CHAPTER 11
MASTER DATA INTEGRATION
This chapter includes contributions from Crysta Anderson (IBM), David Borean (InfoTrellis), Gokula Mishra (Oracle), and Jennifer Reed (IBM).
To meet fundamental strategic objectives such as revenue growth, cost reduction, and risk management, organizations need to gain control over data that is often locked within silos across the business. The most valuable of this information—the business-critical data about customers, products, materials, vendors, and accounts—is commonly known as master data. Despite its importance, master data is often replicated and scattered across business processes, systems, and applications throughout the enterprise. Organizations are now recognizing the strategic value of master data. They are developing long-term master data management (MDM) action plans, to harness this information to drive corporate success. These include a single view of customers, materials, vendors, employees, and charts of accounts.
A master data domain refers to a specific category of information, such as customers, products, materials, vendors and accounts. Each data domain has specific attributes that need to be fit for purpose. For example, phone number is an important attribute of the customer data domain, because it is important for an enterprise to have valid contact information in case of need. There are relationships between master data domains that represent true understanding. For example, it is valuable for a bank to have a linked view of all the accounts and products for a given customer so that it can understand the total relationship to facilitate servicing, the sale of additional products, and profitability analysis. Customers, accounts and products represent master data domains that have a relationship.
There are a number of reasons why organizations should integrate big data with MDM:
- Churn management—Use insight from Twitter, Facebook, and voice transcripts to improve the predictability of customer churn models.
- Risk management—Crawl unstructured financial information such as 10-K and 10-Q reports to dynamically update changes in company ownership structures and MDM hierarchies.
- Customer segmentation—Use additional insight from social media and other sources to fine-tune customer segmentation and behavioral modeling.
- Next best offer—Identify opportunities for cross-sell and up-sell based on customer interactions with the company.
- Reduction of operating costs in the call center—Reduce the average handling time and frequency of calls by understanding the demographics of customers and their reasons for calling.
- De-duplication—It is normally the responsibility of MDM to de-duplicate master data. De-duplicated master data should be fed into the big data platform, as opposed to building another entity resolution process.
- Preference management—Customer preferences such as “do not call” and “do not email” are best managed within MDM. The big data analytics platform should use these preferences when determining the best customers to call as part of a marketing campaign.
The big data governance program needs to adopt the following best practices to align with MDM:
11.1 Improve the quality of master data to support big data analytics.
11.2 Leverage big data to improve the quality of master data.
11.3 Improve the quality and consistency of key reference data to support the big data governance program.
11.4 Consider social media platform policies to determine the level of integration with master data management.
11.5 Extract meaning from unstructured text to enrich master data .
Each best practice is discussed in detail in the rest of this chapter.
11.1 Improve the Quality of Master Data to Support Big Data Analytics
The relationship between MDM and big data is similar to MDM and data warehousing. Many organizations use MDM to cleanse data that is then fed into the data warehouse. Similarly, organizations need high-quality master data to support big data analytics. Here are some examples that justify the importance of high-quality master data to big data analytics projects:
- Materials—Consumer packaged goods companies use point of sale transaction logs from retailers to determine which products are selling at what stores. These initiatives need consistent product information from retailers so that manufacturers can compare trends across outlets.
- Assets—Organizations leverage real-time sensor data to build preventive maintenance models. These models can identify situations where event code A1234 (high vibration) is followed in 95 percent of the cases by event code B2345 (asset breakdown). The preventive maintenance models might be based on millions of rows of sensor event data from hundreds of pieces of equipment and thousands of sensors. Organizations can substantially improve the accuracy of their predictive maintenance models by standardizing asset hierarchies and naming conventions. Consider an example where the asset management system has two instances of the same pump with different names. The two pumps will generate event codes A1234 and A4567 for high vibration, and event codes B2345 and B5689 for asset breakdown. As a result, the predictive model will be unable to pool the sensor data from these assets, which will diminish its overall ability to predict breakdowns.
- Customers—Big data analytics can predict the likelihood of customer churn. For example, telecommunications operators build detailed customer churn models that include big data such as calling patterns, dropped calls, and social media. However, the overall value of the churn models also depends on traditional attributes of customer master data such as date of birth, gender, location, and income.
Case Study 11.1 discusses the importance of network master data to big data relating to performance management and location-based services at a telecommunications operator. (This case study has been blended and disguised.)
