7
Trial-and-Error Searching and Data Fitting
7.1 Problem 1: A Search for Quantum States in a Box
Many computer techniques are well-defined sets of procedures leading to definite outcomes. In contrast, some computational techniques are trial-and-error algorithms in which decisions on what path to follow are made based on the current values of variables, and the program quits only when it thinks it has solved the problem. (We already did some of this when we summed a power series until the terms became small.) Writing this type of program is usually interesting because we must foresee how to have the computer act intelligently in all possible situations, and running them is very much like an experiment in which it is hard to predict what the computer will come up with.
Problem Probably the most standard problem in quantum mechanics1) is to solve for the energies of a particle of mass m bound within a 1D square well of radius a:

As shown in quantum mechanics texts (Gottfried, 1966), the energies of the bound states  within this well are solutions of the transcendental equations
within this well are solutions of the transcendental equations


where even and odd refer to the symmetry of the wave function. Here we have chosen units such that  . Your problem is to
. Your problem is to
- Find several bound-state energies EB for even wave functions, that is, the solution of (7.2).
- See if making the potential deeper, say, by changing the 10 to a 20 or a 30, produces a larger number of, or deeper, bound states.
7.2 Algorithm: Trial-and-Error Roots via Bisection
Trial-and-error root finding looks for a value of x for which

where the 0 on the right-hand side is conventional (an equation such as  can easily be written as
can easily be written as  . The search procedure starts with a guessed value for x, substitutes that guess into f(x) (the “trial”), and then sees how far the LHS is from zero (the “error”). The program then changes x based on the error and tries out the new guess in f(x). The procedure continues until
. The search procedure starts with a guessed value for x, substitutes that guess into f(x) (the “trial”), and then sees how far the LHS is from zero (the “error”). The program then changes x based on the error and tries out the new guess in f(x). The procedure continues until  to some desired level of precision, or until the changes in x are insignificant, or if the search seems endless.
to some desired level of precision, or until the changes in x are insignificant, or if the search seems endless.
The most elementary trial-and-error technique is the bisection algorithm. It is reliable but slow. If you know some interval in which f(x) changes sign, then the bisection algorithm will always converge to the root by finding progressively smaller and smaller intervals within which the zero lies. Other techniques, such as the Newton–Raphson method we describe next, may converge more quickly, but if the initial guess is not close, it may become unstable and fail completely.

Figure 7.1 A graphical representation of the steps involved in solving for a zero of f(x) using the bisection algorithm. The bisection algorithm takes the midpoint of the interval as the new guess for x, and so each step reduces the interval size by one-half. Four steps are shown for the algorithm.
The basis of the bisection algorithm is shown in Figure 7.1. We start with two values of x between which we know that a zero occurs. (You can determine these by making a graph or by stepping through different x values and looking for a sign change.) To be specific, let us say that f(x) is negative at x− and positive at x+:

(Note that it may well be that x− > x+ if the function changes from positive to negative as x increases.) Thus, we start with the interval x+ ≤ x ≤ x− within which we know a zero occurs. The algorithm (implemented as in Listing 7.1) then picks the new x as the bisection of the interval and selects as its new interval the half in which the sign change occurs:

This process continues until the value of f(x) is less than a predefined level of precision or until a predefined (large) number of subdivisions occurs.
Listing 7.1 The Bisection.py is a simple implementation of the bisection algorithm for finding a zero of a function, in this case 2 cos x – x.

The example in Figure 7.1 shows the first interval extending from x− = x+1 to x+ = x−1. We bisect that interval at x, and because f(x) < 0 at the midpoint, we set x− ≡ x−2 = x and label it x−2 to indicate the second step. We then use x+2 ≡ x+1 and x−2 as the next interval and continue the process. We see that only x− changes for the first three steps in this example, but for the fourth step x+ finally changes. The changes then become too small for us to show.
7.2.1 Implementation: Bisection Algorithm
- The first step in implementing any search algorithm is to get an idea of what your function looks like. For the present problem, you do this by making a plot of
 Note from your plot some approximate values at which
Note from your plot some approximate values at which  . Your program should be able to find more exact values for these zeros.
. Your program should be able to find more exact values for these zeros. - Write a program that implements the bisection algorithm and use it to find some solutions of (7.2).
- Warning: Because the tan function has singularities, you have to be careful. In fact, your graphics program (or Maple) may not function accurately near these singularities. One cure is to use a different but equivalent form of the equation. Show that an equivalent form of (7.2) is
- Make a second plot of (7.6), which also has singularities but at different places. Choose some approximate locations for zeros from this plot.
- Evaluate f(EB) and thus determine directly the precision of your solution.
- Compare the roots you find with those given by Maple or Mathematica.

