If we want to write a function that returns the larger of two numbers, and we want this function to be used for both integer variables and double precision floating point variables, then we could use function overloading and write two functions: one for integer variables and the other for double precision floating point variables. Both of these functions would require only a few lines of code, and it would not be difficult to maintain both functions. For larger functions maintaining more than one function to do the same operations may be problematic. This may be avoided by the use of templates, a feature of the C++ language that allows very general code to be written.
We begin this chapter by discussing templates and the flexibility that they permit. One library associated with C++ is the Standard Template Library (STL): we conclude this chapter by giving a brief survey of this library, and other functionality that has been introduced in recent C++ standards.
8.1 Templates to Control Dimensions and Verify Sizes
Many scientific computing applications are underpinned by vectors and matrices. We have seen earlier that these are represented in C++ by arrays. Under normal circumstances there is no check, when we attempt to access elements of an array, that the index is a valid index. For example, in the code fragment below we attempt to access the element with index 7 when the array only has 5 elements. Although this is clearly an error, it may not trigger a compiler or run-time error. The most likely outcome when code including these lines is executed is a segmentation fault or an incorrect answer.
If this fragment is part of a large program, it could be difficult to locate this error. It would be therefore be useful if we could use arrays with an additional feature that a check for validity of the index is performed each time an element of the array is accessed. This may be achieved using the class shown below, which is referred to as a templated class.
The class in the listing above allows us to declare instances of DoubleVector, specifying the length of the array. The entries of the array are private members of this class and so can’t be accessed in the normal way that we would access elements of an array. Instead we access members of this class by overloading the square bracket operator. Overloading this operator allows us to check that the index is a valid index before returning the variable requested.
Use of the class above is demonstrated in the code below. Note (in line 6) how using this class requires us to declare the array v as an instance of a DoubleVector, with the size of this array being enclosed within pointed brackets. Subsequently this array is accessed in exactly the same way as a normal array, but with the additional feature that a check is carried out on the index every time an element of the array is accessed through the overloading of the square bracket operator.
8.2 Templates for Polymorphism
There are very good reasons in C++, and many other programming languages, for distinguishing between integer variables and floating point variables. For example, the argument(s) used to access an element of an array may only take integer values which provides one level of validation that the index is correct. Furthermore, integers may be stored much more efficiently than floating point variables. One slight drawback in having to distinguish between these variables is that if we want to write a function that is valid for all numerical variables—that is, both integers and floating point variables—we have to write more than one instance of the same function. Templates, however, provide a way around this.
The program below demonstrates how a function GetMaximum that returns the maximum of two numbers, either integers or floating point variables, may be written. The code is very similar to the code that we would write to calculate the maximum of two numbers, although there are two important differences. The first difference is that the function prototype in line 3 of the listing specifies that the function is defined for a general class T, and that the return type and both function arguments will be instances of the same class T. To call the function, we have to put the data type used in angled brackets as is shown in lines 7 and 8 of the listing. The function GetMaximum demonstrates polymorphism, because it can perform the same operation on different types of input argument. This type of polymorphism is also called static polymorphism or compile-time polymorphism, because when the compiler sees line 7 or 8 of the listing it makes a specific version of GetMaximum ready for the int or double type.
8.3 A Brief Survey of the Standard Template Library
The Standard Template Library (STL) contains many commonly used patterns that may be reused for different types of objects. In this survey, we give a summary of the features available that are particularly relevant to writers of scientific software.
Containers, such as random-access vectors and sets, are dynamic arrays where the STL is responsible for memory management. We now demonstrate how these two containers may be used. Other containers that are available in the STL are maps, multimaps, multisets, lists and deques (double-ended queues, pronounced “decks”). There are also many more algorithms that may be performed on these containers other than those presented here. Some of these other containers and algorithms do not have application in scientific computing software and so we do not discuss them here. Nevertheless, it is useful for readers to be aware that they exist.
