Chapter 6. Twootr
The Challenge
Joe was an excited young chap, keen to tell me all about his new startup idea. He was on a mission to help people communicate better and faster. He enjoyed blogging but wondered about how to get people to blog more frequently in smaller amounts. He was calling it micro-blogging. The big idea was that if you restricted the size of the messages to 140 characters that people would post little and often rather than in big messages.
We asked Joe if he felt that this restriction would encourage people to just post short, pithy statements that didn’t really mean anything. He said “Yolo!” We asked Joe how he was going to make money. He said “Yolo!” We asked Joe what he planned to call the product. He said “Twootr!” We thought it sounded like a cool and original idea, so we decided to help him build his product.
The Goal
In this chapter you will learn about the big picture of putting a software application together. A lot of the previous apps in this book were smaller examples—batch jobs that would run on the command line. Twootr is a server-side Java application, similar to the kind of application that most Java developers write.
In this chapter you’ll have the opportunity to learn about a number of different skills:
-
How to take a big picture description and break it down into different architectural concerns
-
How to use test doubles to isolate and test interactions from different components within your codebase
-
How to think outside-in—to go from requirements through to the core of your application domain
At several places in this chapter we will also talk not only about the final design of the software, but how we got there. There are a few places where we show how certain methods iteratively evolved over the development of the project in response to an expanding list of implemented features. This will give you a feel for how software projects can evolve in reality, rather than simply presenting an idealized final design abstract of its thought process.
Twootr Requirements
The previous applications that you’ve seen in this book are all line-of-business applications that process data and documents. Twootr, on the other hand, is a user-facing application. When we talked to Joe about the requirements for his system, it became apparent that he had refined his ideas a bit. Each micro-blog from a user would be called a twoot and users would have a constant stream of twoots. In order to see what other users were twooting about, you would follow those users.
Joe had brainstormed some different use cases—scenarios in which his users use the service. This is the functionality that we need to get working in order to help Joe achieve his goal of helping people communicate better:
-
Users log in to Twootr with a unique user ID and password.
-
Each user has a set of other users that they follow.
-
Users can send a twoot, and any followers who are logged in should immediately see the twoot.
-
When users log in they should see all the twoots from their followers since they last logged in.
-
Users should be able to delete twoots. Deleted twoots should no longer be visible to followers.
-
Users should be able to log in from a mobile phone or a website.
The first step in explaining how we go about implementing a solution fit for Joe’s needs is to overview and outline the big-picture design choices that we face.
Design Overview
Note
If at any point you want to look at the source code for this
chapter, you can look at the package com.iteratrlearning.shu_book.chapter_06
in the book’s code repository.
If you want to see the project in action, you should run the TwootrServer class
from your IDE and then browser to http://localhost:8000.
If we pick out the last requirement and consider it first then it strikes us that, in contrast to many of the other systems in this book, we need to build a system that has many computers communicating together in some way. This is because our users may be running the software on different computers—for example, one user may load the Twootr website on their desktop at home and another may run Twootr on a mobile phone. How will these different user interfaces talk to each other?
The most common approach taken by software developers trying to approach this kind of problem is to use the client-server model. In this approach to developing distributed applications we group our computers into two main groups. We have clients who request the use of some kind of service and servers who provide the service in question. So in our case our clients would be something like a website or a mobile phone application that provides a UI through which we can communicate with the Twootr server. The server would process the majority of the business logic and send and receive twoots to different clients. This is shown in Figure 6-1.
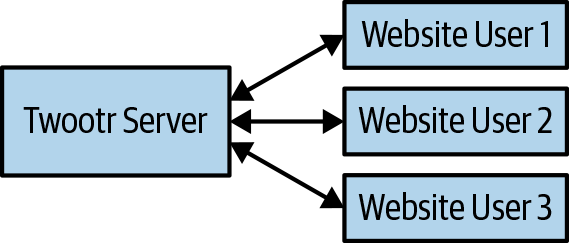
Figure 6-1. Client-server model
It was clear from the requirements and talking to Joe that a key part of this system working was the ability to immediately view twoots from users you follow. This means that the user interface would have to have the ability to receive twoots from the server as well as send them. There are, in big-picture terms, two different styles of communication that can be used to achieve this goal: pull-based or push-based.
Pull-Based
In a pull-based communication style the client makes a request to the server and queries it for information. This style of communication is often called a point-to-point style or a request-response style of communication. This is a particularly common communication style, used by most of the web. When you load a website it will make an HTTP request to some server, pulling the page’s data. Pull-based communication styles are useful when the client controls what content to load. For example, if you’re browsing wikipedia you control which pages you’re interested in reading about or seeing next and the content responses are sent back to you. This is shown in Figure 6-2.

Figure 6-2. Pull communications
Push-Based
Another approach is a push-based communication style. This could be referred to as a reactive or event-driven communication approach. In this model, streams of events are emitted by a publisher and many subscribers listen to them. So instead of each communication being 1 to 1, they are 1 to many. This is a really useful model for systems where different components need to talk in terms of ongoing communication patterns of multiple events. For example, if you’re designing a stock market exchange then different companies want to see updated prices, or ticks, constantly rather than having to make a new request every time they want to see a new tick. This is shown in Figure 6-3.

Figure 6-3. Push communications
In the case of Twootr, an event-driven communication style seems most suitable for the application as it mainly consists of ongoing streams of twoots. The events in this model would be the twoots themselves. We could definitely still design the application in terms of a request-response communication style. If we went down this route, however, the client would have to be regularly polling the server and asking with a request saying, “Hey, has anyone twooted since my last request?” In an event-driven style you simply subscribe to your events—i.e., follow another user—and the server pushes the twoots that you’re interested in to the client.
This choice of an event-driven communication style influences the rest of the application design from here on in. When we write code that implements the main class of our application, we’ll be receiving events and sending them. How to receive and send events determines the patterns within our code and also how we write tests for our code.
From Events to Design
Having said that, we’re building a client-server application—this chapter will focus on the server-side component rather than the client component. In “User Interface” you will see how a client can be developed for this codebase, and an example client is implemented in the code samples that go with this book. There are two reasons why we focus on the server-side component. First, this is a book on how to write software in Java, which is extensively used on the server side but not so widely on the client side. Second, the server side is where the business logic lies: the brains of the application. The client side is a very simple codebase that just needs to bind a UI to publishing and subscribing events.