Case Study 11.1: The Importance of network master data to big data at a telecommunications carrier
A large telecommunications carrier found major data quality issues around the master data relating to its network inventory. The telecommunications carrier used separate systems for network provisioning and for network inventory management. As shown in Figure 11.1, the network field operations teams might receive a service request within the network provisioning system to upgrade a trunk line. However, this change was not always reflected in the network inventory system that was maintained by a separate team. The network inventory data then flowed into the business intelligence system. The business intelligence system still reflected the slower trunk line, so the network performance management (big data) team classified the trunk line as a bottleneck because it was listed as 300 percent utilized. To make matters worse, the capacity planning team included the trunk line on its list of planned upgrades, as well.
When this scenario was duplicated across thousands of network elements, the operator faced huge challenges. The operator would accept new customer orders because the network inventory system reflected sufficient network capacity. However, when the network technicians visited the switch, they would find that there was insufficient capacity. On the flip side, almost 40 percent of the upgrade requests that were sent to the network field operations did not actually require incremental network build.
The advent of location-based services (big data) only made matters worse. For example, the operator wanted to offer a simple child-tracking service. The child would carry a phone that transmitted his or her location to the mobile network. During school hours, parents could have peace of mind by visiting a secure location on the operator’s website to check that their children were safely at school. While the operator was confident in its ability to track the phone, it was not confident that its network topology included an accurate representation of the boundaries of every school (or other location) within its operating area. As a result, there was a distinct possibility that a parent would incorrectly believe that their child had left the property during school hours.

Figure 11.1: A conceptual view of telecommunications network data flows.
11.2 Leverage Big Data to Improve the Quality of Master Data
The master data management program can also leverage big data to improve overall data quality. Case Study 11.2 discusses some of the privacy trade-offs regarding a telecommunications operator looking to enrich customer master data with big data such as call detail records (CDRs) and geolocation data. (This case study has been disguised.)
Case Study 11.2: Big data and master data at a telecommunications operator
A telecommunications operator had wireline and mobile businesses with the following characteristics:
- Wireline—The operator had a virtual monopoly on the wireline business in the country. The wireline division had name, address, and demographic information for its customers that was of reasonably good quality.
- Mobile—The operator faced stiff competition within its mobile business. The mobile division had very sparse information for its subscribers, who mostly purchased prepaid phone cards.
Executive management at the operator wanted to improve the number of products per customer and reduce churn. However, the poor quality of mobile name and address data made it difficult to accomplish this objective.
Figure 11.2 lays out a hypothetical example of the Smith family, consisting of John and Mary (parents) and their two children Elizabeth and Maya. The family has a wireline phone in the name of John Smith. Everybody also has wireless phones using prepaid cards. The bold line shows where the operator was able to establish relationships between devices and persons. The dotted lines show where the operator did not have insight into these relationships. The wireline phone was registered to John Smith, and the operator had his name, address, gender, and date of birth. However, the operator did not have any information about the following:
- Prepaid mobile phones—The operator did not have name, address, and demographic information about the users of the prepaid phones. As a result, it was difficult to initiate cross-selling campaigns to these users.
- Householding—The operator did not have an understanding of the spouse and parent relationships.
The marketing department wanted to use the following sources of big data to enrich its customer master data repository:
- CDRs—Review calling patterns, including called party, calling party, time of day, and frequency of calls to infer relationships.
- Triangulation of data from wireless towers—Obtain an approximate location of the caller based on a triangulation from cell phone towers.
- GPS data—Not all phones were GPS-enabled and, in any case, this data would not be accurate in the case of apartments, where the residences were in close proximity.
However, the chief privacy officer was very concerned about the potential for regulatory backlash if subscribers learned that the operator was using their location data for secondary purposes. The MDM team achieved a compromise in the following manner:
- GPS data would not be used.
- Triangulation data would be used only to determine if the subscriber was within a certain radius of a wireless tower. This would serve to reduce the population subset. For example, if the total population of a city was one million but a subscriber spent the evenings near one tower, then the operator could exclude the entire population that was outside the tower radius from the householding algorithm.
- Regarding CDRs, the operator used calling patterns to infer householding relationships with a high degree of probability.
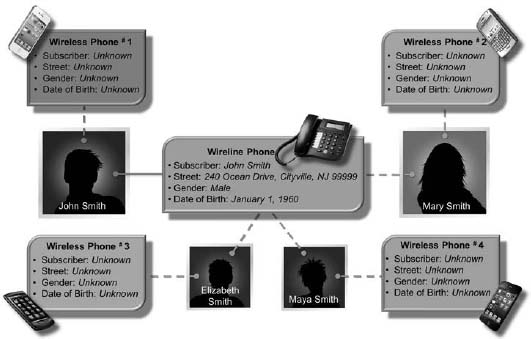
Figure 11.2: A household view of wireline and mobile phones.
