Chapter 3. Extending the Bank Statements Analyzer
The Challenge
Mark Erbergzuck was very happy with the work you did in the previous chapter. You built a basic Bank Statements Analyzer as a minimum viable product. Because of this success Mark Erbergzuck thinks that your product can be taken further and asks you to build a new version that support multiple features.
The Goal
In the previous chapter, you learned how to create an application to analyze bank statements in a CSV format. Along this journey you learned about core design principles that help you write maintainable code, the Single Responsibility Principle, and anti-patterns you should avoid, such as God Class and code duplication. While you were incrementally refactoring your code you also learned about coupling (how dependent you are on other classes) and cohesion (how related things are in a class).
Nonetheless, the application is currently pretty limited. How about providing functionality for searching for different kinds of transactions, supporting multiple formats, processors, and exporting the results into a nice report with different formats such as text and HTML?
In this chapter, you will go deeper in your software development quest. First, you will learn about the Open/Closed principle, which is essential for adding flexibility to your codebase and improving code maintenance. You will also learn general guidelines for when it makes sense to introduce interfaces, as well as other gotchas to avoid high coupling. You will also learn about the use of exceptions in Java—when it makes sense to include them as part of the APIs you define and when it doesn’t. Finally, you will learn how to systematically build a Java project using an established build tool like Maven and Gradle.
Extended Bank Statements Analyzer Requirements
You had a friendly chat with Mark Erbergzuck to collect new requirements for the second iteration of the Bank Statements Analyzer. He would like to extend the functionality of the kind of operations you can perform. At the moment the application is limited, as it can only query for the revenue in a particular month or category. Mark has requested two new functionalities:
-
He’d like to also be able to search for specific transactions. For example, you should be able to return all the bank transactions in a given date range or for a specific category.
-
Mark would like to be able to generate a report of summary statistics for his search into different formats such as text and HTML.
You will work through these requirements in order.
Open/Closed Principle
Let’s start simple. You will implement a method that can find all the transactions over a certain amount. The first question is where should you declare this method? You could create a separate BankTransactionFinder class that will contain a simple findTransactions() method. However, you also declared a class BankTransactionProcessor in the previous chapter. So what should you do? In this case, there aren’t a lot of benefits in declaring a new class every time you need to add one single method. This actually adds complexity to your whole project, as it introduces a pollution of names that makes it harder to understand the relationships between these different behaviors. Declaring the method inside BankTransactionProcessor helps with discoverability as you immediately know that this is the class that groups all methods that do some form of processing. Now that you’ve decided where to declare it, you can implement it as shown in Example 3-1.
Example 3-1. Find bank transactions over a certain amount
publicList<BankTransaction>findTransactionsGreaterThanEqual(finalintamount){finalList<BankTransaction>result=newArrayList<>();for(finalBankTransactionbankTransaction:bankTransactions){if(bankTransaction.getAmount()>=amount){result.add(bankTransaction);}}returnresult;}
This code is reasonable. However, what if you want to also search in a certain month? You need to duplicate this method as shown in Example 3-2.
Example 3-2. Find bank transactions in a certain month
publicList<BankTransaction>findTransactionsInMonth(finalMonthmonth){finalList<BankTransaction>result=newArrayList<>();for(finalBankTransactionbankTransaction:bankTransactions){if(bankTransaction.getDate().getMonth()==month){result.add(bankTransaction);}}returnresult;}
In the previous chapter, you already came across code duplication. It is a code smell which leads to code that is brittle, especially if requirements change frequently. For example, if the iteration logic needs to change, you will need to repeat the modifications in several places.
This approach also doesn’t work well for more complicated requirements. What if we wish to search transactions in a specific month and also over a certain amount? You could implement this new requirement as shown in Example 3-3.
Example 3-3. Find bank transactions in a certain month and over a certain amount
publicList<BankTransaction>findTransactionsInMonthAndGreater(finalMonthmonth,finalintamount){finalList<BankTransaction>result=newArrayList<>();for(finalBankTransactionbankTransaction:bankTransactions){if(bankTransaction.getDate().getMonth()==month&&bankTransaction.getAmount()>=amount){result.add(bankTransaction);}}returnresult;}
Clearly this approach exhibits several downsides:
-
Your code will become increasingly complicated as you have to combine multiple properties of a bank transaction.
-
The selection logic is coupled to the iteration logic, making it harder to separate them out.
-
You keep on duplicating code.
This is where the Open/Closed principle comes in. It promotes the idea of being able to change the behavior of a method or class without having to modify the code. In our example, it would mean the ability to extend the behavior of a findTransactions() method without having to duplicate the code or change it to introduce a new parameter. How is this possible? As discussed earlier, the concepts of iterating and the business logic are coupled together. In the previous chapter, you learned about interfaces as a useful tool to decouple concepts from one another. In this case, you will introduce a BankTransactionFilter interface that will be responsible for the selection logic, as shown in Example 3-4. It contains a single method test() that returns a boolean and takes the complete BankTransaction object as an argument. This way the method test() has access to all the properties of a BankTransaction to specify any appropriate selection criteria.
Note
An interface that only contains a single abstract method is called a functional interface since Java 8. You can annotate it using the @FunctionalInterface annotation to make the intent of the interface clearer.
Example 3-4. The BankTransactionFilter interface
@FunctionalInterfacepublicinterfaceBankTransactionFilter{booleantest(BankTransactionbankTransaction);}
Note
Java 8 introduced a generic java.util.function.Predicate<T> inferface, which would be a great fit for the problem at hand. However, this chapter introduces a new named interface to avoid introducing too much complexity early on in the book.
