At roughly 12 months of age, children begin to utter their first words. After that much-celebrated milestone, they add a smattering of new words over the next several months until they have a stash of about 50 or so. And then their word learning starts to accelerate until they reach, by conservative estimates, about 60,000 words in their total vocabulary by the time they graduate from high school. This translates into about 10 new words per day.
To put this achievement into perspective, think of the tradition of learning “math facts”—memorizing the relationships between numbers and arithmetic operations, such as 2 + 5, or 4 × 7. Many kids spent weeks sweating over practice sheets, drills, and flash cards to solidly commit to memory the multiplication tables—a modest set of several dozen facts. In fact, the process was so time-consuming that it’s been abandoned by many schools in the digital age. And yet, kids seem to be able to pluck words out of the air without any effort, sometimes after hearing a word only once. (If you’re in doubt about one-shot word learning, see what happens when you inadvertently utter a swear word within earshot of a toddler.) How do children manage to do this? Presumably, the process of learning words is quite unlike learning math facts.
When you learn words as an adult in a foreign-language classroom, typically what you do is memorize vocabulary lists that are either translated into words of your first language or linked to pictures and videos describing scenes and events. You might think that parents simulate a version of this teaching environment by helpfully pointing out objects and events and describing them for their children. But when they talk to their kids, parents typically act more like conversational partners than language instructors. You rarely see parents repetitively putting objects into their children’s hands and barking out single-word statements like “Cup.” “Peas.” “Spoon.” Instead, they’re more likely to offer a running commentary, such as “Honey, don’t throw your cup on the floor,” or “Boy, do I have some delicious peas for you!” This would be a bit like having your foreign language teacher talk at you in sentences, leaving you to sort out how many words she’s uttered and what they all mean in the context. Add to that the fact that parents often talk about things that aren’t in the here and now: “Did you have a nice nap?” or “Grandma and Grandpa are coming tonight.” Or they might comment on a child’s state of mind in a way that is only very loosely related to reality: “I know you want these peas!”
Even if parents were to describe only objects and events in the immediate environment, there would still be a lot of explaining to do about exactly how kids make the connections between the stream of sounds they hear and their interpretation of the scenes that these sounds accompany. Researchers of language development like to describe the child’s task of mapping utterances onto meanings by invoking a famous example from the philosopher Willard Quine. In his example, an anthropologist is trying to characterize the language of a small Indigenous tribe previously unknown to Western scientists by noting the relationship between what speakers say and the contexts in which they say it (which also seems like a reasonable strategy for word learning by children). When a rabbit scurries by, a tribesman points to it and exclaims, “Gavagai!” The anthropologist might then assume that gavagai corresponds to the English word rabbit. But how can he be sure? It might also mean any one of the following: “There goes a rabbit,” “I see a rabbit,” “That thing’s a pesky varmint,” “white,” “furry,” “hopping,” “lunch,” “rabbit parts,” “a mammal,” “a living thing,” “a thing that’s good to eat,” or “a thing that’s either good to eat or useful for its skin.” Or, for that matter, the tribesman may not be commenting on anything to do with the rabbit; he might be pointing out the lovely color of the newly sprung leaves on the trees, or the fact that the sun is about to set. The logical possibilities for choosing a meaning to go with the utterance are fairly vast.
Of course, we have the sense that not all of these logical possibilities are equally likely—for example, if the tribesman is pointing to the rabbit, it would be rather strange for him to be describing the approaching sunset, and it’s a good bet that he’d be more likely to be referring to the rabbit itself than its various parts, or some very general category of living things. But do babies know these things? We can’t assume that just because we as adults can rely on certain inferences or biases to figure out new meanings that these would also be available to your average toddler. Ultimately, the child needs to have some way of constraining the enormous space of possibilities when it comes to linking sounds with meanings. In this chapter, we’ll explore what some of these constraints might look like, and how the child might come to have them in place.
5.1 Words and Their Interface to Sound
Learning words goes beyond just figuring out which meanings to attach to bundles of sounds. Chapter 2 introduced the idea that human natural languages show duality of patterning (see Box 2.1). That is, language operates at two very general levels of combination. At one level, meaningless units of sound combine to make meaningful units (for example, words), and at the second level, meaningful units (words) combine with each other to make larger meaningful syntactic units. Words, therefore, are the pivot points between the system of sound and the system of syntactic structure. So, in addition to learning the meanings of words, children also have to learn how words interface with the sound system on the one hand and syntactic structure on the other. This chapter deals with how individual words become connected with these two distinct levels. As was the case in Chapter 4, what might intuitively feel like a straightforward learning task is anything but.
Which sounds to attach to meanings?
In learning new words, a baby’s first job is to figure out which blobs of speech, extracted from an ongoing stream of sounds, are linked to stable meanings. For example, it would be helpful to know if gavagai really consists of one word or three—and if it’s more than one, where the word breaks are. No problem, you might think, having read Chapter 4. In that chapter, you read that infants can segment units out of running speech well before their first birthday, relying on a variety of cues, including statistical regularities. So, by the time babies learn the meanings of their first words, they’ve already been busy prepackaging sounds into many individual bundles. In theory, these bundles of sound are sitting in a young child’s mental store, just waiting for meanings to be attached to them.
For example, let’s suppose that in our hypothetical language, gavagai breaks down into two words: gav agai. As seen from the experiments with artificial languages in which “words” have been completely disembodied from meanings, babies should be able to segment these units based entirely on their knowledge of sound patterns and statistical regularities in running speech. In theory, then, when trying to figure out the meaning of gavagai, they should know that they’re looking to attach meanings to the sound bundles gav and agai. If so, this would make some of the challenges of learning the meanings of words a bit more manageable.
But, once again, never take the workings of the infant mind for granted. We’ve been referring to the segmented units of speech as word units. This is convenient, because as adults we recognize that these sequences of sounds correspond to meaningful words. But babies don’t necessarily know that. Just because they can slice these units out of a continuous speech stream doesn’t mean they understand that these particular groupings of sounds are used as units for meaning. They might simply be treating them as recurring patterns of sound that clump together. This might seem odd to you, since you’re so used to thinking of speech sounds as carrying meaning. But consider this: studies of statistical learning have shown that both babies and adults can learn recurring groupings of musical tones in just the same ways that they learn word units in an artificial language. If you were a participant in such a study, you might recognize a group of tones as a recurring and cohesive bundle of sounds, without having the expectation that there’s any meaning attached to them. It’s entirely possible that for babies, this is exactly how they treat the “word” units they pull out from speech. They’ve figured out that certain sounds systematically go together, but they haven’t yet figured out what these bundles of sounds are for.
A number of researchers have suggested that something very much like this is going on in the minds of babies at the earliest stages of word learning. The idea is that they’ve gotten as far as memorizing a bunch of meaningless sound bundles, but the next phase of linking sounds with meaning is an entirely new step. When they first start linking up sounds to meanings, they don’t simply dip into their bag of stored sound sequences; rather, they start from scratch in building up brand new sound-based representations. The evidence for this argument goes as follows:
Remember that when babies segment units from speech, these units contain an exquisite amount of phonetic detail. Babies are able to attend to subtle details of sounds and make use of them as segmentation cues. But some studies have suggested that the units of sound that babies attach meaning to are much less detailed than the strings that they segment out of speech. Perhaps, then, the mental representations that result from slicing up the speech stream aren’t the same representations that underlie a child’s early meaningful words. So, let’s suppose that a baby has managed to segment the sound sequence for the word dog—that is, she has the sense that this is a non-random, recurring bundle of sounds that clump together. Her representation of this bundle of sounds might look quite different from her representation of the sounds for the meaningful symbol dog when she starts to figure out that dog refers to the furry family pet. It’s even been proposed (see, for example, Hallé and de Boysson-Bardies, 1996) that the representations that serve as containers for meaning aren’t made of strings of individual sounds at all, unlike the representations for segmented speech. Rather, they’re general and quite fuzzy holistic impressions of sounds.
This might seem like an odd proposal. After all, why would babies go to the trouble of segmenting speech into units if they weren’t going to use these units as the basis for meanings? But by now, you should be familiar with the idea that the mental representations for words might be somewhat separate from the detailed representations of the sounds that make up those same words. Back in Chapter 3, I summarized some arguments for the separation of linguistic knowledge into dorsal and ventral streams in the brain. These arguments included evidence that some patients do well on word-recognition tasks even though they struggle with basic sound-discrimination tasks; and conversely, some patients are able to make fine sound discriminations but have a hard time recognizing familiar words. This suggests there’s some potential slippage between the two systems; perhaps it takes babies some time to fully establish the connections between them.
However plausible the notion might be, though, in order to understand the sound representations onto which babies first map meanings, we need to take a close look at the mental life of these early word-learners.
