Interruptions to the normal operation of computer and network systems can and will occur. The causes of service interruptions are numerous, and they can include such events as bad production changes, hardware and software failures, and security breaches. For the purposes of this chapter, an incident will be defined as any disruption of the normal operation of a computer system.
Organizations must have systems and processes to detect such disruptions, and they need plans and procedures to respond and recover accordingly. For security-related incidents, intrusion-detection systems (IDSs) can be deployed to identify and alert appropriate personnel in a timely manner. Independently, organizations can deploy systems that proactively monitor the availability of critical systems and processes and sound alarms when problems are detected. Once a problem is identified, organizations should use the their incident response plans to coordinate their response and recovery.
In certain situations, it will be necessary to reconstruct system activity and extract information from affected computer systems. Forensic analysis is the process of identifying, extracting, preserving, and reporting on data obtained from a computer system. Forensics can be used to recover important data from a failed system, to document unauthorized employee activity, or to obtain evidence for the eventual prosecution of a criminal act.
The ultimate goal of any incident response (IR) plan is to contain, recover, and resume normal operations as quickly and smoothly as possible. Having thought about and developed plans to respond to various types of problems, regardless of the time they occur, can prevent panic and costly mistakes. In addition, creating, reviewing, and testing response procedures will identify weaknesses and failures in the organization’s ability to detect, respond, and recover.
A good IR plan will enable organizations to recover from any type of incident imaginable. Unfortunately, the majority of plans today focus solely on security-related incidents. When the corporate web server suddenly stops responding, it is irresponsible to assume that it has been hacked—perhaps the drive has failed, a power interruption might have occurred, or maybe it is a network problem rather than a server problem that has developed. Therefore, when defining and developing IR procedures, it is important that plans include the ability to identify and resolve system failures.
The initial response will require personnel with the expertise to diagnose, chart a course of action, and who have the authority to implement identified solutions. The initial responders may also discover that the scope of the incident is much larger or that it affects additional systems and will therefore need additional resources. Well-defined escalation lists can assist responders in identifying and contacting such resources. Beyond simply notifying technical personnel, it may be necessary to contact other departments, such as public relations, legal, or human resources to handle the non-technical aspects of the incident.
The IR plan should also take into account that the person who discovers a problem is most likely not capable of responding, and that they will therefore need to report the problem somewhere. Specifying how and where incidents should be reported is a good starting place for many IR plans.
A good IR plan will break down into a number of distinct phases, each of which will be discussed in the following sections:
• Detection
• Response and containment
• Recovery and resumption
• Review and improvement
The details of the IR plan will consist mainly of how personnel are notified, what the escalation procedures are, and who has decision-making authority for a given incident. For example, the failure of a critical transaction-processing system will most likely require different people to be involved than would a suspected security breach or a power outage.
Additional reading on IR and sample IR plans can be found at these web sites:
• www.securityfocus.com/library/category/222
• www.sans.org/rr/catindex.php?cat_id=27
The first obstacle to effective incident response is detecting an actual incident such as a process failure or a security breach. It is a popular practice to proactively monitor the availability of systems via the Simple Network Management Protocol (SNMP). SNMP management systems can be used to routinely monitor system response times and check the availability of processes from a centralized console. Such systems have the ability to notify configured personnel by paging or e-mailing them when an alarm is triggered. In addition, the monitored systems themselves can use SNMP to send emergency messages called traps to a console, should a major fault occur that requires attention.
Beyond SNMP monitoring, organizations require mechanisms to detect security-related events and to inform the appropriate people. Intrusion-detection systems (IDSs) have been specifically developed for the purposes of detecting malicious activity. An IDS differs from a firewall in that it does not actively interact with network traffic. An IDS will passively monitor resources and activity and will alert appropriate personnel as alarms are triggered. Some advanced systems have the ability to take action based on configured alarms, such as sending reset packets to terminate connections, or reconfiguring firewalls to block the offending host.
There are two main types of IDS systems available today: network-based and host-based IDSs. Network-based IDSs monitor networks for evidence of malicious packets, while host-based systems monitor individual hosts for evidence of malicious or unauthorized activity. IDS alarm systems can further be classified as either anomaly-detection engines or attack-signature engines. An attack-signature-based IDS works in a similar fashion to antivirus software by maintaining a database of known attacks, and it searches passing packets for signs of them. Anomaly-detection engines are a slightly newer technology. These systems work by going through a learning phase to construct a baseline of network activity. Once the baseline is complete, they report on any detected deviations from this normal pattern of activity. Chapter 14 discusses IDSs in greater detail.
The biggest failure when deploying an IDS system is misconfiguring the alarms. If the system generates too many false-positives, people will stop responding to the alarms (remember the old story about the boy who cried wolf?). On the flip side, if the system alarms aren’t triggered during a legitimate attack (this failure being a false-negative) then what is the point of having it? It takes many long hours and expertise to strike the appropriate balance.
A newer genre of systems, collectively known as intrusion-prevention systems (IPSs) are gaining in popularity. Like an IDS, an IPS monitors network activity for attack signatures. But unlike an IDS, which is primarily a passive device, an IPS is an inline device that can be configured to block packets that trigger alarms. Because an IPS is inline and is making packet decisions, a false positive can disrupt authorized communications, and a failure in the device can cause an outage. Therefore, IPS systems should have appropriate failover and resiliency functionality to meet network-availability requirements.
Beyond IDSs and IPSs, network devices and hosts are capable of producing significant activity logs. These logs can be used to troubleshoot problems, identify unauthorized activity, and correlate events between hosts. System and application logs can record events such as failed access attempts, system events and errors as well as configuration changes. Network devices, such as firewalls and routers, can also be configured to log traffic passing through them. Firewalls are ideally located to log and record traffic entering and exiting corporate networks.
Analyzing these logs can be an overwhelming and time-consuming task. However, failure to review logs may leave administrators unaware of important events occurring around the network. Tuning logs so that they do not record insignificant events, or developing automated analysis tools, can be time well spent.
