Now that you’ve read about how IBM uniquely handles the largest data analytical problems in a Hadoop environment that’s hardened for the enterprise, let’s turn our attention to the other side of the IBM Big Data story: analytics for data in motion. Using BigInsights gives you a competitive advantage by helping you with the ocean of information out there, and IBM InfoSphere Streams (Streams) gives you insights from the Niagara Falls of data flowing through your environment. You can either tap into that flow to gain time-sensitive competitive advantages for your business, or you can be like most people at Niagara Falls, and simply watch in awe as the mighty river flows past. This is where Streams comes in. Its design lets you leverage massively parallel processing (MPP) techniques to analyze data while it is streaming, so you can understand what is happening in real time and take action, make better decisions, and improve outcomes.
Before we delve into this chapter, let’s start by clarifying what we mean by Streams and streams; the capitalized version refers to the IBM InfoSphere Streams product, and the lowercase version refers to a stream of data. With that in mind, let’s look at the basics of Streams, its use cases, and some of the technical underpinnings that define how it works.
Streams is a powerful analytic computing platform that delivers a platform for analyzing data in real time with micro-latency. Rather than gathering large quantities of data, manipulating the data, storing it on disk, and then analyzing it, as would be the case with BigInsights (in other words, analytics on data at rest), Streams allows you to apply the analytics on the data in motion. In Streams, data flows through operators that have the ability to manipulate the data stream (which can comprise millions of events per second), and in-flight analysis is performed on the data. This analysis can trigger events to enable businesses to leverage just-in-time intelligence to perform actions in real time ultimately yielding better results for the business. After flowing the data through the analytics, Streams provides operators to store the data into various locations (including BigInsights or a data warehouse among others) or just toss out the data if it is deemed to be of no value by the in-flight analysis (either because it wasn’t interesting data or the the data has served its purpose and doesn’t have persistence requirements).
If you are already familiar with Complex Event Processing (CEP) systems, you might see some similarities in Streams. However, Streams is designed to be much more scalable and is able to support a much higher data flow rate than other systems. In addition, you will see how Streams has much higher enterprise-level characteristics, including high availability, a rich application development toolset, and advanced scheduling.
You can think of a stream as a series of connected operators. The initial set of operators (or a single operator) are typically referred to as source operators. These operators read the input stream and in turn send the data downstream. The intermediate steps comprise various operators that perform specific actions. Finally, for every way into the in-motion analytics platform, there are multiple ways out, and in Streams, these outputs are called sink operators (like the water that flows out of the tap and into your kitchen sink). We’ll describe all of these operators in detail later in this chapter.
We refer to Streams as a platform because you can build or customize Streams in almost any possible way to deliver applications that solve business problems; of course, it’s an enterprise capable platform because each of these operators can be run on a separate server in your cluster to improve availability, scalability, and performance. For example, Streams provides a rich tooling environment to help you design your streaming applications (covered later in this chapter). Another nice thing is that Streams shares the same Text Analytics Toolkit with BigInsights, allowing you to reuse skills and code snippets across your entire Big Data platform. When you’re ready to deploy your streaming application, Streams autonomically decides, at runtime, where to run the processing elements (PEs) based on cluster-based load balancing and availability metrics, allowing it to reconfigure operators to run on other servers to ensure the continuity of the stream in the event of server or software failures. You can also programmatically specify which operators run on which servers and run your streams logic on specific servers.
This autonomic streaming and customizable platform allows you to increase the number of servers performing analysis on the stream simply by adding additional servers and assigning operators to run on those servers. The Streams infrastructure ensures that the data flows successfully from one operator to another, whether the operators are running on distinct servers or on the same server: This provides a high degree of agility and flexibility to start small and grow the platform as needed.
Much like BigInsights, Streams is ideally suited not only for structured data, but for the other 80 percent of the data as well—the nontraditional semi-structured or unstructured data coming from sensors, voice, text, video, financial, and many other high-volume sources. Finally, since Streams and BigInsights are part of the IBM Big Data platform, you’ll find enormous efficiencies in which the analytics you build for in-motion or at-rest Big Data can be shared. For example, the extractors built from the Text Analytic Toolkit can be deployed in Streams or BigInsights.
