“The power to guess the unseen from the seen, to trace the implications of things, to judge the whole piece by the pattern … this cluster of gifts may almost be said to constitute experience.”
Henry James, Jr. (1843-1916) — English Author
This chapter presents four patterns that describe how to initiate, receive, demultiplex, dispatch, and process events in networked systems: Reactor, Proactor, Asynchronous Completion Token, and Acceptor-Connector.
Event-driven architectures are becoming pervasive in networked software applications. The four patterns in this chapter help to simplify the development of flexible and efficient event-driven applications. The first pattern can be applied to develop synchronous service providers:
It is the responsibility of a designated component, called reactor, not an application, to wait for indication events synchronously, demultiplex them to associated event handlers that are responsible for processing these events, and then dispatch the appropriate hook method on the event handler. In particular, a reactor dispatches event handlers that react to the occurrence of a specific event. Application developers are therefore only responsible for implementing concrete event handlers and can reuse the reactor’s demultiplexing and dispatching mechanisms.
Although the Reactor pattern is relatively straightforward to program and use, it has several constraints that can limit its applicability. In particular it does not scale to support a large number of simultaneous clients and/or long-duration client requests well, because it serializes all event handler processing at the event demultiplexing layer. The second pattern in this chapter can help alleviate these limitations for event-driven applications that run on platforms that support asynchronous I/O efficiently:
In the Proactor pattern, application components—represented by clients and completion handlers—are proactive entities. Unlike the Reactor pattern (179), which waits passively for indication events to arrive and then reacts, clients and completion handlers in the Proactor pattern instigate the control and data flow within an application by initiating one or more asynchronous operation requests proactively on an asynchronous operation processor.
When these asynchronous operations complete, the asynchronous operation processor and and a designated proactor component collaborate to demultiplex the resulting completion events to their associated completion handlers and dispatch these handlers’ hook methods. After processing a completion event, a completion handler may initiate new asynchronous operation requests proactively.
The remaining two design patterns in this chapter can be applied in conjunction with the first two architectural patterns to cover a broader range of event-driven application concerns.
The next pattern is particularly useful for optimizing the demultiplexing tasks of a Proactor (215) implementation, because it addresses an important aspect of asynchronous application design:
The final pattern in this chapter is often used in conjunction with the Reactor (179) pattern for networking applications:
All four patterns presented in this chapter are often applied in conjunction with the patterns presented in Chapter 5, Concurrency Patterns. Other patterns in the literature that address event handling include Event Notification [Rie96], Observer [GoF95], and Publisher-Subscriber [POSA1].
The Reactor architectural pattern allows event-driven applications to demultiplex and dispatch service requests that are delivered to an application from one or more clients.
Dispatcher, Notifier
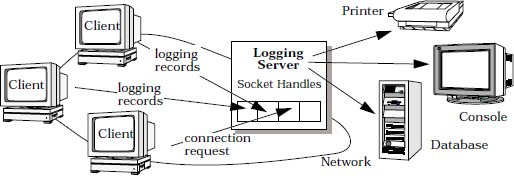
Consider an event-driven server for a distributed logging service. Remote client applications use this logging service to record information about their status within a distributed system. This status information commonly includes error notifications, debugging traces, and performance diagnostics. Logging records are sent to a central logging server, which can write the records to various output devices, such as a console, a printer, a file, or a network management database.
Clients communicate with the logging server using a connection-oriented protocol, such as TCP [Ste98]. Clients and the logging service are thus bound to transport endpoints designated by full associations consisting of the IP addresses and TCP port numbers that uniquely identify clients and the logging service.
The logging service can be accessed simultaneously by multiple clients, each of which maintains its own connection with the logging server. A new client connection request is indicated to the server by a CONNECT event. A request to process logging records within the logging service is indicated by a READ event, which instructs the logging service to read new input from one of its client connections. The logging records and connection requests issued by clients can arrive concurrently at the logging server.
One way to implement a logging server is to use some type of multi-threading model. For example, the server could use a ‘thread-per-connection’ model that allocates a dedicated thread of control for each connection and processes logging records as they arrive from clients. Using multi-threading can incur the following liabilities, however:
These drawbacks can make multi-threading an inefficient and overly-complex solution for developing a logging server. To ensure adequate quality of service for all connected clients, however, a logging server must handle requests efficiently and fairly. In particular, it should not service just one client and starve the others.
An event-driven application that receives multiple service requests simultaneously, but processes them synchronously and serially.
Event-driven applications in a distributed system, particularly servers,1 must be prepared to handle multiple service requests simultaneously, even if those requests are ultimately processed serially within the application. The arrival of each request is identified by a specific indication event, such as the CONNECT and READ events in our logging example. Before executing specific services serially, therefore, an event-driven application must demultiplex and dispatch the concurrently-arriving indication events to the corresponding service implementations.
Resolving this problem effectively requires the resolution of four forces:
Synchronously wait for the arrival of indication events on one or more event sources, such as connected socket handles. Integrate the mechanisms that demultiplex and dispatch the events to services that process them. Decouple these event demultiplexing and dispatching mechanisms from the application-specific processing of indication events within the services.
In detail: for each service an application offers, introduce a separate event handler that processes certain types of events from certain event sources. Event handlers register with a reactor, which uses a synchronous event demultiplexer to wait for indication events to occur on one or more event sources. When indication events occur, the synchronous event demultiplexer notifies the reactor, which then synchronously dispatches the event handler associated with the event so that it can perform the requested service.
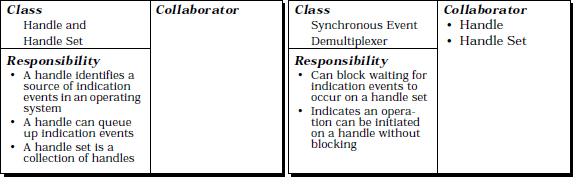
There are five key participants in the Reactor pattern:
Handles are provided by operating systems to identify event sources, such as network connections or open files, that can generate and queue indication events. Indication events can originate from external sources, such as CONNECT events or READ events sent to a service from clients, or internal sources, such as time-outs. When an indication event occurs on an event source, the event is queued on its associated handle and the handle is marked as ‘ready’. At this point, an operation, such as an accept() or read(), can be performed on the handle without blocking the calling thread.
 Socket handles are used in the logging server to identify transport endpoints that receive CONNECT and READ indication events. A passive-mode transport endpoint and its associated socket handle listen for CONNECT indications events. The logging server then maintains a separate connection, and thus a separate socket handle, for each connected client.
Socket handles are used in the logging server to identify transport endpoints that receive CONNECT and READ indication events. A passive-mode transport endpoint and its associated socket handle listen for CONNECT indications events. The logging server then maintains a separate connection, and thus a separate socket handle, for each connected client.
A synchronous event demultiplexer is a function called to wait for one or more indication events to occur on a set of handles—a handle set. This call blocks until indication events on its handle set inform the synchronous event demultiplexer that one or more handles in the set have become ‘ready’, meaning that an operation can be initiated on them without blocking.
select() is a common synchronous event demultiplexer function for I/O events [Ste98] supported by many operating systems, including UNIX and Win32 platforms. The select() call indicates which handles in its handle set have indication events pending. Operations can be invoked on these handles synchronously without blocking the calling thread.
An event handler specifies an interface consisting of one or more hook methods [Pree95] [GoF95]. These methods represent the set of operations available to process application-specific indication events that occur on handle(s) associated with an event handler.
Concrete event handlers specialize the event handler and implement a specific service that the application offers. Each concrete event handler is associated with a handle that identifies this service within the application. In particular, concrete event handlers implement the hook method(s) responsible for processing indication events received through their associated handle. Any results of the service can be returned to its caller by writing output to the handle.
The logging server contains two types of concrete event handlers: logging acceptor and logging handler. The logging acceptor uses the Acceptor-Connector pattern (285) to create and connect logging handlers. Each logging handler is responsible for receiving and processing logging records sent from its connected client.

A reactor defines an interface that allows applications to register or remove event handlers and their associated handles, and run the application’s event loop. A reactor uses its synchronous event demultiplexer to wait for indication events to occur on its handle set. When this occurs, the reactor first demultiplexes each indication event from the handle on which it occurs to its associated event handler, then it dispatches the appropriate hook method on the handler to process the event.

Note how the structure introduced by the Reactor pattern ‘inverts’ the flow of control within an application. It is the responsibility of a reactor, not an application, to wait for indication events, demultiplex these events to their concrete event handlers, and dispatch the appropriate hook method on the concrete event handler. In particular, a reactor is not called by a concrete event handler, but instead a reactor dispatches concrete event handlers, which react to the occurrence of a specific event. This ‘inversion of control’ is known as the Hollywood principle [Vlis98a].
Application developers are thus only responsible for implementing the concrete event handlers and registering them with the reactor. Applications can simply reuse the reactor’s demultiplexing and dispatching mechanisms.
The structure of the participants in the Reactor pattern is illustrated in the following class diagram:

The collaborations in the Reactor pattern illustrate how the flow of control oscillates between the reactor and event handler components:
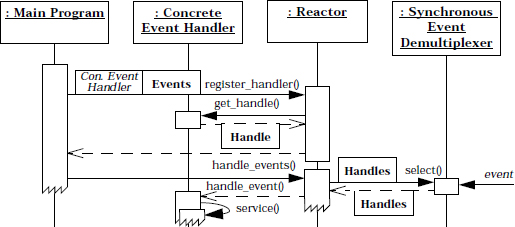
The participants in the Reactor pattern decompose into two layers:
The implementation activities in this section start with the generic demultiplexing/dispatching infrastructure components and then cover the application components. We focus on a reactor implementation that is designed to demultiplex handle sets and dispatch hook methods on event handlers within a single thread of control. The Variants section describes the activities associated with developing concurrent reactor implementations.
The Adapter pattern [GoF95] can be employed to support both objects and pointers to functions simultaneously. For example, an adapter could be defined using an event handler object that holds a pointer to an event handler function. When the hook method was invoked on the event handler adapter object it could automatically forward the call to the event handler function that it encapsulates.
We specify a C++ abstract base class that illustrates the single-method interface. We start by defining a useful type definition and enumeration literals that can be used by both the single-method and multi-method dispatch interface strategies:
typedef unsigned int Event_Type;
enum {
// Types of indication events.
READ_EVENT = 01, // ACCEPT_EVENT aliases READ_EVENT
ACCEPT_EVENT = 01, // due to <select> semantics.
WRITE_EVENT = 02, TIMEOUT_EVENT = 04,
SIGNAL_EVENT = 010, CLOSE_EVENT = 020
// These values are powers of two so
// their bits can be “or’d” together efficiently.
};
Next, we implement the Event_Handler class:
class Event_Handler { // Single-method interface.
public:
// Hook method dispatched by <Reactor> to handle
// events of a particular type.
virtual void handle_event (HANDLE handle, Event_Type et) = 0;
// Hook method that returns the I/O <HANDLE>.
virtual HANDLE get_handle () const = 0;
protected:
// Virtual destructor is protected to ensure
// dynamic allocation.
virtual ~Event_Handler ();
};
The single-method dispatch interface strategy makes it possible to support new types of indication events without changing the class interface. However, this strategy encourages the use of C++ switch and if statements in the concrete event handler’s handle_event() method implementation to handle a specific event, which degrades its extensibility.