7.3 Improved Algorithm: Newton–Raphson Searching
The Newton–Raphson algorithm finds approximate roots of the equation

more quickly than the bisection method. As we see graphically in Figure 7.2, this algorithm is the equivalent of drawing a straight line  tangent to the curve at an x value for which
tangent to the curve at an x value for which  and then using the intercept of the line with the x-axis at
and then using the intercept of the line with the x-axis at  as an improved guess for the root. If the “curve” was a straight line, the answer would be exact; otherwise, it is a good approximation if the guess is close enough to the root for f(x) to be nearly linear. The process continues until some set level of precision is reached. If a guess is in a region where f(x) is nearly linear (Figure 7.2), then the convergence is much more rapid than for the bisection algorithm.
as an improved guess for the root. If the “curve” was a straight line, the answer would be exact; otherwise, it is a good approximation if the guess is close enough to the root for f(x) to be nearly linear. The process continues until some set level of precision is reached. If a guess is in a region where f(x) is nearly linear (Figure 7.2), then the convergence is much more rapid than for the bisection algorithm.
The analytic formulation of the Newton–Raphson algorithm starts with an old guess x0 and expresses a new guess x as a correction Δx to the old guess:



Figure 7.2 A graphical representation of the steps involved in solving for a zero of f(x) using the Newton–Raphson method. The Newton–Raphson method takes the new guess as the zero of the line tangent to f(x) at the old guess. Two guesses are shown.
We next expand the known function f(x) in a Taylor series around x0 and keep only the linear terms:

We then determine the correction Δx by calculating the point at which this linear approximation to f(x) crosses the x-axis:


The procedure is repeated starting at the improved x until some set level of precision is obtained.
The Newton–Raphson algorithm (7.12) requires evaluation of the derivative df / dx at each value of x0. In many cases, you may have an analytic expression for the derivative and can build it into the algorithm. However, especially for more complicated problems, it is simpler and less error-prone to use a numerical forward-difference approximation to the derivative2):

where δx is some small change in x that you just chose (different from the Δ used for searching in (7.12)). While a central-difference approximation for the derivative would be more accurate, it would require additional evaluations of the f’s, and once you find a zero, it does not matter how you got there. In Listing 7.2, we give a program NewtonCD.py that implement the search with the central difference derivative.
Listing 7.2 NewtonCD.py uses the Newton–Raphson method to search for a zero of the function f(x). A central-difference approximation is used to determine df/dx.


7.3.1 Newton–Raphson with Backtracking
Two examples of possible problems with the Newton–Raphson algorithm are shown in Figure 7.3. In Figure 7.3a, we see a case where the search takes us to an x value where the function has a local minimum or maximum, that is, where df / dx = 0. Because Δx = –f/f′, this leads to a horizontal tangent (division by zero), and so the next guess is x = ∞, from where it is hard to return. When this happens, you need to start your search with a different guess and pray that you do not fall into this trap again. In cases where the correction is very large but maybe not infinite, you may want to try backtracking (described below) and hope that by taking a smaller step you will not get into as much trouble.
In Figure 7.3b, we see a case where a search falls into an infinite loop surrounding the zero without ever getting there. A solution to this problem is called backtracking. As the name implies, in cases where the new guess x0 + Δx leads to an increase in the magnitude of the function,  , you can backtrack somewhat and try a smaller guess, say, x0 + Δx/2. If the magnitude of f still increases, then you just need to backtrack some more, say, by trying x0 + Δx/4 as your next guess, and so forth. Because you know that the tangent line leads to a local decrease in
, you can backtrack somewhat and try a smaller guess, say, x0 + Δx/2. If the magnitude of f still increases, then you just need to backtrack some more, say, by trying x0 + Δx/4 as your next guess, and so forth. Because you know that the tangent line leads to a local decrease in  f, eventually an acceptable small enough step should be found.
f, eventually an acceptable small enough step should be found.
The problem in both these cases is that the initial guesses were not close enough to the regions where f(x) is approximately linear. So again, a good plot may help produce a good first guess. Alternatively, you may want to start your search with the bisection algorithm and then switch to the faster Newton–Raphson algorithm when you get closer to the zero.