To give you some insight into how Streams technology can fit into your environment, we thought we would provide some industry use case examples. Obviously, we can’t cover every industry in such a short book, but we think this section will get you thinking about the breadth of possibilities that Streams technology can offer your environment (get ready because your brain is going to shift into overdrive with excitement).
The financial services sector and its suboperations are a prime example for which the analysis of streaming data can provide a competitive advantage (as well as regulatory oversight, depending on your business). The ability to analyze high volumes of trading and market data, at ultra low latencies, across multiple markets and countries simultaneously, can offer companies the microsecond reaction times that can make the difference between profit and loss via arbitrage trading and book of business risk analysis (for example, how does such a transaction occurring at this very moment add to the firm’s risk position?).
Streams can also be used by FSS companies for real-time trade monitoring and fraud detection. For example, Algo Trading supports average throughput rates of about 12.7 million option market messages per second and generates trade recommendations for its customers with a latency of 130 microseconds. As discussed later in this chapter, there are even adapters integrated into Streams that provide direct connectivity via the ubiquitous Financial Information eXchange (FIX) gateways with a function-rich library to help calculate theoretical Put and Call option values. Streams can even leverage multiple types of inputs. For example, you could use Streams to analyze impeding weather patterns and their impact on security prices as part of a short-term hold position decision.
Similarly, real-time fraud detection can also be used by credit card companies and retailers to deliver fraud and multi-party fraud detection (as well as to identify real-time up-sell or cross-sell opportunities).
Healthcare equipment is designed to produce diagnostic data at a rapid rate. From electrocardiograms, to temperature and blood pressure measuring devices, to blood oxygen sensors, and much more, medical diagnostic equipment produces a vast array of data. Harnessing this data and analyzing it in real time delivers benefits unlike any other industry; that is, in addition to providing a company with a competitive advantage, Streams usage in healthcare is helping to save lives.
For example, the University of Ontario Institute of Technology (UOIT) is building a smarter hospital in Toronto and leveraging Streams to deliver a neonatal critical care unit that monitors the health of what we’ll lovingly and affectionately call these little miracles, “data babies.” These babies continually generate data in a neonatal ward: every heartbeat, every breath, every anomaly, and more. With more than 1000 pieces of unique information per second of medical diagnostic information, the Streams platform is used as an early warning system that helps doctors find new ways to avoid life-threatening infections up to 24 hours sooner than in the past. There is a synergistic effect at play here, too. It could be the case that separately monitored streams absolutely fall within normal parameters (blood pressure, heart rate, and so on); however, the combination of several streams with some specific value ranges can turn out to be the predictor of impending illness. Because Streams is performing analytics on moving data instead of just looking for out of bound values, it not only has the potential to save lives, but it also helps drive down the cost of healthcare (check it out at: http://www.youtube.com/watch?v=QVbnrlqWG5I).
The quantity of call detail records (CDRs) that telecommunications (telco) companies have to manage is staggering. This information is not only useful for providing accurate customer billing, but a wealth of information can be gleaned from CDR analysis performed in near real time. For example, CDR analysis can help to prevent customer loss by analyzing the access patterns of “group leaders” in their social networks. These group leaders are people who might be in a position to affect the tendencies of their contacts to move from one service provider to another. Through a combination of traditional and social media analysis, Streams can help you identify these individuals, the networks to which they belong, and on whom they have influence.
Streams can also be used to power up a real-time analytics processing (RTAP) campaign management solution to help boost campaign effectiveness, deliver a shorter time-to-market for new promotions and soft bundles, help find new revenue streams, and enrich churn analysis. For example, Globe Telecom leverages information gathered from its handsets to identify the optimal service promotion for each customer and the best time to deliver it, which has had profound effects on its business. Globe Telecom reduced from 10 months to 40 days the time-to-market for new services, increased sales significantly through real-time promotional engines, and more.
What’s good for CDRs can also be applied to Internet Protocol Detail Records (IPDRs). IPDRs provide information about Internet Protocol (IP)–based service usage and other activities that can be used by operational support to determine the quality of the network and detect issues that might require maintenance before they lead to a breakdown in network equipment. (Of course, this same use case can be applied to CDRs.) Just how real-time and low-latency is Streams when it comes to CDR and IPDR processing? We’ve seen supported peak throughput rates of some detail records equal to 500,000 per second, with more than 6 billion detail records analyzed per day (yes, you read that rate right) on more than 4 PBs (4000 TBs) of data per year; CDR processing with Streams technology has sustained rates of 1 GBps, and X-ray Diffraction (XRD) rates at 100 MBps. Truly, Streams is game changing technology.