Case Study 11.3 discusses how an organization used web and other data sources to improve the quality of its product master data.
Case Study 11.3: Leveraging web and other data sources to improve the quality of product master data at an information services company
An information services provider was responsible for maintaining highly granular master data about millions of consumer products. The company used a number of data sources, including product images from the web, point of sale transaction logs (POS TLogs), and store circulars, to derive a number of attributes for each item such as the following:
- Nutritional information, including ingredients and nutrition panel information that were subject to government regulations
- Marketing claims such as “kosher,” “low cholesterol,” and “no trans fats” that were derived from the front of the package and were not subject to government regulations
- Product sales information from POS TLogs
- In-store promotions from store circulars
- Sentiment analysis from blogs, magazines, and social media
The company leveraged a crawling and indexing engine to pull in structured and semi-structured content from the web. It used several vendor-provided and internally generated techniques to add meaning to unstructured content using keywords, filters, and taxonomies. Because of this initiative, the company was able to achieve the following business results:
- Increase the amount of product data that it was able to manage in-house.
- Improve the quality of sparsely populated datasets such as nutritional information where it did not receive much data from manufacturers.
- Validate product information that it received from manufacturers. For example, the company used web content to validate manufacturer-provided Universal Product Codes, which are 12-digit codes represented as barcodes on products in North America. The company also validated product attributes such as for a shampoo that was listed as “4 oz.” on the web versus “3.8 oz.” in the product master.
- Provide additional analytics to manufacturers that were not possible earlier. For example, it could answer the question, “Does retailer X advertise toothpaste from our competitors at the same time as our brands?”
- Establish causality between sentiment analysis and product sales to show, for example, that a posting by an influential blogger resulted in an increase in sales of a certain product.
11.3 Improve the Quality and Consistency of Key Reference Data to Support the Big Data Governance Program
Organizations now recognize that their reference data presents a similar set of challenges as master data. Compared to master data, reference data is relatively static and may be placed in lookup tables for reference by other applications across the enterprise. Examples of reference data include codes for countries, states, provinces, currencies, and industries. In education, reference data might include codes for courses, ethnicity, and race. Here are some examples of the importance of reference data to the big data governance program:
- ICD-9 healthcare codes—As discussed in Case Study 6.1, big claims transaction data needs a reference table of diagnoses and ICD-9 codes.
- State codes—Telecommunications CDRs include codes for 53 U.S. states, while the billing system includes codes for only 50 states.
- Currencies—One banking application uses “JPY,” while another one uses “YEN” to describe Japanese yen for financial transactions.
- School codes in education—Accurate and up-to-date school code data is necessary for the effective analysis of geolocation data from school bus systems.
- Insurance—Insurers struggle with reference data such as product codes, fire protection classes, and building codes. This data might be dispersed in paper format and spreadsheets. This lack of a centralized library of reference data can make it very hard to price policies and process claims because the data is in the heads of actuaries and underwriters.
- Consumer products—In Case Study 11.3, an information services provider maintained 28,000 unique values for color. For example, it maintained reference data to indicate that “RED,” “RD,” and “ROUGE” all referred to the same color. In addition, it used reference data to classify all the products that a particular manufacturer collectively referred to as “breakfast meals.”
- General—Case Study 9.2 discusses the use of reference data within an application that combines streaming data from motion and temperature sensors. The streaming application used reference data that room A was a classroom and room B was the boiler room. The streaming application stored temperature data every 10 minutes in Hadoop. The analytics team used Hadoop to show that the average temperature readings of the boiler room and classroom were 65 degrees at 3:00 a.m. and 75 degrees at 9:00 a.m., respectively. The application used the sensor data to generate alerts when the temperature of the boiler room rose to 75 degrees at 3:00 a.m., or the motion sensor detected movement in the classroom at 5:00 a.m.
Ideally, big data governance needs to check key reference data against a table of agreed-upon values prior to data load. A reference data steward should flag any deviations as exceptions for subsequent review.