8.3.1 Vectors
The STL vector class is a very useful container because it is an extensible class which has a similar interface to the regular C++ array. The fact that it is extensible means that its size is not fixed (either at compile time or at the time that it is created) and that it will grow to accommodate new items as necessary. One can either declare an empty STL vector of minimal capacity which then grows by adding new items to it, or one can exploit efficiency savings by knowing the maximum size at compile time or run time.
If you explore available STL containers, you will notice that the interface for the STL vector is very similar to the interface for the other basic container types deque and list. This is a good example of object abstraction, because the details which distinguish these container types from each other are not exposed to the user. The main differences between these types of containers are in the efficiency which STL guarantees for various operations: it is possible to retrieve an item from an STL vector via its index in a single operation, but this is not possible from an STL list. It is generally only efficient to insert and delete elements to the back of a vector object and to the front or back of a deque. The list type allows efficient constant time insertion and deletion anywhere in the container.
The use of the vector container is shown in the listing below. Several features of the STL are included in this listing which we now highlight.
To use the vector container, we must include the vector header file (line 2). For some algorithms that may be used on STL vectors, such as sorting, we must include the algorithm header file (line 3).
In line 8, we declare a vector of strings called destinations. Note that we do not have to state the size of the vector: the STL will handle this for us. We can write if we wished to begin with a vector of 50 empty strings rather than an empty vector.
In line 9, we reserve 6 elements. This sets the vector’s capacity without changing the number of items in the vector. Although this line is unnecessary, it may produce efficiency savings in more memory-intensive code because it establishes that 6 items can be stored in the vector without having to reallocate any memory later.
In line 10, we introduce our first entry to the vector, the string “Paris”. The member function push_back appends a copy of this string to the current vector, which is currently empty.
In line 11, we append another entry to the end of the vector, that is, the second entry of this vector is “New York”.
In line 12, we append a further entry to the vector, that is, the third entry of this vector is “Singapore”.
In lines 13 and 14, we demonstrate the use of the member function size for accessing the number of elements of the vector.
In lines 17–20, we show that entries of the vector may be accessed in the same way as for a standard vector.
Lines 22–26 demonstrate how to access entries of the vector using an iterator. The iterator is declared in line 22, where we define what type of vector the iterator is associated with, that is, in this case a vector of strings. In line 23, we construct a for loop that iterates from the start of the vector to the end of the vector using this iterator. The entries are printed using line 25, which prints out the contents of the vector entry that the iterator is pointing at. Note the use of the overloaded * operator which looks like a pointer de-reference.
In line 28, we add a string to the start of a vector by using the insert method, and inserting at the start of the vector using the begin method: all subsequent entries are now moved one place back.
In line 29, we add a string to the vector, and place it in the second position: all subsequent entries are again moved one place back.
In line 30, we add another entry to the end of the vector. We then print out the number of entries of the vector, and the entries, using lines 31–38.
In lines 40 and 41, we erase all entries of the vector that appear after the third entry, and then print out the number of entries of the vector, and the entries, using lines 42–49.
In line 51, we use the algorithm sort: this algorithm will sort a vector of strings into alphabetical order and requires the header file algorithm as described above. This is verified by printing the entries of the vector using lines 52–59.
8.3.2 Sets
A set is an STL container where new entries are only stored if they are distinct from the entries already stored. The machinery for maintaining the distinctness of the entries is abstracted from the user. One might implement a set as an unordered list of elements, so that each insertion requires a membership test that may involve an equality check with all elements of the existing set. One might make a more efficient implementation using an ordered list, so that membership tests involve fewer equality checks against existing members. The STL set actually uses a more efficient structure1 so that it is able to guarantee the efficiency of all possible set operations. It is only possible to make an efficient set implementation if the elements of the set can be ordered. We will demonstrate the set container by using the class of points in two dimensions whose members have coordinates that take integer values. As the items in a set have to be comparable, we need to define an ordering on points in two dimensions, which we do by overloading the “less than” operator for these points. If we are comparing two points and , which represent the points () and (), we say that if , and if . Only if we say that if , and if . If and then the points and are identical: the set would only store one instance of these two.