The interface BankTransactionFilter models the concept of a selection criteria for a BankTransaction. You can now refactor the method findTransactions() to make use of it as shown in Example 3-5. This refactoring is very important because you now have introduced a way to decouple the iteration logic from the business logic through this interface. Your method no longer depends on one specific implementation of a filter. You can introduce new implementations by passing them as an argument without modifying the body of this method. Hence, it is now open for extension and closed for modification. This reduces the scope for introducing new bugs because it minimizes cascading changes required to parts of code that have already been implemented and tested. In other words, old code still works and is untouched.
Example 3-5. Flexible findTransactions() method using Open/Closed Principle
publicList<BankTransaction>findTransactions(finalBankTransactionFilterbankTransactionFilter){finalList<BankTransaction>result=newArrayList<>();for(finalBankTransactionbankTransaction:bankTransactions){if(bankTransactionFilter.test(bankTransaction)){result.add(bankTransaction);}}returnresult;}
Creating an Instance of a Functional Interface
Mark Erbergzuck is now happy as you can implement any new requirements by calling the method findTransactions() declared in the BankTransactionProcessor with appropriate implementations of a BankTransactionFilter. You can achieve this by implementing a class as shown in Example 3-6 and then passing an instance as argument to the findTransactions() method as shown in Example 3-7.
Example 3-6. Declaring a class that implements the BankTransactionFilter
classBankTransactionIsInFebruaryAndExpensiveimplementsBankTransactionFilter{@Overridepublicbooleantest(finalBankTransactionbankTransaction){returnbankTransaction.getDate().getMonth()==Month.FEBRUARY&&bankTransaction.getAmount()>=1_000);}}
Example 3-7. Calling findTransactions() with a specific implementation of BankTransactionFilter
finalList<BankTransaction>transactions=bankStatementProcessor.findTransactions(newBankTransactionIsInFebruaryAndExpensive());
Lambda Expressions
However, you’d need to create special classes every time you have a new requirement. This process can add unnecessary boilerplate and can rapidly become cumbersome. Since Java 8, you can use a feature called lambda expressions as shown in Example 3-8. Don’t worry about this syntax and language feature for the time being. We will learn about lambda expressions and a companion language feature called method references in more detail in Chapter 7. For now, you can think of it as instead of passing in an object that implements an interface, we’re passing in a block of code—a function without a name. bankTransaction is the name of a parameter and the arrow -> separates the parameter from the body of the lambda expression, which is just some code that is run to test whether or not the bank transaction should be selected.
Example 3-8. Implementing BankTransactionFilter using a lambda expression
finalList<BankTransaction>transactions=bankStatementProcessor.findTransactions(bankTransaction->bankTransaction.getDate().getMonth()==Month.FEBRUARY&&bankTransaction.getAmount()>=1_000);
To summarize, the Open/Closed Principle is a useful principle to follow because it:
Interfaces Gotchas
So far you introduced a flexible method to search for transactions given a selection criterion. The refactoring you went through raises questions about what should happen to the other methods declared inside the BankTransactionProcessor class. Should they be part of an interface? Should they be included in a separate class? After all, there are three other related methods you implemented in the previous chapter:
-
calculateTotalAmount() -
calculateTotalInMonth() -
calculateTotalForCategory()
One approach that we discourage you to put in practice is to put everything into one single interface: the God Interface.
God Interface
One extreme view you could take is that the class BankTransactionProcessor acts as an API. As a result, you may wish to define an interface that lets you decouple from multiple implementations of a bank transaction processor as shown in Example 3-9. This interface contains all the operations that the bank transaction processor needs to implement.
Example 3-9. God Interface
interfaceBankTransactionProcessor{doublecalculateTotalAmount();doublecalculateTotalInMonth(Monthmonth);doublecalculateTotalInJanuary();doublecalculateAverageAmount();doublecalculateAverageAmountForCategory(Categorycategory);List<BankTransaction>findTransactions(BankTransactionFilterbankTransactionFilter);}
However, this approach displays several downsides. First, this interface becomes increasingly complex as every single helper operation is an integral part of the explicit API definition. Second, this interface acts more like a “God Class” as you saw in the previous chapter. In fact, the interface has now become a bag for all possible operations. Worse, you are actually introducing two forms of additional coupling:
-
An interface in Java defines a contract that every single implementation has to adhere by. In other words, concrete implementations of this interface have to provide an implementation for each operation. This means that changing the interface means all concrete implementations have to be updated as well to support the change. The more operations you add, the more likely changes will happen, increasing the scope for potential problems down the line.
-
Concrete properties of a
BankTransactionsuch as the month and the category have cropped up as part of method names; e.g.,calculateAverageForCategory()andcalculateTotalInJanuary(). This is more problematic with interfaces as they now depend on specific accessors of a domain object. If the internals of that domain object change, then this may cause changes to the interface as well and, as a consequence, to all its concrete implementations, too.
All these reasons are why it is generally recommended to define smaller interfaces. The idea is to minimize dependency to multiple operations or internals of a domain object.
Too Granular
Since we’ve just argued that smaller is better, the other extreme view you could take is to define one interface for each operation, as shown in Example 3-10. Your BankTransactionProcessor class would implement all these interfaces.
Example 3-10. Interfaces that are too granular
interfaceCalculateTotalAmount{doublecalculateTotalAmount();}interfaceCalculateAverage{doublecalculateAverage();}interfaceCalculateTotalInMonth{doublecalculateTotalInMonth(Monthmonth);}
This approach is also not useful for improving code maintenance. In fact, it introduces “anti-cohesion.” In other words, it becomes harder to discover the operations of interest as they are hiding in multiple separate interfaces. Part of promoting good maintenance is to help discoverability of common operations. In addition, because the interfaces are too granular it adds overall complexity, as well as a lot of different new types introduced by the new interfaces to keep track of in your project.
