The film Thirteen Days portrays the efforts of President John F. Kennedy and his staff to deal with the 1962 Cuban Missile Crisis. With the Cold War at its chilliest, the Americans have learned that Soviet missiles have been installed in Cuba, within easy striking range of many U.S. cities. Kennedy needs to apply pressure on the Soviets to force them to withdraw their missiles. But he’s trying not to respond in an overly aggressive way that might be interpreted by the Soviets as an intent to go to war, thereby triggering a full-scale nuclear confrontation. Kennedy’s first move is to declare a blockade of all Soviet ships headed to Cuba. In a later scene of the film, several Soviet ships have crossed the blockade lines, and Secretary of Defense Robert McNamara learns that one of the admirals under Kennedy’s command has taken it upon himself to fire blank warning shots above one of the offending ships. McNamara yells at the admiral that he is not to fire unless directly ordered by the president. The admiral replies that he’s been running blockades for decades and knows how it’s done. McNamara explodes: “You don’t understand a thing, do you admiral? This is not a blockade. This is language. A new vocabulary, the likes of which the world has never seen. This is President Kennedy communicating with Secretary Khrushchev!”

At first glance, it might seem that the mutual messages Kennedy and Khrushchev are sending here are very unlike what happens when people
use conventional language to communicate. Most of the time, people don’t communicate by relying on subtle signals encoded in the movement of ships and the presence or non-presence of gunfire. The whole point of having language would seem to be to make such mind-reading feats unnecessary. After all, isn’t meaning precisely and conveniently packaged up in the language? Linguistic communication, one might argue, doesn’t require mind reading, just straightforward information processing to decipher a code that maps forms fairly directly to meanings.
For the most part, this book has focused on how humans learn and process the linguistic code. We’ve discussed the mechanisms that allow people to transmit linguistic information, or decode it, or discover its patterns and generalizations, all under the assumption that language form and meaning are intrinsically connected. From this angle, the problem of recovering meaning from language is very similar to the problems of, say, interpreting a visual scene or deciphering musical patterns. In all of these cases, information that hits our senses has to be processed and structured into sensible representations before we can recognize specific objects, make sense of a chord progression, or figure out what a sentence means.
Except it’s a bit misleading to talk about “what a sentence means.” When you really think about it, words and sentences don’t convey meanings—people convey meanings by using certain words and combining them into sentences. This might seem like a distinction without a difference until you consider just how often people bend language to their will and manage to convey messages that are very remote from the usual meanings of the words or sentences they’re using. A waitress might communicate a customer’s complaint to the kitchen staff by “The steak sandwich says his meat was overcooked,” using the phrase the steak sandwich to refer not to the food itself, but to the person who ordered it. Or, a person might ask the object of his affections, “Do you feel like having dinner sometime?” This is usually understood as an invitation to go out on a date, and not as a question about whether the other person is likely to ever be inclined to eat food in the evening. Or, a boss might describe her employee metaphorically, saying “That guy’s my best worker. He’s a bulldozer.” And, if you’ve ever resorted to sarcasm (“I’m really looking forward to my exam this afternoon”), you probably figured that your hearer could work out that what you really meant was pretty much the exact opposite of the usual meaning of the language you used.
In all of these cases, communicating through language seems to come a lot closer to the problem that Kennedy was trying to solve. The question is not “What does this bit of language mean?” but instead, “What is the speaker trying to communicate by using this particular bit of language in this situation?” In other words, the hearer has to hoist herself into the speaker’s mind and guess his intended message, using the language he’s uttered as a set of clues.
It might seem that all this sophisticated social cognition is restricted to a smattering of instances of language use—those unusual cases where a speaker’s intended meaning has somehow become disconnected from the inherent meanings of the language he’s recruited. But the bigger point here is that there are no inherent meanings in language, even when we’re talking about its more “fixed” aspects. The only reason there’s a connection between specific sounds and specific meanings is that this connection has been socially sanctioned. In this way, language is deeply different from many other kinds of information processing that we do. When it comes to visual perception, for instance, the array of lines, shadows, and colors that we have to interpret is intrinsically related to the real-world objects that we’re perceiving. But there’s no intrinsic connection between the sounds in the word dog and the thing in the world it refers to; its meaning comes entirely from the fact that a bunch of people within a common linguistic community have tacitly agreed to use that word for that thing. That same group of people can also agree to invent new words for new meanings, like Internet, or mitochondria—and subgroups can agree to appropriate existing words for new meanings, so words like wicked, sick, lame, and cool can mean completely different things, depending on who’s saying them and in what context.
For language, unlike for many kinds of perception, our interpretation of the stimuli doesn’t derive from the laws of physics and biology. Instead, it’s mediated by social conventions, or agreements to use certain words and structures for certain meanings. It’s hard to imagine that someone could possibly be a competent user of language without having a deep grasp of these social underpinnings of language. In fact, as you’ll soon see, it’s common for conversational partners to spend a fair bit of time in everyday conversation negotiating the appropriate language to use.
None of the above is especially controversial among language scientists. Where the disagreements bubble up is over the question of how much active social cognition takes place under the time pressures of normal conversation or reading. In other words, how much of language use is straightforward decoding and how much of it looks like mind reading, Thirteen Days style? Once we’ve learned the conventional, socially sanctioned links between language and meaning, it seems that we should be able to use them as efficient shortcuts to the speaker’s intended meaning, allowing us to bypass the whole business of having to put ourselves inside his mind. For instance, when someone uses the word dog, we should be able to activate the mental representation of a four-legged domestic canine without asking ourselves, “Now, what is the speaker trying to convey by using this word?” At the same time, there’s no guarantee that the speaker’s intended meaning lines up neatly with the conventional meaning of the language he’s chosen to use, so some monitoring of his communicative intentions would certainly be useful. And from the speaker’s perspective, having a sense of the hearer’s knowledge or assumptions could be useful in deciding exactly how to express an idea.
For some researchers, mind-reading capabilities are absolutely central to how language works and are part of the core skills of all language users in all situations. To others, these capabilities are more like icing on the cake—extremely useful to have in many situations, handy in avoiding or clarifying miscommunications, but not always critical for bread-and-butter language use. This chapter explores some ideas about the extent to which we track one another’s mental states in the course of normal language learning, production, and comprehension.
12.1 Tiny Mind Readers or Young Egocentrics?
Anyone who’s locked eyes with a 5-month-old baby on a bus or in a grocery checkout line has experienced an infant’s eagerness for social contact. From a very young age, babies demonstrate a potent urge to make eye contact with other humans, to imitate their facial expressions and actions, and to pay attention to objects that hold the attention of others. Long before they know any words, babies engage in “conversations” with adults, cooing and babbling in response to their caregivers’ utterances. This remarkable social attunement suggests that, right from the start, babies’ learning of the linguistic code may be woven together with an appreciation of the social underpinnings of language and of speakers’ goals and intentions.
In previous chapters, we’ve discussed the close connection between social understanding and language: in Chapter 2, we explored the possibility that complex social cognition is a prerequisite for the development of language in a species, and in Chapter 5, we saw that children draw heavily on inferences about a speaker’s referential intent in learning the meanings of words. However, there are also hints that children take a while to develop a sophisticated social competence, and in some ways, social cognition seems to lag behind language development. At an age when children can speak in complex sentences and show mastery over many aspects of grammatical structure, they can still have trouble producing statements that are relevant or useful to others. And when the language code collides with others’ communicative intent, children tend to stick close to the language code for recovering meaning—sarcasm or innuendo are often completely lost on kids younger than 7 or 8. These findings suggest that language learning may proceed somewhat independently of mind reading and that it takes some time for the two to become well integrated.
In this section, we’ll look closely at the relationship between children’s emerging social cognition and language learning and use. What assumptions do young children make about speakers or hearers, and how do these assumptions shape children’s linguistic behavior? To what extent can children consider evidence about their conversational partner’s mental state?
Social interaction enhances language learning
Language exists for social purposes and arises in social contexts. But it also exists physically as a series of auditory or visual signals. In the previous chapters, I laid out abundant evidence that these signals have a great deal of internal structure. In principle, it should be possible to learn something about how linguistic elements pattern without needing to project yourself into the mind of the speaker, or, for that matter, engage in social interaction at all. And in fact, there’s evidence that babies can learn a great deal about language simply by being exposed to structured repetitions of a natural or artificial language, disembodied from any social communication. In Chapter 4, you saw that infants are able to learn to segment words and form phonemic categories based on the statistical regularities in prerecorded speech. In Chapter 6, I presented evidence that young children are able to use statistical information about co-occurring words to infer the grammatical categories of novel words. None of these studies involved communicative interaction, but children were able to pick up on the statistical patterns present in input that was piped in through loudspeakers.
You also saw that other species of animals can pick up on regularities inherent in human speech. This too suggests that certain aspects of language learning may not require grasping that language is a socially mediated phenomenon. At some level, it’s possible to treat the sounds of human language as just that—sounds whose structure can be learned with sufficient exposure.
Still, there’s intriguing evidence that even for these very basic and physically bound aspects of language learning, social interaction matters. Patricia Kuhl and her colleagues (2003) tested whether social interaction affected the ability of 9-month-olds to learn phonemic contrasts that don’t occur in their native language. As you learned in Chapter 4, over the second half of their first year, babies adapt to the sound structure of their own language and “lose” the ability to easily detect contrasts between two sounds that are not phonemic in their own language (for example, English-reared babies become less responsive to the distinction between aspirated consonants like [ph] and unaspirated consonants like [p]). Kuhl and her colleagues targeted monolingual American-raised infants at an age when they had already lost the distinction between certain contrasts that occur in Mandarin Chinese. They wanted to know: Could the American babies learn to pick up on the Mandarin sound contrasts? And would they learn better from a live speaker than from a video or audio recording?
In their study, a number of the babies interacted with native Mandarin speakers who read books to them and played with toys while speaking Mandarin in an unscripted, natural way (see Researchers at Work 12.1). By the end of this period, they clearly had learned the Mandarin sound contrasts—in fact, their performance was indistinguishable from babies of the same age who had been raised in Taiwan and learned Mandarin as their native language.
This robust learning was all the more startling when compared with the abject failure of another experimental group of the same age to learn the Mandarin sounds. Just like the successful learners, this group was exposed to the same amount of Mandarin language, with the same books and toys, over the same period of time, uttered by the same native speakers of Mandarin. This time, however, the infants were either exposed to the language through video, or merely heard the same recording on audio. There was no evidence of learning in either of these cases. Mere exposure to the language was not enough. Learning only happened in the context of live interactions with a real speaker. This phenomenon, in which learning is enhanced through social interaction, is known as social gating.
Why was live social interaction so important for this task, when many other studies have shown that babies can learn certain sound patterns merely by listening to snippets of prerecorded speech? The researchers suggested that language learning in a child’s natural habitat tends to be much more complex and variable than your typical artificial language experiment, which usually presents a sample of speech carefully designed to provide information about key statistical patterns. Hence, real language learning needs some additional support from social interaction. But what’s the nature of this support? There are several possibilities. One is that interacting with a live talker simply caused the babies to pay more attention to the talker and to be more motivated to learn from the speech input. In the experiments involving the Mandarin phonemes, there was evidence that babies were paying more attention to the talker in the live interactions than in the videos, and they also became quite excited whenever that person entered the room, more so than when the TV screen was switched on.
Another possibility is that the babies were able to pull more information out of the speech stream when interacting with a live person. In the live interaction, the babies had a richer set of cues about the speaker’s referential intentions, which may have given them an advantage in identifying specific words. This would have helped them structure the speech stream in a more detailed way than they could without the strong referential cues, and in turn, this enriched structure would have helped them to figure out which sounds are used to make meaningful distinctions in Mandarin. Under this second interpretation, inferences about a speaker’s intended meaning can indirectly shape even the most basic aspects of language learning, by providing additional information about how the speech stream should be carved up.
A third possibility is that the live interaction allowed the babies to adopt a special, highly receptive mind-set because they recognized that the adult speaker was trying to teach them something. Researchers György Gergely and Gergely Csibra (2005) call this mind-set the pedagogical stance. They argue that while other species of animals are capable of learning through social imitation, and even show evidence of social gating (see Box 12.1), only humans have evolved a special capacity to transmit information by means of focused teaching. When we slide into teaching mode, we instinctively adopt certain communication techniques that signal that we’re trying to impart some knowledge that’s new and relevant to our hearers. And according to Gergely and Csibra, human infants are able to instinctively recognize when someone is trying to teach them. Once they see that the speaker is in teaching mode, they automatically assume that the information will be new and relevant, and focus their efforts on learning it quickly and efficiently.
Not all social interactions involve teaching. So, what kinds of cues signal a pedagogical act? Think of the difference between chatting with a friend while you’re preparing a chocolate soufflé and teaching your friend how to make the soufflé. In both cases, your friend could learn to make the dish by imitating you, but he’d be more likely to succeed if you were deliberately trying to teach him. How would your actions and communication be different? In the teaching scenario, you’d be more inclined to make eye contact to check that your friend was paying attention at critical moments. You’d make a special attempt to monitor his level of understanding. Your actions might be exaggerated and repetitive, and you’d be more likely to provide feedback in response to your friend’s actions, questions, or looks of puzzlement. Notice that many of these behaviors rely on having the learner physically present.
So, one way to make sense of the results of the Mandarin phoneme learning study, which demonstrated huge benefits of live social interaction, is that the babies were being exposed to a very particular kind of social interaction. The infants probably got many cues that signaled a teaching interaction, and as a result they adopted a focused pedagogical stance to the language input that they were hearing.