The reliability of system logs can come under scrutiny during a security breach. It is common practice for an intruder to remove incriminating log entries to avoid detection. Logs that are stored remotely and out of the attackers reach, can be considered more reliable than logs kept on the local system. Additionally, centrally aggregating logs from multiple systems can allow for more complex event correlation analysis. Correlation of log events across multiple hosts is significantly simplified when the system clocks of these systems are synchronized. The Network Time Protocol (NTP) is a simple and mature method for synchronizing and maintaining system clocks across multiple hosts. For more information on NTP, see www.ntp.org.
A growing trend is to outsource the IDS and log management. Companies like Counterpane Internet Security (www.counterpane.com) specialize in configuring and monitoring IDS systems for signs of unauthorized activity. Additionally, by aggregating IDS logs from multiple companies, event correlation analysis can be performed across company systems to spot trends and potential threats earlier.
Incident detection comes in many forms. It may come from a user phone call, or a dedicated system may sound the alarm. However, a notification or warning may also come from a public service. The Computer Emergency Response Team at Carnigie Mellon University (www.cert.org) maintains a mailing list that sends out alerts on newly discovered security vulnerabilities and provides reports on detected activity trends before any specific vulnerability is known. Subscribing to such a notification list may alert administrators to potential security threats and enable the organization to take a proactive stance. For example, CERT sent out an early notification on a Cisco router vulnerability (www.cert.org/advisories/CA-2003-15.html), and included in this notification was a workaround that could be implemented to reduce an organization’s exposure before a patch was available.
When a potential incident is detected, the organization’s response plan should be initiated. As mentioned earlier, an organization needs to get the right people working on the problem as rapidly as possible. A clear and simple mechanism should be available for notifying and apprising appropriate staff members of the developing situation. This may be as simple as making a phone call or sending a page to the system administrator. Contacting individuals is now remarkably easy, since many regularly carry cell phones. Having up-to-date contact information in the IR plan is crucial. Larger organizations may maintain a ticketing system with various queues that automatically contact configured staff when a ticket is assigned to that queue.
Whatever mechanism is implemented, it should be a reliable and efficient method for contacting whomever the organization wants working on the problem. Remember, a quick and organized response may mean the difference between a minor incident and a major catastrophe.
Once the proper people have been notified, their primary goal is to perform a quick assessment of the situation, identifying any immediate actions required to contain and prevent further damage to systems. These are the immediate questions to answer:
• Is this a security incident?
• If it is a security incident, has the attacker successfully penetrated the organization’s systems, and is the attack still actively in progress?
• If it is not a security incident, why is the system or process not operating normally?
If the incident appears to be a security breach, it is important to determine whether the attack is active or not, and whether it is obviously successful. If it is not active or not successful, more time will be available for planning the response. If the attack appears successful or is still in progress, decisive actions should be taken quickly to contain the breach.
The actual actions taken will be influenced by the ultimate goals of the organization. Should an organization wish to prosecute an intruder, response plans should be careful to preserve and collect evidence. There are a number of legal requirements that must be satisfied in order to have system evidence that is admissible in court (which will be discussed in the “Forensics” section of this chapter). If an organization is not interested in prosecution, only in recovery, immediately shutting down affected systems or network connections may be the most appropriate response.
If response personnel feel that the security breach may not be limited to a single host, shutting down all external connections may be the appropriate response. However, detaching production systems may cause more financial harm to the organization than the security breach. Imagine if Yahoo or eBay shut down every time an attack was detected. It is probably not advisable to shut off network connectivity if downtime costs the corporation $100,000 per hour, when the estimated damages from the breach are only $10,000. If the source of attack can be determined and isolated from authorized traffic, administrators may wish to reconfigure firewalls to block all traffic related to this incident. For example, quickly implementing filters to deny all traffic from a specific source address may be a viable short-term containment strategy. However, if the attackers are determined, they may switch source addresses to circumvent the newly implemented filters.
While assessing the extent of the security breach, it may be necessary to interact with the affected systems. Be careful not to make an intrusion worse by logging in and issuing commands, especially as an administrator. Intruders may be waiting for this response to complete their attack! The most important thing to realize when working with a potentially compromised system is that it should not be trusted. System commands should not be relied upon to report accurate information, and logs may have been altered to hide the hacker activity. The “Forensics” section later in this chapter will provide more detailed information about working with a potentially compromised system.
While responding to an incident, appropriate communication between response personnel, decision makers, system owners, and affected parties is crucial to prevent duplication of effort and people working at cross purposes. For example, the response team may decide to temporarily disconnect the affected systems from the network, and without proper communication an application owner may think there is a problem with the system and take unnecessary steps to fix it. In addition, contacting vendors and ISPs may provide additional information about events going on outside of your particular network. The ISP can also provide information from their logs, which may shed more light on the events. In certain situations, the ISP may also be able to quickly implement upstream filters to protect your network from the suspected attacker.
For system failures, administrators may be able to diagnose and implement changes quickly. Most organizations maintain specific blocks of time in which configuration changes to production systems can be made; these are commonly known as change windows. For example, Sunday mornings at 3 A.M. for 24×7 operations is not an uncommon change window. IR plans should contain appropriate documentation for obtaining emergency authorization to make changes outside of that window. If the root cause is not initially obvious, contacting the system vendor to report the problem and to gain access to the vendor’s support personnel may be necessary—IR plans should contain vendor contact information as well as the necessary information to gain access to support.
Now that the incident has been contained, the organization can move into recovery and resumption mode to return the organization to normal operations. For system failures, this will include applying patches, making configuration changes, or replacing failed hardware. For security breaches, it will focus on locking down systems, identifying and patching security holes, removing intruder access, and returning systems to a trusted state.
Intruders can and will install programs and back doors (commonly called rootkits) to maintain and hide their access. Therefore, simply patching the security hole that enabled their access may not be sufficient to remove them. For example, they may have replaced the telnet daemon with a version that allows certain connections without a password. In addition, they may have replaced common binaries, such as who and ps, with Trojans that will not report their presence while on the system.
