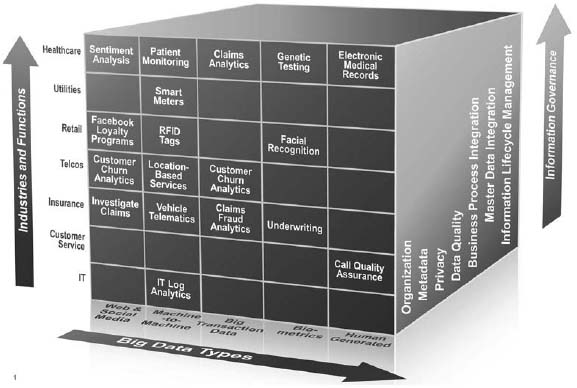
This chapter provides a framework for big data governance. As shown in Figure 2.1, this framework consists of three dimensions:
We will discuss each dimension in this chapter.
Figure 2.1: A framework for big data governance.
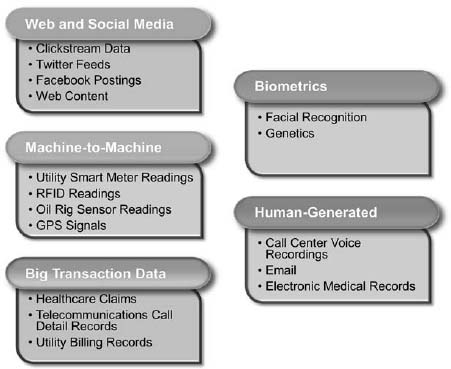
As shown in Figure 2.2, big data can be broadly classified into five types.
Let’s consider each type in more detail:
The seven core disciplines of information governance also apply to big data:
Before going any further, it’s important to discuss experimentation in big data projects where the killer use case might not be known upfront. Tom Deutsch argues that organizations should adopt experimentation as a strategic process, along with a tolerance (and even encouragement) of failure as a way of advancing the business. This tolerance of experimentation is rooted in the understanding that failure is often the single best way to learn something. Deutsch further argues that organizations that are not trying and failing at validating their analytic hypotheses are actually not being aggressive enough in working with their data.4 Notwithstanding all of this, big data needs to be governed with specific reference to the analytic and operational requirements for applications that vary by industry and function. We discuss these scenarios by industry and function in the following pages.
| Solution: | Sentiment analysis |
| Big data type: | Web and social media (health plans) |
| Disciplines: | Privacy |
Because of privacy regulations such as the United States Health Insurance Portability and Accountability Act (HIPAA), health plans are somewhat limited in what they can do online.
If someone posts a complaint on Twitter, the health plan might want to post a limited response and then move the conversation offline.
| Solution: | Patient monitoring |
| Big data type: | M2M data (healthcare providers) |
| Disciplines: | Data quality, information lifecycle management, privacy |
A hospital leveraged streaming technologies to monitor the health of newborn babies in the neonatal intensive care unit. Using streaming technologies, the hospital was able to predict the onset of disease a full 24 hours before the onset of symptoms. The application depended on large volumes of time series data. However, the time series data was sometimes missing when a patient moved, which caused a lead to disengage and stop providing readings. In these situations, the streaming platform used linear and polynomial regressions to fill in gaps in the historical time series data. The hospital also stored both the original and modified readings in the event of a lawsuit or medical inquiry. Finally, the hospital established policies around safeguarding protected health information.
| Solution: | Claims analytics |
| Big data type: | Big transaction data (health plans) |
| Disciplines: | Data quality |
A large health plan processed over 500 million claims per year, with each claims record consisting of 600 to 1,000 attributes. The plan was using predictive analytics to determine if certain proactive care was required for a small subset of members. However, the business intelligence team found that physicians were using inconsistent procedure codes to submit claims, which limited the effectiveness of the predictive analytics. The business intelligence team also analyzed the text within claims documents. The team used terms such as “chronic congestion” and “blood sugar monitoring” to determine that members might be candidates for disease management programs for asthma and diabetes, respectively.
| Solution: | Employee credentialing |
| Big data type: | Biometrics (healthcare providers) |
| Disciplines: | Privacy |
The use of biometric information continues to expand in the marketplace and the workplace. For example, hospital staff members might use biometrics so that they do not have to retype their user names and passwords. Instead, they can use a biometric scan to quickly log into the system when they arrive at a bed or station. Hospitals need to work with legal counsel, however, to conduct privacy impact assessments regarding the use and retention of biometric data about their employees.