Streams provides a huge opportunity for improved law enforcement and increased security, and offers unlimited potential when it comes to the kinds of applications that can be built in this space, such as real-time name recognition, identity analytics, situational awareness applications, multimodal surveillance, cyber security detection, wire taps, video surveillance, and face recognition. Corporations can also leverage streaming analytics to detect and prevent cyber attacks by streaming network and other system logs to stop intrusions or detect malicious activity anywhere in their networks.
TerraEchos uses InfoSphere Streams to provide covert sensor surveillance systems to enable companies with sensitive facilities to detect intruders before they even get near the buildings or other sensitive installations. They’ve been a recipient of a number of awards for their technology (the Frost and Sullivan Award for Innovative Product of the Year for their Fiber Optic Sensor System Boarder Application, among others). The latest version of Streams includes a brand new development framework, called Streams Processing Language (SPL), which allows them to deliver these kinds of applications 45 percent faster than ever before, making their capability, and the time it takes to deliver it, that much faster.
As we said, we can’t possibly cover all the use cases and industries that a potent product such as Streams can help solve, so we’ll cram in a couple more, with fewer details, here in this section.
Government agencies can leverage the broad real-time analytics capabilities of Streams to manage such things as wildfire risks through surveillance and weather prediction, as well as manage water quality and water consumption through real-time flow analysis. Several governments are also improving traffic flow in some of their most congested cities by leveraging GPS data transmitted via taxis, traffic flow cameras, and traffic sensors embedded in roadways to provide intelligent traffic management. This real-time analysis can help them predict traffic patterns and adjust traffic light timings to improve the flow of traffic, thereby increasing the productivity of their citizens by allowing them to get to and from work more efficiently.
The amount of data being generated in the utilities industry is growing at an explosive rate. Smart meters as well as sensors throughout modern energy grids are sending real-time information back to the utility companies at a staggering rate. The massive parallelism built into Streams allows this data to be analyzed in real time such that energy distributors and generators are able to modify the capacity of their electrical grids based on the changing demands of consumers. In addition, companies can include data on natural systems (such as weather or water management data) into the analytics stream to enable energy traders to meet client demand while at the same time predicting consumption (or lack of consumption) requirements to deliver competitive advantages and maximize company profits.
Manufacturers want more responsive, accurate, and data rich quality records and quality process controls (for example, in the microchip fabrication domain, but applicable to any industry) to better predict, avoid, and determine defined out of tolerance events and more. E-science domains such as space weather prediction, detection of transient events, and Synchrotron atomic research are other opportunities for Streams. From smarter grids, to text analysis, to “Who’s talking to Whom?” analysis, and more, Streams use cases, as we said earlier, are nearly limitless.
As mentioned, Streams is all about analytics on data in motion. You can think of a stream as somewhat like a set of dominoes in a line. When you push the first one over, you end up with a chain reaction (assuming you have lined everything up right) where the momentum of one falling domino is enough to start the next one falling and so on. If you are good, you can even have the line of dominoes split into several lines of simultaneously falling tiles and then merge them back together at some point down the line. In this way you have many dominoes falling in parallel, all feeding the momentum to the next dominoes in their line. (In case you are wondering, according to the Guinness Book of World Records, the greatest number of dominoes toppled by a group at one time is over 4.3 million.) Streams is similar in nature in that some data elements start off a flow which moves from operator to operator, with the output of one operator becoming the input for the next. Similarly, a record, or tuple, of data can be split into multiple streams and potentially joined back together downstream. The big difference of course is that with the game Dominoes, once a tile falls down, that’s the end of it, whereas with Streams, the data continuously flows through the system at very high rates of speed, allowing you to analyze a never-ending flow of information continuously.