Studying how children map sounds to meaning: The switch task
Our best bet for studying how babies map sounds onto meaning is through carefully designed lab studies that look at the precise conditions under which these mappings are made. One way to do this is through an association test known as the switch task. Stager and Werker (1997) used this technique to test whether children pay attention to fine details of sound in learning new object–word mappings. In this task, there’s a habituation phase in which two objects are each paired up with a novel word that is not an actual English word but obeys its phonotactic rules (for example, lif and neem; see Figure 5.1A). To learn these associations, babies watch pictures of objects one at a time, accompanied by their associated labels spoken through a loudspeaker over a number of trials during this phase. The trials are repeated until the babies show signs of habituation—that is, of having become so familiar with the stimuli that the amount of time they spend looking at the picture starts to decline. A test phase follows during which the labels and their objects are sometimes swapped, so that the object that used to be shown along with the word lif is now shown with the word neem, and vice versa. These “switched” trials are compared with “same” trials, in which the words accompany their original pictures.
If babies have linked the correct label to the picture of each object, they should register surprise when the wrong label is paired with the familiar picture; that is, they should look longer at the “switch” trials than at the “same” trials. This result is exactly what we see for babies who are 14 months of age or older—shortly after the average age at which babies gurgle their first recognizable words (Stager & Werker, 1997). Or rather, the effect shows up for two words that are very different from each other, such as lif and neem. But babies at this age don’t notice the switch if the words are very similar to each other—for example, bih and dih. Instead, they act as if these were just variants of the same word, linked to the same meaning (see Figure 5.1B). This is interesting, because in speech perception tasks that don’t require them to link meanings with sounds, infants can clearly hear the difference between /b/ and /d/. But they seem to ignore this difference when it comes to linking up sounds with simple pictures.

Figure 5.1 (A) A switch task using the highly distinct stimuli lif and neem. During the habituation phase, children heard lif paired with the visual image. In the test phase, children either heard lif again or heard a new word (neem) paired with the original visual image. In a different version of the same experiment, the highly similar sound stimuli bih and dih were used. (B) Mean looking times for 14-month-old participants. Babies readily distinguished between lif and neem, but not between bih and dih. (Adapted from Stager & Werker, 1997, Nature 388, 381.)
These results raise the possibility that babies’ representations of meaningful words don’t actually contain all the phonetic detail of the strings of sounds that they segment from speech. But why would this be? One idea is that there’s a difference between information that babies can pay attention to while processing language in the here and now, and the information they commit to long-term memory in the form of a stable lexical representation by which sound and meaning properties are recorded. The thinking might go like this: babies (and maybe adults too) are somewhat miserly about their long-term memory space, and only keep as much detail about sound in the lexical representation of a word as they need for the purpose of distinguishing that word from other words in their long-term memory. But adults and older children have large vocabularies of thousands of words, so they need a lot of sound detail to keep their lexical representations separate from one another.
For example, older individuals really need to encode the difference between /b/ and /d/ so they can distinguish between word pairs like big/dig, bean/dean, bad/Dad, bought/dot, and so on. But put yourself in the shoes of an infant who only knows a smattering of meaningful words. Take the following meager collection:
| baby | mommy | daddy |
| hat | shoe | diaper |
| yummy | milk | juice |
| spoon | bottle | blanket |
None of these words are very similar to each other, so there’s no need to clutter up lexical representations with unnecessary details. However, with time and a burgeoning vocabulary, the infant might notice not only that she needs to distinguish between words like big and dig, but also that the voicing difference between /b/ and /d/ is mighty useful for distinguishing between many other words. She would then start paying attention to voicing (see Section 4.3) as a general property that serves to signal meaning differences. When she later comes across a new word such as pill, her lexical representation would reflect the fact that its first sound is voiceless, even though she may never have heard the contrasting word bill.
This is a plausible account. But it’s not clear that babies’ failure to notice the difference between bih and dih in the switch task really reflects less detailed lexical representations. Another possible explanation is that babies are just very inefficient and prone to error when it comes to retrieving words from memory. So, they might confuse words that are similar to each other during the retrieval process, even though sound distinctions between them are actually there in their lexical representations. For example, it’s possible that they do in fact have separate lexical representations for bih and dih, but they might easily confuse them because of their similarity—just as you might mistakenly pull a bottle of dried basil out your cupboard while searching for oregano. You know they’re different herbs, but their similar appearance has momentarily confused you.
This alternative retrieval account gains support from evidence that even adults are less sensitive to detailed sound differences when they’re trying to match newly learned words with their meanings. Katherine White and her colleagues (2013) showed that when adult subjects were taught a new “language” in which made-up words were paired with abstract geometric objects, they showed a tendency to confuse novel words like blook with similar-sounding words like klook if they’d heard the word only once before. But this confusion lessened if they’d heard the novel word multiple times. These findings suggest that, like those of adults, children’s lexical representations might well be linked to rich and detailed phonetic representations, but be vulnerable to sound-based confusion when words are unfamiliar. And in fact, 14-month-olds seem perfectly capable of distinguishing familiar words like dog from very similar ones like bog (Fennell & Werker, 2003). Together, these two experiments argue against the notion that the sound representations that children map onto meanings are different in nature from the sound representations they segment out of running speech.
We can find even more direct evidence that the units babies pull out of the speech stream are put to good use in the process of attaching meanings to clumps of sounds. In a study led by Katharine Graf Estes (2007), 17-month-old babies first heard a 2.5-minute stream of an artificial language. Immediately after that, the babies were exposed to a novel word-learning task using the switch paradigm. The added twist was that half of the new words in the switch task corresponded to word units in the artificial language the babies had just heard. The other half were sequences of sounds that had occurred just as often in the artificial language but that straddled word boundaries (“part-words”), as seen in the experiments in Chapter 4. Babies were able to learn the associations between pictures and words, but only for the sound units that represented word units in the artificial language, showing that they were applying the results of their segmentation strategies to the problem of mapping sounds to meaning.
Results like these suggest that, indeed, very small children are able to draw on their stores of segmented units to help them in the difficult task of matching words and meanings. In other words, if you’re a baby and the transitional probabilities among sounds lead you to treat agai as a coherent and recurring clump of sounds, you might have a leg up in figuring out what is meant by “Gavagai!” All of this suggests that word learning relies heavily on the statistical experience that babies have with language. As it turns out, the amount of exposure to language that children get in their daily lives can vary quite dramatically, leading to some striking consequences for their early word learning, a notion we’ll take up in detail in Section 5.5.
5.2 Reference and Concepts
A young child’s sense that certain bundles of sound are likely to be linked to meaning is a start. Now let’s look at the other side of the equation, and which meanings a child considers to be good candidates for linguistic expression. It would be a startling child indeed whose first word turned out to be stockbroker or mitochondria, even if her parents held down jobs as financial analyst and genetics researcher and uttered such words on a daily basis at home. It’s simply implausible that these concepts would be part of a toddler’s mental repertoire. These are complex notions that are probably impossible to grasp without the benefit of some already fairly sophisticated language to explain them. Most children’s first words instead refer to tangible objects or creatures that can be experienced more directly through the senses: rabbit, bottle, milk, baby, shoe.
Words and objects
But how does a child know (or come to learn) that rabbit is more likely to be referring to the whole squirming animal than to its fur or, even more implausibly, three of its four limbs? It feels obvious to us. Our intuitions tell us that some concepts—such as whole objects—are simply more psychologically privileged than others, almost crying out to be named. But, as always, we can’t assume that what feels obvious to us would also feel obvious to a very young baby. Our own intuitions may be the result of a great deal of learning about the world and about how languages use words to describe it. (Think back, for example, to how phonemic categories that seem so deeply ingrained to us in fact had to be learned early in childhood.) Have intuitions about “obvious” candidates for word meanings been with us since babyhood, guiding our acquisition of words throughout our lives?
It would seem that they have. Many studies have shown, for example, that when babies hear a new word in the context of a salient object, they’re likely to assume that the word refers to the whole thing, and not its parts, color, or surface, the stuff it’s made of, or the action it’s involved in. Researchers often refer to this assumption as the whole-object bias in word learning. This bias doesn’t seem all that surprising when you consider the landscape of very early infant cognition. Even as young as 3 months of age, babies clearly organize the jumble of lines, colors, and textures that make up their visual world into a set of distinct objects, and they have robust expectations that objects in the world will behave in stable and predictable ways.
In one study by Philip Kellman and Elizabeth Spelke (1983), 3-month-old babies saw a screen with a stick visible at its top and another stick at the bottom. If the two sticks moved simultaneously, the babies assumed that they were joined to a single object, and they were surprised if the screen was removed to reveal two disconnected objects. (“Surprise” was measured by how long the babies stared at the scene once it was revealed.) On the other hand, if the two sticks moved separately, the babies were unfazed to find that two separate objects were hiding behind the screen. Aside from knowing that objects usually act as indivisible wholes, young babies also seem to know that objects can’t disappear at one point and reappear at another, that they can’t pass through other objects, and that inanimate objects can’t move unless they come into contact with other objects.
Given that babies can clearly parse the world into whole objects long before they can parse speech into word-like units, it would seem natural that once children figure out that words are used to refer, they then take for granted that objects are great things to refer to. At one level, this might be simply because objects are perceptually important, so when babies hear a word, they easily slap that word onto whatever happens to be most prominent in their attention. But in fact the relationship appears to go deeper. It’s not just that whole objects have a tendency to draw babies’ attention; it appears that babies have a sense of what kinds of things words attach to.