The following C++ abstract base class illustrates the multi-method interface:
class Event_Handler {
public:
// Hook methods dispatched by a <Reactor> to handle
// particular types of events.
virtual void handle_input (HANDLE handle) = 0;
virtual void handle_output (HANDLE handle) = 0;
virtual void handle_timeout (const Time_Value &) = 0;
virtual void handle_close (HANDLE handle,
Event_Type et) = 0;
// Hook method that returns the I/O <HANDLE>.
virtual HANDLE get_handle () const = 0;
};
Both the single-method and multi-method dispatch interface strategies are implementations of the Hook Method [Pree95] and Template Method [GoF95] patterns. Their intent is to provide well-defined hooks that can be specialized by applications and called back by lower-level dispatching code. This allows application programmers to define concrete event handlers using inheritance and polymorphism.
To shield applications from complex and non-portable demultiplexing and dispatching operating system platform mechanisms, the Reactor pattern can use the Bridge pattern [GoF95]. The reactor interface corresponds to the abstraction participant in the Bridge pattern, whereas a platform-specific reactor instance is accessed internally via a pointer, in accordance with the implementation hierarchy in the Bridge pattern.
The reactor interface in our logging server defines an abstraction for registering and removing event handlers, and running the application’s event loop reactively:
class Reactor {
public:
// Methods that register and remove <Event_Handler>s
// of particular <Event_Type>s on a <HANDLE>.
virtual void register_handler
(Event_Handler *eh, Event_Type et) = 0;
virtual void register_handler
(HANDLE h, Event_Handler *eh, Event_Type et) = 0;
virtual void remove_handler
(Event_Handler *eh, Event_Type et) = 0;
virtual void remove_handler
(HANDLE h, Event_Type et) = 0;
// Entry point into the reactive event loop. The
// <timeout> can bound time waiting for events.
void handle_events (Time_Value *timeout = 0);
// Define a singleton access point.
static Reactor *instance ();
private:
// Use the Bridge pattern to hold a pointer to
// the <Reactor_Implementation>.
Reactor_Implementation *reactor_impl_;
};
A typical reactor interface also defines a pair of overloaded methods, which we call register_handler(), that allow applications to register handles and event handlers at run-time with the reactor’s internal demultiplexing table described in implementation activity 3.3 (193). In general, the method for registering event handlers can be defined using either or both of the following signatures:
The following code fragment illustrates how double-dispatching is used in the register_handler() implementation:
void Select_Reactor_Implementation::register_handler
(Event_Handler *event_handler,
Event_Type event_type) {
// Double-dispatch to obtain the <HANDLE>.
HANDLE handle = event_handler->get_handle ();
// …
}
Both types of registration methods store their parameters into the appropriate demultiplexing table, as indicated by the handle.
The reactor interface also defines two other overloaded methods, which we call remove_handler(), that can be used to remove an event handler from a reactor. For example, an application may no longer want to process one or more types of indication events on a particular handle. These methods remove the event handler from a reactor’s internal demultiplexing table so that it is no longer registered for any types of indication events. The signatures of the methods that remove an event handler can be passed either a handle or an event handler in the same way as the event handler registration methods.
The reactor interface also defines its main entry point method, which we call handle_events(), that applications can use to run their reactive event loop. This method calls the synchronous event demultiplexer to wait for indication events to occur on its handle set. An application can use the timeout parameter to bound the time it spends waiting for indication events, so that the application will not block indefinitely if events never arrive.
When one or more indication events occur on the handle set, the synchronous event demultiplexer function returns. At this point the handle_events() method ‘reacts’ by demultiplexing to the event handler associated with each handle that is now ready. It then dispatches the handler’s hook method to process the event.
In our example the base class of the reactor implementation hierarchy is defined by the class Reactor_Implementation. We omit its declaration here because this class has essentially the same interface as the Reactor interface in implementation activity 2 (189). The primary difference is that its methods are pure virtual, because it forms the base of a hierarchy of concrete reactor implementations.
For our logging server, we choose the select() function, which is a synchronous event demultiplexer that allows event-driven reactive applications to wait for an application-specified amount of time for various types of I/O events to occur on multiple I/O handles:
int select (u_int max_handle_plus_1, fd_set *read_fds, fd_set *write_fds, fd_set *except_fds,timeval *timeout);
The select() function examines the three ‘file descriptor set’ (fd_set) parameters whose addresses are passed in read_fds, write_fds, and except_fds to see if any of their handles are ‘ready for reading’, ‘reading for writing’, or have an ‘exceptional condition’, respectively. Collectively, the handle values in these three file descriptor set parameters constitute the handle set participant in the Reactor pattern.
The select() function can return multiple ‘ready’ handles to its caller in a single invocation. It cannot be called concurrently on the same handle set by multiple threads of control, however, because the operating system will erroneously notify more than one thread calling select() when I/O events are pending on the same subset of handles [Ste98]. In addition, select() does not scale up well when used with a large set of handles [BaMo98].
Two other synchronous event demultiplexers that are available on some operating systems are the poll() and WaitForMultipleObjects() functions. These two functions have similar scalability problems as select(). They are also less portable, because they are only available on platforms compatible with Win32 and System V Release 4 UNIX, respectively. The Variants section describes a unique feature of WaitForMultipleObjects() that allows it to be called concurrently on the same handle set by multiple threads of control.
The demultiplexing table can be implemented using various search strategies, such as direct indexing, linear search, or dynamic hashing. If handles are represented as a continuous range of integers, as they are on UNIX platforms, direct indexing is most efficient, because demultiplexing table tuple entries can be located in constant O(1) time.
On platforms like Win32 where handles are non-contiguous pointers, direct indexing is infeasible. Some type of linear search or hashing must therefore be used to implement a demultiplexing table.
I/O handles in UNIX are contiguous integer values, which allows our demultiplexing table to be implemented as a fixed-size array of structs. In this design, the handle values themselves index directly into the demultiplexing table’s array to locate event handlers or event registration types in constant time. The following class illustrates such an implementation that maps HANDLEs to Event_Handlers and Event_Types:
class Demux_Table {
public:
// Convert <Tuple> array to <fd_set>s.
void convert_to_fd_sets (fd_set &read_fds,
fd_set &write_fds,
fd_set &except_fds);
struct Tuple {
// Pointer to <Event_Handler> that processes
// the indication events arriving on the handle.
Event_Handler *event_handler_;
// Bit-mask that tracks which types of indication
// events <Event_Handler> is registered for.
Event_Type event_type_;
};
// Table of <Tuple>s indexed by Handle values. The
// macro FD_SETSIZE is typically defined in the
// <sys/socket.h> system header file.
Tuple table_[FD_SETSIZE];
};
In this simple implementation, the Demux_Table’s table_ array is indexed by UNIX I/O handle values, which are unsigned integers ranging from 0 to FD_SETSIZE-1. Naturally, a more portable solution should encapsulate the UNIX-specific implementation details with a wrapper facade (47).
Our concrete reactor implementation uses select() as its synchronous event demultiplexer and the Demux_Table class as its demultiplexing table. It inherits from the Reactor_Implementation class and overrides its pure virtual methods:
class Select_Reactor_Implementation :
public Reactor_Implementation {
public:
The handle_events() method defines the entry point into the reactive event loop of our Select_Reactor_Implementation:
void Select_Reactor_Implementation::handle_events
(Time_Value *timeout = 0) {
This method first converts the Demux_Table tuples into fd_set handle sets that can be passed to select():
fd_set read_fds, write_fds, except_fds; demuxtable.convert_to_fd_sets (read_fds,write_fds,except_fds);
Next, select() is called to wait for up to timeout amount of time for indication events to occur on the handle sets:
HANDLE max_handle = // Max value in <fd_set>s. int result = select (max_handle + 1, &read_fds, &write_fds, &except_fds, timeout); if (result <= 0) throw /* handle error or timeout cases */;
Finally, we iterate over the handle sets and dispatch the hook method(s) on event handlers whose handles have become ‘ready’ due to the occurrence of indication events:
for (HANDLE h = 0; h <= max_handle; ++h) {
// This check covers READ_ + ACCEPT_EVENTs
// because they have the same enum value.
if (FD_ISSET (&read_fds, h))
demux_table.table_[h].event_handler_->
handle_event (h, READ_EVENT);
// … perform the same dispatching logic for
// WRITE_EVENTs and EXCEPT_EVENTs …
}
For brevity, we omit implementations of other methods in our reactor, for example those for registering and unregistering event handlers.
The private portion of our reactor class maintains the event handler demultiplexing table:
private: // Demultiplexing table that maps <HANDLE>s to // <Event_Handler>s and <Event_Type>s. Demux_Table demux_table_; };
Note that this implementation only works on operating system platforms where I/O handles are implemented as contiguous unsigned integers, such as UNIX. Implementing this pattern on platforms where handles are non-contiguous pointers, such as Win32, therefore requires an additional data structure to keep track of which handles are in use.
However, some operating systems limit the number of handles that it is possible to wait for within a single thread of control. Win32, for example, allows WaitForMultipleObjects() to wait for a maximum of 64 handles in a single thread. To develop a scalable application in this case, it may be necessary to create multiple threads, each of which runs its own instance of the Reactor pattern.
Allocating a separate reactor to each of the multiple threads can also be useful for certain types of real-time applications [SMFG00]. For example, different reactors can be associated with threads running at different priorities. This design provides different quality of service levels to process indication events for different types of synchronous operations.
Note that event handlers are only serialized within an instance of the Reactor pattern. Multiple event handlers in multiple threads can therefore run in parallel. This configuration may necessitate the use of additional synchronization mechanisms if event handlers in different threads access shared state concurrently. The Variants section describes techniques for adding concurrency control to reactor and event handler implementations.
The Example Resolved section illustrates the SOCK_Acceptor and SOCK_Stream classes, which are hard-coded into the logging server components. These two classes are wrapper facades that are defined in the Implementation section of the Wrapper Facade pattern (47). They encapsulate the stream Socket semantics of socket handles within a portable and type-secure object-oriented interface. In the Internet domain, stream Sockets are implemented using TCP.
The Acceptor, Connector, and Service_Handler classes shown in the Implementation section of the Acceptor-Connector pattern (285) are templates instantiated with wrapper facades.
Our logging server uses a singleton reactor implemented via the select() synchronous event demultiplexer along with two concrete event handlers—logging acceptor and logging handler—that accept connections and handle logging requests from clients, respectively. Before we discuss the implementation of the two concrete event handlers, which are based on the single-method dispatch interface strategy, we first illustrate the general behavior of the logging server using two scenarios.
The first scenario depicts the sequence of steps performed when a client connects to the logging server:
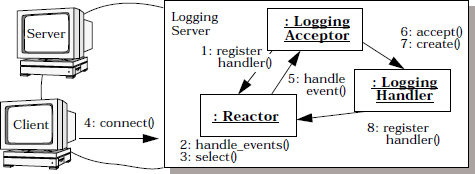
After the client is connected, it can send logging records to the server using the socket handle that was connected in step 6.
The second scenario therefore depicts the sequence of steps performed by the reactive logging server to service a logging record:

The following code implements the concrete event handlers for our logging server example. A Logging_Acceptor class provides passive connection establishment and a Logging_Handler class provides application-specific data reception and processing.
The Logging_Acceptor class is an example of the acceptor component in the Acceptor-Connector pattern (285). It decouples the task of connection establishment and service initialization from the tasks performed after a connection is established and a service is initialized. The pattern enables the application-specific portion of a service, such as the Logging_Handler, to vary independently of the mechanism used to establish the connection and initialize the handler.
A Logging_Acceptor object accepts connection requests from client applications passively and creates client-specific Logging_Handler objects, which receive and process logging records from clients. Note that Logging_Handler objects maintain sessions with their connected clients. A new connection is therefore not established for every logging record.