Explicit Versus Implicit API
So what is the pragmatic approach to take? We recommend following the Open/Closed Principle to add flexibility to your operations and define the most common cases as part of the class. They can be implemented with the more general methods. In this scenario, an interface is not particularly warranted as we don’t expect different implementations of a BankTransactionProcessor. There aren’t specializations of each of these methods that will benefit your overall application. As a result, there’s no need to over-engineer and add unnecessary abstractions in your codebase. The BankTransactionProcessor is simply a class that lets you perform statistical operations on bank transactions.
This also raises the question of whether methods such as findTransactionsGreaterThanEqual() should be declared given that they can easily be implemented by the more general findTransactions() method. This dilemma is often referred to as the problem of providing an explicit versus implicit API.
In fact, there are two sides of the coin to consider. On one side a method like findTransactionsGreaterThanEqual() is self-explanatory and easy to use. You should not be worried about adding descriptive method names to help readability and comprehension of your API. However, this method is restricted to a particular case and you can easily have an explosion of new methods to cater for various multiple requirements. On the other side, a method like findTransactions() is initially more difficult to use and it needs to be well-documented. However, it provides a unified API for all cases where you need to look up transactions. There isn’t a rule of what is best; it depends on what kind of queries you expect. If findTransactionsGreaterThanEqual() is a very common operation, it makes sense to extract it into an explicit API to make it easier for users to understand and use.
The final implementation of the BankTransactionProcessor is shown in Example 3-11.
Example 3-11. Key operations for the BankTransactionProcessor class
@FunctionalInterfacepublicinterfaceBankTransactionSummarizer{doublesummarize(doubleaccumulator,BankTransactionbankTransaction);}@FunctionalInterfacepublicinterfaceBankTransactionFilter{booleantest(BankTransactionbankTransaction);}publicclassBankTransactionProcessor{privatefinalList<BankTransaction>bankTransactions;publicBankStatementProcessor(finalList<BankTransaction>bankTransactions){this.bankTransactions=bankTransactions;}publicdoublesummarizeTransactions(finalBankTransactionSummarizerbankTransactionSummarizer){doubleresult=0;for(finalBankTransactionbankTransaction:bankTransactions){result=bankTransactionSummarizer.summarize(result,bankTransaction);}returnresult;}publicdoublecalculateTotalInMonth(finalMonthmonth){returnsummarizeTransactions((acc,bankTransaction)->bankTransaction.getDate().getMonth()==month?acc+bankTransaction.getAmount():acc);}// ...publicList<BankTransaction>findTransactions(finalBankTransactionFilterbankTransactionFilter){finalList<BankTransaction>result=newArrayList<>();for(finalBankTransactionbankTransaction:bankTransactions){if(bankTransactionFilter.test(bankTransaction)){result.add(bankTransaction);}}returnbankTransactions;}publicList<BankTransaction>findTransactionsGreaterThanEqual(finalintamount){returnfindTransactions(bankTransaction->bankTransaction.getAmount()>=amount);}// ...}
Note
A lot of the aggregation patterns that you have seen so far could be implemented using the Streams API introduced in Java 8 if you are familiar with it. For example, searching for transactions can be easily specified as shown here:
bankTransactions.stream().filter(bankTransaction->bankTransaction.getAmount()>=1_000).collect(toList());
Nonetheless, the Streams API is implemented using the same foundation and principles that you’ve learned in this section.
Domain Class or Primitive Value?
While we kept the interface definition of BankTransactionSummarizer simple, it is often preferable to not return a primitive value like a double if you are looking at returning a result from an aggregation. This is because it doesn’t give you the flexibility to later return multiple results. For example, the method summarizeTransaction() returns a double. If you were to change the signature of the result to include more results, you would need to change every single implementation of the BankTransactionProcessor.
A solution to this problem is to introduce a new domain class such as Summary that wraps the double value. This means that in the future you can add other fields and results to this class. This technique helps further decouple the various concepts in your domain and also helps minimize cascading changes when requirements change.
Multiple Exporters
In the previous section you learned about the Open/Closed Principle and delved further into the usage of interfaces in Java. This knowledge is going to come handy as Mark Erbergzuck has a new requirement! You need to export summary statistics about a selected list of transactions into different formats including text, HTML, JSON, and so on. Where to start?
Introducing a Domain Object
First, you need to define exactly what is it the user wants to export. There are various possibilities, which we explore together with their trade-offs:
- A number
-
Perhaps the user is just interested in returning the result of an operation like
calculateAverageInMonth. This means the result would be adouble. While this is the most simple approach, as we noted earlier, this approach is somewhat inflexible as it doesn’t cope well with changing requirements. Imagine you create an exporter which takes thedoubleas an input, this means that every places in your code that calls this exporter will need to be updated if you need to change the result type, possibly introducing new bugs. - A collection
-
Perhaps the user wishes to return a list of transactions, for example, returned by
findTransaction(). You could even return anIterableto provide further flexibility in what specific implementation is returned. While this gives you more flexibility it also ties you to only being able to return a collection. What if you need to return multiple results such as a list and other summary information? - A specialized domain object
-
You could introduce a new concept such as
SummaryStatisticswhich represents summary information that the user is interested in exporting. A domain object is simply an instance of a class that is related to your domain. By introducing a domain object, you introduce a form of decoupling. In fact, if there are new requirements where you need to export additional information, you can just include it as part of this new class without having to introduce cascading changes. - A more complex domain object
-
You could introduce a concept such as
Reportwhich is more generic and could contain different kinds of fields storing various results including collection of transactions. Whether you need this or not depends on the user requirements and whether you are expecting more complex information. The benefit again is that you are able to decouple different parts of your applications that produceReportobjects and other parts that consumeReportobjects.
For the purpose of our application, let’s introduce a domain object that stores summary statistics about a list of transactions. The code in Example 3-12 shows its declaration.
