The point of implementing security solutions is to mitigate risks. Mitigating risks does not mean eliminating them; it means reducing them to an acceptable level. The point is to buy time to react appropriately to an incident. To be successful, you need to anticipate what kinds of incidents may occur. You also need to identify what you are trying to protect, and from whom. That’s where risk analysis, threat definition, and vulnerability analysis come in. What is being protected? What are the threats? And where are the weaknesses that may be exploited?
Considering the threats is a prerequisite for any security endeavor. By identifying the threats, you can give your security strategy focus and reduce the chance of overlooking important areas of risk that might otherwise remain unprotected. Threats to a company’s finances or reputation can take many forms, and in order to be successful, a security strategy must be comprehensive enough to account for every possible threat.
A risk analysis must be a part of any security effort. It should analyze and categorize the things to be protected and avoided, and it should facilitate the identification and prioritization of protective elements. It should also provide a means to measure the effectiveness of the overall security architecture.
The formality and extent of the risk analysis depends entirely on the needs of the organization and the audience for the information. Nevertheless, there must be at least some definition of what the security architecture is intended to defend—otherwise the security effort may focus on the wrong priorities or may overlook important assets and threats. Simply put, risk is the probability of an undesired event (a threat) causing damage to an asset. Estimating the likelihood of such an event quantifies the risk, while simply enumerating the events that could occur, and their impact, provides a qualitative analysis.
These are the three components of a risk analysis:
• Asset identification and valuation
• Threat definition
• Likelihood and impact analysis
NOTE A threat is something that can go wrong and cause damage to valuable assets. A vulnerability is an exposure in the infrastructure that can lead to a threat becoming realized. Risk is the cost of a threat successfully exploiting a vulnerability.
The most basic risk analysis assumes that all threats are equally likely and takes the form of a simple definition of the assets to be protected. Among other things, these can include
• Computer and peripheral equipment
• Physical premises
• Power, water, environmental control, and communications utilities
• Computer programs
• Privacy of personal information
• Health and safety of people
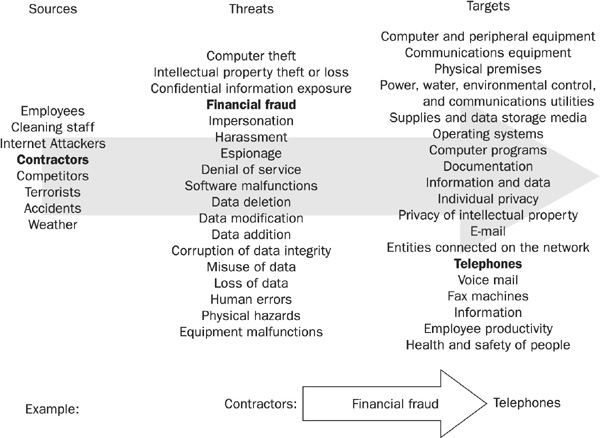
A more complete list of targets is included in Figure 2-1, a bit later in this section.
A more advanced risk analysis places a value on each identified asset and enumerates the threats that could damage those assets. Some common threats include
• Computer theft
• Confidential information exposed on the Internet
• Financial fraud
• Denial of service
• Corruption of data integrity
A more complete list of threats is included in Figure 2-1, shown in the next section.
A highly advanced risk analysis attempts to identify the likelihood of each threat occurring to each asset and estimates the monetary cost resulting from that event. Regardless of the extent to which the company decides to perform the risk analysis, it must not overlook the concept entirely.
A threat vector includes information about a particular threat—where it may originate and what asset it exposes to risk. The type of threat and the means by which it gains entry to the protected asset constitute a threat vector. For example, consider an e-mail message originating outside the company that contains an interesting subject line and an executable attachment that happens to be a virus. The threat is the attachment that can be opened by an unsuspecting employee; the threat vector is the e-mail message carrying it. Figure 2-1 shows a variety of possible threat vectors.
NOTE A threat vector describes what a threat is and where it comes from.
There are many different breakdowns of threat vectors. Statistics gathered via surveys form the basis of many of these breakdowns, and as such reflect only the perceptions of the management of various companies. One reputable source for this type of survey result is the Computer Security Institute (CSI), which has identified particular threat vectors and their frequency. Their results, shown in Figure 2-2, imply that the majority of losses suffered by organizations originate from within the company—a result that agrees with most other surveys. Typically, the total percentage of internal threats is quoted at 70 to 80 percent. That is, 70 to 80 percent of computer crimes, attacks, and violations originate from trusted employees inside the company. A firewall can do nothing to protect against inside attacks—the origin of the threat is part of the threat vector.