The Logging_Acceptor class inherits from the ‘single-method’ dispatch interface variant of the Event_Handler base class that was defined in implementation activity 1.2 (187). The Logging_Acceptor constructor registers itself with a reactor for ACCEPT events:
class Logging_Acceptor : public Event_Handler {
public:
Logging_Acceptor (const INET_Addr &addr, Reactor *reactor):
acceptor_ (addr), reactor_ (reactor) {
reactor_->register_handler (this, ACCEPT_EVENT);
}
Note that the register_handler() method ‘double dispatches’ to the Logging_Acceptor’s get_handle() method to obtain its passive-mode socket handle. From this point, whenever a connection indication arrives the reactor dispatches the Logging_Acceptor’s handle_event() method, which is a factory method [GoF95]:
virtual void handle_event
(HANDLE, Event_Type event_type) {
// Can only be called for an ACCEPT event.
if (event_type == ACCEPT_EVENT) {
SOCK_Stream client_connection;
// Accept the connection.
acceptor_.accept (client_connection);
// Create a new <Logging_Handler>.
Logging_Handler *handler = new
Logging_Handler (client_connection, reactor_);
}
}
The handle_event() hook method invokes the accept() method of the SOCK_Acceptor, which initializes a SOCK_Stream. After the SOCK_Stream is connected with the new client passively, a Logging_Handler object is allocated dynamically in the logging server to process the logging requests.
The final method in this class returns the I/O handle of the underlying passive-mode socket:
virtual HANDLE get_handle () const {
return acceptor_.get_handle ();
}
This method is called by the reactor singleton when the Logging_Acceptor is registered. The private portion of the Logging_Acceptor class is hard-coded to contain a SOCK_Acceptor wrapper facade (47):
private: // Socket factory that accepts client connections. SOCK_Acceptor acceptor_; // Cached <Reactor>. Reactor *reactor_; };
The SOCK_Acceptor handle factory enables a Logging_Acceptor object to accept connection indications on a passive-mode socket handle that is listening on a transport endpoint. When a connection arrives from a client, the SOCK_Acceptor accepts the connection passively and produces an initialized SOCK_Stream. The SOCK_Stream is then uses TCP to transfer data reliably between the client and the logging server.
The Logging_Handler class receives and processes logging records sent by a client application. As with the Logging_Acceptor class shown above, the Logging_Handler inherits from Event_Handler so that its constructor can register itself with a reactor to be dispatched when READ events occur:
class Logging_Handler : public Event_Handler {
public:
Logging_Handler (const SOCK_Stream &stream,
Reactor *reactor):
peer_stream_ (stream) {
reactor->register_handler (this, READ_EVENT);
}
Subsequently, when a logging record arrives at a connected Socket and the operating system generates a corresponding READ indication event, the reactor dispatches the handle_event() method of the associated Logging_Handler automatically:
virtual void handle_event (HANDLE, Event_Type event_type) {
if (event_type == READ_EVENT) {
Log_Record log_record;
// Code to handle “short-reads” omitted.
peer_stream_.recv (&log_record, sizeof log_record);
// Write logging record to standard output.
log_record.write (STDOUT);
}
else if (event_type == CLOSE_EVENT) {
peer_stream_.close ();
// Deallocate ourselves.
delete this;
}
}
The handle_event() method receives, processes, and writes the logging record3 to the standard output (STDOUT). Similarly, when the client closes down the connection, the reactor passes the CLOSE event flag, which informs the Logging_Handler to shut down its SOCK_Stream and delete itself. The final method in this class returns the handle of the underlying data-mode stream socket:
virtual HANDLE get_handle () const {
return peer_stream_.get_handle ();
}
This method is called by the reactor when the Logging_Handler is registered. The private portion of the Logging_Handler class is hard-coded to contain a SOCK_Stream wrapper facade (47):
private: // Receives logging records from a connected client. SOCK_Stream peer_stream_; };
The logging server contains a single main() function that implements a single-threaded logging server that waits in the reactor singleton’s handle_events() event loop:
// Logging server port number.
const u_short PORT = 10000;
int main () {
// Logging server address.
INET_Addr addr (PORT);
// Initialize logging server endpoint and register
// with reactor singleton.
Logging_Acceptor la (addr, Reactor::instance ());
// Event loop that processes client connection
// requests and log records reactively.
for (;;)
Reactor::instance ()->handle_events ();
/* NOTREACHED */
}
As requests arrive from clients and are converted into indication events by the operating system, the reactor singleton invokes the hook methods on the Logging_Acceptor and Logging_Handler concrete event handlers to accept connections, and receive and process logging records, respectively.
The sequence diagram below illustrates the behavior in the logging server:

The Implementation section described the activities involved in implementing a reactor that demultiplexes indication events from a set of I/O handles within a single thread of control. The following are variations of the Reactor pattern that are needed to support concurrency, re-entrancy, or timer-based events.
Thread-safe Reactor. A reactor that drives the main event loop of a single-threaded application requires no locks, because it serializes the dispatching of event handler handle_event() hook methods implicitly within its application process.
However, a reactor also can serve as a single-threaded demultiplexer/dispatcher in multi-threaded applications. In this case, although only one thread runs the reactor’s handle_events() event loop method, multiple application threads may register and remove event handlers from the reactor. In addition, an event handler called by the reactor may share state with other threads and work on that state concurrently with them. Three issues must be addressed when designing a thread-safe reactor:
For example, a mutex can be added to the reactor’s demultiplexing table, and the Scoped Locking idiom (325) can be used in the reactor’s methods for registering and removing event handlers to acquire and release this lock automatically. This enhancement helps ensure that multiple threads cannot corrupt the reactor’s demultiplexing table by registering or removing handles and event handlers simultaneously.
To ensure the reactor implementation is not penalized when used in single-threaded applications, the Strategized Locking pattern (333) can be applied to parameterize the locking mechanism.
To prevent self-deadlock, mutual exclusion mechanisms can use recursive locks [Sch95], which can be re-acquired by the thread that owns the lock without incurring self-deadlock on the thread. In the Reactor pattern, recursive locks help prevent deadlock when locks are held by the same thread across event handler hook methods dispatched by a reactor.
An efficient way for an application thread to notify the reactor thread is to pre-establish a pair of ‘writer/reader’ IPC handles when a reactor is initialized, such as a UNIX pipe or a ‘loopback’ TCP Socket connection. The reader handle is registered with the reactor along with a special ‘notification event handler’, whose purpose is simply to wake up the reactor whenever a byte is sent to it via its connected writer handle.
When any application thread calls the reactor’s methods for registering and removing event handlers, they update the demultiplexing table and then send a byte to the writer handle. This wakes up the reactor’s event loop thread and allows it to reconstruct its updated handle set before waiting on its synchronous event demultiplexer again.
Concurrent Event Handlers. The Implementation section described a single-threaded reactive dispatching design in which event handlers borrow the thread of control of a reactor. Event handlers can also run in their own thread of control. This allows a reactor to demultiplex and dispatch new indication events concurrently with the processing of hook methods dispatched previously to its event handlers. The Active Object (369), Leader/Followers (447), and Half-Sync/Half-Async (423) patterns can be used to implement concurrent concrete event handlers.
Concurrent Synchronous Event Demultiplexer. The synchronous event demultiplexer described in the Implementation section is called serially by a reactor in a single thread of control. However, other types of synchronous event demultiplexers, such as the WaitForMultipleObjects() function, can be called concurrently on the same handle set by multiple threads.
When it is possible to initiate an operation on one handle without the operation blocking, the concurrent synchronous event demultiplexer returns a handle to one of its calling threads. This can then dispatch the appropriate hook method on the associated event handler.
Calling the synchronous event demultiplexer concurrently can improve application throughput, by allowing multiple threads to simultaneously demultiplex and dispatch events to their event handlers. However, the reactor implementation can become much more complex and much less portable.
For example, it may be necessary to perform a reference count of the dispatching of event handler hook methods. It may also be necessary to queue calls to the reactor’s methods for registering and removing event handlers, by using the Command pattern [GoF95] to defer changes until no threads are dispatching hook methods on an event handler. Applications may also become more complex if concrete event handlers must be made thread-safe.
Re-entrant Reactors. In general, concrete event handlers just react when called by a reactor and do not invoke the reactor’s event loop themselves. However, certain situations may require concrete event handlers to retrieve specific events by invoking a reactor’s handle_events() method to run its event loop. For example, the CORBA asynchronous method invocation (AMI) feature [ARSK00] requires an ORB Core to support nested work_pending()/perform_work() ORB event loops. If the ORB Core uses the Reactor pattern [SC99], therefore, its reactor implementation must be re-entrant.
A common strategy for making a reactor re-entrant is to copy the handle set state information residing in its demultiplexing table to the run-time stack before calling the synchronous event demultiplexer. This strategy ensures that any changes to the handle set will be local to that particular nesting level of the reactor.
Integrated Demultiplexing of Timer and I/O Events. The reactor described in the Implementation section focuses primarily on demultiplexing and dispatching features necessary to support our logging server example. It therefore only demultiplexes indication events on handle sets. A more general reactor implementation can integrate the demultiplexing of timer events and I/O events.
A reactor’s timer mechanism should allow applications to register time-based concrete event handlers. This mechanism then invokes the handle_timeout() methods of the event handlers at an application-specified future time. The timer mechanism in a reactor can be implemented using various strategies, including heaps [BaLee98], delta-lists [CoSte91], or timing wheels [VaLa97]:
Several changes are required to the Reactor interface defined in implementation activity 2 (189) to enable applications to schedule, cancel, and invoke timer-based event handlers:
class Reactor {
public:
// … same as in implementation activity 2 …
// Schedule a <handler> to be dispatched at
// the <future_time>. Returns a timer id that can
// be used to cancel the timer.
timer_id schedule (Event_Handler *handler,
const void *act,
const Time_Value &future_time);
// Cancel the <Event_Handler> matching the <timer_id>
// value returned from <schedule>.
void cancel (timer_id id, const void **act = 0);
// Expire all timers <= <expire_time>. This
// method must be called manually since it
// is not invoked asynchronously.
void expire (const Time_Value &expire_time);
private:
// …
};
An application uses the schedule() method to schedule a concrete event handler to expire after future_time. An asynchronous completion token (ACT) (261) can be passed to schedule(). If the timer expires the ACT is passed as the value to the event handler’s handle_timeout() hook method. The schedule() method returns a timer id value that identifies each event handler’s registration in the reactor’s timer queue uniquely. This timer id can be passed to the cancel() method to remove an event handler before it expires. If a non-NULL act parameter is passed to cancel(), it will be assigned the ACT passed by the application when the timer was scheduled originally, which makes it possible to delete dynamically-allocated ACTs to avoid memory leaks.
To complete the integration of timer and I/O event demultiplexing, the reactor implementation must be enhanced to allow for both the timer queue’s scheduled event handler deadlines and the timeout parameter passed to the handle_events() method. This method is typically generalized to wait for the closest deadline, which is either the timeout parameter or the earliest deadline in the timer queue.
InterViews [LC87]. The Reactor pattern is implemented by the InterViews windowing system, where it is known as the Dispatcher. The InterViews Dispatcher is used to define an application’s main event loop and to manage connections to one or more physical GUI displays. InterViews therefore illustrates how the Reactor pattern can be used to implement reactive event handling for graphical user interface systems that play the role of both client and server.
The Xt toolkit from the X Windows distribution uses the Reactor pattern to implement its main event loop. Unlike the Reactor pattern implementation described in the Implementation section, callbacks in the Xt toolkit use C function pointers rather than event handler objects. The Xt toolkit is another example of how the Reactor pattern can be used to implement reactive event handling for graphical user interface systems that play the role of both client and server.
