By this point, you might be ready to concede that the business of amassing and deploying knowledge of words and language structure is more involved than you initially thought. But once basic language skills are in place and words can be dependably retrieved for language production or comprehension, and once the machinery for assembling well-formed sentences and computing their meanings is running smoothly, we’re home free, right?

Not exactly. Try reading the following collection of impeccably formed English sentences:
Frank became convinced that his brother, a handsome and witty doctor, was having an affair with his wife. The doctor warned her that it was only a matter of months until probable death. Her only hope was to undergo a disfiguring surgery. But she was afraid to do so. She lingered for some time, but eventually, Frank had to confront the fact that she was gone from his life. Then he learned the truth. Racked with sorrow, he killed himself. It was a brutal stab in the back. She thought that she should eventually tell Frank. Frank’s wife was secretly being treated for a dangerous illness. He was consumed with rage over it.
For added fun, now look away from the text and try to paraphrase what you’ve just read. I’ll admit the passage is hard to make sense of. But there’s nothing wrong with the sentences themselves. In fact, they seem to pose no problem at all when arranged in a somewhat different order, like this:
Frank became convinced that his brother, a handsome and witty doctor, was sleeping with his wife. It was a brutal stab in the back. He was consumed with rage over it. Then he learned the truth. His wife was secretly being treated for a dangerous illness. The doctor warned her that it was only a matter of months until probable death. Her only hope was to undergo a disfiguring surgery. She thought that she should eventually tell Frank. But she was afraid to do so. In the end, she lingered for some time, but eventually, Frank had to confront the fact that she was gone from his life. Racked with sorrow, he killed himself.
Why is the second version so much easier to read than the first? It’s not just that this version is “orderly” and the first one is “disorganized.” The reason that the order of sentences matters at all is because our understanding of the passage is supplied only partially by the language itself—the rest of its meaning is actually filled in by the connections that we draw between sentences and the extra details that we throw in.
Normally, when people talk about “reading between the lines,” they have in mind some especially skilled or attentive scrutiny of the message; the phrase usually refers to hunting for some underlying meaning that’s been slipped in or hidden, invisible to anyone who’s not carefully looking for it. But in reality, whether as hearers or readers, we read between the lines of language all the time and without even thinking about it. Further, as producers of language, we rely on our audience to be able to do it. Take the seemingly complete sentence The doctor warned her that it was only a matter of months until probable death. There are many pieces of information that this sentence leaves out. We know that some doctor (but we don’t know exactly which one) warned someone female (but who?) that someone (but who?) would likely die (but from what?) in a matter of months (but how many?). Because this sentence is nestled among others in the two preceding passages, much of this information gets filled in, though the result is somewhat different in the two contexts:
Frank became convinced that his brother, a handsome and witty doctor, was having an affair with his wife. The doctor warned her that it was only a matter of months until probable death.
His wife was secretly being treated for a dangerous illness. The doctor warned her that it was only a matter of months until probable death.
Because a specific doctor and a specific female have already been mentioned in each version, we can easily figure out who is referred to by the doctor and by her. But only the second context leads to a clear and sensible inference about whose death is under discussion. In the first context, we’re left wondering exactly who will die. The wife? Her lover, the doctor? Will they be murdered by the husband? The story only gets more mysterious with the sentence Her only hope was to undergo a disfiguring surgery. If you look back at the first passage, you’ll see that much of its jarring effect comes from the fact that you can’t help but try to make connections among the pieces of the text, sometimes with bizarre effects.
Hearers and readers can be counted on to bring this connection-making mindset to the task of language comprehension, which in turn has a powerful effect on the choices that a speaker makes about how much meaning gets packed into the language itself. If all meaning had to be encoded explicitly through language, we would end up with stories that sound like this:
Frank became convinced that Frank’s brother, a handsome and witty doctor, was sleeping with Frank’s wife. According to Frank’s belief, the fact that Frank’s brother was sleeping with Frank’s wife was a horrible betrayal by Frank’s brother and Frank’s wife, much like the experience of Frank being brutally stabbed in the back by Frank’s brother and Frank’s wife. Frank was consumed with rage over Frank’s belief that Frank’s brother and Frank’s wife were sleeping together. Then Frank learned the truth about the situation between Frank’s brother and Frank’s wife.
This passage is hard to read (not to mention highly annoying), even though it is meant to take the guesswork out of comprehension.
Any account of how human minds engage with language has to grapple with the fact that the meaning that’s conveyed by the actual linguistic code has to be dovetailed with knowledge that comes from other sources. These “other sources” don’t just represent icing on the cake of linguistic meaning. They interact with linguistic form and meaning in complex ways, and without them it would be impossible for us to use language to communicate efficiently.
The goal of this chapter is to give you a sense of the wide-ranging ways in which we all “read between the lines” of language, using the linguistic content of sentences as a starting point—and not the end point—for the construction of an enriched meaning representation. You’ll see how we fill in certain details that are not provided by the language itself; we do this by mentally re-creating the real-world situations that gave rise to the sentences in question. This allows us, among other things, to infer cause–effect relationships between sentences even when they’re not explicitly stated; to have a clear sense of how things and events that are described in a text are related in real time and space; to add vivid perceptual detail to our understanding of a narrative; to understand metaphors; and to draw very precise meanings from linguistic expressions that are inherently vague, such as words like she or his.
11.1 From Linguistic Form to Mental Models of the World
The whole purpose of talking (or writing) to others is to implant certain thoughts in their minds (often with the goal that these thoughts will lead to specific actions). At its heart, then, language comprehension involves transforming information about linguistic form into thought structures. The linguistic code constrains these thought structures, but on its own is not enough to determine them. Let’s start by taking a look at what the linguistic code does and does not contribute to meaning.
What do sentence meanings look like?
Consider a sentence like Juanita kissed Samuel. Your knowledge of English keeps you from transforming this sentence into a thought representation in which Samuel receives a violent wallop from Juanita or where Samuel is the one doing the kissing—the sentence itself simply doesn’t map onto these meanings. And it requires you to build a thought representation in which Juanita kisses Samuel. This event represents the core meaning of the sentence, derived entirely from the meanings of the words in the sentence and their combinations. (Note: with extra assumptions or background knowledge, you might also imagine other events that either led to Juanita kissing Samuel, or are the consequence of Juanita kissing Samuel. But any such additional events hinge on the thought representation of the core Juanita-kissing-Samuel event.)
Language researchers call this core meaning the proposition that corresponds to a sentence. You can think of propositions as the interface between sentences and their corresponding representations of reality. In print, it’s common to see propositions written down as logical formulas that follow specific notational conventions, so you might see the proposition that’s expressed by a sentence like Juanita kissed Samuel as:
kiss (j, s)
This is simply shorthand for a thought structure that looks something like this: In the world we’re talking about, there was a kissing event in which the person referred to as Juanita kissed the person referred to as Samuel.
Propositions represent the bare bones of a sentence, capturing those things about a situation that have to be true in the world in order for the sentence to be considered true. But this leaves a fair bit of detail unspecified. The sentence Juanita kissed Samuel is true regardless of whether Juanita gave Samuel a brief peck on the cheek or whether she kissed him on the mouth for an entire minute without drawing a breath; whether Juanita is Samuel’s mother or his lover; whether Samuel enjoyed it or was repulsed by the kiss; and so on. Presumably, some details along these lines were present in the situation that caused the speaker to utter this sentence in the first place, but none of this is contained within the sentence’s propositional content.
The propositional content is the end result of unpacking the words and syntactic structure of a sentence, so propositions are determined by the structural relationships of elements within the sentence (notice that you get a different proposition for the sentence Samuel kissed Juanita). However, in Chapter 10 you learned that speakers can choose from a variety of sentence structures to express the same meaning. So, several different linguistic forms can give rise to the same proposition: Samuel was kissed by Juanita; It was Juanita who kissed Samuel; It was Samuel who was kissed by Juanita, etc. All of these have the same core meaningful content. What this means is that all of these sentences are either true or false under the same set of circumstances. If you imagine any situation in the real world in which the sentence Juanita kissed Samuel is true, then all of the above paraphrases are true as well. Conversely, any situation in which Juanita kissed Samuel is false also renders the other paraphrases false.
What information do mental models contain?
When linguists talk about the meanings of sentences, they often have in mind their propositions. But we do much more during language comprehension than just extract the abstract propositional content of a sentence. To some extent, we also mentally encode the specific event or situation that might have triggered the utterance of the sentence. That is, we tend to build a fairly detailed conceptual representation of the real-world situation that a sentence evokes. Such representations are often called mental models or situation models. They aren’t nearly as detailed as the real triggering events, but they’re a lot richer than just the sentence’s propositional content.
It seems self-evident that understanding language must involve some form of enriched mental encoding. Admittedly, if all we did with language was to recover the propositional content of sentences, language would still be useful—for all you know, one of your distant ancestors may have survived long enough to reproduce solely because of the very useful propositional content of a statement like, “There’s a saber-tooth tiger behind you!” But there are some things that propositional content alone can’t do. It’s not likely to move you to tears when embedded within a novel, or to create enough suspense to cause you to stay up all night turning the pages of a well-written thriller. It’s often been suggested that fiction has such a hold on us precisely because our mental representations of the events described in the text are almost as detailed as if we were actually participating in those events.
But figuring out exactly what information is contained in that mental model is no trivial matter for psycholinguists. Trying to probe for its contents could well change the type of information that people encode, making it hard to infer what they represent spontaneously when curled up with a book on the couch. (Think about it: How much detail do you think you represent in the normal course of reading sentences? As soon as you try to analyze your mental representations in response to a sentence, the very act of scrutiny probably changes them.) Even less trivial is explaining precisely how the information in the mental model got there and what cognitive mechanisms were involved.
There’s a surprising amount we still don’t know about the thought structures that language implants in us. But we do have some sense of what these mental models look like from an intriguing variety of experimental scenarios and results. The first step in investigating mental models is to establish whether thought representations for sentences do in fact look more like real-world situations than like abstract propositions. So, what do real-world situations look like?
At the most basic level, when a sentence describes a situation, certain things and people are involved. But not all things that are mentioned are actually present in the situation that’s being described. For example, consider the following sentences:
Simon baked some cookies and some bread.
Simon baked some cookies but no bread.
Both of these sentences specifically mention bread, and the propositional content for each sentence also includes bread. (The proposition for a sentence like Simon baked no bread can be paraphrased as something like: it’s false that there was an event of baking in which the person referred to as Simon baked bread; Figure 11.1A.) But things are a bit different if we look at the actual situations in the world that correspond to these sentences (Figure 11.1B). The first sentence evokes a situation in which there are cookies and bread; no bread exists in the situation evoked by the second sentence. The question is, do our mental representations of the sentences somehow reflect this difference between the situations, as shown in Figure 11.1B? Or do they, like the propositions in Figure 11.1A, include the concept of bread for both example sentences?
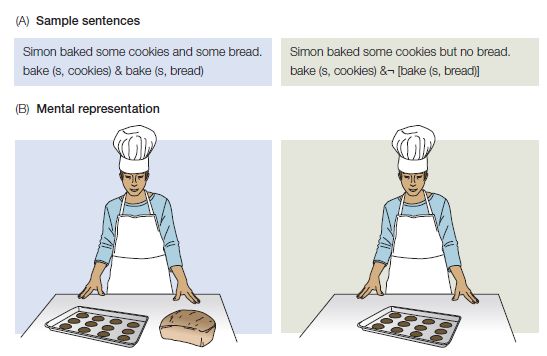
Figure 11.1 Propositions versus situations for sentences with and without negation. (A) Propositions and corresponding target sentences. Note that the symbol indicates the logical concept of negation, which is understood as stating that the proposition under negation is false. (B) Drawings showing the real-world situations that are consistent with the meanings of each of the target sentences.
To find out, Maryellen MacDonald and Marcel Just (1989) probed readers’ mental models using a memory task. Subjects read stimulus sentences like Simon baked some cookies but no bread, followed immediately by a probe word (bread or cookies). They had to respond to the probe word by pressing a “Yes” or “No” button to indicate whether that word had appeared somewhere in the stimulus sentence (see Researchers at Work 11.1). People were faster to respond “Yes” correctly when the probe word was not negated—that is, when it referred to an object that actually existed in the situation described by the sentence.
A reasonable way of interpreting these results is that even though the word bread appeared in all the critical sentences, the concept of bread was more strongly activated when the sentence required its existence in the real-world situation it described. This suggests that readers’ representations of sentences are more like encodings of real situations than like abstract propositions.