| Solution: | Predictive modeling based on electronic medical records |
| Big data type: | Human-generated data (healthcare providers) |
| Disciplines: | Data quality |
The analytics department at a hospital built a predictive model, based on 150 variables and 20,000 patient encounters, to determine the likelihood that a patient would be readmitted within 30 days of treatment for congestive heart failure. The analytics team identified “smoking status” as a critical variable in their predictive models. At the outset, only 25 percent of the structured data around smoking status was populated with binary yes/no answers. However, the analytics team was able to increase the population rate for smoking status to 85 percent of the encounters by using content analytics based on electronic medical records containing doctors’ notes, discharge summaries, and patient physicals. In summary, the analytics team was able to improve the quality of sparsely populated structured data by using unstructured data sources.
| Solution: | Smart meters |
| Big data type: | M2M data |
| Disciplines: | Privacy, information lifecycle management |
Several utilities are rolling out smart meters to measure the consumption of water, gas, and electricity at regular intervals of an hour or less. These smart meters generate copious amounts of “interval” data that need to be governed appropriately. Utilities need to safeguard the privacy of this interval data because it can potentially point to a subscriber’s household activities, as well as the comings and goings from his or her home. In addition, utilities need to establish policies for the archival and deletion of interval data to reduce storage costs.
| Solution: | Facebook loyalty app |
| Big data type: | Web and social media |
| Disciplines: | Privacy, master data integration |
The marketing department at a retailer might want to use master data on customers, products, employees, and store locations to enrich its Facebook app. The success of the Facebook app depends on a strong foundation of master data management and policies pertaining to social media governance. For example, the retailer needs to adhere to the Facebook Platform Policies by not using data on a customer’s friends outside of the context of the app. In addition, the retailer needs to leverage a consistent set of identifiers to link a customer’s Facebook profile with his or her MDM record. Finally, the retailer needs to establish a robust product hierarchy to enable product comparisons. As a simple example, the retailer would need to know that a customer who purchased a “Whirlpool GX5FHDXVY” already had a product in the “refrigerator” hierarchy.
| Solution: | RFID tags |
| Big data type: | M2M data |
| Disciplines: | Privacy |
Organizations invest in radio frequency identification (RFID) technologies to track the movement of materials across the supply chain, from the manufacturer to the distribution center and the store. However, RFID tags can create privacy issues if they are coupled with personally identifiable information. Consider an example of a retailer that does not deactivate RFID tags at the point of sale. In this situation, another retailer might be able to scan the RFID tags if a shopper is in the proximity of their outlet, to tailor marketing messages in a manner that might violate the shopper’s privacy.
| Solution: | Personalized messaging based on facial recognition and social media |
| Big data type: | Web and social media, biometrics |
| Disciplines: | Privacy, business process integration |
A recent report from the U.S. Federal Trade Commission (FTC) reviews the potential uses of facial recognition technology in combination with social media.5 Today, retailers use facial detection software in digital signs to analyze the age and gender of viewers and deliver targeted advertisements.6 Facial detection does not uniquely identify an individual. Instead, it detects human faces and determines gender and approximate age range. In the future, digital signs and kiosks placed in supermarkets, transit stations, and college campuses could capture images of viewers and, with facial recognition software, match those faces to online identities and return advertisements based on websites that specific individuals have visited or the publicly available information contained in their social media profiles.
Retailers could also implement loyalty programs, ask users to associate a photo with the account, and then use the combined data to link the consumer to other online accounts or their in-store actions. This would enable the retailer to glean information about the consumer’s purchase habits, interests, and even movements, which could be used to offer discounts on particular products or otherwise market to the consumer. The ability of facial recognition technology to identify consumers based solely on a photograph, create linkages between the offline and online world, and compile highly detailed dossiers of information makes it especially important for companies using this technology to implement the appropriate privacy policies.
| Solution: | Customer churn analytics |
| Big data type: | Web and social media, big transaction data |
| Disciplines: | Privacy, master data integration, data quality |
Telecommunications operators build detailed customer churn models that include big transaction data such as call detail records (CDRs) and social media. However, the overall value of the churn models also depends on the quality of traditional attributes of customer master data, such as date of birth, gender, location, and income. A large operator wanted to implement a predictive analytics strategy around churn management. Analyzing subscribers’ calling patterns has empirically proved to be an effective way to predict churn. The operator decided that it needed to outsource its churn analytics to an overseas vendor. Because these CDRs needed to be shipped to the vendor on a daily basis, there was significant concern about safeguarding the privacy of customer data. After the appropriate deliberation, the operator decided to mask sensitive data such as subscriber name because the calling and receiving telephone numbers were the primary fields of value for churn analytics.