Csibra and Gergely argue that the pedagogical stance doesn’t require babies to make any sophisticated inferences about the speaker’s state of mind or communicative intentions. Rather, they see it as an instinctive response to behaviors that human adults display when they’re purposefully trying to impart their knowledge. Csibra and Gergely suggest that these behaviors automatically trigger the infant’s default assumption that the adult is in possession of relevant knowledge that they are trying to share. Eventually, children may have to learn that not everyone who exhibits these behaviors actually is knowledgeable, or is demonstrating knowledge that is relevant or new.
Children are selective learners
The next stop on our tour of young language learners is the child who’s trying to learn the conventional meanings of words. As you saw in Section 5.3, children are often reluctant to map a word onto a meaning without some good evidence that the speaker meant to use that word for a particular purpose. For clues, they pay attention to the speaker’s eye gaze or other behavior to identify the object of the speaker’s referential intent.
But as a youngster absorbed in the task of word learning, you might be well advised to do more than just look for signs of referential intent. A speaker might be utterly and obviously purposeful in using the word dax to refer to a dog, but that doesn’t mean that the word she uses is going to match up with what other speakers in your linguistic community agree to call that furry creature. Maybe she speaks another language. Maybe she doesn’t know the right word. Maybe she’s pretending, or even lying. Or maybe she’s insane. Perhaps you should approach such interactions with a grain of skepticism, in light of the fact that the speaker may not always be a reliable source of linguistic information. Naturally, knowing something about the speaker’s underlying knowledge or motivations would be helpful in deciding whether to adopt this new word.
But what evidence would you look for to figure out whether the speaker can be trusted as a teacher of words in the language you’re trying to acquire? Assessing the speaker’s reliability seems to involve a level of social reasoning that’s a notch or two more sophisticated than simply looking for clues about referential intent. Nevertheless, an impressive array of studies shows that preschoolers, and perhaps even toddlers, do carry out some sort of evaluation in deciding whether or not to file away in memory a word that’s just been used by an adult in a clearly referential act.
Mark Sabbagh and Dare Baldwin (2001) created an elaborate scenario in which they established one speaker as clearly knowledgeable about the objects she was referring to, while a second speaker showed evidence of uncertainty. In this scenario, a 3- or 4-year-old child heard a message recorded on an answering machine from a character named Birdie, who asked the experimenter to send her one of her toys, which she called a “blicket.” Birdie’s collection of “toys” consisted of a set of weird, unfamiliar objects. Half of the children interacted with an experimenter who claimed to be very familiar with these objects. This speaker told the child, “I’ve seen Birdie play with these a lot. I’ll show you what this does. I’ve seen all these toys before.” This “expert” then proceeded to demonstrate how to play with Birdie’s toys. In response to Birdie’s request for the blicket, this experimenter confidently announced, “You know, I’d really like to help my friend Birdie, and I know just which one’s her blicket. It’s this one.” The experimenter asked the child to put the blicket into a “mailbox,” saying, “Good, now Birdie will get her blicket.”
The other half of the kids interacted with an experimenter who acted much less knowledgeable. Upon hearing Birdie’s request, this experimenter said, “You know, I’d really like to help my friend Birdie, but I don’t know what a blicket is. Hmm.” While playing with Birdie’s toys, she said, “I’ve never seen Birdie play with these. I wonder what this does. I’ve never seen these toys before.” She played with the toys tentatively, pretending to “discover” their function while manipulating them. Finally, she told the child, touching the same object that the “expert” speaker had, “Maybe it’s this one. Maybe this one’s her blicket. Could you put it in the mailbox to send to Birdie?” When the child complied, the experimenter said, “Good, now maybe Birdie will get her blicket.”
In both of these experimental conditions, the children heard the experimenter use blicket to refer to the same object exactly the same number of times. The question was whether the preschoolers would be more willing to map the word to this object when the speaker claimed to know what she was talking about than when she was unsure. In the test phase, both the older and the younger children were more likely to produce the word blicket to refer to the target object if they’d heard the word from the “expert” speaker, in addition to being more likely to identify the correct object from among the others when asked to pick out the blicket.
Since this initial study, a number of experiments have looked at other cues that kids might use when sizing up the speaker’s credibility. For instance, children seem to figure that a good predictor of future behavior is past behavior: they take into account whether the speaker has previously produced the right labels for familiar objects. Melissa Koenig and Amanda Woodward (2010) showed that if a speaker has falsely called a duck a “shoe,” children are less eager to embrace her subsequent labels of unfamiliar objects (this work was summarized in Researchers at Work 5.1).
It’s hard to know, though, whether children’s evaluations of a speaker’s credibility are truly rational, based on assessing what speakers know, and making predictions on that basis. Sure, it’s logical to conclude that someone who expresses uncertainty about their knowledge, or someone who’s behaved unreliably in the past, is more likely to be an unreliable communicator. But we want to be careful not to attribute more knowledge and sophistication to children’s behavior than the data absolutely indicate. Are kids really reasoning about what speakers know (not necessarily consciously), or does their distrust of certain speakers reflect more knee-jerk responses to superficial cues? For example, preschoolers are also more reticent in accepting information from people who are simply unfamiliar, or who have a different accent or even different hair color than themselves. There are still a lot of questions about how children weight these various cues at different ages, and just how flexibly they adapt their evaluations, as one might expect of a fully rational being, in the face of new, predictive information about a speaker.
Still, there’s quite strong evidence that in many communicative situations, even very young kids make accurate inferences about the mental states of others. In a 2007 study by Henrike Moll and Michael Tomasello (2007), 14- and 18-month-old children interacted with an adult, with adult–child pairs playing together with two objects. The adult then left the room while the toddler played with a third, novel object. When the adult returned, she pointed in the general direction of all of the objects and exclaimed with excitement, “Oh, look! Look there! Look at that there!” She then held out her hand and requested, “Give it to me, please!” It seems that even 14-month-olds know that excitement like this is normally reserved for something new or unexpected and used this information to guess which object the adult was referring to. All three toys were familiar to the children; nevertheless, they handed over the new-to-the-adult item more often than either of the two objects that the adult had played with earlier.
Limits to children’s mind-reading abilities
Studies like those by Moll and Tomasello point to very early mind-reading abilities in children and, as discussed in Chapter 2, a number of researchers have argued that humans are innately predisposed to project themselves into each other’s minds in ways that our closest primate cousins can’t. But these stirring demonstrations of young tots’ empathic abilities seem to contradict the claims of many researchers who have emphasized that children are strikingly egocentric in their interactions with others, often quite oblivious of others’ mental states.
Indeed, anyone who’s ever interacted with very young children can be struck by their lack of ability to appreciate another person’s perspective or emotional state. It seems they constantly have to be reminded to consider another person’s feelings. When they choose gifts for others, they often seem to pick them based on their own wish lists, oblivious to the preferences and needs of others. And they do sweetly clueless things like play hide-and-seek by covering their faces, assuming that if they can’t see you, you can’t see them, or they nod their heads to mean yes while talking on the phone, seemingly unaware that the listener can’t see them.
The famous child psychologist Jean Piaget argued that it’s not until at least about the age of 7 years that children really appreciate the difference between their own perspective and that of others. This observation was based partly on evidence from what’s now known as the “three mountains study,” which involved placing children in front of a model of a mountain range, while the experimenter sat himself on the opposite side of it and asked the young subjects to choose one photo from among a set that best depicted his own viewpoint rather than the child’s (Piaget & Inhelder, 1956). Before age 7, most kids simply guess.
It seems that Piaget overestimated children’s egocentrism, partly because his experiments required kids to be able to do some fancy visual transformations in their heads rather than simply show awareness that another person’s viewpoint could differ from theirs. It’s now established that well before age 7—in fact at around age 4—most kids show a clear ability to reason about the mental states of others, as evident by their ability to handle a tricky setup known as a false-belief test. There are several variants of this basic task, but a common one goes like this: A child is shown a familiar type of box that normally contains a kind of candy called “Smarties.” She’s asked to guess what’s inside, and not surprisingly, kids usually recognize the box and say “Smarties.” The experimenter then opens the box to show the child that—alas!—the box contains pencils, not candy. Then the experimenter asks the child what another person, who had not witnessed this interaction, would think was inside the box. At age 3, children tend to say “pencils,” seemingly unable to shift themselves back into the perspective of someone who saw only the outside of the box. But by 4 or 5, they tend to say that the other person will be fooled into thinking it contains Smarties. To use the terminology of developmental psychologists, success on the false-belief task is taken as solid evidence that children have acquired a theory of mind (ToM)—that is, an understanding that people have mental states that can be different from one’s own.
Some researchers, however, have argued that these false-belief tests underestimate younger children’s mind-reading skills. Even toddlers seem to show awareness that people hold false beliefs if the task uses a toddler-friendly method that doesn’t require him to introspect and report on his own thoughts. In a study by David Buttelmann and his colleagues (2009), 18-month-olds watched an experimenter put a toy in one of two boxes and leave the room. An assistant then snuck in, moved the toy to the other box, and latched both boxes, all in view of the child. When the experimenter returned, he tried to open the empty box, into which he had put the toy. Ever eager to help, the young participants typically went to the other box—the one that now held the toy—to help the experimenter open it. This makes sense if the children thought that the experimenter was trying to retrieve the toy, believing it to be in the original box. In contrast, if the experimenter stayed in the room and watched the toy transfer, and then struggled to open the empty box, the children typically tried to help him open that box—assuming, perhaps, that the experimenter was not trying to get the toy, since he already knew where it was, but wanted to open the empty box for some other reason.
In another cleverly adapted false-belief task by Rose Scott (2017), 20-month-olds watched short videos in which an adult placed three marbles each into a red and green container and shook each of them, which produced a rattling sound. A second clip immediately followed, in which a different person took the marbles from the red container and demonstrated that the red container rattled, but now the green one did not. A third crucial clip showed the original first person back in front of the two containers into which she’d put marbles. She picked up the red container and shook it—but now, no rattle. It’s at this point that the manipulation of interest occurred: some of the babies watched a clip in which the woman showed surprise when the red container was silent, and then picked up the green object, shook it, and smiled and nodded in satisfaction. This reaction is consistent with her believing that both of the containers contained marbles. Some babies watched a clip that was inconsistent with this belief: the woman picked up the red container, shook it, found it produced no sound, and expressed satisfaction; she then picked up the green container, shook it, and expressed surprise upon finding that it rattled. Babies spent more time looking at the inconsistent trial, suggesting that they had some awareness of the woman’s beliefs and expectations, and an understanding that people are surprised when their expectations turn out to be wrong. Importantly, this effect did not occur in a version of the experiment when the woman came back in the third clip and saw that three marbles were sitting on a tray between the two containers; in this clip, a reasonable inference would be that she was aware that three marbles had been removed from one or both of the containers but did not know which. In this case, she shouldn’t have firm expectations that both objects would rattle when shaken.
Right alongside results like these that demonstrate impressive social cognition in tiny children, there are many studies showing that much older kids are surprisingly unhelpful when it comes to avoiding potential communication problems that might arise for their conversational partners. This can be seen by using a common type of experimental setup known as a referential communication task (see Method 12.1). In this paradigm, the subject usually plays a communication “game” with an experimenter (or, in some cases, a secret experimental confederate who the subject believes is a second participant, but who is really following a specific script). The game involves a set of objects that are visible to the speaker and hearer, and the speaker has to refer to or describe certain target objects in a way that will be understood by the hearer. The array of objects can be manipulated to create certain communication challenges.
It turns out that children can be quite bad at communicating effectively with their partners in certain referential contexts. In one study by Werner Deutsch and Thomas Pechmann (1982), children played the speaker role, and had to tell an adult partner which toy from among a set of eight they liked best as a present for an imaginary child. The toys varied in color and size, and the set included similar items, so that to unambiguously refer to just one of these items, the child had to refer to at least two of its properties. For example, a large red ball might be included in a set that also contained a small red ball and a large blue ball, so simply saying “the ball,” or “the red ball,” or “the big ball” would not be enough for the partner to unambiguously pick out one of the objects. To successfully refer, the kids had to recognize that a hearer’s attention wasn’t necessarily aimed at the same object that they were thinking of, and they had to be alert to the potential ambiguity for their partner.
But preschoolers were abysmal at using descriptions that were informative enough for their hearers: at age 3, 87 percent of their descriptions were inadequate, failing to provide enough information to identify a unique referent. Things improved steadily with age, but even by age 9, kids were still producing many more ambiguous expressions (at 22 percent) than adults in the same situation (6 percent). Their difficulty didn’t seem to be in controlling the language needed to refer unambiguously, because when their partner pointed out the ambiguity by asking “Which ball?” they almost always produced a perfectly informative response on the second try. It’s just that they often failed to spontaneously take into account the comprehension needs of the hearer.
We can get an even clearer idea of the extent to which kids are able to take their partner’s perspective by looking at referential communication experiments that directly manipulate the visual perspective of each partner, as discussed in Method 12.1. In these studies, the child and adult interact on opposite sides of a display case that’s usually set up so that the child can see more objects than the adult can. The nature of the communication task shifts depending on which objects are in common ground (visible to both partners) versus privileged ground (visible only to the child). For instance, if there are two balls in common ground, it’s not enough for the speaker to just say “the ball”; but it is if one of the balls is in the speaker’s privileged ground because from the hearer’s perspective, this phrase is perfectly unambiguous. Conversely, suppose the hearer sees two balls, but one of these is in privileged ground so that the speaker only sees one; in this case, if the speaker says “Point to the ball,” this should be perfectly unambiguous to the hearer, assuming she’s taking her partner’s perspective into account. However, the instruction would be completely ambiguous if both balls were in common ground.
Studies along these lines have shown that as early as 3 or 4 years of age, kids show some definite sensitivity to their partner’s perspective, both in the expressions they produce and in their comprehension as hearers (Nadig & Sedivy, 2002; Nilsen & Graham, 2009). But they’re not as good at it as adults are, and there are hints that when it comes to linguistic interactions like these, kids may be more egocentric than adults as late as adolescence (Dumontheil et al., 2010). So, the general conclusion seems to be that while many of the ingredients for mind reading are present at a very young age, it takes a long while for kids to fully hone this ability—longer, even, than it takes them to acquire some of the most complex aspects of syntax.