A study by George Hollich and colleagues (2007) explored whether the act of naming by an experimenter affected how babies visually examined objects and their parts. Babies age 12 and 19 months were shown objects made of two parts—a single-colored “base” piece and a more exciting, colorfully patterned piece that inserted into the base (see Figure 5.2). During a training phase, the experimenter labeled the object with a nonsense word (“Look at the modi! See the modi? It’s a modi”). The experimenter did nothing to hint at whether the word referred to the whole object or just one of its parts but did emphasize that the object came apart, by repeatedly pulling it apart and putting it back together again. Then, during the testing phase, the experimenter put the whole object and an exact copy of the colorful part on a board in front of the child and asked the child, “Where’s the modi? Can you find the modi?” Since babies reliably look longer at an object that’s been named than at other objects, it’s possible to measure looking times to infer whether the child thinks that modi refers to the whole object or to the colorful part; the child’s eye gaze should rest longer on whichever object he thinks the word refers to.
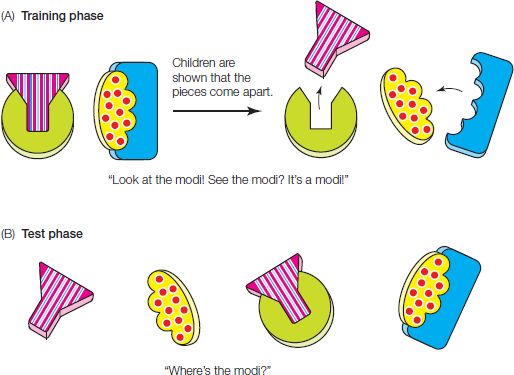
Figure 5.2 (A) Two of the novel objects used in experiments by Hollich et al. Experimenters demonstrated to young children (ages 12 and 19 months) how the objects could be separated into two parts. (B) During the test phase, children saw a display showing both the entire assembled object and the more colorful of its parts. (Adapted from Hollich et al., 2007, Dev. Psych. 43, 1051.)
The results of the study showed that babies looked longer at the whole object than at the object part, suggesting that they had taken the word modi to refer to the whole object rather than to one of its parts. But before we draw this conclusion with any certainty, we want to make sure that kids weren’t just looking at the whole object because it was more interesting or visually important, but that their eye gaze really reflected something about making a link between the object and the word modi. To check for this, during an earlier phase of the experiment, even before the experimenter labeled the object, babies’ free-ranging eye movements to the whole object and the isolated part were also measured. Before hearing the novel name, babies spent roughly the same amount of time looking at the colorful part as the whole object. So it wasn’t just that the babies found the whole object more visually compelling; it was specifically the act of naming that drew their attention to it. In other words, the whole-object bias seems to be about something more specific than just finding whole objects more interesting, and even at 12 months of age, babies have some ideas about what kinds of meanings words are likely to convey. This kind of knowledge can really help narrow down the set of possible meanings for words. Obviously, though, people do talk about parts of an object as well as the whole thing, and they can also describe an object’s color, texture, temperature, function, taste, ingredients, location, origin, the material it’s made of, or any actions or events it’s involved in. A whole-object bias might help babies break into an early vocabulary, but sticking to it too rigidly would obviously be pretty limiting. For example, researcher John MacNamara (1972) describes a scenario in which a child thought the word hot referred to the kitchen stove. (You can imagine a parent warning “Don’t touch that! It’s hot!”)
Here’s yet another example of a possible constraint on word meaning. One of these objects is called a “dopaflexinator.” Can you guess which one?

A 3-year-old would be inclined to agree with you (assuming you chose the object on the right). But why? It seems obvious: the object on the left is called a “hammer,” so there’s only one other candidate for the novel word. If your reasoning went something like this, it hints at a general bias to line up object categories and linguistic labels in a one-to-one correspondence. This expectation has been called the mutual exclusivity bias.
As with other word-learning biases, it’s possible to take mutual exclusivity too far. Hammer isn’t the only word you could use to describe the object on the left. You could also, under various conditions, call it a “tool,” a “piece of hardware,” a “weapon,” a “thingamajig,” an “artifact,” or simply an “object.” But given that hammer is by far the most common way to refer to it, the mutual exclusivity bias might be a useful way for a small child to zoom in on the likely referent for a word she doesn’t know yet, especially when the new word is spoken in the context of many objects whose names she does know.
Up to this point, we’ve discussed biases that focus on probable meanings, without showing any concern at all for the match between the word’s shape and its meaning. This seems reasonable. After all, many linguists have long assumed that the relationship between words’ shapes and meanings is arbitrary (with a few exceptions like bang, moo, or buzz), so you’d expect something like the mutual exclusivity bias to operate regardless of whether the word in question was dopaflexinator or blicket—or would you?
As linguists have looked more closely at a diverse set of languages, they’ve found that sound-meaning correspondences extend well beyond a handful of onomatopoeic words, which use the sounds of language to imitate specific noises (see Box 5.1). Many languages have a rich set of ideophones, a special class of words in which sounds are used in a more abstract way to convey sensory information such as size, texture, or certain aspects of motion. Moreover, languages tend to show systematic correlations between sound patterns and broader classes of words, such as male versus female names or nouns versus verbs. These correlations likely emerged as language-specific patterns that became amplified over time through the process of language evolution. The lack of arbitrariness is even more obvious in signed languages, where iconicity of signs is widespread (see Figure 5.3). About two-thirds of signs in a database of American Sign Language (ASL) words have been identified as showing at least a moderate degree of transparency between the shape of a sign and its meaning (Caselli et al., 2017).
Do children consider the non-arbitrary connections between forms and meanings in guessing at the meanings of new words? There is evidence that they do. For example, in a spoken-language study led by Daphne Maurer (2006), toddlers (average age 32 months) were shown various pairs of objects in which one had sharp, spiky properties and the other had blobby, rounded properties, as depicted in Figure 5.4, and were asked to identify the object that matched a novel name such as [kejki] or [buba]. Their responses were not random; more than 70 percent of the time, they chose the object that matched the sound-symbolic properties of the novel word. Adults showed even greater sensitivity to sound symbolism, at about 83 percent of sound-symbolic matches overall.

Figure 5.3 Signed languages offer many opportunities for iconicity, the visually transparent relationship between signs and the objects to which they refer. (A) Some signs incorporate typical motions involved in handling the referent; the ASL sign “hammer” mimics how one holds the object. (B, C) Signs may invoke all or part of the referent’s shape. The ASL sign “house” traces the outline of a stereotypical house (B), while the sign “cat” depicts a cat’s whiskers (C). (From Magid and Pyers, 2017, Cognition 162, 78; photos courtesy of Rachel Magid.)
Given that signed languages are shot through with iconicity, we might expect that this would provide a constraining source of information for children learning to sign. This hypothesis is supported by a study led by Robin Thompson (2012) of young learners of British Sign Language (BSL), showing that iconic signs were more heavily represented than non-iconic signs in the vocabularies of young children—though the effect was more pronounced among the older children tested (21–30 months) than the younger group (11–20 months). A more direct test of iconicity as a learning constraint comes from a study by Rachel Magid and Jennie Pyers (2017). They tested both Deaf children who were learning ASL and non-signing, hearing children on their ability to learn iconic versus non-iconic signs. They focused specifically on signs whose shape was either arbitrarily or transparently related to the shape of their referent (see Figure 5.5). Among the hearing children, 4-year-olds, but not 3-year-olds, used iconicity to their advantage: they were more likely to match an iconic sign to the referent over a non-iconic sign, and in a learning task, they were better able to remember a new sign when it was iconic. Among the Deaf children, iconicity boosted learning for both 3- and 4-year-olds, suggesting that their experience with ASL strengthened their expectation of form-meaning matches, making it more salient to them at a younger age.
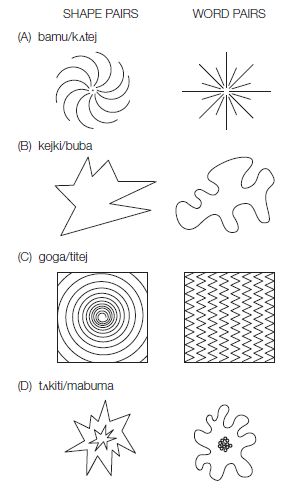
Figure 5.4 Line drawings of the pairs of shapes and accompanying choices of words used in the study by Maurer et al. (2006). The actual objects were two- or three-dimensional objects of varying media: (A) the shapes were drawn on construction paper; (B) the shapes were cut to form holes in the top of a cardboard box; (C) the shapes were drawn on separate sheets of white paper and glued onto Bristol board; (D) the shapes were made into three-dimensional objects using clay. (From Maurer et al., 2006, Dev. Sci. 9, 316.)