The class Point2d representing the class of points in two dimensions is given in the listing below. This class has two member variables, x and y, that store the x- and y-coordinates. There is also a constructor that allows us to initialise the coordinates, and an overloaded “less than” operator that allows us to order points in two dimensions as described above.
In the listing below, we create a set of instances of the class Point2d. When using the set container, we must include the set header file (line 1). In line 7 we create a set, made up of instances of the class Point2d, that is called points. In lines 9–12, we attempt to insert four points into this set using the insert method associated with sets. Two of these points—the origin and the point (0, 0)—are identical, and so only one is stored. This is seen in lines 14 and 15 where we print out the size of the set, which is 3. Note how the iterator may be used in lines 17–21 of the code to print the member variables of the class of points in line 20.
8.4 A Survey of Some New Functionality in Modern C++
At the close of Chap. 4 we thought it pertinent to give you an indication that some features of C++ have moved on since the first edition of this book was written. In Sect. 4.4 we introduced two of the new smart pointer constructs which have been implemented in compilers that conform to modern C++ standards. This enabled us to indicate that, whereas in former days all dynamically allocated memory was the responsibility of the programmer, there are now ways to ensure that certain pointers are not aliased (via the unique_ptr type) and to automatically garbage collect certain variables (via shared_ptr).
Now, towards the close of this chapter, we would like to introduce a selection of some of the other features available in modern C++ standards such as C++11. With the exception of smart pointers, we have deferred writing about any of these new features until now because most of the features are templated over a type. By introducing modern C++ features here we only intend to scratch the surface. As in Sect. 8.3, this section is intended only as a brief survey of some of the available features. We have deliberately selected those features which we have found most helpful in the years since we wrote the first edition of this book—in the belief that these features will prove useful to other computational scientists.
Note that with a current version of the GNU C++ compiler, all code fragments in this section require that the compiler is explicitly told that it is compiling code that conforms to a newer standard of C++ than its default. This may mean invoking
or something similar on the command-line.
8.4.1 The auto Type
After reading Sect. 8.3 you may have been left believing that templates are all double colons and angle brackets. Worse, that whenever you want to iterate over a vector or set which you have created, then you will need to remember the exact form of the iterator type. The good news is that much of the writing of these types can now be simplified via automatic type inference. This not only saves on writing, but it also makes templated code more readable, by removing some of the lengthy type names. This relies on one simple rule.
Rule: if the type of a new variable can be inferred by the compiler at the point of its initialisation then the type may be replaced by auto.
For example, in the code fragment below, there is enough information for the compiler to infer that i ought to be an integer variable: at its initialisation it is given the value 1 (an integer). Meanwhile the variable x which is initialised to a floating point value is given the inferred type double. Note that each of these two lines contain both the auto type and an assignment. Neither of these lines can itself be split across two lines, because if the type is separated from the initialisation then the type can no longer be inferred.
It is worth pointing out that the full power of automatic type inference is not demonstrated by the above example and, furthermore, that inferring simple types as in this example is potentially dangerous because the programmer may find unexpected behaviour if the compiler infers a different type to the type presumed by the programmer. For example, the code below will print to console that x contains the value 22 which may not be what the programmer intended. This is because, on line 1, the compiler will infer that the type of x ought to be int. A programmer, reading line 2, may assume that x ought to be of type double, but at this point it’s too late—the type is fixed. The programmer could repair this issue either by initialising the value of x to 22.0 or by using double as the explicit type for x.