Example 3-12. A domain object storing statistical information
publicclassSummaryStatistics{privatefinaldoublesum;privatefinaldoublemax;privatefinaldoublemin;privatefinaldoubleaverage;publicSummaryStatistics(finaldoublesum,finaldoublemax,finaldoublemin,finaldoubleaverage){this.sum=sum;this.max=max;this.min=min;this.average=average;}publicdoublegetSum(){returnsum;}publicdoublegetMax(){returnmax;}publicdoublegetMin(){returnmin;}publicdoublegetAverage(){returnaverage;}}
Defining and Implementing the Appropriate Interface
Now that you know what you need to export, you will come up with an API to do it. You will need to define an interface called Exporter. The reason you introduce an interface is to let you decouple from multiple implementations of exporters. This goes in line with the Open/Closed Principle you learned in the previous section. In fact, if you need to substitute the implementation of an exporter to JSON with an exporter to XML this will be straightforward given they will both implement the same interface. Your first attempt at defining the interface may be as shown in Example 3-13. The method export() takes a SummaryStatistics object and returns void.
Example 3-13. Bad Exporter interface
publicinterfaceExporter{voidexport(SummaryStatisticssummaryStatistics);}
This approach is to be avoided for several reasons:
-
The return type
voidis not useful and is difficult to reason about. You don’t know what is returned. The signature of theexport()method implies that some state change is happening somewhere or that this method will log or print information back to the screen. We don’t know! -
Returning
voidmakes it very hard to test the result with assertions. What is the actual result to compare with the expected result? Unfortunately, you can’t get a result withvoid.
With this in mind, you come up with an alternative API that returns a String, as shown in Example 3-14. It is now clear that the Exporter will return text and it’s then up to a separate part of the program to decide whether to print it, save it to a file, or even send it electronically. Text strings are also very useful for testing as you can directly compare them with assertions.
Example 3-14. Good Exporter interface
publicinterfaceExporter{Stringexport(SummaryStatisticssummaryStatistics);}
Now that you have defined an API to export information, you can implement various kinds of exporters that respect the contract of the Exporter interface. You can see an example of implementing a basic HTML exporter in Example 3-15.
Example 3-15. Implementing the Exporter interface
publicclassHtmlExporterimplementsExporter{@OverridepublicStringexport(finalSummaryStatisticssummaryStatistics){Stringresult="<!doctype html>";result+="<html lang='en'>";result+="<head><title>Bank Transaction Report</title></head>";result+="<body>";result+="<ul>";result+="<li><strong>The sum is</strong>: "+summaryStatistics.getSum()+"</li>";result+="<li><strong>The average is</strong>: "+summaryStatistics.getAverage()+"</li>";result+="<li><strong>The max is</strong>: "+summaryStatistics.getMax()+"</li>";result+="<li><strong>The min is</strong>: "+summaryStatistics.getMin()+"</li>";result+="</ul>";result+="</body>";result+="</html>";returnresult;}}
Exception Handling
So far we’ve not talked about what happens when things go wrong. Can you think of situations where the bank analyzer software might fail? For example:
-
What if the data cannot be parsed properly?
-
What if the CSV file containing the bank transctions to import can’t be read?
-
What if the hardware running your applications runs out of resources such as RAM or disk space?
In these scenarios you will be welcomed with a scary error message that includes a stack trace showing the origin of the problem. The snippets in Example 3-16 show examples of these unexpected errors.
Example 3-16. Unexpected problems
Exceptioninthread"main"java.lang.ArrayIndexOutOfBoundsException:0Exceptioninthread"main"java.nio.file.NoSuchFileException:src/main/resources/bank-data-simple.csvExceptioninthread"main"java.lang.OutOfMemoryError:Javaheapspace
Why Use Exceptions?
Let’s focus on the BankStatementCSVParser for the moment. How do we handle parsing problems? For example, a CSV line in the file might not be written in the expected format:
-
A CSV line may have more than the expected three columns.
-
A CSV line may have fewer than the expected three columns.
-
The data format of some of the columns may not be correct, e.g., the date may be incorrect.
Back in the frightening days of the C programming language, you would add a lot of if-condition checks that would return a cryptic error code. This approach had several drawbacks. First, it relied on global shared mutable state to look up the most recent error. This made it harder to understand individual parts of your code in isolation. As a result, your code became harder to maintain. Second, this approach was error prone as you needed to distinguish between real values and errors encoded as values. The type system in this case was weak and could be more helpful to the programmer. Finally, the control flow was mixed with the business logic, which contributed to making the code harder to maintain and test in isolation.
To solve these issues, Java incorporated exceptions as a first-class language feature that introduced many benefits:
- Documentation
-
The language supports exceptions as part of method signatures.
- Type safety
-
The type system figures out whether you are handling the exceptional flow.
- Separation of concern
-
Business logic and exception recovery are separated out with a try/catch block.
The problem is that exceptions as a language feature also add more complexity. You may be familiar with the fact that Java distinguishes between two kinds of exceptions:
- Checked exceptions
-
These are errors that you are expected to be able to recover from. In Java, you have to declare a method with a list of checked exceptions it can throw. If not, you have to provide a suitable try/catch block for that particular exception.
- Unchecked exceptions
-
These are errors that can be thrown at any time during the program execution. Methods don’t have to explicitly declare these exceptions in their signature and the caller doesn’t have to handle them explicitly, as it would with a checked exception.
Java exception classes are organized in a well-defined hierarchy. Figure 3-1 depicts that hierarchy in Java. The Error and RuntimeException classes are unchecked exceptions and are subclasses of Throwable. You shouldn’t expect to catch and recover from them. The class Exception typically represents errors that a program should be able to recover from.