Categories large and small
So far, I’ve talked about object names as if they refer to specific objects, things that the child can see or touch. But that’s actually the wrong way to think about words like rabbit or bottle or blanket. These nouns don’t just apply to any particular object—they apply to the entire categories of rabbits, bottles, and blankets. It turns out that only a small subset of nouns—the ones we call proper nouns, like Dave, Betty, Marilyn Monroe, or Cleveland—refer to particular entities or individuals. And, when you think about it, language would be only very narrowly useful if words didn’t generalize beyond specific referents. We’d like to be able to talk to our kids not just about this family dog (“Honey, don’t tease the dog”), but also about dogs more generally (“Don’t get too close to a strange dog”; “Some dogs bite”; “Dogs need to go outside for walks”; and, eventually, “The dog is descended from the wolf”). Presumably, one of the huge benefits of language for humans is its ability to convey useful information that generalizes to new situations.
Mapping words onto categories is even more complex than mapping words onto specific referents. In principle, any single object could fall into an infinite number of categories. Along with categories like “dogs,” “furniture,” or “reggae music,” people could (and sometimes do) talk about categories such as “foods that give you heartburn,” “professions that pay poorly but give great satisfaction,” “things I like to do but my ex never wanted me to do,” or even “objects that broke at exactly 2 PM on March 22, 2018.” But categories like these rarely get their own words. How do children figure out which categories are most likely to have words bestowed upon them?
Just as whole objects seem to be more natural candidates for reference than their properties or their parts, we also have intuitions about which categories seem the best candidates for reference. Even if we look at just those categories that do have their own words, it becomes clear that people are inclined to talk about some kinds of categories more than others. For instance, unless you’re a dog breeder, you probably use the word dog in your daily communication much more often than you do the more specific word Dalmatian. What’s more, you probably also use it more often than the more general terms mammal and animal, even though these broader categories obviously encompass a larger number of creatures. This is generally true of categories at a mid-level degree of specificity—for example, chairs get talked about more often than recliners or furniture, and the same holds for apples versus Cortlands or fruit. These privileged midlevel categories are called basic-level categories, in contrast with the more general superordinate-level categories and the more specific subordinate-level categories.
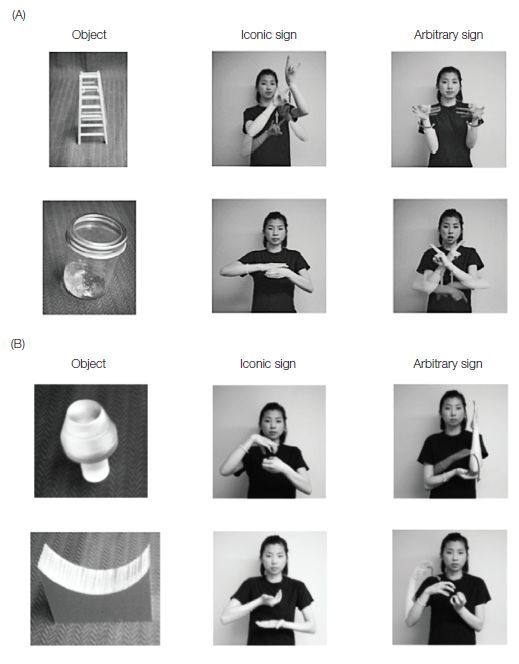
Figure 5.5 Examples of novel signs used in the study by Magid and Pyers (2017). (A) Examples of iconic and arbitrary signs for familiar objects; (B) examples of iconic and arbitrary signs for unfamiliar objects created for the purpose of the experiment. (From Magid and Pyers, 2017, Cognition 162, 78; photos courtesy of Rachel Magid.)
When you look closely at their informational value, the basic-level categories are especially useful for capturing generalities. If you know that something is a dog, you know a lot of things that are likely to be true about it: you know that it probably barks, needs exercise, eats meat, has a pack psychology, marks its territory, has sharp teeth, and so on. On the other hand, if you only know that something is an animal, the number of things you know about it is much smaller and vaguer. So, being told “Fido is a dog” allows you to infer many more things about Fido than being told “Fido is an animal.” At the same time, basic-level categories (say, dogs versus cats or birds) also tend to be fairly distinct from one another, unlike subordinate-level categories (for example, Dalmatians versus collies). Often it makes sense to talk about what the category members have in common that differentiate them from other categories. So, if you’re told “Dogs need to be walked,” this is a more useful piece of information than being told “Dalmatians need to be walked.” It may be that basic-level categories are favored by language users exactly because they strike this balance between similarity among members and distinctiveness from other categories.
In learning their early words, then, kids have to figure out how to map the words onto just the right categories, including how to hit exactly the right level of specificity. They sometimes show evidence of under-extension of category names—for example, if a child first learned the word flower in the context of referring to a carnation, she might not realize that daisies can be referred to by the same word. But you wouldn’t necessarily notice a child’s vocabulary under-extensions without some explicit probing—she might not call a daisy anything rather than use an obviously wrong word for it. Over-extension, in which a child uses a word for an inappropriately general category—for instance, referring to all animals as doggie—is more easily observed. Errors of over-extension may well be more common in children’s minds, although it’s a bit hard to tell based only on how they label things in the world.
Despite these missteps, children’s early speech (just like adult language) contains a disproportionate number of basic-level words. Is this simply because basic-level words are more common in their parents’ speech, or is it because young children are especially attuned to words in this middle layer of categories? It might be helpful to young children if they showed up at the word-learning job with some preconceptions about not just what aspects of the physical environment are most likely to be talked about (whole objects more than parts), but also what categories make for good conversation. To answer this question, we need to look at experiments that specifically probe for the links young children make between new words and their meanings.
One way to do this is with an activity slightly modified version of Web Activity 5.3, in which you had to guess the possible referents for the made-up word zav. If children see a novel word like zav used to refer to a Dalmatian, and they assume that it applies to members of the same basic-level category, they’ll also accept collies and terriers as possible referents of the word and will happily apply the word zav to these kinds of dogs as well. On the other hand, if their guesses are more conservative, they might limit their choices to only Dalmatians and reject other kinds of dogs as falling under the meaning of zav. Or, they might guess more liberally, and extend the word to apply to all animals, including cows and cats.
Several studies (e.g., Callanan et al., 1994; Xu & Tenenbaum, 2007) have found that young children are clearly reluctant to extend a new word to a broad category such as animals, as are adults. But, whereas adults seem to have fairly strong assumptions that zav extends to a basic-level category, preschoolers seem a bit more conservative, sticking more often with the subordinate-level category as the appropriate meaning of the word. However, these early assumptions about categories seem to be fairly fluid. For example, the study by Fei Xu and Josh Tenenbaum (2007) found that preschoolers became willing to shift their interpretation of a new word to a basic-level category if they’d heard just three examples of the word being applied to members of the same basic-level category. So, hearing that both a collie and a terrier could also be called a zav would lead children to assume that zav could also be used to name a poodle or a Labrador retriever, even though they’d never heard the word applied to those particular kinds of dogs. And, if they’d heard zav being used three times only in reference to a Dalmatian, they became even more convinced than they’d been at the outset that this word applied only to members within this subordinate-level category.
This study suggests that youngsters don’t necessarily match up words with the right categories the first time they hear them, but that they’re not set in their ways when it comes to their first hypotheses about word meanings. Instead, they gather evidence that either confirms or disconfirms their preliminary guesses and fine-tune these guesses accordingly. Of course, as outside observers we might never become aware of their internally shifting word meanings unless we specifically choose to test for them.
Naturally, in order to map meanings onto categories, children need to first carve the world up into the right sorts of categories, which in itself is no small feat. In fact, having immature and still-unstable categories may well explain why kids are less eager than adults to map new words onto basic-level category members. Adults may simply be more certain than young children that collies and terriers do fall into the same category as Dalmatians, but that cats and pigs don’t.
Cues for forming categories
Clearly, the process of mapping meanings onto words has to go hand in hand with the process of forming categories. So how do children learn that bananas belong in a category that excludes oranges? Or that dining room chairs, stools, and recliners all are the same kind of thing? Or that their own scribbled attempts at art have more in common with paintings hung in a museum than with splatters on the ground from accidentally spilled paint?
There’s no single cue across all these categories that obviously groups category members together. For bananas versus oranges, it might be handy to pay attention to shape. But for different examples of chairs, what really seems to matter is that people sit on them. As for pictures versus accidental paint splatters, what’s important is not so much how they look or even how people use them (a picture is still a picture even if someone can wash it off its surface), but whether someone intended to create them.
What are the essential properties that bind together the members of a category? The photographs in Figure 5.6 give you an idea of some of the challenges children face in identifying both the features that category members have in common with each other and the features that distinguish them from members of other categories. While shape seems to be an especially useful cue in the early days of word learning, children as young as age 2 are able to tune in to all of these cues—shape, function, and the creator’s intent—as a way of grouping objects into categories, paving the way for correctly naming a great variety of different categories.

Figure 5.6 Do all of these images represent category members for the words on the left? Do you have any intuitions about the kinds of features that might be easiest for very young children to attend to?