Similar probe tasks have been used to study specific aspects of mental models. A number of studies show that these mental representations aren’t fixed, static recordings; rather, the degree to which entities are active in memory waxes and wanes, much as a camera might zoom in to capture something in more detail, then zoom out again, only to focus on something else. The shifts in focus can reveal interesting things about how people structure their mental representations as they interpret language.
For example, Art Glenberg and colleagues (1987) had their subjects read stories that contained a particular object of interest (here, a sweatshirt). In half the stories, the object was physically connected to the main character of the story, like this:
John was preparing for a marathon in August. After doing a few warm-up exercises, he put on his sweatshirt and went jogging. He jogged halfway along the lake without too much difficulty. Further along his route, however, John’s muscles began to ache.
The other half of the stories were very similar, with one slight but important change: in the second sentence, the critical object becomes separated from the protagonist, as shown in this alternate version of the story:
John was preparing for a marathon in August. After doing a few warm-up exercises, he took off his sweatshirt and went jogging. He jogged halfway along the lake without too much difficulty. Further along his route, however, John’s muscles began to ache.
The researchers varied whether the memory probe appeared immediately following the critical second sentence or after either one or two additional sentences. They found that immediately after the key sentence, subjects were quite fast to respond to the probe (sweatshirt) in both types of stories, suggesting that this object was highly active in memory. But for the second story, in which the sweatshirt was peeled away from the main character, the sweatshirt quickly faded in memory, and responses to the probe were considerably slower if just one sentence intervened between the mention of sweatshirt in the text and the memory probe. In contrast, for the first story, in which the critical object stayed attached to the main character, responses to the sweatshirt probe were faster even after an intervening sentence, suggesting that the sweatshirt concept stayed highly activated in memory. Despite the fact that there’s no further mention of the sweatshirt in either story, subjects must have constructed some mental representation of what the protagonist was wearing as he jogged around the lake, causing them to respond more quickly to the probe when the sweatshirt was attached to his body. But by the fourth sentence of the story (two sentences after the mention of the sweatshirt), the activation of the sweatshirt concept waned to the point that responses were equally slow for both story types.
The memory-probe technique is interesting because it reveals something about how attention to various entities shifts over time and in response to the nature of the situation and the relationships between entities. In the study by Glenberg and colleagues, it’s apparent that the spatial relationship between entities can affect such shifts of attention. Other work with memory probes has shown that temporal information is also coded in the mental model.
In one such study, Rolf Zwaan (1996) had people read stories that described a series of events. At some point in the story, a new event was introduced with one of the following phrases: A moment later/an hour later/a day later. For example, embedded within a story describing an aspiring novelist settling down to work, readers might encounter the following pair of adjacent sentences: Jamie turned on his PC and started typing. An hour later, the telephone rang. After reading the second of these sentences, subjects had to respond to a memory probe that tested for content that had appeared in the first sentence before the temporal phrase (e.g., typing). They took longer to respond “Yes” to the probe when the temporal phrase expressed a longer interval of time (an hour later/a day later) than when it expressed a very short interval, suggesting that material in a mental model becomes less accessible if it has to be retrieved from beyond the imagined barrier of a long time interval.
Zwaan’s study also revealed that people took longer to read sentences that introduced a long temporal shift (an hour or a day, rather than a minute). He took this to mean that when a temporal phrase introduces a long break between events, it becomes harder to integrate these events in a mental model. This was supported by evidence that the connection between events separated by a longer time interval was more tenuous in long-term memory. In a variation on the memory-probe task, Zwaan tested for memory of the stories’ content after all of the stories had been read, rather than while people were reading them. Specifically, he presented subjects with sentences describing events that either had or had not occurred in the little stories, and probed to see how quickly people would respond “Yes” to the test item the telephone rang immediately after responding to the test item Jamie started typing. The idea here is that if the first test item speeds up responses to the second, this must be because the two events are tightly linked in memory. Subjects’ responses to the second event were quite fast for those stories in which the two events were separated by just a very brief interval (a moment later); by comparison, responses to the second test item were significantly slower when a longer time interval intervened between the two events.
A large number of studies have confirmed that information about time tends to be a stable fixture of mental models as people read text. Other information is also encoded in mental models—for instance, the representation of a character’s goals, as is illustrated by these two contrasting stories:
(a) Betty wanted to give her mother a present. She went to the department store. She found out that everything was too expensive. Betty decided to knit a sweater.
(b) Betty wanted to give her mother a present. She went to the department store. She bought her mother a purse. Betty decided to knit a sweater.
In (a), Betty’s decision to knit a sweater is best interpreted as serving the goal of giving her mother a present. In (b), Betty has already satisfied this goal while at the department store, and the decision to knit a sweater seems unrelated. Tom Trabasso and Soyoung Suh (1993) found that content related to a character’s goals became less accessible if the goal had been satisfied. But if the goal remained unfulfilled, depriving the reader of a sense of closure, the same content stayed highly active in memory.
Trabasso and Suh’s is not the only study to show that a lack of closure leads to stronger memory for the unresolved elements; another example can be found in a 2009 paper by Richard Gerrig and colleagues. Such results may make you wonder whether cliffhanger endings in TV episodes actually help you remember their content better. Lab studies have looked at memory over fairly short intervals of time within a single lab session, but it wouldn’t be hard to design an experiment that investigates whether cliffhangers help people remember key events over the period of a week or so.
Various studies have explored dimensions such as time, space, cause–effect relations, or information about a character’s goals, thoughts, or characteristics, and all of these seem to play a part in building mental models that are triggered by linguistic content. There’s still a bit of work to do, though, to establish whether some of these dimensions are more important than others (and if so, why), and how they might interact with each other.
There’s also still a fair bit that we don’t know about the amount of perceptual detail that goes into mental models. For example, we usually take it for granted that when people read novels, they conjure up a lot of perceptual detail through their own imaginations (though there may be some significant individual differences; see Box 11.1). When a novel gets adapted into a movie, many people have strong opinions about whether the actors in the film version look “right,” suggesting that they have mentally encoded these details while reading. But how much detail, exactly, and of what kind?
One intriguing study used a neat twist on the common memory-probe task to test whether readers actually bring to mind sounds that are described in a text. Tad Brunyé and colleagues (2010) showed their participating readers sentences that contained auditory descriptions (for example, The engine clattered as the truck driver warmed up his rig). Subjects then had to classify certain sounds as either real sounds that could occur in the world, or computer-generated artificial sounds. This test included sounds that had been described in the previous sentences, as well as sounds that had not. People were faster to classify the sounds that had been described in the earlier sentences that they’d read, suggesting that they had to some extent mentally activated these sounds, rather than representing them as mere abstractions. As a result, these sounds felt familiar by the time subjects took the sound categorization test. This is consistent with a mound of work in brain imaging, which shows that when people read perceptually rich sentences, this activates those areas of the brain that are responsible for perception in those domains (e.g., Speer et al., 2009).
At the same time, not all perceptual details of an event are represented by readers of texts—or even by their writers, as sometimes becomes apparent when a novel is adapted for the screen. In a New Yorker magazine piece about the screen adaptation of David Mitchell’s novel Cloud Atlas, Aleksandar Hemon (2012) describes some of the challenges that arose unexpectedly in creating real objects out of the novel’s material:
The scene in the control room, for example, features an “orison,” a kind of super-smart egg-shaped phone capable of producing 3-D projections, which Mitchell had dreamed up for the futuristic chapters. The Wachowskis [the film’s directors], however, had to avoid the cumbersome reality of having characters running around with egg-shaped objects in their pockets; it had never crossed Mitchell’s mind that that could be a problem. “Detail in the novel is dead wood. Excessive detail is your enemy,” Mitchell told me, squeezing the imaginary enemy between his thumb and index finger. “In film, if you want to show something, it has to be designed.” The Wachowskis’ solution: the orison is as flat as a wallet and acquires a third dimension only when spun. Mitchell, who had been kept in the loop throughout the process (and has a cameo in the film), was boyishly excited by the filmmakers’ “groping toward exactitude.”
Clearly, David Mitchell, the novel’s author, had never envisioned the “orison” in enough detail to imagine it bulging in his characters’ pockets, and it’s doubtful that his readers had either—nor is it likely that even the most committed readers designed it in their minds to the point of giving the device the aesthetically pleasing feature of shifting from two dimensions to three.
This is not surprising, because it probably takes quite a bit of time and effort to instantiate detailed visual representations (by one estimate, it can take up to 3 seconds for people to generate a detailed image of an object; see Marschark & Cornoldi, 1991). When it comes to language processing speeds, 3 seconds is a thoroughly glacial pace—the average word can be read as much as 10 times faster than that. Presumably, slower reading would allow for more visual detail to be elaborated by the reader (so, if you want to experience a novel more vividly, stop skimming!), but much is still unknown about which features are most likely to be spontaneously brought to mind during ordinary recreational reading.
What information “sticks” in memory?
Let’s step back for a moment and think about the implications of mental models (see Method 11.1). So far, I’ve been suggesting that linguistic representations are not the end result of comprehension processes, but simply the means to an end. If the ultimate goal of language comprehension is the mental model, we might expect that it would be cognitively privileged over abstract linguistic representations. And that seems to be the case, at least in terms of accessibility in long-term memory. In a now-famous study, John Bransford and his colleagues (1972) had people listen to a list of sentences and later take a memory test in which they had to state whether they’d heard that sentence earlier, in exactly that same form. Bransford and colleagues made various subtle changes to the original sentences from the list, so that they appeared in slightly altered form on the memory test. For example, subjects might first hear:
Three turtles rested beside a floating log, and a fish swam beneath them.
and later, might have to respond to the following:
Three turtles rested beside a floating log, and a fish swam beneath it.
Though the difference in wording is very slight, people had little trouble recognizing that the second sentence was different from the first. But they showed a lot more confusion if they first heard this:
Three turtles rested on a floating log, and a fish swam beneath them.
and later had to respond to this:
Three turtles rested on a floating log, and a fish swam beneath it.
In terms of surface linguistic structure, the difference between the second pair of sentences was no greater than the difference between the first pair. Yet people’s responses suggested the difference in the first pair was more memorable. The important fact seems to be that the first two sentences yield different mental models—in one sentence, the fish swims beneath the turtles, while in the second, the fish swims beneath the log and not the turtles. But the sentences in the second pair result in nearly identical mental models (see Figure 11.3). This suggests that what people remember is the mental model rather than the linguistic information used to build the model. The language itself is merely the delivery device for the really valuable information.
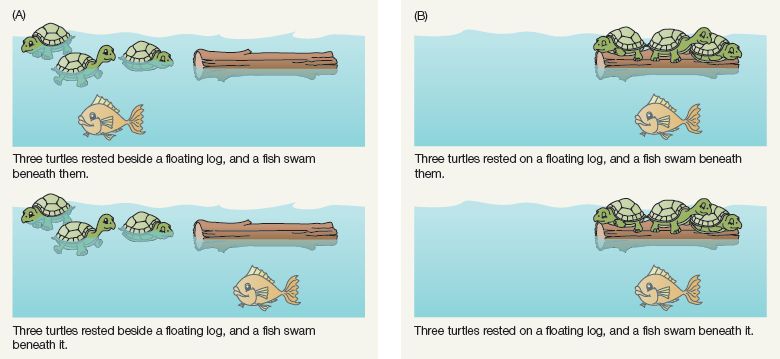
Figure 11.3 (A) Two sentences for which a small difference in wording leads to a large difference in their corresponding mental models. (B) Two sentences with a small wording difference but identical mental models. Study results indicate the difference between the two sentences in (A) is remembered much more accurately than the difference between the sentences in (B)—that is, people remember differences between mental models more readily than differences between sentences. (Adapted from Bransford et al., 1972, Cogn. Psych. 3, 193.)
I should add a qualifying remark to the conclusions that we can draw from this famous study: the study reveals that we tend not to consciously remember the exact linguistic form of what we’ve recently heard. But that’s not to say that the details of linguistic form are entirely absent from long-term memory. In numerous chapters throughout this book, you’ve seen many examples where people do retain memory for details of linguistic form, and then make efficient use of this information. Here are just a few examples of phenomena that rely on preserving information about linguistic form in long-term memory: tracking the transitional probabilities of syllables in order to segment words; learning the most probable ways of completing a temporary syntactic ambiguity; and being primed by a previous bit of syntactic structure so that you’re more likely to later reuse that same structure.