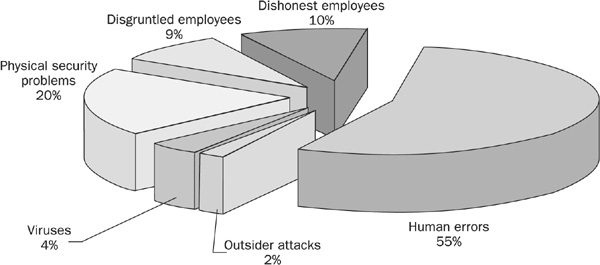
FIGURE 2-2 Computer Security Institute (CSI) crime-loss statistics
It is important to understand threat vectors and consider them when designing security controls to ensure that possible routes of attack for the various threats receive appropriate scrutiny. Threat vectors are also important for explaining to others how the protective mechanisms work, and why they are important. It is not uncommon to encounter the question, “Why do we need internal protection when we have a firewall?” This question can be answered with an explanation of the various threat vectors that bypass the protection provided by the firewall. For example, attackers that enter an internal network from the Internet use three common threat vectors:
• Bypassing the firewall
• Hijacking active connections
Because the Internet connection is used to send and receive data, all firewalls allow some access into the network from the outside. These allowed services often include e-mail, DNS, Java on web browsers, and often virtual private network (VPN) connections. Any of these can be abused to provide unauthorized access. In addition, many companies use e-mail and web proxy software, such as Microsoft’s Outlook Web Access, to allow their employees to gain access to e-mail and files residing on the private network when they are away from the office. Attackers may exploit flaws or weaknesses in the software that runs these services, or they may capture or guess weak passwords to take over an authorized account.
CAUTION A firewall can provide a false sense of security, because many people assume that firewalls block all unwanted access. This is not true—firewalls allow many types of traffic to pass, some of which may be malicious.
Most firewalls filter traffic assigned network communication ports. More advanced firewalls look at an entire network session as a stream of connected fragments of network traffic. However, most firewalls do not look at the content of the network traffic to see whether it is typical traffic intended for normal application communication. For example, most firewalls don’t look at network communications between e-mail clients and servers to determine whether a real e-mail message is being transferred or whether somebody is trying to harvest e-mail addresses. These firewalls would not be able to detect an attacker who is using a common application protocol to “tunnel” traffic by embedding hostile traffic inside an otherwise normal protocol.
Bypassing the firewall entirely is often possible with the use of certain very specific types of attacks. One such type of attack that was common in the past involved crafted packets that contain bit patterns designed to confuse the firewall’s filtering capability. For example, fragmented packets or ICMP messages were used to tunnel through an otherwise working firewall, allowing an attacker direct access to the machines behind the firewall.
Dial-up modems that accept connections from anywhere and connect the user to the internal network also are threat vectors that bypass the firewall. Dual-homed systems, which contain multiple network interfaces that connect to both untrusted and trusted networks at the same time, contain even more threat vectors.
Established connections from the Internet, such as some types of VPN connections, wireless connections based on 802.11, or other active sessions, can also be hijacked. Most security software components only authenticate at the start of a connection, so once the connection is established, an attacker can sometimes disable the authorized system using a denial of service (DoS) attack and masquerade as that system, continuing the session. This is known as a man-in-the-middle attack.
Some threat vectors originate from inside the network. These provide routes for attackers and programs on the outside to connect directly to a system on the inside. Common examples of inside threat vectors include
• Server programs implanted by unsuspecting employees (such as girlfriend programs)
• Back door (or trap door) configurations
• Trojan programs
• Viruses
The term girlfriend program or girlfriend virus (developed by early hackers) refers to a program handed to an employee on a floppy or CD by a trusted friend, that actually contains a Trojan program designed to open a connection on the employee’s machine. These programs allow unrestricted access directly from the Internet. They can be difficult to detect and eliminate because they do not traverse the Internet, unlike many viruses. Since they take advantage of an employee’s personal trust in the attacker, these attacks are very effective and not at all uncommon. Defenses against them include virus-scanning software set to disable such programs, vigilance by network scanning software designed to detect these programs, clear corporate policies, and end-user education programs.
Back door (also known as trap door) configurations are built-in features of computer and network devices that allow vendor support personnel to connect directly to the devices by way of a commonly known account and password. Almost all network equipment contains back doors. The passwords to the back door accounts are widely shared on the Internet. Back doors are very hard to defend against, because they are a type of inside threat vector.