The real power of the auto keyword comes in places where the onus used to be on the programmer to write out a lengthy type name. For example in Listing 8.3, loops beginning at lines 23, 35, 46 and 56 all rely on a const_iterator which is declared once globally in line 22. This was largely done to keep the code compact. Note though that the style of globally declaring a loop iterator in Listing 8.3 is in direct contravention to point 4 in our tips on coding style (given in Sect. 6.6). In the code below we have indicated how the code in any of these for loops over the vector destinations may be replaced concisely with one which has a locally-declared iterator of type auto.
8.4.2 Some Useful Container Types with Unified Functionality
Modern C++ provides std::array which is a useful replacement for the small size, statically allocated array (as found in Sect. 1.4.5). The idea behind this array type is to provide a uniform way to access and use arrays. It is templated by the type of object it contains and its size. In terms of access to its elements it can behave exactly like the old style plain array: the element index in square brackets is used to read or write individual elements. This is demonstrated below where an old-style array and a new-style array are created on lines 1 and 2 respectively. In the assert statement on line 3, elements of the two arrays are compared using the same syntax.
However, there are two main ways in which the new std::array is very different to the old array. In both of these respects it behaves a lot more like a fixed-size version of std::vector. The first difference is that many of the vector functions, such as begin() and size(), are available in the templated array class. The second difference is that arrays can now be passed into functions as first-class objects. That is, whereas old-style arrays are always sent to functions as pointers (a fact we exploited in Sect. 5.2.4) the new type can either be copied or sent as a reference.
Because the new-style array is built around the same infrastructure as the previous STL structures it interacts with many of them in the way one might expect. Many structures may be initialised using the initialiser list style (a list of elements in curly braces). One can also convert between many of the structures by copying data between objects.
In the code below, after initialising an array in line 1, we then copy the array contents into both a vector and a set in lines 2–4. Note that the syntax for the two operations is that same but that the data are converted to different underlying representations. Finally the representation is tested in line 5, where we expect that the set, which has no duplicates, will contain fewer members.
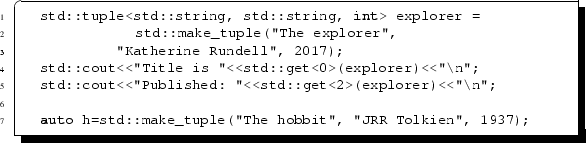
Modern C++ also contains a light-weight mixed-type tuple. This allows us to put pieces of data together in one place in a modular way, so that it is similar to a small class with no methods. The tuple is a generalisation of the existing STL data structure pair (which was restricted to having exactly two pieces of data). An example of the use of a tuple is given below. The new tuple explorer is required to represent information about a book via two strings and a number. It is clear from lines 4 and 5 that access to the member data in the tuple is possible (though the syntax may look a little strange). Finally in line 7 we tidy up some of this new strange syntax by using the keyword auto which enables us to initialise a reasonably complicated mixed-type tuple in a single line.
8.4.3 Range-based forLoops
A very useful feature of modern C++ is the range-based loop. This is sometimes known in other languages as a “for each” loop but, as we will see later, “for each” has a reserved meaning in modern C++. The range-based loop provides the programmer with a way of iterating over each and every member of a particular container (array or vector, for example) without having to worry about how many members there are, or about the exact mechanism of iteration.
The most simple way to demonstrate this is with an iteration over an intialiser list. Here the variable even, which is local to the for loop takes on all the values in the given list up to, and including the value 8:
The range-based loop is available for all structures which might be iterated over: arrays, vectors, sets, maps and so on. In each case the meaning of the range-based loop is to iterate over the container in the same way that the container’s regular iterator might behave (but with a far more compact syntax). If we use a range-based loop on a std::set then we expect to see each element of the set exactly once, but with no guarantee on the order in which they appear. If we use a range-based loop on a std::vector then we will see each item according to their position in the vector.
We can now re-visit the example code for the STL vector type in Listing 8.3 and again re-write those loops which are iterating over the members of the vector and printing them out. Note that in the code below we have taken advantage of the array initialiser in lines 8–9 in order to rapidly fill the vector destinations with content.