The importance of background knowledge
As you’ve seen, the information conveyed by each sentence is integrated into a mental model that contains information from earlier sentences. But other information, such as background knowledge, also contributes to the mental model. If certain background information is missing, it can sometimes make a text extremely hard to understand. Consider the following passage from Bransford and Johnson (1972):
The procedure is actually quite simple. First, you arrange things into two different groups. Of course, one pile may be sufficient depending on how much there is to do. If you have to go somewhere else due to lack of facilities, that is the next step; otherwise you are pretty well set. It is important not to overdo things. That is, it is better to do fewer things at once than too many. In the short run this might not seem important, but complications can easily arise. A mistake can be expensive as well. At first the whole procedure will seem complicated. Soon, however, it will become just another facet of life. It is difficult to foresee an end to the necessity for this task in the immediate future, but then one can never tell. After the procedure is completed, one arranges the material into different groups again. Then they can be put into their appropriate places. Eventually they will be used once more, and the whole cycle will have to be repeated. However, that is part of life.
Raise your hand if you have a very clear image in your head of what’s being described in this passage. Not likely—the passage contains a heap of extraordinarily vague words and phrases: you arrange things (what things?); one pile (of what?) may be sufficient; lack of facilities (what kind of facilities?); It is important not to overdo things, and so on and so on. Chances are, your mental model of this whole “procedure” is not very rich.
But let’s activate some background knowledge, simply by slapping a title onto this passage—say, Instructions for washing clothes. Now go back and reread the paragraph. Notice how your mental model suddenly sprouts many details that you had no way of supplying before. This little exercise demonstrates how skimpy the linguistic content can get and still be perfectly comprehensible—provided we have the means to enrich our mental models either through background knowledge or by connecting the dots within a text. It also raises an important set of pedagogical implications: that the understanding of a text can depend heavily on specific knowledge a reader is presumed to have. Even when the ability to decode the linguistic content is there, comprehension can really suffer without an adequate knowledge base (see Language at Large 11.1). For example, if you’ve led a highly sheltered life when it comes to laundry and you really don’t know what’s involved in washing clothes, the title may not have helped you that much.
11.2 Pronoun Problems
One of the key points to take away from the previous section is that hearers and readers are very good at mentally filling in an abundance of meaning even when the language itself isn’t precise. This means that communication doesn’t depend entirely on information that’s made explicit in the linguistic code, a fact that has far-reaching implications for how human languages are structured.
If readers are able to flesh out detailed meanings when confronted with imprecise language, this makes a speaker’s job much easier. In many contexts, speakers can get away with using vague, common, and easy-to-produce words like thing or stuff rather than digging deeper into the lexicon for a less accessible word, and they can avoid spelling out more detail than is necessary—in short, a great deal of information can be left unstated. Nothing demonstrates this as neatly as the existence of pronouns like she or they. Much like the words thing or stuff, pronouns contain very little semantic information. This becomes evident if you meet one in an out-of-the-blue sentence like She promised to come for lunch. Who’s she? All we know from the pronoun itself is that it refers to someone female. Yet when pronouns are used in text or conversation, we usually have no trouble figuring out the specific identity of the person in question.
As far as I know, all languages contain pronouns (though, as you’ll see in a moment, there can be some variety across languages in the specific information that pronouns carry inside themselves). It’s easy to miss just how stripped bare of meaning pronouns can be if you only consider your own familiar language. Their semantic starkness is often more visible from the outside. A revealing example can be found in a discussion of pronouns by the journalist Christie Blatchford (2011), who covered the murder trial of an Afghan-born Canadian, Mohammed Shafia. Together with his wife, Tooba Yahya, and their son, Hamed, Shafia was charged with murdering his three daughters and his first wife. Writing in the National Post, the journalist noted that there were some linguistic difficulties that arose in the testimony of a relative of the slain woman (Ms. Amir) because the witness spoke in Dari, a dialectal variant of the Farsi language:
[The witness] also said in the last months of her life, Ms. Amir was unhappy, often calling to complain about her life, and that she told her she’d overheard a conversation among the parents and Hamed, during which Mr. Shafia threatened to kill Zainab, who in April of 2009 had run away to a women’s shelter, and “the other one,” which Ms. Amir took to mean her.
But because the Dari/Farsi languages have no separate male and female pronouns—essentially, everyone is referred to as male, it apparently being the only worthy sex—she can’t be sure if it was Ms. Yahya who asked about “the other one” or Hamed.
|
Singular |
Plural |
|
|
First person |
||
|
Male |
I/me |
we/us |
|
Female |
I/me |
we/us |
|
Neuter |
I/me |
we/us |
|
Second person |
||
|
Male |
you/you |
you/you |
|
Female |
you/you |
you/you |
|
Neuter |
you/you |
you/you |
|
Third person |
||
|
Male |
he/him |
they/them |
|
Female |
she/her |
they/them |
|
Neuter |
it/it |
they/them |
Blatchford went on to remark that ongoing interpretation difficulties arose at the trial in part because Dari and Farsi are “imprecise languages.” But she’s wrong to attribute imprecision (not to mention sexism) to an entire language based on the potential ambiguity of its pronouns. Pronouns are by their very nature imprecise, as Ms. Blatchford might have concluded had she taken a moment to survey the pronominal system of English. English, as it turns out, doesn’t bother to provide information about the gender of any of its pronouns except the third-person singular; it entirely forgoes marking number on the second person; and it blurs the subject/object distinction for several pronouns (see Table 11.1). In short, using the English pronoun they to refer to a group of women (or to a group of men) leaves an English speaker in exactly the same boat as a speaker of Dari—nothing about the linguistic form of the pronoun gives the hearer a clue about gender. Box 11.2 describes some of the different pronominal systems found in languages other than English.
Even when gender is marked on pronouns, the potential for ambiguity is rife, and yet, highly skilled users of language persist in wielding them. Following are a few passages pulled from acclaimed literary works. As you’ll see, pronouns are used despite the fact that there’s more than one linguistic match in the discourse that precedes them. In these examples, the same color font is used for pronouns (underlined) and all their linguistically compatible matches (that is, all the nouns that agree in number and gender with the pronouns):
In the boxes, the men heard the water rise in the trench and looked out for cottonmouths. They squatted in muddy water, slept above it, peed in it.
from Beloved by Toni Morrison (1987)
Now the drum took on a steady arterial pulse and the sword was returned to the man. He held it high above his head and glowered at the crowd. Someone from the crowd brought him the biscuit tin. He peered inside and shook his great head.
from In Between the Sheets by Ian McEwan (1978)
In 1880 Benjamin Button was twenty years old, and he signalized his birthday by going to work for his father in Roger Button & Co., Wholesale Hardware. It was in that same year that he began “going out socially”—that is, his father insisted on taking him to several fashionable dances. Roger Button was now fifty, and he and his son were more and more companionable—in fact, since Benjamin had ceased to dye his hair (which was still grayish) they appeared about the same age and could have passed for brothers.
from The Curious Case of Benjamin Button by F. Scott Fitzgerald (1922)
Every now and then, pronouns do result in confusion, as evident in the Shafia trial testimony. Most of the time, however, they’re interpreted without fuss exactly as the speaker or writer intended. How is this done?
How do we resolve the meanings of pronouns?
In many cases, we can use real-world knowledge to line up pronouns with their correct referential matches, or antecedents. In the Toni Morrison quote, while both the nouns boxes and cottonmouths match the linguistic features on the pronoun (they’re both plural), practical knowledge about boxes and cottonmouths (venomous snakes) allows us to rule them out as antecedents for the pronoun in the phrase they squatted; only the men remains as a plausible antecedent for they.
But when real-world plausibility is not enough, we may get some help from information we’ve already entered into the mental model. In the Ian McEwan passage, by the time we get the pronoun it in the second sentence (He held it high above his head), we’ve seen three possible linguistic matches for the pronoun in the first sentence: the drum, a steady arterial pulse, and the sword. The pulse can be ruled out because of basic knowledge about how the world works—you can’t hold a pulse—but something more is needed to decide between the drum and the sword. Here, the mental model derived from the first sentence is critical: only the sword is in the hands of the man (who is the sole possible antecedent for he in He held it high above his head), and therefore is the most likely candidate. So, just as mental models are useful for filling in all sorts of implicit material, they can also help fix the reference of ambiguous pronouns.
But even more than a model is required. In the above quote by F. Scott Fitzgerald, the first sentence introduced Benjamin Button and his father Roger. How should we interpret the pronoun in the second sentence: It was in that same year that he began “going out socially”? Either Benjamin or the father are viable antecedents, given the situation model at that point, and in fact, the text goes on to elaborate that both of these characters go out together. Yet most readers will automatically assume that he refers to Benjamin, and not his father. Why is that? (Go ahead and try to answer—the question’s not purely rhetorical.)
If you did attempt an answer, you might have said something to the effect that Benjamin is the person that the passage is about, or the person who’s being focused on in the text. If so, you were exactly on the right track. In Section 11.1, I described some results by Art Glenberg and colleagues (1987) showing that when entities are entered into a mental model, they wax and wane in terms of their accessibility, depending on what’s going on in the text—typically, this accessibility was measured by memory probes. Let’s revisit the following two stories:
John was preparing for a marathon in August. After doing a few warm-up exercises, he put on his sweatshirt and went jogging. He jogged halfway along the lake without too much difficulty. Further along his route, however, John’s muscles began to ache.
John was preparing for a marathon in August. After doing a few warm-up exercises, he took off his sweatshirt and went jogging. He jogged halfway along the lake without too much difficulty. Further along his route, however, John’s muscles began to ache.
We saw from the Glenberg study that the sweatshirt entity was more accessible in a situation like the first one, where it was spatially connected with the main character, than in the second case, when it was cast aside at some point in the story. It turns out that the degree of accessibility, as measured by a memory probe, also predicted how easy it was for subjects to read sentences containing pronouns. Consider this story:
Warren spent the afternoon shopping at the store. He set down his bag and went to look at some scarves. He had been shopping all day. He thought it was getting too heavy to carry.
Did you trip over the pronoun it in the last sentence, hunting around for what was being referred to? If you did, try this version:
Warren spent the afternoon shopping at the store. He picked up his bag and went to look at some scarves. He had been shopping all day. He thought it was getting too heavy to carry.
If the second version felt smoother, then your intuitions align with the results from this study; participants spent longer reading the last sentence in the first passage than in the second passage. Notice that the sentence itself is identical in both cases, so the difficulty must have come from trying to integrate this sentence with the preceding discourse, presumably because people had some trouble tracking down the antecedent of the pronoun. Based on the results from the memory task, a likely explanation for the difficulty is that the antecedent had already faded somewhat in memory.
Pronouns, then, seem to signal a referential connection to some entity that is highly salient and very easily located in memory; the fact that the entity is so readily accessible is probably exactly what allows pronouns to be as sparse as they are when it comes to their own semantic content. You might view this as one example of a much broader language phenomenon: that the easier it is for hearers to recover or infer certain information, the less the speaker relies on linguistic content to communicate that information. This generalization fits well with the idea that the amount of information that appears in the linguistic code reflects a balance between need for clear communication and ease of production.
What makes some discourse referents more salient than others?
There are quite a few factors that seem to affect the salience or accessibility of possible antecedents. As noted earlier, the relationship of various entities within the mental model can play a role; the spotlight tends to be on the protagonist of a story and other entities associated with or even just spatially close to that character. But a number of other generalizations can be made. Often, the syntactic choices that a speaker has made reflect the accessibility of some referents over others. For example, in Section 10.3, I pointed out that when a concept is highly salient to speakers, they tend to mention this concept first, often slotting it into the subject position of a sentence. This creates a sense that whatever is in the subject position is what the sentence “is about” or is the focus of attention, and has an effect on how ambiguous pronouns get interpreted. Consider these examples:
Bradley beat Donald at tennis after a grueling match. He …
Donald was beaten by Bradley after a grueling match. He …
There’s a general preference for the subject over the object as the antecedent of a pronoun (Bradley in the first sentence, Donald in the second).
Let’s look more closely at the excerpt from F. Scott Fitzgerald on pages 462 and 464. In that passage, the cues guiding the reader through the various interpretations of the third-person pronoun come largely from the syntax. In the first sentence, Benjamin Button is established as the subject and, with two pronouns referring back to him, is the more heavily “lit” character; his father is mentioned more peripherally as an indirect object:
In 1880 Benjamin Button was twenty years old, and he signalized his birthday by going to work for his father in Roger Button & Co., Wholesale Hardware.
Hence, it’s easy to get that the pronoun in the next sentence refers back to Benjamin:
It was in that same year that he began “going out socially”—that is, his father insisted on taking him to several fashionable dances.