This raises the question of what it is that has to develop in order for mind-reading abilities to reach full bloom. Some researchers have argued that the social cognition demonstrated by young children is different in kind from older children’s reasoning about mental states. For example, Cecilia Heyes and Chris Frith (2014) suggest that infants have a (possibly innate) system of implicit mind reading that allows for efficient and automatic tracking of others’ attentional states. This may allow very young children to make good predictions about people’s behavior (for example, expecting that someone will search for an object in the last place they saw it) but it falls short of true awareness of mental states. This system can be thought of as a “start-up kit” that serves as the foundation for a more complex system of explicit mind reading, which allows us to consciously reason and talk about mental states. Heyes and Frith propose that the explicit system is dependent upon the implicit system, but separate from it—much like reading text is dependent upon spoken language, but involves mastering a set of cognitive skills that are not required for speech. And, like print reading, they suggest, explicit mind-reading skills are culturally transmitted through a deliberate process of teaching. Parents spend a great deal of time explaining others’ mental states and prompting their offspring to do the same: “She’s crying because you took her toy and now she’s sad”; “Why do you think the witch wants her to eat the apple?” And there’s evidence that talking about mental states does boost children’s (or even adults’) awareness of them (see Box 12.2).
Not all researchers buy into the idea of a sharp split between implicit and explicit mind reading. The ongoing debate is sending scientists off looking for supporting evidence such as: Do explicit mind-reading tasks recruit different brain networks than implicit ones? Does explicit mind reading depend heavily on a culture in which people discuss or read about mental states? In contrast, we might expect variability in implicit mind reading to have more of a genetic cause than a cultural one. Is there neuropsychological evidence for a double dissociation between explicit and implicit mind reading—that is, can one be preserved but the other impaired, and vice versa? And do implicit and explicit mind reading interact differently with other cognitive processes and abilities? If explicit mind reading is a slower, more effortful process than implicit mind reading, we might expect it to be affected more by individual differences in working memory or cognitive control.
Regardless of whether there are two separate systems (or perhaps even more!) for mind reading, there’s growing evidence that children’s failures in complex referential tasks are due at least somewhat to their difficulties in juggling complex information in real time. Think about what’s needed to give your partner just enough information to identify a single object from many others that are similar: you need to notice and keep track of the objects’ similarities and differences all while going through the various stages of language production you read about in Chapter 10. As you saw from the eye-tracking studies described on pages 414–418, adults often start speaking before they’ve visually registered the need for disambiguating information, and if they don’t notice the relevant information quickly enough, they may need to interrupt themselves to launch a repair. This suggests that they’re constantly monitoring their speech in order to quickly fix any speaking glitches that do occur. We know surprisingly little about children’s language production—how far ahead can they plan? Do they have the bandwidth to simultaneously speak and monitor their own speech? But given how complex speaking is, there are many opportunities for breakdown among small people with small working memories.
Things are even more difficult if the child’s own perspective clashes with that of a partner, in which case the child has to suppress their own knowledge, which may be competing with their representation of what their partner knows or can see. And as we’ve seen already in Section 9.6, children are especially bad at inhibiting a competing representation or response, whether this happens to be a lexical item that stirs up competitive activation, or the lure of a misleading syntactic interpretation for an ambiguous sentence fragment. All of these examples rely on highly developed cognitive control (also referred to as “executive function”)—that is, the ability to flexibly manage cognitive processes and behavior in the service of a particular goal. Unfortunately, cognitive control follows a long and slow developmental path, and it’s now well known that the regions of the brain that are responsible for its operation are also among the last to mature. So, many of children’s egocentric tendencies may not be due to the fact that they’re neglecting to consider their partner’s perspective; rather, the problem may be that they have trouble resolving the clash between their partner’s perspective and their own.
A number of studies have explored the consequences of these processing limitations for referential communication. Elizabeth Nilsen and her colleagues (2015) recruited 9- to 12-year-olds for a complex referential communication task and assessed their working memory (using a digit span test) and their cognitive control (using a test in which the kids were taught to press a button if a specific shape appeared on the screen, but avoid pressing it if that shape was preceded by a beep). Kids with better working memory and cognitive control scores produced fewer ambiguous descriptions in the task. The effects of poor cognitive control are even subtly evident in adult’s performance on perspective-taking tasks (Brown-Schmidt, 2009b). And, if a referential communication task is made simple enough, thereby reducing these processing demands, even kids as young as two-and-a-half show attempts to provide disambiguating information for a partner when it’s needed, though they don’t achieve complete success (Abbot-Smith et al., 2016).
In this section, we’ve explored the tension between the very early intertwining of language and social cognition, and its long developmental trajectory. In the next section, we’ll see that social cognition is deeply embedded in the ways in which we elaborate meanings beyond what’s offered by the linguistic code. We’ll also look at how fragile or difficult these social inferences might be.
12.2 Conversational Inferences: Deciphering What the Speaker Meant
As I’ve already suggested, one of the benefits of language is that it should eliminate the need for constant mind reading, since the linguistic code contains meanings that the speaker and hearer presumably agree upon. But in Chapter 11, I used up a lot of ink describing situations in which the linguistic code by itself was not enough to deliver all of the meaning that readers and hearers routinely extract from text or speech. Hearers have a knack for filling in the cracks of meanings left by speakers, pulling out much more precise or elaborate interpretations than are made available by the linguistic expressions themselves—which, as we’ve seen, can sometimes be pretty sparse or vague.
“Soft” and “hard” meanings
It turns out that a good bit of this meaning enrichment involves puzzling out what the speaker intended to mean, based on her particular choice of words. Suppose you ask me how old I am, and I produce the spectacularly vague reply “I’m probably older than you.” My vagueness might be due to the fact that I have trouble keeping track of my precise age, but it seems rather unlikely that I wouldn’t have access to this information. A more plausible way to interpret my response is that I’m letting you know that my age is not open for discussion (and maybe you should apologize for asking). But this message strays quite far from the conventional meaning of my reply, and clearly it does require you to speculate about my knowledge and motivations. So, in this case, even though you can easily access the conventional meaning of the sentence that I’ve produced, you still need to do some mind reading to get at my intended meaning.
The well-known philosopher H. Paul Grice argued that reasoning about a speaker’s intended meaning is something that is so completely woven into daily communication that it’s easy to mistake our inferences about speakers’ meanings for the linguistic meanings themselves. For example, what does the word some mean, as in Some liberals approve of the death penalty? It’s tricky to pin down, and if you took a poll of your classmates’ responses, you’d probably get several different answers. But if your definition included the notion that some means “not many” or “not all” of something, Grice would argue that you’re confusing the conventional meaning of the word some with an inferred conclusion about the most likely meaning that the speaker intended. In other words, the conventional meaning of some doesn’t include the “not all” component. Rather, the speaker has used the word some to communicate—or imply—“not all” in this specific instance.
To see the distinction, it helps to notice that there are contexts where some is used without suggesting “not all.” The sentence I gave you about some liberals was unfairly designed to make you jump to the conclusion that some means “not all,” because that’s the most likely speaker meaning of that sentence. But imagine instead a detective investigating the cause of a suspicious accident. She arrives at the scene of the accident, and tells one of the police officers who’s already there: “I’m going to want to talk to some of the witnesses.” If the police officer lines up every single witness, it’s doubtful that the detective will chastise him by saying, “I said some of the witnesses—don’t bring me all of them.” Here, the detective seems to have used some to mean “at least a few, and all of them if possible.” By looking closely at how the interpretation of some interacts with the context of a sentence, Grice concluded that the linguistic code provides a fairly vague meaning, roughly “more than none.”
You can think of the linguistic code as providing the “hard” part of meaning in language, the part that’s stable across contexts and is impossible to undo without seeming completely contradictory. For example, it sounds nonsensical to say “Some of my best friends like banjo music—in fact, none of them do.” But you can more easily undo the “not all” aspect of the interpretation of some: “Some of my best friends like banjo music—in fact, they all do.” The “not all” component seems to be part of the “soft” meaning of some, coming not directly from the linguistic code, but from inferences about what the speaker probably meant to convey. Grice used the term conversational implicature to refer to the extra “soft” part of meaning that reflects the speaker’s intended meaning over and above what the linguistic code contributes.
Grice suggested that making inferences about speaker meaning isn’t limited to exotic or exceptional situations. Even in everyday, plain-vanilla conversation, hearers are constantly guessing at the speaker’s intentions as well as computing the conventional linguistic meaning of his utterances. The whole enterprise hinges on everyone sharing the core assumptions that communication is a purposeful and cooperative activity in which (1) the speaker is trying to get the hearer to understand a particular message, rather than simply verbalizing whatever thoughts happen to flit through his brain without caring whether he’s understood, and (2) the hearer is trying to interpret the speaker’s utterances, guided by the belief that they’re cooperative and purposeful.
Sometimes it’s easier to see the force of these unspoken assumptions by looking at situations where they come crashing down. Imagine getting the following letter from your grown son:
I am writing on paper. The pen I am using is from a factory called “Perry & Co.” This factory is in England. I assume this. Behind the name Perry & Co. the city of London is inscribed; but not the city. The city of London is in England. I know this from my schooldays. Then, I always liked geography. My last teacher in that subject was Professor August A. He was a man with black eyes. There are also blue eyes and gray eyes and other sorts too. I have heard it said that snakes have green eyes. All people have eyes …
Something’s gone awry in this letter. The text appears to be missing the whole point of why it is that people write letters in the first place. Instead of being organized around a purposeful message, it comes across as a brain dump of irrelevant associations. As it happens, the writer of this letter is an adult patient suffering from schizophrenia, which presumably affects his ability to communicate coherently (McKenna & Tomasina, 2008; the letter itself comes from the case studies of Swiss psychiatrist Egon Bleuler).
Once you know this fact, the letter seems a bit less puzzling. It’s possible to suspend the usual assumptions about how speakers behave because a pathology of some sort is clearly involved. But suppose you got a letter like this from someone who (as far as you knew) was a typically functioning person. Your assumptions about the purposeful nature of communication would kick in, and you might start trying to read between the lines to figure out what oblique message the letter writer was intending to send. Unless we have clear evidence to the contrary, it seems we can’t help but interpret a message through the lens of expectations about how normal, rational communication works.
How do rational speakers behave?
Exactly what do hearers expect of speakers? Grice proposed a set of four maxims of cooperative conversation, which amount to key assumptions about how cooperative, rational speakers behave in communicative situations (see Table 12.1). I’ll discuss each of these four maxims in detail.
MAXIM 1: QUALITY Hearers normally assume that a speaker will avoid making statements that are known to be false, or for which the speaker has no evidence at all. Obviously, speakers can and do lie, but if you think back to the last conversation you had, chances are that the truthful statements far outnumbered the false ones. In most situations, the assumption of truthfulness is a reasonable starting point. Without it, human communication would be much less useful than it is—for example, would you really want to spend your time taking a course in which you regarded each of your instructor’s statements with deep suspicion? In fact, when a speaker says something that’s blatantly and obviously false, hearers often assume the speaker’s intent was to communicate something other than the literal meaning of that obviously false statement; perhaps the speaker was being sarcastic, or metaphorical.
MAXIM 2: RELATION Hearers assume that a speaker’s utterances are organized around some specific communicative purpose, and that speakers make each utterance relevant in the context of their other utterances. This assumption drives many of the inferences we explored in Chapter 11. Watch how meaning gets filled in for these two sentences: Cathy felt very dizzy and fainted at her work. She was carried away unconscious to a hospital. It’s normal to draw the inferences that Cathy was carried away from her workplace, that her fainting spell triggered a call to emergency medical services, that her unconscious state was the result of her fainting episode rather than being hit over the head, and so on. But all of these rest on the assumption that the second sentence is meaningfully connected to the first, and that the two sentences don’t represent completely disjointed ideas.
|
TABLE 12.1 Grice’s “maxims of cooperative conversation”a |
|
1. Quality If a speaker makes an assertion, he has some evidence that it’s true. Patently false statements are typically understood to be intended as metaphorical or sarcastic. 2. Relation Speakers’ utterances are relevant in the context of a specific communicative goal, or in relation to other utterances the speaker has made. 3. Quantity Speakers aim to use language that provides enough information to satisfy a communicative goal, but avoid providing too much unnecessary information. 4. Manner Speakers try to express themselves in ways that reflect some orderly thought, and that avoid ambiguity or obscurity. If a speaker uses a convoluted way to describe a simple situation, he’s probably trying to communicate that the situation was unusual in some way. |
aThat is, mutually shared assumptions between hearers and speakers about about how rational speakers behave.
Adjacent sentences often steer interpretation, but inferences can also be guided by the hearer’s understanding of what the speaker is trying to accomplish. For example, in the very first episode of the TV series Mad Men, adman Don Draper has an epiphany about how to advertise Lucky Strike cigarettes. Given that health research has just shown cigarette smoking to be dangerous (the show is set in the early 1960s), the tobacco company has been forced to abandon its previous ad campaign, which claimed its cigarettes were healthier than other brands. Don Draper suggests the following slogan: “It’s toasted.” The client objects, “But everybody’s tobacco is toasted.” Don’s reply? “No. Everybody else’s tobacco is poisonous. Lucky Strike’s is toasted.”
What Don Draper understands is that the audience can be counted on to imbue the slogan with a deeper meaning. Consumers will assume that if the quality of being toasted has been enshrined in the company’s slogan, then it must be something unique to that brand. What’s more, it must be something desirable, perhaps improving taste, or making the tobacco less dangerous. These inferences are based on the audience’s understanding that the whole point of an ad is to convince the buyer why this brand of cigarettes is better than other brands. Focusing on something that all brands have in common and that doesn’t make the product better would be totally irrelevant. Hence, the strong underlying assumption of relevance leads the audience to embellish the meaning of the slogan in a way that’s wildly advantageous for the company.