Figure 7.3 Two examples of how the Newton–Raphson algorithm may fail if the initial guess is not in the region where f(x) can be approximated by a straight line. (a) A guess lands at a local minimum/maximum, that is, a place where the derivative vanishes, and so the next guess ends up at x = ∞. (b)The search has fallen into an infinite loop. The technique know as “backtracking” could eliminate this problem.
7.3.2 Implementation: Newton–Raphson Algorithm
- Use the Newton–Raphson algorithm to find some energies EB that are solutions of (7.2). Compare these solutions with the ones found with the bisection algorithm.
- Again, notice that the 10 in (7.2) is proportional to the strength of the potential that causes the binding. See if making the potential deeper, say, by changing the 10 to a 20 or a 30, produces more or deeper bound states. (Note that in contrast to the bisection algorithm, your initial guess must be closer to the answer for the Newton–Raphson algorithm to work.)
- Modify your algorithm to include backtracking and then try it out on some difficult cases.
- Evaluate f(EB) and thus determine directly the precision of your solution.
7.4 Problem 2: Temperature Dependence of Magnetization
Problem Determine M(T) the magnetization as a function of temperature for simple magnetic materials.
A collection of N spin-1/2 particles each with the magnetic moment µ is at temperature T. The collection has an external magnetic field B applied to it and comes to equilibrium with NL particles in the lower energy state (spins aligned with the magnetic field), and with NU particles in the upper energy state (spins opposed to the magnetic field). The Boltzmann distribution law tells us that the relative probability of a state with energy E is proportional to  , where kB is Boltzmann’s constant. For a dipole with moment µ, its energy in a magnetic field is given by the dot product
, where kB is Boltzmann’s constant. For a dipole with moment µ, its energy in a magnetic field is given by the dot product  . Accordingly, spin-up particle have lower energy in a magnetic field than spin-down particles, and thus are more probable.
. Accordingly, spin-up particle have lower energy in a magnetic field than spin-down particles, and thus are more probable.
Applying the Boltzmann distribution to our spin problem, we have that the number of particles in the lower energy level (spin up) is

while the number of particles in the upper energy level (spin down) is

As discussed by (Kittel, 2005), we now assume that the molecular magnetic field B = λ M is much larger than the applied magnetic field and so replace B by the molecular field. This permits us to eliminate B from the preceding equations. The magnetization M(T) is given by the individual magnetic moment µ times the net number of particles pointing in the direction of the magnetic field:


Note that this expression appears to make sense because as the temperature approaches zero, all spins will be aligned along the direction of B and so M(T = 0) = Nµ.
Solution via Searching Equation 7.17 relates the magnetization and the temperature. However, it is not really a solution to our problem because M appears on the LHS of the equation as well as within the hyperbolic function on the RHS. Generally, a transcendental equation of this sort does not have an analytic solution that would give M as simply a function of the temperature T. But by working backward, we can find a numerical solution. To do that we first express (7.17) in terms of the reduced magnetization m, the reduced temperature t, and the Curie temperature Tc:


While it is no easier to find an analytic solution to (7.18) than it was to (7.17), the simpler form of (7.18) makes the programming easier as we search for values of t and m that satisfy (7.18).

Figure 7.4 A function of the reduced magnetism m at three reduced temperatures t. A zero of this function determines the value of the magnetism at a particular value of t.
One approach to a trial-and-error solution is to define a function