But notice what happens in the next sentence:
Roger Button was now fifty, and he and his son were more and more companionable—in fact, since Benjamin had ceased to dye his hair (which was still grayish) they appeared about the same age and could have passed for brothers.
Here, focus has shifted to the father, Roger Button, who now appears in subject position—and as a result, the next appearance of the pronoun he now refers back to Roger, not Benjamin. In fact, the next time that the author refers to Benjamin in the text, he uses his name, not a pronoun.
This last fact turns out to be quite revealing, and suggests that the Benjamin character has been demoted from his original position of prominence in the mental model. Throughout the narrative, the spotlight has moved from one character to the other, as made apparent by the occupant of the subject position of the various sentences and by the preferred interpretation of the pronouns.
The repeated-name penalty
Psycholinguists have found that if an entity is highly salient, readers seem to expect that a subsequent reference to it will involve a pronoun rather than a name, and actually find it harder when the text uses a repeated name instead, even though this name should be perfectly unambiguous (e.g., Gordon et al., 1993). This set of expectations can be inferred from reading times. For example:
Bruno was the bully of the neighborhood. He chased Tommy all the way home from school one day.
Bruno was the bully of the neighborhood. Bruno chased Tommy all the way home from school one day.
Readers seem to find the repeated name in the second example somewhat jarring, as shown by longer reading times for this sentence than the corresponding one in the first passage. This has been called the repeated-name penalty. But if the antecedent is somewhat less salient, no such penalty arises. Consider this sentence:
Susan gave Fred a pet hamster.
Presumably, Susan is more accessible as a referent than Fred. Hence, a repeated-name penalty should be found if Susan is later referred to by name rather than tagged by a pronoun; but no such penalty should be found if Fred is referred to by name in a later sentence.
This is precisely what Gordon and his colleagues found. That is, sequence (a) below took longer to read than sequence (b):
(a) Susan gave Fred a pet hamster. In his opinion, Susan shouldn’t have done that.
(b) Susan gave Fred a pet hamster. In his opinion, she shouldn’t have done that.
But there was no difference between sequences (c) and (d):
(c) Susan gave Fred a pet hamster. In Fred’s opinion, she shouldn’t have done that.
(d) Susan gave Fred a pet hamster. In his opinion, she shouldn’t have done that.
While expressing a referent as a subject has the effect of boosting its salience, certain special syntactic structures—often called focus constructions—are a bit like putting a referent up on a pedestal. Observe:
It was the bird that ate the fruit. It was already half-rotten.
This sounds odd, because the pronoun in the second sentence can only plausibly refer to the fruit. However, because the bird has been elevated to such a salient status (using a construction called an it-cleft sentence), the inclination to interpret it as referring to the bird is strong, leading to a plausibility clash later in the sentence. There’s no such clash, though, when the first sentence puts focus on the fruit instead, as in the following (using a construction called a wh-cleft sentence):
What the bird ate was the fruit. It was already half-rotten.
Amit Almor (1999) found that, not surprisingly, when a repeated name was used to refer back to the heavily focused antecedent in constructions like these, readers showed the repeated-name penalty. That is, readers took longer to read the repeated name (the bird or the fruit) in the second sentence of passages like these (antecedents that are in focus are in boldface):
(a) It was the bird that ate the fruit. The bird seemed very satisfied.
(b) What the bird ate was the fruit. The fruit was already half-rotten.
rather than these:
(c) It was the bird that ate the fruit. The fruit was already half-rotten.
(d) What the bird ate was the fruit. The bird seemed very satisfied.
Repeated names seem to do more than just cause momentary speed bumps in reading—they can actually interfere with the process of forming an accurate long-term memory representation of the text, as found by a subsequent study by Almor and Eimas (2008). When subjects were later asked to recall critical content from the sentences they’d read (for example, “Who ate the fruit?” or “What did the bird eat?”), they were less accurate if they’d read passages (a) and (b) than if they’d read passages (c) and (d).
We’ve seen that there are several factors that heighten the accessibility of a referent, making it a magnet for later pronominal reference: the degree to which entities are spatially linked to central characters in a text, and syntactic structure, including subject status and the use of focus constructions. In addition, the salience of a referent can be boosted by a number of other factors such as being the first entity to be mentioned in a sentence (either as the subject or not), having been recently mentioned, or having been mentioned repeatedly. Variables like these are famous for affecting the ease with which just about any stimuli can be retrieved from memory (for instance, if you’re trying to remember the contents of your grocery list, it’s easiest to remember items that appeared at the top of the list, or last on the list, or those you happened to write down more than once). It’s interesting to see that the same variables also have an impact on the process of resolving pronouns.
Where’s this going?
Although accessibility is an important factor in pronoun interpretation, it can be overridden. Consider the following examples:
John spotted Bill. He …
John passed the comic to Bill. He …
Chances are, you understood the pronoun in the first sentence to refer to John. And in the second sentence? If you were like the participants in a study by Rosemary Stevenson and her colleagues (1994), you took the pronoun to refer to Bill, even though the name Bill is in a less prominent position in the sentence than John. This fact may have less to do with what’s prominent in memory and more to do with where readers think the discourse is going. In the same study, some participants saw only the first sentence and were asked to provide a plausible second sentence to follow it; in these cases, no pronoun at all was supplied. When building on sentences like John passed the comic to Bill, most people provided a continuation that focused on the goal or endpoint of the event—that is, they more often referred to Bill than to John. Similar results were found by Jennifer Arnold (2001) in an analysis of speech from Canadian parliamentary proceedings: when speakers described an event that had a goal or an end point, they were subsequently more likely to refer back to the goal or end point of the event.
Where the discourse goes depends on the nature of the event, as well as the relations between events that are explicitly coded in the language. Try continuing these sentences:
Sally apologized to Miranda because she …
Sally admired Miranda because she …
The word because throws into relief a causal connection between the first event and whichever event is coming next; but the specific events of admiring or apologizing place different emphases when it comes to their typical causes. Normally, you apologize to someone because of something you did, but you admire someone because of something about the other person. Hence, in the first sentence, the focus is on the subject (Sally), whereas in the second it’s on the object (Miranda). A number of researchers have noted that different verbs seem to evoke different expectations of implicit causality; this was first noticed by Garvey and Caramazza (1974).
Some researchers (e.g., Kehler & Rohde, 2013) have suggested that these facts about pronouns reflect something deeper about how people interpret the relationships between sentences in a discourse. They point to examples like the following, which don’t line up neatly with an accessibility explanation:
(a) Mitt narrowly defeated Rick, and the press promptly followed him to the next primary state. (him = Mitt)
(b) Mitt narrowly defeated Rick, and Newt absolutely trounced him. (him = Rick)
(c) Mitt narrowly defeated Rick, and he quickly demanded a recount. (him = Rick)
While the first clause is identical in all of these examples, the relationship between the two clauses is not. In sentence (a), the second clause describes an event that happened after Rick’s defeat by Mitt; in sentence (b), the second clause describes an event that is highly similar to the event in the first clause (and which may have happened before, after, or at the same time as the first); in example (c), the second clause describes a consequence of the event described in the first.
To fix the reference of these pronouns, readers need to be able to discern the relationship between the clauses. But unlike the connection between accessible referents and pronouns, this discernment is not specific to pronoun interpretation—it’s something we need to do all the time in order to understand a string of sentences as a connected, coherent discourse, an issue we’ll take up in Section 11.4. In some cases, linguistic cues—including the meanings of verbs, or connectives like because, so, although, and so on—may allow readers or hearers to anticipate a specific relation, and to generate strong expectations about which entities are likely to be mentioned. In such cases, the use of coherence relations to resolve ambiguous pronoun reference is a happy side effect.
11.3 Pronouns in Real Time
The preceding section helps to explain why pronouns are usually perfectly interpretable, despite their blatant grammatical ambiguity. It also adds to the pile of evidence from earlier chapters showing that ambiguity as an inherent feature of language. We’ve seen that lexical and syntactic ambiguities are almost always resolved without too much trauma. But they’re not cost-free, either. They often exert a processing cost that can be detected through experimental techniques, whether or not that cost is consciously registered by a hearer or reader. And there’s growing evidence that some language users deal with ambiguities less smoothly than others.
In this section, we’ll explore how hearers or readers cope with pronouns under time pressure, coordinating different types of information. And we’ll take a look at what it takes to interpret pronouns smoothly by considering what children need to learn in order to accomplish the task in an adult-like way.
Coordinating multiple sources of information
At the very least, pronoun resolution involves four general sources of information: (1) the grammatical marking of number and gender, among other factors, on the pronouns themselves, where this is available; (2) the prominence of antecedents in a mental model; (3) real-world knowledge that might constrain the matching process; and (4) coherence relations that allow us to understand the connections between sentences. How are these sources of information coordinated by hearers? One possibility is that grammatical marking acts as a filter on prospective antecedents so that only those that are linguistically compatible with the pronoun are ever considered as candidates; information about discourse prominence or real-world information might then kick in to help the reader/listener choose among the viable candidates. On the other hand, the most accessible antecedent may automatically rise to the top and become automatically linked to any pronoun that later turns up; grammatical marking and other information sources might then apply retroactively to verify that the match was an appropriate one.
A number of serviceable techniques can be used to shed light on the time course of pronoun resolution, but probably the most direct and temporally sensitive method is to track people’s eye movements to a scene as they hear and interpret the pronoun. As you’ve seen in Chapters 8 and 9, when people establish a referential link between a word and an image, they tend to look at the object in the visual display that’s linked with that word. The same is true in the case of pronouns. Researchers can use eye movement data to figure out how long it takes hearers to identify the correct antecedent for the pronoun, as well as whether any other entities were considered as possible referents.
In a 2000 study, Jennifer Arnold and her colleagues had their subjects listen to miniature stories, and tracked their subjects’ eye movements to pictures that depicted the various characters and objects involved in these narratives. The story introduced two characters of either the same gender or different genders. Each story contained a key sentence with a pronoun. Depending on which characters had been introduced, the pronoun was grammatically compatible either with both of the characters, or with just one of them:
Mr. Biggs is bringing some mail to Tom, while a violent storm is beginning. He’s carrying an umbrella, and it looks like they’re both going to need it.
Mr. Biggs is bringing some mail to Maria, while a violent storm is beginning. She’s carrying an umbrella, and it looks like they’re both going to need it.
These two stories and their accompanying illustrations are shown in Figure 11.4. For participants looking at the depictions in Figures 11.4A and 11.4C, it would be obvious that Mr. Biggs is the correct referent for the pronoun he. He also happens to be the character that is mentioned first and occupies the subject position in the first sentence.
Now, if grammatical marking serves as a filter on antecedents so that only matching antecedents are considered, we’d expect that when there’s only one male character, people would be very quick to locate the antecedent of the pronoun and that they wouldn’t consider Maria as a possible referent for the pronoun he. That is, their eye movements should quickly settle on Mr. Biggs and not be lured by the Maria character. But in the stories with two male characters, they should briefly consider both Mr. Biggs and Tom as possibilities, and this should be reflected in their eye movements. The discourse prominence of Mr. Biggs might kick in slightly later to help disambiguate between the two possible referents.
On the other hand, if pronoun resolution is driven mainly by the accessibility of the antecedent, then grammatical marking has a more secondary role to play when it comes to processing efficiency. For the stories above, only Mr. Biggs should be considered as the possible antecedent, regardless of whether the pronoun is grammatically ambiguous or not. So eye movements should favor Mr. Biggs over either Tom or Maria as soon as the pronoun he is pronounced. But now let’s suppose that the picture shows the less prominent discourse entity (that is, either Tom or Maria) as the umbrella holder, and hence the correct referent of the pronoun he in the second sentence. Now finding the referent should be slower and more fraught with error. This should be true regardless of whether the pronoun is grammatically ambiguous (Figure 11.4B) or specific (Figure 11.4D).
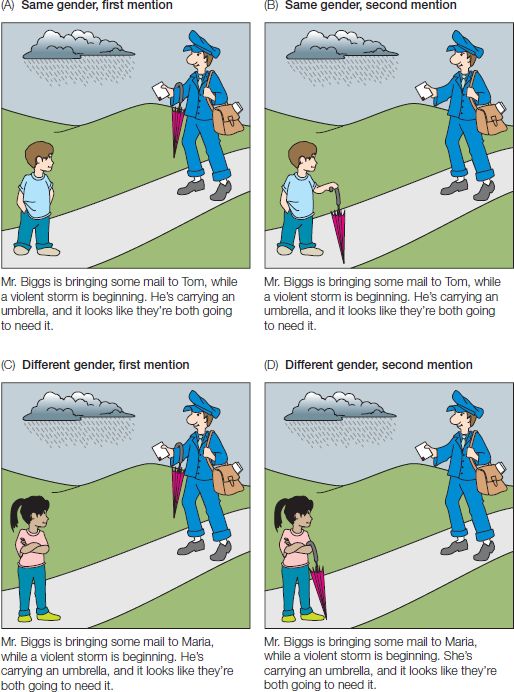
Figure 11.4 Visual displays and critical stimuli from the eye-tracking study (Experiment 2) by Arnold et al. The character carrying the umbrella was always the referent of the critical pronoun. (Note: the pictures shown here are modified from the well-known cartoon characters that were used in the original study.) (Adapted from Arnold et al., 2000, Cognition 76, B13.)