ACE Reactor Framework [Sch97]. The ACE framework uses an object-oriented framework implementation of the Reactor pattern as its core event demultiplexer and dispatcher. ACE provides a class, called ACE_Reactor, that defines a common interface to a variety of reactor implementations, such as the ACE_Select_Reactor and the ACE_WFMO_Reactor. These two reactor implementations can be created using different synchronous event demultiplexers, such as WaitForMultipleObjects() and select(), respectively.
The ORB Core component in many implementations of CORBA [OMG98a], such as TAO [SC99] and ORBacus, use the Reactor pattern to demultiplex and dispatch client requests to servants that process the requests.
Call Center Management System. The Reactor pattern has been used to manage events routed by Event Servers [SchSu94] between PBXs and supervisors in a Call Center Management system.
Project Spectrum. The high-speed I/O transfer subsystem of Project Spectrum [PHS96] uses the Reactor pattern to demultiplex and dispatch events in an electronic medical imaging system.
Receiving phone calls. The Reactor pattern occurs frequently in everyday life, for example in telephony. Consider yourself as an event handler that registers with a reactor—a telecommunication network—to ‘handle’ calls received on a particular phone number—the handle. When somebody calls your phone number, the network notifies you that a ‘call request’ event is pending by ringing your phone. After you pick up the phone, you react to this request and ‘process’ it by carrying out a conversation with the connected party.
The Reactor pattern offers the following benefits:
Separation of concerns. The Reactor pattern decouples application-independent demultiplexing and dispatching mechanisms from application-specific hook method functionality. The application-independent mechanisms can be designed as reusable components that know how to demultiplex indication events and dispatch the appropriate hook methods defined by event handlers. Conversely, the application-specific functionality in a hook method knows how to perform a particular type of service.
Modularity, reusability, and configurability. The pattern decouples event-driven application functionality into several components. For example, connection-oriented services can be decomposed into two components: one for establishing connections and another for receiving and processing data.
This decoupling enables the development and configuration of generic event handler components, such as acceptors, connectors, and service handlers, that are loosely integrated together through a reactor. This modularity helps promote greater software component reuse, because modifying or extending the functionality of the service handlers need not affect the implementation of the acceptor and connector components.
In our logging server, the Logging_Acceptor class can easily be generalized to create the acceptor component described in the Acceptor-Connector pattern (285). This generic acceptor can be reused for many different connection-oriented services, such as file transfer, remote log-in, and video-on-demand. It is thus straightforward to add new functionality to the Logging_Handler class without affecting the reusable acceptor component.
Portability. UNIX platforms offer two synchronous event demultiplexing functions, select() [Ste98] and poll() [Rago93], whereas on Win32 platforms the WaitForMultipleObjects() [Sol98] or select() functions can be used to demultiplex events synchronously. Although these demultiplexing calls all detect and report the occurrence of one or more indication events that may occur simultaneously on multiple event sources, their APIs are subtly different. By decoupling the reactor’s interface from the lower-level operating system synchronous event demultiplexing functions used in its implementation, the Reactor pattern therefore enables applications to be ported more readily across platforms.
Coarse-grained concurrency control. Reactor pattern implementations serialize the invocation of event handlers at the level of event demultiplexing and dispatching within an application process or thread. This coarse-grained concurrency control can eliminate the need for more complicated synchronization within an application process.
The Reactor pattern can also incur the following liabilities:
Restricted applicability. The Reactor pattern can be applied most efficiently if the operating system supports synchronous event demultiplexing on handle sets. If the operating system does not provide this support, however, it is possible to emulate the semantics of the Reactor pattern using multiple threads within the reactor implementation. This is possible, for example, by associating one thread to process each handle.
Whenever events are available on a handle, its associated thread reads the event and places it on a queue that is processed sequentially by the reactor implementation. This design can be inefficient, however, because it serializes all the event handler threads. Thus, synchronization and context switching overhead increases without enhancing application-level parallelism.
Non-pre-emptive. In a single-threaded application, concrete event handlers that borrow the thread of their reactor can run to completion and prevent the reactor from dispatching other event handlers. In general, therefore, an event handler should not perform long duration operations, such as blocking I/O on an individual handle, because this can block the entire process and impede the reactor’s responsiveness to clients connected to other handles.
To handle long-duration operations, such as transferring multi-megabyte images [PHS96], it may be more effective to process event handlers in separate threads. This design can be achieved via an Active Object (369) or Half-Sync/Half-Async (423) pattern variant that performs services concurrently to the reactor’s main event loop.
Complexity of debugging and testing. It can be hard to debug applications structured using the Reactor pattern due to its inverted flow of control. In this pattern control oscillates between the framework infrastructure and the method call-backs on application-specific event handlers. The Reactor’s inversion of control increases the difficulty of ‘single-stepping’ through the run-time behavior of a reactive framework within a debugger, because application developers may not understand or have access to the framework code.
These challenges are similar to the problems encountered trying to debug a compiler’s lexical analyzer and parser written with lex and yacc. In such applications, debugging is straightforward when the thread of control is within user-defined semantic action routines. After the thread of control returns to the generated Deterministic Finite Automata (DFA) skeleton, however, it is hard to follow the program’s logic.
The Reactor pattern is related to the Observer [GoF95] and Publisher-Subscriber [POSA1] patterns, where all dependents are informed when a single subject changes. In the Reactor pattern, however, a single handler is informed when an event of interest to the handler occurs on a source of events. In general, the Reactor pattern is used to demultiplex indication events from multiple event sources to their associated event handlers. In contrast, an observer or subscriber is often associated with only a single source of events.
The Reactor pattern is related to the Chain of Responsibility pattern [GoF95], where a request is delegated to the responsible service handler. The Reactor pattern differs from the Chain of Responsibility because the Reactor associates a specific event handler with a particular source of events. In contrast, the Chain of Responsibility pattern searches the chain to locate the first matching event handler.
The Reactor pattern can be considered a synchronous variant of the asynchronous Proactor pattern (215). The Proactor supports the demultiplexing and dispatching of multiple event handlers that are triggered by the completion of asynchronous operations. In contrast, the Reactor pattern is responsible for demultiplexing and dispatching multiple event handlers that are triggered when indication events signal that it is possible to initiate an operation synchronously without blocking.
The Active Object pattern (369) decouples method execution from method invocation to simplify synchronized access to shared state by methods invoked in different threads. The Reactor pattern is often used in lieu of the Active Object pattern when threads are unavailable or the overhead and complexity of threading is undesirable.
The Reactor pattern can be used as the underlying synchronous event demultiplexer for the Leader/Followers (447) and Half-Sync/Half-Async (423) pattern implementations. Moreover, if the events processed by a reactor’s event handlers are all short-lived, it may be possible to use the Reactor pattern in lieu of these other two patterns. This simplification can reduce application programming effort significantly and potentially improve performance, as well.
Java does not offer a synchronous demultiplexer for network events. In particular, it does not encapsulate select() due to the challenges of supporting synchronous demultiplexing in a portable way. It is therefore hard to implement the Reactor pattern directly in Java. However, Java’s event handling in AWT, particularly the listener or delegation-based model, resembles the Reactor pattern in the following way:
All pumping, dispatching, and subsequent event processing runs synchronously in the same thread, which resembles the synchronous processing of events by a reactor.
John Vlissides, the shepherd of the [PLoPD1] version of Reactor, Ralph Johnson, Doug Lea, Roger Whitney, and Uwe Zdun provided many useful suggestions for documenting the original Reactor concept in pattern form.
The Proactor architectural pattern allows event-driven applications to efficiently demultiplex and dispatch service requests triggered by the completion of asynchronous operations, to achieve the performance benefits of concurrency without incurring certain of its liabilities.
Consider a networking application that must perform multiple operations simultaneously, such as a high-performance Web server that processes HTTP requests sent from multiple remote Web browsers [HPS99]. When a user wants to download content from a URL four steps occur:

One way to implement a Web server is to use a reactive event demultiplexing model in accordance with the Reactor pattern (179). In this design, whenever a Web browser connects to a Web server, a new event handler is created to read, parse, and process the request and transfer the contents of the file back to the browser. This handler is registered with a reactor that coordinates the synchronous demultiplexing and dispatching of each indication event to its associated event handler.
Although a reactive Web server design is straightforward to program, it does not scale up to support many simultaneous users and/or long-duration user requests, because it serializes all HTTP processing at the event demultiplexing layer. As a result, only one GET request can be dispatched and processed iteratively at any given time.
A potentially more scalable way to implement a Web server is to use some form of synchronous multi-threading. In this model a separate server thread processes each browser’s HTTP GET request [HS98]. For example, a new thread can be spawned dynamically for each request, or a pool of threads can be pre-spawned and managed using the Leader/Followers (447) or Half-Sync/Half-Async (423) patterns. In either case each thread performs connection establishment, HTTP request reading, request parsing, and file transfer operations synchronously—that is, server processing operations block until they complete.
Synchronous multi-threading is a common concurrency model. However, problems with efficiency, scalability, programming complexity, and portability may occur, as discussed in the Example section of the Reactor pattern (179).
On operating systems that support asynchronous I/O efficiently, our Web server can therefore invoke operations asynchronously to improve its scalability further. For example, on Windows NT the Web server can be implemented to invoke asynchronous Win32 operations that process externally-generated indication events, such as TCP CONNECT and HTTP GET requests, and transmit requested files to Web browsers asynchronously.
When these asynchronous operations complete, the operating system returns the associated completion events containing their results to the Web server, which processes these events and performs the appropriate actions before returning to its event loop. Building software that achieves the potential performance of this asynchronous event processing model is hard due to the separation in time and space of asynchronous invocations and their subsequent completion events. Thus, asynchronous programming requires a sophisticated yet comprehensible event demultiplexing and dispatching mechanism.
An event-driven application that receives and processes multiple service requests asynchronously.
The performance of event-driven applications, particularly servers, in a distributed system can often be improved by processing multiple service requests asynchronously. When asynchronous service processing completes, the application must handle the corresponding completion events delivered by the operating system to indicate the end of the asynchronous computations.
For example, an application must demultiplex and dispatch each completion event to an internal component that processes the results of an asynchronous operation. This component can reply to external clients, such as a Web browser client, or to internal clients, such as the Web server component that initiated the asynchronous operation originally. To support this asynchronous computation model effectively requires the resolution of four forces:
Split application services into two parts: long-duration operations that execute asynchronously and completion handlers that process the results of these operations when they finish. Integrate the demultiplexing of completion events, which are delivered when asynchronous operations finish, with their dispatch to the completion handlers that process them. Decouple these completion event demultiplexing and dispatching mechanisms from the application-specific processing of completion events within completion handlers.
In detail: for every service offered by an application, introduce asynchronous operations that initiate the processing of service requests ‘proactively’ via a handle, together with completion handlers that process completion events containing the results of these asynchronous operations. An asynchronous operation is invoked within an application by an initiator, for example, to accept incoming connection requests from remote applications. It is executed by an asynchronous operation processor. When an operation finishes executing, the asynchronous operation processor inserts a completion event containing that operation’s results into a completion event queue.
This queue is waited on by an asynchronous event demultiplexer called by a proactor. When the asynchronous event demultiplexer removes a completion event from its queue, the proactor demultiplexes and dispatches this event to the application-specific completion handler associated with the asynchronous operation. This completion handler then processes the results of the asynchronous operation, potentially invoking additional asynchronous operations that follow the same chain of activities outlined above.