The best avenue for recovery after an intrusion is to rebuild affected systems from scratch. This is the only way to ensure that the system is free from Trojans and tampering. Once the system is rebuilt, restore critical data from a trusted backup tape (one created before the intrusion occurred, not necessarily the backup from the previous night). However, if critical data has been deleted that cannot be restored from a backup, forensics may be required to recover the data. In this situation, it is important to preserve the disk media to increase chances of data recovery.
Once the system is recovered to its previous operating state, be sure to remove the security vulnerability that allowed the intrusion in the first place. This may entail applying a patch, reconfiguring the vulnerable service, or protecting it via a more restrictive firewall rule set.
The last and often overlooked step is review. Performing an overall assessment of the incident will allow the organization to identify response deficiencies and make improvements.
The review process should include the following elements:
• Perform a damage assessment. How long were systems unavailable? Could systems have been recovered quicker if better backups or spare hardware was available? Did monitoring systems fail? Was there evidence of the impending failure that was not reviewed timely?
• For security breaches, was critical data accessed, such as trade secrets or credit card data? If so, does the organization have a legal responsibility to notify the credit card owners or companies? If the attack was not successful, significant work may not be required. However, even if the attack was unsuccessful, the organization may wish to increase its monitoring, especially if the intruder was aggressive and persistent.
• Identify how the intrusion occurred and why it was not detected more quickly, ideally before it was successful. This can include going back through firewall and IDS logs to find evidence of initial probing by the intruder.
• Ensure appropriate steps were taken to close the security hole on the affected machine, as well as to identify and similarly protect any other servers in which the hole might exist.
• Review procedures to identify how the security hole may have come into existence. The origins of a security hole are numerous and can include such things as a failure to identify and apply a critical patch, a misconfiguration of a service, or poor password controls.
• Beyond a simple review of the technical aspects of the attack, the organization should review its performance to identify areas of improvement. For example, how long did it take critical personnel to begin working on the problem? Were they reachable in a timely and simple fashion? Did they encounter any roadblocks while responding?
• Should legal proceedings be under consideration, ensure that all evidence has been adequately collected, labeled, and stored.
As mentioned at the beginning of this chapter, the field of computer forensics is dedicated to the identifying, extracting, preserving and reporting on data obtained from a computer system. Forensic analysis has a wide array of uses, including reconstructing or documenting user activity on a given system and extracting evidence related to a computer break-in. Additionally, forensics can be used to recover data from a failed system or data that had been accidentally or maliciously deleted. The remainder of this chapter will provide an introduction to forensic concepts and various procedures and tools for forensically examining systems.
Due to the vast number of variables that will be encountered on a forensic investigation, no two endeavors will require the exact same steps. Therefore, a specific checklist of steps is not likely to be helpful. In legal situations, the defense might subpoena such a list and the examiner might be forced into explaining why some steps on the checklist were not performed. However, a crime scene is a chaotic environment, and an examiner may wish to keep a cheat sheet to ensure that general steps are taken and good procedures are followed.
Before diving into the nuts and bolts of computer forensics, it is important to understand that forensic evidence that will be used in criminal proceedings must satisfy a number of legal standards to be admissible. It would be very disappointing to have spent many tedious hours scouring a computer system collecting evidence only to have it thrown out due to improper procedure. In a nutshell, forensic evidence is held to the same standards of evidence collection as any other evidence collected. These standards require that evidence is acquired intact without being altered or damaged. It also requires that the evidence presented be extracted from the crime scene. Finally, the analysis must be performed without modifying the data. For cases where the ultimate use of the evidence is unknown, or even if there is an extremely remote chance that the case will ever go to court, an examiner should remain diligent in his or her procedures and documentation. Improper evidence-handling procedures cannot be rectified later, should proceedings in fact end up in court.
As stated, the evidence must be presented without alteration. This requirement applies to the entire evidence life cycle, from collection to examination to storage and to its eventual presentation in a court of law. Once evidence has been taken into custody, it is necessary to account for its whereabouts and ownership at all times. The documentation of the possession of evidence is known as the chain of custody. You must be able to provide a documented, uninterrupted chain of custody when testifying to evidence integrity. To protect the integrity of evidence when it is not being analyzed, it should be physically secured in a safe or an evidence locker. Additionally, a detailed log should be maintained of each person who accesses the evidence, the reason for the access, and the date and time it was removed and returned to storage.
Unrelated to the physical scene, but important nonetheless, is the identification of relevant management policies and procedures. Should a corporation wish to terminate or prosecute an employee for improper use of systems, they will need documented policies that establish what types of activities are prohibited. Policies should also establish that employees have no expectation of privacy and consent to monitoring when using corporate systems. However, written policies that aren’t disseminated and acknowledged by employees do little good. It is good practice to have employees acknowledge that they have read and understood such policies on an annual basis.
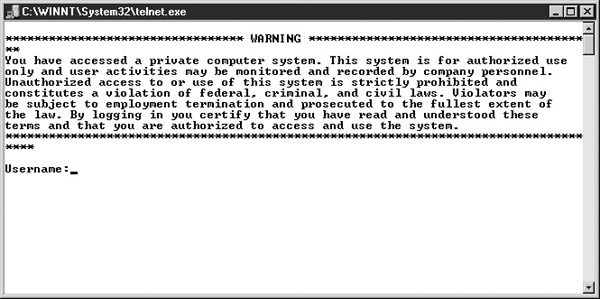
In addition to documented policies and procedures, corporations should make use of system banners. Hackers will not have read and consented to organizational acceptable use policies. System banners, such as the one shown in Figure 29-1, can be used to inform any individuals that connect to a given system that they are private property, that the system is monitored, and that unauthorized activity is strictly prohibited. Documented policies and login banners prevent someone from claiming that they didn’t know their activity was illegal or prohibited. In addition, failure to obtain consent could inhibit the forensic examiner’s ability to monitor the offender’s system usage legally.
FIGURE 29-1 An example of a warning banner
The process of acquiring evidence is perhaps the most sensitive and crucial step in the entire process. If done improperly, potential evidence may be lost, missed, or deemed inadmissible by the courts.
