7 DeepDream: How Alexander Mordvintsev Excavated the Computer’s Hidden Layers
Whatever you see there, I want more of it.
—Alexander Mordvintsev1
Early in the morning on May 18, 2015, Alexander Mordvintsev made an amazing discovery. He had been having trouble sleeping. Just after midnight, he awoke with a start. He was sure he’d heard a noise in the Zurich apartment where he lived with his wife and child. Afraid that he hadn’t locked the door to the terrace, he ran out of the bedroom to check if there was an intruder. All was fine; the terrace door was locked, and there was no intruder. But as he was standing in his living room, suddenly he “was surrounded by dozens of very beautiful ideas. That beautiful moment occurred when one idea crystallizes to a point where you can start programming.”2 It all came together. In an instant he saw what everyone else had missed. He sat down straightaway at his computer and began to type lines of code.
Up until then, artificial neural networks had been our servants, dutifully performing the tasks we asked them to perform, becoming steadily better at serving us. They definitely worked, but no one quite knew how. Mordvintsev’s adventure that night was to transform completely our conception of what computers were capable of. His great idea was to let them off the leash, see what happened when they were given a little freedom, allowed to dream a little. He let loose the computer’s inner workings, tapped into their mysterious hidden layers. Who would have guessed that they would throw up wild images not a million miles from van Gogh’s Starry Night?
Mordvintsev comes across as focused, intense. He’s more relaxed when he recalls his childhood, growing up in St. Petersburg. Mordvintsev graduated in 2010 from Saint Petersburg State University of Information Technologies, Mechanics, and Optics with a master’s in computer science, then went to work for a company specializing in marine-training simulators, using computers to model biological systems—in this case, coral reefs. Assigned to a computer vision group, he quickly became fascinated with the field. Computer vision is all about reinventing the eye, teaching computers to see, developing computers that can understand digital and audio images—that is, pictures and sound. “I spent a beautiful year on machine algorithms and was amazed at the machine’s ability to track faces,” he tells me.3
When Mordvintsev’s first child was born, he and his wife decided that big cities were not the place for children. It was then that he received a call from a Google recruiter in Zurich, offering him a job there.
On arrival, he was worried. There were not many teams that did computer vision, and he was “a computer vision guy.”4 Worse, he was assigned to a team specializing in SafeSearch, preventing spam and porn from infecting search results. Nevertheless, he had the chance to wander around Google. Chatting to his fellow workers, Mordvintsev was struck by the power of deep neural networks. Previously he had been skeptical, but now he was in a place with access to huge data caches and the most up-to-date machines. He realized how deep neural networks could “really shine,” as he puts it, and he began to look into how convolutional neural networks (ConvNets) function.
* * *
Neural networks are designed to mimic the brain. Our brains are made up of at least one hundred billion interconnected nerve cells (neurons), linked by a barely understood thicket of one hundred trillion connections. For us to see, the neurons in our brains pick up the images we receive on our retinas and give them shape and meaning. The process of creating an image out of a jumble of visual impressions begins in the primary visual cortex, which identifies lines and edges. This basic sketch is passed—like an assembly line in a factory—to the regions of the brain, which fill in the shape, spot shadows, and build up noses, eyes, and faces. The final image is put together using information from our memories and from language, which helps us categorize and classify images into, for example, different types of dogs and cats.
Artificial neural networks are designed to replicate the activities of the brain and to cast light on how the brain works. Convolutional neural networks are a specialized form devoted mainly to vision, able to recognize objects and spot patterns in data. The neurons are arranged in a similar way as in the eye. ConvNets have up to thirty layers, each made up of many thousands of artificial neurons, which is why they are called deep neural networks. The neurons in each layer are able to detect signals but are much less complex than the brain’s nerve cells. The number of neurons and connections in a ConvNet is tiny in comparison to the number of nerve cells and connections in the human brain. For now, artificial neural networks are more akin to the brain of a mouse. But the assembly line process by which the machine recognizes an image is similar to the way in which we see.
* * *
To train a ConvNet, you feed in millions of images from a database such as ImageNet, made up of over fourteen million URLs of images, annotated by hand to specify the content. The network’s adjustable parameters—the connections between the neurons—are tuned until it has learned the classifications so that when it is shown an image of, for example, a particular breed of dog, it recognizes it.
When you then show it an image and ask it to identify it, the ConvNet works in a similar way to the human brain. First the early layers pick out lines in the map of the pixels that make up the image. Each layer in succession picks out more and more details, building up parts of faces, cars, pagodas, whatever images it has inside its memory. The deeper you go, the more abstract the information gets. Finally, in the last layer, all the results of analyzing features in the pixels are assembled into the final image, be it a face, a car, a dog, or any of the millions of images that the neural net was trained on.