When Arnold and her colleagues analyzed the eye movement data from their study, they found that hearers were able to use gender marking right away to disambiguate between referents, even when the antecedent was the less prominent of the discourse entities (see Figure 11.5). That is, as soon as participants heard the pronoun he, they rejected Maria as a possible antecedent. This was evident by the fact that very shortly after hearing the pronoun, their eye movements for the illustrations 11.4C and D settled on the only male referent. So, grammatical marking of gender seems to be used right away to disambiguate among referents. But discourse prominence had an equally privileged role in the speed of participants’ pronoun resolution. That is, when the pronoun referred to the more prominent entity, hearers quickly converged on the correct antecedent, regardless of whether the pronoun was grammatically ambiguous. The only time that hearers showed any difficulty or delay in settling on the correct referent was when the pronoun was both grammatically ambiguous and referred to a less prominent discourse entity (see Figures 11.4B and 11.5B).
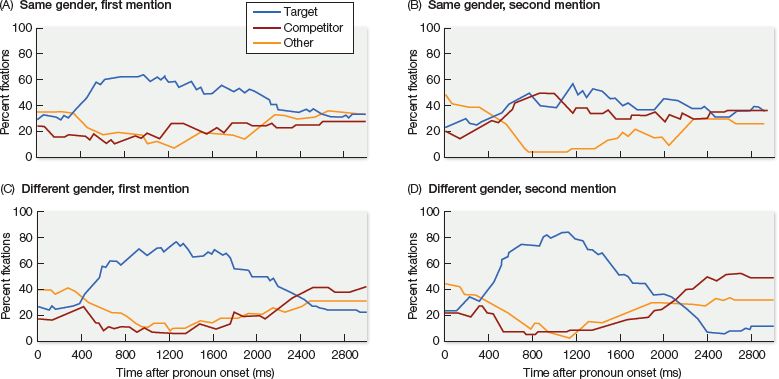
Figure 11.5 Results of Arnold et al.’s Experiment 2. The patterns of eye movements plotted against the three objects in the visual displays shown in Figure 11.4. The graph tracks the mean percentage of looks (within a 33-ms timeframe) to each of the three objects in the display. Target = correct character (with umbrella); competitor = competing character (no umbrella); other = elsewhere in the display (e.g., clouds). (Adapted from Arnold et al., 2000, Cognition 76, B13.)
These results may have a familiar ring to them. Back in Chapter 9, we tested various theories of ambiguity resolution, focusing on temporarily ambiguous garden path sentences. For the most part, findings from that body of work show that there don’t seem to be dramatic differences in the relative timing with which various types of information are recruited to resolve the ambiguity. The results from the pronoun study we’ve just seen make a similar point: people seem to be able to simultaneously juggle multiple sources of information to resolve the potential ambiguity inherent in pronouns. But the data also revealed that, in some cases, interpreting a pronoun can cause difficulty—specifically, hearers in that study took a while to resolve the pronoun when it was grammatically ambiguous and referred to the less prominent antecedent. You don’t have to dig too far in the experimental literature to find other examples where pronouns create some processing costs for readers/hearers.
For example, Bill Badecker and Kathleen Straub (2002) measured reading times for sentences like these:
(a) Kenny assured Lucy that he was prepared for the new job.
(b) Julie assured Harry that he was prepared for the new job.
(c) Kenny assured Harry that he was prepared for the new job.
The researchers found that the second clause of sentence (a) was read faster than the second clause of either sentence (b) or (c). In (a), both gender and discourse prominence converge to favor Kenny as the antecedent, while in (b), the pronoun he is grammatically consistent with a single antecedent (Harry), but this antecedent is not discourse prominent, and in (c) the (presumed) antecedent Kenny is discourse prominent but the pronoun is grammatically consistent with both Kenny and Harry. These results suggest that pronoun resolution goes most smoothly when multiple sources of information (or perhaps a single very strong one) favor a single antecedent. (Notice that Badecker and Straub’s results don’t align exactly with the eye-tracking data from Arnold et al., where a delay in interpreting the pronoun was only found in the situation where neither gender marking nor discourse prominence was helpful in finding the referent. See if you can generate ideas about why the two experiments didn’t pattern exactly alike.)
Pronoun resolution by children
Pronouns, then, however ubiquitous they may be across the world’s languages, do come with some processing cost at least some of the time, and they do require hearers to efficiently coordinate the activation and inhibition of competing alternatives. But as I discussed in Chapter 9, such coordinating skill is not to be taken for granted. It requires considerable cognitive control, something that’s lacking in certain populations—little kids, for example. It’s possible that shakiness in cognitive control skills could have implications for the successful interpretation of pronouns.
In fact, a glance through some texts written for children makes it seem as if the authors think that pronouns might tax the abilities of their young readers. In the following passage, repeated names occur in contexts where an adult reader might expect (and prefer) a pronoun. Take this example from Thank You, Amelia Bedelia by Peggy Parish:
“Jelly! Roll!” exclaimed Amelia Bedelia. “I never heard tell of jelly rolling.” But Amelia Bedelia got out a jar of jelly. Amelia Bedelia tried again and again. But she just could not get that jelly to roll.
Amelia Bedelia washed her hands. She got out a mixing bowl. Amelia Bedelia began to mix a little of this and a pinch of that.
Is this kind of writing doing kids a favor? What do we know about how young children manage the interpretation of pronouns?
Hyun-joo Song and Cynthia Fisher (2007) discovered that even tots as young as two and a half are able to pick out one of two possible characters in a story as the referent for an ambiguous pronoun, based on the referent’s prominence in the discourse. Their young participants looked at pictures while listening to stories like these:
Look at the dog and the horse. On a sunny day, the dog walked with the horse to the park. And what did he see? Look! He saw a balloon!
By tracking the children’s eye movements, Song and Fisher were able to see that their little subjects preferred to look at the more prominent character (the dog) rather than the less prominent one (the horse) upon hearing the ambiguous pronoun, much as the adults did in the study by Jennifer Arnold and colleagues (2000). But the youngsters were far slower to apply this information than the adults; where adults tended to settle on the more prominent character within 200 ms of the end of the pronoun, it took the children more than 3 seconds to do the same. (Just slightly older children, about 3 years of age, were already considerably more efficient.) So, at a very young age, kids are already starting to develop the tools to interpret ambiguous pronouns, although this ability is still sluggish.
Looking at somewhat older kids, Arnold et al. (2007) found that 4-year-olds were consistently able to use gender marking to pick out the correct antecedent of a pronoun, and that by age 5, they were as quick as adults in applying that knowledge. But their ability to use information about discourse prominence was not clearly apparent even by age 5. Hence, there’s good reason to believe that children’s interpretation of grammatically ambiguous pronouns truly is somewhat vulnerable.
In fact, well after they show clear knowledge of some of the constraints on pronominal reference, kids still seem to be readily distracted by other discourse entities. Kaili Clackson and her colleagues (2011) tracked children’s eye movements to narratives like these:
(a) Peter was waiting outside the corner shop. He watched as Mr. Jones bought a huge box of popcorn for him/himself over the counter.
(b) Susan was waiting outside the corner shop. She watched as Mr. Jones bought a huge box of popcorn for her/himself over the counter.
There’s no real ambiguity here for either sentence (see Box 11.3). In (a), constraints on ordinary personal pronouns (him) and reflexive pronouns (himself) dictate the correct antecedents (him = Peter; himself = Mr. Jones). It’s the same in (b), except that now there is information from gender marking in addition to these linguistic constraints on pronouns and reflexives.
When Clackson and her colleagues tested 6- to 9-year-olds, they found that the kids reliably picked out the correct antecedent in response to questions like, “Did Mr. Jones buy the popcorn?” Nevertheless, their eye movements hinted at lingering troubles in suppressing the competing referent when it matched the gender of the actual antecedent. That is, in the (a) sentences, kids often looked at the wrong character upon hearing the pronoun. Adults, on the other hand, were very adept at ignoring the wrong character, even when it matched the gender of the antecedent.
Despite taking some time to fully stabilize in their understanding of pronouns, kids seem to have a good sense of what pronouns, in their stripped-down linguistic essence, are for—that is, they serve as a practical shorthand for referring to highly salient discourse entities. Maya Hickmann and Henriëtte Hendriks (1999) found that, across various languages, children age 4 and older appropriately used pronouns to refer back to more prominent discourse entities rather than repeating their names. And there’s some evidence that 7-year-olds show a repeated-name penalty when a proper name refers back to a highly salient entity, preferring a grammatically unambiguous pronoun in its place (Megherbi & Ehrlich, 2009).
But it would be a mistake to conclude that all children easily converge on efficient pronoun resolution in early their school years. Jane Oakhill and Nicola Yuill (1986) assessed the reading skills of 7- and 8-year-old children and tested their ability to resolve pronouns in sentences like:
Sam sold a car to Max because he needed the money.
Sam sold a car to Max because he needed it.
Pronoun resolution was tested by having the children answer questions like “Who needed the money?”
Oakhill and Yuill found that less skilled readers were considerably worse at identifying the correct antecedent of the pronoun (see Table 11.2). The poor readers made errors more than 37 percent of the time when they were not allowed to reread the sentence before identifying the antecedent—an error rate that begins to approach random guessing. Even when they were allowed to reread the sentence, and the pronoun was grammatically unambiguous (with one male and one female character in the sentence), the less skilled readers still made mistakes more than 13 percent of the time.
Adapted from Oakhill & Yuill, 1986, Lang. Speech 29, 25.
This study looked at sentences that were fairly demanding, in which readers needed to recognize that the second clause was an explanation for the first, and then work out what a plausible explanation would look like. Perhaps it’s not surprising that young readers would be overly taxed by such examples. But a paper by Jennifer Arnold and her colleagues (2018) suggests that individual differences in pronoun resolution persist into adulthood, even for simple spoken sentences, and that these differences may be driven in part by how much exposure people have to written language. Adult participants heard narrated stories involving two characters. The stories included sequences of sentences like:
Ana is cleaning up with Liz. She needs the broom.
The participants answered questions that probed for the antecedent of the pronoun. By now, you know enough to predict that most people would choose the subject of the first sentence, Ana. But the preference for subject antecedents turned out to be quite variable, and this variability was related to a measure of participants’ reading habits. The researchers used a task known as the Author Recognition Test (ART), which requires participants to identify real authors’ names from a list that includes both authors and nonauthors—performance on this simple test has been shown to correlate with how much reading people do. Those who scored higher on the ART showed a stronger bias to interpret the pronoun as referring to the subject of the previous sentence.
It’s important not to draw sweeping conclusions from this result, as we don’t know for sure that reading a lot causes the stronger subject bias. (It’s possible, for example, that people who happen to be efficient processors of language enjoy reading more.) In discussing the link between reading and pronoun resolution, the authors of the study speculated that written discourse tends to be more structured and thematically organized than spoken language, so perhaps there is a more systematic relationship in written language between pronouns and their antecedents. This claim awaits further testing through detailed statistical analyses of the patterns of spoken and written language, as well as experiments testing the effects of language exposure on pronoun interpretation. But the study hints at the possibility that variations in linguistic experience affect how we make sense of pronouns, those ubiquitous, ambiguous morsels of language. If this turns out to be true, the picture for pronoun interpretation would be quite consistent with that we’ve seen for other types of ambiguities: resolving them requires both fluid cognitive abilities such as cognitive control and working memory, as well as crystallized knowledge that comes from a deep base of language knowledge and the patterns of its use.
For all their bareness, pronouns clearly play a useful role in language, one that apparently makes up for the ambiguities they create. Like all ambiguity, the referential uncertainty that pronouns introduce does at times have a discernible processing cost for hearers and readers. And, as with other species of ambiguity, the degree of difficulty falls on a continuum, depending on how strongly various information sources support one interpretation over another, and depending on the abilities and knowledge of the hearer.