| Solution: | Location-based services |
| Big data type: | M2M data |
| Disciplines: | Privacy |
Let’s consider an example of the marketing department at a telecommunications operator that wants to unlock new sources of revenue. The marketing team wants to sell geolocation data to third parties, who can offer coupons to subscribers based on their proximity to certain retailers. However, the privacy department is concerned about the reputational and regulatory risks associated with sharing subscriber geolocation data. The big data governance program needs to balance the revenue potential from a new revenue source with the privacy risks involved.
| Solution: | Claims investigation, underwriting |
| Big data type: | Web and social media |
| Disciplines: | Privacy, business process integration |
Many insurance carriers now use social media to investigate claims. However, most regulators still do not permit insurers to use social media to set rates on policies during the underwriting process. For example, can a life insurer use the fact that an applicant’s Facebook profile indicates that she is a skydiver to increase her premiums because of her higher risk profile?
| Solution: | Vehicle telematics |
| Big data type: | M2M data |
| Disciplines: | Information lifecycle management |
An insurer instituted a pilot that offered lower rates to policyholders in exchange for the ability to place on-board sensors on motor vehicles. These sensors gathered telematics data that monitored the driving behavior of policyholders. The insurer was overwhelmed with a large amount of telematics data. It had to establish a policy regarding the retention period for the data.
| Solution: | Claims |
| processing | |
| Big data type: | Big transaction data |
| Disciplines: | Master data integration, business process integration |
Marginal improvements in claims processing and analytics can have outsized improvements on an insurer’s bottom-line. Big claims transaction data is highly dependent on high-quality reference data such as product codes, fire protection classes, and building codes. This data might be dispersed in paper format and spreadsheets. The lack of a centralized library of reference data can make it very hard to price policies and process claims because the data is in the heads of actuaries and underwriters.
| Solution: | Underwriting |
| Big data type: | Biometrics |
| Disciplines: | Privacy |
DNA splicing technology has become sufficiently commoditized that some companies now offer low-cost DNA-mapping services. The result is an explosion in the available DNA datasets, which opens up new opportunities as well as significant privacy issues. Most states in the U.S. have specific laws that govern the privacy of genetic information regarding insurance. The Association of British Insurers has announced a moratorium on the use of genetic testing for any type of insurance other than life insurance over £500,000. Above that amount, insurers will not use adverse predictive genetic test results unless the government has specifically approved the test.7
| Solution: | Geospatial and seismic analysis |
| Big data type: | M2M data |
| Disciplines: | Metadata |
Oil and gas companies have big data initiatives to analyze geospatial and seismic data to discover new energy reserves and to extend the life of existing reservoirs. However, oil and gas companies need to ensure that this data is of the appropriate quality. For example, an oil company bought the same seismic data twice from an external vendor because of inconsistent naming conventions in its internal repositories. This is a metadata challenge relating to big data governance.
| Solution: | Rig and environmental monitoring |
| Big data type: | M2M data |
| Disciplines: | Information lifecycle management |
In the past, an oil rig might have had only about 1,000 sensors, of which only about 10 fed databases that would be purged every two weeks due to capacity limitations. Today, a typical facility might have more than 30,000 sensors. Oil and gas companies also need to retain sensor data for a longer period. This information needs to be maintained well after the lifetime of the rig itself, to demonstrate adherence to environmental regulations. As a result, this information might need to be stored for 50 to 70 years, and up to 100 years in some cases. While storage is cheap, it is not free. The big data governance program needs to establish retention schedules for sensor data, and archiving policies to move information on to cheaper storage, if possible.
| Solution: | Demand Signal Repository (DSR) |
| Big data type: | Big transaction data |
| Disciplines: | Business process integration, master data integration, data quality |
Consumer packaged goods companies implement DSRs, which are business intelligence environments that capture, aggregate, and cleanse all customer-related data. DSRs support core processes such as forecasting and optimizing stock-keeping unit (SKU) level assortments, vendor managed inventory programs (where the manufacturer manages the inventory of products at the retailer), trade promotions, product development, and consumer segmentation. DSRs leverage multiple data sources, including Point of Sale Transaction Logs (POS TLogs) that represent highly granular transaction data from retailers. DSRs have to deal with multiple product data quality issues, including product descriptions and Universal Product Codes (UPCs) that are inconsistent for the same product across retailers. These data quality issues might result in inaccurate forecasts based on misleading demand signals.