Communication
Having established that we want to send and receive events, a common next step in our design would be to pick some kind of technology to send those messages to or from our client to our server. There are lots of choices in this area, and here are a few routes that we could go down:
-
WebSockets are a modern, lightweight communications protocol to provide duplex (two-way) communication of events over a TCP stream. They are often used for event-driven communication between a web browser and a web server and is supported by recent browser releases.
-
Hosted cloud-based message queues such as Amazon Simple Queue Service are an increasingly popular choice for broadcasting and receiving events. A message queue is a way of performing inter-process communication by sending messages that can either be received by a single process of a group of processes. The benefit of being a hosted service is that your company doesn’t have to expend effort on ensuring that they are reliably hosted.
-
There are many good open source message transports or message queues, such as Aeron, ZeroMQ, and AMPQ implementations. Many of these open source projects avoid vendor lock-in, though they may limit your choice of client to something that can interact with a message queue. For example, they wouldn’t be appropriate if your client is a web browser.
That’s far from an exhaustive list, and as you can see different technologies have different trade-offs and use cases. It might be the case that, for your own program, you pick one of these technologies. At a later date you decide that it’s not the right choice and want to pick another. It might be that you wish to choose different types of communications technologies for different types of connecting clients. Either way, making that decision at the beginning of your project and being forced to live with it forever isn’t a great architectural decision. Later in this chapter we will see how it’s possible to abstract away this architectural choice to avoid a big-mistake-up-front architectural decision.
It’s even possibly the case that you may want to combine different communications approaches; for example, by using different communications approaches for different types of client. Figure 6-4 visualizes using WebSockets to communicate with a website and Android push notifications for your Android mobile app.
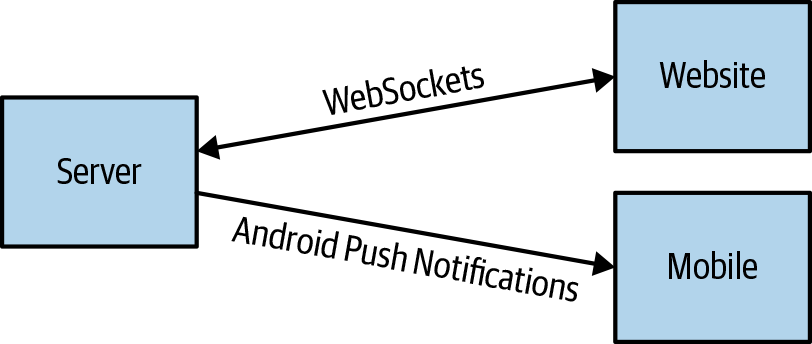
Figure 6-4. Different communications approaches
GUI
Coupling the choice of UI communications technology or your UI to your core server-side business logic also has several other disadvantages:
-
It is difficult and slow to test. Every test would have to test the system by publishing and subscribing to events running in parallel with the main server.
-
It breaks the Single Responsibility Principle that we talked about in Chapter 2.
-
It assumes that we’re going to have a UI as our client. At first this might be a solid assumption for Twootr, but in the glorious future we might wish to have interactive artificially intelligent chat bots helping solve user problems. Or twooting cat GIFs at least!
The takeaway from this is that we would be prudent to introduce some kind of abstraction to decouple the messaging for our UI from the core business logic. We need an interface through which we can send messages to the client and an interface through which we can receive messages from the client.
Persistence
There are similar concerns at the other side of the application. How should we store the data for Twootr? We have many choices to pick from:
-
Plain-text files that we can index and search ourselves. It’s easy to see what has been logged and avoids a dependency on another application.
-
A traditional SQL database. It’s well tested and understood, with strong querying support.
-
A NoSQL database. There are a variety of different databases here with differing use cases, query languages, and data storage models.
We don’t really know which to pick at the beginning of our software project and our needs may evolve over time. We really want to decouple our choice of storage backend from the rest of our application. There’s a similarity between these different issues—both are about wanting to avoid coupling yourself to a specific technology.
The Hexagonal Architecture
In fact, there’s a name for a more general architectural style here that helps us solve this problem. It’s called the Ports and Adapters or Hexagonal architecture and was originally introduced by Alister Cockburn. The idea, shown in Figure 6-5, is that the core of your application is the business logic that you’re writing, and you want to keep different implementation choices separate from this core logic.
Whenever you have a technology-specific concern that you want to decouple from the core of your business logic, you introduce a port. Events from the outside world arrive at and depart from your business logic core through a port. An adapter is the technology-specific implementation code that plugs into the port. For example, we may have a port for publishing and subscribing to UI events and a WebSocket adapter that talks to a web browser.
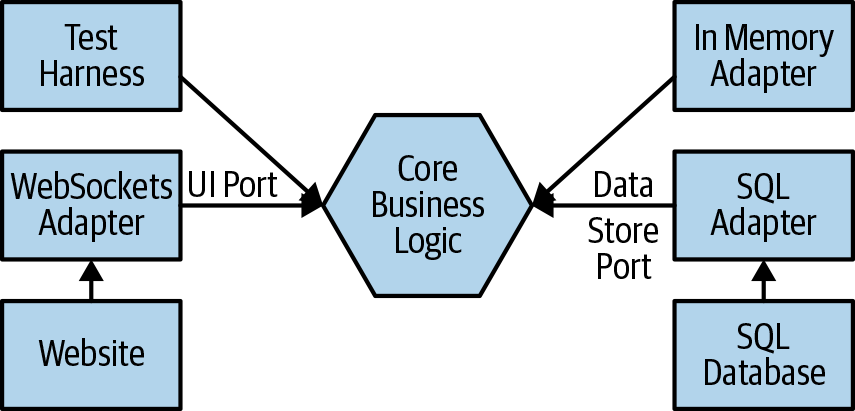
Figure 6-5. Hexagonal architecture
There are other components within a system for which you might want to create a port and adapter abstraction. One thing that might be relevant to an expanded Twootr implementation is a notification system. Informing users that they have a lot of twoots they might be interested in logging in and seeing would be a port. You may wish to implement this with an adapter for email or text messages.