11.4 Drawing Inferences and Making Connections
If you go back to the introduction to this chapter and read the two versions of the story about Frank, his wife, and his brother the doctor, you’ll see that the well-sequenced discourse makes it easy to interpret pronouns in a smooth and sensible way, while the jumbled discourse often does not. But there are other important ways in which discourse structure affects interpretation. For example, look again at the following snippets from the two versions:
Frank had to confront the fact that she was gone from his life. Then he learned the truth. Racked with sorrow, he killed himself.
In the end, she lingered for some time, but eventually, Frank had to confront the fact that she was gone from his life. Racked with sorrow, he killed himself.
The difficulties in the first passage arise because we insist on understanding sentences as connected together in a coherent way‚ but none of the connections that we attempt make much sense. We struggle to fill in what “truth” Frank learned—connecting the second sentence back to the first seems to imply that his wife wasn’t gone from his life after all. But then the third sentence mystifies when we try to read it in the context of the second: why would this particular turn of events cause Frank to kill himself out of sorrow? In the second, smoother passage, on the other hand, connecting the last sentence with the previous one provides us with a perfectly reasonable explanation for Frank’s sorrow and ultimate suicide.
Bridging inferences
As I mentioned in Section 11.2, in order to understand a text as coherent, we often have to draw inferences that connect some of the content in a sentence with previous material in the text or with information encoded in the mental model. Such inferences are called bridging inferences. There’s good evidence that people routinely and spontaneously try to generate bridging inferences as part of normal language comprehension. For instance, in one study, John Black and Hyman Bern (1981) presented readers with contrasting sentence pairs such as these:
The cat leapt up on the kitchen table. Mike picked up the cat and put it outside.
The cat walked past the kitchen table. Mike picked up the cat and put it outside.
The first pair of sentences offers a readily accessible causal link between the two sentences. We infer that the cat’s action of leaping onto the kitchen table is likely what caused Mike to deposit it outside. But no handy causal connection is available in the second pair. Black and Bern had their subjects read through a series of such sentence pairs and then distracted them for about 15 minutes before administering a memory test. They found that their readers were better able to recall the content of the second sentence when cued with the first if the two sentences were easily interpreted as cause and effect than if they were not. Moreover, in a slightly different version of the memory test, when subjects were asked to freely recall the content of the little discourses, they found that for the causally related sentences, there was a greater tendency to remember the two sentences as a unit; people tended to remember the content of both sentences if they recalled either one of them, and they were more likely to roll them together into a single complex sentence connected by an explicit linking word.
Another way to see the integration process in action is by looking at the reading times of discourses that offer strong versus weak inferential connections between sentences. Jerome Myers and colleagues (1987) measured how long it took people to read a sentence that had either a very close or a more distant causal connection to the preceding sentence. For instance:
(a) Cathy felt very dizzy and fainted at her work. She was carried away unconscious to a hospital.
(b) Cathy worked very hard and became exhausted. She was carried away unconscious to a hospital.
(c) Cathy worked overtime to finish her project. She was carried away unconscious to a hospital.
(d) Cathy had begun working on her project. She was carried away unconscious to a hospital.
Reading times for the target sentence (She was carried away unconscious to a hospital) got progressively longer as the causal relationship between the two sentences became more opaque, with the sentence being read fastest in passage (a) and slowest in passage (d). At the same time, memory for the content of the sentences was best when the causal connection was clearest, in line with the data from Black and Bern’s study. These results suggest that during reading, people do generally invest the processing resources—even if unconsciously—to establish causal connections between sentences. (As discussed in Language at Large 11.2, similar visual inferences are at play when we watch movies.)
Causal links between sentences are just one type of bridging inference. Another common type involves linking referents across sentences, when the relationship is not linguistically explicit, as in:
Horace took the picnic supplies out of the car. The beer was warm.
The most natural way to interpret the beer is to assume it’s among the picnic supplies that were taken out of the car. Plausible enough, but it seems some extra work needs to be done in order to make that connection; in one of the earliest studies of bridging inferences (Haviland & Clark, 1974), reading times for the target sentence The beer was warm were longer when the link to the preceding sentence was implicit than when it was explicit, as in:
Horace took some beer out of the car. The beer was warm.
The relationship between the two parts of the bridge can be instantiated in various ways. It can involve a set-membership relationship between the bridged element and the previous content, as in the picnic supplies example or the sentence below, in which we infer the captain is a member of the Canadian Olympic hockey team (as indicated by the matching color font):
The Canadian Olympic hockey team looks really strong this year. The captain is brimming with confidence.
The bridge can involve a part-whole relationship, like this:
My car broke down on my way to work. It was the radiator.
Be careful carrying that box! The bottom is about to give out.
The bridging relationship can involve an alternative (often unflattering) way of describing the referent:
I can’t stand my physics professor. I’d be happy if the windbag dropped dead.
My son is starting to get on my nerves. The damn child won’t stop whining.
Or, the bridge can involve an element that’s known to be associated with a particular scenario:
Timmy’s birthday party was a great success. The cake was shaped like a triceratops.
Our final exam came to an abrupt halt when the proctor fell to the floor in a dead faint.
Presuppositions
The two types of bridging inferences we’ve discussed so far—causal and referential inferences—differ in an interesting way. Let’s look again at an example of each:
Stuart was caught plagiarizing his essay. He was expelled immediately.
Horace took some beer out of the car. The beer was warm.
In the first example, which involves a causal inference, there’s nothing in the second sentence to signal that the hearer needs to connect up the second sentence with previous material—the sentences are spontaneously integrated as the hearer attempts to relate the second sentence in some sensible way to the first sentence. But sometimes the integration is guided a bit more precisely by a specific word or phrase that signals that a particular piece of new content has to be linked back with some older content. In the second example, it’s the definite article in the phrase the beer that forces the link. Notice how the connection between the two sentences seems weaker in the sequence Horace took the picnic supplies out of the car. Some beer was warm. Unlike an indefinite noun phrase (some beer), the definite description (the beer) signals that the speaker is referring to something that’s already been established in the discourse or, at the very least, can be presumed to exist. Consider, for instance, the difference between these two sentences:
Sandra wants to vote for an honest politician.
Sandra wants to vote for the honest politician.
The first sentence makes sense even if there’s no such thing as an honest politician anywhere, but the second requires not only that one exists but that there’s a specific one that’s already familiar in the discourse. So, certain bits of language can serve as triggers that force a bridging inference because they communicate exactly what information should already be present in the mental model—such language is said to carry a specific presupposition. Linguistic expressions that trigger presuppositions come in a variety of forms, from definite referential phrases (the beer, his dog), to certain types of verbs (regret, know, stop), to some adverbs (again, once more), and even to certain kinds of syntactic constructions, like the focus constructions you say in Section 11.2.
Here are a few other examples, with the presupposition-triggering expression in bold type:
Daniel regrets that he wasted five years of his life studying geology. (presupposes that Daniel wasted five years studying geology)
Jana has finally stopped illegally importing smutty comic books. (presupposes that Jana has been illegally importing comic books)
It was her boyfriend’s boss who Melinda irritated at the party. (presupposes that Melinda annoyed some person at the party)
Ganesh escaped from jail again. (presupposes that Ganesh has escaped from jail before)
Presuppositional language basically acts as an instruction to the hearer to go search for specific content in the mental model. It can greatly enhance the efficiency of communication, by serving as a pointer to already-encoded material. For example, in a certain context, you could tell your friend:
So, the problem with my car turned out to be the battery.
The definite descriptions in this sentence (my car, the battery, and the problem with my car) allow you to make certain assumptions about what your friend already knows. You don’t need to say:
So, I have a car and my car has a battery. The car had a problem, and the problem turned out to be the battery.
Now suppose that you and your friend have never spoken about your car before. It’s reasonable to suppose that, despite this, she knows it’s common for people to own a car, and for cars to have batteries. But she may not have known that you were having problems with your car. By using the phrase the problem with my car, you’re signaling to her that you assume this information is already in her mental model, so it would be natural for her to insert this as background knowledge through a process known as accommodation. This happens to be a really interesting consequence of presuppositional language, and it can have powerful effects on the inferences that get added to the mental model. Imagine attending your first day of class and having the instructor tell the students, “You need to have this form signed by your probation officer.” At this, you might cast nervous glances around at your classmates. You can infer, based on the definite description your probation officer, that it’s typical for the students in the class to have a probation officer—or at least, that the instructor thinks so!
Because presupposition can serve as a trigger to add (presumably familiar) information into a mental model, these linguistic devices have caught the attention of researchers who study the phenomenon of false memories. False memories arise much more often than people think, partly because the mental models we build as a result of communicating with others are not neatly divided from the memories we have of events that we’ve witnessed or experienced ourselves. Language-based memories have a way of sloshing over to other kinds of memories, and vice versa. For example, memory researchers have discovered that people sometimes come to believe that they themselves have experienced something they’ve only heard about. (Perhaps this has happened to you. Have you ever mistakenly absorbed as your own memory a story you’ve repeatedly heard a relative talk about, only to have that person later object that the event happened to her and not you?)
All this raises some thorny questions about the accuracy of eyewitness testimony in situations in which a person has witnessed a crime or an accident. Do their accounts really reflect the person’s firsthand memories and perceptions of the event, or have their recollections become contaminated by how other people have talked about the event? If the latter, it becomes important to look at the kind of language used in the course of discussing the event—for example, there’s a concern that the language used by police while interrogating a witness could taint the witness’s reported memories.
One particularly provocative research thread involves looking at whether presuppositional language—with its presumption that certain information is already known—can induce hearers to falsely remember events or referents. Memory researcher Elizabeth Loftus and her colleagues (1978) carried out some classic experiments to see whether people could be nudged to misremember events as a result of leading questions that triggered presuppositions. For instance, in one scenario, subjects played the role of eyewitnesses to a traffic accident and were questioned about the series of events that led to the accident. Those who heard the question, “Did you see the stop sign?” were more likely to answer “Yes” than those who heard, “Did you see a stop sign?”—in neither case was there a stop sign in the scene. Later work by Klaus Fiedler and Eva Walthier (1996) confirmed that questions containing presuppositions led subjects to falsely remember objects in a scene at a rate of 10 to 40 percent, and that these false memories became more likely as the time gap between first hearing the presuppositional language and the memory test lengthened. This finding hints at the very real possibility of corrupting the memories of witnesses in real-life situations, given that witnesses often must wait weeks or months between first being questioned about an event and eventually testifying about it in a court.
Beyond eyewitness accounts, it’s worth taking a close look at presuppositions in persuasive messages. Since presuppositional language signals that certain information should already be present in the hearer’s mental model, it may well have the force of making controversial statements feel more settled and less open to debate than they would be if the same notions were overtly introduced as new information to add to the mental model. Or, it may signal something about implied social norms. For example, one married lesbian woman has told me that she makes a point of casually referring to her spouse using the definite description my wife, even to people who are unfamiliar with the fact that she has one. She explains that by doing so, she can communicate that it’s a common, unremarkable fact for two women to be married to each other—just as a heterosexual man wouldn’t feel the need to explicitly say, “So, I have a wife,” before referring to his spouse as “my wife.”
Elaborative inferences
So far, we’ve been looking at examples where inferences are required for a sentence to become properly integrated with previous discourse or material that’s presumed to be already encoded in the mental model. But not all inferences have this quality of backward connection. For instance:
The intruder stabbed the hapless homeowner three times in the chest.
The hungry python caught the mouse.
After years of training, the swimmer won a bronze medal at the Olympics.
Though these sentences don’t say so, you may have arrived at the following conclusions: the intruder used a knife to stab the homeowner, and not an ice pick or a pair of scissors; the python ate the mouse after catching it; and the swimmer didn’t win any silver or gold medals at the Olympics. Such inferences aren’t dependent on making connections between sentences. Instead, they seem to capture fairly natural assumptions about what’s typical for the events that are being described, or what the speaker was likely intending to convey. Such inferences are called elaborative inferences.