| Solution: | Risk management |
| Big data type: | Web and social media (web content) |
| Disciplines: | Master data integration |
Risk management departments need to update their customer hierarchies based on up-to-date financial information. As an example, when Tata Motors acquired Jaguar, the risk management department needed to update the risk hierarchy for Tata Motors to also include any exposure to Jaguar. In another example, a bank has developed an economic hierarchy to aggregate its overall exposure to a car manufacturer, its tier-one and tier-two suppliers, and the employees of the manufacturer and its suppliers. The risk management department might want to update its economic hierarchy in the event of consolidation between suppliers. All these hierarchies depend on up-to-date financial information. The risk management department might use text analytics to crawl through unstructured financial information, such as U.S. Securities and Exchange Commission (SEC) 10-K and 10-Q filings, and U.S. Federal Deposit Insurance Corporation (FDIC) call reports to dynamically update changes in company ownership, directors, and officers within its MDM hierarchies.
| Solution: | Credit, collections |
| Big data type: | Web and social media (social media) |
| Disciplines: | Privacy |
Banks need to consider regulations such as the United States Fair Credit Reporting Act (FCRA) when using social media for credit decisions. In addition, collections departments need to adhere to regulations such as the United States Fair Debt Collection Practices Act (FDCPA), which are designed to prevent collectors from harassing debtors or infringing upon their privacy, including within social media.
| Solution: | Preventive maintenance |
| Big data type: | M2M data |
| Disciplines: | Data quality, information lifecycle management |
Sensors on a modern train record more than 1,000 different types of mechanical and electrical events. These include operational events such as “opening door” or “train is braking,” warning events such as “line voltage frequency is out of range” or “compression is low in compressor X,” and failure events such as “pantograph is out of order” or “inverter lockout.” The preventive maintenance team uses predictive models to identify events that are highly correlated with preceding events.
Consider an example where failure event 1245 is preceded by warning event 2389 in 90 percent of the cases. In that example, the operations team needs to issue a work order for preventive maintenance whenever warning event 2389 is logged in the system. If the railroad has trains in its fleet from different manufacturers, the sensor data from different trains might first need to be standardized before it can be used. If a particular part fails on one train, the operations department might want to inspect similar parts on other trains. However, that might be difficult if the same part is named differently across trains. Finally, retention of sensor data is driven by business and safety-related regulatory requirements.
| Solution: | Longitudinal data warehouse |
| Big data type: | Web and social media |
| Disciplines: | Privacy |
State governments in the U.S. are building longitudinal data warehouses with information from preschool, early learning programs, K-12 education, post-secondary education, and work force institutions to address pressing public policy questions. The source data for these so-called “P20W” data warehouses comes from a variety of agencies led by different elected officials or independent boards. Many P20W data warehouses do not always have the full post-graduation employment history for all students. The key question is whether the P20W team can use social media like LinkedIn and Facebook to update the employment status for these students. From a big data governance perspective, the P20W team will have to grapple with privacy issues that are constantly evolving.
| Solution: | Call monitoring, analytics of call center agents‘ notes |
| Big data type: | Human generated |
| Disciplines: | Master data integration, privacy |
Given intense financial pressure, customer service departments are always looking for avenues to reduce operating expenses based on specific metrics such as average handle time, self-service, and first call resolution. The customer service department might leverage text analytics on call center agents’ notes to discern specific trends such as a high percentage of calls relating to a similar complaint. The customer service department might also integrate call data with customer master data to gain insight into the following:
Customer service departments also analyze voice recordings to improve operational efficiency and to support agent training. Before using this data, customer service departments need to mask the portions of the voice recordings that contain sensitive information such as Social Security number, account number, name, and address.
| Solution: | Log analytics |
| Big data type: | M2M data |
| Disciplines: | Metadata |
IT departments are turning to big data to analyze application logs for slivers of insight that can improve the performance of systems. Because application vendors’ log files are in different formats, they need to be standardized first, before anything useful can be done with them.
| Solution: | Sentiment analysis |
| Big data type: | Web and social media |
| Disciplines: | Master data integration, data quality, privacy |
The marketing department might want to use Twitter feeds for “sentiment analysis,” to determine what users are saying about the company and its products or services. The analytics team needs to determine if, for example, references to “@Acme” and “Acme” both refer to “Acme Corporation.” Integrating sentiment analysis with a customer’s profile can also be challenging. In addition to privacy issues, the Twitter handle might reveal the user name in only 50 to 60 percent of cases. Finally, marketing might need to answer the following question, “Do we really believe that Twitter sentiment analysis is representative if users are younger and more affluent than our typical customers?”