The crucial point is that the machine does not see a cat or dog, as we do, but a set of numbers. The image is broken up into pixels. Each pixel is represented by numbers that give its color on a red, green, and blue scale and its position. In other words, it’s numbers all the way down. In the first layer, a filter illuminates areas of the pixel map one at a time, seeking out lines and edges, convolving—hence the term convolutional neural network. Then it transmits this primitive sketch to the next layer. The filters operate in the same way in each layer to clarify and identify the target image.
Finally, the last layer comes up with probabilities of what the image actually is. If the network has been asked to identify a dog, the conclusion might be 99.99 percent probability that it’s a dog, with as many low probabilities for it being a cat, a lion, or a car as there are classes in the data it’s been trained on.
Before deep neural networks, the filters in each of the layers had to be hand-engineered, a formidable task. In ConvNets, they emerge as a natural consequence of training.
* * *
One of the first successes of artificial neural networks was to read the numbers on checks. Now they can recognize faces, find patterns in data, and power driverless cars. Most scientists were satisfied to leave it at that. The unasked question was, What is the machine’s reasoning? What occurs in the layers of neurons between the input layer that receives the image to be identified and the output layer where the solution emerges? These are the hidden layers, so called because they are neither input nor output; they are inside the machine. Mordvintsev became obsessed with finding out not only why ConvNets worked so well but why they worked at all, how they reasoned, what goes on in the hidden layers.
He set to work even though this problem was not part of his official duties, which related to SafeSearch. Google has a policy of allowing its engineers to spend up to 20 percent of their time, or one day a week, on some other Google-related project. Researchers, of course, can’t just turn their minds on and off. The passion of your inquiry stays with you, either in your conscious or, more likely, unconscious.
A team from Oxford University had published papers that provided clues as to how best to proceed. They explained that when the computer was being fed with images, the pixels that made up the image were converted into numbers. To investigate how the ConvNet worked, the researchers stopped the process part way into the hidden layers and made the network generate an image of what it could see right then. They were trying to find out what the network saw, what was going on inside its “brain.” They discovered that the images in the various layers, though blurry, still resembled the target image.5
Following the same lines, Mordvintsev was sure the hidden layers were not just black boxes, taking in data and producing results. He saw them as “transparent but very very obscure.”6 And that was when, not long after midnight on that early May morning, everything suddenly fell into place. Mordvintsev sat down and wrote the code that encapsulated his breakthrough, enabling him to explore “how a neural network works layer by layer.”
Ideas sometimes emerge at the strangest of times, as when French mathematician, philosopher, and scientist Henri Poincaré was stepping up into an omnibus and suddenly realized the solution to a problem that he had been struggling with. For Poincaré, unconscious thought, primed by conscious thought, was the key to the creative moment, the moment of illumination.7 And so it was for Mordvintsev.
Instead of looking at what features of the original image are contained in a particular layer and then generating those features in the form of pixels to produce an approximate impression of the original image, as the Oxford team had done, Mordvintsev did the reverse. He fed an image into a ConvNet that had been trained on the ImageNet data, but stopped the forward progress part way through. In other words, he stepped on the brakes. When the network was still in the middle of trying to verify a nascent sense that a particular pattern might be a target object, he told it to generate it right then and there.
The intermediate layers in a network are made up of many thousands of interconnected neurons containing a bit of everything the network has been trained on—in this case, the ImageNet dataset with lots of dogs and cats. If the target image has, for example, even a hint of dog in it, the relevant artificial neuron in that layer will be stimulated to emphasize the dogness. Then you reverse the process repeatedly back and forth and see what emerges. As Mordvintsev puts it, “Whatever you see there, I want more of it.”8 Google engineers refer to this as “brain surgery.”9 Whereas the Oxford group tried to reconstruct the original image, Mordvintsev’s great idea was to keep the strengths of the connections between the neurons fixed and let the image change. As he put it modestly: “There were many suggestions about understanding neural networks. Mine was very practical.”
So much for theory. But what happened in practice?
The first image that Mordvintsev used was of a cat and a beagle (see figure 7.1).

Mordvintsev’s reference image of a cat and a beagle, 2015.
Normally, if you fed this through the machine, it would identify both the cat and the dog, having been trained on ImageNet with its images of 118 breeds of dog plus several cats. Mordvintsev fed in just the cat portion of the image and stopped part way through the hidden layers, bursting with neurons containing a mash-up of dog and cat features, as well as whatever else is in ImageNet. The result of passing this image through several times was the nightmare beast shown in figure 7.2. Nothing like it had ever been seen—a thing with two sets of eyes on its head and another set on its haunches, and eyes and canine attributes bursting out all over its body: not entirely surprising, as the network had been trained more on dogs than cats. The background too had been transformed into complex geometric patterns, with a couple of spiders bursting through. It seems the machine saw spiders there, even though we hadn’t. It was a vision of the world through the eyes of the machine.