It’s easy to see that naming things accurately depends on having the right kinds of categories in place. What may be less obvious is that words themselves can serve as cues to forming categories. That is, just hearing someone name things can help children group these things into categories. An interesting line of research by Sandy Waxman and her colleagues (e.g., Waxman & Markow, 1995) reveals a very early connection in the minds of children between words and categories. The researchers used the following experimental setup: 1-year-old babies were shown several objects of the same superordinate-level category (various animals, for instance). In the key experimental condition, all of the objects were named with the same made-up word during a familiarization phase—for example, “Look at the toma! Do you see the toma?” Afterward, the babies were shown either another animal or an object from a completely different superordinate category, such as a truck. The babies tended to be less interested in the new animal than in the truck—as if thinking, “I’ve already seen one of those—show me something different!” But this novelty effect for the truck only showed up if all of the animals had been labeled with the same word. If each animal had been named with a different word, the babies paid as much attention to the new animal as the truck. But using the same word for all of the animals seems to have focused their attention on what the animals all had in common, so when they later saw another one, they were more indifferent to it.
In this version of the study, babies tuned in to the fact that when objects share a common label, this means they can be grouped into a common category. But the more general expectation that language communicates something about categories emerges at the tender age of 3 or 4 months. Alissa Ferry and colleagues (2010) found that after the familiarization phase, these tiny infants paid attention differently to objects of the same category than they did to objects of a completely new category, as the 1-year-olds did in the earlier study. But they did this only when the objects were accompanied by a phrase, such as “Look at the toma! Do you see the toma?” When the same objects were accompanied by a musical tone instead, the babies didn’t seem inclined to group the objects into categories.
Remember: at this age, babies haven’t managed to segment words out of the speech stream yet. So it seems that well before they produce their first word, or possibly even pull out their first word-like unit from a torrent of speech, babies have the preconception that words are useful for talking about object categories. Happily, then, infants aren’t left to flounder around among all the meanings that words might theoretically convey. Once they begin learning the meanings of words, they can rely on certain built-in expectations about which meanings are the best candidates for newly encountered words.
There’s still some debate among researchers about the exact nature of some of these expectations. Are they innate? Are they specific to language? That is, expectations that act as constraints on word learning could amount to default assumptions that specifically link words to certain meanings. Alternatively, they could be side effects of other kinds of cognitive and perceptual mechanisms that tend to organize the world in certain ways. For example, novice word learners often extend names on the basis of the shapes of objects. If they hear someone use the word zav to refer to a red ball and then they are asked whether zav also refers to an orange or to a red hat, they’ll choose the object of the same shape (the orange) over the other object that has the same color as the original zav (see, e.g., Landau et al., 1988). Is this because there is a specific word-learning bias that directs them to equate shape with object labels? Or is it simply that they’ve figured out that shape is a more reliable cue than color for deciding which category the object falls into? (After all, grapes, apples, and shirts all come in different colors, so it’s best to pay attention to their shapes in figuring out what kind of objects they are.)
We don’t always know why young children make the assumptions they do about the alignment of words and meanings, but it’s become clear that at various points in their early word learning, children have a whole repertoire of ways in which to constrain their possible hypotheses about word meanings.
5.3 Understanding Speakers’ Intentions
So far, we’ve looked at two aspects of word learning: (1) the sound sequences that are the bearers of meaning, and (2) the things in the world—whether objects or categories of objects—that are linked with these sound sequences. But there’s an important dimension we’ve neglected so far. I’ve been talking as if words have meanings and as if objects or categories have names. But of course, it’s not that objects have names in the same way that they have certain shapes, colors, or textures. It’s that people use certain names to refer to these objects. As discussed in Chapter 2, word meanings are a fundamentally social phenomenon. As members of a particular linguistic community, we’ve entered into an implicit social agreement to use certain words to describe certain concepts—much like we’ve agreed to use paper money with certain markings, or numbers electronically associated with a specific bank account, as proxies for things of value that can be exchanged for other things like food or cars.
Associations versus intentions
As adults, we recognize that linguistic labels aren’t inherently associated with objects or categories, and that they’re social constructs rather than properties of the natural world. When we interact with someone, we understand that their use of a word isn’t automatically triggered by the presence of a certain object, but rather that the other person is using the word to communicate some intentional message involving that object. But how prominently does this understanding figure in a child’s early word learning? Do very young children have the same understanding of the social underpinnings of language, knowing that names are used by speakers with the intent to refer? And if they do, does this understanding help guide the process of learning what words mean? Or do they simply create associative links between words and objects without concern for what’s in the mind of the speaker?
It takes children quite a while to behave like adults in terms of their ability to fully appreciate the contents of another person’s mind. For example, if you’ve ever played hide-and-seek with a toddler, you probably discovered that he can fall prey to the charming delusion that if he can’t see you, you can’t see him—as long as his face and eyes are covered, he may be unconcerned that the rest of his body is in plain view. And, until about age 4, children have a hard time thoroughly understanding that something that they know could be unknown to another person. (In Chapter 12 we’ll explore in more detail some of the ways in which children fail to take the perspective of others.)
Given that babies begin the process of word learning long before they have a complete sense of people’s states of mind, it could be that their early word learning is associative in nature, and that it’s only over time that they begin to treat language as the social construct that it is, reasoning about speakers’ communicative motives and intentions. So you might think of a child’s early word learning as similar to the associations learned by Pavlov’s dogs in the famous classical conditioning experiments in which a bell was rung every time dinner was served. The end result was that the dogs eventually began to salivate whenever a bell was rung, even if dinner wasn’t forthcoming. It’s rather doubtful that the dogs went through a process of reasoning that the bell was intentionally being rung by the human experimenter with the specific purpose of communicating that dinner was on its way. More likely, they just paired the two events—bell ringing and dinner—together in their minds. This kind of simple-minded associative learning is well within the learning capacities of animals with far less intelligence than dogs. So it stands to reason that as a learning mechanism, it would be readily available to infants in the early days of vocabulary mastery.
All of which makes it really interesting to consider the experimental results of Dare Baldwin and her colleagues (1996), in which young children failed to learn the meanings of words on the basis of paired association between an object and a particular word. In this study, 15- to 20-month-old toddlers were left in a room with a novel object. While they played with it, and were therefore obviously focusing their attention on the object, they heard a disembodied voice intone “Dawnoo! There’s a dawnoo!” over a set of loudspeakers. But they didn’t end up learning that dawnoo was the name for the object they were playing with. Since it’s been well documented that kids can learn the meaning of a word after a single exposure, what gives? This seems to be the perfect scenario in which rapt attention to a single object is paired with hearing a single common noun—in other words, just the scenario in which an associative mechanism should produce results in word learning.
The trouble was, the researchers argued, that children don’t learn words like Pavlov’s dogs. Even when they’re extremely young, they understand that language is rooted in highly social behavior. And there was nothing in this situation that clearly signaled to the babies that anyone was actually intending to use the word dawnoo to refer to that object. Without this evidence, the infants weren’t willing to attach the word dawnoo to the object right in front of them merely because they heard the name simultaneously with focusing their attention on the object. Essentially, the kids were treating the simultaneous utterance of the word as a coincidence.
In other studies, Dare Baldwin (1993) demonstrated that when there was clear evidence of a speaker’s intent to refer, young children were able to map the right word onto an object even if when they heard the word, they were paying attention to a different object than the one intended. For instance, in one study, 18-month-old infants played with toys on a tabletop, and while they were absorbed with a toy, the experimenter would utter, “It’s a modi!” The infants would look up at the speaker, only to find that her attention was focused on a different object, at which point they would direct their own attention to this new object. When later asked to “find the modi,” they’d be more likely to choose the thing that the experimenter had been looking at than the toy they themselves had been playing with at the time they’d heard the word.
Social cues modulate word learning
By 2 years of age, toddlers can put together some pretty subtle clues about a speaker’s referential intent in order to figure out what words are likely to mean. In a clever study by Michael Tomasello and Michelle Barton (1994), an experimenter suggested to the child, “Let’s find the toma. Where’s the toma?” The experimenter then proceeded to look inside five buckets in a row. For all but one of the buckets, he lifted an object out of the bucket, scowled, and put it back. One object elicited an excited “Ah!” before the experimenter put it back inside its bucket. For the most part, children guessed that toma referred to the object that seemed to satisfy the experimenter. In fact, when children’s word learning in this condition was compared with a different condition in which the experimenter showed only one object to the child while uttering a satisfied “Ah,” there was no difference in performance. The children had no trouble rejecting the other objects as possible referents, based solely on the reactions of the experimenter.
Such studies suggest that very young children make subtle inferences about which word/meaning pairs are intended by the speaker. Children also look askance at word/meaning pairs that are produced by speakers who obviously intend them but whose labeling behavior has been demonstrably bizarre in the past. For instance, Melissa Koenig and Amanda Woodward (2010) had 2-year-olds interact with speakers who labeled various familiar objects. When a speaker named three familiar objects inaccurately (for example, calling a shoe a “duck”), the children were more reluctant to learn a new word (for example, blicket) that he applied to a novel object than when the speaker behaved normally, giving all the familiar objects their conventional names (see Researchers at Work 5.1 for details).