11.4 Consider Social Media Platform Policies to Determine the Level of Integration with Master Data Management
While it might be tempting to integrate social media data with a customer master repository, the big data governance program needs to first consider privacy policies, as well as rules and regulations from social media platforms. As an example, Table 11.1 discusses Facebook’s Platform Policies (as of March 6, 2012) and the implications for master data management.
| Table 11.1: The Implications of Facebook Platform Policies on Master Data Management |
| Topic |
Relevant Facebook Platform Policies as of March 6, 2012 |
Implications for MDM |
| 1 |
A user’s friends’ data can only be used in the context of the user’s experience on your application |
Organizations cannot use data on a person’s friends outside of the context of the Facebook application (e.g., using Facebook friends to add new relationships within MDM). |
| 2 |
Subject to certain restrictions, including on transfer, users give you their basic account information when they connect with your application. For all other data obtained through use of the Facebook API, you must obtain explicit consent from the user who provided the data to us before using it for any purpose other than displaying it back to the user on your application. |
Organizations need to obtain explicit consent from the user before using any information other than basic account information (name, email, gender, birthday, current city, and the URL of the profile picture). |
| 3 |
You will not use Facebook user IDs for any purpose outside your application (e.g., your infrastructure, code, or services necessary to build and run your application). Facebook user IDs may be used with external services that you use to build and run your application, such as a web infrastructure service or a distributed computing platform, but only if those services are necessary to running your application and the service has a contractual obligation with you to keep Facebook user IDs confidential. |
Organizations need to explore if they can store Facebook user IDs within MDM. |
| 4 |
If you stop using Platform or we disable your application, you must delete all data you have received through use of the Facebook API unless: (a) it is basic account information; or (b) you have received explicit consent from the user to retain their data. |
Organizations need to be very careful about merging Facebook data with other data within their MDM environment. Consider a situation where an organization merged “married to” information from a user’s Facebook profile into their MDM system. If the organization stops using the Facebook Platform, it will need to obtain explicit permission from the user to retain this information. This can be problematic when the organization has merged Facebook data into a golden copy that has been propagated across the enterprise. |
| 5 |
You cannot use a user’s friend list outside of your application, even if a user consents to such use, but you can use connections between users who have both connected to your application. |
Similar issues to topic 1 above. |
| 6 |
You will delete all data you receive from us concerning a user if the user asks you to do so, and will provide an easily accessible mechanism for users to make such a request. We may require you to delete data you receive from the Facebook API if you violate our terms. |
Similar issues to topic 4 above. |
11.5 Extract Meaning from Unstructured Text to Enrich Master Data
MDM systems provide a 360-degree view of customers, vendors, materials, assets, and other entities. Traditional MDM systems collect structured data from a number of structured data sources. With the advent of big data, MDM projects will increasingly look to derive value from the large volumes of entity information that is hidden within unstructured text, such as social media, email, call center voice transcripts, agent logs, and scanned text. This content might reside in multiple formats, such as plain text, Microsoft Word® documents, and Adobe® PDF documents, and in different forms of storage, such as content management repositories and file systems. In Case Study 11.4, the MDM team at a hypothetical company needs to integrate email with the customer record.
Case Study 11.4: Integrating email with customer MDM
The MDM program needs to adopt the following steps to enrich master data with sources of unstructured text:
- Define the attributes for each entity that needs to be governed.
Figure 11.3 describes a simplified schema for the customer entity. It includes attributes for name, company, city, country, and email address that are commonly found in a CRM system. In this theoretical example, the master data team will use these attributes to make correlations to existing MDM records with additional content from emails.

Figure 11.3: A simplified schema for the customer entity.
- Generate a dictionary file for each attribute from the MDM repository and other sources.
The MDM team then needs to create or reuse a dictionary containing a list of all possible values. This dictionary may be generated in multiple ways. One approach would be to create the dictionary based on all the existing values for each attribute in the MDM system. Additional algorithms and annotation logic can then enhance these dictionaries. Figure 11.4 provides an example of a dictionary that was created by looking up the values for each customer attribute within MDM.

Figure 11.4: Attribute dictionaries for the customer entity.
- Annotate relevant terms based on fuzzy matching and business rules.
Figure 11.5 shows a sample intercompany email that summarizes some business discussions. The team uses text annotation techniques to locate the highlighted terms based on the dictionary. Some terms, such as “date,” are not amenable to dictionary-based annotation because there are too many different ways of writing the same date. Although date is not a key attribute in this example, a date-specific annotation algorithm or rule might be more appropriate.

Figure 11.5: A sample email with unstructured content.
- Construct a query to the MDM system that consists of the annotations from the unstructured text.
As shown in Figure 11.6, the text analytics platform issues a single MDM query based on the annotations from the unstructured text.