Another example port that comes to mind is authentication services. You may wish to start off with an adapter that just stores the usernames and passwords, later replacing it with an OAuth backend or tying it to some other system. In the Twootr implementation that this chapter describes we don’t go so far as to abstract out authentication. This is because our requirements and initial brainstorming session haven’t come up with a good reason why we might want different authentication adapters as of yet.
You might be wondering how you separate what should be a port and what should be part of the core domain. At one extreme you could have hundreds or even thousands of ports in your application and nearly everything could be abstracted out of the core domain. At the other extreme you could have none at all. Where you decide your application should live on this sliding scale is a matter of personal judgment and circumstance: there are no rules.
A good principle to help you decide might be to think of anything that is critical to the business problem that you’re solving as living inside the core of the application and anything that is technology specific or involves communicating with the outside world as living outside the core application. That is the principle that we’ve used in this application. So business logic is part of our core domain, but responsibility for persistence and event-driven communication with the UI are hidden behind ports.
Where to Begin
We could proceed with outlining the design in more and more detail at this stage, designing more elaborate diagrams and deciding what functionality should live in what class. We’ve never found that to be a terribly productive approach to writing software. It tends to result in lots of assumptions and design decisions being pushed down into little boxes in an architecture diagram that turn out to be not so little. Diving straight into coding with no thought to overall design is unlikely to result in the best software, either. Software development needs just enough upfront design to avoid it collapsing into chaos, but architecture without coding enough bits to make it real can quickly become sterile and unrealistic.
Note
The approach of pushing all your design work before you start writing your code is called Big Design Up Front, or BDUF. BDUF is often contrasted with the Agile, or iterative, development methodologies that have become more popular over the last 10–20 years. Since we find iterative approaches to be more effective, we’ve described the design process over the next couple of sections in an iterative manner.
In the previous chapter you saw an introduction to TDD—test-driven development—so by now you should be
familiar with the fact that it’s a good idea to start writing our project with a test class, TwootrTest.
So let’s start with a test that our user can log in: shouldBeAbleToAuthenticateUser().
In this test a user will log in and be correctly authenticated. A skeleton for this method can be seen in
Example 6-1.
Example 6-1. Skeleton for shouldBeAbleToAuthenticateUser()
@TestpublicvoidshouldBeAbleToAuthenticateUser(){// receive logon message for valid user// logon method returns new endpoint.// assert that endpoint is valid}
In order to implement the test we need to create a Twootr class and have a way of modeling the login
event. As a matter of convention in this module any method that corresponds to an event happening
will have the prefix on. So, for example, we’re going to create a method here called onLogon. But
what is the signature of this method—what information does it need to take as parameters and what
should it reply with?
We’ve already made the architectural decision to separate our UI communications layer with a
port. So here we need to make a decision as to how to define the API. We need a way of emitting events
to a user—for example, that another user who the user is following has twooted. We also need a way
of receiving events from a given user. In Java we can just use a method call to represent the events.
So whenever a UI adapter wants to publish an event to Twootr, it will call a method on some object
owned by the core of the system. Whenever Twootr wants to publish an event, it will call a method on some
object owned by the adapter.
But the goal of ports and adapters is that we decouple the core from a specific adapter implementation. This means we need some way of abstracting over different adapters—an interface. We could have chosen to use an abstract class at this point in time. It would have worked, but interfaces are more flexible because adapter classes can implement more than one interface. Also by using an interface we’re discouraging our future selves from the devilish temptation to add some state into the API. Introducing state in an API is bad because different adapter implementations may want to represent their internal state in a different way, so putting state into the API could result in coupling.
We don’t need to use an interface for the object where user events are published as there will only be a single implementation in the core—we can just use a regular class. You can see what our approach looks like visually in Figure 6-6. Of course we need a name, or indeed a pair of names, in order to represent this API for sending and receiving events. There are lots of choices here; in practice, anything that made it clear that these were APIs for sending and receiving events would do well.
We’ve gone
with SenderEndPoint for the class that sends events to the core and ReceiverEndPoint for the interface that
receives events from the core. We could in fact flip the sender and receiver designations around to work from the
perspective of the user or the adapter. This ordering has the advantage that we’re thinking core first, adapters
second.
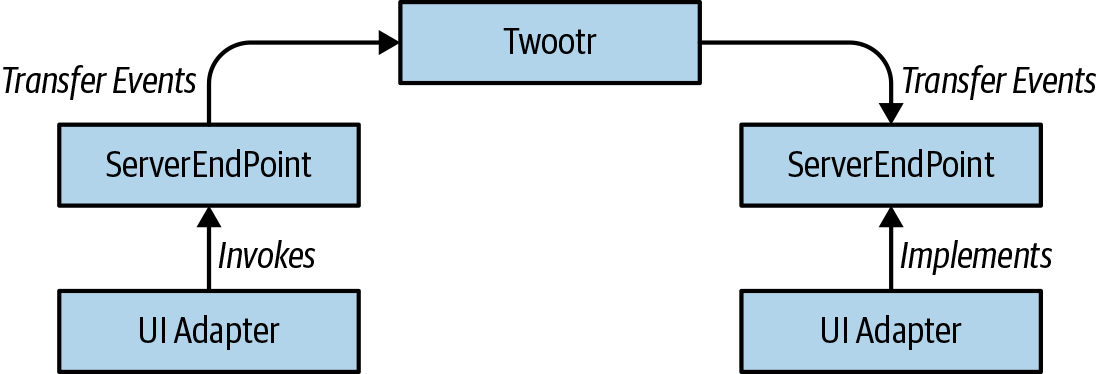
Figure 6-6. Events to code
Now that we know the route we’re going down we can write the shouldBeAbleToAuthenticateUser() test. This just needs
to test that when we log on to the system with a valid username that the user logs on. What does logging on mean here?
Well, we want to return a valid SenderEndPoint object, as that is the object returned to the UI in order to represent
the user who has just logged on. We then need to add a method to our Twootr class in order to represent the
logon event happening and allow the test to compile. The signature of our implementation is shown in
Example 6-2. Since TDD encourages us to do the minimal implementation work in order to get a test to pass
and then evolve the implementation, we’ll just instantiate the SenderEndPoint object and return it from our method.