It’s clear, then, that even at a very young age, small kids don’t just link words together with objects that happen to be in their attention when they hear the word. But associative learning mechanisms are extremely powerful, and it seems far-fetched that children would be totally unable or unwilling to use them in the process of learning the meanings of words. What’s more plausible is that on their own, associations are taken to be weakish evidence of word meanings, in the absence of direct evidence of referential intent by a speaker (see Method 5.1). Barring clear signs of the speaker’s intent, children may need to hear multiple pairings before settling on the meaning of a word, or they may have a much more fragile memory trace of the word. And solid evidence of a competent speaker’s intent may trump associative processes when the two are in conflict.
This story would suggest that words could still be learned to some extent if, for some reason, kids didn’t have a deep appreciation of the fact that words are used by speakers to satisfy a communicative goal, or if they lacked the ability to make inferences about what those goals are. And this seems to be largely true for children with autism spectrum disorder (ASD), a neurological condition that impairs the ability to coordinate attention with another person or to make inferences about someone else’s state of mind. Autism researcher Simon Baron-Cohen teamed up with Dare Baldwin and Mary Crowson (1997) to replicate Baldwin’s experiments in which the speaker uttered a word while looking at a different object than the one the child was gazing at. The researchers found dramatically different results between typical kids and kids with autism. The children with autism did end up mapping novel words onto object referents—but they mostly assumed that the word referred to the object that they themselves were looking at, rather than the one the experimenter was looking at. It’s easy to see how a failure to check what the speaker meant to be talking about could lead to some instability in word meanings. For example, if you happened to be looking at a duck the first time you heard someone say, “Look at the bicycle”; at the lint between your toes the second time you hear the word bicycle; and then, finally, at the correct object the third time, you would have some confusion sorting out the meaning of bicycle. It’s not surprising, then, that many children with ASD have some significant language impairment. Evidence of speaker intent can serve as a powerful filter on the range of possible word meanings.
5.4 Parts of Speech
Reading the previous sections of this chapter, a person could easily come to believe that learning the meanings of words boils down to learning all the object categories that happen to have names. But language also has a healthy assortment of words with very different kinds of meanings. For instance, how many words in the following sentence actually map onto an object category?
Mommy will cook some tasty porridge in a pot.
The answer is, one. The word pot is a well-behaved, basic-level category term. But Mommy refers to a specific individual, not a category; cook denotes an action; porridge picks out some stuff, rather than a whole object; tasty refers to a property; and in signals a spatial relationship. Not to mention nebulous words like will, some, and a, which don’t easily map onto anything in the world at all but communicate much more abstract notions.
The word-learning biases we’ve discussed so far seem best geared to learning meanings that are captured by common nouns like pot. And nouns do in fact make up the lion’s share of the very early vocabulary of toddlers across different cultures and languages. But how would a small child go about learning all the other kinds of words?
Verbs and other learning problems
The “not a noun” problem is especially acute for words whose meanings are not transparent from the immediate context. Verbs in particular pose some prickly challenges. Imagine being a child at your own birthday party and hearing your parent say, “Look! Grandma brought you a present! Why don’t you open your present? Here, let me help you.” If you didn’t already know what brought, open, and help mean, it would be a bit tricky to figure it out just from this context. Brought refers to something that happened in the past, rather than the here and now; no act of opening has happened yet; and even if your parent is in the act of helping while uttering the word help, how do you know that the word isn’t referring to a much more specific kind of action, such as handing or holding something, or getting scissors or undoing tape?
A study led by Jane Gillette (1999) starkly demonstrates the difficulties of learning verbs from non-linguistic context. The researchers tested college undergraduates’ ability to infer the meanings of words from the visual context, reasoning that college students should be at least as good at the task as your average toddler. They tested the students’ ability to guess the meanings of nouns and verbs based on a series of video clips of parents interacting with their toddlers while manipulating objects and talking about them. The sound had been removed from the video clips, but a beep indicated where in the speech stream a target word had appeared. The videos contained the 24 most frequent nouns and verbs that the parents had used in interacting with their children—words like ball, hat, put, and stand rather than unfairly difficult words like predator or contemplate. For each target word, the students saw six different videos and had to guess which word had been used in each of the six videos, the idea being that they should be able to notice what all six videos had in common and figure out the meaning of the target word accordingly.
It doesn’t sound like it should be an onerous task, especially for intelligent adults endowed with full conceptual knowledge of the world. And when it came to the nouns, the students did reasonably well, guessing correctly 45 percent of the words. But their performance on verbs was dismal, at a mere 15 percent. Some common words like love, make, or think were never guessed correctly. What was missing from these videos was the linguistic context that accompanied the words. And this turns out to be especially informative when it comes to identifying the meanings of verbs.
First of all, most verbs come with handy suffixes attached that let you know that they are verbs—as in licking or kicked. This might give you a clue that the word probably depicts an action rather than an object or a property. But more than this, the sentence frame also provides some important information. Think about the events being described by each of the following sentences:
Sarah is glorping.
Sarah is glorping Ben.
Sarah glorped the ball from Ben.
Sarah glorped Cindy to Ben.
Sarah will glorp to Toronto.
The different sentence frames dramatically constrain the meaning of the word glorp. This is because verbs come specified for argument structures: syntactic frames that provide information about how many objects or participants are involved in each event, and what kind of objects or participants are involved. For instance, an intransitive verb such as sleep or sneeze has only one participant (“Sarah is glorping”). A transitive verb such as kick has two—the actor, and the object of the action “Sarah is glorping Ben”). And a ditransitive verb such as take involves three participants—the actor, the object, and a third participant, typically introduced by a preposition (“Sarah glorped the ball from Ben”). So you can infer something about the kind of verb you’re dealing with just by noticing how many noun phrases surround it, and you can tell even more by the nature of those noun phrases. In the preceding example, you can tell that glorp to Toronto probably involves some kind of verb of motion.
Children use syntax to constrain meaning
Having access to the syntactic context of a new word would make the word-learning task much less daunting. The question is: Can very small children benefit from this potentially useful information?
The answer appears to be yes. For example, Letitia Naigles (1990) showed 2-year-olds videos in which a duck repeatedly pushed a rabbit into a bending position while both the duck and rabbit waved their arms around. The videos were intentionally designed to include two salient actions: arm waving and pushing. Some children heard the video described as “the duck is gorping the bunny.” Others heard “the duck and the bunny are gorping.” Both groups were then shown two new videos—one of the duck and rabbit waving their arms, with no pushing, and the other with the duck pushing the rabbit, but no arm waving. They were asked, “Find gorping.” The toddlers looked longer at the pushing scene when gorp had occurred as a transitive verb (The duck is gorping the bunny). But when they’d previously heard an intransitive frame (The duck and the bunny are gorping), they looked longer at the arm-waving scene. These differences suggest they had interpreted the meaning of the verb from its linguistic context.
Verbs are especially rich in syntactic information, but other categories of words also come with useful markers that can help narrow down their meanings. For instance, take the nonsense sentence Dobby will fep some daxy modi in the nazzer. There’s a lot you can infer about the made-up words in this sentence based on syntactic cues alone. You know that Dobby is the name of someone or something specific; you know that fep is likely an action; that daxy probably refers to a property of modi; that modi is a substance, rather than an object; and that nazzer refers to a category of object.

Figure 5.8 Visual stimuli accompanying Gelman and Markman’s novel word-learning test. When children were asked, “Show me the fep one,” they were most likely to choose the object in the upper right corner. When asked, “Show me the fep,” they were most likely to pick the one in the lower left. (From Gelman & Markman, 1985, J. Child Lang. 12, 125.)
Babies begin to pay attention to these cues quite early in their word-learning careers. For example, in Section 5.2, we found that 3- to 4-month-olds form categories more readily when pictures are accompanied by language than by musical tones. At that age, the instinct to categorize seems to be triggered by any kind of linguistic material, regardless of its content. But by 13 or 14 months of age, they begin to expect that words that appear to have the shape of nouns (“These are blickets”) but not words that sound like adjectives (“These are blickish”) are used to refer to categories (Booth & Waxman, 2009). By 2 years of age, they can differentiate between common nouns (“This is a zav”) and proper names (“This is Zav”) based on their syntax alone, knowing that proper names refer to specific individuals while common nouns refer to kinds of objects or individuals (Katz et al., 1974). Around the same age, when seeing a substance piled up on the table, children assume that if a speaker uses a mass noun to describe it (“This is some fep”), she’s referring to the substance, but if she uses a count noun (“This is a fep”), she’s talking about the pile itself (Soja, 1992). By 3 or 4 years of age, kids infer that adjectives are used to communicate properties of objects; they are especially good at recognizing adjectives that highlight some sort of contrast between objects—for example, a word used to distinguish a large object from a smaller one of the same kind (Gelman & Markman, 1985; see Figure 5.8).
It’s clear, then, that the syntactic identities of words can help children narrow in on those aspects of meaning that the words are likely to convey, a phenomenon known as syntactic bootstrapping. Of course, this raises the question of how kids learn about syntactic categories in the first place, an issue we’ll take up in the next chapter.