If you think advertising techniques like this only turn up in TV fiction, consider what advertisers are really claiming (and hoping you’ll “buy”) when they tell you that their brand of soap floats, or that their laundry detergent has special blue crystals, or that their food product contains no additives. Inferences based on assumptions of quality and relevance likely spring from the hearer’s curiosity about the speaker’s underlying purpose. They allow the hearer to make sense of the question, “Why are you telling me this?” The next two conversational maxims that Grice described allow the hearer to answer the question, “Why are you telling me this in this particular way?”
MAXIM 3: QUANTITY Hearers assume that speakers usually try to supply as much information as is needed to fulfill the intended purpose without delving into extra, unnecessary details. Obviously, speakers are sometimes painfully redundant or withhold important information, but their tendency to strive for optimal informativeness leads to certain predictable patterns of behavior. For example, in referential communication tasks, speakers try to provide as much information as the hearer needs to unambiguously identify a referent, so an adjective such as big or blue is tacked onto the noun ball more often if the hearer can see more than one ball. This is also evident in expressions like male nurse, where the word male presumably adds some informational value—when is the last time you heard a woman described as a “female nurse”? This asymmetry reflects the fact that the speaker probably assumes that nurses are female more often than not, and so it doesn’t add much extra information to specify female gender.
From the hearer’s perspective, certain inferences result from the working assumption that the speaker is aiming for optimal informativeness. Grice argued that this is why people typically assume that some means “not all,” or “not most,” or even “not many.” The argument goes as follows: The conventional meaning of some is compatible with “all,” as well as “most” and “many.” (The test: you can say without contradicting yourself “Some of my friends are blonde—in fact, many/most/all of them are.”) Because some is technically true in a wide range of situations, it’s very vague (just as the vague word thing can be applied to a great many, well, things). If I were to ask you “How many of your friends are blonde?” and you answered “Some of them are,” I could make sense of your use of the word some in one of several ways, including the following:
1. You used the vague expression some because that was all that was called for in this communicative situation, and you assumed that all I cared about was whether you had at least one blonde friend, so there was no need to make finer distinctions (in some contexts, this might be the case, but normally, the hearer would be interested in more fine-grained distinctions).
2. You used such a vague expression because, in fact, you didn’t know how many of them were blonde (this seems unlikely).
3. You used the vague word some because you couldn’t truthfully use the more precise words many, most, or all. Hence, I could conclude that only a few of your friends, and not many, or most, or all, were blonde. This line of reasoning can be applied any time a vague expression sits in a scalar relation to other, more precise words, yielding what language researchers call a scalar implicature (see Box 12.3).
MAXIM 4: MANNER Hearers typically assume that speakers use reasonably straightforward, unambiguous, and orderly ways to communicate. Speakers normally describe events in the order in which they happened, so the speaker is probably conveying different sequences of events by saying “Sam started hacking into his boss’s email. He got fired,” versus “Sam got fired. He started hacking into his boss’s email.” Speakers also generally get to the point and avoid using obscure or roundabout language. It would be strange for someone to say “I bought some frozen dairy product with small brown flecks” when referring to chocolate chip ice cream—unless, for example, she was saying this to another adult in front of small children and meant to get across that she didn’t want the kids to understand what she was saying. In fact, any time a speaker uses an unexpected or odd way of describing an object or a situation, this can be seen as an invitation to read extra meaning into the utterance. To see this in action, next time you’re having a casual conversation with someone, try replacing simple expressions like eat or go to work with more unusual ones like insert food into my oral cavity or relocate my physical self to my place of employment, and observe the effect on your listener.
Grice argued that conversational implicatures arise whenever hearers draw on these four maxims to infer more than what the linguistic code provides. An important claim was that such inferences aren’t triggered directly by the language—instead, they have to be reasoned out, or “calculated,” by the hearer who assumes that the speaker is being cooperative and rational. The speaker, for his part, anticipates that the hearer is going to be able to work out his intended meaning based on the assumptions built into the four conversational maxims.
At what age do children derive conversational inferences?
Grice made a convincing case that conventional linguistic meaning has to be supplemented by socially based reasoning about speakers’ intentions and expected behaviors. As speakers, we tend to take it for granted that our listeners can competently do this, even when we’re talking to young children. For example, a parent confronted with a small child’s request for a cookie might say “We’re having lunch in a few minutes,” or “You didn’t eat all of your dinner.” To get a sensible answer out of this, the child has to assume that the parent is intending to be relevant, and then figure out how this reply is meant to be relevant in the context of the question. Some fairly complex inferencing has to go on. Should the parent be so confident that the message will get across? (And if the child persists in making the request, maybe the parent shouldn’t impatiently burst out, “I already told you—the answer is no!” After all, the parent hasn’t actually said that, merely implied it.)
Some researchers have presented evidence that kids have slid well into middle childhood or beyond before they compute conversational implicatures as readily as adults do. A number of studies have shown that children have trouble understanding indirect answers to questions like the one above until they’re about 6 years old (e.g., Bucciarelli et al., 2003). Even by age 10, kids appear not to have fully mastered the art of implicature. In one such study, Ira Noveck (2001) asked adults and children between the ages of 7 and 11 to judge whether it was true that “some giraffes have long necks.” Adults tended to say the statement was false, reflecting the common inference that some conveys “not all.” But even at the upper end of that age range, most kids accepted the sentence as true. In other words, they seemed to be responding to the conventional meaning of some, rather than to its probable intended meaning. These results raise the possibility that reaching beyond the linguistic code to infer speakers’ meanings is something that develops after kids have acquired a solid mastery over the linguistic code. And they resonate with the notion that some mind-reading tasks are difficult and develop slowly over time, possibly under the tutelage of parents and teachers.
But other researchers have claimed that these experiments drastically underestimate kids’ communicative skills, arguing that many of the studies that show late mastery of conversational inferences require kids to reflect on meanings in a conscious way. This makes it hard to tell whether their trouble is in getting the right inferences or in thinking and talking about these inferences. As with the false-belief tests described in Section 12.1, studies that use more natural interactive tasks, probing for inferences implicitly rather than explicitly, tend to reveal more precocious abilities. Cornelia Schulze and her colleagues (2013) had 3- and 4-year-old children play a game in which the young subjects were to decide which one of two things (cereal or a breakfast roll) to give to a puppet character. When the puppet was asked “Do you want cereal or a roll?” she gave an indirect reply such as “The milk is all gone” from which the child was supposed to infer that she wanted the roll. The researchers analyzed how often the kids handed the puppet the correct object. They found that the responses of even the 3-year-olds were not random: more often than not, the kids understood what the puppet wanted. Another study by Cornelia Schulze and Michael Tomasello (2015) showed that by 18 months, toddlers are able to grasp the intent of a referential gesture, even when its meaning is indirect. They had children play a game with the experimenter in which they retrieved puzzle pieces from a locked container and assembled the puzzle. The experimenter surreptitiously took one of the pieces and put it back into the container. When the child had assembled all the other pieces, the experimenter said, “Oh, look, a piece is missing!” and held up the key to the container. The children took the key and tried to open the container, showing that they had interpreted the experimenter’s action as a suggestion to look in the container for the missing piece. But they didn’t respond in this way if the experimenter held up the key and gazed at it without communicating with the child in any way, or if the experimenter “accidentally” slid the key in the child’s direction. It was the clear intent to communicate that triggered the children’s inferences.
Other researchers have emphasized that specific inferences (such as scalar implicature associated with the word some) may be hard not because young kids lack mind-reading abilities but because they lack experience with language and don’t yet have clear expectations of what people would normally say in certain situations. To understand that a statement like Some giraffes have long necks is weird, you have to know that people would typically say All giraffes have long necks, and this knowledge has to be robust enough to be quickly used in interpreting the speaker’s probable meaning. When this knowledge requirement is removed from a task, children far younger than 9 years can reliably generate scalar inferences. In one such task (Stiller et al., 2015), kids played a game in which they had to guess which referent a stuffed animal had in mind when he “said” things like “My friend has glasses” in reference to a picture like the one shown in Figure 12.5. Two of the “friends” have glasses, so the speaker could be truthfully referring to either of these. But the most sensible way to describe the rightmost character is by saying “My friend has glasses and a hat.” Therefore, the speaker probably meant to refer to the character in the middle. The line of reasoning here is identical to the scalar implicature in which some = not all, but it doesn’t require the child to notice the contrast between various expressions of quantity; instead, the contrast is built right into the experiment. The researchers found that from 2.5 to 3.5 years of age, the kids tended to pick one of the characters with glasses, but their choices were randomly split between the two. At 3.5 years of age, they started to more consistently choose the glasses-only character, and this tendency became stronger for 4- and 4.5-year-olds.

Figure 12.5 A sample picture accompanying the statement My friend has glasses. The child’s task is to identify the “friend.” Although two of the characters have glasses, a reasonable inference is that the statement refers to the one in the center, because the speaker would probably have said My friend has glasses and a hat in referring to the rightmost character. (From Stiller et al., 2015, Lang. Learn. Dev. 11, 176.)
There’s not much evidence, then, that conversational inferences emerge only fairly late in childhood. The machinery to generate them seems to be in place from a very young age. When kids do have trouble with conversational inferences, their difficulties can’t easily be traced to mind-reading limitations or a poor grasp of how cooperative conversation works. Still, their limited experience with language and social interactions can make it hard for them to have the sharp expectations that are sometimes needed to drive conversational implicatures. And it’s quite possible that at least some implicatures elude children because their computational demands exceed the abilities of young minds.
Conversational inferences in real time
Speaking of computational demands, just how much of it do hearers need in order to be able to decipher the speaker’s intended meaning? Some studies suggest that it takes some non-trivial amount of processing effort and time to get from the linguistic code to the intended meaning when there’s a significant gap between the two.
Let’s go back to the scalar implicatures that come up in sentences like Some tuna are fish. To adults, this sentence seems odd, and is usually judged as false because it’s taken to imply that not all tuna are fish. But getting to this implicature takes some work. Lew Bott and Ira Noveck (2004) devised a study in which they explained to their subjects the difference between the conventional linguistic meaning of some (the conventional meaning is often referred to as its semantic meaning) and the commonly intended meaning associated with some, which involves the scalar implicature (or its pragmatic meaning). They then instructed their subjects to push buttons to indicate whether they thought the sentence was true or false. Half of their subjects were told to respond to the semantic interpretation of the sentence (which would make it true), and the other half were told to respond to the pragmatic reading (which would make it false). Even though the pragmatic meaning seems to be the preferred one when people are left to their own devices, the researchers saw evidence that people have to work harder to get it: the subjects who were told to judge the truth or falsity of the pragmatic interpretation took more time to respond than the others, and made more errors when they had to respond under time pressure.
In a follow-up study, Wim De Neys and Walter Schaeken (2007) carried out a similar experiment with a twist: before subjects saw each target sentence, they were shown a visual arrangement of several dots in a grid and had to memorize them. They then pressed a button to indicate whether the target sentence was true or false (they were given no specific instructions about how to respond), all while holding the dot pattern in memory. After their response, they saw an empty grid and had to reproduce the dot pattern. The whole sequence was repeated until the subjects had seen all the experimental trials (see Figure 12.6). The results showed that when the dot pattern was hard to remember (thereby putting a strain on processing resources), subjects were more likely to push the “True” button for sentences like Some tuna are fish, compared with trials where the dot pattern was easy to remember. This suggests that even though the reading with the scalar inference (leading subjects to say the sentence was false) is the most natural one for hearers in normal circumstances, such a reading consumes processing resources, and is vulnerable to failure when there’s a limit on resources and/or time.
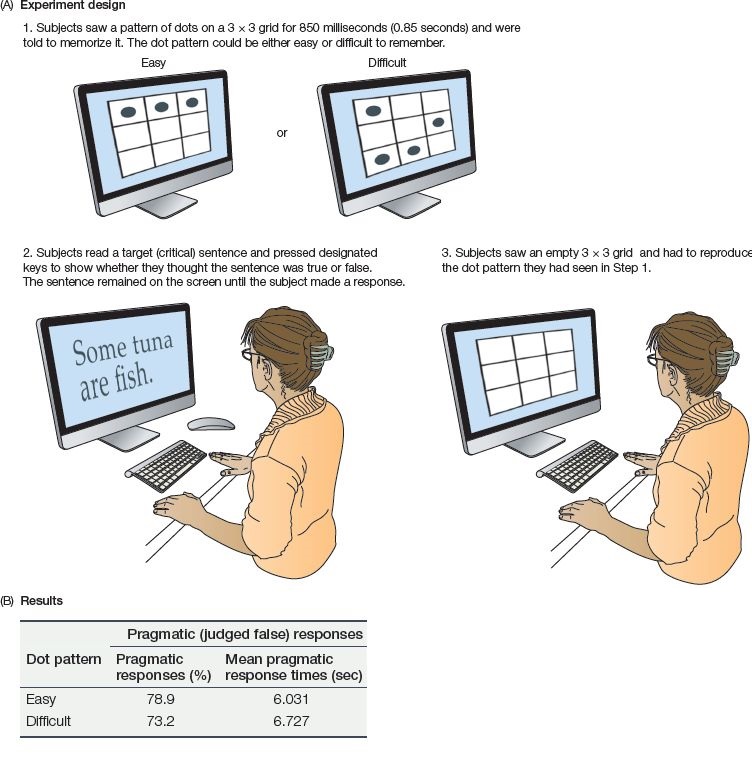
Figure 12.6 Summary of experimental design and results from De Neys and Schaeken (2007). (A) Experiment design. Steps 1–3 were repeated until the subject had been exposed to all of the critical target sentences and all of the filler sentences. Example filler sentences for this particular critical sentence might be Some birds are eagles (true) and Some pigeons are insects (false). (B) Tabularized results, showing the percentage of “pragmatic” responses (that is, the statement was judged false based on scalar inference) for the critical target sentence; and response times for the pragmatic responses, separated by whether they occurred in the easy or difficult dot pattern condition. (Adapted from De Neys & Schaeken, 2007, Exp. Psychol. 54, 128.)