Traffic to back doors that tunnels over ICMP or other allowed protocols will slip right through any firewall that allows inbound access for those protocols. Firewalls typically allow inbound traffic, often SMTP and sometimes HTTP for web servers on the demilitarized zone (DMZ), and back doors on these systems would function.
Many companies also have multiple trusted network connections they don’t control, such as routers connecting their network to service providers or their parent company for the purpose of extranet connectivity, and these require many types of access to be allowed through the firewall (as in the case of an Application Service Provider (ASP) that provides services or information to internal systems from the Internet, for example).
Another potential danger is user-initiated connections, started with java applets or other techniques. Connections initiated from the inside of a company (whether by spyware, keyloggers, or adware) will get out of any firewall, regardless of how it is configured. Additional, specialized security software is required to protect against these threats.
CAUTION Inside threats, although they create some of the most hazardous and ubiquitous risks to networks, are often overlooked in security strategies.
Trojan programs (of which the girlfriend program is one example) are pieces of software installed on trusted internal systems, and they allow direct access to the internal system from the network. These connections can be exploited over the Internet, through the firewall, or across the internal network by users who are not authorized to have that access. Trojans work because the firewall rules are set to allow certain types of traffic pass from the Internet to the internal systems, assuming that these internal systems do not allow direct connections other than the well-known functional components of the standard system software. Trojans may be installed by authorized internal staff, by unauthorized people who gain physical or network access to systems, or by viruses.
Viruses typically arrive in documents, executable files, and e-mail. They may include Trojan components that allow direct outside access, or they may automatically send private information, such as IP addresses, personal information, and system configurations, to a receiver on the Internet. Very nasty viruses will capture password keystrokes and send them out to an Internet receiver.
Viruses, Trojans, back doors, spyware, adware, keyloggers, and other hostile and unwanted software often infest networks via file-sharing programs. Kazaa, Morpheus, and Imesh are examples of peer-to-peer (P2P) software that can infect unsuspecting users’ computers with hostile programs. In addition, most instant message software, such as Microsoft MSN Chat, Yahoo Messenger, and AOL Instant Messenger, have built-in file transfer capabilities that can allow hostile programs to infect computers. These file-sharing programs often bypass the protection of the firewall, depending on the configuration of the firewall and the network.
Every network security implementation is based on some kind of model, whether clearly stated as such or assumed. For example, companies that use firewalls as their primary means of defense rely on a perimeter security model, while other companies that rely on several different security mechanisms are practicing a layered defense model. Every security design includes certain assumptions about what is trusted and what is not trusted, and who can go where. Starting out with clear definitions of what is fully trusted, what is partially trusted, and what is not trusted along with an understanding of what type of defense model is being used can make a security infrastructure more effective and applicable to the environment it is meant to protect.
The most common form of defense, known as perimeter security, involves building a wall around the object of value. A house has walls, doors, and windows to protect what’s inside; a safe deposit box made of metal is designed to maintain the secrecy of the contents within; and in network security, a firewall is the most common choice for controlling outside access to the internal network. Perimeter security is like a lollipop with a hard crunchy outside, but a soft chewy center, as shown in Figure 2-3. Unfortunately, most people think only in terms of perimeter security and overlook the shortcomings of the lollipop model, which results in a dangerous false sense of security.
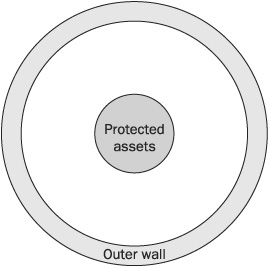
FIGURE 2-3 The lollipop model of defense
One of the limitations of perimeter security is that once an attacker breaches the perimeter defense, the valuables inside are completely exposed. As with a lollipop, once the hard crunchy exterior is cracked, the soft chewy center is exposed.
Another limitation of the lollipop model is that it does not provide different levels of security. In a house, for example, there may be jewels, stereo equipment, and cash. These are all provided the same level of protection by the outside walls, but they often require different levels of protection. On a computer network, a firewall is likewise limited in its abilities, and it shouldn’t be expected to be the only line of defense against intrusion.
NOTE A lollipop defense is not enough to provide sufficient protection. It fails to address inside threats and provides no protection against a perimeter breach. Yet many organizations do not understand firewalls in this way. Firewalls are an important part of a complete network security strategy, but they are not the only part. A layered approach is best.