Alexander Mordvintsev, nightmare beast created using DeepDream, 2015. [See color plate 1.]
Mordvintsev sat up until 2:00 a.m. writing a report full of images like that of the cat. He applied his algorithm at multiple scales, producing big and small cat-like creatures simultaneously, producing images with fractal properties and a look that can only be called psychedelic. The crucial point is that the machine was producing images that were not programmed into it.
Our human perceptual system behaves in a similar way, making us “see” things that aren’t really there, like the face on the moon or pictures in clouds or the happy face in the Galle crater on Mars, an illusion called pareidolia. The dream-like images generated by Mordvintsev’s algorithm were almost hallucinogenic, startlingly akin to those experienced by people on LSD. Did that mean that an artificial neural net was not that artificial? Could we say that Mordvintsev had found a way to look into the machine’s unconscious, into its inner life, its dreams? Certainly he’d found a way to plumb its hidden layers.
Finally, Mordvintsev posted several of his images on an internal Google website, assuming that no one would notice them for a while. “I was wondering how to get back to sleep,” he recalls.10
But the sun never sets on Google. It was late afternoon in Mountain View, California, and Google headquarters was in full swing. Mordvintsev’s images went viral. The unknown engineer from the innocuous SafeSearch team in Zurich received rave reviews and soon after was snapped up by the Google machine-learning team in Seattle.
Mike Tyka Takes the Dream Deeper
I’m a computationalist and I believe the brain is a computer, so obviously computers can be creative.
—Mike Tyka11
One of the first to spot Mordvintsev’s post was Mike Tyka, a software engineer at Google’s Seattle office. At first, Tyka and Mordvintsev dubbed it inceptionism, after Christopher Nolan’s 2010 movie Inception, starring Leonardo DiCaprio, about a technology capable of inserting people into other people’s dreams, akin to plumbing the hidden layers of a machine. Then Tyka came up with the name DeepDream. “We had to call it something,” he tells me.
Mordvintsev’s images catalyzed Tyka. Normally, you don’t explicitly program a deep neural network, so “you don’t know how it works. Alex [Mordvintsev] looked for ways to visualize the knowledge in a trained neural net,” he explains. “At that time most people seemed not to be interested in those sorts of problems.”12
Tyka is an authority on neural networks. Long-haired, bearded, and amiable, dressed in a regulation black t-shirt, he never studied art but was attracted to the demoscene and fascinated by the possibilities of electronically generating graphics and text, not realizing that this was “basically art.”13 Tyka’s father, none too happy about his son’s artistic interests and concerned about his future, recommended that he study science. At the University of Bristol, Tyka studied biotechnology and biochemistry and soon after found himself at Google, using neural networks to study protein folding, the process by which proteins come together to form organs in the earliest phases of the embryo.
But he still wanted to become an artist. His studies of the forms that emerge in protein folding inspired him to create copper and glass sculptures. I spoke with Tyka by Skype in March 2017 about his work developing DeepDream. “So you’ve finally succeeded in combining art, science and technology?” I asked him. “Sure, I try all the time,” Tyka replied.14
For Tyka, it was the fractal nature of Mordvintsev’s images that made them so compelling.15 This came from Mordvintsev scaling and rescaling them, compounding images, producing weird, psychedelic effects.
Not surprisingly, the public relations people at Google were wary of publishing Mordvintsev’s images. After all, they queried, “Are people really going to be interested in this?”16 But then they realized that somebody was going to leak them. And indeed, on July 16, 2015, two months after Mordvintsev’s initial discovery, someone posted the soon-to-be-famous “dogslug cum puppyslug,” as everyone called it, anonymously (see figure 7.3).

“Dogslug cum puppyslug” created using DeepDream, 2015.
Reactions ranged from “looks like a bad dream” to “this thing can see into the abyss.” In response, Tyka, Mordvintsev, and another software engineer, Chris Olah, wrote a blog post entitled “Inceptionism: Going Deeper into Neural Networks.”17
As an artist, Tyka realized that this could be “a great tool to make interesting art.”18 Following Mordvintsev’s method, he tried feeding a photograph of an ibis into the system, reversing it as Mordvintsev suggested, stopping at an early layer. He expected the network to enhance lines because the earlier layers only pick up lines and edges. This is more or less what happened, as in the right-hand image in figure 7.4, in which linear patterns have developed.