In lines 11–15 we show the normal usage for a range-based loop over a vector. On each iteration of this loop the variable city, which is local to the loop, is assigned a value which is a copy of an item in the vector. This means that the content of the underlying vector cannot be changed: any modifications to the copied string in the variable city will stay local to the loop. If, on the other hand, we intended to change the contents of destinations, then we would do so by using a reference to the items. The use of a reference in a range-based loop is demonstrated in lines 16–21. Here each of the city names in the vector is modified using simple string concatenation. Finally, in line 23, we show that a combination of a range-base loop, the auto keyword, and writing the loop without braces leads to a highly compact way to express the same code. The loop in line 23 is equivalent to that in lines 11–15. If we wanted to make modifications to the vector then we could insist that the local variable were a reference by writing auto& instead of auto for the type name.
8.4.4 Mapping Lambda Functions
We close this survey with the “for each” function, which is intended to take a function and apply it to every member of a container (for example a vector). This type of functionality is called a “map” in some languages. It works by taking as arguments the beginning and end of a range to be iterated over, and the function that should be applied. In the most straightforward form the “function” might just be the name of function which has been defined elsewhere, but it becomes more powerful when the function can be declared locally: inside the current scope, or even within the for_each function itself. The local declaration of a function is known as a lambda closure by computer scientists.
In the following code fragment, we apply functions which double each element of a vector. The first time this happens is on line 7 where the function name twice appears in the third argument. Now this twice function might have been declared externally (as indicated by the comment on line 4) but, instead, it is declared on line 6. Square brackets here indicate that what follows is a function, with round brackets around the argument, braces around the function body, and a final semicolon. We have used auto for the type of twice because its real type is a function from int& to void. Lines 10–11 show that the function does not need a name. Instead we can just declare the form and definition of the function in place. This is a very compact form, but perhaps renders the code less readable.
8.5 Tips: Template Compilation
In Sect. 8.1 we presented a templated class DoubleVector in which the size of the vector is specified at compile time. Since the size of the vector in UseDoubleVector.cpp (Listing 8.2) is known at compile time, the memory allocation is static.
When building a program to use a templated class such as DoubleVector we might follow the pattern laid down in Sect. 6.2.4.1 of placing the definition of the class in the file DoubleVector.hpp and the implementation of the class in the file DoubleVector.cpp. We would write a main program to test it and write the rules for compilation into a Makefile. There is an unfortunate snag with this plan, because when we instantiate a vector (, say) in our main program and compile it, the compiler has no access to the implementation from DoubleVector.cpp. The compiler needs to compile code from the DoubleVector.cpp file, in which all the instances of DIM are replaced by “5”.
There are three strategies which can be used to overcome this template instantiation problem.
1.
Each file which uses the class may include the implementation of the entire class through the use of #include "DoubleVector.cpp". This means the code compilation may be slower since the entire class must be compiled every time it is used. It also means that care must be taken to ensure that the file DoubleVector.cpp is included at most once. (The #define mechanism introduced in Sect. 6.2.2 may be suitably adapted for this purpose.)
2.
A similar solution is to place the entire class in the file DoubleVector.hpp, as we did for DoubleVector in Listing 8.1 of Sect. 8.1. This, again, has the disadvantage that the entire class must be compiled every time it is used.
3.
A more advanced solution to the problem is explicit instantiation. If it is known that we only use DoubleVector with a small set of sizes, then we can force the compiler to produce exactly the ones which are needed as it compiles DoubleVector.cpp into the object file DoubleVector.o. This is done by making an unnamed instance of the class of each required size in the file DoubleVector.cpp, as the code fragment below illustrates.