Perhaps even more important, the lollipop defense does not protect against an inside attack. Inside jobs are, in fact, quite common, and providing protection against them is very important.
Firewalls are an important part of a comprehensive network security strategy, but they are not sufficient alone. Today, networks both send information to and receive information from the Internet, and the rules for doing so are complex. Firewalls are still useful for shielding networks from each other, but they are often not sufficient to provide proper access controls, especially when internetwork communication is complicated.
The onion model of security is a layered strategy, sometimes referred to as defense in depth. This model addresses the contingency of a perimeter security breach occurring. It includes the strong wall of the lollipop but goes beyond the idea of a simple barrier, as shown in Figure 2-4. A layered, security architecture, like an onion, must be peeled away layer by layer, with plenty of crying (on the part of the hacker).
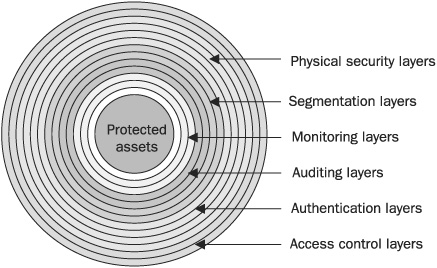
FIGURE 2-4 The onion model of defense
Consider what happens when an invader picks the front door lock or breaks a window to gain entry to a house? The homeowner may hide cash in a drawer and may store valuable jewels in a safe. These protective mechanisms address the contingency that the perimeter security fails. They also address the prospect of an inside job. The same principles apply to network security. What happens when an attacker gets past the firewall? What happens when a trusted insider, like an employee or a contractor, abuses their privileges? The onion model addresses these contingencies.
A firewall solution alone provides only one layer of protection against the Internet, but it does not address internal security needs. With only one layer of protection, which is very common for networks connected to the Internet, all a determined individual has to do is successfully attack that one system to gain full access to everything on the network. A layered security architecture provides multiple levels of protection against internal and external threats.
A layered, security architecture can be designed in many ways. Segmenting your network is one way of creating multilayer security at the network layer. Multiple firewall subnets for external networks, the DMZ, and internal networks are another. At the system level, personal firewall software combined with appropriate system access controls are another example. At the application layer, application authentication that uses more than one factor (password, token, or biometrics) for each application or authorization level is another way of creating layered security.
The more layers of controls that exist, the better the protection against a failure of any one of those layers. Consider a system that allows full access to an account that only uses username/password authentication, without any other security controls. That system uses only one layer of security, and it is strictly an authentication control. Anyone who obtains the username and password can gain full access to the system, and since there are no other layers that must be bypassed, the system would be completely compromised. If such a system had further layers of security controls that needed to be passed after the username and password authentication, compromising the system would be correspondingly more difficult.
The layered security approach can be applied at any level where security controls are placed, to increase the amount of work required for an attacker to break down the defenses and reduce the risk of unintended failure of any single technology. System, network, and application authentication controls can be layered. Network and system access controls can also be layered. Encryption protocols can be layered (such as by encrypting first with Triple DES followed by encrypting with Blowfish or AES). Audit trails can be layered with the use of local system logs coupled with off-system network activity logs. System availability controls can be layered by using clustering technology. Many companies use uninterruptible power supply (UPS) systems but also have backup generators in case the UPS systems fail. These are all examples of layered approaches that place similar controls in conjunction, or in sequence, to compensate for the loss of any individual control.
A security architecture must identify regions of the network that have varying levels of trust. Some computer systems or networks must be trusted completely—these are where the critical data is stored. Some are trusted incompletely—these are where important data is stored but they are also made available to untrusted networks. Some networks (like network connections to the Internet or 802.11 wireless hot spot connections) are completely untrusted. The security controls must carefully screen the interfaces between each of these networks. These definitions of trust levels of networks and computer systems are known as zones of trust (as shown in Figure 2-5).
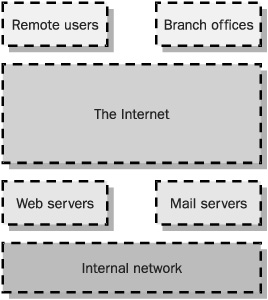
NOTE Trust is always present in any security architecture. Some areas are trusted, and others are not. Enumerating these areas is the first step in reducing the weak spots that can defeat a security model.
