Case Study 19.1: The governance of smart meter data at a large water utility
A water utility serving a large metropolitan area was in the process of rolling out a wireless meter program across more than a million customers. The objective of the program was to reduce peak water usage through tiered pricing. As shown in Figure 19.1, the solution architecture for the smart meter program consisted of five tiers:
- Meter Transmission Units (MTUs)
The utility company had 800,000 MTUs in its operating area. There was one MTU per building. These units made wireless transmissions of very simple information every six hours. This information consisted of the location identifi er that was embedded in the MTU fi rmware, the timestamp, and the actual meter reading. The system generated more than three million unique meter readings per day. Each MTU could hold up to three days’ worth of meter data if the readings could not be sent upstream.
- Collection MTUs
The MTUs sent their readings to 380 collection MTUs. The system had built-in redundancy, with each MTU sending their readings to three or four collection units to ensure that no reading was ever lost.
- Data collection center
Each collection MTU sent files containing 10, 50, or 300 readings to the data collection center for collection and further processing. The data collection center consisted of eight servers that received the files from the collection MTUs. The servers parsed the files, read the MTU identifier, and used lookup tables to insert the reading into the corresponding account number in the table. Over the course of 24 hours, the data center processed upwards of one million raw data files.
- Data analysis center
Data was then propagated to the analytics environment in nightly batch mode from 1:00 a.m. to 6:00 a.m.
- Legacy billing application
The billing application was on the mainframe and contained the customer master data for account number, name, and address. Address data on the mainframe was validated against an online address standardization system. The data in the analysis center was augmented with additional attributes from the mainframe, including account number, name, address, and additional information for commercial customers. This information was presented to residential and commercial customers via the web and call center.
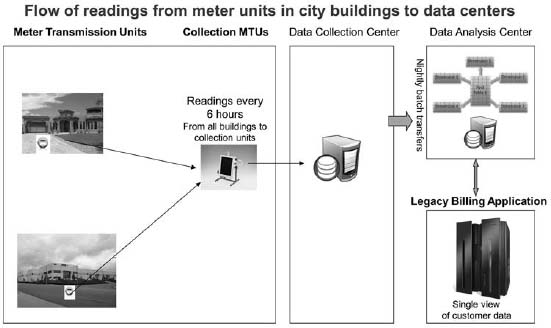
Figure 19.1: The solution architecture for the smart meter program.
The smart meter program had to deal with a number of big data governance challenges, which are described below.
19.1 Duplicate Meter Readings
- Problem:
Because each MTU sent its readings to three or to four collection points, there was a huge data redundancy problem that could cause data quality problems if not appropriately addressed.
- Solution:
The utility established a process that continuously monitored redundant readings so only a single unique reading could be inserted for each timestamp for a given building or account. During the initial phase, the application inserted a row in the table and then checked if the reading already existed in the table, by searching for duplicates. Since this approach was inefficient, the utility used an index to search for duplicates prior to inserting rows into the table.
Out of the more than 10 million raw readings, only about three million were unique. As a result, the application had to search for duplicates through a table of 270 million rows (3 million x 90 days). To improve the overall performance of the system, the utility deployed streaming analytics so that the data could be processed dynamically in real time. That way, only the unique meter readings would actually flow into the database.
19.2 Referential Integrity of the Primary Key
- Problem:
Several database tables had the timestamp of the meter reading as the primary key. This caused a violation of referential integrity because timestamps were not unique across readings from different meters. As a result, a number of rows were rejected upon insert. This, in turn, led to manual processing of these rejected rows and, ultimately, to higher maintenance costs.
- Solution:
The IT team deployed a composite key consisting of the MTU location identifier and the timestamp.
19.3 Anomalous Meter Readings
- Problem:
Even in an automated environment, a small percentage of the three million readings were bound to be incorrect. For example, a building might send the following four readings for the day: 500, 520, 600, 10,000. The last reading is likely either a mistake, a sign of a leakage, or some other serious problem.