Example 6-2. First onLogon signature
SenderEndPointonLogon(StringuserId,ReceiverEndPointreceiver);
Now that we’ve got a nice green bar we need to write another test—shouldNotAuthenticateUnknownUser(). This
will ensure that we don’t allow a user who we don’t know about to log on to the system. When writing this
test, an interesting issue crops up. How do we model the failure scenario here? We don’t want to return a
SenderEndPoint here, but we do need a way of indicating to our UI that the logon has failed. One approach
would be to use exceptions, which we described in Chapter 3.
Exceptions could work here, but arguably it’s a bit of an abuse of the concept. Failing to logon isn’t really
an exceptional scenario—it’s a thing that happens all the time. People typo their username, they typo their
passwords, and they can sometimes even go to the wrong website! An alternative, and common, approach would be to
return the
SenderEndPoint if the logon succeeds, and return null if it fails. This is a flawed approach for several
reasons:
-
If another developer uses the value without checking that it isn’t
null, they get aNullPointerException. These kinds of bugs are incredibly common mistakes for Java developers to make. -
There is no compile-time support in order to help avoid these kind of issues. They crop up at runtime.
-
There is no way to tell from looking at the signature of a method whether it is deliberately returning a
nullvalue to model failure or whether there’s just a bug in the code.
A better approach that can help here is to use the Optional data type. This was introduced in Java 8 and
models values that may be present or absent. It’s a generic type and can be thought of a box where a value may or
may not lurk inside—a collection with only one or no values inside. Using Optional as a return type
makes it explicit what happens when the method fails to return its value—it returns the empty Optional.
We’ll talk about how to create and use the Optional type throughout this chapter. So we now refactor our
onLogon method to have the signature in Example 6-3.
Example 6-3. Second onLogon signature
Optional<SenderEndPoint>onLogon(StringuserId,ReceiverEndPointreceiver);
We also need to modify the shouldBeAbleToAuthenticateUser() test in order to ensure that it checks that the
Optional value is present. Our next test is shouldNotAuthenticateUserWithWrongPassword() and is shown in
Example 6-4. This test ensures that the user who is logging
in has the correct password for their logon to work. That means our onLogon() method needs to not only
store the names of our users, but also their passwords in a Map.
Example 6-4. shouldNotAuthenticateUserWithWrongPassword
@TestpublicvoidshouldNotAuthenticateUserWithWrongPassword(){finalOptional<SenderEndPoint>endPoint=twootr.onLogon(TestData.USER_ID,"bad password",receiverEndPoint);assertFalse(endPoint.isPresent());}
A simple approach for storing the data in this case would have been to use a Map<String, String>, where
the key is the user ID and the value is the password. In reality, though, the concept of a user is important to
our domain. We’ve got stories that refer to users and a lot of the system’s functionality is related to users
talking to each other. It’s time for a User domain class to be added to our implementation. Our data
structure will be modified to a Map<String, User>, where the key is the user’s ID and the value is the User object
for the user in question.
A common criticism about TDD is that it discourages the design of software. That it just leads you to write tests and you end up with an anaemic domain model and have to just rewrite your implementation at some point. By an anaemic domain model we mean a model where the domain objects don’t have much business logic and it’s all scattered across different methods in a procedural style. That’s certainly a fair critique of the way that TDD can sometimes be practiced. Spotting the right point in time to add a domain class or make some concept real in code is a subtle thing. If the concept is something that your user stories are always referring to, though, you should really have something in your problem domain representing it.
There are some clear anti-patterns that you can spot, however. For example, if you’ve built different lookup structures
with the same key, that you add to at the same time but relate to different values, then you’re missing a domain class.
So if we track the set of followers and the password for our user and we have two Map objects
from the user ID, one onto followers and one onto a password, then there’s a concept in the problem domain missing. We
actually introduced our User class here with only a single value that we cared about—the password—but an
understanding of the problem domain tells us that users are important so we weren’t being overly premature.
Passwords and Security
So far we’ve avoid talking about security at all. In fact, not talking about security concerns and hoping that they will just go away is the technology industries’ favorite security strategy. Explaining how to write secure code isn’t a primary, or even secondary, objective of this book; however, Twootr does use and store passwords for authentication so it’s worth thinking a little about this topic.
The simplest approach to storing passwords is to treat them like any other String, known as storing them
plain text. This is bad practice in general as it means anyone who has access to your database has access
to the passwords of all your users. A malicious person or organization can, and in many cases has, used
plain-text passwords in order to log in to your system and pretend to be the users. Additionally, many people
use the same password for multiple different services. If you don’t believe us, ask any of your elderly
relatives!
In order to avoid anyone with access to your database just reading the passwords, you can apply a cryptographic hash function to the password. This is a function that takes some arbitrarily sized input string and converts it to some output, called a digest. Cryptographic hash functions are deterministic, so that if you want to hash the same input again you can get the same result. This is essential in order to be able to check the hashed password later. Another key property is that while it should be quick to go from input to digest, the reverse function should take so long or use so much memory that it is impractical for an attacker to reverse the digest.
The design of cryptographic hash functions is an active research topic on which governments and companies spend a lot of money. They are hard to implement correctly so you should never write your own—Twootr uses an established Java library called Bouncy Castle. This is open source and has undergone heavy peer review. Twootr uses the Scrypt hashing function, which is a modern algorithm specifically designed for storing passwords. Example 6-5 shows an example of the code.
Example 6-5. KeyGenerator
classKeyGenerator{privatestaticfinalintSCRYPT_COST=16384;privatestaticfinalintSCRYPT_BLOCK_SIZE=8;privatestaticfinalintSCRYPT_PARALLELISM=1;privatestaticfinalintKEY_LENGTH=20;privatestaticfinalintSALT_LENGTH=16;privatestaticfinalSecureRandomsecureRandom=newSecureRandom();staticbyte[]hash(finalStringpassword,finalbyte[]salt){finalbyte[]passwordBytes=password.getBytes(UTF_16);returnSCrypt.generate(passwordBytes,salt,SCRYPT_COST,SCRYPT_BLOCK_SIZE,SCRYPT_PARALLELISM,KEY_LENGTH);}staticbyte[]newSalt(){finalbyte[]salt=newbyte[SALT_LENGTH];secureRandom.nextBytes(salt);returnsalt;}}
A problem that many hashing schemes have is that even though they are very computationally expensive to compute, it may be feasible to compute a reversal of the hashing function through brute forcing all the keys up to a certain length or through a rainbow table. In order to guard against this possibility, we use a salt. Salts are extra randomly generated input that is added to a cryptographic hashing function. By adding some extra input to each password that the user wouldn’t enter, but is randomly generated, we stop someone from being able to create a reverse lookup of the hashing function. They would need to know the hashing function and the salt.