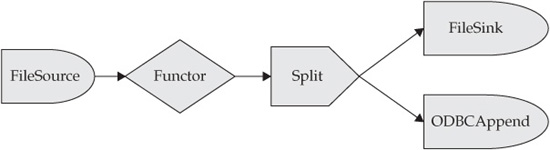
In a more technical sense, a stream is a graph of nodes connected by edges. Each node in the graph is an operator or adapter that will process the data within the stream in some way. Nodes can have zero or more inputs and zero or more outputs. The output (or outputs) from one node is connected to the input (or inputs) of another node or nodes. The edges of the graph that join the nodes together represent the stream of data moving between the operators. Figure 6-1 represents a simple stream graph that reads data from a file, sends the data to an operator known as a functor (this operator transforms incoming data in some programmatic manner), and then feeds that data to another operator. In this figure, the streamed data is fed to a split operator, which then feeds data to either a file sink or a database (depending on what goes on inside the split operator).
Figure 6-1 A simple data stream that applies a transformation to some data and splits it into two possible outputs based on some predefined logic.
Data flows through a stream in what are known as tuples. In a relational database sense, you can think of them as rows of data. However, when Streams works on semistructured and unstructured data, a tuple is an abstraction to represent a package of data. Think of a tuple as a set of attributes for a given object. Each element in the tuple contains the value for that attribute, which can be a character string, a number, a date, or even some sort of binary object.
Some operators work on an individual tuple, transforming the data and then passing it along. Other operators need to work on groups of tuples before they send out results. Consider, for example, a sort operation: you can’t sort data by simply working on one tuple at a time. You must have a set of data that you can put into sorted order and then pass along. For this reason, some operators work on a window of data, which is essentially a set of tuples that are grouped together. The operator itself will define how many tuples are in the window based on the window expression inside the operator. For example, the operator can define a window to be the next N tuples that come into the operator, or it could define the window to be any tuple that enters the operator in the next M seconds. There are many other ways to define a window, and in fact some windows can be moving (so they define a sliding window of tuples) and others are more batching (they group together a set of tuples, empty the operator of all those tuples at some certain point in time or event, and subsequently group together the next set). We discuss windowing later in this chapter where we talk about the various operators, but it’s an important concept to understand in that Streams is not just about manipulating one tuple at a time, but rather analyzing large sets of data in real time.
The Streams Processing Language (SPL) is a structured application development language that is used by Streams to create your applications. It’s a higher generation and more productive programming framework for Streams than what was available in past releases; in fact, one customer claims up to 45 percent productivity improvements in their Streams applications because of the rich SPL. After all, technology is great, but if you can’t quickly apply it to the business need at hand, what’s the point?
Streams-based applications written in SPL are compiled using the Streams compiler, which turns them into binary (bin) executable code, which then runs in the Streams environment to accomplish the tasks on the various servers in the cluster. An SPL program is a text-based representation of the graph we discussed in the preceding section: It defines the sources, sinks, and operators between them that in turn define the stream processing and how each operator will behave within the stream. Later in this chapter, we talk about the application development tooling that makes building Streams applications simple. But in the same way children learn to multiply in their head before being allowed to use a calculator, we are going to look at SPL before showing you the easy application development tooling. For example, the following SPL code snippet represents a simple stream from one source, through a single operator, and to an eventual single sink:

In this SPL snippet, the FileSource operator reads data from the specified file and puts it into a stream called LineStream. The operator in this case is called a Functor operator, which converts data from the stream to the uppercase text of that stream and puts that tuple on an output stream called upperedTxt. The Sink operator then reads the upperedTxt stream of data and sends it, in this case, to standard output.
This snippet represents the simplest stream with a single source, a single operation, and a single sink. Of course, the power of Streams is that it can run massively parallel jobs across large clusters of servers where each operator, or a group of operators, can be running on a separate server. But before we get into the enterprise class capabilities of Streams, let’s look at the various adapters that are available with this product.
It goes without saying that in order to perform analysis on a stream of data, the data has to enter the stream. Of course, a stream of data has to go somewhere when the analysis is done (even if somewhere is defined as a void where bits just get dumped into “nowhere”). Let’s look at the most basic source adapters available to ingest data along with the most basic sink adapters to which data can be sent.