The Proactor pattern includes nine participants:
Handles are provided by operating systems to identify entities, such as network connections or open files, that can generate completion events. Completion events are generated either in response to external service requests, such as connection or data requests arriving from remote applications, or in response to operations an application generates internally, such as time-outs or asynchronous I/O system calls.
Our Web server creates a separate socket handle for each Web browser connection. In Win32 each socket handle is created in ‘overlapped I/O’ mode, which means that operations invoked on the handles run asynchronously. The Windows NT I/O subsystem also generates completion events when asynchronously-executed operations complete.
Asynchronous operations represent potentially long-duration operations that are used in the implementation of services, such as reading and writing data asynchronously via a socket handle. After an asynchronous operation is invoked, it executes without blocking its caller’s thread of control. Thus, the caller can perform other operations. If an operation must wait for the occurrence of an event, such as a connection request generated by a remote application, its execution will be deferred until the event arrives.
Our proactive Web server invokes the Win32 AcceptEx() operation to accept connections from Web browsers asynchronously. After accepting connections the Web server invokes the Win32 asynchronous ReadFile() and WriteFile() operations to communicate with its connected browsers.

A completion handler specifies an interface that consists of one or more hook methods [Pree95] [GHJV95]. These methods represent the set of operations available for processing information returned in the application-specific completion events that are generated when asynchronous operations finish executing.
Concrete completion handlers specialize the completion handler to define a particular application service by implementing the inherited hook method(s). These hook methods process the results contained in the completion events they receive when the asynchronous operations associated with the completion handler finish executing. A concrete completion handler is associated with a handle that it can use to invoke asynchronous operations itself.
For example, a concrete completion handler can itself receive data from an asynchronous read operation it invoked on a handle earlier. When this occurs, the concrete completion handler can process the data it received and then invoke an asynchronous write operation to return the results to its connected remote peer application.
Our Web server’s two concrete completion handlers—HTTP acceptor and HTTP handler—perform completion processing on the results of asynchronous AcceptEx(), ReadFile(), and WriteFile() operations. The HTTP acceptor is the completion handler for the asynchronous AcceptEx() operation—it creates and connects HTTP handlers in response to connection request events from remote Web browsers. The HTTP handlers then use asynchronous ReadFile() and WriteFile() operations to process subsequent requests from remote Web browsers.

Asynchronous operations are invoked on a particular handle and run to completion by an asynchronous operation processor, which is often implemented by an operating system kernel. When an asynchronous operation finishes executing the asynchronous operation processor generates the corresponding completion event. It inserts this event into the completion event queue associated with the handle upon which the operation was invoked. This queue buffers completion events while they wait to be demultiplexed to their associated completion handler.

In our Web server example, the Windows NT operating system is the asynchronous operation processor. Similarly, the completion event queue is a Win32 completion port [Sol98], which is a queue of completion events maintained by the Windows NT kernel on behalf of an application. When an asynchronous operation finishes the Windows NT kernel queues the completion event on the completion port associated with the handle on which the asynchronous operation was originally invoked.
An asynchronous event demultiplexer is a function that waits for completion events to be inserted into a completion event queue when an asynchronous operation has finished executing. The asynchronous event demultiplexer function then removes one or more completion event results from the queue and returns to its caller.
One asynchronous event demultiplexer in Windows NT is GetQueuedCompletionStatus(). This Win32 function allows event-driven proactive applications to wait up to an application-specified amount of time to retrieve the next available completion event.
A proactor provides an event loop for an application process or thread. In this event loop, a proactor calls an asynchronous event demultiplexer to wait for completion events to occur. When an event arrives the asynchronous event demultiplexer returns. The proactor then demultiplexes the event to its associated completion handler and dispatches the appropriate hook method on the handler to process the results of the completion event.

Our Web server application calls the proactor’s event loop method. This method calls the GetQueuedCompletionStatus() Win32 function, which is an asynchronous event demultiplexer that waits until it can dequeue the next available completion event from the proactor’s completion port. The proactor’s event loop method uses information in the completion event to demultiplex the next event to the appropriate concrete completion handler and dispatch its hook method.
An initiator is an entity local to an application that invokes asynchronous operations on an asynchronous operation processor. The initiator often processes the results of the asynchronous operations it invokes, in which case it also plays the role of a concrete completion handler.
In our example HTTP acceptors and HTTP handlers play the role of both initiators and concrete completion handlers within the Web server’s internal thread of control. For example, an HTTP acceptor invokes AcceptEx() operations that accept connection indication events asynchronously from remote Web browsers. When a connection indication event occurs, an HTTP acceptor creates an HTTP handler, which then invokes an asynchronous ReadFile() operation to retrieve and process HTTP GET requests from a connected Web browser.

Note how in the Proactor pattern the application components, represented by initiators and concrete completion handlers, are proactive entities. They instigate the control and data flow within an application by invoking asynchronous operations proactively on an asynchronous operation processor.
When these asynchronous operations complete, the asynchronous operation processor and proactor collaborate via a completion event queue. They use this queue to demultiplex the resulting completion events back to their associated concrete completion handlers and dispatch these handlers’ hook methods. After processing a completion event, a completion handler may invoke new asynchronous operations proactively.
The structure of the participants in the Proactor pattern is illustrated in the following class diagram:

The following collaborations occur in the Proactor pattern:
The HTTP handler in our Web server can instruct the operating system to read a new HTTP GET request by invoking the ReadFile() operation asynchronously on a particular socket handle. When initiating this operation on the handle, the HTTP handler passes itself as the completion handler so that it can process the results of an asynchronous operation.
The Windows NT operating system defers the asynchronous ReadFile() operation used to read an HTTP GET request until this request arrives from a remote Web browser.
If an HTTP handler invoked an asynchronous ReadFile() operation to read an HTTP GET request, the Windows NT operating system will report the completion status in the completion event, such as its success or failure and the number of bytes read.
The proactor in our Web server example uses a Win32 completion port as its completion event queue. Similarly, it uses the Win32 GetQueuedCompletionStatus() function [Sol98] as its asynchronous event demultiplexer to remove completion events from a completion port.
Second, a remote application or an application internal component may have requested the asynchronous operation. In this case, the completion handler can invoke an asynchronous write operation on its transport handle to return results to the remote application.
In response to an HTTP GET request from a remote Web browser, an HTTP handler might instruct the Windows NT operating system to transmit a large file across a network by calling WriteFile() asynchronously. After the operating system completes the asynchronous operation successfully the resulting completion event indicates the number of bytes transferred to the HTTP handler. The entire file may not be transferred in one WriteFile() operation due to transport-layer flow control. In this case the HTTP handler can invoke another asynchronous WriteFile() operation at the appropriate file offset.
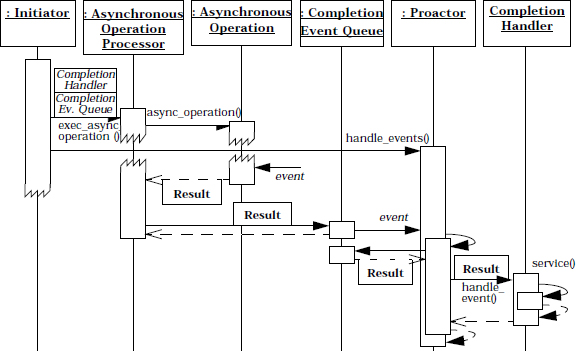
The participants in the Proactor pattern can be decomposed into two layers:
The implementation activities in this section start with the generic demultiplexing/dispatching infrastructure components and then cover the application components. We focus on a proactor implementation that is designed to invoke asynchronous operations and dispatch hook methods on their associated completion handlers using a single thread of control. The Variants section describes the activities associated with developing multi-threaded proactor implementations.
The products of this activity are a set of asynchronous operations, a set of completion handlers, and a set of associations between each asynchronous operation and its completion handler.
The following C++ class conveys the results of an asynchronous Win32 operation back to a concrete completion handler:
class Async_Result : public OVERLAPPED {
// The Win32 OVERLAPPED struct stores the file offset
// returned when an asynchronous operation completes.
public:
// Dispatch to completion handler hook method.
virtual void complete () = 0;
// Set/get number of bytes transferred by an
// asynchronous operation.
void bytes_transferred (u_long);
u_long bytes_transferred () const;
// Set/get the status of the asynchronous operation,
// i.e., whether it succeeded or failed.
void status (u_long);
u_long status () const;
// Set/get error value if the asynchronous operation
// failed or was canceled by the initiator.
void error (u_long);
u_long error () const;
private:
// … data members omitted for brevity …
};
Deriving Async_Result from the OVERLAPPED struct allows applications to add custom state and methods to the results of asynchronous operations. C++ inheritance is used because the Win32 API does not provide a more direct way to pass a per-operation result object to the operating system when an asynchronous operation is invoked.
The following C++ abstract base class illustrates the single-method dispatch interface strategy. We start by defining useful type definitions and enumeration literals that can be used by both the single-method and multi-method dispatch interface strategies:
typedef unsigned int Event_Type;
enum {
// Types of indication events.
READ_EVENT = 01,
ACCEPT_EVENT = 01, // An “alias” for READ_EVENT.
WRITE_EVENT = 02, TIMEOUT_EVENT = 04,
SIGNAL_EVENT = 010, CLOSE_EVENT = 020
// These values are powers of two so
// their bits can be “or’d” together efficiently.
};
class Completion_Handler {
public:
// Cache the <proactor> so that hook methods can
// invoke asynchronous operations on <proactor>.
Completion_Handler (Proactor *proactor):
proactor_ (proactor) { }
// Virtual destruction.
virtual ~Completion_Handler ();
// Hook method dispatched by cached <proactor_> to
// handle completion events of a particular type that
// occur on the <handle>. <Async_Result> reports the
// results of the completed asynchronous operation.
virtual void handle_event
(HANDLE handle, Event_Type et,
const Async_Result &result) = 0;
// Returns underlying I/O <HANDLE>.
virtual HANDLE get_handle () const = 0;
private:
// Cached <Proactor>.
Proactor *proactor_;
};
The following C++ abstract base class illustrates a multi-method interface used by a proactor for network events in our Windows NT-based Web server example:
class Completion_Handler {
public:
// The <proactor> is cached to allow hook methods to
// invoke asynchronous operations on <proactor>.
Completion_Handler (Proactor *proactor):
proactor_ (proactor) { }
// Virtual destruction.
virtual ~Completion_Handler ();
// The next 3 methods use <Async_Result> to report
// results of completed asynchronous operation.
// Dispatched by <proactor_> when an asynchronous
// read operation completes.
virtual void handle_read
(HANDLE handle, const Async_Result &result) = 0;
// Dispatched by <proactor_> when an asynchronous
// write operation completes.
virtual void handle_write
(HANDLE handle, const Async_Result &result) = 0;
// Dispached by <proactor_> when an asynchronous
// <accept> operation completes.
virtual void handle_accept
(HANDLE handle, const Async_Result &result) = 0;
// Dispatched by <proactor_> when a timeout expires.
virtual void handle_timeout
(const Time_Value &tv, const void *act) = 0;
// Returns underlying I/O <HANDLE>.
virtual HANDLE get_handle () const = 0;
private:
// Cached <Proactor>.
Proactor *proactor_;
};
Both the single-method and multiple-method dispatch interface strategies are implementations of the Hook Method [Pree95] and Template Method [GoF95] patterns. The intent of these patterns is to provide well-defined hooks that can be specialized by applications and called back by lower-level dispatching code.