Figure 11.6: A single MDM query based on annotations from unstructured text.
The MDM system then returns the records shown in Figure 11.7 that were above the minimal matching threshold. Entity identifier 1 (EID 1) received a high matching score because MDM found a match on email, employer, country, and name, which have a high weighting in the matching algorithm.

Figure 11.7: An MDM system returning records above the minimal matching threshold.
- Construct a record for the unstructured entity.
The system then constructs the matching entities based on the attributes found in the document. In Figure 11.8, the system uses the email to construct a record for matching entity identifier 1 (MEID 1) as follows:
Name = “Jon Doe”
Employer = “Acme”
Country = “UK”
Email = “jdoe@acme.com”
The record also contains the following attributes to identify the source of the information, the type of document, and the strength of that association:
DOCID = “Doc1” (identifier for the specific email)
Source = “Email”
Confidence = “High”

Figure 11.8: Entities constructed by text analytics intersecting the results from MDM with the extracted terms.
- Associate newly constructed entity records with existing MDM records.
As shown in Figure 11.9, the newly constructed entity records are automatically inserted into the MDM system if the confidence level is high. On the other hand, they are automatically rejected if the confidence level is low. For records with a medium confidence level, a data steward will manually review the records to determine if they should be linked to existing MDM records.
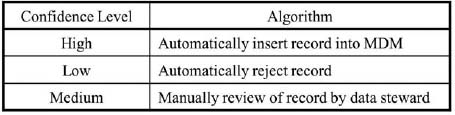
Figure 11.9: An algorithm to process the newly constructed entity records in MDM.
As shown in Figure 11.10, MDM will automatically link MEID 1 for Jon Doe in Figure 11.8 with EID 1 for John Doe in Figure 11.7. The email in Figure 11.5 will now be associated with EID 1 as well. On the other hand, MDM will automatically reject MEID 2 from Figure 11.8 because the confidence level is low. Finally, a data steward will manually review MEID 3 and MEID 5 because the confidence level is medium.
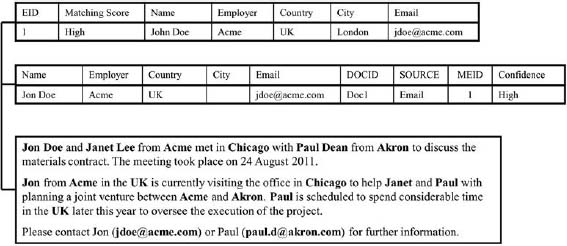
Figure 11.10: Linking matching entities and emails in MDM.
By incorporating unstructured information into MDM, the master data team can build a better view of the overall customer relationship. This can also be extremely helpful during personnel changes. In the above example, Jon Doe and Janet Lee from Acme were working with Paul Dean from Akron. If Paul Dean left Akron before completion of the contract, how would the new representative, Lucas Alexander, get an updated status on all the work that was scheduled with Acme? By enriching MDM with unstructured text such as this email, Lucas would be able to open the profile of Acme. He would see that his contacts were John Doe and Jane Lee. Looking further, he would see that there was an email related to the profile. Upon reading the text, he would know that he should follow up with Acme and let them know that he was looking forward to continuing the work they began with Paul. This would help cement the relationship between Acme and Akron, increase Akron’s retention of Acme as a client and reduce the risk of critical leads being lost due to employee turnover or the failure of Paul Dean to enter the opportunity in the lead tracking system.
There are a number of other business applications to support the integration of text analytics with MDM. For example, bank risk departments can use the integration of text analytics with MDM to update counterparty risk. The risk department at a bank can use unstructured financial information such as SEC filings to learn that the ownership of a company has changed, or that a large customer is also a director in three other companies. The risk department can use this information to update the customer hierarchies in MDM to establish an up-to-date picture of the overall exposure to a customer.
Insurance companies need accurate location information to answer questions such as “What is our overall exposure to hurricanes in Florida?” Actuaries’ catastrophic risk models are highly sensitive to the precise latitudinal and longitudinal coordinates of a property because a house on the beach will have a much higher risk than one that is only a few hundred feet inland. An insurance company with poor location master data about its policies should explore the use of text analytics to extract hidden location data within its policies and contracts, which would then enrich MDM.
Finally, text analytics is also applicable to the integration of social media like Facebook and Twitter with customer MDM.
Summary
Big data and master data are highly synergistic. Big data should use master data on customers, materials, assets, and employees. In addition, master data can be enriched based on big data such as web content, call detail records, and social media.