8.6 Exercises
8.1
The probability of rain for each of the next N days is to be stored in a double precision floating point array of size N. As the entries of this array are probabilities they should all take values between 0 and 1 inclusive. However, as they have been calculated using a numerical algorithm, these probabilities are only correct to within an absolute error of : that is, in reality these numbers may be between and inclusive. Using the ideas presented in Sect. 8.1, use templates so that when accessing an individual entry of the array:
1.
the value stored by the array is returned if it is between 0 and 1 inclusive;
2.
the value 0 is returned if the value stored is between and 0 inclusive;
3.
the value 1 is returned if the value stored is between 1 and inclusive; and
4.
an assertion is tripped otherwise.
8.2
Use templates to write a single function that may be used to calculate the absolute value of an integer or a double precision floating point number.
8.3
Use the class of complex numbers given in Sect. 6.4 to create an STL vector of complex numbers. Investigate the functionality of the STL demonstrated in Sect. 8.3.1 using this vector of complex numbers. Note that when you add an object to an STL vector it is a copy which is added, so it is imperative that the copy constructor is working as expected.
8.4
Modify the example of an STL set given in Sect. 8.3.2 so that the coordinates of the point are now given by double precision floating point variables. You will now need to think a bit more carefully about what it means for two coordinates to be equal: see the tip on comparing two floating point numbers given in Sect. 2.6.5.
8.5
Use the container (a mapping from keys of type string to values of type int) to represent a phone book. If you have access to a compiler which is compatible with C++11 or higher then you might consider some of the following ideas.
1.
Use an initialiser list to populate the phone book with a small list of name-number pairs. See Sect. 8.4.2 for examples of structures initialised in this way, but be aware that a map needs to be initialised with a list of lists.
2.
Write a for loop to iterate over the contents of the phone book and output all name-number pairs. Try this with the range-based loop that was introduced in Sect. 8.4.3.
3.
Write out the entire contents of the phone book using a std::for_each loop and a lambda function, in a similar manner to the loops shown in Sect. 8.4.4.
4.
Write functionality to get all names from the map and store them in a vector.
5.
Write functionality to get all the numbers from the map into a vector. Then use std::set to detect whether two or more people share the same number.
6.
Write the “reverse” map to look up a name when given a number. If you have two people who share the same number then you may find that std::multimap is useful.
7.
Re-write the map so that, instead of each name mapping to a single number value, it maps to a std::tuple consisting of a number and an email address. See Sect. 8.4.2 for example use of tuples.




 if we wished to begin with a vector of 50 empty strings rather than an empty vector.
if we wished to begin with a vector of 50 empty strings rather than an empty vector.


 and
and  , which represent the points (
, which represent the points ( ) and (
) and ( ), we say that
), we say that  if
if  , and
, and  if
if  . Only if
. Only if  we say that
we say that  if
if  , and
, and  if
if  . If
. If  and
and  then the points
then the points  and
and  are identical: the set would only store one instance of these two.
are identical: the set would only store one instance of these two. operator that allows us to order points in two dimensions as described above.
operator that allows us to order points in two dimensions as described above.










 , say) in our main program and compile it, the compiler has no access to the implementation from DoubleVector.cpp. The compiler needs to compile code from the DoubleVector.cpp file, in which all the instances of DIM are replaced by “5”.
, say) in our main program and compile it, the compiler has no access to the implementation from DoubleVector.cpp. The compiler needs to compile code from the DoubleVector.cpp file, in which all the instances of DIM are replaced by “5”.
 : that is, in reality these numbers may be between
: that is, in reality these numbers may be between  and
and  inclusive. Using the ideas presented in Sect. 8.1, use templates so that when accessing an individual entry of the array:
inclusive. Using the ideas presented in Sect. 8.1, use templates so that when accessing an individual entry of the array: and 0 inclusive;
and 0 inclusive; inclusive; and
inclusive; and (a mapping from keys of type string to values of type int) to represent a phone book. If you have access to a compiler which is compatible with C++11 or higher then you might consider some of the following ideas.
(a mapping from keys of type string to values of type int) to represent a phone book. If you have access to a compiler which is compatible with C++11 or higher then you might consider some of the following ideas.