Completion handlers are often designed to act both as a target of a proactor’s completion dispatching and an initiator that invokes asynchronous operations, as shown by the HTTP_Handler class in the Example Resolved section. Therefore, the constructor of class Completion_Handler associates a Completion_Handler object with a pointer to a proactor. This design allows a Completion_Handler’s hook methods to invoke new asynchronous operations whose completion processing will be dispatched ultimately by the same proactor.
A common strategy to consolidate all this completion processing information efficiently is to apply the Asynchronous Completion Token pattern (261). When an initiator invokes an asynchronous operation on a handle, an asynchronous completion token (ACT) can then be passed to the asynchronous operation processor, which can store this ACT for later use. Each ACT contains information that identifies a particular operation and guides its subsequent completion processing.
When an asynchronous operation finishes executing, the asynchronous operation processor locates the operation’s ACT it stored earlier and associates it with the completion event it generates. It then inserts this updated completion event into the appropriate completion event queue. Ultimately, the proactor that runs the application’s event loop will use an asynchronous event demultiplexer to remove the completion event results and ACT from its completion event queue. The proactor will then use this ACT to complete its demultiplexing and dispatching of the completion event results to the completion handler designated by the ACT.
Although our Web server is implemented using Win32 asynchronous Socket operations, we apply the Wrapper Facade pattern (47) to generalize this class and make it platform-independent. It can therefore be used for other types of I/O devices supported by an asynchronous operation processor.
The following Async_Stream class interface is used by HTTP handlers in our Web server example to invoke asynchronous operations:
class Async_Stream {
public:
// Constructor ‘zeros out’ the data members.
Async_Stream ();
// Initialization method.
void open (Completion_Handler *handler,
HANDLE handle, Proactor *proactor);
// Invoke an asynchronous read operation.
void async_read (void *buf, u_long n_bytes);
// Invoke an asynchronous write operation.
void async_write (const void *buf, u_long n_bytes);
private:
// Cache parameters passed in <open>.
Completion_Handler *completion_handler_;
HANDLE handle_;
Proactor *proactor_;
};
A concrete completion handler, such as an HTTP handler, can pass itself to open(), together with the handle on which the Async_Stream’s async_read() and async_write() methods are invoked:
void Async_Stream::open (Completion_Handler *handler,
HANDLE handle,
Proactor *proactor) {
completion_handler_ = handler;
handle_ = handle;
proactor_ = proactor;
// Associate handle with <proactor>’s completion
// port, as shown in implementation activity 4.
proactor->register_handle (handle);
}
To illustrate the use of asynchronous completion tokens (ACTs), consider the following implementation of the Async_Stream::async_read() method. It uses the Win32 ReadFile() function to read up to n_bytes asynchronously and store them in its buf parameter:
void Async_Stream::read (void *buf, u_long n_bytes) {
u_long bytes_read;
OVERLAPPED *act = new // Create the ACT.
Async_Stream_Read_Result (completion_handler_);
ReadFile (handle_, buf, n_bytes, &bytes_read, act);
}
The ACT passed as a pointer to ReadFile() is a dynamically allocated instance of the Async_Stream_Read_Result class below:
class Async_Stream_Read_Result : public Async_Result {
public:
// Constructor caches the completion handler.
Async_Stream_Read_Result
(Completion_Handler *completion_handler):
completion_handler_ (completion_handler) { }
// Adapter that dispatches the <handle_event>
// hook method on cached completion handler.
virtual void complete ();
private:
// Cache a pointer to a completion handler.
Completion_Handler *completion_handler_;
};
This class plays the role of an ACT and an adapter [GoF95]. It inherits from Async_Result, which itself inherits from the Win32 OVERLAPPED struct, as shown in implementation activity 2.1 (227). The ACT can be passed as the lpOverlapped parameter to the ReadFile() asynchronous function. ReadFile() forwards the ACT to the Windows NT operating system, which stores it for later use.
When the asynchronous ReadFile() operation finishes it generates a completion event that contains the ACT it received when this operation was invoked. When the proactor’s handle_events() method removes this event from its completion event queue, it invokes the complete() method on the Async_Stream_Read_Result. This adapter method then dispatches the completion handler’s handle_event() hook method to pass the event, as shown in implementation activity 5.4 (240).
Some asynchronous operation processors allow initiators to cancel asynchronous operations. However, completion events are still generated. Thus, ACTs and other resources can be reclaimed properly by completion handlers.
Certain operating environments provide these asynchronous operation execution and completion event generation mechanisms, such as Real-time POSIX [POSIX95] and Windows NT [Sol98]. In this case implementing the asynchronous completion processor participant simply requires mapping existing operating system APIs onto the asynchronous operation wrapper facade (47) interfaces described in implementation activity 3.1 (232). The Variants section describes techniques for emulating an asynchronous operation processor on operating system platforms that do not support this feature natively.
The Proactor pattern can use the Bridge pattern [GoF95] to shield applications from complex and non-portable completion event demultiplexing and dispatching mechanisms. The proactor interface corresponds to the abstraction participant in the Bridge pattern, whereas a platform-specific proactor instance is accessed internally via a pointer, in accordance with the implementation hierarchy in the Bridge pattern.
The proactor interface in our Web server defines an abstraction for associating handles with completion ports and running the application’s event loop proactively:
class Proactor {
public:
// Associate <handle> with the <Proactor>’s
// completion event queue.
void register_handle (HANDLE handle);
// Entry point into the proactive event loop. The
// <timeout> can bound time waiting for events.
void handle_events (Time_Value *wait_time = 0);
// Define a singleton access point.
static Proactor *instance ();
private:
// Use the Bridge pattern to hold a pointer to
// the <Proactor_Implementation>.
Proactor_Implementation *proactor_impl_;
};
A proactor interface also defines a method, which we call register_handle(), that associates a handle with the proactors completion event queue, as described in implementation activity 5.5 (240). This association ensures that the completion events generated when asynchronous operations finish executing will be inserted into a particular proactor’s completion event queue.
The proactor interface also defines the main entry point method, we call it handle_events(), that applications use to run their proactive event loop.7 This method calls the asynchronous event demultiplexer, which waits for completion events to arrive on its completion event queue, as discussed in implementation activity 3.1 (232). An application can use the timeout parameter to bound the time it spends waiting for completion events. Thus, the application need not block indefinitely if events never arrive.
After the asynchronous operation processor inserts a completion event into the proactor’s completion event queue, the asynchronous event demultiplexer function returns. At this point the proactor’s handle_events() method dequeues the completion event and uses its associated ACT to demultiplex to the asynchronous operation’s completion handler and dispatch the handler’s hook method.
In our example the base class of the proactor implementation hierarchy is defined by the class Proactor_Implementation. We omit its declaration here because this class has essentially the same interface as the Proactor interface in implementation activity 4 (235). The primary difference is that its methods are purely virtual, because it forms the base of a hierarchy of concrete proactor implementations.
The Win32 GetQueuedCompletionStatus() function allows event-driven proactive applications to wait up to an application-specified amount of time for any completion events to occur on a completion port. Events are removed in FIFO order [Sol98].
The POSIX aio_suspend() function [POSIX95] and the Win32 WaitForMultipleObjects() function [Sol98] are passed an array parameter designating asynchronous operations explicitly. They suspend their callers for an application-specified amount of time until at least one of these asynchronous operations has completed.
The completion event queue and asynchronous event demultiplexer are often existing operating system mechanisms that need not be developed by Proactor pattern implementors.
The primary difference between GetQueuedCompletionStatus(), aio_suspend(), and WaitForMultipleObjects() is that the latter two functions can wait selectively for completion events specified via an array parameter. Conversely, GetQueuedCompletionStatus() just waits for the next completion event enqueued on its completion port. Moreover, the POSIX aio_*() functions can only demultiplex asynchronous I/O operations, such as aio_read() or aio_write(), whereas GetQueuedCompletionStatus() and WaitForMultipleObjects() can demultiplex other Win32 asynchronous operations, such as timers and synchronization objects.
Our Web server uses a Win32 completion port as the completion event queue and the GetQueuedCompletionStatus() function as its asynchronous event demultiplexer:
BOOL GetQueuedCompletionStatus (HANDLE CompletionPort, LPDWORD lpNumberOfBytesTransferred, LPDWORD lpCompletionKey, LPOVERLAPPED *lpOverlapped, DWORD dwMilliseconds);
As shown in implementation activity 5.5 (240), our proactor implementation’s handle_events() method uses this function to dequeue a completion event from the specified CompletionPort. The number of bytes transferred is returned as an ‘out’ parameter. The lpOverlapped parameter points to the ACT passed by the original asynchronous operation, such as the ReadFile() call in the Async_Stream::async_read() method shown in implementation activity 3.1 (232).
If there are no completion event results queued on the port, the function blocks the calling thread, waiting for asynchronous operations associated with the completion port to finish. The GetQueuedCompletionStatus() function returns when it is able to dequeue a completion event result or when the dwMilliseconds timeout expires.
When the asynchronous operation completes, the asynchronous operation processor generates the corresponding completion event, associates it with its ACT and inserts the updated completion event into the appropriate completion event queue. After an asynchronous event demultiplexer removes the completion event from its completion event queue, the proactor implementation can use the completion event’s ACT to demultiplex to the designated completion handler in constant O(1) time.
As shown in implementation activity 3.1 (232), when an async_read() or async_write() method is invoked on an Async_Stream, they create a new Async_Stream_Read_Result or Async_Stream_Write_Result ACT, respectively and pass it to the corresponding Win32 asynchronous operation. When this asynchronous operation finishes, the Windows NT kernel queues the completion event on the completion port designated by the handle that was passed during the original asynchronous operation invocation. The ACT is used by the proactor to demultiplex the completion event to the completion handler designated in the original call.
An Async_Stream_Read_Result is an adapter, whose complete() method can dispatch the appropriate hook method on the completion handler that it has cached in the state of its ACT:
void Async_Stream_Read_Result::complete () {
completion_handler_->handle_event
(completion_handler_->get_handle (),
READ_EVENT, *this);
}
Note how the handle_event() dispatch hook method is passed a reference to the Async_Stream_Read_Result object that invoked it. This double-dispatching interaction [GoF95] allows the completion handler to access the asynchronous operation results, such as the number of bytes transferred and its success or failure status.
Our concrete proactor implementation overrides the pure virtual methods it inherits from class Proactor_Implementation:
class Win32_Proactor_Implementation :
public Proactor_Implementation {
public:
The Win32_Proactor_Implementation constructor creates the completion port and caches it in the completion_port_ data member:
Win32_Proactor_Implementation::
Win32_Proactor_Implementation () {
completion_port_ = CreateIoCompletionPort
(INVALID_HANDLE, 0, 0, 0);
}
The register_handle() method associates a HANDLE with the completion port:
void Win32_Proactor_Implementation::register_handle
(HANDLE h) {
CreateIoCompletionPort (h, completion_port_,0,0);
}
All subsequent completion events hat result from asynchronous operations invoked via the HANDLE will be inserted into this proactor’s completion port by the Windows NT operating system.
The next code fragment shows how to implement the handle_events() method:
void Win32_Proactor_Implementation::handle_events
(Time_Value *wait_time = 0) {
u_long num_bytes;
OVERLAPPED *act;
This method first calls the GetQueuedCompletionStatus() asynchronous event demultiplexing function to dequeue the next completion event from the completion port:
BOOL status = GetQueuedCompletionStatus (completion_port_, &num_bytes, 0, &act, wait_time == 0 ? 0 : wait_time->msec ());
When this function returns, the ACT received from the Windows NT operating system is downcast to become an Async_Result *:
Async_Result *async_result = static_cast <Async_Result *> (act);
The completion event that GetQueuedCompletionStatus() returned updates the completion result data members in async_result:
async_result->status (status); if (!status) async_result->error (GetLastError ()); else async_result->bytes_transferred(num_bytes);
The proactor implementation’s handle_events() method then invokes the complete() method on the async_result adapter:
async_result->complete ();
Implementation activity 5.4 (240) illustrates how the complete() method in the Async_Stream_Read_Result adapter dispatches to the concrete completion handler’s handle_event() hook method.