One way to interpret results like these is to say that people first compute the semantic meaning of a sentence, and then they evaluate whether extra elaboration is needed, based on the standards for rational communication. This view segregates the processing of pragmatic meanings from that of semantic meanings. And it’s consistent with the idea that the two processes are different in kind, with very different characteristics and developmental paths. (This perspective might remind you of early theories of metaphor comprehension sketched out in Section 11.5, in which people were believed to consider metaphorical meanings only as a last resort, after the literal meaning of a sentence turned out to be problematic.)
But some researchers have taken a very different view, arguing that conversational inferences are deeply interwoven with other aspects of language processing at all stages of comprehension. They’ve pointed to evidence that in some cases, people seem to compute scalar inferences as quickly as they interpret the linguistic code itself (e.g., Breheny et al., 2013; Degen & Tanenhaus, 2015). And scalar inferences can even be used to resolve ambiguities or vagueness in the linguistic code (see Box 12.4).
Noah Goodman and Michael Frank (2016) invite us to think of the problem like this: Let’s take seriously the idea that the goal of language understanding is to grasp what the speaker is trying to tell us about some aspect of reality. This is at odds with the notion that pragmatic inferencing is something “extra” that’s added, like icing, once the core meaning of a sentence emerges from the mental oven. Instead, at every stage, the hearer is trying to figure out which reality the speaker is likely to have wanted to communicate, based on what he actually said (and what he chose not to say). In other words, it’s very much like the scenario depicted in the film Thirteen Days, in which Krushchev and Kennedy had to decipher each other’s probable intentions based on their choice of military maneuvers. The main difference is that in a typical conversation, we have far more information than Kennedy and Krushchev had—including what the speaker said, which turns out to be enormously helpful in constraining the possibilities. But linguistic information is not privileged in this model; it’s simply one of several sources of information that’s used to infer the speaker’s probable meaning. The hearer’s awareness of the menu of linguistic options available to the speaker, her sense of the speaker’s knowledge or linguistic competence, her own knowledge of the world, the apparent purpose of the conversational exchange, and perhaps even the social rules that govern what counts as acceptably polite speech (see Language at Large 12.2)—all of these are combined with what the speaker actually said and culminate in the hearer’s best guess at the speaker’s underlying intent.
If this depiction of how people derive inferences is right, then we’d expect some inferences to be very easy and some to be very hard. They should be easy when all of the sources of information converge upon a highly probable message. But when some of the cues conflict or don’t offer much guidance, the hearer might thrash about for a while, trying to settle on the most likely scenario the speaker wants to convey.
Brain networks for thinking about thoughts
If you look back to Figure 3.13, which shows the brain regions thought to be involved in language, you’ll notice that there are no areas in that diagram representing the mind-reading processes that I’ve just argued are so important for language use. Why is that?
The absence of mind-reading areas from the brain’s language networks is actually perfectly consistent with Grice’s view of how human communication works. Grice argued that the mental calculations involved in generating or interpreting implicatures aren’t specifically tied to language—rather, they’re part of a general cognitive system that allows people to reason about the intentions and mental states of others, whether or not language is involved. So, despite the fact that social reasoning is so commonly enlisted to understand what people mean when they use language, it shouldn’t surprise us to find that it’s part of a separate network.
Over the past 15 years or so, neuroscientists have made tremendous progress in finding evidence for a brain network that becomes active when people think about the thoughts of others. A variety of such tasks—both linguistic and non-linguistic—have consistently shown increased blood flow to several regions of the brain, especially the medial prefrontal cortex (mPFC) and temporoparietal junction (TPJ) (see Figure 12.8).

Figure 12.8 Brain regions for “theory of mind” (ToM). The medial prefrontal cortex and the temporoparietal junction have been found to be especially active in tasks that require subjects to think about the mental states of others.
Some of the earliest evidence for brain regions devoted to mind reading came from experiments using false-belief tasks like the “Smarties” test discussed in Section 12.1. Following the terminology used by child development researchers, neuroscientists often refer to these areas as the “theory of mind (ToM) regions.” Similar patterns of brain activity have been found during many other tasks that encourage subjects to consider the mental states of others. To isolate the ToM regions, researchers try to compare two tasks that are equally complex and involve similar stimuli, but are designed so that thinking about mental states is emphasized in one set of stimuli, but not in the other. For example, Rebecca Saxe and Nancy Kanwisher (2003) had their subjects read stories like this:
A boy is making a papier-mâché project for his art class. He spends hours ripping newspaper into even strips. Then he goes out to buy flour. His mother comes home and throws all the newspaper strips away.
This story encourages readers to infer how the boy will feel about his newspaper strips being thrown out. This next story also invites an inference, but one of a physical nature rather than one involving mind reading:
A pot of water was left on low heat yesterday in case anybody wanted tea. The pot stayed on the heat all night. Nobody did drink tea, but this morning, the water was gone.
The researchers found that activity in the TPJ was higher for the stories that involved reasoning about people’s thoughts and emotions. Figure 12.9 presents examples of various other contrasts that have been tested, all with the result that tasks or stimuli that emphasize social reasoning are associated with more activity in the ToM regions. Converging results have been found regardless of whether the tasks involve language or images, and single thoughts or complex scenarios (for a summary, see Koster-Hale & Saxe 2013).
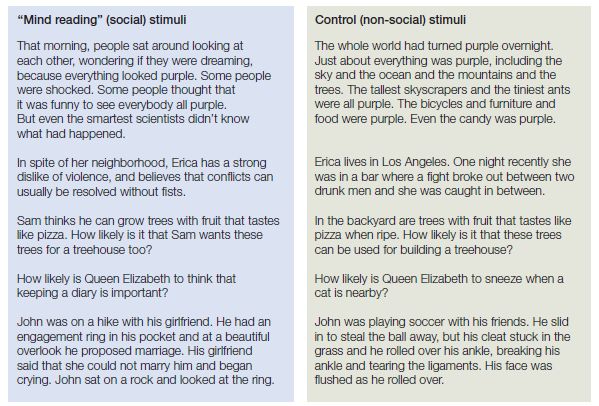
Figure 12.9 Activity in the temporoparietal junction (see Figure 12.8) has been shown to be higher for stimuli that involve “mind reading”—that is, social reasoning about other people’s thoughts and emotions. The examples of social stimuli increased activity in “theory of mind” areas relative to the control (non-social) stimuli at the right. (Examples from Koster-Hale & Saxe, 2013. In Baron-Cohen et al., eds., Understanding other minds, 3rd ed.)
The discovery of a social reasoning network is a handy tool for psycholinguists. It offers a good way to test Grice’s theory that certain aspects of linguistic meaning involve socially based inferences. This was precisely the goal of an fMRI study by Jana Bašnáková and her colleagues (2013). In their experiment, the researchers measured blood flow in subjects’ brains as they heard the last sentence of a short narrative. In one of the experimental conditions, there was no need to go beyond the meaning provided by the linguistic code in order to make sense of the final sentence:
John needs to earn some extra course points. One of the possibilities is to attend a student conference. He has never been to a conference before, and he has to decide whether he wants to present a poster, or give a 15-minute oral presentation. He is talking to his friend Robert, who has more experience with conferences. John knows that Robert will be realistic about how much work it takes to prepare for a conference.
John: How is it to prepare a poster?
Robert: A nice poster is not so easy to prepare.
John: And how about a presentation?
Robert: It’s hard to give a good presentation.
But in another condition, the final sentence was used to convey an implicature. Subjects had to puzzle out the speaker’s intended meaning, using the linguistic meaning of the final sentence as the starting point for their inference:
John and Robert are following a course in Philosophy. It is the last lesson of the semester, and everybody has to turn in their assignments. Some people have written a paper, and others have given a presentation about a philosopher of their choice. John has chosen the latter. When the lesson is over, he is talking to Robert:
John: I’m relieved it’s over!
Robert: Yes, the lecturer was really strict.
John: Did you find my presentation convincing?
Robert: It’s hard to give a good presentation.
The researchers found that the indirect replies in this second scenario led to increased blood flow to a number of brain regions, including the mPFC and the right TPJ, which are generally thought to be part of the ToM network (see Figure 12.10).
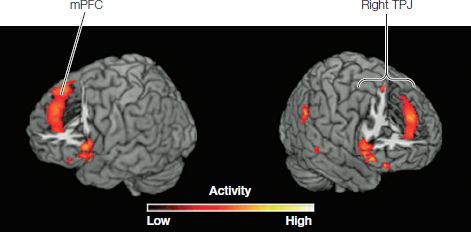
Figure 12.10 These fMRI images show brain regions in which there was increased activity for indirect responses, compared with activity for direct responses. In addition to several other areas, the subjects showed increases in the medial prefrontal cortex (mPFC) and right temporoparietal junction (TPJ), which have previously been shown to be active in “theory of mind” tasks. (From Bašnáková et al., 2014, Cereb. Cortex, 24, 2572, by permission of Oxford University Press.)
At this point, you might be thinking: What about the idea, explored in Section 12.1, that mind-reading abilities spring from two separate systems, not just one? Does neuroimaging support a division between mind reading that is automatic and implicit versus deliberate and effortful? And if so, can brain imaging be used to figure out which system drives conversational inferences in typical conversational settings?
Most brain-imaging work has used tasks that either require or don’t discourage conscious deliberation about mental states, so it’s possible that the evidence for a ToM network only applies to an explicit ToM network. But researchers are beginning to address the separate-systems question by using implicit tasks that have yielded evidence of mind reading in very young children. Claire Naughtin and colleagues (2017) put their participants in a brain scanner and had them watch a false-belief video in which an actor observed a puppet moving an object between two boxes and then left the room. The puppet then moved the object from the box in which the person had last seen it to the other box. The person then came back to the (now-empty) room, at which point the video action was frozen. This video was compared with a similar one in which the person faced away from the puppet the entire time object was being moved, and therefore could not have developed a false belief about the object’s location. While watching the videos, the participants were made to monitor for two different tones, pressing a different button upon hearing each; this was meant to discourage them from consciously thinking about the mental states of the person in the video. For good measure, the researchers questioned the participants afterward and threw out the data of any participants who reported they’d been aware of what the person in the video must be thinking or described the puppet as “tricking” the person. When they compared the results from this task to an explicit task that required people to think about mental states, they found considerable overlap in the brain regions that were heavily active, including the right TPJ.
This line of inquiry is still in its early stages, and results are far from conclusive. At least one similar study has found more distinct patterns of activity between implicit and explicit mind-reading tasks (Schneider et al., 2014). On the other hand, a study using transcranial magnetic stimulation (TMS) to disrupt the right TPJ, which has been found to derail mind reading in explicit tasks, found that it also affected performance on an implicit task (Bardi et al., 2017).
As you’ll see in the upcoming sections, it’s not always clear whether certain language behaviors really do involve mind reading or whether that behavior can be driven by some other mechanisms. In some cases, mind-reading explanations compete with other accounts, generating vigorous debates among researchers. Cleverly designed behavioral tests can help sort out these disagreements. But over the coming decade, I’m sure we’ll also see a growing number of studies in which researchers refine our knowledge of ToM networks in the brain and use this new knowledge to help resolve the disputes.
12.3 Audience Design
So far in this chapter, we’ve looked at how language users of various ages blend together mind-reading skills with their knowledge of the linguistic code. We’ve focused mainly on experiments dealing with language learning and comprehension. In this section, let’s put the spotlight on the speaker. To what extent does mind-reading behavior show up in the task of producing language?
In Chapter 10, you saw that the act of speaking involves a constant series of choices. The speaker has to pick certain words over others that may be nearly as good, and she has to commit to building a specific syntactic structure while rejecting other options that convey much the same meaning. You learned about some of the factors that affect the speaker’s choices—including the degree to which certain linguistic options happen to be more accessible than others at the precise moment of speech planning. Now let’s look at whether there’s also any evidence that in making their choices, speakers tailor their speech to their hearers.
The notion of audience design, in which speakers adapt their utterances to their listeners, can encompass many aspects of production, from speaking more slowly to foreigners, to using less formal language when hanging out with friends, to pronouncing words in a particular local accent. In this section, I’ll concentrate on whether speakers take into account the comprehension challenges of their listeners.
Are speakers sensitive to comprehension demands?
A Gricean view of language use, as outlined in the previous section, certainly claims that speakers do actively consider the needs and abilities of their hearers. For example, Grice’s maxims of Manner and Quantity state that speakers craft language that is unambiguous and that has as much information as is called for. Do speakers live up to these standards? The usual referential tasks show that for the most part, speakers do succeed at avoiding ambiguity in situations where there are multiple referents of the same category that have to be distinguished from each other. For example, if a speaker is trying to direct the hearer’s attention to a specific pair of shoes in a context where there’s more than one pair, she would normally use a more precise phrase like the brown shoes or the loafers rather than simply the shoes. Speakers can even throw themselves into the perspective of their hearers when their own visual perspective conflicts with that of their partners, adapting their language to the partners’ perspective—though there’s some evidence that under time pressure, the ability to shift perspective drops off somewhat (Horton & Keysar, 1996). Overall, speakers do quite well at averting referential ambiguity by choosing as much content as is needed to uniquely pick out the target object.