As the names imply, FileSource and FileSink are standard adapters used to read or write to a file. You use parameters to specify the name and location of the file used for the read or write operation. Another parameter identifies the format of the file’s contents, which could be any of the following:
txt Simple text files, where each tuple is a row in the file
csv Files that contain comma-separated values
bin Files that contain binary data tuples
line Files that contain lines of text data
block An input stream made up of binary data blocks (much like a BLOB)
There are a number of other optional parameters that can be used to specify, for example, column separators, end of line markers, delimiters, and more.
The TCPSource and TCPSink adapters are the basic TCP adapters used in Streams to read and write to a socket. When you use these adapters, you specify the IP address (using either IPv4 or IPv6) along with the port, and the adapter will read from the socket and generate tuples into the stream. These adapters’ parameters are the same as the FileSource and FileSink adapters in terms of the format of the data flow (txt, csv, and so on). The UDPSource and UDPSink adapters read from and write to a UDP socket in the same manner as the TCP-based adapters.
The export and import adapters work together within a stream. You can export data using the export adapter and assign the exported stream a streamID. Once the stream is assigned this ID, any other stream application in the same instance can import this data using the assigned streamID. Using export and import is a great way to stream data between applications running under the same Streams instance.
The MetricsSink adapter is a very interesting and useful sink adapter because it allows you to set up a named meter, which is incremented whenever a tuple arrives at the sink. You can think of these meters as a gauge that you can monitor using Streams Studio or other tools. If you’ve ever driven over one of those traffic counters (those black rubber tubes that seem to have no purpose, rhyme, or reason for lying across an intersection or road) you’ve got the right idea, and while a traffic counter measures the flow of traffic through a point of interest, a MetricsSink can be used to monitor the volume and velocity of data flowing out of your data stream.
Quite simply, operators are at the heart of the Streams analytical engine. They take data from upstream adapters or other operators, manipulate that data, and then move the resulting tuples downstream to the next operator. In this section we discuss some of the more common Streams operators that can be strung together to build a Streams application.
The filter operator is similar to a filter in an actual water stream, or in your furnace or car: its purpose is to allow only some of the streaming contents to pass. A Streams filter operator removes tuples from a data stream based on a user-defined condition specified as a parameter to the operator. Once you’ve programmatically specified a condition, the first output port defined in the operator will receive any tuples that satisfy that condition. You can optionally specify a second output port, to receive any tuples that did not satisfy the specified condition. (If you’re familiar with extract, transform, and load [ETL] flows, this is similar to a match and discard operation.)
The functor operator reads from the input stream, transforms them in some way, and sends those tuples to an output stream. The transformation applied can manipulate any of the elements in the stream. For example, you could extract a data element out of a stream and output the running total of that element for every tuple that comes through a specific functor operator.
The punctor operator adds punctuation into the stream, which can then be used downstream to separate the stream into multiple windows. For example, suppose a stream reads a contact directory listing and processes the data flowing through that stream. You can keep a running count of last names in the contact directory by using the punctor operator to add a punctuation mark into the stream any time your application observes a change in the last name in the stream. You could then use this punctuation mark downstream in an aggregation functor operator to send out the running total for that name, later resetting the count back to 0 to start counting the next set of last names.
The sort operator is fairly easy to understand in that it simply outputs the same tuples it receives, but in a specified sorted order. This is the first operator we’ve discussed that uses a stream window specification. Think about it for a moment: if a stream represents a constant flow of data, how can you sort the data, because you don’t know if the next tuple to arrive will need to be sorted to the first tuple you must send as output? To overcome this issue, Streams allows you to specify a window on which you want to operate. You can specify a window of tuples in a number of ways:

In addition to specifying the windowing option, you must also specify the expression that defines how you want the data sorted (for example, sort by a given attribute in the stream). Once the window fills up, the sort operator will sort the tuples based on the element you specified, and sends those tuples to the output port in the defined sorted order (then it goes back to filling up the window again). By default, Streams sorts in ascending order, but you can also specify that you want a descending sort.
As you’ve likely guessed, the join operator takes two streams, matches the tuples on a user-specified condition, and then sends the matches to an output stream. When a row arrives on one input stream, the matching attribute is compared to the tuples that already exist in the operating window of the second input stream to try to find a match. Just as in a relational database, several types of joins can be used, including inner joins (in which only matches will be passed on) and outer joins (which can pass on one of the stream tuples, even without a match in addition to matching tuples from both streams). As with the sort operator, you must specify a window of tuples to store in each stream in order to join them.