| Solution: | Operations management |
| Big data type: | M2M data |
| Disciplines: | Metadata |
A large automotive facility makes extensive use of robots on its assembly line. The operations department at the factory would like to compare the operating performance of different robots. However, this might be difficult because the error codes generated by each robot are different, since their software versions are inconsistent.
| Solution: | Employment pre-screening |
| Big data type: | Web and social media |
| Disciplines: | Privacy |
Regulations in many jurisdictions prohibit employers from using information such as a candidate’s age, marital status, religion, race, and sexual orientation in hiring decisions. Social media such as LinkedIn, Twitter, and Facebook are rich sources of such information. If an employer prescreens a prospective employee by consulting their LinkedIn profile, Tweets, or Facebook page, it becomes problematic to prove later on that they did not use this information to discriminate against a prospective employee. As of the publication of this book, the U.S. states of Maryland, Minnesota, Illinois, Washington, Massachusetts, and New Jersey either have passed or are moving towards legislation that prohibits employers from using social media to prescreen job candidates.8 The German government drafted legislation in late 2010 to prohibit employers from screening the Facebook profiles of job candidates. Although Canada does not yet have specific legislation targeted at social media, it does have tough privacy laws and privacy commissioners at the Federal and provincial levels. Obviously, legislation, regulations, and case law governing the use of social media about employees and job candidates vary by country, state, and province and are continually evolving. Employers need to work with legal counsel to draft specific policies tailored to their unique situations.
| Solution: | Network analytics |
| Big data type: | M2M data |
| Disciplines: | Metadata |
Security Information and Event Management (SIEM) tools aggregate log data from systems, applications, network elements, and security devices across the enterprise. SIEMs correlate the aggregated information to determine if a security incident might be taking place. SIEMs then determine the origin of the security incident and apply recourse techniques to interrupt the flow of information to prevent further data leakage.
According to a report by Jon Olstik, security intelligence demands more data.9 The report mentions that early SIEMs collected event and log data and then steadily added other data sources like NetFlow, packet capture, database activity monitoring, identity, and access management. Large enterprises now regularly collect gigabytes or even terabytes of data for security intelligence, investigations, and forensics. Finally, the report indicates that many existing tools cannot meet these scalability needs and makes the case for big data technologies.
From a big data governance perspective, security professionals need to grapple with inconsistent nomenclature across network elements such as firewalls, virtual private networks, bridges, and routers from different vendors. It is highly likely that the log files from two network elements will refer to the same event using different codes. Security professionals need to normalize these event codes prior to SIEM analytics.
There are five different types of big data: web and social media, M2M, big transaction data, biometrics, and human generated. In addition, there are seven information governance disciplines: organization, metadata, privacy, data quality, business process integration, master data integration, and information lifecycle management. This chapter provides a framework so that organizations can tailor their governance programs by big data type, information governance discipline, industry, and function.

1. “An Overview of Biometric Recognition.” http://biometrics.cse.msu.edu/info.html/.
2. “Biometrics in the workplace.” Data Protection Commissioner of Ireland. http://dataprotection.ie/viewdoc.asp?DocID=244.
3. Warren, Samuel and Brandeis, Louis. “The Right to Privacy.” Harvard Law Review, Vol. IV No. 5, December 15, 1890.
4. Deutsch, Tom. “Failure Is Not a Four-Letter Word.” IBM Data Management, April 17, 2012. http://ibmdatamag.com/2012/04/failure-is-not-a-four-letter-word/.
5. Reproduced from Protecting Consumer Privacy in an Era of Rapid Change: Recommendations for Businesses and Policymakers. Federal Trade Commission report, March 2012.
6. Li, Shan and Sarno, David. “Advertisers Start Using Facial Recognition to Tailor Pitches.” Los Angeles Times, August 21, 2011. http://articles.latimes.com/2011/aug/21/business/la-fi-facial-recognition-20110821.
7. Association of British Insurers news release, April 5, 2011. http://www.abi.org.uk/Media/Releases/2011/04/Insurance_Genetics_Moratorium_extended_to_2017.aspx.
8. Stern, Joanna. “Maryland Bill Bans Employers From Facebook Passwords.” ABC News, April 11, 2012. http://abcnews.go.com/blogs/technology/2012/04/maryland-bill-bans-employers-fromfacebook-passwords/.
9. Olstik, Jon. “Insecure About Security.” February 13, 2012.