To conclude this book, let’s take a step back and discuss how you can make a life and career as a malware data scientist or a security data scientist in general. Although this is a nontechnical chapter, it’s just as important as the technical chapters in this book, if not more important. This is because becoming a successful security data scientist involves much more than simply understanding the subject matter.
In this chapter, we the authors share our own career paths to becoming professional security data scientists. You’ll get a glimpse of what day-to-day life looks like as a security data scientist and what it takes to become an effective data scientist. We also share tips on how to approach data science problems and how to stay resilient in the face of inevitable challenges.
Because security data science is a new field, there are many paths to becoming a security data scientist. Whereas many data scientists receive formal training through graduate school, many others are self-taught. For example, I grew up in the 1990s computer hacking scene, where I learned to program in C and assembly and to write black-hat hacking tools. Later, I got a bachelor’s degree and then a master’s degree in the humanities before re-entering the tech world as a security software developer. Along the way, I taught myself data visualization and machine learning at night, finally moving into a formal security data science role at Sophos, a security research and development company. Hillary Sanders, my co-author on this book, studied statistics and economics in college, worked as a data scientist for a time, and later found work at a security company as a data scientist, picking up her security knowledge on the job.
Our team at Sophos is just as diverse. Our colleagues hold a number of degrees in a wide range of disciplines: psychology, data science, mathematics, biochemistry, statistics, and computer science. Although security data science is biased toward those with formal training in quantitative methods in science, it includes folks with varied backgrounds in these fields. And although scientific and quantitative training is helpful for learning security data science, my own experience suggests that it’s also possible to enter and excel in our field with a nontraditional background, as long as you’re willing to teach yourself.
Excelling in security data science hinges on one’s willingness to constantly learn new things. This is because practical knowledge is just as important as theoretical knowledge in our field, and you pick up practical knowledge through doing, not through school work.
Being willing to learn new things is also important because machine learning, network analysis, and data visualization are constantly changing, so what you learn in school quickly goes out of date. For example, deep learning has only taken off as a trend in the years since around 2012, and has developed rapidly since, so almost everyone in data science who graduated before then has had to teach themselves these powerful ideas. This is good news for those seeking to enter security data science professionally. Since those already in the field have to constantly teach themselves new skills, you can get a foot in the door by already knowing those skills.
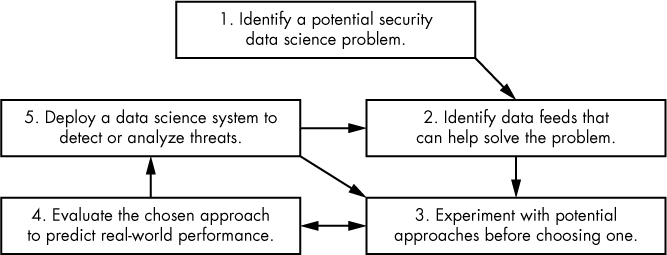
A security data scientist’s job is to apply the type of skills taught in this book to hard security problems. But application of these skills tends to be embedded within a larger workflow that involves other skills as well. Figure 12-1 illustrates a typical workflow of a security data scientist, based on our experience and that of our colleagues at other companies and organizations.
Figure 12-1: A model of the security data science workflow
As Figure 12-1 shows, the security data science workflow involves an interplay between five areas of work. The first area, problem identification, involves identifying security problems where data science can help. For example, we may hypothesize that identifying spear-phishing emails can be solved using data science methods, or that identifying the particular method used to obfuscate known malware is a problem worth investigating.
At this stage, any assumption that a given problem may be solvable with data science is just a hypothesis. When you have a hammer (data science), every problem can look like a nail (a machine learning, data visualization, or network analysis problem). We have to reflect on whether these problems are truly best addressed using data science methods, keeping in mind that it will take building a prototype data science solution and then testing this solution to better understand if data science actually provides the best solution.
When you’re working within an organization, identifying a good problem almost always involves interacting with stakeholders who are not themselves data scientists. For example, within our company, we often interface with product managers, executives, software developers, and salespeople who think that data science is like a magic wand that can solve any problem, or that data science is akin to “artificial intelligence” and therefore has some magical ability to achieve unrealistic results.
The key thing to remember when dealing with such stakeholders is to be honest about the capabilities and limitations of data science–based approaches, and to maintain a shrewd, measured attitude so that you don’t go chasing the wrong problems. You should discard problems for which there is no data to drive data science algorithms or no way to evaluate whether your data science approaches are actually working, as well as problems you can clearly solve better through more manual methods.