and then, for a variety of fixed t = ti values, search for those m values at which f(m, ti) = 0. (One could just as well fix the value of m to mj and search for the value of t for which f(mj, t) = 0; once you have a solution, you have a solution.) Each zero so found gives us a single value of m(ti). A plot or a table of these values for a range of ti values then provides the best we can do as the desired solution m(t).
Figure 7.4 shows three plots of f(m,t) as a function of the reduced magnetization m, each plot for a different value of the reduced temperature. As you can see, other than the uninteresting solution at m = 0, there is only one solution (a zero) near m = 1 for t = 0.5, and no solution at other temperatures.
7.4.1 Searching Exercise
- Find the root of (7.20) to six significant figures for t = 0.5 using the bisection algorithm.
- Find the root of (7.20) to six significant figures for t = 0.5 using the Newton–Raphson algorithm.
- Compare the time it takes to find the solutions for the bisection and Newton–Raphson algorithms.
- Construct a plot of the reduced magnetization m(t) as a function of the reduced temperature t.
7.5 Problem 3: Fitting An Experimental Spectrum
Problem The cross sections measured for the resonant scattering of neutrons from a nucleus are given in Table 7.1. Your problem is to determine values for the cross sections at energy values lying between those in the table.
You can solve this problem in a number of ways. The simplest is to numerically interpolate between the values of the experimental f(Ei) given in Table 7.1. This is direct and easy but does not account for there being experimental noise in the data. A more appropriate solution (discussed in Section 7.7) is to find the best fit of a theoretical function to the data. We start with what we believe to be the “correct” theoretical description of the data,
Table 7.1 Experimental values for a scattering cross section (f(E) in the theory), each with absolute error ±σi, as a function of energy (xi in the theory).
| i = | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Ei (MeV) | 0 | 25 | 50 | 75 | 100 | 125 | 150 | 175 | 200 |
| g(Ei) (mb) | 10.6 | 16.0 | 45.0 | 83.5 | 52.8 | 19.9 | 10.8 | 8.25 | 4.7 |
| Error (mb) | 9.34 | 17.9 | 41.5 | 85.5 | 51.5 | 21.5 | 10.8 | 6.29 | 4.14 |

where fr, Er, and Γ are unknown parameters. We then adjust the parameters to obtain the best fit. This is a best fit in a statistical sense but in fact may not pass through all (or any) of the data points. For an easy, yet effective, introduction to statistical data analysis, we recommend (Bevington and Robinson, 2002).
These two techniques of interpolation and least-squares fitting are powerful tools that let you treat tables of numbers as if they were analytic functions and sometimes let you deduce statistically meaningful constants or conclusions from measurements. In general, you can view data fitting as global or local. In global fits, a single function in x is used to represent the entire set of numbers in a table like Table 7.1. While it may be spiritually satisfying to find a single function that passes through all the data points, if that function is not the correct function for describing the data, the fit may show nonphysical behavior (such as large oscillations) between the data points. The rule of thumb is that if you must interpolate, keep it local and view global interpolations with a critical eye.
Consider Table 7.1 as ordered data that we wish to interpolate. We call the independent variable x and its tabulated values xi(i = 1, 2, …), and assume that the dependent variable is the function g(x), with the tabulated values gi = g(xi). We assume that g(x) can be approximated as an (n – 1)-degree polynomial in each interval i:

Because our fit is local, we do not assume that one g(x) can fit all the data in the table but instead use a different polynomial, that is, a different set of ai values, for each interval. While each polynomial is of low degree, multiple polynomials are needed to span the entire table. If some care is taken, the set of polynomials so obtained will behave well enough to be used in further calculations without introducing much unwanted noise or discontinuities.
The classic interpolation formula was created by Lagrange. He figured out a closed-form expression that directly fits the (n – 1)-order polynomial (7.22) to n values of the function g(x) evaluated at the points xi . The formula for each interval is written as the sum of polynomials:


For three points, (7.23) provides a second-degree polynomial, while for eight points it gives a seventh-degree polynomial. For example, assume that we are given the points and function values

With four points, the Lagrange formula determines a third-order polynomial that reproduces each of the tabulated values:

As a check, we see that

If the data contain little noise, this polynomial can be used with some confidence within the range of the data, but with risk beyond the range of the data.
Notice that Lagrange interpolation has no restriction that the points xi be evenly spaced. Usually, the Lagrange fit is made to only a small region of the table with a small value of n, despite the fact that the formula works perfectly well for fitting a high-degree polynomial to the entire table. The difference between the value of the polynomial evaluated at some x and that of the actual function can be shown to be the remainder

where ζ lies somewhere in the interpolation interval. What significant here is that we see that if significant high derivatives exist in g(x), then it cannot be approximated well by a polynomial. For example, a table of noisy data would have significant high derivatives.
7.5.1 Lagrange Implementation, Assessment
Consider the experimental neutron scattering data in Table 7.1. The expected theoretical functional form that describes these data is (7.21), and our empirical fits to these data are shown in Figure 7.5.
- Write a subroutine to perform an n-point Lagrange interpolation using (7.23). Treat n as an arbitrary input parameter. (You may also perform this exercise with the spline fits discussed in Section 7.5.2.)
- Use the Lagrange interpolation formula to fit the entire experimental spectrum with one polynomial. (This means that you must fit all nine data points with an eight-degree polynomial.) Then use this fit to plot the cross section in steps of 5MeV.
- Use your graph to deduce the resonance energy Er (your peak position) and Γ (the full-width at half-maximum). Compare your results with those predicted by a theorist friend, (Er, Γ) = (78, 55) MeV.
- A more realistic use of Lagrange interpolation is for local interpolation with a small number of points, such as three. Interpolate the preceding cross-sectional data in 5-MeV steps using three-point Lagrange interpolation for each interval. (Note that the end intervals may be special cases.)
- We deliberately have not discussed extrapolation of data because it can lead to serious systematic errors; the answer you get may well depend more on the function you assume than on the data you input. Add some adventure to your life and use the programs you have written to extrapolate to values outside Table 7.1. Compare your results to the theoretical Breit–Wigner shape (7.21).
This example shows how easy it is to go wrong with a high-degree-polynomial fit to data with errors. Although the polynomial is guaranteed to pass through all the data points, the representation of the function away from these points can be quite unrealistic. Using a low-order interpolation formula, say, n = 2 or 3, in each interval usually eliminates the wild oscillations, but may not have any theoretical justification. If these local fits are matched together, as we discuss in the next section, a rather continuous curve results. Nonetheless, you must recall that if the data contain errors, a curve that actually passes through them may lead you astray. We discuss how to do this properly with least-squares fitting in Section 7.7.
7.5.2 Cubic Spline Interpolation (Method)
If you tried to interpolate the resonant cross section with Lagrange interpolation, then you saw that fitting parabolas (three-point interpolation) within a table may avoid the erroneous and possibly catastrophic deviations of a high-order formula. (A two-point interpolation, which connects the points with straight lines, may not lead you far astray, but it is rarely pleasing to the eye or precise.) A sophisticated variation of an n = 4 interpolation, known as cubic splines, often leads to surprisingly eye-pleasing fits. In this approach (Figure 7.5), cubic polynomials are fit to the function in each interval, with the additional constraint that the first and second derivatives of the polynomials be continuous from one interval to the next. This continuity of slope and curvature is what makes the spline fit particularly eye-pleasing. It is analogous to what happens when you use the flexible spline drafting tool (a lead wire within a rubber sheath) from which the method draws its name.

Figure 7.5 Three fits to data. Dashed: Lagrange interpolation using an eight-degree polynomial; Short dashes: cubic splines fit ; Long dashed: Least-squares parabola fit.
The series of cubic polynomials obtained by spline-fitting a table of data can be integrated and differentiated and is guaranteed to have well-behaved derivatives. The existence of meaningful derivatives is an important consideration. As a case in point, if the interpolated function is a potential, you can take the derivative to obtain the force. The complexity of simultaneously matching polynomials and their derivatives over all the interpolation points leads to many simultaneous linear equations to be solved. This makes splines unattractive for hand calculation, yet easy for computers and, not surprisingly, popular in both calculations and computer drawing programs. To illustrate, the smooth solid curve in Figure 7.5 is a spline fit.
The basic approximation of splines is the representation of the function g(x) in the subinterval [xi, xi+1] with a cubic polynomial:


This representation makes it clear that the coefficients in the polynomial equal the values of g(x) and its first, second, and third derivatives at the tabulated points xi. Derivatives beyond the third vanish for a cubic. The computational chore is to determine these derivatives in terms of the N tabulated gi values. The matching of gi at the nodes that connect one interval to the next provides the equations

The matching of the first and second derivatives at each interval’s boundaries provides the equations

The additional equations needed to determine all constants are obtained by matching the third derivatives at adjacent nodes. Values for the third derivatives are found by approximating them in terms of the second derivatives:

As discussed in Chapter 5, a central-difference approximation would be more accurate than a forward-difference approximation, yet (7.33) keeps the equations simpler.
It is straightforward yet complicated to solve for all the parameters in (7.30). We leave that to the references (Thompson, 1992; Press et al., 1994). We can see, however, that matching at the boundaries of the intervals results in only (N – 2) linear equations for N unknowns. Further input is required. It usually is taken to be the boundary conditions at the endpoints a = x1 and b = xN, specifically, the second derivatives g″(a) and g″(b). There are several ways to determine these second derivatives:
Natural spline: Set g″(a) = g″(b) = 0; that is, permit the function to have a slope at the endpoints but no curvature. This is “natural” because the derivative vanishes for the flexible spline drafting tool (its ends being free).
Input values for g′ at the boundaries: The computer uses g′(a) to approximate g″(a). If you do not know the first derivatives, you can calculate them numerically from the table of gi values.
Input values for g″ at the boundaries: Knowing values is of course better than approximating values, but it requires the user to input information. If the values of g″ are not known, they can be approximated by applying a forward-difference approximation to the tabulated values:

7.5.2.1 Cubic Spline Quadrature (Exploration)
A powerful integration scheme is to fit an integrand with splines and then integrate the cubic polynomials analytically. If the integrand g(x) is known only at its tabulated values, then this is about as good an integration scheme as is possible; if you have the ability to calculate the function directly for arbitrary x, Gaussian quadrature may be preferable. We know that the spline fit to g in each interval is the cubic (7.30)

It is easy to integrate this to obtain the integral of g for this interval and then to sum over all intervals:


Making the intervals smaller does not necessarily increase precision, as subtractive cancelations in (7.36) may get large.
Spline Fit of Cross Section (Implementation) Fitting a series of cubics to data is a little complicated to program yourself, so we recommend using a library routine. While we have found quite a few Java-based spline applications available on the Internet, none seemed appropriate for interpreting a simple set of numbers. That being the case, we have adapted the splint.c and the spline.c functions from (Press et al., 1994) to produce the SplineInteract.py program shown in Listing 7.3 (there is also an applet). Your problem for this section is to carry out the assessment in Section 7.5.1 using cubic spline interpolation rather than Lagrange interpolation.







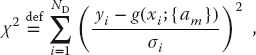
 weighting means that measurements with larger errors4) contribute less to χ2.
weighting means that measurements with larger errors4) contribute less to χ2.
 ND−Mp where ND is the number of data points and MP is the number of parameters in the theoretical function. If your χ2 is much less than ND − MP, it does not mean that you have a “great” theory or a really precise measurement; instead, you probably have too many parameters or have assigned errors (σi values) that are too large. In fact, too small χ2 may indicate that you are fitting the random scatter in the data rather than missing approximately one-third of the error bars, as expected if the errors are random. If your χ2 is significantly greater than ND − MP, the theory may not be good, you may have significantly underestimated your errors, or you may have errors that are not random.
ND−Mp where ND is the number of data points and MP is the number of parameters in the theoretical function. If your χ2 is much less than ND − MP, it does not mean that you have a “great” theory or a really precise measurement; instead, you probably have too many parameters or have assigned errors (σi values) that are too large. In fact, too small χ2 may indicate that you are fitting the random scatter in the data rather than missing approximately one-third of the error bars, as expected if the errors are random. If your χ2 is significantly greater than ND − MP, the theory may not be good, you may have significantly underestimated your errors, or you may have errors that are not random.








 (This last approximation is reasonable for large numbers, which this is not.)
(This last approximation is reasonable for large numbers, which this is not.)













 . This leads to the Mp equations
. This leads to the Mp equations 








 is the full width of the peak at half-maximum, good guesses for the a’s can be extracted from a graph of the data. To obtain the nine derivatives of the three f’s with respect to the three unknown a’s, we use two nested loops over i and j, along with the forward-difference approximation for the derivative
is the full width of the peak at half-maximum, good guesses for the a’s can be extracted from a graph of the data. To obtain the nine derivatives of the three f’s with respect to the three unknown a’s, we use two nested loops over i and j, along with the forward-difference approximation for the derivative