But there are many other ways in which linguistic input can be ambiguous or difficult for the hearer to understand. There might be a lexical or a syntactic ambiguity to resolve. Or the speaker might use a stripped-down expression such as a pronoun, forcing the hearer to search through a number of possible antecedents. Or the speaker might expect the hearer to make inferences that are just too demanding under the time pressures of spoken language. Or the pronunciation of a word might simply be indistinct, leading to confusion with other similar-sounding words.
A number of production patterns across various languages suggest that speakers do balance comprehension challenges against the difficulties of production. Here are just a few examples:
■ Some languages, like Russian, allow the subject of the sentence to be dropped entirely, so instead of “He fumbled the ball,” you might simply say, “Fumbled the ball.” Subjects tend to be dropped only in contexts in which they are highly predictable, and therefore easily inferred by the hearer (Kravtchenko, 2014).
■ Japanese is a language that has flexible word order and uses case marking to show which entities are subjects versus objects, and so on. But case marking is not compulsory, so speakers can leave these tags off the nouns in a sentence, and do so quite often in conversational speech. But they are more likely to drop these morphemes if the role of the noun is predictable in the context. For example, the morpheme is more likely to be left off the object grandma in a sentence like The doctor treated the grandma than in a sentence like The doctor sued the grandma, where you’d normally expect the grandma to be the one doing the suing (Kurumada & Jaeger, 2015).
■ In English, the function word that is optional when it introduces a complement clause, as in She knew (that) the documents were fake. (In fact, some copyeditors have seemed intent on deleting all such instances of that from my writing, presumably to make my sentences more elegant!) But it turns out that speakers and writers use this word selectively, tending to insert it after a verb that is less likely to be followed by a complement clause (such as know) than one that typically takes a complement clause (such as claim) (e.g., see Garnsey et al., 1997; Jaeger, 2010), thereby reducing garden path effects.
Even sloppy pronunciation seems attuned to hearers’ needs. Most of our conversations don’t sound like elocution exercises—for example, a sentence like How am I supposed to know what you like on your sandwich might come out something like, “How’my s’posta know whachu like on yer sawich?” In running speech, we often shorten words, pronounce sounds indistinctly, meld adjacent sounds together, and even drop consonants and vowels entirely, all of which can put a greater burden on the hearer. But there’s apparently a method to mumbling. Speakers tend to produce lower-quality output when the words they’re speaking are highly predictable. For example, the word nine would be pronounced with less care in familiar proverb like A stitch in time saves nine than in than in a sentence like The next word is nine, where the word is highly unpredictable (Lieberman, 1963). Speakers also tend to articulate less clearly when the words they’re using are less common, or when the same word has recently been uttered in the conversation (Bell et al., 2009). In other words, the acoustic quality of speech is the lowest in situations where word recognition is easiest for hearers.
All of this makes it seem as if speakers judiciously adjust their speech to make it as efficient as possible without posing too many problems for the hearer. Perhaps speakers’ choices are a bit like the data compression techniques used to create MP3 and JPEG files. The idea behind such data compression is to keep only the information that has the greatest impact, with the goal of whittling down the space needed to store these files by throwing out information that’s redundant or doesn’t add much to our perceptual experience—for example, the compression algorithm may toss out data at sound frequencies we can’t hear, or not bother to encode slight gradations of color that are hard to see. Do speakers similarly produce utterances with the hearers’ perceptual capabilities in mind?
This is an intriguing idea. But it isn’t the only explanation for many of the patterns that end up benefitting the hearer. For example, speakers might utter common or predictable words in a lazy manner simply because these are easier to produce, and it could be that speakers devote less articulatory effort to easy words without necessarily considering the effect on the hearer at all. Luckily for the hearer, words that are easy to produce are often also those that are easy to recognize during language comprehensions, including common or highly predictable words. It’s possible to come up with plausible speaker-centered stories for the other examples I’ve listed as well. And a number of experimental studies cast doubt on the notion that the hearer’s needs always figure prominently in a speaker’s linguistic choices.
For example, Vic Ferreira (2005) adapted a referential task to test whether speakers would steer clear of producing lexically ambiguous words as competently as they manage to avoid referential ambiguities. The study included visual displays that contained two objects that could be described by the same ambiguous word—for example, bat could refer either to a flying nocturnal animal, or to a baseball bat. Without any additional information, just saying the bat would be as ambiguous for the hearer as saying the ball in a visual display with more than one ball. If speakers are attentive to this potential problem for their listeners, they should either choose a different word, or add some disambiguating information (such as the baseball bat, the flying bat). For comparison, the researchers also included trials in which the display contained two objects of the same kind that differed in size (for example, two flying bats, one large and one small) as well as control trials in which all of the objects were unrelated (see Figure 12.11).
The results showed that when all of the objects were unrelated and therefore created no potential ambiguity, speakers tended to produce (65 percent of the time) a single bare noun (e.g., the bat). When the display had two objects of the same kind (two flying bats), speakers were almost always able to avoid referential ambiguity by including additional information and generated ambiguous bare nouns only 1 percent of the time. But speakers were much less adept at producing unambiguous phrases when the visual displays created the opportunity for lexical ambiguity (the flying bat and baseball bat)—in this case, ambiguous bare nouns such as the bat were produced 40 percent of the time. If you compare this condition to the control display with unrelated objects (which resulted in bare nouns 65 percent of the time), it seems obvious that speakers were adapting their speech to avoid the potential ambiguity some of the time. But despite their efforts, an ambiguous phrase escaped their lips in a very large portion of trials.
Why are speakers so good at avoiding non-linguistic referential ambiguities, but quite bad at steering clear of lexical ambiguity? This pattern might seem very puzzling at first. But it becomes a lot less surprising if you take into account the mechanics of how language production works. As discussed in Chapter 10, speaking involves an ordered set of stages: the speaker first settles on a meaning she wants to convey, then chooses an appropriate syntactic frame, then chooses lexical items that match up with that meaning and fit into the sentence’s frame, and finally assembles and executes the sounds that make up the words. Different types of ambiguities tap into different stages of production. Avoiding a non-linguistic referential ambiguity (distinguishing between two flying bats of different sizes) can be done at the very earliest step in production, when the speaker is still sketching out the meaning of the utterance. But avoiding a lexical ambiguity would have to take place at a later stage, when the specific words are being chosen. The demands on the speaker might be quite different at these two stages of production.

Figure 12.11 Examples of the type of displays used in the study by Ferreira and colleagues (2005). (A) The display contains a potential non-linguistic ambiguity with regard to the word bat. (B) There is a potential linguistic (lexical) ambiguity with regard to the word bat. (C) This group displays no potential ambiguity. (Adapted from Ferreira et al., 2005, Cognition 96, 263.)
What’s more, the process of detecting the ambiguity is very different in the two situations. In the easier case of avoiding a referential ambiguity, the speaker needs to make sure that enough conceptual material is present to distinguish among similar referents. But in order to avoid the lexical ambiguity, the speaker has to become aware that the same form can be linked to two different meanings. Since the intended meaning is so prominent in the speaker’s mind, the competing meaning (which, after all, is irrelevant from the speaker’s perspective) may never become active enough for her to register the ambiguity. You might think of the process as analogous to trying to proofread your own writing—people often can’t “see” their own typos, because knowing what they intended to express makes them blind to the forms with which they actually express it.
The moral of the story is that even if the speaker has every intention of avoiding ambiguity in her speech, there might still be a lot of variation in how well she succeeds in meeting that goal. The specific task of ambiguity avoidance might look very different for different types of ambiguity.
Syntactic ambiguity and audience design
Speakers hoping to avoid syntactic ambiguities have an abundant array of options available to them: they can choose a different unambiguous structure that has the same general meaning as a potentially ambiguous one; they can use intonation to help clarify which of the possible meanings was intended; and in many cases, they can disambiguate a structure merely by inserting a small but useful grammatical marker. Consider the ambiguous sentence fragment The coach knew you… . This can be read either as a simple clause in which you is the direct object of knew (as in The coach knew you too well) or as a more complex sentence in which you is the subject of an upcoming clause (for example, The coach knew you had it in you). If you were wanting to express the second option, you could do your hearer a great favor by splicing in the little word that: The coach knew that you… . Ambiguity problem solved!
Just as with lexical ambiguities, though, the stumbling block is whether speakers are able to realize that certain structures will be potentially ambiguous for the hearer. Again, since the intended meaning is already obvious to the speaker, becoming aware of the ambiguity means the speaker has to anticipate the experience of the hearer while deeply engaged in the act of speaking. The research literature is riddled with studies that showcase speakers’ failures to do this. For example, as you saw in Box 9.4, speakers are not particularly strategic about using intonation to disambiguate, even though this information could be quite helpful to hearers. And when faced with the menu of syntactic options, their choices are often driven more by what makes their own task of language production easier than by what makes comprehension easier for their listeners.
This last point is apparent in a detailed study by Jennifer Arnold (2004) looking at whether speakers take pains to avoid ambiguities in how prepositional phrases (PPs) are attached. As you saw in Chapter 9, potential “garden path” traps often lurk in sentences with prepositional phrases, causing readers or hearers to settle on an interpretation that turns out to be wrong. For example:
The foundation gave Grant’s letters to Lincoln to a museum in Philadelphia.
On hearing the prepositional phrase to Lincoln, a hearer might be fooled into thinking that the foundation gave the letters in question to Lincoln (the PP is attached to the verb phrase, or VP). But instead, the phrase is really just clarifying which letters the foundation gave to the museum (that is, the PP is attached to the noun phrase, or NP). Of course, the speaker could rearrange the constituents of this sentence in a way that makes the problem vanish:
The foundation gave a museum in Philadelphia Grant’s letters to Lincoln.
Here, the recipient of the verb gave is ordered first (a museum in Philadelphia), so by the time the hearer gets to the phrase to Lincoln, there’s no way he can mistakenly interpret the prepositional phrase as referring to the recipient of gave. The researchers confirmed that hearers did indeed have less difficulty with this unambiguous version than the earlier, ambiguous one. The question was: Would speakers veer away from the ambiguous structures to produce the sentences that hearers clearly prefer?
To test whether speakers’ sentence choices were influenced by the potential ambiguity of a sentence, the experiment had to include a good baseline to measure how often speakers ordered the recipient first when the alternative choice wouldn’t lead to an ambiguity. For example, the following sentence is very similar in meaning to the preceding ambiguous sentence but poses no potential ambiguity:
The foundation gave Grant’s letters praising Lincoln to a museum in Philadelphia.
If speakers make syntactic choices in part by anticipating problems for the hearer, there should be little pressure to reorder the sentence to make the recipient first, as in the following sentence:
The foundation gave a museum in Philadelphia Grant’s letters praising Lincoln.
In other words, examples like sentence B in Table 12.2, for which the alternative is ambiguous, should outnumber examples like D, where the alternative is unambiguous. But that’s not what the researchers found. Speakers chose the two types of sentences with about the same frequency, suggesting that the potential ambiguity of their sentences didn’t make a dent in their syntactic choices.
|
TABLE 12.2 Example stimuli and results from Arnold et al., 2004, J. Mem. Lang. 51, 55, Experiment 2 | |
|
Spoken responses |
Results (% of responses) |
|
Potential ambiguity |
|
|
(A) Ambiguous: The foundation gave Grant’s letters to Lincoln to a museum in Philadelphia. |
33 |
|
(B) Unambiguous alternative: The foundation gave a museum in Philadelphia Grant’s letters to Lincoln. |
67 |
|
No potential ambiguity |
|
|
(C) Unambiguous: The foundation gave Grant’s letters praising Lincoln to a museum in Philadelphia. |
20 |
|
(D) Unambiguous: The foundation gave a museum in Philadelphia Grant’s letters praising Lincoln. |
80 |
What did affect speakers’ choices were factors that relieve the pressures of production. One of these was the relative weight of the two NPs that follow the verb. In Chapter 10, you saw that when choosing among various options for ordering two NPs, speakers use the one that allows them to pronounce shorter phrases first—the idea is that the planning of shorter phrases is completed before the longer ones, and by dumping whichever phrase is ready first into the sentence frame, the speaker can clear some material out of working memory. So, regardless of potential ambiguity, speakers were inclined to produce the first of the following sentences rather than the second sentence. To allow you to compare their length, the main constituents after the verb are marked off in square brackets:
The foundation gave [Grant’s letters to Lincoln] [to a highly respected American history museum in Philadelphia].
The foundation gave [Grant’s famous recently recovered letters to Lincoln] [to a museum in Philadelphia].
These results suggest that in syntactic planning, speakers take the option that lightens the load for speaking, rather than the one that makes comprehension easier. Presumably, this is either because the pressures on language production are so strong, or because it’s too hard to keep track of potential ambiguities from the hearer’s perspective, or a combination of both.
A similar conclusion was reached by Vic Ferreira and Gary Dell (2000), in a study that looked at whether speakers strategically make use of disambiguating grammatical words to make their sentences less ambiguous. As I’ve pointed out, in some cases, ambiguity could easily be avoided simply by including disambiguating grammatical words; for example, the potential garden path structure The coach knew you… could be transformed into the unambiguous The coach knew that you… . The troublesome reduced relative clauses that we spent so much time discussing in Chapter 9 can also be disambiguated in a similar way, as shown in the following sentences:
The horse raced past the barn fell.
The horse that was raced past the barn fell.
As in the Arnold et al. (2004) study, Ferreira and Dell reasoned that if speakers take into account potential ambiguities while planning to speak, then they should be especially likely to use the helpful, disambiguating word that in sentences where omitting it would lead to an ambiguity. In contrast, they should be less likely to include it in sentences that would be unambiguous regardless of whether that is included. So, compare the following two fragments, with and without the inclusion of that:
The coach knew (that) you …
The coach knew (that) I …
The second fragment is unambiguous even without that, simply because in the first person, the subject pronoun I is different from the object pronoun me, so there’s no possibility of taking the pronoun to be the direct object of the verb. Because the second-person pronoun you takes the same form regardless of whether it’s a subject or object, the that-less fragment is completely ambiguous at this point in the sentence.