Finally, the proactor deletes the async_result pointer, which was allocated dynamically by an asynchronous operation interface method, as shown in implementation activity 3.1 (232).
delete async_result; }
The private portion of our proactor implementation caches the handle to its Windows NT completion port:
private: // Store a HANDLE to a Windows NT completion port. HANDLE completion_port_; };
It can be useful to run multiple proactors simultaneously within the same application process, however. For example, different proactors can be associated with threads running at different priorities. This design provides different quality of service levels to process completion handlers for asynchronous operations.
Note that completion handlers are only serialized per thread within an instance of the proactor. Multiple completion handlers in multiple threads can therefore run in parallel. This configuration may necessitate the use of additional synchronization mechanisms if completion handlers in different threads access shared state concurrently. Mutexes and synchronization idioms such as Scoped Locking (325) are suitable.
Our Web server uses Windows NT features, such as overlapped I/O, completion ports, and GetQueuedCompletionStatus(), to implement proactive event demultiplexing. It employs a single-method completion handler dispatch interface strategy that can process multiple Web browser service requests asynchronously. HTTP acceptors asynchronously connect and create HTTP handlers using a variant of the Acceptor-Connector pattern (285). Each HTTP handler is responsible for asynchronously receiving, processing, and replying to a Web browser GET request delivered to the Web server’s proactor via a completion event. The example shown here uses a single thread to invoke asynchronous operations and handle completion event processing. It is straightforward to enhance this example to take advantage of multiple threads, however, as described in the Variants section.
The Web server’s main() function starts by performing its initialization activities, such as creating a proactor singleton, a Windows NT completion port, and an HTTP acceptor. This acceptor associates its passive-mode acceptor handle with the proactor singleton’s completion port. The Web server next performs the following scenario during its connection processing:
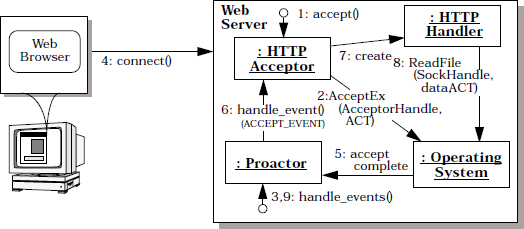
After the connection is established and the HTTP handler is created, the following diagram illustrates the subsequent scenario used by a proactive Web server to service an HTTP GET request:

Below we illustrate how the HTTP handler in our Web server can be written using the Completion_Handler class defined in the Implementation section.
class HTTP_Handler : public Completion_Handler {
// Implements HTTP using asynchronous operations.
HTTP_Handler inherits from the ‘single-method’ dispatch interface variant of the Completion_Handler base class defined in implementation activity 2.3 (228). This design enables the proactor singleton to dispatch its handle_events() hook method when asynchronous ReadFile() and WriteFile() operations finish. The following data members are contained in each HTTP_Handler object:
private: // Cached <Proactor>. Proactor *proactor_; // Memory-mapped file_; Mem_Map file_; // Socket endpoint, initialized into “async-mode.” SOCK_Stream *sock_; // Hold the HTTP Request while its being processed. HTTP_Request request_; // Read/write asynchronous socket I/O. Async_Stream stream_;
The constructor caches a pointer to the proactor used by the HTTP_Handler:
public:
HTTP_Handler (Proactor *proactor):
proactor_ (proactor) { }
When a Web browser connects to the Web server the following open() method of the HTTP handler is called by the HTTP acceptor:
virtual void open (SOCK_Stream *sock) {
// Initialize state for request.
request_.state_ = INCOMPLETE;
// Store pointer to the socket.
sock_ = sock;
// Initialize <Async_Stream>.
stream_.open
(this, // This completion handler.
sock_->handle (), proactor_);
// Start asynchronous read operation on socket.
stream_.async_read
(request_.buffer (), request_.buffer_size ());
}
In open(), the Async_Stream is initialized with the completion handler, handle, and proactor to use when asynchronous ReadFile() and WriteFile() operations finish. It then invokes an async_read() operation and returns to the proactor that dispatched it. When the call stack unwinds the Web server will continue running its handle_events() event loop method on its proactor singleton.
After the asynchronous ReadFile() operation completes, the proactor singleton demultiplexes to the HTTP_Handler completion handler and dispatches its subsequent handle_event() method:
virtual void handle_event
(HANDLE,
Event_Type event_type,
const Async_Result &async_result) {
if (event_type == READ_EVENT) {
if (!request_.done
(async_result.bytes_transferred ()))
// Didn’t get entire request, so start a
// new asynchronous read operation.
stream_.async_read (request_.buffer (),
request_.buffer_size ());
else
parse_request ();
}
// …
}
If the entire request has not arrived, another asynchronous ReadFile() operation is invoked and the Web server returns once again to its event loop. After a complete GET request has been received from a Web browser, however, the following parse_request() method maps the requested file into memory and writes the file data to the Web browser asynchronously:
void parse_request () {
// Switch on the HTTP command type.
switch (request_.command ()) {
// Web browser is requesting a file.
case HTTP_Request::GET:
// Memory map the requested file.
file_.map (request_.filename ());
// Invoke asynchronous write operation.
stream_.async_write (file_.buffer (),
file_.buffer_size ());
break;
// Web browser is storing file at the Web server.
case HTTP_Request::PUT:
// …
}
}
This sample implementation of parse_request() uses a C++ switch statement for simplicity and clarity. A more extensible implementation could apply the Command pattern [GoF95] or Command Processor pattern [POSA1] instead.
When the asynchronous WriteFile() operation completes, the proactor singleton dispatches the handle_event() hook method of the HTTP_Handler:
virtual void handle_event
(HANDLE, Event_Type event_type,
const Async_Result &async_result) {
// … see READ_EVENT case above …
else if (event_type == WRITE_EVENT) {
if (!file_.done
(async_result.bytes_transferred ()))
// Didn’t send entire data, so start
// another asynchronous write.
stream_.async_write
(file_.buffer (),file_.buffer_size ());
else
// Success, so free up resources…
}
}
After all the data has been received the HTTP handler frees resources that were allocated dynamically.
The Web server contains a main() function that implements a single-threaded server. This server first calls an asynchronous accept operation and the waits in the proactor singleton’s handle_events() event loop:
// HTTP server port number.
const u_short PORT = 80;
int main () {
// HTTP server address.
INET_Addr addr (PORT);
// Initialize HTTP server endpoint, which associates
// the <HTTP_Acceptor>’s passive-mode socket handle
// with the <Proactor> singleton’s completion port.
HTTP_Acceptor acceptor (addr, Proactor::instance ());
// Invoke an asynchronous <accept> operation to
// Invoke the Web server processing.
acceptor.accept ();
// Event loop processes client connection requests
// and HTTP requests proactively.
for (;;)
Proactor::instance ()->handle_events ();
/* NOTREACHED */
}
As service requests arrive from Web browsers and are converted into indication events by the operating system, the proactor singleton invokes the event handling hook methods on the HTTP_Acceptor and HTTP_Handler concrete event handlers to accept connections and receive and process logging records asynchronously. The sequence diagram below illustrates the behavior in the proactive Web server.
The proactive processing model shown in this diagram can scale when multiple HTTP handlers and HTTP acceptors process requests from remote Web browsers simultaneously. For example, each handler/acceptor can invoke asynchronous ReadFile(), WriteFile(), and AcceptEx() operations that run concurrently. If the underlying asynchronous operation processor supports asynchronous I/O operations efficiently the overall performance of the Web server will scale accordingly.
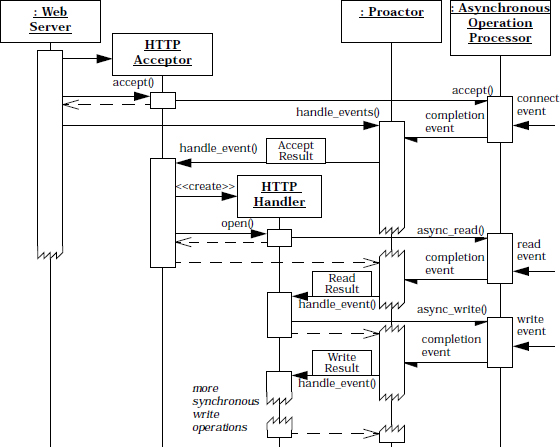
Asynchronous Completion Handlers. The Implementation section describes activities used to implement a proactor that dispatches completion events to completion handlers within a single proactor event loop thread. When a concrete completion handler is dispatched, it borrows the proactor’s thread to perform its completion processing. However, this design may restrict the concrete completion handler to perform short-duration synchronous processing to avoid decreasing the overall responsiveness of the application significantly.
To resolve this restriction, all completion handlers could be required to act as initiators and invoke long-duration asynchronous operations immediately, rather than performing the completion processing synchronously. Some operating systems, such as Windows NT, explicitly support asynchronous procedure calls (APCs). An APC is a function that executes asynchronously in the context of its calling thread. When an APC is invoked the operating system queues it within the thread context. The next time the thread is idle, such as when it blocks on an I/O operation, it can run the queued APCs.
Concurrent Asynchronous Event Demultiplexer. One downside to using APCs is that they may not use multiple CPUs effectively. This is because each APC runs in a single thread context. A more scalable strategy therefore may be to create a pool of threads that share an asynchronous event demultiplexer, so that a proactor can demultiplex and dispatch completion handlers concurrently. This strategy is particularly scalable on operating system platforms that implement asynchronous I/O efficiently.
For example, a Windows NT completion port [Sol98] is optimized to run efficiently when accessed by GetQueuedCompletionStatus() from multiple threads simultaneously [HPS99]. In particular, the Windows NT kernel schedules threads waiting on a completion port in ‘last-in first-out’ (LIFO) order. This LIFO protocol maximizes CPU cache affinity [Mog95] by ensuring that the thread waiting the shortest time is scheduled first, which is an example of the Fresh Work Before Stale pattern [Mes96].
Shared Completion Handlers. Iinitiators can invoke multiple asynchronous operations simultaneously, all of which share the same concrete completion handler [ARSK00]. To behave correctly, however, each shared handler may need to determine unambiguously which asynchronous operation has completed. In this case, the initiator and proactor must collaborate to shepherd operation-specific state information throughout the entire asynchronous processing life-cycle.
As with implementation activity 3.1 (232), the Asynchronous Completion Token pattern (261) can be re-applied to disambiguate each asynchronous operation—an initiator can create an asynchronous completion token (ACT) that identifies each asynchronous operation uniquely. It then ‘piggy-backs’ this initiator-ACT onto the ACT passed when an asynchronous operation is invoked on an asynchronous operation processor. When the operation finishes executing and is being processed by the proactor, the ‘initiator-ACT’ can be passed unchanged to the shared concrete completion handler’s hook method. This initiator-ACT allows the concrete completion handler to control its subsequent processing after it receives an asynchronous operation’s completion results.