Now we’ve mentioned a few basic security concepts here around the idea of storing passwords. In reality, keeping a system secure is an ongoing effort. Not only do you need to worry about the security of data at rest, but also data in flight. When someone connects to your server from a client, it needs to transmit the user’s password over a network connection. If a malicious attacker intercepts this connection, they could take a copy of the password and use it to do the most dastardly thing possible in 140 characters!
In the case of Twootr, we receive a login message via WebSockets. This means that for our application to be secure the WebSocket connection needs to be secure against a man-in-the-middle attack. There are several ways to do this; the most common and simplest is to use Transport Layer Security (TLS), which is a cryptographic protocol that aims to provide privacy and data integrity to data sent out over its connection.
Organizations with a mature understanding of security build regular reviews and analysis into the design of their software. For example, they might periodically bring in outside consultants or an internal team to attempt to penetrate a system’s security defenses by playing the role of a attacker.
Followers and Twoots
The next requirement that we need to address is following users. You can think about designing software in one of two different ways. One of those approaches, called bottom-up, starts with designing the core of the application—data storage models or relationships between core domain objects—works its way up to building the functionality of the system. A bottom-up way of looking at following between users would be to decide how to model the relationship between users that following entails. It’s clearly a many-to-many relationship since each user can have many followers and a user can follow many other users. You would then proceed to layer on top of this data model the business functionality that is required to keep users happy.
The other approach is a top-down approach to software development. This starts with user requirements or stories and tries to develop the behavior or functionality needed to implement these stories, slowly driving down to the concerns of storage or data modeling. For example, we would start with the API for receiving an event to follow another user and then design whatever storage mechanism is needed for this behavior, slowly working from API to business logic to persistence.
It is hard to say that one approach is better in all circumstances and that the other should always be avoided; however, for the line-of-business type of applications that Java is very popular for writing our experience is that a top-down approach works best. This is because the temptation when you start with data modeling or designing the core domain of your software is that you can expend unncessary time on features that aren’t necessary for your software to work. The downside of a top-down approach is that sometimes as you build out more requirements and stories your initial design can be unsatisfactory. This means that you need to take a vigilant and iterative approach to software design, where you constantly improve it over time.
In this chapter of the book we will show you a top-down approach. This means that we start with a test to
prove out the functionality of following users, shown in Example 6-6. In this case
our UI will be sending us a event to indicate that a user wants to follow another user, so our test will call the
onFollow method of our end point with the unique ID of the user to follow as an argument. Of course, this
method doesn’t yet exist—so we need to declare it in the Twootr class in order to get the code to compile.
Modeling Errors
The test in Example 6-6 just covers the golden path of the following operation, so we need to ensure that the operation has succeeded.
Example 6-6. shouldFollowValidUser
@TestpublicvoidshouldFollowValidUser(){logon();finalFollowStatusfollowStatus=endPoint.onFollow(TestData.OTHER_USER_ID);assertEquals(SUCCESS,followStatus);}
For now we only have a success scenario, but there are other potential scenarios to think about. What if the user ID passed as an argument doesn’t correspond to an actual user? What if the user is already following the user that they’ve asked to follow? We need a way of modeling the different results or statuses that this method can return. As with everything in life, there’s a proliferation of different choices that we can make. Decisions, decisions, decisions…
One approach would be to throw an exception when the operation returns and return void when it succeeds. This could be a completely reasonable choice. It may not fall foul of our idea that exceptions should only be used for exceptional control flow, in the sense that a well-designed UI would avoid these scenarios cropping up under normal circumstances. Let’s consider some alternatives, though, that treat the status like a value, rather than using exceptions at all.
One simple approach would be using a boolean value—true to indicate success and false to indicate failure.
That’s a fair choice in situations where an operation can either succeed or fail, and it would only fail for
a single reason. The problem with the boolean approach in situations that have multiple failure scenarios is that
you don’t know why it failed.
Alternatively, we could use simple int constant values to represent each of the different failure scenarios,
but as discussed in Chapter 3 when introducing the concept of exceptions, this is an error prone, type unsafe,
and poor readability + maintainability approach. There is an alternative here for statuses that is type safe
and offers better documentation: enum types. An enum is a list of predefined constant alternatives that
constitutes a valid type. So anywhere that you can use an interface or a class you can use an enum.
But enums are better than int-based status codes in several ways. If a method returns you an int
you don’t necessarily know what values the int could contain. It’s possible to add javadoc to
describe what values it can take, and it’s possible to define constants (static final fields), but these are
really just lipstick on a pig. Enums can only contain the list of values that are defined by the enum
declaration. Enums in Java can also have instance fields and methods defined on them in order to add useful
functionality, though we won’t be using that feature in this case. You can see the declaration of our follower
status in Example 6-7.
Example 6-7. FollowStatus
publicenumFollowStatus{SUCCESS,INVALID_USER,ALREADY_FOLLOWING}
Since TDD drives us to write the simplest implementation to get a test passing, then onFollow method at this
point should simply return the SUCCESS value.
We’ve got a couple of other different scenarios to think about
for our following() operation. Example 6-8 shows the test that drives our
thinking around duplicate users. In order to implement it we need to add a set of user IDs to our User
class to represent the set of users that this user is following and ensure that the addition of another user
isn’t a duplicate. This is really easy with the Java collections API. There’s already a Set interface
that defines unique elements, and the add method will return false if the element that you’re trying to
add is already a member of the Set.
Example 6-8. shouldNotDuplicateFollowValidUser
@TestpublicvoidshouldNotDuplicateFollowValidUser(){logon();endPoint.onFollow(TestData.OTHER_USER_ID);finalFollowStatusfollowStatus=endPoint.onFollow(TestData.OTHER_USER_ID);assertEquals(ALREADY_FOLLOWING,followStatus);}
The test shouldNotFollowInValidUser() asserts that if the user isn’t valid, then the result status will indicate
that. It follows a similar format to shouldNotDuplicateFollowValidUser().