For example, here are some problems we declined after others asked us to solve them:
Once you do successfully identify a potential security data science problem, your next task is to identify data feeds you can use to help solve it using the data science techniques explained in this book. This is shown in step 2 of Figure 12-1. At the end of the day, if you don’t have data feeds that you can use to train machine learning models, feed visualizations, or drive network analysis that solves your chosen security problem, data science is probably not going to help you.
After you’ve selected a problem and identified data feeds that will allow you to build a data science–based solution to the problem, it’s time to begin building your solution. This actually happens in an iterative loop between steps 3 and 4 of Figure 12-1: you build something, evaluate it, improve it, reevaluate it, and so on.
Finally, once your system is ready, you deploy it, as shown in step 5 of Figure 12-1. As long as your system stays deployed, you’ll need to go back and integrate new data feeds as they become available, try out new data science methods, and redeploy new versions of your system.
Success in security data science depends a lot on your attitude. In this section, we list some mental attributes we’ve found are important to success in security data science work.
Data is full of surprises, and this disrupts what we thought we knew about a problem. It’s important to keep your mind open to your data proving your preconceived notions wrong. If you don’t, you’ll end up missing important learnings from your data, and even reading too much into random noise to convince yourself of a false theory. Fortunately, the more security data science you do, the more open-minded you’ll be about “learning” from your data, and the more okay you’ll be with how little you know and how much you have to learn from each new problem. In time, you’ll come to both enjoy and expect surprises from your data.
Data science projects are very different from software engineering and IT projects in that they require exploring data to find patterns, outliers, and trends, which we then leverage to build our systems. Identifying these dynamics is not easy: it often requires running hundreds of experiments or analyses to get a sense of the overall shape of your data and the stories hidden inside. Some people have a natural drive to run shrewdly designed experiments and to dig deeper into their data, almost addictively, whereas others don’t. The former is the type of person who tends to succeed at data science. Curiosity is therefore a requirement in this field because it’s what differentiates our ability to arrive at a deep understanding of our data versus a shallow one. The more you can cultivate an attitude of curiosity when building models and visualizations of your data, the more useful your systems will be.
Once you’ve defined a good security data science problem and have begun iteratively trying solutions and evaluating them, an obsession with results may take hold of you, particularly on machine learning projects. This is a good sign. For example, when I’m heavily involved in a machine learning project, I have multiple experiments running 24 hours a day, 7 days a week. This means that I might wake up multiple times a night to check on the status of the experiments, and often need to fix bugs and restart experiments at 3:00 in the morning. I tend to check in on my experiments before going to bed every night and multiple times throughout the weekend.
This kind of round-the-clock workflow is often necessary to build top-of-the-line security data science systems. Without it, it’s easy to settle for mediocre results, failing to break out of ruts or overcome blockages built out of misplaced assumptions about the data.
It’s easy to fool yourself into thinking you’re succeeding on a security data science project. For example, perhaps you set up your evaluation incorrectly, such that it appears your system’s accuracy is much better than it actually is. Evaluating your system on data that’s too similar to your training data or too dissimilar from real-world data is a common pitfall. You also might have inadvertently cherry-picked examples from your network visualization that you thought were useful but most users don’t find much value in. Or perhaps you worked so hard on your approach that you convinced yourself that the evaluation statistics are good, when in fact they’re not good enough to make your system useful in your real world. It’s important to maintain a healthy level of skepticism of your results, lest you find yourself in an embarrassing situation someday.
We’ve covered a lot in this book, but we’ve also barely scratched the surface. If this book has convinced you to pursue security data science in a serious way, we have two recommendations for you: first, begin applying the tools you’ve learned in this book to problems you care about immediately. Second, read more books on data science and security data science. Here are some examples of problems you might consider applying your newfound skills to:
To expand your knowledge of data science methods, we recommend starting simple, with Wikipedia articles on the data science algorithms you want to learn more about. Wikipedia is a surprisingly accessible and authoritative resource when it comes to data science, and it’s free. For those who want to go deeper, especially in machine learning, we recommend picking up books on linear algebra, probability theory, statistics, graph analytics, and multivariable calculus, or taking free online courses. Learning these fundamentals will pay dividends for the rest of your data science career, because they are the foundation on which our field rests. Beyond focusing on these fundamentals, we also recommend taking courses on or reading more “applied” books about Python, numpy, sklearn, matplotlib, seaborn, Keras, and any other tools covered in this book that are used heavily in the data science community.