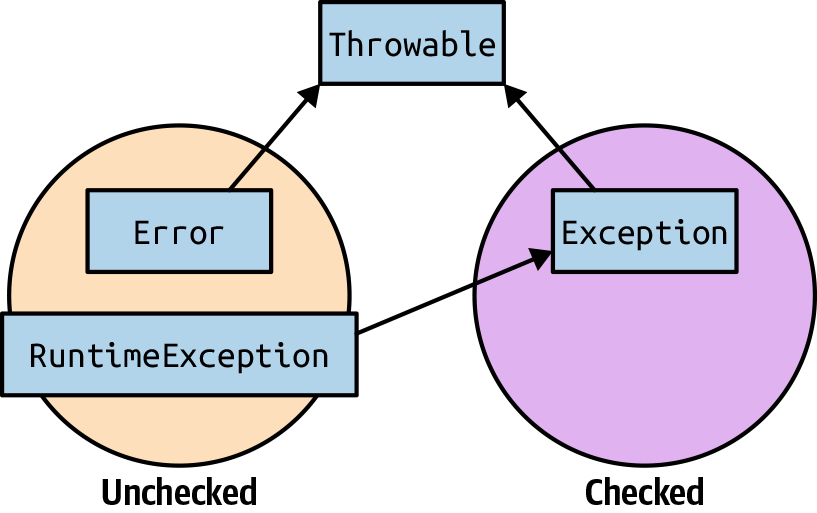
Figure 3-1. Exceptions hierarchy in Java
Patterns and Anti-Patterns with Exceptions
Which category of exceptions should you use under what scenario? You may also wonder how should you update the BankStatementParser API to support exceptions. Unfortunately, there isn’t a simple answer. It requires a bit of pragmatism when deciding what is the right approach for you.
There are two separate concerns when thinking about parsing the CSV file:
-
Parsing the right syntax (e.g., CSV, JSON)
-
Validation of the data (e.g., text description should be less than 100 characters)
You will focus on the syntax error first and then the validation of the data.
Deciding between unchecked and checked
There are situations when the CSV file may not follow the correct syntax (for example, if separating commas are missing). Ignoring this problem will lead to confusing errors when the application runs. Part of the benefit of supporting exceptions in your code is to provide a clearer diagnosis to the user of your API in the event that a problem arises. Accordingly, you decide to add a simple check as shown in the code in Example 3-17, which throws a CSVSyntaxException.
Example 3-17. Throwing a syntax exception
finalString[]columns=line.split(",");if(columns.length<EXPECTED_ATTRIBUTES_LENGTH){thrownewCSVSyntaxException();}
Should CSVSyntaxException be a checked or an unchecked exception? To answer this question you need to ask yourself whether you require the user of your API to take a compulsory recovery action. For example, the user may implement a retry mechanism if it is a transient error or she may display a message back on the screen to add graceful responsiveness to the application. Typically, errors due to business logic validation (e.g., wrong format or arithmetic) should be unchecked exceptions, as they would add a lot of try/catch clutter in your code. It may also not be obvious what the right recovery mechanism is. Consequently, there’s no point enforcing it on the user of your API. In addition, system errors (e.g., disk ran out of space) should also be unchecked exceptions as there’s nothing the client can do. In a nutshell, the recommendation is to use unchecked exceptions and only use checked exceptions sparingly to avoid significant clutter in the code.
Let’s now tackle the problem of validating the data once you know it follows the correct CSV format. You will learn about two common anti-patterns with using exceptions for validation. Then, you will learn about the Notification pattern, which provides a maintainable solution to the problem.
Overly specific
The first question going through your mind is where should you add validation logic? You could have it right at the construction time of the BankStatement object. However, we recommend creating a dedicated Validator class for several reasons:
-
You don’t have to duplicate the validation logic when you need to reuse it.
-
You get confidence that different parts of your system validate the same way.
-
You can easily unit test this logic separately.
-
It follows the SRP, which leads to simpler maintenance and program comprehension.
The are various approaches to implementing your validator using exceptions. One overly specific approach is shown in Example 3-18. You have thought of every single edge case to validate the input and converted each edge case into a checked exception. The exceptions DescriptionTooLongException, InvalidDateFormat, DateInTheFutureException, and InvalidAmountException are all user-defined checked exceptions (i.e., they extend the class Exception). While this approach lets you specify precise recovery mechanisms for each exception, it is clearly unproductive as it requires a lot of setup, declares multiple exceptions, and forces the user to explicitly deal with each of these exceptions. This is doing the opposite of helping the user understand and simply use your API. In addition, you can’t collect all the errors as a whole in case you want to provide a list to the user.
Example 3-18. Overly specific exceptions
publicclassOverlySpecificBankStatementValidator{privateStringdescription;privateStringdate;privateStringamount;publicOverlySpecificBankStatementValidator(finalStringdescription,finalStringdate,finalStringamount){this.description=Objects.requireNonNull(description);this.date=Objects.requireNonNull(description);this.amount=Objects.requireNonNull(description);}publicbooleanvalidate()throwsDescriptionTooLongException,InvalidDateFormat,DateInTheFutureException,InvalidAmountException{if(this.description.length()>100){thrownewDescriptionTooLongException();}finalLocalDateparsedDate;try{parsedDate=LocalDate.parse(this.date);}catch(DateTimeParseExceptione){thrownewInvalidDateFormat();}if(parsedDate.isAfter(LocalDate.now()))thrownewDateInTheFutureException();try{Double.parseDouble(this.amount);}catch(NumberFormatExceptione){thrownewInvalidAmountException();}returntrue;}}
Overly apathetic
The other end of the spectrum is making everything an unchecked exception; for example, by using IllegalArgumentException. The code in Example 3-19 shows the implementation of the validate() method following this approach. The problem with this approach is that you can’t have specific recovery logic because all the exceptions are the same! In addition, you still can’t collect all the errors as a whole.