Twooting
Now we’ve laid the foundations let’s get to the exciting bit of the product—twooting! Our user story described how any user could send a twoot and that any followers who were logged in at that moment in time should immediately see the twoot. Now realistically we can’t see that users will see the twoot immediately. Perhaps they’re logged into their computer but getting a coffee, staring at another social network or, God forbid, doing some work.
By now you’re probably familiar with the overall approach. We want to write a test for a scenario where a user
who has logged on receives a twoot from another user who sends the twoot—shouldReceiveTwootsFromFollowedUser().
In addition to logging on and following, this test requires a couple of other concepts. First, we need to model
the sending of a twoot, and thus add an onSendTwoot() method to the SenderEndPoint. This has parameters
for the id of the twoot, so that we can refer back to it later, and also its content.
Second, we need a way of notifying a follower that a user has twooted—something that we can check has happened
in our test. We earlier introduced the ReceiverEndPoint as a way of publishing messages out to users, and now is
the time to start using it. We’ll add an onTwoot method resulting in Example 6-9.
Example 6-9. ReceiverEndPoint
publicinterfaceReceiverEndPoint{voidonTwoot(Twoottwoot);}
Whatever
our UI adapter is will have to send a message to the UI to tell it that a twoot has happened. But the
question is how do write a test that checks that this onTwoot method has been called?
Creating Mocks
This is where the concept of a mock object comes in handy. A mock object is a type of object that pretends to
be another object. It has the same methods and public API as the object being mocked and looks to the Java type
system as though it’s another object, but it’s not. Its purpose is to record any interactions, for example,
method calls, and be able to verify that certain method calls happen. For example, here we want to be able
to verify that the onTwoot() method of ReceiverEndPoint has been called.
Note
It might be confusing for people who have a computer science degree reading this book to hear the word “verify” being used in this way. The mathematics and formal methods communities tend to use it to mean situations where a property of a system has been proved for all inputs. Mocking uses the word totally differently. It just means checking that a method has been invoked with certain arguments. It’s sometimes frustrating when different groups of people use the same word with overloaded meanings, but often we just need to be aware of the different contexts that terminology exists within.
Mock objects can be created in a number of ways. The first mock objects tended to be written by hand;
we could in fact hand write a mock implementation of ReceiverEndPoint here, and Example 6-10
is an example of one. Whenever the onTwoot method is called we record its invocation by storing the Twoot
parameter in a List, and we can verify that it has been called with certain arguments by making an assertion that the List contains the Twoot object.
Example 6-10. MockReceiverEndPoint
publicclassMockReceiverEndPointimplementsReceiverEndPoint{privatefinalList<Twoot>receivedTwoots=newArrayList<>();@OverridepublicvoidonTwoot(finalTwoottwoot){receivedTwoots.add(twoot);}publicvoidverifyOnTwoot(finalTwoottwoot){assertThat(receivedTwoots,contains(twoot));}}
In practice, writing mocks by hand can become tedious and error prone. What do good software engineers do to tedious
and error-prone things? That’s right—they automate them. There are a number of libraries that can help us by
providing ways of creating mock objects for us. The library that we will use in this project is called Mockito,
is freely available, open source, and commonly used. Most of the operations relating to Mockito can be invoked
using static methods on the Mockito class, which we use here as static imports. In order to create the mock
object you need to use the mock method, as shown in Example 6-11.
Example 6-11. mockReceiverEndPoint
privatefinalReceiverEndPointreceiverEndPoint=mock(ReceiverEndPoint.class);
Verifying with Mocks
The mock object that has been created here can be used wherever a normal ReceiverEndPoint implementation is
used. We can pass it as a parameter to the onLogon() method, for example, to wire up the UI adapter. Once the
behavior under test—the when of the test—has happened our test needs to actually verify that the onTwoot
method was invoked (the then). In order to do this we wrap the mock object using the Mockito.verify() method.
This is a generic method that returns an object of the same type that it is passed; we simply call the method
in question with the arguments that we expect in order to describe the expected interaction with the mock
object, as shown in Example 6-12.
Example 6-12. verifyReceiverEndPoint
verify(receiverEndPoint).onTwoot(aTwootObject);
Something you may have noticed in the last section is the introduction of the Twoot class that we used
in the signature of the onTwoot method. This is a value object that will be used to wrap up the values
and represent a Twoot. Since this will be sent to the UI adapter it should just consist of fields of
simple values, rather than exposing too much from the core domain. For example, in order to represent the
sender of the twoot it contains the id of the sender rather than a reference to their User object.
The Twoot also contains a content String and the id of the Twoot object itself.
In this system Twoot objects are immutable. As mentioned previously, this style reduces the scope for bugs. This
is especially important in something like a value object that is being passed to a UI adapter. You really
just want to let your UI adapter display the Twoot, not to alter the state of another user’s Twoot.
It’s also worth noting that we continue to follow domain language here in naming the class Twoot.
Mocking Libraries
We’re using Mockito in this book because it has nice syntax and fits our preferred way of writing mocks, but it’s not the only Java mocking framework. Both Powermock and EasyMock are also popular.
Powermock can emulate Mockito syntax but it allows you to mock things that Mockito doesn’t support; for example, final classes or static methods. There is some debate around whether it’s ever a good idea to mock things like final classes—if you can’t provide a different implementation of the class in production, then should you really really be doing so in tests? In general, Powermock usage isn’t encouraged but there can occasionally be break-glass situations where it is useful.
EasyMock takes a different approach to writing mocks. This is a stylistic choice and may be preferred by some developers over others. The biggest conceptual difference is that EasyMock encourages strict mocking. Strict mocking is the idea that if you don’t explicitly state that an invocation should occur, then it’s an error to do so. This results in tests that are more specific about the behavior that a class performs, but that can sometimes become coupled to irrelevant interactions.
SenderEndPoint
Now these methods like onFollow and onSendTwoot are declared on the SenderEndPoint class. Each
SenderEndPoint instance represents the end point from which a single user sends events into the core
domain. Our design for Twoot keeps the SenderEndPoint simple—it just wraps up the main
Twootr class and delegates to the methods passing in the User object for the user that it represents
within the system. Example 6-13 shows the overall declaration of the class and an
example of one method corresponding to one event—onFollow.