To get speakers to produce sentences that would allow for a focused comparison (rather than simply waiting for speakers to spontaneously produce enough examples of exactly the right type), the study used a sentence recall task. Participants saw a set of sentences, including the critical ones revolving around potential ambiguity (The coach knew you/I missed practice), and then based on a two-word cue from each sentence (for example, coach knew), had to try to recall it as best they could from memory. In a sentence recall task like this one, subjects usually don’t reproduce the sentences word for word, and typically make wording adjustments while keeping the meaning consistent. The aim was to see whether, in recalling these sentences, speakers would be more likely to utter the word that in situations where it would be helpful in averting ambiguity.
But, like Arnold and colleagues, Ferreira and Dell found that the decision to insert that was not influenced by the potential ambiguity of the target sentence. Instead, it was affected by the accessibility of the pronoun that came after the main verb. What seemed to be going on was this: When the postverbal pronoun was very accessible, it got dumped into the sentence as soon as possible, so the speaker chose to forgo the option of introducing the embedded clause with that in favor of getting the subject pronoun out the door as quickly as possible. On the other hand, when the pronoun was less accessible, speakers took advantage of the optional that as a placeholder while still working on the retrieval and planning of the pronoun. So, rather than exploiting the disambiguating power of this little word for their hearers’ benefit, speakers appeared to be using it as a way of smoothing out the demands of language production.
The importance of feedback from hearers
At this point, you might be harboring an objection: is recalling sentences in response to an experimenter’s instructions a task that’s likely to awaken a speaker’s cooperative impulses? From the speaker’s perspective, the goal of the recall task is not to be understood by the hearer but to reproduce the sentences accurately. In fact, the “hearer” seems no more than an abstraction in this experiment—is the hearer the research assistant who administers the experiment? The one who codes the data? The scientist(s) who designed the study? Why should the speaker care whether she produces sentences that are easy for this nebulous hearer to understand?
This is a valid objection. To test whether speakers take hearers’ comprehension needs into account while planning their utterances, doesn’t it make sense for the speaker to have some evidence that (1) there is a hearer, and (2) the hearer actually does have needs, or is invested in understanding what the speaker says? So far, I’ve argued that in considering whether the speaker can get inside the head of his hearer, it’s important to think about the specific production mechanisms that are in play and the processing demands on the speaker that these mechanisms impose. Perhaps it’s just as important to consider whether the hearer’s requirements play a part in the equation.
Not surprisingly, the answer is that it often does seem to matter who the hearer is and what he or she is doing. For one thing, it can make a difference if there’s an actual flesh-and-blood person, rather than an “abstract” listener, or even an alleged conversational partner sitting in an adjoining room who in reality is a computer emitting a set of prerecorded utterances. It can matter whether the hearer is just a passive listener, or an active partner in an interactive task. (For example, Sarah Haywood and her colleagues reported in 2005 that speakers did show some ability to anticipate and avoid syntactic ambiguity. Their task involved a highly interactive game in which research participants alternated being in the speaker and hearer roles so that they were able to have some firsthand experience of how disruptive ambiguity could be for comprehension.) And, it might even matter whether the hearer is a confederate who is hired to follow an experimental script or a naive, off-the-street, bona fide conversational partner.
For an interesting case study that addresses this last point, let’s look at a pair of experiments that showed different degrees of audience design on the part of speakers. In a classic study by Paula Brown and Gary Dell (1987), subjects read little stories and then retold the same stories to a listener. Each of the stories described an action involving some specific instrument. For example:
The robber hid behind the door and when the man entered the kitchen he stabbed him in the back. He wiped the blood off the knife and rummaged through the drawers. Later police investigators found his fingerprints all over the knife and had no trouble catching him.
In this story, the instrument (the knife) is the typical instrument you’d expect to be used in a stabbing incident. Half of the stories contained predictable instruments like this one, while the other half involved unusual instruments—for example, an ice pick might have been used in the stabbing instead. Brown and Dell found that in retelling the stories, speakers explicitly mentioned the instruments twice as often when they were unusual ones than when they were highly predictable.
At first glance, this seems to be perfectly aligned with Grice’s suggestion that speakers produce as much information for their hearers as is needed, but no more. When the instrument is highly typical, speakers might count on the fact that listeners can easily infer the instrument, so it doesn’t need to be mentioned. But Brown and Dell cautioned that the results don’t necessarily mean that speakers were actually calculating what their hearers might or might not be able to infer—instead, the speakers could simply be following a general strategy of not mentioning highly predictable information, perhaps based on a history of their own experiences with language. Their proposal reminds me of an experience I had while traveling on a plane from my home in Calgary, Canada. I sat next to a man who was on his way home to Florida. He told me that he and his family were just coming back from a wonderful vacation in the Rocky Mountains—evidently, they’d had a great time “snow skiing.” To my Canadian ears, it struck me as odd that one would bother to specify that skiing was done on snow. It seemed a bit like saying you’d eaten a “bread sandwich” or had bought a “metal car.” I asked my fellow traveler whether he would ever just say “skiing” instead of “snow skiing.” He patiently explained that yes, he would, but then that would take place on the water. In this case, my plane-mate revealed a lapse in audience design. His choices of skiing terminology seemed to have more to do with his own sense of what usually takes place when you put skis on, and of what the word skiing generally refers to, rather than on any evaluation about the amount of information that I needed.
Much of the time, a general strategy based on the speaker’s own experiences would coincide nicely with the communicative needs of the hearer, making the speaker’s behavior seem fully cooperative (for example, if I too had been from Florida, I wouldn’t have batted an eye at the speaker’s choice of words). Brown and Dell argued that in order to really test whether speakers take on the hearers’ perspective in designing their utterances, you’d have to create a situation in which the hearers’ actual informational needs didn’t line up with the usual patterns of predictability. For example, what would happen if the situation made it easy for the hearers to infer even the atypical instruments like the ice pick? To find out, the researchers designed a version of the experiment in which, while retelling the story, some of the speakers showed the hearers a picture of the event that illustrated the instrument in question. Other speakers showed the hearers either no picture at all or one that didn’t reveal the instrument. Obviously, the hearers who saw the informative picture should have no trouble figuring out the instrument even if it was never mentioned in the speakers’ retelling. But speakers didn’t seem to take their partners’ visual perspective into account, and still mentioned the atypical instrument about twice as often as the more common one even when hearers had access to the picture that showed the instrument. Brown and Dell concluded that the predictability of certain elements in events, rather than mind-reading efforts, was the main force behind their speakers’ design of utterances.
But a later study by Calion Lockridge and Susan Brennan (2002) yielded different results, despite using a near identical experimental design. This time, speakers did show a sensitivity to the visual information that their hearers were privy to. That is, speakers were more likely to mention the atypical instruments when the hearers didn’t see a picture than when they saw one that showed the instrument of the action. Why the different results? One of the main differences between the two studies was that Brown and Dell ran their experiment with experimental confederates in the role of the hearer. That is, each speaker was partnered with a student who pretended to be a one-time research participant who had volunteered for the study, just like the speaker. But in reality, unbeknownst to the speaker, this student was a confederate who was being paid to run through 40 iterations of the experiment. Lockridge and Brennan, on the other hand, actually did recruit one-time participants as both speakers and hearers, and randomly assigned their recruits to one or the other role. This meant that the hearers genuinely had no knowledge of the experimental structure or the stories.
Why would this matter, especially if the speakers were successfully duped into thinking that the confederates were real subjects? Lockridge and Brennan point out that in real conversations, hearers don’t just passively listen and wait for the speakers to say what they have to say, without showing any reaction. Even when they’re not speaking, listeners are often busy providing the speakers with a slew of cues about whether the speakers are being effective—a furrowed brow, a quizzical look, or a slight impatience to get on with the story and stop beating around the bush. If the message is clear, hearers might nod, or make little approving sounds, or say “OK” in a decisive way. Cues like these from the hearer to the speaker are called back-channel responses. But experimental confederates who’ve already heard the same stories over and over again might not emit the kinds of cues and responses throughout the story that naive hearers would. So, even if the speakers believed at a conscious level that the confederates were hearing the stories for the first time, they still might not be exposed to continuous feedback that provided them with real evidence of the hearers’ efforts to process what they were saying. And this lack of back-channel feedback could conceivably affect the speakers’ motivation to consider their partners’ communicative needs and perspective—after all, if your partner seems to understand you pretty well no matter how you choose your words, why bother devoting precious processing resources to tailoring your speech for her benefit?
The importance of feedback from hearers offers a way out of a seeming paradox: At the beginning of this section, I listed several language patterns showing that speakers tend to reduce information the most when the information loss is least troublesome to hearers. I then proceeded to describe a number of experiments in which speakers failed to take their hearers’ needs into account. What gives? Is it just a convenient coincidence that the mechanisms of production so often turn out to be to the hearer’s benefit? Here’s one way of reconciling these facts: when speakers succumb to production pressures and utter language that is difficult for their hearers, they often receive a signal from the hearer about the communication glitch and this may lead them to adjust their future language production. Over time, speakers will learn to drop information selectively—not necessarily because they’re carefully monitoring the hearer’s state of mind at every moment, but because they’ve gradually learned to produce more helpful patterns.
Esteban Buz (2016) have argued for this position, showing evidence of learning as a result of feedback. They had people take part in a web-based task in which several words appeared on a screen, with one of them highlighted as the target. Their job was to pronounce the target word into a microphone, and they were told that an unseen partner in the task would click on the word that he or she thought the speaker had pronounced. On some of the trials, the target word was very similar to another word on the screen, contrasting only in the voicing of the first sound (e.g., target pill in the presence of bill). On a handful of trials, the speakers received feedback that the “hearer” (who was, in reality, nonexistent) had clicked on the wrong word, choosing the similar one instead. Over the course of the experiment, these speakers came to pronounce the word-initial sounds more distinctly in the presence of a similar word; however, speakers who either got no feedback at all, or feedback suggesting that their hearers always understood their speech, did not adjust their articulation. This suggests that feedback can trigger more adaptive communication, in which speakers invest effort into preserving information where hearers are most likely to need it.
12.4 Dialogue
If you spend time listening to people talking to each other, it becomes clear that conversation is very different from written language. When you write, you do what you can to craft an understandable message, you send it out, and you hope for the best. Your reader’s job is to do his best to accurately interpret what you wrote, but his actions don’t shape the way you structure your message. In conversation, though, roles aren’t so rigidly divided, and hearers and speakers often adopt a mutual, step-by-step responsibility for successful communication. Speakers depend on hearers to provide feedback about how the interpretive effort is going, and they make their conversational moves contingent on that feedback.
Conversation as a collaborative process
Conversation isn’t just about two partners taking turns being the active and passive participants in a talk exchange. In live dialogue, the actions and responses of hearers can have a profound influence on the communicative behavior of speakers. A detailed discussion of such joint effort can be found in a paper by Herb Clark and Deanna Wilkes-Gibbs (1986). Here’s an example (originally from Sacks & Schlegoff, 1979) that illustrates the hearer’s contribution to shaping an utterance during a conversation:
A: … well I was the only one other than the uhm tch Fords? Mrs. Holmes Ford? You know, uh … the cellist?
B: Oh yes. She’s she’s the cellist.
A: Yes. Well she and her husband were there.
As Clark and Wilkes-Gibbs point out, in the first conversational turn, Person A introduces the Fords into the conversation, but seems to have some question about whether B will understand who these people are, as suggested by the questioning intonation. Getting no response from B at first, A tries a slightly different expression, offering the full name Mrs. Holmes Ford? again as a question. The lack of a response from B elicits yet a third attempt: the cellist? Finally, B responds, showing agreement with the description, and the conversation can move on.
Clark and Wilkes-Gibbs argue that it’s misleading to say that speakers refer and hearers interpret. Instead, they see referring as a collaborative process for which both participants are responsible. Speakers propose referring expressions, sometimes tentatively, and then wait to see whether their conversational partners accept them. Sometimes, the speaker will explicitly invite feedback by posing a question, or by using rising intonation. But often the hearer takes the initiative and signals agreement even without being explicitly invited to do so, as in this example (Cohen, 1985):
A: Take the spout—the little one that looks like the end of an oil can—
B: Okay.
A: —and put that on the opening in the other large tube. With the round top.
At other times, the partner might correct or clarify an expression, or even jump in when the speaker signals some difficulty in production:
A: That tree has, uh, uh …
B: tentworms.
A: Yeah.
B: Yeah.
Clark and Wilkes-Gibbs argue that when hearers take their conversational turn without questioning or correcting the speakers’ choice of wording, they implicitly ratify the speakers’ linguistic choices, which makes it likely that the expression will be used again in the future. In this way, the hearers’ responses shape how the speakers will proceed.
Establishing common ground between conversational partners
For Clark and Wilkes-Gibbs, examples like those we just explored reveal something profound about the very nature of conversation. The whole process is seen as a joint effort to establish common ground with a conversational partner—that is, to identify the body of mutual knowledge, mutual beliefs, and shared assumptions that serves as the basis for communicating with that partner. Both partners contribute to building up common ground, whether it’s by proposing, rejecting, acknowledging, modifying, or clarifying information, and in order for new information to be entered as part of the common ground, it has to be grounded—that is, it has to be accepted as sufficiently well understood (whether overtly or tacitly) by both partners. Partners can also rely on reasonable predictions about what’s likely to be in the common ground that they share with a partner. These predictions might be based on community membership (for example, if you’re a fellow rock climber, I might reasonably assume that you know what I’m referring to when I say “What kind of belay device do you like to use?”). Information might also be assumed to be part of common ground if both partners have witnessed it or heard about it, as long as there’s evidence that they were both paying attention to that information. Notice that under this worldview, tracking a conversational partner’s attentional state and knowledge base is central to successful communication.