Computer forensic data can be classified as either host-based or network-based. Network-based data comes from communications captured from a network-based system, such as a firewall or IDS. IDS products such as the Niksun NetVCR are specifically designed to record network traffic for playback at a later date. This can be useful in reconstructing events surrounding a computer break-in. Logs of network firewalls can also provide insight into network activity and evidence.
Host-based data is the evidence found on a given system, and it can encompass a variety of different things depending on what is being investigated. If the investigation is related to a break-in, a forensic examination may wish to detect the presence of foreign files and programs, document access to critical files, and any alteration to such files. When investigating unauthorized employee activity, the examiner may be attempting to reconstruct the employee’s Internet usage, recover e-mails, or identify documents that the employee should not have possessed.
Before ever touching the computer, an examiner must gain control of the immediate vicinity of the computers to be examined and document the surroundings. Note the location of important items, such as diskettes, plugs, and assorted wiring (so that it can be disassembled and moved to another location without any difficulty, if necessary), and if it is still operating, note the contents of the display.
A simple and effective way to indisputably document the scene is to take pictures. The more thorough the documentation, the harder it will be to dispute the authenticity and accuracy of the evidence. When collecting evidence from a crime scene, err on the side of over-collection: grab anything and everything that may contain evidence, such as laptops, PDAs (and its charger!), floppy disks, CDs, and DVDs. Label and seal each item that is collected from the scene, being sure to include the date and time and the location the item was recovered from. An examiner rarely gets a second chance to return to the scene and pick up a forgotten item.
TIP While at the scene, check under keyboards and inside drawers to see if you can find a note with a password or two. These passwords may be used to log in to the system, gain access to accounts or encrypted files.
If the computer has not already been powered off, the examiner must make a critical judgment call: let it continue running or pull the plug. If the machine is already turned off, make sure it remains off until the appropriate images are made. Evidence must be presented without alteration, and the boot process of an operating system will cause numerous changes to the drive media, such as updates to file access times and changes to swap space and temporary files. The forensic imaging process will be discussed in greater detail shortly.
Both approaches have their merits, and the individual situation will dictate the best approach. Pulling the plug and freezing the system is usually considered safest and should never be construed as a wrong decision. By powering the machine off, the examiner cannot be accused of contaminating the system contents. In addition, once the system is frozen, the examiner has more time to formulate a plan without being concerned that more damage to systems could occur. However, in some cases the only evidence available may be in memory, or management may have refused to allow the machine to be taken offline. The server may perform functions too integral to the business for it to be down for even a short time. Allowing the machine to continue to function may enable the examiner to monitor the intruder and obtain additional evidence. An examiner should be flexible and be prepared for either scenario.
When the machine can be taken offline, the examiner should make a forensic backup of the local hard drives. The goal of a forensic backup is different than that of a regular system recovery backup. A regular backup targets intact files and is designed to recover the system to a functioning state as quickly as possible. A forensic backup, usually called a system image or bit-stream backup is a low-level copy of the entire drive. The bit-stream method captures any and all partitions that have been created, whether used or not, and even unallocated space (drive space that has not yet been partitioned). Thus, any data that may exist in file slack or in the file system, and anything written to disk not in the file system, will be captured. This way, when examining the forensic image (the original is rarely examined directly) it is possible to recover deleted files and fragments of data that may have found their way onto one of these locations.
Hard drives are actually comprised of many nested data structures. The largest structure on the drive will be a partition. A hard drive can contain one or more partitions, each of which can be referenced separately by the operating system. Partitions are often used to separate multiple operating systems on the same drive or to enable more efficient use of one very large drive. Information about the available partitions is kept in a special area of the disk called the partition table. Once the partition is created, a file system can be installed upon it.
The file system is used by the operating system to store and access files in a simple and logical fashion. To function, the file system must be subdivided into evenly sized units. On a Unix system, these units are referred to as blocks, while on a Windows system they are known as clusters. These units are the smallest chunks that a file or piece of data can be stored in, and depending on the size of the file system, these units can be as small as 4 bytes but also can be upwards of several hundred bytes. If a file does not fill the entire cluster, the remaining space is left unused and is referred to as slack. Thus, storing a 64-byte file in a 128-byte cluster actually leaves 64 bytes of file slack.
File slack is interesting to a forensic investigator because of what it may contain. If a smaller file overwrites a larger file, there may be remnants of the larger file in the file slack. Additionally, a sophisticated user may intentionally hide data in file slack to avoid detection. File slack is not transferred with a file when the file is copied to another drive or backed-up in a non-forensic manner.
Bit-stream backups can be created several different ways. Dedicated hardware, such as the Image MASSter from Intelligent Computer Solutions, can be used to copy one drive to another. If dedicated hardware is not available, it will be necessary to boot the system to an alternative operating system contained either on a floppy disk or a bootable CD. While many different software programs exist to make a viable forensic image of a system, it may be necessary to prove to the courts that the backup is truly identical and the software used is reliable. Tools such as the forensic software EnCase (www.guidancesoftware.com) and SafeBack (www.forensics-intl.com/safeback.html), as well as the Unix tool dd, have already been accepted by the courts as reliable. When using software to make an image, be sure to capture the entire drive and not just the file system in the main partition. A simple way to view the partition table is to create an MS-DOS boot disk and run the FDISK program.
TIP Software that has not been properly licensed will not stand up in court. An examiner cannot prove that the patch applied to disable the licensing restrictions did not alter the operation of the software in some other fashion.
As further support of an examiner’s claim that the image is an identical copy of the original drive, it is good practice to compute a hash value of the untouched original media. A hash value is produced by applying a cryptographic algorithm to the contents of the drive. Hashes are one-way, meaning that a set of data will produce a hash value, but the algorithm cannot be used to derive the original data from the hash. For the hash algorithm to be reliable, no two sets of data should produce the same hash value, and any change to the data set will produce a different hash value. Currently, MD5 and SHA1 are the hash algorithms of choice. It is good practice to create hashes using two different algorithms, so that if a flaw or attack is discovered in one hash, rendering it unreliable, the other hash can still be used to validate evidence.
In addition to hashing the original media, compute a hash value for the newly created image to ensure the hash values match. If they don’t, the image is not an identical image of the original and another image should be created.