In a sense, elaborative inferences feel less necessary than bridging inferences in that they’re not needed for a text to stick together in a cohesive way. Rather, they feel a bit more like some of the “extra” aspects of meaning in mental models that we talked about in Section 11.1—for example, very specific sensory representations about the sounds of the events being described, or, as in the vague passage about doing laundry (see page 459), all the added details that brought the passage to life. In many cases, nothing terribly serious hinges on whether the elaborative inferences are drawn, and they often seem truly optional from the perspective of the speaker’s intended message—perhaps they make the message richer or more memorable but skipping the details doesn’t necessarily impede understanding. At other times, though, speakers might feel they’d been misunderstood if the hearer failed to compute the inference; and conversely, the hearer might feel that the speaker had somehow been deceptive or uncooperative if he hadn’t meant to imply a certain additional meaning. For example, a hearer would be right to complain if a speaker described the achievements of superstar swimmer Michael Phelps with the sentence Phelps won two silver medals at the 2012 Olympics, when in fact the athlete had won four gold medals as well. Inferences of this sort seem to hinge on expectations that hearers and speakers have about each other and about how rational communication words; because they involve a strong social component, we’ll pick these up in much more detail in Chapter 12.
Overall, the body of psycholinguistic literature suggests that while hearers or readers consistently compute bridging inferences, they don’t always compute elaborative inferences. They’re more likely to do so if the context sets up very strong expectations in support of the inference. For example, Tracy Linderholm (2002) created small discourses that invited varying degrees of predictive inference—these are inferences about the likely outcome of a described event, as illustrated earlier with the hungry python sentence (which led to the plausible inference that the python ate the mouse after catching it). The degree of contextual support for the inference was manipulated by varying the final sentence of the following discourse:
Patty felt like she had been in graduate school forever. Her stipend was minimal and she was always low on cash. Some weeks, she had nothing to eat but peanut butter and jelly. Patty packed her lunch every single day to save money. She yearned for the day she could afford to eat in a restaurant. Alas, she pulled out her sack lunch and looked at its contents. Patty bit into her apple, then stared at it.
The final sentence could then read either:
It had half a worm in it. (high support)
or It had an unpleasant taste. (moderate support)
or It had little flavor. (low support)
A plausible predictive inference is that Patty spit out her mouthful of apple. This would be far more likely in the event of finding half a worm (high support) than if the apple were merely bland (low support). Linderholm tested for the presence of this inference by using the standard tool of comparing reading times for sentences that were either consistent or inconsistent with this inference: Patty spit out the bite of apple versus Patty swallowed the bite of apple. She found longer reading times for the inconsistent sentence than for the consistent one only in the “high support” context, suggesting that it takes a fairly loaded context before people will generate plausible predictions of events.
But there was a catch to this finding. The likelihood that her subjects computed an inference was also dependent on their working-memory capacity. Linderholm administered a reading span test to all her participants (as discussed in Section 9.6), so she was able to separate them into those with a high memory span and those with a low memory span. The low-span subjects showed no evidence of computing the inference for any of the contexts—a reliable difference in reading times for consistent versus inconsistent target sentences was limited to the high-span subjects, and even then, only in the “high support” contexts. Other studies have confirmed the role of both contextual factors and individual differences in determining whether certain inferences are likely to be drawn.
Here’s an especially interesting variable: people are more likely to predict outcomes that they want to happen than they are to predict undesired outcomes. Have you ever read a novel and reacted with utter disbelief when you got to the part where your favorite character died? That sense of disbelief may be a reflection of your predictive processes in action.
In a well-known study of predictive inferences, Gail McKoon and Roger Ratcliff (1986) found that people rarely generated specific predictions when presented with sentences such as:
The director and cameraman were ready to shoot close-ups when suddenly the actress fell from the fourteenth story.
Instead of inferring, say, that the actress died as a result of the fall, they encoded something more vague, along the lines of “something bad happened.” David Rapp and Richard Gerrig (2006) probed a bit deeper and suggested that the specificity of people’s predictions might depend on how they felt about the actress. What if she was a tireless advocate for charity work? Would people be less likely to predict her death than if they thought she was a dishonest and abusive person? To test this question, they created stories that varied on several dimensions. Some of the stories were written so that the final sentence represented a probable outcome of the story’s events:
Peter was hoping to win lots of money at the poker table in Vegas. He was holding a pretty lousy hand but stayed in the game. Peter bet all of his money on the current hand. Peter lost the hand and all of his money.
Stories like these were compared with ones where the final sentence described a very unlikely outcome—for example, the same story about Peter might end with the sentence Peter won the pot of money with his hand. Not surprisingly, when subjects were asked whether the outcome was a likely one, they judged the first version (in which Peter lost his money) as more likely than the second version. They also spent more time reading the final sentence when it described an unlikely outcome, which suggests that the sentence clashed with their expectations about the story’s continuation. This finding is consistent with Tracy Linderholm’s study, in which strong contextual information in the story led to certain predictions. The interesting twist in Rapp and Gerrig’s study was that at the very beginning of the story, subjects were given information that was intended to get readers to either root for Peter or hope he would lose his money:
Peter was trying to raise money to pay for his sister’s college education. Peter was hoping to win lots of money at the poker table in Vegas. He was holding a pretty lousy hand but stayed in the game. Peter bet all of his money on the current hand.
Do you want Peter to win? Of course you do. Now consider this version:
Peter was raising money to finance a racist organization in the United States. Peter was hoping to win lots of money at the poker table in Vegas. He was holding a pretty lousy hand but stayed in the game. Peter bet all of his money on the current hand.
Rapp and Gerrig assumed (based on ratings with a separate set of subjects) that for this story version, the majority of readers would hope Peter would lose. Moreover, they predicted that readers’ desires about the outcome would help shape their predictive inferences. That’s exactly what they found: in addition to the likelihood of the outcome in the final sentence, people also took into account the information about Peter’s character and goals. When the story was biased to favor the story’s conclusion and was consistent with readers’ desires, subjects agreed 95 percent of the time that the outcome was very likely. However, when this probable outcome clashed with their own desires for how the story should end, the agreement rate dropped to 69 percent. Reading times of the final sentence also showed that people were slower to read the outcome sentences when they were mismatched with readers’ preferred outcomes. To a significant degree, their predictions about the text were driven by wishful thinking.
Overall, the study of elaborative inferences reveals several findings. Detailed inferences are not always generated by readers. A number of factors determine whether they are encoded. One of these is the amount of available processing resources (in terms of working memory). This suggests that making inferences can be fairly expensive from a cognitive point of view—contextual support can reduce the cost by boosting the accessibility of some inferences, but even so, there have to be enough resources available in working memory for even fairly accessible elaborative inferences to be spontaneously generated. The likelihood of making an inference, then, seems to reflect the combination of its accessibility (which affects its processing cost) and the available processing resources.
The cognitive costs of elaborative inferences
It’s worth saying a few words about the apparent costliness of many inferences. You might remember that even bridging inferences, which readers mostly do seem to spontaneously generate, showed evidence of processing cost as reflected in longer reading times. This cognitive price tag for inferences raises some interesting questions. Psycholinguists often think of language understanding as something that we do automatically and without the need for conscious deliberation. If someone is talking to you, you have to go out of your way not to understand what they’re saying; you might have to cover your ears to block out the sounds of speech. You don’t choose to figure out what someone is saying in the same way that you choose (or don’t) to figure out a math problem, and then allocate your attention and cognitive resources to the task. But when it comes to certain inferences or elaborations of meaning, it’s a bit less clear whether these are part and parcel of the automatic, reflexive aspect of language understanding.
Certainly, it seems there would have to be some limits to the depth of detail and number of inferences and elaborations that hearers typically compute for any given sentence. For example, the simple sentence The hungry python caught the mouse could, in theory, lead to all of the following extra meanings layered onto the sentence: the python ate the mouse; the python swallowed the mouse whole; the mouse was brown and furry; the python squeezed the mouse before eating it; the mouse wriggled while being squeezed; the python had a bulge afterward; the python wouldn’t be hungry for a while, and so on. But it’s doubtful that we have the brainpower to actively generate all of these inferences in the course of everyday language use—and even if we did, it might not be adaptive to worry about all of these details in most contexts.
This brings us to an interesting paradox. On the one hand, normal communication seems to rely very heavily on the ability of hearers to read between the lines of the meaning that’s provided by the linguistic code. On the other hand, hearers have to spend precious cognitive resources to do so, which might put some limits on the extra meanings they can derive. As psycholinguists, we’d like to know: Are some inferences less costly than others, or computed more automatically? If so, what accounts for the differences in processing cost among various inferences? Are they generated in different ways? And if there are inferences that aren’t automatically generated, do speakers manage to predict which ones their hearers are most likely to compute, and does this drive speakers’ decisions about how much needs to be said explicitly? In the upcoming Digging Deeper section, we’ll look more closely at debates over which inferences are automatically generated, and what specific mechanisms are involved. The question of how well speakers anticipate what their hearers will understand will be left to Chapter 12.
It seems apt to end this section by pointing out that the hard work of generating inferences can have some interesting side effects or benefits for the hearer or reader. When the audience has to work at connecting the dots, the resulting meaning sometimes has more impact than if it is hand-delivered through explicit language. Some researchers who study instructional texts have noted that many textbooks do a poor job of clearly connecting ideas to each other or marking the relationships between concepts. Textbook authors can make reading less strenuous by supplying overt cohesion markers in the text—for example, by replacing some pronouns with noun phrases; adding descriptive content to link unfamiliar concepts with familiar ones; adding connecting words and phrases such as in addition, nevertheless, as a result, and so on. But, paradoxically, readers who already know a fair bit about the subject matter sometimes seem to learn and retain more from a text that leaves out these convenient linguistic markers (e.g., see McNamara & Kintsch, 1996). This reverse cohesion effect may arise because the more challenging texts force the readers to activate their knowledge base in order to make sense of the text. This added activation may well result in a more robust mental model of the material in the text.
In more artistic domains, writing instructors have long extolled the virtues of a “show, don’t tell” approach to writing narratives. Writers who subscribe to this approach may lay out a specific event or patch of dialogue, but let the reader pull out the important meaning or conclusions to be drawn from it—this is supposed to be more satisfying for the reader than having the author wrap up the meaning in a bow. (Language at Large 11.2 described the same theory expressed by filmmakers.) There isn’t a vast collection of empirical studies that confirm the aesthetic virtues of the “show, don’t tell” doctrine, but a couple of studies are suggestive. For example, Marisa Bortolussi and Peter Dixon (2003) reported a study in which subjects read either an original version of a short story by Alice Munro, or one that had been doctored to overtly explain a character’s internal emotional state rather than simply hint at it. The readers of the more explicit text seemed to have a harder time getting into the character’s head, as evidenced by lower ratings about the extent to which the character’s actions were connected to her internal motivations and emotions.
In a similar vein, in a 1999 study by Sung-il Kim, participants read versions of stories in which important information was either spelled out or left to be filled in by the reader. The enigmatic versions of the stories were judged to be more interesting than the more explicit ones. But this effect depended on readers having the opportunity to resolve the puzzle in the first place; they found the implicit texts more interesting than the explicit ones only if they were given ample time to compute inferences; when the text flew by at a brisk 400 ms a word, the difference between the two versions disappeared. Kim suggested that when language moves by at such a fast clip, readers don’t have enough time to generate rich inferences. It may be, then, that whatever advantages come from letting readers connect the dots could easily evaporate if readers aren’t able or motivated to invest the cognitive resources to draw inferences or don’t have the right background knowledge to bring to the task.
11.5 Understanding Metaphor
In the preceding sections, you saw many cases where hearers or listeners needed to add something “extra” to the meaning provided by the linguistic code. But some sentences seem to require their audience to ignore some aspects of the linguistic code to get a sensible interpretation:
My lawyer is a shark.
The hurricane devoured the coastline.
Universities are petri dishes for ideas.
In these metaphorical sentences, you need to set aside some of what you know about the usual meanings of words like shark or devour. Sentences like these feel richer and more difficult than ones that hew to literal meaning:
The hammerhead is a shark.
The hurricane destroyed the coastline.
Universities are productive spaces for ideas.
Metaphors seem to skirt the rules of language. Intuitively, it feels as if they draw on mental activity that falls outside of regular language use. This intuition is bolstered by evidence that some otherwise competent language users have inordinate trouble with them, including children (e.g., Inhelder & Piaget, 1958) and people with autism (Happé, 1991) or schizophrenia (de Bonis & Epelbaum, 1997).
Does metaphor rise from the ashes of literal meaning?
Here’s a metaphor for some early ideas about metaphor: Having learned to drive the vehicle of language, you proceed with your interpretation of a sentence, diligently following all the rules of the road, when suddenly, you slam into a brick wall. You dust yourself off and realize there is no way you can proceed down the road in your car, so you start looking for alternatives. Eventually, you manage to clamber over the wall and continue down the road on foot.