- Solution:
The smart meter application calculated running totals and a daily average consumption for each MTU, which created a pattern of normalcy for each account. The application then checked the readings for errors or outliers. It then discarded the “erroneous” reading and used the prior reading (500, 520, 600, 600), or created an estimate based on consumption history (500, 520, 600, 630). The application would flag this calculated entry as an estimate and not as the real reading. Because the anomalies might actually be caused by water leakages, the system flagged these readings for further research if the problem persisted.
19.4 Data Quality for Customer Addresses
- Problem:
The system also had to deal with inconsistent addresses for the same customer across the billing application (mainframe) and the data collection and analysis centers (distributed).
- Solution:
The billing system on the mainframe used a live application to standardize customer addresses. In case of any inconsistencies between the customer addresses in the mainframe and distributed environments, the billing application was considered the golden copy. The billing application received only a subset of all the daily meter readings using the following business rules:
- Only the final reading of the day was used.
- Only meter readings for the billing day were recorded. For example, if out of the 800,000 accounts, only 100,000 had the current day as the billing day, only those 100,000 readings would be kept on the mainframe. The others would be discarded.
19.5 Information Lifecycle Management
- Problem:
The utility needed to archive smart meter readings so that it did not accumulate large volumes of data that hindered performance during row inserts or when running queries.
- Solution:
The utility implemented the following policies to govern the lifecycle of its meter data:
- Deletion—The data collection center continuously deleted data after 90 days.
- Partitioning—The analysis center retained data in-line for two years.
Although the analysis environment stored two years of data, the utility found that most reports only used a few months of data. The utility explored various options to partition the data by time and location, or both, to speed up queries and to reduce overhead. Ultimately, the utility partitioned the data by month, with about 30 partitions for the years 2009-2011.
- Archiving—The utility implemented an archiving strategy for data in the analysis center that was older than two years. The requirements for archiving included the ability to query both archived and non-archived data in combination, if needed.
19.6 Database Monitoring
- Problem:
There have been several newspaper reports of the potential privacy threats posed by smart meters. For example, smart meter data could possibly tell an observer everything a subscriber does in his or her home, down to how often microwave dinners are eaten, how often towels are washed, and even what brand of washer-dryer they’re washed in.1
- Solution:
As part of the overall roadmap, the utility planned to establish policies to monitor access to the smart meter data by privileged users such as database administrators.
19.7 Technical Architecture
The proposed technical architecture for the smart meter project is shown in Figure 19.2. Key components of this technical architecture are described in the following pages.

Figure 19.2: The to be technical architecture for a utility smart meter program.
Real-Time Data Processing
It was more efficient to process the meter readings in-flight between the collection units and the data collection center. The utility deployed IBM InfoSphere® Streams to process millions of semi-structured meter readings in flight and to do the following:
- Resolve millions of duplicate records
- Locate anomalies and correct them with the proper estimates
- Process running averages
- Identify water usage patterns
- Identify water shortage patterns
- Identify problems and leakages
- Predict shortages, and proactively redirect resources from other sources, to address potential issues during peak consumption times
Data Warehousing for Analytical Data and Reporting
After the data was cleansed and de-duplicated, the historical and aggregated data had to be stored in the right data model for reporting and analytical purposes. The utility selected IBM Netezza® for its analytical warehouse to support audit activities, respond to advocacy groups regarding water shortages, analyze consumption patterns, conduct financial analyses, and report on customer consumption patterns.
Data Archiving
The utility in the case study deployed archiving technology to lower storage, hardware, and maintenance costs and improve system performance by ensuring that queries would run against smaller datasets. The utility selected IBM InfoSphere Optim™ Data Growth as its archiving platform. The applications could still access current and archived data using reports, ODBC/JDBC connectors, relational databases, and even Microsoft Excel®. The applications team had to treat the data as complete business objects. For example, it had to archive not only a set of rows, but also the entire database structure related to those rows that had business relevance. So, a set of meter readings might be archived together with the billing information, historical trends and patterns, and other relevant customer data.
As part of its roadmap, the utility wanted to establish multiple archiving tiers. For example, a set of data that was three to five years old could be on faster storage, data that was five to ten years old could be on less expensive storage, and older data could be archived to tape, compact disc, or optical storage devices. Native application access was generally most useful in the first two to three years of the information management lifecycle, while archived data was being used mainly for historical trends. Older data was necessary for legal discovery requests.