It is also common practice to not work directly with the original backup, but instead to use an image of the image. This way, the original image can be safely locked up, and if a mistake is made or the evidence becomes corrupted, a fresh and intact copy still exists.
NOTE The media used to back up the original must be either unused or forensically cleaned prior to use. If not, data remnants on the drive may contaminate the evidence. Programs like Pretty Good Privacy (PGP) and WipeDrive by AccessData (www.accessdata.com/index.html) can be used to prepare media.
Should the decision be made to work on a live system, proceed with extreme caution! As mentioned earlier, an attacker may be waiting for an authorized administrator to log in to complete an attack. The goal of working with a live system is to capture items that won’t survive the power-off process. These can include such items as the contents of physical memory and swap files, running processes, and active connections. Additionally, the trick is to capture these items as intact as possible. For example, asking a system to list running processes will start a new process, and this new process will require and use system memory. The output of any commands executed will also need to be captured.
Writing files to the local file system can potentially destroy evidence, as well. Be prepared to write output to remote systems via a network, or attach a local storage device that is capable of recording the output.
Capturing System Contents It is important to realize that the contents of computer memory and parts of the computer hard drive are highly volatile. When working with a live system, the initial steps will be to capture information from the most to the least volatile. These are the major items to be captured:
• CPU activity and system memory CPU activity is one of the most volatile and therefore hardest things to capture accurately. Fortunately CPU activity is of little use to the forensic examiner and is not really worth the effort. The contents of system memory can be captured on a Unix system by dumping the contents of the /dev/mem and /dev/kmem files to a remote system.
• Running processes Documenting the active system processes can help the examiner understand what was occurring on the system at the time. Processes can be captured via the Unix command ps and via the Windows Task Manager.
• Network connections Documenting network connections serves two purposes: understanding what systems are currently connected, and determining if any unknown processes are currently listening for incoming connections. The presence of such listeners is a telltale sign of an intrusion. On both Unix and Windows platforms, the netstat command can be used to capture network connection information. In addition to netstat, capture the contents of the system’s Address Resolution Protocol (ARP) table by using the arp command, and capture the system routing table by using netstat with the –r switch.
• Open files Open files on a Unix system can be captured with the lsof command (list of open files). For Windows, the Handle utility from www.sysinternals.com can be used.
TIP Sysinternals.com has a number of useful utilities for capturing and obtaining data from a live Windows system.
The Danger of Rootkits If your investigation is occurring because of a security breach on the system, the examiner cannot initially determine the extent of compromise and therefore should not consider the victimized system to be trustworthy. The intruder may have taken steps to hide his or her presence on the system, such as replacing system commands to not report their presence on the system or doctoring logs to remove evidence of the break-in. Unfortunately, this is not as complicated as it sounds, and it has been largely automated through the proliferation of rootkits.
Rootkits are automated packages that create back doors, remove incriminating log entries, and alter system binaries to hide the intruder’s presence, and an intruder may well have installed a rootkit on a compromised system. On a Unix system, the ps command is used to list the running processes, and a common rootkit function is to replace the system’s version of ps with a modified one that conveniently does not report any processes related to the intruder. This means that an unsuspecting administrator is left blind to their presence. When examining a compromised system, an examiner should maintain a set of trusted binaries on a CD or a set of floppies, and run those in lieu of the binaries that are installed on the system.
While this may be sufficient, a growing rootkit trend is to modify the actual operating system itself. The ps command obtains its output by asking the operating system to report what processes are currently active, and a newer type of rootkits, commonly called loadable kernel modules (LKMs), work by intercepting the actual request to the operating system and removing the intruder’s processes from the output. The end result is that even if a trusted version of ps is run, the output will not list the intruder processes.
Detecting the presence of an LKM is more complicated and requires searching through the system memory contents. In a Linux environment, the command kstat can be used to search memory contents. For in-depth reading on locating LKMs see www.s0ftpj.org/docs/1km.htm.
Once a set of evidence has been obtained, it is time for the analysis to begin. The analysis will consist of a number of phases, and evidence may exist in a number of places. The most obvious place evidence may exist is in a file contained somewhere on the file system. If the criminal is a suspected child pornographer, it would be logical to search the file system for image files containing child pornography. However, not all evidence will be that obvious. If the examiner is documenting unauthorized use of computer systems, evidence may need to be pieced together from temporary and swap files, identifying recently used files and relevant e-mails, reconstructing Internet browser caches and cookies, and recovering deleted files and pieces of data from local and possibly from remote file systems.
As previously mentioned, forensic examiners need to be flexible. They encounter a myriad of systems and situations that test their skills and knowledge. The following sections provide an introduction to the various methods for extracting evidence from systems and provide examples of helpful and relevant tools.
When examining a file system for potential evidence, a growing challenge facing forensic experts today is the ever-increasing storage capacities of today’s disks. A forensic examination will scour the entire disk in search of evidence, and it is not uncommon for a PC hard disk to exceed 30 GB while a server can have in excess of 100 GB of available storage. Either computer may be connected to an external storage device or even a storage area network (SAN) with terabytes of storage. Unfortunately, files on the file system will be the most significant source of evidence, and it may be necessary to manually inspect each and every file and search through every byte for potential evidence or tampering. Such an endeavor on a 100 GB disk could keep an examiner busy for months.
In reality, the majority of files on a system are harmless and can be quickly discarded. However, how can the examiner be sure that a Windows device driver doesn’t contain hidden data, or that it is really a Windows device driver? General forensic software, such as EnCase, as well as specialized software, including the program HashKeeper, can be used to verify that common files have not been tampered with or are really what the filenames say they are. These programs work by using the same trusted MD5 and SHA1 hash algorithms used to authenticate drive images. An examiner can build a system with the same operating system, patch level, and installed programs as the suspect machine and then use one of these packages to obtain a cryptographic hash for each file on the trusted system. Once a trusted database has been created, its hash values can be compared to the cryptographic hashes of files on the target system. Files that have hashes that match those of the trusted system have not been tampered with and can be discarded, and those that don’t match will need to be investigated further. A well-constructed database may eliminate the need to examine upwards of 50 or 60 percent of the files on the system. Figures 29-2 and 29-3 are examples of using HashKeeper to assist with this process. To assist examiners, hash sets are available for many of the common operating systems at numerous patch levels, as well as for major application programs.