5.5 The Role of Language Input
How much language does a child need to hear (or see)? Is there such a thing as an inadequate linguistic “diet”? In a well-known study published in 1995, researchers Todd Risley and Betty Hart found that there were massive differences in the amount of speech that children heard in their homes; the average number of parental words directed at the babies ranged from 200 to 3,000 words per hour. The quantity of language input was strongly correlated with the size of the children’s vocabulary (Hart & Risley, 1995).
Inequalities
An especially troubling finding of Hart and Risley’s study was that kids from the poorest families generally heard much less speech than children from more economically privileged homes, and were significantly behind in their vocabulary growth as well (see Figure 5.9). The authors of the study estimated that by age 3, lower-income kids would have heard an average of 30 million fewer words than their wealthier counterparts—and had a productive vocabulary only half the size to show for it. This finding, which has come to be popularly known as the “30-million-word gap,” has raised a good deal of concern because it appears to be related to deep linguistic disparities that crop up in a number of countries, as thoroughly discussed in a review article by Amy Pace and her colleagues (2017). For example, a 15-month lag in vocabulary was documented among lower-income 5-year-olds in both the United States and the United Kingdom, and an 8-month lag was found in Australia. Disparities at this stage of development typically snowball into differences in the ability to produce and understand complex sentences, and eventually, gaps in literacy skills—in fact, the size of a child’s vocabulary upon entering school is a good predictor of how easily he’ll learn to read. According to a sobering report published in 2013 by the Annie E. Casey Foundation, 80% of American children from low-income families could not read proficiently by the end of the third grade. Ultimately, low socioeconomic status (SES) is correlated with lower performance on various measures of language production and comprehension from infancy through high school.
The study by Hart and Risley focused attention on socioeconomic differences, but the broader lesson is the relationship between language input and the child’s word-learning trajectory. There is tremendous variation in the richness of the linguistic environment among low-SES families, and children in households with a rich language environment have better language outcomes, regardless of family income or education level. And in some cases, reduced linguistic input has little to do with socioeconomic factors, as is true for deaf children who are born to hearing parents. Such kids are at a disadvantage relative to deaf children who are born to deaf parents because deaf parents typically already know how to sign, whereas hearing parents don’t usually start learning a signed language until after their child’s deafness is detected. As novices, the quality of their signing is generally much poorer than that of deaf parents. And, significantly, they are often their child’s only source of language input in the early years, because hearing families are usually not well integrated within a Deaf community with a variety of adults and older children who already sign. These disparities in language input have noticeable repercussions; for instance, Jenny Lu and Anna Jones (2016) found that hearing parents of deaf kids produced fewer signs and that the signs they did produce had less variety of handshapes, factors that were reflected in the children’s vocabularies.
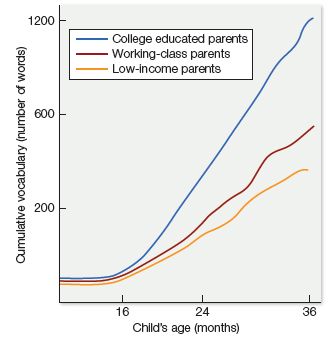
Figure 5.9 Hart and Risley’s data show that disparities emerge very early in life among children living with college-educated professional parents, working-class parents, and low-income parents living on welfare. (Adapted from Hart & Risley, 1995, Meaningful differences in the everyday experience of young American children.)
Discovery of the importance of language input—and its connection to SES—has led to some recent intervention programs that provide lower-income parents with information about the connection between input and language development, and offer quantitative feedback about how much they talk to their children. (More information about these programs is provided on this textbook’s accompanying website.) But as ongoing research fine-tunes our knowledge about the effects of linguistic input, it’s becoming apparent that the quality of the input—and not just the sheer quantity—affects how children learn new words.
What does high-quality input look like?
If you observe interactions within a large and talkative family, you may notice that the way in which older family members talk to babies and toddlers is almost always quite different from the language they use with each other. Speech directed at young kids is often slower, uses shorter and simpler sentences, has more repetition, is more animated with “swoopier” intonation, and is more focused on objects that are in joint attention. Is any of this helpful to little ones who are building their vocabularies? Or do toddlers benefit from any language in the ambient environment?
To answer this question, Laura Schneidman and her colleagues (2013) recorded samples of language produced in families where the toddler spent most days in a household with multiple older speakers as well as in families where the toddler spent the day with a single caregiver. The number of words directed at 2-and-a-half-year-old children predicted their vocabulary size at age three and a half. However, the overall number of words the children heard did not, suggesting that the additional speech overheard by children in multiple-speaker households provided no additional benefit for word learning. So it’s important to speak to your child—and no, plunking her in front of the TV is not likely to lead to a robust vocabulary.
But which aspects of child-directed speech appear to be important? After all, your observations of family interactions may also lead you to notice that some people talk to toddlers very differently than other people do. Do some speakers produce more helpful input than others? There’s good reason to think so, as certain aspects of language input are especially predictive of vocabulary growth. One of these is the contingency of the caregiver’s response to the child—that is, whether the response is related to the words or actions of a child, and whether its timing is fluidly connected to the child’s action (e.g., Hirsh-Pasek et al., 2015; Tamis-LeMonda et al., 1998). A contingent response to a child squealing and throwing her spoon at breakfast might be: “Whoa! You’re gonna need that spoon!” uttered as the spoon hits the ground. A non-contingent response might be: “You’d better finish your breakfast or you’ll be late for day care,” uttered a few moments after the spoon is retrieved.
Another important factor is the referential transparency of language input—that is, the extent to which words are connected in an obvious way to objects that are in joint attention. In a study led by Erica Cartmill (2013), videos of 50 parents interacting with their children (aged 14–18 months) were evaluated using the same method as described for the study by Gillette and her colleagues: that is, adult subjects had to guess the target word for randomly selected clips in which the audio track was removed and the target word was replaced by a bleep. On average, subjects were able to guess 22 percent of the target words—but this varied wildly for individual parents, with scores between 5 and 38 percent. The researchers found that individual parents’ scores predicted their child’s vocabulary 3 years later. The sheer quantity of input predicted vocabulary as well, but the authors argued that this was simply because more speech created more opportunities for high-quality interactions; when this was accounted for, quantity alone did not seem to add any extra benefit.
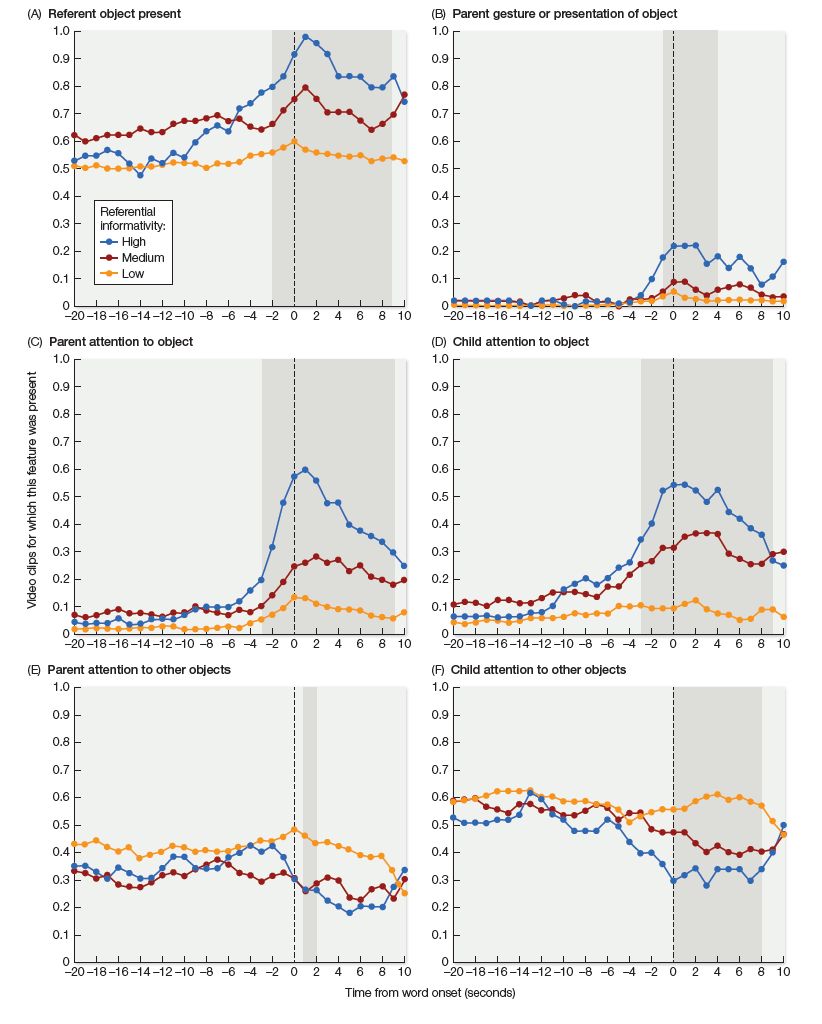
Figure 5.10 The level of referential transparency—the extent to which target words are connected to objects that are in joint attention—was evaluated in videos of parents interacting with their children ages 14–18 months. The graphs track the interactions from 20 s before the onset of the target word (at time 0) to 10 s after the target word. Shaded areas indicate periods during which the presence or absence of each of six indicated features reliably predicted the adult participants’ ability to correctly guess the target word. (From Trueswell et al., 2016, Cognition 148, 117.)