Example 3-19. IllegalArgument exceptions everywhere
publicbooleanvalidate(){if(this.description.length()>100){thrownewIllegalArgumentException("The description is too long");}finalLocalDateparsedDate;try{parsedDate=LocalDate.parse(this.date);}catch(DateTimeParseExceptione){thrownewIllegalArgumentException("Invalid format for date",e);}if(parsedDate.isAfter(LocalDate.now()))thrownewIllegalArgumentException("date cannot be in the future");try{Double.parseDouble(this.amount);}catch(NumberFormatExceptione){thrownewIllegalArgumentException("Invalid format for amount",e);}returntrue;}
Next, you will learn about the Notification pattern, which provides a solution to the downsides highlighted with the overly specific and overly apathetic anti-patterns.
Notification Pattern
The Notification pattern aims to provide a solution for the situation in which you are using too many unchecked exceptions. The solution is to introduce a domain class to collect errors.1
The first thing you need is a Notification class whose responsibility is to collect errors. The code in Example 3-20 shows its declaration.
Example 3-20. Introducing the domain class Notification to collect errors
publicclassNotification{privatefinalList<String>errors=newArrayList<>();publicvoidaddError(finalStringmessage){errors.add(message);}publicbooleanhasErrors(){return!errors.isEmpty();}publicStringerrorMessage(){returnerrors.toString();}publicList<String>getErrors(){returnthis.errors;}}
The benefit of introducing such a class is that you can now declare a validator that is able to collect multiple errors in one pass. This wasn’t possible in the two previous approaches you explored. Instead of throwing exceptions, you can now simply add messages into the Notification object as shown in Example 3-21.
Example 3-21. Notification pattern
publicNotificationvalidate(){finalNotificationnotification=newNotification();if(this.description.length()>100){notification.addError("The description is too long");}finalLocalDateparsedDate;try{parsedDate=LocalDate.parse(this.date);if(parsedDate.isAfter(LocalDate.now())){notification.addError("date cannot be in the future");}}catch(DateTimeParseExceptione){notification.addError("Invalid format for date");}finaldoubleamount;try{amount=Double.parseDouble(this.amount);}catch(NumberFormatExceptione){notification.addError("Invalid format for amount");}returnnotification;}
Guidelines for Using Exceptions
Now that you’ve learned the situations for which you may use exceptions, let’s discuss some general guidelines to use them effectively in your application.
Do not ignore an exception
It’s never a good idea to ignore an exception as you won’t be able to diagnose the root of the problem. If there isn’t an obvious handling mechanism, then throw an unchecked exception instead. This way if you really need to handle the checked exception, you’ll be forced to come back and deal with it after seeing the problem at runtime.
Do not catch the generic Exception
Catch a specific exception as much as you can to improve readability and support more specific exception handling. If you catch the generic Exception, it also includes a RuntimeException. Some IDEs can generate a catch clause that is too general, so you may need to think about making the catch clause more specific.
Document exceptions
Document exceptions at your API-level including unchecked exceptions to facilitate troubleshooting. In fact, unchecked exceptions report the root of an issue that should be addressed. The code in Example 3-22 shows an example of documenting exceptions using the @throws Javadoc syntax.
Example 3-22. Documenting exceptions
@throwsNoSuchFileExceptionifthefiledoesnotexist@throwsDirectoryNotEmptyExceptionifthefileisadirectoryandcouldnototherwisebedeletedbecausethedirectoryisnotempty@throwsIOExceptionifanI/Oerroroccurs@throwsSecurityExceptionInthecaseofthedefaultprovider,andasecuritymanagerisinstalled,the{@linkSecurityManager#checkDelete(String)}methodisinvokedtocheckdeleteaccesstothefile
Watch out for implementation-specific exceptions
Do not throw implementation-specific exceptions as it breaks encapsulation of your API. For example, the definition of read() in Example 3-23 forces any future implementations to throw an OracleException, when clearly read() could support sources that are completely unrelated to Oracle!
Example 3-23. Avoid implementation-specific exceptions
publicStringread(finalSourcesource)throwsOracleException{...}
Exceptions versus Control flow
Do not use exceptions for control flow. The code in Example 3-24 exemplifies a bad use of exceptions in Java. The code relies on an exception to exit the reading loop.
Example 3-24. Using exceptions for control flow
try{while(true){System.out.println(source.read());}}catch(NoDataExceptione){}
You should avoid this type of code for several reasons. First, it leads to poor code readability because the exception try/catch syntax adds unnecessary clutter. Second, it makes the intent of your code less comprehensible. Exceptions are meant as a feature to deal with errors and exceptional scenarios. Consequently, it’s good not to create an exception until you are sure that you need to throw it. Finally, there’s overhead associated with holding a stack trace in the event that an exception is thrown.
Alternatives to Exceptions
You’ve learned about using exceptions in Java for the purpose of making your Bank Statements Analyzer more robust and comprehensible for your users. What are alternatives to exceptions, though? We briefly describe four alternative approaches together with their pros and cons.
Using null
Instead of throwing a specific exception, you may ask why you can’t just return null as shown in Example 3-25.
Example 3-25. Returning null instead of an exception
finalString[]columns=line.split(",");if(columns.length<EXPECTED_ATTRIBUTES_LENGTH){returnnull;}
This approach is to be absolutely avoided. In fact, null provides no useful information to the caller. It is also error prone as you have to explicitly remember to check for null as a result of your API. In practice, this leads to many NullPointerExceptions and a lot of unnecessary debugging!
The Null Object pattern
An approach you sometimes see adopted in Java is the Null Object pattern. In a nutshell, instead of returning a null reference to convey the absence of an object, you return an object that implements the expected interface but whose method bodies are empty. The advantage of this tactic is that you won’t deal with unexpected NullPointer exceptions and a long list of null checks. In fact, this empty object is very predictable because it does nothing functionally! Nonetheless, this pattern can also be problematic because you may hide potential issues in the data with an object that simply ignores the real problem, and as a result make troubleshooting more difficult.