The aggregate operator can be used to sum up the values of a given attribute or set of attributes for the tuples in the window; this operator also relies on a windowing option to group together a set of tuples to address the same challenges outlined in the “Sort” section. An aggregate operator also allows for groupBy and partitionBy parameters to divide up the tuples in a window and perform an aggregation on those smaller subsets of tuples. You can use the aggregate operator to perform count, sum, average, max, min, first, last, count distinct, and other forms of aggregation.
A beacon is a useful operator because it’s used to create tuples on the fly. For example, you can set up a beacon to send tuples into a stream at various intervals defined either by a time period (send a tuple every n tenths of a second) and/or by iteration (send out n tuples and then stop). The beacon operator can be useful in testing and debugging your Streams applications.
Two other useful operators can help you manipulate the timing and flow of a given stream: throttle and delay. The throttle operator helps you to set the “pace” of the data flowing through a stream. For example, tuples that are arriving sporadically can be sent to the output of the throttle operator at a specified rate (as defined by tuples per second). Similarly, the delay operator can be used to change the timing of the stream. A delay can be set up simply to output tuples after a specific delay period; however, with delay, the tuples exit the operator with the same time interval that existed between the tuples when they arrived. That is, if tuple A arrives 10 seconds before tuple B, which arrives 3 seconds before tuple C, then the delay operator will maintain this timing between tuples on exit, after the tuples have been delayed by the specified amount of time.
The split operator will take one input stream and, as the name suggests, split that stream into multiple output streams. This operator takes a parameterized list of values for a given attribute in the tuple and matches the tuple’s attribute with this list to determine on which output stream the tuple will be sent out. The union operator acts in reverse: it takes multiple input streams and combines all the tuples that are found in the input streams into an output stream.
In addition to the adapters and operators described previously, Streams also ships with a number of rich toolkits that allow for even faster application development. These toolkits allow you to connect to specific data sources and manipulate data that is commonly found in databases, financial markets, and much more. Because the Streams toolkits can accelerate your time to analysis with Streams, we figure it’s prudent to spend a little time covering them here in more detail; specifically, we’ll discuss the Database Toolkit and the Financial Markets Toolkit section.
The Database Toolkit allows a stream to read or write to an ODBC database or from a SolidDB database. This allows a stream to query an external database to add data or verify data in the stream for further analysis. The operators available in this Streams toolkit include the following:

The Financial Information eXchange (FIX) protocol is the standard for the interchange of data to and from financial markets. This standard defines the data formats for the exchange of information related to securities transactions. The Streams Financial Markets Toolkit provides a number of FIX protocol adapters such as:

In addition to these operators, other useful components such as market simulation adapters to simulate market quotes, trades, orders, and more are provided with this toolkit. It also includes adapters for WebSphere MQ messages and WebSphere Front Office for financial markets. All in all, this toolkit greatly reduces the time it takes to develop, test, and deploy stream processes for analyzing financial-based market data.
Many real-time application and parallel processing environments built in the past have come and gone; what makes Streams so different is its enterprise class architecture and runtime environment which are powerful and robust enough to handle the most demanding streaming workloads. This is the value that IBM and its research and development arms bring to the Big Data problem. Although some companies have massive IT budgets to try and do this themselves, wouldn’t it make sense to invest those budgets in core competencies and the business?
Large, massively parallel jobs have unique availability requirements because in a large cluster, there are bound to be failures. The good news is that Streams has built-in availability characteristics that take this into account. Also consider that in a massive cluster, the creation, visualization, and monitoring of your applications is a critical success factor in keeping your management costs low (as well as the reputation of your business high). Not to worry: Streams has this area covered, too. Finally, the integration with the rest of your enterprise architecture is essential to building a holistic solution rather than a stove pipe or single siloed application. It’s a recurring theme we talk about in this book: IBM offers a Big Data platform, not a Big Data product.
In this section, we cover some of the enterprise aspects of the Big Data problem for streaming analytics: availability, ease of use, and integration.
When you configure your Streams platform, you tell a stream which hosts (servers) will be part of the Streams instance. You can specify three types of hosts for each server in your platform:
• An application host is a server that runs SPL jobs.