Figure 12.12 Examples of the type of experimental stimuli used by Brennan and Clark (1996). Pairs of subjects receive identical six-card sets. One partner verbally directs the other to arrange the cards in a specific order. (A) Card set in which the target referent (the dog) is the only one of its kind; hence reference by means of a bare, basic-level word (dog) is adequate to avoid ambiguity. (B) Card set in which the target referent is accompanied by another object of the same basic level. Reference to the dog would be ambiguous, motivating the use of a more detailed expression (the cocker spaniel; the dog with the spots) in directing the cards’ arrangement.
Susan Brennan and Herb Clark (1996) showed how once two partners have accepted a referring expression as part of common ground, there’s momentum to re-use that expression with the same partner, even when other wording choices might seem natural. Pairs of subjects were involved in a card-matching game in which both partners got the same set of picture cards (see Figure 12.12). One partner (the director) had to communicate to the other partner (the matcher) how to arrange the cards in a particular order. The goal of the study was to see how the director would refer to certain target objects—for example, a dog, or to be more precise, a cocker spaniel. The identities of the other cards in the set were manipulated so that some of the time, there would be another object of the same kind (another dog, but of a different breed), while at other times, the target card would be the only object of its kind.
We’ve already seen that people tend to refer to objects by using basic-level nouns (the dog) unless there’s some specific reason to add more information, such as the need to distinguish one dog from another—in which case, they use more detailed expressions like the cocker spaniel, or the brown dog, or the dog with the floppy ears. Brennan and Clark found that this was true for their conversational participants. But the real question of interest was how the directors would refer to a lone dog in a card set after they’d been forced to provide extra detail because the card set in the previous trial had included a second dog. Under the grounding view of reference, there should be some motivation to re-use the more specific expression (the cocker spaniel), because that wording had been ratified earlier by both participants. In Brennan and Clark’s words, the partners had entered into a conceptual pact to describe the object in a particular way. But would this pact prevail, even when the detailed phrase had become more informative than necessary?
In fact, conceptual pacts seemed to play an important role in shaping speakers’ choices. When speakers had previously used a more specific expression, they often kept on using that same phrase or a very similar one even when the basic-level term was all that was needed for unambiguous reference. The more firmly tethered that phrase was in common ground (that is, the more times it had been used previously), the more likely it was to be re-used. Finally, the tendency to persist in using the familiar expression was linked to the original partner. When interacting with a new, unknown partner, a speaker was more likely to revert to using a bare, basic-level term.
Other researchers have also found a tendency for conversational partners to become closely aligned in the way they use language. Simon Garrod and Anthony Anderson (1987) had pairs of subjects play a computerized maze game in which one partner had to guide the other to a destination in a maze made of interconnected boxes. This game left open a number of ways you could describe the locations in the maze (see Table 12.3). For example, you could anchor yourself to a starting point and describe the path you’d follow from that point to your current location (Table 12.3A). Or you could impose an abstract grid over the maze structure and use a coordinate system to refer to locations (Table 12.3B). Or you could focus your descriptions on saying which line you were in, and which box from the left within that line (Table 12.3C). Garrod and Anderson found that their subject pairs quickly settled on one approach, with both partners persisting in using a consistent structure for their descriptions.
How much mind reading takes place during conversation?
Clearly, conversation is a coordinated activity, with partners affecting each other’s behavior and speech. But not all researchers agree that coordination is achieved by having the partners maintain a representation of common ground. To do this, people would have to track and update information about each other’s mental states, knowledge, and beliefs. And they’d have to be able to keep all this information in memory while coping with the chaotic demands of real-time conversation. Is all this really computationally feasible? And more important, is it really necessary to assume such depth of mind-reading activity in order to explain the typical patterns of dialogue? Or could the effects be captured instead by simpler and dumber mechanisms?
A number of researchers have argued that results like those found by Brennan and Clark don’t really require partners to negotiate conceptual pacts and retain these pacts in memory. Among such researchers are Martin Pickering and Simon Garrod (2004). Pickering and Garrod agree that the mechanism that causes partners to converge on similar bits of language does have a social basis. They just don’t think that it involves something as sophisticated and complex as modeling a conversational partner’s mental states. Instead, they think that speakers resonate to and copy each other’s linguistic expressions for reasons that are a lot like why it is that yawning is contagious, or why people subconsciously imitate each other’s body language or accent. To explain this kind of imitation, they believe that a straightforward, general-purpose priming mechanism should do the trick.
As you’ve already seen, hearers find it easier to access material that’s been recently activated in memory—either because it’s been heard a short while ago, or because it’s closely associated with something recently heard. On the other side of the conversational table, speakers also seem eager to produce material that’s highly activated in memory. The phenomenon of syntactic priming shows that speakers are more likely to recycle a recently used structure than generate a fresh one that conveys the same meaning. All of these basic priming results are simple by-products of the way that language is pulled out from memory. To Pickering and Garrod, conceptual pacts are cut from the same cloth. According to their interactive alignment model, reflexive mechanisms like priming can explain a great deal of the coordination that happens between conversational partners. When this simple mechanism fails, a handy set of interactive repair mechanisms can be called upon to fix misalignments that result in misunderstanding. Finally, more sophisticated and cognitively expensive strategies that do rely on representing the partner’s mental space are available. But for Pickering and Garrod, these are fairly rarely used, occurring as a last resort when all else fails, or in unusual situations that call for strategic mindreading efforts. This view is quite different from that of Clark and colleagues, for whom being attuned to a partner’s knowledge, beliefs, and experiences is a fundamental aspect of conversation, playing a role in just about every utterance.
|
TABLE 12.3 Sample dialogues from Garrod and Anderson, 1987, Cognition 27, 181. |
|
(A) Sample dialogue illustrating a “path” strategy |
|
Speaker A: Right from the bottom left-hand corner: above the wee purple thing: go along one and up one and that’s where I am. Speaker B: Right I’m the same only on the other side. A: I’m two along, up one now: from the bottom . . . from the left. B: I’m down one. A: Oh down one. A: Uh-huh. A: What, from where? B: One along from the right . . . I’m one along from the bottom right. |
|
(B) Sample dialogue illustrating a “coordinates” strategy |
|
Speaker A: O.K.? right—er Andy we’ve got a six by six matrix. Speaker B: Yup. A: A, B, C, D, E, F. B: 1, 2, 3, 4, 5, 6. A: Correct, I’m presently at C5 O.K. B: El. A: I have to get to A, B, B, 1. B: Bl. A: I take it you have to get to— B: No. A: D5, is that correct? B: Er—A, B, C, D, E: A, B, C, D, E. yeah. A: So you’re now at Dl are you? B: Uh-huh. A: And I’m in B5. |
|
(C) Sample dialogue featuring a “lines and boxes” strategy |
|
B: I’m on the top line, fourth box along. A: I’m on the second row, second box along. B: So I’m fourth box on the top row now. B: You’re on the bottom line second box along, Yeah. A: Uh-huh. B: The fourth box on the second row. A: Second row, first box. B: Fifth, fifth box fifth row. B: Fifth box fourth row. B: Fifth box on the second row. B: Sixth box on the fourth row. A: I’m on the second box on the fourth row. A: That’s me on the first box on the fifth row. |
There are other researchers who echo Pickering and Garrod’s claims that mind reading plays a secondary and not a primary role in conversation. For example, Boaz Keysar and various colleagues (Horton & Keysar, 1996; Kronmüller & Barr, 2007; Lin et al., 2010) have argued that all automatic processes in language take place within an egocentric frame of reference—it’s not until a later and more strategic stage of monitoring that speakers and hearers take into account perspectives other than their own. Like the interactive alignment model, Keysar’s assumption is that the fast and general egocentric mechanisms are fairly sharply separated from the slow process of reasoning about the mental states and beliefs of others. In contrast, those who think that socially based inferences are a primary, core aspect of linguistic ability often argue that these inferences can take place very quickly, are quite likely automatic, and possibly even have an innate basis or a specialized cognitive “module” devoted to them (e.g., Sperber & Wilson, 2002).
In the battle between collaborative accounts and egocentric ones, researchers have focused on two key areas where the two theories clash in their predictions:
1. The two accounts make different predictions about how quickly people will make use of information about the contents of common ground relative to information that comes directly from the linguistic code. Collaborative theorists claim that that even in the earliest moments of language production and comprehension, people show sensitivity to a partner’s perspective or knowledge state. However, egocentric theorists argue that the earliest moments of language processing are limited to automatic processes that are triggered by the linguistic code, with awareness of the partner’s perspective being integrated only at a later stage of processing.
2. The two accounts make different predictions about the degree to which the repetition of previous linguistic expressions is linked to a specific partner. Collaborative theorists claim that conceptual pacts are set up between partners who have negotiated (usually implicitly) a joint agreement to use a certain linguistic expression to fulfill some purpose. The agreement doesn’t automatically extend to a different partner, so the bias to link a previously used expression with a certain referent (or lexical entrainment, as it’s often called) shouldn’t necessarily generalize when someone interacts with a new partner. But egocentric modelers say that lexical entrainment happens because words that have been used recently or frequently are highly active in memory, making them very accessible for the production or comprehension system. This heightened accessibility holds regardless of who uttered the words, so the bias for repetition should persist even into interactions with new partners.
To test the first prediction about whether information in common ground affects the earliest moments of language processing, researchers usually rely on some version of a referential task like the one we discussed in Section 12.1, where some objects are visually blocked off from the view of one of the partners, but the other partner is able to see all of them. The question then becomes whether the partner who can see all the objects is able to immediately restrict the domain of reference to just those objects that his partner can also see, or whether he experiences some temporary interference from a possible competitor for reference in his own (privileged) perspective.
As I write this, there’s a resounding lack of consensus among researchers on this point. Some studies have presented very speedy effects of perspective-taking (e.g., Hanna & Tanenhaus, 2004; Heller et al., 2008; Nadig & Sedivy, 2002), while others have shown sluggish or very weak effects (e.g., Barr, 2008; Epley et al., 2004; Keysar et al., 2000). Arguments boil over about which methods are best suited for testing the predictions. For example, different results have turned up depending on how interactive the task is, how complex the displays are, what the natures of the stimuli are, and precisely how the data are analyzed, to name a few of the experimental details. (Mucking about in the literature on this topic is highly recommended as an exercise in how to navigate through unsettled scientific issues—see if you think the evidence is more convincing one way or the other.)
Let’s look at the second point that the egocentric versus collaborative accounts have fought over: Is lexical entrainment something that is intrinsic to interactions with a particular partner, or does it generalize more broadly as predicted by a priming account? A typical experimental setup to investigate this question involves having a research participant hear someone produce a specific phrase to refer to a certain object. There’s a short break in the experiment, after which the hearer participant either resumes interacting with the original partner or continues with a different partner. The speaker—either the original one or a new one—now refers back to the familiar object, either with the same phrase or with a different phrase.
According to the collaborative theory, subjects should expect the original partner to stick to the conceptual pact and re-use the same phrase in referring to the object. So, the old phrase should be easier to understand than the new phrase when spoken by the original speaker. On the other hand, the hearer should have no special expectations for how a new partner would refer to that object, so in interacting with the new speaker, there shouldn’t be a difference in how easy the new phrase is to understand compared with the old one. Quite a different set of results is predicted by egocentric theories, since lexical entrainment between partners is seen as the result of a general priming mechanism. The mention of a specific referring phrase in the first part of the experiment should make that same phrase more accessible in the second. Therefore, the old expression should be easier to understand than the new one, regardless of who the partner is in the second part of the study.
Though the predicted patterns sound clear enough as I’ve just laid them out, in real-world research, things are a bit more subtle. For example, the researchers who argue for the collaborative approach don’t deny that general priming mechanisms do exist, and that priming might also have a noticeable effect on the comprehension results, on top of any effects of conceptual pacts. So, it wouldn’t be surprising to see that the old expression is somewhat easier with a new partner as well as with the original partner—it’s just that in comparison, the advantage should be even greater for interactions with the original partner.
Conversely, most advocates of egocentric models assume that people are able to consider mutual experiences and beliefs while using language—just that this knowledge is used strategically and slowly. So, the disagreement comes down to when in the processing stage we should see partner-specific effects. Again, papers have been published arguing in favor of both the collaborative view (Brown-Schmidt, 2009a) and the egocentric priming view (Barr & Keysar, 2002; Kronmüller & Barr, 2007), with much methodological discussion.
Complicating the picture even further is the objection that partner-specific effects could arise from pure memory-based mechanisms (for example, as argued by Horton & Gerrig, 2005). So, even if it turns out that lexical entrainment is closely linked to one partner, this doesn’t necessarily show that people are actively tracking their partner’s knowledge state, as claimed by the collaborative account. Instead, the partner-specific effect could be explained like this: the original speaker is connected in memory with the old expression, so the old expression becomes even more accessible when it’s uttered by the original speaker in the second part of the experiment than when it’s spoken by the new speaker. But this may have nothing to do with negotiating conceptual pacts or tracking the knowledge states of conversational partners. Instead, it might be a bit like the following experience: Suppose you go out for lunch with a friend and order an exotic dish. You then go for months without thinking about that specific dish, until you find yourself out once again with the same friend. Suddenly, you think about that special dish again, simply because the presence of your friend has triggered that memory. In the same way, the presence of a specific conversational partner may trigger the memory of a particular word or phrase, without there being any mind reading on your part.
A satisfying conclusion to these debates has yet to emerge. But regardless of the outcome, the sheer volume and intensity of the discussion is a testament to the importance that researchers place on the broader question: To what extent do flexible, socially attuned representations about other minds play a central role in our use of language, and to what extent can we do without them and still manage to communicate with each other?
GO TO