Optional<T>
Java 8 introduced a built-in data type java.util.Optional<T>, which is dedicated to representing the presence or absence of a value. The Optional<T> comes with a set of methods to explicitly deal with the absence of a value, which is useful to reduce the scope for bugs. It also allows you to compose various Optional objects together, which may be returned as a return type from different APIs you use. An example of that is the method findAny() in the Streams API. You will learn more about how you can use Optional<T> in Chapter 7.
Try<T>
There’s another data type called Try<T>, which represents an operation that may succeed or fail. In a way it is analogous to Optional<T>, but instead of values you work with operations. In other words, the Try<T> data type brings similar code composability benefits and also helps reduce the scope for errors in your code. Unfortunately, the Try<T> data type is not built in to the JDK but is supported by external libraries that you can look at.
Using a Build Tool
So far you’ve learned good programming practices and principles. But what about structuring, building, and running your application? This section focuses on why using a build tool for your project is a necessity and how you can use a build tool such as Maven and Gradle to build and run your application in a predictable manner. In Chapter 5, you will learn more about a related topic of how to structure the application effectively using Java packages.
Why Use a Build Tool?
Let’s consider the problem of executing your application. There are several elements you need to take care of. First, once you have written the code for your project, you will need to compile it. To do this, you will have to use the Java compiler (javac). Do you remember all the commands required to compile multiple files? What about with multiple packages? What about managing dependencies if you were to import other Java libraries? What about if the project needs to be packaged in a specific format such as WAR or JAR? Suddenly things get messy, and more and more pressure is put on the developer.
To automate all the commands required, you will need to create a script so you don’t have to repeat the commands every time. Introducing a new script means that all your current and future teammates will need to be familiar with your way of thinking to be able to maintain and change the script as requirements evolve. Second, the software development life cycle needs to be taken into consideration. It’s not just about developing and compiling the code. What about testing and deploying it?
The solution to these problems is using a build tool. You can think of a build tool as an assistant that can automate the repetitive tasks in the software development life cycle, including building, testing, and deploying your application. A build tool has many benefits:
-
It provides you with a common structure to think about a project so your colleagues feel immediately at home with the project.
-
It sets you up with a repeatable and standardized process to build and run an application.
-
You spend more time on development, and less time on low-level configurations and setup.
-
You are reducing the scope for introducing errors due to bad configurations or missing steps in the build.
-
You save time by reusing common build tasks instead of reimplementing them.
You will now explore two popular build tools used in the Java community: Maven and Gradle.2
Using Maven
Maven is highly popular in the Java community. It allows you to describe the build process for your software together with its dependencies. In addition, there’s a large community maintaining repositories that Maven can use to automatically download the libraries and dependencies used by your application. Maven was initially released in 2004 and as you might expect, XML was very popular back then! Consequently, the declaration of the build process in Maven is XML based.
Project structure
The great thing about Maven is that from the get-go it comes with structure to help maintenance. A Maven project starts with two main folders:
/src/main/java-
This is where you will develop and find all the Java classes required for your project.
src/test/java-
This where you will develop and find all the tests for your project.
There are two additional folders that are useful but not required:
src/main/resources-
This is where you can include extra resources such as text files needed by your application.
src/test/resources-
This is where you can include extra resources used by your tests.
Having this common directory layout allows anyone familiar with Maven to be immediately able to locate important files. To specify the build process you will need to create a pom.xml file where you specify various XML declarations to document the steps required to build your application. Figure 3-2 summarizes the common Maven project layout.
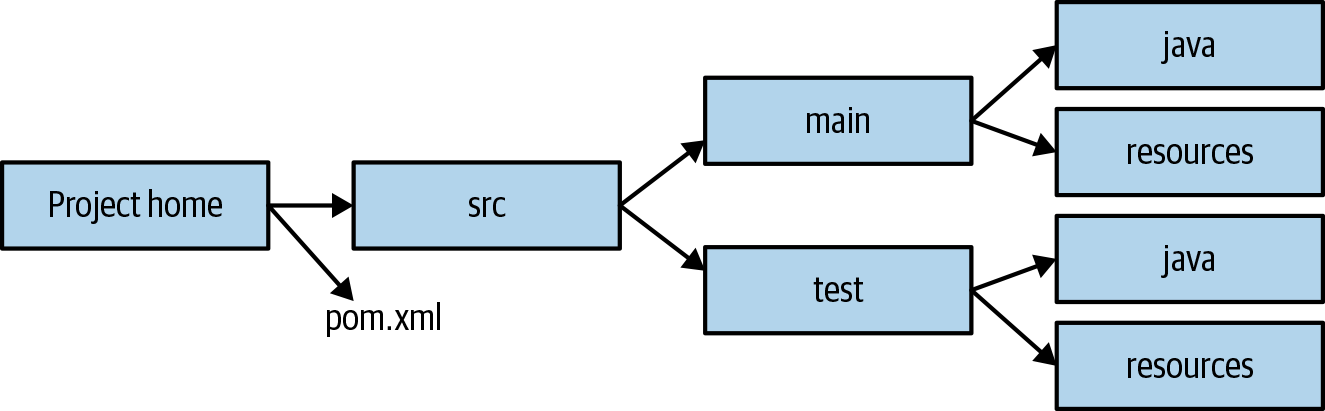
Figure 3-2. Maven standard directory layout
Example build file
The next step is to create the pom.xml that will dictate the build process. The code snippet in Example 3-26 shows a basic example that you can use for building the Bank Statements Analyzer project. You will see several elements in this file:
project-
This is the top-level element in all pom.xml files.
groupId-
This element indicates the unique identifier of the organization that created the project.
artifactId-
This element specifies a unique base name for the artifact generated by the build process.
packaging-
This element indicates the package type to be used by this artifact (e.g., JAR, WAR, EAR, etc.). The default is JAR if the XML element
packagingis omitted. version-
The version of the artifact generated by the project.
build-
This element specifies various configurations to guide the build process such as plug-ins and resources.
dependencies-
This element specifies a dependency list for the project.