• A management host runs the management services that control the flow of SPL jobs (but doesn’t explicitly run any SPL jobs directly), manages security within the instance, monitors any running jobs, and so on.
• A mixed host can run both SPL jobs and management tasks.
In a typical environment you would have one management host and the remainder of your servers would be used as application hosts.
When you execute a streaming application, the processing elements (PEs) can each execute on a different server, because, quite simply, PEs are essentially the operators and adapters that make up your streaming application. For example, a source operator can run on one server, which would then stream tuples to another server running operator A, which could then stream tuples to another server running operator B. The operator on this last server would then stream tuples to the sink operator running on yet another server.
In the event of a PE failure, Streams will automatically detect the failure and take any possible remediation actions. For example, if the PE is restartable and relocatable, the Streams runtime will automatically pick an available host on which to run the job and start that PE on that host (and “rewire” the inputs and outputs to other servers as appropriate). However, if the PE continues to fail over and over again (perhaps due to a recurring underlying hardware issue), a retry threshold indicates that after that number of retries is met, the PE will be placed into a stopped state and will require manual intervention to resolve the issue. If the PE is restartable, but has been defined as not relocatable (for example, the PE is a sink that requires it to be run on a specific host), the Streams runtime will automatically attempt to restart the PE on the same host, if it is available. Likewise, if a management host fails, you can have the management function restarted elsewhere, assuming you have configured the system with RecoveryMode=ON. In this case, the recovery database will have stored the necessary information to restart the management tasks on another server in the cluster.
Consumability: Making the Platform Easy to Use
Usability means deployability. Streams comes with an Eclipse-based visual toolset called InfoSphere Streams Studio (Streams Studio), which allows you to create, edit, test, debug, run, and even visualize a Streams graph model and your SPL applications. Much like other Eclipse-based application development add-ins, Streams Studio has a Streams perspective which includes a Streams Explorer to manage Streams development projects. The Streams perspective also includes a graphical view that lets you visualize the stream graph from one or more sources to one or more sinks and lets you manipulate the graph to manage the application topology.
When you are running an SPL application, Streams Studio provides a great deal of added benefits. Built-in metrics allow you to view the streaming application to surface key runtime characteristics such as the number of tuples in and out of each operator, and more. A log viewer lets you view the various logs on each of the Streams cluster’s servers, and an interactive debugger lets you test and debug your applications.
If you click a Streams operator in Streams Studio it opens the SPL editor for that specific operator, which is infused with all sorts of syntax and semantic-related items that make coding the task at hand easier as it steps you through the development process. Finally, there’s an integrated help engine that comes in awfully handy when you’re developing, debugging, and deploying your Streams applications. All in all, Streams Studio offers the ease of use you would expect from a feature-rich application integrated development environment (IDE) that is part of the full Streams platform, rather than just the parallel execution platform that other vendors offer.
The final aspect of an enterprise class solution is how well it integrates into your existing enterprise architecture. As we’ve discussed previously, Big Data is not a replacement for your traditional systems; it’s there to augment them. Coordinating your traditional and new age Big Data processes takes a vendor that understands both sides of the equation. As you’ve likely deduced after reading this chapter, Streams already has extensive connection capability into enterprise assets, such as relational databases, in-memory databases, WebSphere queues, and more.
In the preceding section, we briefly talked about Streams’ Eclipse-based IDE plug-in and monitoring infrastructure, which allows it to fit into existing application development environments such as Rational or other toolsets based on the widespread de facto standard open source Eclipse framework (which IBM invented and donated to open source, we might add). But that’s just the beginning: Streams has sink adapters that allow streaming data to be put into a BigInsights Hadoop environment with a high-speed parallel loader for very fast delivery of streaming data into BigInsights (via the BigInsights Toolkit for Streams) or directly into your data warehouse for your data-at-rest analysis.
As we’ve talked about throughout this book, Big Data problems require the analysis of data at rest and data in motion, and the integration of Streams and BigInsights offers a platform (not just products) for the analysis of data in real time, as well as the analysis of vast amounts of data at rest for complex analytical workloads. IBM gives you the best of both worlds, and it is brought together under one umbrella with considerations for security, enterprise service level agreement expectations, nationalization of the product and support channels, enterprise performance expectations, and more.