To share a concrete completion handler we first add an initiator-ACT data member and a pair of set/get methods to the Async_Result class:
class Async_Result : public OVERLAPPED {
private:
const void *initiator_act_;
// ….
public:
// Set/get initiator’s ACT.
void initiator_act (const void *);
const void *initiator_act ();
// …
We next modify the Async_Stream I/O methods to ‘piggy-back’ the initiator-ACT with its existing ACT:
int Async_Stream::async_read (void *buf,
u_long n_bytes,
const void *initiator_act)
{
u_long bytes_read;
OVERLAPPED *act = new // Create the ACT.
Async_Stream_Read_Result (completion_handler_);
// Set <initiator_act> in existing ACT.
act->initiator_act (initiator_act);
ReadFile (handle_, buf, n_bytes, &bytes_read, act);
}
Finally, we can retrieve this initiator-ACT in a concrete event handler’s handle_event() method via the Async_Result parameter:
virtual void handle_event
(HANDLE, Event_Type event_type,
const Async_Result &async_result) {
const void *initiator_act =
async_result.initiator_act ();
// …
}
The handle_event() method can use this initiator_act to disambiguate its subsequent processing.
Asynchronous Operation Processor Emulation. Many operating system platforms, including the traditional versions of UNIX [MBKQ96] and the Java Virtual Machine (JVM), do not export asynchronous operations to applications. There are several techniques that can be used to emulate an asynchronous operation processor on such platforms, however. A common solution is to employ a concurrency mechanism to execute operations without blocking initiators, such as the Active Object pattern (369) or some type of threading model. Three activities must be addressed when implementing a multi-threaded asynchronous operation processor:
Each operation will subsequently be dequeued and executed in a thread internal to the asynchronous operation processor. For example, to implement asynchronous read operations an internal thread can block while reading from socket or file handles. Operations thus appear to execute asynchronously to initiators that invoke them, even though the operations block internally within the asynchronous operation processor in their own thread of control.
Other variants. Several variants of the Proactor pattern are similar to variants in the Reactor pattern (179), such as integrating the demultiplexing of timer and I/O events, and supporting concurrent concrete completion handlers.
Completion ports in Windows NT. The Windows NT operating system provides the mechanisms to implement the Proactor pattern efficiently [Sol98]. Various asynchronous operations are supported by Windows NT, such as time-outs, accepting new network connections, reading and writing to files and Sockets, and transmitting entire files across a Socket connection. The operating system itself is thus the asynchronous operation processor. Results of the operations are queued as completion events on Windows NT completion ports, which are then dequeued and dispatched by an application-provided proactor.
The POSIX AIO family of asynchronous I/O operations. On some real-time POSIX platforms the Proactor pattern is implemented by the aio_*() family of APIs [POSIX95]. These operating system features are similar to those described above for Windows NT. One difference is that UNIX signals can be used to implement a pre-emptively asynchronous proactor in which a signal handler can interrupt an application’s thread of control. In contrast, the Windows NT API is not pre-emptively asynchronous, because application threads are not interrupted. Instead, the asynchronous completion routines are called back at well-defined Win32 function points.
ACE Proactor Framework. The ADAPTIVE Communication Environment (ACE) [Sch97] provides a portable object-oriented Proactor framework that encapsulates the overlapped I/O and completion port mechanisms on Windows NT and the aio_*() family of asynchronous I/O APIs on POSIX platforms. ACE provides an abstraction class, ACE_Proactor, that defines a common interface to a variety of proactor implementations, such as ACE_Win32_Proactor and ACE_POSIX_Proactor. These proactor implementations can be created using different asynchronous event demultiplexers, such as GetQueuedCompletionStatus() and aio_suspend(), respectively.
Operating system device driver interrupt-handling mechanisms. The Proactor pattern is often used to enhance the structure of operating system kernels that invoke I/O operations on hardware devices driven by asynchronous interrupts. For example, a packet of data can be written from an application to a kernel-resident device driver, which then passes it to the hardware device that transmits the data asynchronously. When the device finishes its transmission it generates a hardware interrupt that notifies the appropriate handler in the device driver. The device driver then processes the interrupt to completion, potentially initiating another asynchronous transfer if more data is available from the application.
Phone call initiation via voice mail. A real-life application of the Proactor pattern is the scenario in which you telephone a friend, who is currently away from her phone, but who returns calls reliably when she comes home. You therefore leave a message on her voice mail to ask her to call you back. In terms of the Proactor pattern, you are a initiator who invokes an asynchronous operation on an asynchronous operation processor—your friend’s voice mail—to inform your friend that you called. While waiting for your friend’s ‘call-back’ you can do other things, such as re-read chapters in POSA2. After your friend has listened to her voice mail, which corresponds to the completion of the asynchronous operation, she plays the proactor role and calls you back. While talking with her, you are the completion handler that ‘processes’ her ‘callback’.
The Proactor pattern offers a variety of benefits:
Separation of concerns. The Proactor pattern decouples application-independent asynchronous mechanisms from application-specific functionality. The application-independent mechanisms become reusable components that know how to demultiplex the completion events associated with asynchronous operations and dispatch the appropriate callback methods defined by concrete completion handlers. Similarly, the application-specific functionality in concrete completion handlers know how to perform particular types of service, such as HTTP processing.
Portability. The Proactor pattern improves application portability by allowing its interface to be reused independently of the underlying operating system calls that perform event demultiplexing. These system calls detect and report the events that may occur simultaneously on multiple event sources. Event sources may include I/O ports, timers, synchronization objects, signals, and so on. For example, on real-time POSIX platforms the asynchronous I/O functions are provided by the aio_*() family of APIs [POSIX95]. Similarly, on Windows NT, completion ports and overlapped I/O are used to implement asynchronous I/O [MDS96].
Encapsulation of concurrency mechanisms. A benefit of decoupling the proactor from the asynchronous operation processor is that applications can configure proactors with various concurrency strategies without affecting other application components and services.
Decoupling of threading from concurrency. The asynchronous operation processor executes potentially long-duration operations on behalf of initiators. Applications therefore do not need to spawn many threads to increase concurrency. This allows an application to vary its concurrency policy independently of its threading policy. For instance, a Web server may only want to allot one thread per CPU, but may want to service a higher number of clients simultaneously via asynchronous I/O.
Performance. Multi-threaded operating systems use context switching to cycle through multiple threads of control. While the time to perform a context switch remains fairly constant, the total time to cycle through a large number of threads can degrade application performance significantly if the operating system switches context to an idle thread.9 For example, threads may poll the operating system for completion status, which is inefficient. The Proactor pattern can avoid the cost of context switching by activating only those logical threads of control that have events to process. If no GET request is pending, for example, a Web server need not activate an HTTP Handler.
Simplification of application synchronization. As long as concrete completion handlers do not spawn additional threads of control, application logic can be written with little or no concern for synchronization issues. Concrete completion handlers can be written as if they existed in a conventional single-threaded environment. For example, a Web server’s HTTP handler can access the disk through an asynchronous operation, such as the Windows NT TransmitFile() function [HPS99], hence no additional threads need to be spawned.
The Proactor pattern has the following liabilities:
Restricted applicability. The Proactor pattern can be applied most efficiently if the operating system supports asynchronous operations natively. If the operating system does not provide this support, however, it is possible to emulate the semantics of the Proactor pattern using multiple threads within the proactor implementation. This can be achieved, for example, by allocating a pool of threads to process asynchronous operations. This design is not as efficient as native operating system support, however, because it increases synchronization and context switching overhead without necessarily enhancing application-level parallelism.
Complexity of programming, debugging and testing. It is hard to program applications and higher-level system services using asynchrony mechanisms, due to the separation in time and space between operation invocation and completion. Similarly, operations are not necessarily constrained to run at well-defined points in the processing sequence—they may execute in non-deterministic orderings that are hard for many developers to understand.
Applications written with the Proactor pattern can also be hard to debug and test because the inverted flow of control oscillates between the proactive framework infrastructure and the method callbacks on application-specific handlers. This increases the difficulty of ‘single-stepping’ through the run-time behavior of a framework within a debugger, because application developers may not understand or have access to the proactive framework code.
Scheduling, controlling, and canceling asynchronously running operations. Initiators may be unable to control the scheduling order in which asynchronous operations are executed by an asynchronous operation processor. If possible, therefore, an asynchronous operation processor should employ the Strategy pattern [GoF95] to allow initiators to prioritize and cancel asynchronous operations. Devising a completely reliable and efficient means of canceling all asynchronous operations is hard, however, because asynchronous operations may complete before they can be cancelled.
The Proactor pattern is related to the Observer [GoF95] and Publisher-Subscriber [POSA1] patterns, in which all dependents are informed when a single subject changes. In the Proactor pattern, however, completion handlers are informed automatically when completion events from multiple sources occur. In general, the Proactor pattern is used to demultiplex multiple sources of asynchronously delivered completion events to their associated completion handlers, whereas an observer or subscriber is usually associated with a single source of events.
The Proactor pattern can be considered an asynchronous variant of the synchronous Reactor pattern (179). The Reactor pattern is responsible for demultiplexing and dispatching multiple event handlers that are triggered when it is possible to invoke an operation synchronously without blocking. In contrast, the Proactor pattern supports the demultiplexing and dispatching of multiple completion handlers that are triggered by the completion of operations that execute asynchronously.
Leader/Followers (447) and Half-Sync/Half-Async (423) are two other patterns that demultiplex and process various types of events synchronously. On platforms that support asynchronous I/O efficiently, the Proactor pattern can often be implemented more efficiently than these patterns. However, the Proactor pattern may be harder to implement because it has more participants, which require more effort to understand. The Proactor’s combination of ‘inversion of control’ and asynchrony may also require application developers to have more experience to use and debug it effectively.
The Active Object pattern (369) decouples method execution from method invocation. The Proactor pattern is similar, because an asynchronous operation processor performs operations asynchronously on behalf of initiators. Both patterns can therefore be used to implement asynchronous operations. The Proactor pattern is often used instead of the Active Object pattern on operating systems that support asynchronous I/O efficiently.
The Chain of Responsibility [GoF95] pattern decouples event handlers from event sources. The Proactor pattern is similar in its segregation of initiators and completion handlers. In the Chain of Responsibility pattern, however, the event source has no prior knowledge of which handler will be executed, if any. In Proactor, initiators have full control over the target completion handler. The two patterns can be combined by establishing a completion handler that is the entry point into a responsibility chain dynamically configured by an external factory.
Current Java implementations do not support Proactor-like event processing schemes, because java.io does not support asynchronous I/O. In basic Java implementations blocking I/O operations can even block the whole Java Virtual Machine (JVM)—the I/O operation blocks the current thread and, as multi-threading may be implemented in user space, the operating system considers the task running the JVM as blocked and schedules other operating system processes instead of other JVM threads.
More sophisticated Java implementations work around this problem by implementing asynchronous I/O internally on the native code level—the thread doing the blocking call is blocked, but other threads are able to run. The blocked thread is subsequently called back, or may explicitly wait for the blocking call to return. Applications cannot make use of this directly, however, because current JDK libraries do not expose asynchronous I/O. This will change with the next generation of the Java I/O system, which is under development and will appear as a package called java.nio or something similar [JSR51].
Certain programming languages, such as Scheme, support continuations. Continuations can be used in single-threaded programs to enable a sequence of function calls to relinquish its run-time call stack when blocked without losing the execution history of the call stack. In the context of the Proactor pattern, the indirect transfer of control from an asynchronous operation invocation to the subsequent processing by its completion handler can be modeled as a continuation.
Tim Harrison, Thomas D. Jordan, and Irfan Pyarali are co-authors of the original version of the Proactor pattern. Irfan also provided helpful comments on this version. Thanks to Ralph Johnson for suggestions that helped improve this pattern and for pointing out how this pattern relates to the programming language feature continuations.