|
Proxies and search engines may alter content they return to you in ways they don’t disclose. |
Try multiple proxies (and compare results before trusting any of them) or run your own proxy. |
Reduce risk, and reduce the number of people that must be trusted. |
|
Multiple parties may collaborate to censor your document. |
Publish your document in a way that requires a large number of parties to collaborate before they can censor successfully. (Only a small subset of parties needs to be trusted not to collaborate, and any subset of that size will do.) |
Reduce the number of people that must be trusted. |
|
Parties may censor your document by making it appear as if you updated your document when you did not. |
Publish your document in a way that it cannot be updated, or publish your document in a way that requires a large number of parties to collaborate before they can make it appear that you updated your document. (Only a small subset of parties needs to be trusted not to collaborate, and any subset of that size will do.) |
Reduce the number of people that must be trusted. |
|
Publishers may flood disks with bogus content as part of a denial of service attack. |
Impose limits or quotas on publishers; require publishers to pay for space with money, computation, space donations; establish a reputation system for publishers. |
Reduce risk; look for positive reputations. |
|
Censors may use laws to try to force documents to be deleted. |
Publish your document in a way that requires a large number of parties to collaborate before they can censor successfully. (Only a small subset of parties needs to be trusted not to collaborate, and any subset of that size will do.) |
Reduce the number of people that must be trusted. |
|
Censors may threaten publishers to get them to delete their own documents. |
Publish your document in a way that even the publisher cannot delete it. |
Reduce risk, and reduce the number of people that must be trusted. |
Conclusions
In this chapter we have presented an overview of the areas where trust plays a role in distributed file-sharing systems, and we have described some of the methods that can be used to increase trust in these systems. By signing software they make available for download, authors can provide some assurance that their code hasn’t been tampered with and facilitate the building of a reputation associated with their name and key. Anonymity tools and tools for establishing secure channels can reduce the need to trust ISPs and other intermediaries not to record or alter information sent over the Internet. Quota systems, CPU payment systems, and e-cash payment systems can reduce the risk of denial of service attacks. Search engines can help facilitate dissemination of files but can introduce additional trust issues.
There are several open issues. The first is the lack of existence of a global Public Key Infrastructure (PKI). Many people believe that such a PKI is not ever going to be possible. This has ramifications for trust, because it implies that people may never be able to trust signed code unless they have a direct relationship with the signer. While the problem of trusting strangers exists on the Net, strangely, it is also very difficult to truly be anonymous on the Internet. There are so many ways to trace people and correlate their online activity that the sense of anonymity that most people feel online is misplaced. Thus, there are two extremes of identity: both complete assurance of identity and total anonymity are very difficult to achieve. More research is needed to see how far from the middle we can push in both directions, because each extreme offers possibilities for increased trust in cyberspace.
[40] For a more comprehensive discussion of this topic, see Bruce Schneier (1999), Secrets and Lies: Digital Security in a Networked World, John Wiley & Sons.
[41] Proving certain properties of programs can be reduced to proving the "Halting Problem.” See, for example, Michael Sipser (1997). Introduction to the Theory of Computation. PWS Publishing Company.
[42] Mix networks were first introduced by David Chaum. See David Chaum (1981), “Untraceable Electronic Mail, Return Addresses, and Digital Pseudonyms,” Communications of the ACM, vol. 24, no. 2, pp. 84-88.
[43] See Ross Anderson (1996), “The Eternity Service,” PragoCrypt’96.