Example 3-26. Build file pom.xml in Maven
<?xml version="1.0" encoding="UTF-8"?><projectxmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.iteratrlearning</groupId><artifactId>bankstatement_analyzer</artifactId><version>1.0-SNAPSHOT</version><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.7.0</version><configuration><source>9</source><target>9</target></configuration></plugin></plugins></build><dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version><scope>test</scope></dependency></dependenciesn></project>
Maven commands
Once you’ve set up a pom.xml, the next step is to use Maven to build and package your project! There are various commands available. We only cover the fundamentals:
mvn clean-
Cleans up any previously generated artifacts from a prior build
mvn compile-
Compiles the source code of the project (by default in a generated target folder)
mvn test-
Tests the compiled source code
mvn package-
Packages the compiled code in a suitable format such as JAR
For example, running the command mvn package from the directory where the pom.xml file is located will produce an output similar to this:
[INFO] Scanning for projects... [INFO] [INFO] ------------------------------------------------------------------------ [INFO] Building bankstatement_analyzer 1.0-SNAPSHOT [INFO] ------------------------------------------------------------------------ [INFO] [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 1.063 s [INFO] Finished at: 2018-06-10T12:14:48+01:00 [INFO] Final Memory: 10M/47M
You will see the generated JAR bankstatement_analyzer-1.0-SNAPSHOT.jar in the target folder.
Note
If you want to run a main class in the generated artifact using the mvn command, you will need to take a look at the exec plug-in.
Using Gradle
Maven is not the only build tool solution available in the Java space. Gradle is an alternative popular build tool to Maven. But you may wonder why use yet another build tool? Isn’t Maven the most widely adopted? One of Maven’s deficiencies is that the use of XML can make things less readable and more cumbersome to work with. For example, it is often necessary as part of the build process to provide various custom system commands, such as copying and moving files around. Specifying such commands using an XML syntax isn’t natural. In addition, XML is generally considered as a verbose language, which can increase the maintenance overhead. However, Maven introduced lots of good ideas such as standardization of project structure, which Gradle gets inspiration from. One of Gradle’s biggest advantages is that it uses a friendly Domain Specific Language (DSL) using the Groovy or Kotlin programming languages to specify the build process. As a result, specifying the build is more natural, easier to customize, and simpler to understand. In addition, Gradle supports features such as cache and incremental compilation, which contribute to faster build time.3
Example build file
Gradle follows a similar project structure to Maven. However, instead of a pom.xml file, you will declare a build.gradle file. There’s also a settings.gradle file that includes configuration variables and setup for a multiproject build. In the code snippet in Example 3-27 you can find a small build file written in Gradle that is equivalent to the Maven example you saw in Example 3-26. You have to admit it’s a lot more concise!
Example 3-27. Build file build.gradle in Gradle
apply plugin: 'java'
apply plugin: 'application'
group = 'com.iteratrlearning'
version = '1.0-SNAPSHOT'
sourceCompatibility = 9
targetCompatibility = 9
mainClassName = "com.iteratrlearning.MainApplication"
repositories {
mavenCentral()
}
dependencies {
testImplementation group: 'junit', name: 'junit', version:'4.12'
}Gradle commands
Finally, you can now run the build process by running similar commands to what you learned with Maven. Each command in Gradle is a task. You can define your own tasks and execute them or use built-in tasks such as test, build, and clean:
gradle clean-
Cleans up generated files during a previous build
gradle build-
Packages the application
gradle test-
Runs the tests
gradle run-
Runs the main class specified in
mainClassNameprovided theapplicationplug-in is applied
For example, running gradle build will produce an output similar to this:
BUILD SUCCESSFUL in 1s 2 actionable tasks: 2 executed
You will find the generated JAR in the build folder that is created by Gradle during the build process.
Takeaways
-
The Open/Closed Principle promotes the idea of being able to change the behavior of a method or class without having to modify the code.
-
The Open/Closed Principle reduces fragility of code by not changing existing code, promotes reusability of existing code, and promotes decoupling, which leads to better code maintenance.
-
God interfaces with many specific methods introduce complexity and coupling.
-
An interface that is too granular with single methods can introduce the opposite of cohesion.
-
You should not be worried about adding descriptive method names to help readability and comprehension of your API .
-
Returning
voidas a result of an operation makes it difficult to test its behavior. -
Exceptions in Java contribute to documentation, type safety, and separation of concerns.
-
Use checked exceptions sparingly rather than the default as they can cause significant clutter.
-
Overly specific exceptions can make software development unproductive.
-
The Notification Pattern introduces a domain class to collect errors.
-
Do not ignore an exception or catch the generic
Exceptionas you will lose the benefits of diagnosing the root of the problem. -
A build tool automates the repetitive tasks in the software development life cycle including building, testing, and deploying your application.
-
Maven and Gradle are two popular build tools used in the Java community.
Iterating on You
If you want to extend and solidify the knowledge from this section you could try one of these activities:
-
Add support for exporting in different data formats including JSON and XML
-
Develop a basic GUI around the Bank Statements Analyzer
1 This pattern was first put forward by Martin Fowler.
2 Earlier in Java’s life there was another popular build tool, called Ant, but it is now considered end-of-life and should not be used anymore.
3 For more information on Maven versus Gradle, see https://gradle.org/maven-vs-gradle/.