Example 6-13. SenderEndPoint
publicclassSenderEndPoint{privatefinalUseruser;privatefinalTwootrtwootr;SenderEndPoint(finalUseruser,finalTwootrtwootr){Objects.requireNonNull(user,"user");Objects.requireNonNull(twootr,"twootr");this.user=user;this.twootr=twootr;}publicFollowStatusonFollow(finalStringuserIdToFollow){Objects.requireNonNull(userIdToFollow,"userIdToFollow");returntwootr.onFollow(user,userIdToFollow);}
You might have noticed the java.util.Objects class in Example 6-13. This is a utility class
that ships with the JDK itself and offers convenience methods for null reference checking and implementation
of hashCode() and equals() methods.
There are alternative designs that we could consider instead of introducing the SenderEndPoint. We could
have received events relating to a user by just exposing the methods on the Twootr object directly,
and expect to have any UI adapter call those methods directly. This is a subjective issue, like many
parts of software development. Some people would consider creating the SenderEndPoint as adding unnecessary
complexity.
The biggest motivation here is that, as mentioned earlier, we don’t want to expose
the User core domain object to a UI adapter—only talking to them in terms of simple events. It would
have been possible to take a user ID as a parameter to all the Twootr event methods, but then the first
step for every event would have been looking up the User object from the ID, whereas here we already
have it in the context of the SenderEndPoint. That design would have removed the concept of the
SenderEndPoint, but added more work and complexity in exchange.
In order to actually send the Twoot we need to evolve our core domain a little bit. The User object
needs to have a set of followers added to it, who can be notified of the Twoot when it arrives.
You can see code for our onSendTwoot method as it is implemented at this stage in the design in
Example 6-14. This finds the users the who are logged on and tells them
to receive the twoot. If you’re not familiar with the filter and forEach methods or the :: or -> syntax, don’t worry—these will be covered in “Functional Programming”.
Example 6-14. onSendTwoot
voidonSendTwoot(finalStringid,finalUseruser,finalStringcontent){finalStringuserId=user.getId();finalTwoottwoot=newTwoot(id,userId,content);user.followers().filter(User::isLoggedOn).forEach(follower->follower.receiveTwoot(twoot));}
The User object also needs to implement the receiveTwoot() method. How does a User receive a twoot? Well,
it should notify the UI for the user that there’s a twoot ready to be displayed by emitting an event, which
entails calling receiverEndPoint.onTwoot(twoot). This is the method call that we’ve verified the invocation
of using mocking code, and calling it here makes the test pass.
You can see the final iteration of our test in Example 6-15, and this is
the code that you can see if you download the example project from GitHub. You might notice it looks a bit
different than what we’ve so far described. First, as the tests for receiving twoots have been written, a
few operations have been refactored out into common methods. An example of this is logon(), which logs
our first user onto the system—part of the given section of many tests. Second, the test also creates a Position
object and passes it to the Twoot, and also verifies the interaction with a twootRepository. What the heck
is a repository? Both of these are concepts that we’ve not needed so far, but are part of the
evolution of the design of the system and will be explained in the next two sections.
Example 6-15. shouldReceiveTwootsFromFollowedUser
@TestpublicvoidshouldReceiveTwootsFromFollowedUser(){finalStringid="1";logon();endPoint.onFollow(TestData.OTHER_USER_ID);finalSenderEndPointotherEndPoint=otherLogon();otherEndPoint.onSendTwoot(id,TWOOT);verify(twootRepository).add(id,TestData.OTHER_USER_ID,TWOOT);verify(receiverEndPoint).onTwoot(newTwoot(id,TestData.OTHER_USER_ID,TWOOT,newPosition(0)));}
Positions
You will learn about Position objects very soon, but before presenting their definition we should meet
their motivation.
The next the requirement that we need to get working is that when a user logs in they should see all the
twoots from their followers since they last logged in. This entails needing to be able to perform
some kind of replay of the different twoots, and know what twoots haven’t been seen when a user logs on.
Example 6-16 shows a test of that functionality.
Example 6-16. shouldReceiveReplayOfTwootsAfterLogoff
@TestpublicvoidshouldReceiveReplayOfTwootsAfterLogoff(){finalStringid="1";userFollowsOtherUser();finalSenderEndPointotherEndPoint=otherLogon();otherEndPoint.onSendTwoot(id,TWOOT);logon();verify(receiverEndPoint).onTwoot(twootAt(id,POSITION_1));}
In order to implement this functionality, our system needs to know what twoots were sent while a user was logged off. There are lots of different ways that we could think about designing this feature. Different approaches may have different trade-offs in terms of implementation complexity, correctness, and performance/scalability. Since we’re just starting out building Twootr and not expecting many users to begin with, focusing on scalability issues isn’t our goal here:
-
We could track the time of every twoot and the time that a user logs off and search for twoots between those times.
-
We could think of twoots as a contiguous stream where each twoot has a position within the stream and record the position when a user logs off.
-
We could use positions and record the position of the last seen twoot.
When considering the different designs we would lean away from ordering messages by time. It’s the kind of decision that feels like a good idea. Let’s suppose we store the time unit in terms of milliseconds—what happens if we receive two twoots within the same time interval? We wouldn’t know the order between those twoots. What if a twoot is received on the same millisecond that a user logs off?
Recording the times at which users log off is another problematic event as well. It might be OK if a user will only ever log off by explicitly clicking a button. In practice, however, that’s only one of several ways in which they can stop using our UI. Perhaps they’ll close the web browser without explicitly logging off, or perhaps their web browser will crash. What happens if they connect from two web browsers and then log off from one of them? What happens if their mobile phone runs out of battery or closes the app?
We decided the safest approach to knowing from where to replay the twoots was to assign positions
to twoots and then store the position up to which each user has seen. In order to define positions
we introduce a small value object called Position, which is shown in Example 6-17. This class also has
a constant value for the initial position where streams will be before the stream starts. Since all of our
position values will be positive, we could use any negative integer for the initial position: -1 is chosen here.