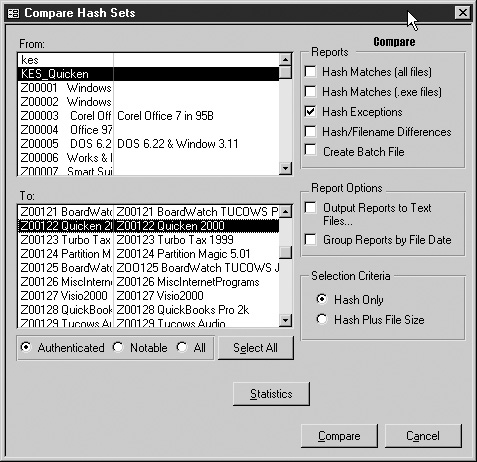
FIGURE 29-2 Use HashKeeper to compare confiscated files against trusted file sets.
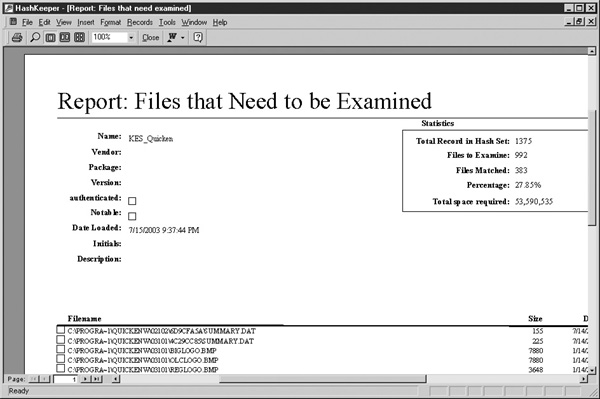
FIGURE 29-3 A HashKeeper report listing the remaining files requiring analysis
Once the population of files has been reduced, the remaining files will need to be examined. When attempting to reconstruct and document the activity of the system owner, the most recently accessed files will probably be of significant interest. Each file on the operating system will have a timestamp indicating the last time it was accessed. For Windows systems, the AFind utility from Foundstone’s forensic toolkit (www.foundstone.com/resources/forensics.htm) can create a list of file access times on a given system.
The number of files on the system could still be significant, and going through them one by one can be time consuming. Several utilities are available to simplify the process of examining files and directory contents in bulk. In addition to EnCase and other commercial forensic software, shareware such as ThumbsPlus (www.cerious.com/) and Retriever (www.djuga.net/retriever.html) can catalog and present thumbnails of the contents of an entire directory at once. Another time saver is to employ a utility that understands and can open many different file formats; for example, INSO Quick View Plus (www.inso.com), owned by Stellent, can open and understand over 200 different types of files. This can be a significant time saver over importing dozens of Corel WordPerfect documents into Microsoft Word, and hunting down a viewer for a file that can’t be opened natively.
Another source of information that will be of interest to an examiner is a user’s Internet usage history. An examiner will want to examine the browser cache and cookie files to see what web sites were visited recently. Another good tool available from Foundstone is called Pasco. Pasco can automate and reconstruct the cache of the most popular browser in use, Internet Explorer. Pasco outputs a list of URL’s that can be examined in a spreadsheet program as shown in Figure 29-4.
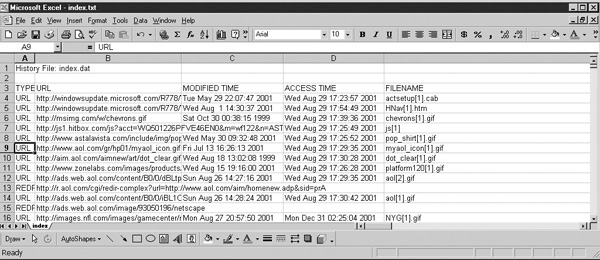
FIGURE 29-4 Foundstone’s Pasco can be used to reconstruct Internet Explorer usage.
Unfortunately, not all evidence will be sitting out in the open. Users may take the time to conceal the presence of incriminating data. A rudimentary way to hide evidence in a Windows environment is changing the file extension and placing the file in a nondescript directory. For example, changing a file extension from .doc (a Word document) to .dll (a Windows system driver) and moving it from the My Documents directory to the Windows System32 directory (c:\winnt\system32) may hide it from a cursory search of file extensions and popular file-storage directories.
A more interesting search would be to identify all files that have extensions that do not match the true type of file. Forensic programs such as EnCase can be used to seek out and identify such files. Another good practice is not to rely on a program, such as Windows Explorer, that is dependant on file extensions. INSO Quick View Plus can open a Word document with a .jpg extension without any problem.
Unix environments do not rely on file extensions to determine file types, so such attempts at concealment do not apply. However, a popular Unix trick is to precede the filename with a period (giving it a name such as “.hiddenfile”) or even making a file look like a directory by naming it with a period followed by a space (.). A filename consisting of simply a period is the current directory in a Unix listing, so a period followed by a space would look the same.
Hidden files also exist in a Windows environment, so be sure to set Windows Explorer to show any and all hidden files.
Alternative Data Streams The NTFS file system used by Windows NT, 2000, and XP enables a single file to have an alternative data stream (ADS). The ADS can be used to store data or other files, and its presence is almost completely hidden behind the primary data stream. ADS functionality was originally developed to provide compatibility for Macintosh users storing files on NT-based systems.
Windows Explorer does not indicate the presence of the alternative data stream, and most antivirus programs will overlook its existence as well. To demonstrate how streams can be used, Figure 29-5 shows an empty file created on an NTFS drive in Windows 2000. Once the file exists, you can hide text in the file’s ADS, but the file is still reported as being 0 bytes long.