Once you have identified the risks and threats to your business, and you know what functions are required for your business, you can begin to separate those functions into zones of trust. To do this, you need to assign levels of trust to each business function—in other words, you need to specify what level of risk is acceptable to accomplish each business function. That involves making trade-offs between what you want to do and what you want to avoid.
Zones of trust are connected with one another, and business requirements evolve and require communications between various disparate networks, systems, and other entities on the networks. Corporate mergers and acquisitions, as well as business partner relationships, produce additional complexities within the networking environment that can be diagrammed and viewed from the perspective of trust relationships. Once you decide whom you do and do not trust, you can begin to develop a strategy for containing those entities into zones.
IT resources vary in the extent to which they can be trusted. Separating these resources into zones of trust enables you to vary the levels of security for these resources according to their individual security needs. Some zones are less trusted, and some are more trusted. The use of multiple zones allows access between a less and a more trusted zone to be controlled to protect a more trusted resource from attack by a less trusted one. Any zone could be subdivided into policy pockets of common security policies if need be, to support additional classification categories without the infrastructure expense of establishing another zone.
To visualize trust zones, imagine a castle surrounded by multiple walls that form concentric rings around the castle. There are cities in the rings, and there is exactly one door in each of the ring walls. Each door has a guard who says “Who goes there?” and the guard may ask for identification and a password. It is difficult for people in outer rings to attack people in the inner rings, but it isn’t difficult to attack people if they are in the same ring. Thus, those in the same ring need to have the same minimum level of trustworthiness.
To establish a minimum level of trust, each zone (except perhaps an “untrusted” zone) requires that the devices in it have a certain, equivalent level of security—this level of security is determined by the technologies and procedures that are in place to check for attacks, intrusions, and security policy violations. Measures to establish trust include fixing known problems, detecting intrusions, and periodically checking for unauthorized changes, violations of policy, and vulnerabilities to attack.
Firewalls, routers, virtual LANs (VLANs), and other network access control devices and technologies can be used to separate trust zones from each other (as the walls in the castle analogy did). Access control lists (ACLs) and firewall rules can be used to control the intercommunication between these levels, based on authorization rules defined in the security architecture.
The importance of trust models is that they allow a broad, enterprise-wide view of networks, systems, and data communications, and they highlight the interactions among all of these components. Trust models can also distinguish boundaries between networks and systems, and they can identify interactions that might otherwise be overlooked at the network level or system level.
Trust can also be viewed from a transaction perspective. During a particular transaction, several systems may communicate through various zones of trust. Diagramming these transaction-level trust relationships, along with the trust zones, provides a complete picture of security relationships among systems. Figure 2-6 shows an example of trust relationships with each color representing a set of systems that trust each other
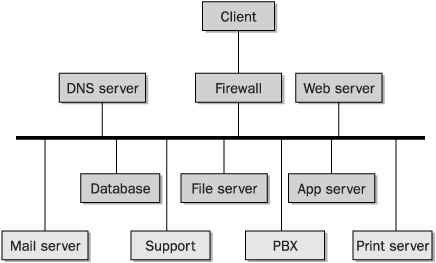
FIGURE 2-6 Transaction-level trust relationships
In a transaction-level trust model, instead of systems being separated into different trust zones based on their locations on the network (as is done with the Internet, a DMZ, and an internal network) systems can be separated into functional categories based on the types of transactions they process. For example, a credit card transaction may pass through a web server, an application server, a database, and a credit-checking service on the Internet. During the transaction, all of these systems must trust each other equally, even though the transaction may cross several network boundaries. Thus, security controls at the system and network levels should allow each of these systems to perform their authorized functions while preventing other systems not involved in the transaction from accessing these resources.
A diagram of transaction-level trust relationships, in conjunction with a data-flow diagram that shows where each piece of information resides on each system and traverses each network connection, can illustrate security requirements that cross network boundaries. This can lead the security architect to visualize the access, authentication, authorization, and privacy controls necessary to protect the entire transaction. This point of view can be more powerful than just a network-level trust model by itself.
Segmenting network data resources based on their access requirements constitutes a good security practice. Segmentation allows greater refinement of access control based on the audience for each particular system, and it helps confine the communications between systems to those systems that have transactional trust relationships. Segmentation also confines the damage of a security compromise. In the event that a particular system is compromised, network segmentation with access control lists reduces the number and types of attacks that can be launched from the compromised system. For example, web servers often experience compromises due to the ease and flexibility of web server attacks. A compromised web server that is confined in its own network segment offers fewer opportunities for the attacker to continue attempting to attack other servers. This holds true for any server on the network.