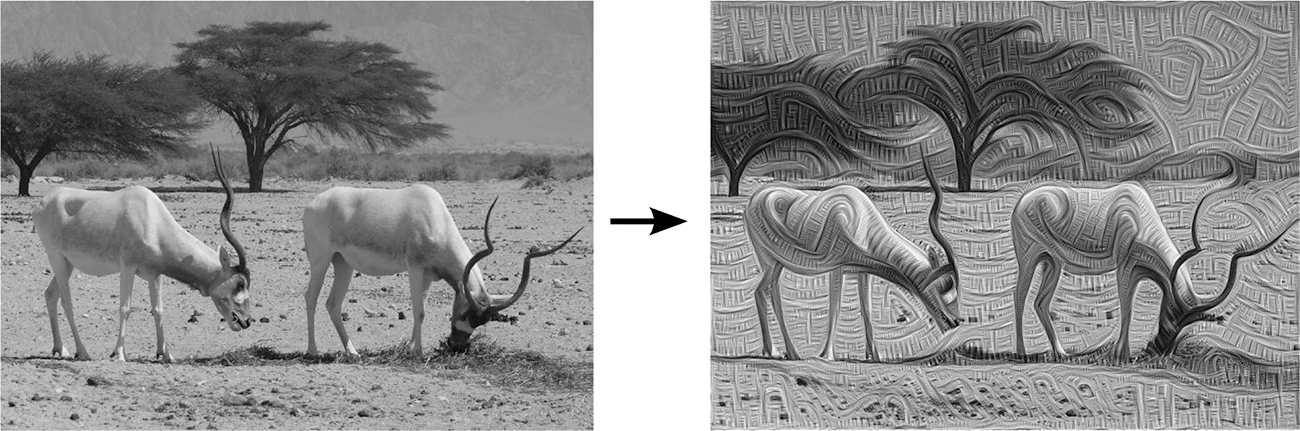
Two ibises—the original photograph (left) and as “seen” by a machine, 2015 (right).
Pushing the image further in touches on layers that seek out more complex information, producing abstractions and creating psychedelic effects. Indeed, if you put in a photograph of yourself and stop at an intermediate layer, and the machine detects dog-like features, it will turn you into a weird dog-like creature, as if it were hallucinating when it looked at you.
Tyka arranged for Mordvintsev’s code to be shared within Google. It was soon shared externally as well on GitHub, a web-based repository for code. Tyka then went one step further. Up until now, scientists had studied DeepDream by putting in photographs in the form of JPGs. Tyka fed in a much less clearly defined image of a sky with clouds, then stopped the network at an interior layer, allowing the machine to tweak the image, bringing out any faint resemblances it happened to spot with parts of images in the ImageNet data it already had in its memory—dogs, cats, cars, pagodas, whatever. As Mordvintsev had put it, “Whatever you see, give me more.”
Leonardo da Vinci’s advice to students who had difficulty in finding something to paint was to look at the wall. “See that splotch? Stare at it for a while. What do you see?” Similarly, he advised them to look at clouds. This is precisely what Tyka had the machine do.
If we look hard at the top image in figure 7.5, we might be able to make out some bird-like features. The machine, which has been trained to recognize birds, spots them too. The machine’s bird neurons in that intermediate layer activate and firm up the image. But this layer is not deep enough into the machine for recognizable birds to appear. Other neurons also activate, creating other shapes, and weird, bird-like creatures appear. Tyka continued to run the photograph backward and forward again, always stopping at the same layer, further embellishing the image each time, rendering it increasingly psychedelic.

Picture of clouds before (top) and after (bottom) being transformed by DeepDream, 2015.
But Tyka wanted to go a step further yet. Was there a way to use DeepDream to produce something completely new rather than simply embellishing images? He decided to input “noise,” a collection of random dots, and let the machine look for what wasn’t really there. He passed the image back and forth, stopping at a layer deep inside, letting the machine run through its repertoire of images as it tried to detect resemblances to them. Was there any way he could enhance this technique? The critical idea came to him at 2:00 a.m.19 He concentrated on one segment of the image the machine had spawned and magnified it, zoomed in on it. In fact, he zoomed in and then zoomed out, intermittently cropping the image, revealing structures within structures. “Zoom is compelling,” he says, “because of the fractal features that start to appear as a result of the network having only a finite amount of imagery it knows about.” Soon you have a strange conglomeration of animals, reptiles, lizards, cars, bicycles, stretching to infinity, “all the way down.”20 Tyka’s extraordinary, ever-changing video holds audiences spellbound.21
Tyka tells me, “I’m a computationalist and I believe the brain is a computer—so of course machines can be creative.”22 Furthermore, he says, when the Go grand master Lee Se-dol played AlphaGo and described its moves as beautiful, he was acknowledging its creativity.
He shares this computational view of creativity with his colleague at Google’s Seattle office, Blaise Agüera y Arcas, who says: “As a computational neuroscientist I am sure that there is nothing spooky going on in the brain.”23 Convolutional neural networks, modeled on our visual system, can help us understand how we make sense of the world by turning incoming perceptions into knowledge. In other words, they can help us understand our brains better—the reverse of what was intended.