Example 6-17. Position
publicclassPosition{/*** Position before any tweets have been seen*/publicstaticfinalPositionINITIAL_POSITION=newPosition(-1);privatefinalintvalue;publicPosition(finalintvalue){this.value=value;}publicintgetValue(){returnvalue;}@OverridepublicStringtoString(){return"Position{"+"value="+value+'}';}@Overridepublicbooleanequals(finalObjecto){if(this==o)returntrue;if(o==null||getClass()!=o.getClass())returnfalse;finalPositionposition=(Position)o;returnvalue==position.value;}@OverridepublicinthashCode(){returnvalue;}publicPositionnext(){returnnewPosition(value+1);}}
This class looks a little bit complex, doesn’t it? At this point in your programming you may ask yourself:
Why do I have these equals() and hashCode() methods defined on
it, rather than just let Java handle them for me? What is a value object? Why am I asking so many questions? Don’t
worry, we have just introduced a new topic and will answer your questions soon. It is often very convenient to introduce
small objects that represent values that are compounds of fields or give a relevant domain name to some numeric value.
Our Position class is one example; another one might be the Point class that you see in Example 6-18.
Example 6-18. Point
classPoint{privatefinalintx;privatefinalinty;Point(finalintx,finalinty){this.x=x;this.y=y;}intgetX(){returnx;}intgetY(){returny;}
A Point has an x coordinate and a y coordinate, while a Position has just a value. We’ve defined the fields on
the class and the getters for those fields.
The equals and hashcode Methods
If we want to compare two objects defined like this with the same value,
then we find that they aren’t equal when we want them to be. Example 6-19 shows an example of this; by default, the
equals() and hashCode() methods that you inherit from java.lang.Object are defined to use a concept of reference
equality. This means that if you have two different objects located in different places in your computer’s memory, then
they aren’t equal—even if all the field values are equal. This can lead to a lot of subtle bugs in your program.
Example 6-19. Point objects aren’t equal when they should be
finalPointp1=newPoint(1,2);finalPointp2=newPoint(1,2);System.out.println(p1==p2);// prints false
It’s often helpful to think in terms of two different types of objects—reference objects and value objects—based
upon what their notion of equality is. In Java we can override the equals() method in order to define our own
implementation that uses the fields deemed relevant to value equality. An example implementation is shown in
Example 6-20 for the Point class. We check that the object that we’re being given is the same
type as this object, and then check each of the fields are equal.
Example 6-20. Point equality definition
@Overridepublicbooleanequals(finalObjecto){if(this==o)returntrue;if(o==null||getClass()!=o.getClass())returnfalse;finalPointpoint=(Point)o;if(x!=point.x)returnfalse;returny==point.y;}@OverridepublicinthashCode(){intresult=x;result=31*result+y;returnresult;}finalPointp1=newPoint(1,2);finalPointp2=newPoint(1,2);System.out.println(p1.equals(p2));// prints true
The Contract Between equals and hashCode
In Example 6-20 we not only override the equals() method, but also the hashCode() method. This is due
to the Java equals/hashcode contract. This states that if we have two objects that are equal according to their
equals() method, they also have to have the same hashCode() result. A number of core Java APIs make use of the
hashCode() method—most notably collection implementations like HashMap and HashSet. They rely on this contract
holding true, and you will find that they don’t behave as you would expect if it doesn’t. So how do you correctly implement
the hashCode()?
Good hashcode implementations not only follow the contract, but they also produce hashcode values that are evenly spread
throughout the integers. This helps improve the efficiency of HashMap and HashSet implementations.
In order to achieve both of those goals, the following is a simple series of rules that if you follow will result in a
good hashCode() implementation:
-
Create a
resultvariable and assign it a prime number. -
Take each field that is used by the
equals()method and compute anintvalue to represent the hashcode of the field. -
Combine the hashcode from the field with the existing result by multiplying the previous result by a prime number; for example,
result = 41 * result + hashcodeOfField;
In order to calculate the hashcode for each field, you need to differentiate based upon the type of the field in question:
-
If the field is a primitive value, use the
hashCode()method provided on its companion class. For example, if it’s adoublethen useDouble.hashCode(). -
If it’s a nonnull object, just call its
hashCode()method or use0otherwise. This can be abbreviated with thejava.lang.Objects.hashCode()method. -
If it’s an array, you need to combine the
hashCode()values of each of its elements using the same rules as we’ve described here. Thejava.util.Arrays.hashCode()methods can be used to do this for you.
In most cases you won’t need to actually write the equals() and hashCode() methods yourself. Modern Java IDEs will
generate them for you. It’s still helpful to understand the principles and reasons behind the code they generate, though.
It’s especially important to be able to review a pair of equals() and hashCode() methods that you see in code and
know whether they are well or poorly implemented.
Note
We’ve talked in this section a little bit about value objects, but a future version of Java is scheduled to include
inline classes. These are being prototyped in Project Valhalla. The idea
behind inline classes is to provide a very efficient way to implement data structures that look like values. You will
still be able to code against them like you can a normal class, but they will generate correct hashCode() and
equals() methods, use up less memory, and for many use cases be faster to program with.
When implementing this feature we need to associate a Position with every Twoot, so we add a
field to the Twoot class. We also need to record each user’s last seen Position, so we add
a lastSeenPosition to a User. When a User receives a Twoot they update their position,
and when a User logs on they emit the twoots that the user hasn’t seen. So no new events
need to be added to either the SenderEndPoint or the ReceiverEndPoint. Replaying twoots
also requires that we store the Twoot objects somewhere—initially, we just use a JDK List.
Now our users don’t have to be logged on to the system all the time in order to enjoy Twootr,
which is awesome.
Takeaways
-
You learned about bigger-picture architectural ideas like communication styles.
-
You developed the ability to decouple domain logic from library and framework choices.
-
You drove the development of code in this chapter with tests going outside-in.
-
You applied object-oriented domain modeling skills to a larger project.
Iterating on You
If you want to extend and solidify the knowledge from this section you could try one of these activities:
-
Try the word wrap Kata.
-
Without reading the next chapter write down a list of things that need to be implemented in order for Twootr to be complete.
Completing the Challenge
We had a followup meeting with your client Joe and talked about the great progress that was made with the project. A lot of the core domain requirements have been covered and we’ve described how the system could be designed. Of course Twootr isn’t complete at this point. You’ve not heard about how you wire the application up together so that the different components can talk to each other. You’ve also not been exposed to our approach to persist the state of twoots into some kind of storage system that won’t disappear when Twootr is rebooted.
Joe is really excited by both the progress made and he’s really looking forward to seeing the finished Twootr implementation. The final chapter will complete the design of Twootr and cover the remaining topics.