According to philosopher Paul Grice (1975), metaphorical understanding is triggered by the failure of literal meaning. As a hearer, you first attempt to compute the literal meaning of a metaphorical sentence based on your grasp of the linguistic code, only to realize that it’s utterly nonsensical; you’ve hit the brick wall. This triggers a set of inferences that are essentially non- linguistic in nature, as you search around for some way to recover a plausible meaning and move forward in the conversation. The idea is that this inference looks a lot like what goes on when someone makes a statement that is true, but carries no useful information on its own. For example, if you ask your car mechanic how much your repair will cost, and she answers, “Well, your car’s a Volvo,” you probably don’t take it to mean she’s informing you of the make of your car. Sure, that’s what she said, but what she likely meant was that you’re about to get a shockingly high repair bill. Grice claimed that understanding metaphor involves a similar disengagement from what the speaker said to get at what she really meant. (Much more on these kinds of inferences in the next chapter.)
This account makes the following crucial prediction: Without the impediment of the brick wall, there should be no need to clamber over it rather than drive on through. In other words, if computing the literal meaning of a sentence is sufficient, people should make no attempt to pursue a metaphorical interpretation. But Sam Glucksberg and his colleagues (1982) found that people couldn’t help deriving metaphorical meanings, even when it made sense not to. They created an experiment in which people judged sentences as true or false. A quarter of these were straightforward sentences that were true:
Some birds are robins.
Another quarter were straightforward and false:
Some birds are apples.
The most interesting category involved sentences that were literally false, but true on a metaphorical reading:
Some jobs are jails.
Some flutes are birds.
The most efficient thing to do would be to stop at the literal meaning and reject the sentence as false. But if people automatically compute metaphorical meanings in parallel with literal meanings, the true nature of the metaphorical meaning might interfere with the false nature of the literal meaning, leading to longer response times for rejections. The remaining quarter of sentences were scrambled metaphors that were nonsensical on both a literal and metaphorical reading:
Some jobs are birds.
Some flutes are jails.
These were included to provide a control condition for the interference hypothesis: if people took longer to reject the reasonable metaphorical sentences, the researchers wanted to make sure this wasn’t because the individual components of the metaphors caused any difficulty.
The result showed people did in fact have trouble rejecting the metaphors, taking longer to do so with sentence like Some jobs are jails than any of the other categories. It would seem that the metaphorical meanings sprang to participants’ minds not as a last resort, but as a normal part of reading those sentences. This conclusion was buttressed by other experiments showing that metaphorical sentences can be read as quickly as sentences with straightforward literal meanings. For example, Blasko and Connine (1993) had participants listen to a number of fresh metaphors (e.g., Indecision is a whirlpool). Immediately after hearing each sentence, they had to respond to a visually presented word that was either related to the sentence’s literal meaning (water) or its metaphorical meaning (confusion). On average, people responded to the words related to metaphorical meanings as quickly as they did to words related to literal meanings, indicating that literal meanings don’t necessarily precede metaphorical meanings. A number of studies have reached the same conclusion, relying on different methods (e.g., Hoffman & Kemper, 1987; McElree & Nordlie, 1999).
How are metaphorical meanings computed?
If constructing metaphorical meaning is an automatic part of language understanding, and not something we do only when language understanding runs into a dead end, then how exactly do we understand metaphors? And why do we have the sense that they involve special mental processes that aren’t required for run-of-the-mill sentences? In trying to answer this question, researchers have hunted around to see what existing cognitive machinery could be deployed for understanding (and producing) metaphors.
Sam Glucksberg and Boaz Keysar (1990) suggested that metaphors like My lawyer is a shark should be understood just like other sentences of the form X is Y—as statements of categorization. When you say “My boss is a jerk” or “The robin is a bird,” you’re claiming that your boss falls into the category of people labeled as jerks or that robins fall into the category of animals we call birds. But wait … how can a lawyer be categorized as a shark? Glucksberg and Keysar argue that here, the word shark is not being used in its most common sense, that is, as a basic-level category referring to a certain species of fish; rather, it’s used in a more abstract sense, as an abstract category that refers to tenacious things that may act aggressively. The idea is that this abstract meaning of shark is much like the superordinate-level categories of mammal or occupation (see Figure 11.7). And, just as the category of mammal includes some but not all of the properties of its basic-level members such as dogs or giraffes, the abstract shark category includes some but not all of the properties of its members—among them the basic-level shark category as well as the person designated as “my lawyer.”

Figure 11.7 The relationship between basic-level and superordinate-level categories. Here, metaphorical categories are considered to be superordinate-level categories that contain a subset of the features of their basic-level category members.
This requires saying that words like shark can shape-shift between their literal, basic-level meanings and their metaphorical, abstract meanings. What’s more, the abstract meanings need to be highly flexible. Think about what shark means if someone says, “That professor is the shark of the department; he’s had a successful career without ever changing his theory or his methods.” Here, shark seems to evoke “things that have thrived for a long time without evolving.” But Glucksberg and Keysar point out that the creative construction of categories is rampant in language use. We do it all the time when we string together noun–noun combinations such as toy theory or sweater dress; here, toy refers to an abstract category such as “things that are simple and amusing, but not to be taken seriously” and sweater refers to something like “major item of clothing that is knitted from yarn.” These categories are inherently flexible; if they combine with different nouns, they might evoke different categories, as in the examples toy truck or sweater weather. Under this view, metaphors simply repurpose cognitive abilities that allow us to creatively combine concepts in novel ways. And because abstract meanings of words such as shark can be computed in parallel with their more specific literal meanings, understanding a metaphor doesn’t depend on detecting the weirdness of the literal meaning of the sentence.
A second approach, articulated by Dedre Gentner (1983), also takes the view that existing cognitive abilities can be recruited for producing and understanding metaphor. However, Gentner emphasizes that metaphors often require people to notice the overlap between two complex sets of informational structures. Think about a metaphor like Tree trunks are drinking straws. Gentner argues that to understand this metaphor, you need to do more than simply construct an abstract category for drinking straw and attribute the properties of that category to a tree trunk. You need to notice important relations as well, such as the fact that a tree trunk acts on the water it draws up to its leaves in much the same ways as a drinking straw functions with regard to some liquid substance drawn up to the drinker’s mouth (see Figure 11.8). In other words, metaphors draw on our ability to engage in analogical reasoning, where the similarities between intricate conceptual structures are aligned and highlighted, while other irrelevant properties or relations are disregarded. Linguistic structures like X is Y or X is like Y can trigger this process of comparison. Metaphors that involve analogy are especially useful for teaching new, highly abstract concepts because they allow large chunks of knowledge structure to be transferred from a familiar domain to an unfamiliar one (see Language at Large 11.3).
Figure 11.8 Analogical reasoning involved in understanding the metaphor Tree trunks are drinking straws. Comprehending a metaphor requires noticing and highlighting the overlap between complex knowledge structures from two different domains (in red type) while ignoring dissimilar properties and relations (pale gray type). Elements that occupy matching positions in the knowledge structure are shown in matching type colors.
Both of these accounts see metaphor as a way of triggering specific types of cognitive reasoning. For Glucksberg and Keysar, metaphor is cut from the cloth of categorization, whereas for Gentner it involves analogical reasoning. Humans rely on categorization and analogy in many domains of their lives—not all of which involve language—so some of the cognitive machinery involved in metaphor exists outside of the domain of language. However, linguistic cues can set these processes in motion. Therefore, what both of these theories have in common is the idea that metaphorical language is a way to activate certain cognitive activities that are not purely linguistic in nature. These features help to explain why computing metaphorical meaning is automatic rather than something that’s done as a last resort when “normal” language processing has failed; but the same features also jibe with our sense that metaphorical language activates mental processes that may not be in play during more pedestrian language use.
A model proposed by Walter Kintsch (2000) places metaphor comprehension right at the heart of language understanding proper, treating it as an extension of processes that typically take place during routine language comprehension. The model builds on two well-grounded assumptions. First, when a word is recognized, semantic information that is related to it becomes active. For example, recognition of the word cat might activate mouse or purr—a claim for which you saw ample evidence in Chapter 8 Second, as words are combined into meaningful sentences, these activation levels are adjusted—some semantic information becomes amplified, while other information may be suppressed. So, the sentence The mouse quickly pounced might elevate the activation of mouse while suppressing purr, but the opposite might occur for the sentence Cats make affectionate pets. In some cases, significant activation of a word might be dependent on the combination of certain words—for example, Duffy (1994) found faster reading times for mustache when it appeared in the sentence frame The barber trimmed the mustache; but this facilitation was not found if either of the words barber or trimmed was replaced with a more general word (e.g., The barber saw the mustache or The person trimmed the mustache).
Kintsch suggests that metaphorical language is simply an extreme case of ramming together two words from different semantic domains that rarely occur together. This leads to the suppression of information that is typically activated by these words in their more usual contexts and the boosting of information that may be only weakly related to either word on its own. Therefore, the mechanism of comprehension is exactly the same for both literal and metaphorical sentences, but the outcome—in terms of what information is active as a result of the combination—is quite different. It’s the unique outcome that metaphors can generate that give them their feeling of specialness.
This approach claims that boring sentences like Sharks are good swimmers and metaphors like My lawyer is a shark are simply two points on the end of a continuum. In the middle are less common meanings of polysemous words; unlike fully ambiguous words, polysemous words are recognizable as related to a single core sense, but shift depending on their contexts of use. This flexible mechanism of meaning combinations yields many possible ways to use the word run for example:
The athlete ran the race even though he was sick.
The ink ran all over the page.
Let’s try running the program.
Jake ran his fingers through his hair.
This motor refuses to run.
According to Kintsch, these are all cases where some of the information related to run has been boosted and other information has been suppressed. All of this leads to the impression that there are many different meanings for run—just as we have the impression that metaphorical meanings are different in kind from literal meanings.
What skills are needed to understand metaphor?
Researchers have yet to sort through and test all of the predictions that would distinguish among these three theories—and it’s possible that each theory is partly right, accounting for some kinds of metaphors but not others. What’s striking, though, is that these accounts make a number of converging predictions about the mental machinery needed to understand metaphors.
For example, all three accounts predict that when people interpret metaphors, some of the information related to the literal interpretation of the sentence needs to be suppressed while other information is heightened. There’s some evidence that this occurs. Morton Gernsbacher and her colleagues (2001) tested how quickly people responded to statements that were related to literal or metaphorical uses of nouns such as shark. Each participant read either a literal or a metaphorical sentence related to the noun:
a. That hammerhead is a shark. (literal)
b. That defense lawyer is a shark. (metaphorical)
They then had to respond to a probe sentence that highlighted a shark property related to either the literal or the metaphorical meaning of shark by indicating whether the sentence was meaningful:
c. Sharks are good swimmers. (related to literal meaning)
d. Sharks are tenacious. (related to metaphorical meaning)
Participants were faster to verify sentences related to the literal meaning (c) when the probe sentence was preceded by a literal sentence (a). Conversely, they were faster to verify sentences related to the metaphorical meaning (d) if these were preceded by a relevant metaphorical sentence (b).
These results suggest that an important part of understanding metaphor is managing the degree of activation of relevant versus irrelevant information. In that case, we’d expect that individual differences in cognitive control might affect people’s ability to interpret metaphor. Dan and Penny Chiappe (2007) found that performance on the Stroop task, which requires participants to ignore irrelevant information about a word’s meaning (see Section 9.6) was indeed related to the speed and quality of metaphor interpretation. Better performance on a digit span task was also linked to stronger metaphor comprehension, suggesting that it’s helpful to keep a lot of information active in working memory.
All three accounts also demand a rich network of semantic knowledge. Without an extensive knowledge base, you might fail at metaphor comprehension under the categorization account if you didn’t have the information you needed to set up an appropriate higher-order category—understanding My lawyer is a shark requires knowledge of both sharks and lawyers. Under Gentner’s analogical theory, knowledge gaps would leave you especially vulnerable to intricate relational metaphors like Socrates was a midwife; there’s a lot you need to know to grasp that Socrates helped his students produce ideas in the same way as midwives help women produce children. In fact, Gentner (1988) has suggested that limited knowledge is one reason why children have difficulty with relational comparisons such as Tree bark is like skin; they do much better with comparisons involving surface properties that can be observed directly, such as The moon is like a penny.
And, under Kintsch’s activation account, you’d need robust experience with a wide range of words and their meanings. Because metaphorical meanings often hinge on the activation of semantic information that is only weakly related to each of its elements, without sufficient exposure to both elements in a variety of different contexts, such information may be too faintly represented in memory to become sufficiently activated even when those elements are combined.
In short, all three accounts suggest that metaphor comprehension, much like inference generation, is both computationally demanding and dependent on a rich body of acquired knowledge.
GO TO