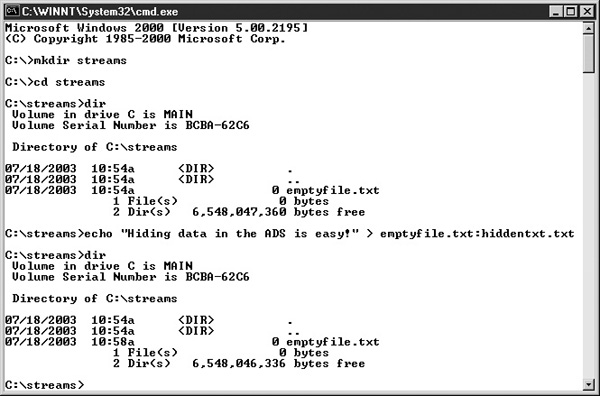
FIGURE 29-5 Using the command line, you can place one file into another’s ADS.
For particularly sneaky users, data can be directly hidden in an ADS without a filename. Figure 29-6 takes a file called evidence.doc and hides it in an ADS without a filename, and then deletes the original file. To prove its presence, you can do a type on the ADS to show that it’s there.
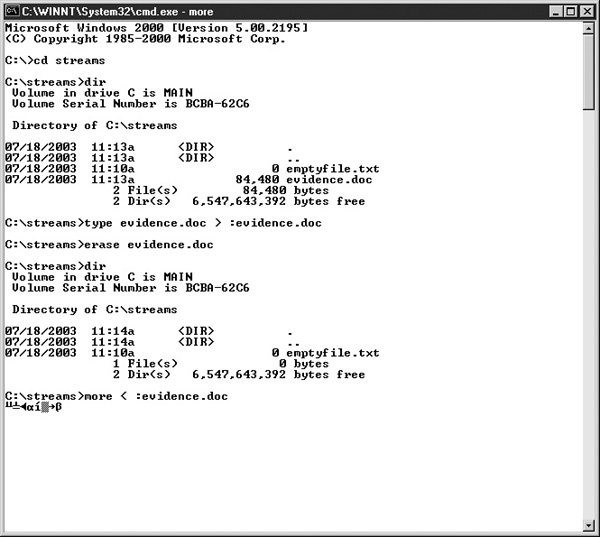
FIGURE 29-6 An ADS can be created without an actual file!
A couple of utilities are available to search systems for files hidden in an ADS. Figure 29-7 shows the Sfind utility(www.foundstone.com/resources/forensics.htm) from Foundstone being used to find the ADS file.
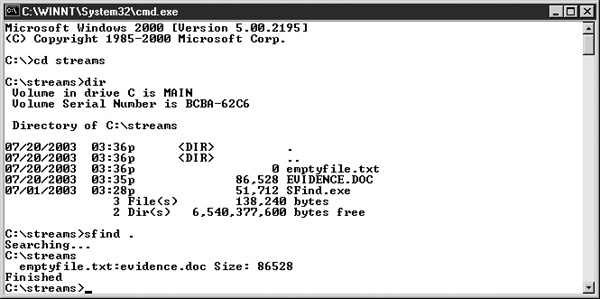
FIGURE 29-7 The Sfind utility can be used to find files in an ADS.
Steganography Steganography is the practice of camouflaging data in plain sight. The practice is very difficult to detect, and even if steganographic data is identified, it is most likely encrypted. Files most likely to include steganographic data are audio and image files, where extra data can be inserted without affecting the file tremendously. For example, data can be added to the file by changing the shades of various colors ever so slightly, such that the alterations are not likely to be noticed. However, this only works well with very small amounts of data. Adding a megabyte worth of data into a two megabyte picture would drastically alter the original image. The inability to store large amounts of data keeps the practice from being widespread.
A newer technique that is emerging is a steganographic file system. This would mitigate the problem of data sizes by allowing hidden data to be dispursed across an entire file system. Due to the problems associated with detecting steganography, a more practical approach is to search for the existence of steganography tools on the target system. Without such tools, it is unlikely that steganographic data exists.
The act of telling an operating system to delete a file doesn’t actually cause the data to be removed from the disk. In the interest of saving valuable CPU cycles and disk operations, the space used by the file is simply marked as available for the operating system. Should a need for the disk space arise at a later time, the data will be overwritten, but until then the actual data is left intact on the disk. Programs such as Norton UnErase or Filerecovery Professional from LC Technology International, shown in Figure 29-8, are specifically designed to retrieve deleted files from Windows systems. However, before searching the drive, be sure to check the Recycle Bin contents for anything useful.
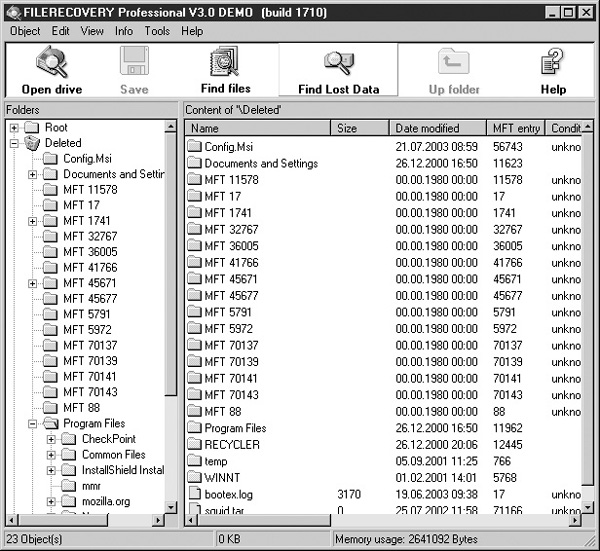
FIGURE 29-8 Filerecovery Professional searches drives for deleted files.
Even if the section of disk gets reused, it may be possible to find parts of the original file in the slack space. Advanced tools and techniques also make it possible to determine what was on the disk before the data was erased or overwritten. Much like on a blackboard that has not been thoroughly cleaned, a faint image of the original file is left behind on a disk.
To securely delete data from a disk, it is necessary to overwrite the section of disk on which the file resided with a file-wiping program. The wiping program overwrites the section of disk many times with binary ones and zeros to thoroughly destroy all trace elements from the drive.
NOTE Guidelines published by the National Security Agency indicate that it is possible to recover meaningful data from a disk that has been overwritten more than 20 times.