NOTE Network segmentation is an important component of network security because it contains the damage caused by network intrusions, malfunctions, and accidents.
Segmentation can be accomplished in many ways—there are many ways systems can be placed on a segmented network. In general, the greater the amount of segmentation, the tighter the confinement. Ideally, every server would be on its own network segment, with ACLs specifying which network protocols can pass to and from each segment and to and from which IP addresses. In environments where segmenting every system is impractical, it is useful to group systems together on network segments according to their functionality. For example, web-accessible servers may reside on a segment together, and databases may reside on a different segment.
Figure 2-7 shows an example of network segmentation in a large organization in which three zones of trust exist. These zones of trust are organized into network “layers” for public, application, and data access. In this example, the public layer contains systems that communicate with the public over the Internet through a firewall, and are thus assigned the lowest level of trust. Access control lists (ACLs) are used to protect each individual server on this layer, allowing only network communication from the appropriate systems and networks to which each system needs to communicate. The application layer contains systems that need to communicate with the systems on the public layer, but not to the public itself. These systems don’t need to have direct communication with the Internet, so they are assigned a higher level of trust and given more protection. ACLs are also used to control intra-system communication. Finally, the data layer contains systems with the highest level of trust because they house sensitive and confidential information. These systems only need to communicate with systems on the application layer, not on the public layer or directly to the Internet. ACLs are again used to ensure that each system can only communicate to other authorized systems.
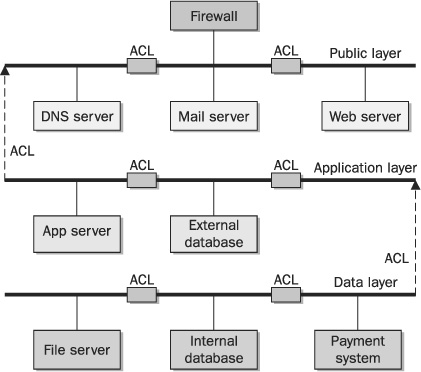
FIGURE 2-7 Network segmentation with access controls
A layered segmentation approach also provides a useful conceptual model for network administrators. Several groups of network segments can comprise a layer, defined by the general types of systems and data included on that layer. For example, a public layer may contain systems that accept communication directly from the Internet. An application layer may contain systems that accept communication from the public layer. A data layer may accept communication from the application layer. ACLs can control the traffic between each set of layers. The ACLs can reside on a router or firewall, but the specific implementation details vary with the environment.
When threats are first identified, a security strategy gains focus and reduces the chance of oversights that result in unprotected areas. Threat vectors include information about particular threats—where they originate and what assets they expose to risk. Risk analysis is an important part of any successful security effort, and it should analyze and categorize the things to be protected and avoided. It should also provide a means to measure the effectiveness of the overall security architecture.
There are two types of security defenses—the lollipop model, and the onion model. Perimeter security is like a lollipop with a hard crunchy outside, but it has a soft chewy center that fails to address inside threats and provides no protection against a perimeter breach. The more layers of controls that exist, the better the protection against a failure of any one of those layers, and this is the approach the onion model takes. The onion model can be applied at any level where security controls are placed, and it increases the amount of work required for an attacker to break down the defenses and reduces the risk of any single technology failing.
Once the risks and threats to a business have been identified, business controls can be separated into zones of trust. Segmentation of data, systems, and network components allows greater refinement of access control based on the audience for each particular system, and it helps confine the communications between systems to those systems that have transactional trust relationships.
Essinger, James. Internet Trust. Massachusetts: Addison Wesley, 2001.
Knightmare. Secrets of a Super Hacker. Washington: Loompanics Unlimited, 1994.
McClure, Stuart. Hacking Exposed: Network Security Secrets and Solutions. New York: McGraw-Hill/Osborne, 2003.
Mitnick, Kevin D. and Simon, William L. The Art of Deception: Controlling the Human Element of Security. New Jersey: John Wiley & Sons, 2002.
Quarantiello, Laura E. Cyber Crime: How to Protect Yourself from Computer Criminals. Wisconsin: Tiare Publications, 1999.
Schneier, Bruce. Secrets and Lies. New Jersey: John Wiley & Sons, 2002.
Schwartau, Winn. Cybershock: Surviving Hackers, Phreakers, Identity Thieves, Internet Terrorists, and Weapons of Mass Disruption. New York: Thunder’s Mouth Press, 2000.
Vacca, John R. Identity Theft. New York: Prentice Hall, 2002.