Encryption is a technique that an individual can use to hide data on a given system. Compression is commonly used to bundle multiple objects into a single smaller object to conserve resources. Common compression formats include the Windows installation CAB files and Zip archives, and .tar and .gz (gzip) files in Unix. Compression can be viewed as a weak form of encryption.
The difficultly posed by compression is that any data contained in a compressed file will be missed by a keyword search on the hard drive. While decompressing the file is most likely a trivial process, the examiners can’t decompress and search such files if they’re unaware of their existence.
Encryption poses similar problems, but decrypting files is most likely not a trivial exercise. Beyond detecting the presence of the encrypted data, it is necessary to decrypt and inspect the contents of those files. If the suspect is unavailable or uncooperative and will not provide access to the files, alternative means may be necessary.
Encryption schemes work by mathematically modifying data with an encryption algorithm that uses a secret key. The security provided by the encryption system is dependent on the strength of the algorithm and the key. Unless there is a flaw in the algorithm, it is necessary to try all the possible keys to decrypt the data—this is called a brute-force attack. The range of values a key can have is called the keyspace, and the larger the keyspace, the more values the key can have, and the longer it will take for a brute-force attack to succeed. On average, the proper key will be discovered after approximately half the possible keys in the keyspace are tried. This is commonly the attack of last resort, and it is also the most time- and resource-intensive approach.
To put the concept of keyspaces into perspective, web browsers use the Secure Sockets Layer (SSL) to encrypt sensitive communications. SSL can use either 40-bit or 128-bit keys. The 40-bit encryption provides a keyspace of 240 possible keys, while a key length of 128 bits generates 2128 possible keys. That means 128-bit encryption provides approximately 300 billion trillion more keys than 40-bit encryption.
This is not to say that brut-force attacks render all encryption systems useless. With modern and foreseeable computing power, systems with adequately strong keys (such as 128-bit SSL) can require many many billions of years to find the correct key. This is very likely much longer than the amount of time the information needs to remain secret.
NOTE For an interesting exercise in attacking today’s encryption algorithms, see www.distributed.net. Distributed.net is a project that harnesses the unused computing power of desktop PCs around the world to perform brute-force attacks against modern encryption systems.
The strongest encryption algorithms are those that are public. While this may seem strange at first, algorithms that have been made available for public scrutiny by cryptography experts are likely to have had their design flaws identified and corrected. In the case of flawed algorithms, it may be possible to mount faster and more efficient attacks than to launch a brute-force attack.
In addition to encryption, a forensic examiner may encounter files protected by a password or may need to decrypt the operating system login passwords. Unfortunately for security professionals, but fortunately for forensic examiners, people do not normally use strong passwords, thus making a brute-force attack possible. For example, a Pentium IV computer running a brute-force program can try almost all possible alphanumeric passwords (those passwords consisting of the letters A–Z and numbers 0–9) of six characters or less in under 24 hours. Password-cracking efforts can also be accelerated by trying all the words found in a dictionary first (as well as dictionary words followed by the number 1). The entire Webster’s unabridged dictionary can be checked inside of 20 minutes by a fast machine. Numerous programs are available for mounting attacks against the various passwords that may be encountered, such as the following:
• Access Data www.accessdata.com/ Microsoft Office documents
• L0phtcrack www.l0pht.com Windows 2000 and Windows NT passwords
• John the Ripper www.openwall.com/john/ Unix system passwords
• PGPPASS packetstormsecurity.nl/Crackers/pgppass.zip PGP systems
• Zipcrack packetstormsecurity.nl/Crackers/zipcracker-0.1.0.tar.gz WinZip files
• Cain packetstormsecurity.nl/Crackers/Cain10b.zip Windows 9x passwords
Examiners will have some idea of the topics that are relevant to the investigation, so an excellent way to find evidence is to perform keyword searches on the hard drive. A keyword search is a bit-level search that goes systematically through the drive looking for matches. While string searching will not decipher encrypted text, it may turn up evidence in file slack, regular or misnamed files, swap space, and data hidden in alternative data streams.
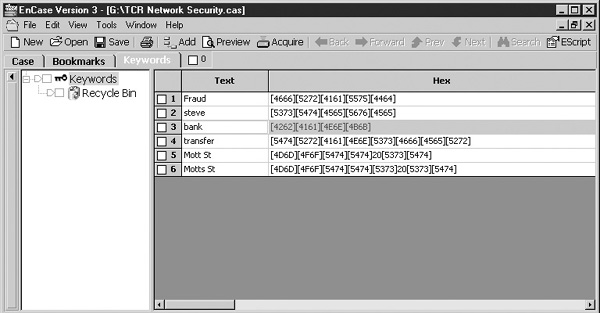
The trick with string searching is finding an exact match and determining exactly what to search for. When defining search terms, it may be helpful to include some spelling deviations; for example, if you’re looking for an address such as “56th Street,” be sure to search for “56th St.” and “fifty-sixth street.” Most forensic programs have fuzzy logic capabilities that automatically search on similarly spelled words. Figure 29-9 shows the forensic software EnCase performing a keyword search on a hard drive.
FIGURE 29-9 Keyword searching can be used to locate evidence.
The primary goal of intrusion response is to effectively detect and respond to disruptions of normal computer operations. Responding to an incident includes contacting appropriate personnel, identifying the cause of an outage, and developing and implementing a recovery plan. Finally, one of the most important but often overlooked steps of the incident response is to review the organization’s performance and make improvements.
Computer forensics has many applications in today’s modern world. Forensics can be used to investigate and document the use of a computer system, extract evidence in support of a criminal investigation or civil suit, and recover data that has been deleted or that was lost during a drive failure. Regardless of the purpose, when performing forensic work it is imperative that information be captured intact and without alteration. There are numerous forensic tools available, and a good investigator will be familiar with many of them.
Kruse, Warren G. II, and Heiser, Jay G. Computer Forensics. New York: Addison-Wesley, 2002.
Vacca, John R. Computer Forensics, Computer Crime Scene Investigation. Massachusetts: Charles River Media, Inc., 2002.