In a follow-up study from the same lab (Trueswell et al., 2016), the researchers analyzed the same videotapes to pin down exactly which aspects of the parent–child interaction made the target words easy or hard to guess. They found a number of features were evident in the video clips that scored high on referential transparency (see Figure 5.10). These features included the presence of the object to which the target word referred in the immediate environment (Figure 5.10A); the parent presented or gestured at the referent object (Figure 5.10B); participants were visually oriented to the referent object prior to the target word being uttered (Figure 5.10C,D). Referential transparency was lower when parent and child were visually oriented to other objects in the environment around the time the target word was uttered (Figure 5.10E,F). Based on these studies, the authors suggest that a small number of high-quality interactions is responsible for much of the early word learning of small children, and that the number of such interactions available to children depends heavily on their parents’ style of interacting with them.
As children move beyond the earliest stages of word learning, their vocabulary growth becomes less dependent on their immediate visual context, and they can glean word meanings based on their linguistic context, as discussed in Section 5.4. Some researchers have argued that children can get useful information of this type from overheard speech. In one study (Arunachalam, 2013), 2-year-olds watched a silent animated video or played with a toy as various sentences were piped in over a loudspeaker. All of the sentences had a novel verb (lorp), but some of the toddlers heard the verb only in transitive frames (The girl wants to lorp the teacher; Mommy lorped the train), whereas the other half heard lorp only in intransitive frames (The girl and the teacher want to lorp; Mommy and the train lorped). In a later test phase, the children were asked, “Where’s lorping?” as two videos played simultaneously side by side; one of these showed one girl tapping another girl on the shoulder, and the other video showed two girls waving. The kids who had heard the transitive frames were more likely to stare at the tapping video, whereas the other group looked longer at the waving video. The children were able to infer something about the verb’s meaning even though the piped-in sentences were not contingent on the children’s actions and were not accompanied by any referential cues. However, these sentences did contain certain child-friendly qualities: they tended to be fairly short, used common nouns that would be familiar to 2-year-olds, and repeated the verb lorp in a sequence of sentences that used a variety of transitive or intransitive frames.
To help children learn from linguistic context, it’s important to expose them to a rich variety of words and sentence structures. Janellen Huttenlocher and her colleagues (2010) found that linguistic variety in parental speech, as measured by the number of different words and combinations of clauses, partially explained the associations between SES and children’s vocabulary size and the complexity of the sentences they produced. These differences in parental input across SES groups are most likely exacerbated by another common rift between lower-income and higher-income kids: the quantity and quality of children’s books that are available in the homes and schools of lower- versus higher-income kids, and the extent to which young children are read to in these different environments. Books really do matter, because written language is more varied than spoken language, a difference that shows up even in children’s books. For example, when researchers analyzed 100 picture books written for children aged 0 to 60 months, they found that the books contained 1.72 times more unique words than comparable amounts of speech directed at children of the same age (Montag et al., 2015).
Input meets the developing mind
Suppose you’re in week 1 of learning Cree. Your instructor randomly sorts you and your classmates into two groups, one of which will hear a richer variety of words and structures than the other over the next few weeks. At this stage of learning, you wouldn’t expect the difference in input to have much of an effect—the more privileged group is unlikely to be able to use the enriched input, not having any Cree as a foundation to build on. But in 6 months’ time, the same sorting could have a much bigger impact. This is because learning is less directly related to linguistic input—the language present in the environment—than it is to linguistic intake—that is, linguistic information that is successfully processed and internalized by the child.
Language begets language. As children gain linguistic skill and knowledge, their ability to suck greater amounts of information from the same input grows. Children who can readily segment words out of a speech stream will learn new words more easily than those whose segmentation skills are shaky. A constraint such as mutual exclusivity is more useful for a child with a significant vocabulary than one with very few words. And you can’t syntactically bootstrap your way into the meanings of words if you don’t know enough about the syntactic structure of your language or can’t process syntactic information quickly enough to use it on the spot.
The development of such skills and knowledge depends heavily on experience, which means that children who are exposed to better input quickly develop the capacity for more effective intake. If this heightened capacity is then combined with continued exposure to better input, it’s easy to see how their advantage might grow over time. It would be as if your Cree instructor decided to identify the most advanced learners in your class and decide to give them an enriched environment, hardly a recipe for equity. (At this point, you may be wondering whether getting input from more than one language at a time counts as enriched input or watered-down input; see Box 5.2 for a discussion of this question.)
Research by Adriana Weisleder and Anne Fernald (2013) explores the effects of impoverished input on the development of language skills that are important for word learning. All of the (Spanish-speaking) families in their study came from low SES households, but as in other studies, the amount of speech directed at their 19-month-old child varied dramatically, ranging between 670 and 12,000 words in a one-day sample. (This is almost as large a difference as the one found between the lowest and highest SES groups in the earlier Hart and Risley study.) The children’s vocabulary was assessed at 24 months, and the toddlers were also evaluated for how efficiently they recognized familiar words. This was done by tracking their eye movements as they heard sentences that contained familiar words such as el perro (dog) or la manzana (apple). Kids who heard a large amount of child-directed speech were faster to look at a picture that matched the spoken word than those who were exposed to smaller quantities of input, in addition to having larger vocabularies (see Figure 5.11). This processing advantage for high-input kids was found even among children whose vocabularies were no larger than low-input kids. And a statistical analysis showed that the connection between input and vocabulary size was partly explained by the speed with which children identified the referents of familiar words, suggesting that processing efficiency played a causal role in word learning. (In line with other studies discussed earlier, the relationship between processing efficiency and input only held for child-directed speech—the quantity of overheard speech was not found to be related to processing efficiency). If, at this point in time, all of the children in the study were provided with equally rich input, the kids who came from low-input households would not benefit as much or as quickly from the same input—how long it would take for their processing skills to catch up is not yet known.
Figure 5.11 Average proportion of time spent looking at the correct image, with the onset of the target noun aligned with 0. In the example provided, perro (dog) is the target noun, embedded in the sentence Mira el perro (“Look at the dog”). The dashed vertical line represents the average offset of the target noun. Infants in high-input households (the blue line) identified the target referent more often and more quickly than infants from low-input households (the red line). (From Weisleder & Fernald, 2013, Psych. Sci. 24, 2143.)
5.6 Complex Words
So far, I’ve been talking about words as if they were the Lego blocks of language—the smallest meaningful parts that speakers can snap together in an endless array of new structures. But this isn’t completely correct. Some words are made up of more than one piece of meaning and can themselves be broken down into smaller blocks.
Some assembly required
Each of the words in Table 5.1 can be split apart into smaller meaningful units. All are made of at least two parts whose meanings contribute something to the meaning of the whole (and three and four parts, respectively, in the case of unchewable and lifeboat salesgirl). When you get down to the pieces that can’t be broken down any further, you’re dealing with morphemes—the smallest bundles of sound that can be related to some systematic meaning. It’s obvious, for example, that housewife has something to do with houses and something to do with wives, but if you take just a part of the morpheme house—say, hou—it’s equally obvious that this set of sounds doesn’t contribute anything specific to the meaning of the word.
|
(A) Compounding |
(B) Derivational affixes |
(C) Inflectional affixesa |
|
housewife |
preview |
drinking |
|
blue-blood |
un-chewable |
kicked |
|
girlfriend |
owner |
cats |
|
lifeboat salesgirl |
redness |
eats |
aIn English, only suffixes are inflectional, there are no inflectional prefixes (see p. 193).
Many words, like rabbit or red, are made up of a single morpheme, so it’s been convenient to talk about words as the smallest units of meaning. But it’s quite possible to stack morphemes up on top of one another to create towering verbal confections such as:
antidisestablishmentarianism position announcement
(If you’re wondering why I’m treating lifeboat salesgirl or antidisestablishmentarianism position announcement as single words when anyone can see that there are spaces that separate some of the morphemes, you can spend some time with Web Activity 5.6.) So rather than saying that children learn the meanings of words, it would be more accurate to say that children have to learn the meanings of morphemes—whether these stand alone as words or whether they get joined together. Part of the process of learning words, then, is learning how morphemes can be assembled into complex words.
In English, there are three main options for building complex words out of multiple morphemes. The first of these involves compounding, as illustrated in the examples under (A) in Table 5.1. The process is essentially to glue together two independent words (for example, house and wife) into one unit so that the new unit acts as a single word.
The complex words in parts (B) and (C) of the table are built with the use of affixes—that is, linguistic units that can’t stand on their own but have predictable meanings when attached to a stem morpheme such as own, pink, or cat. In English, we’re limited to prefixes that attach at the front end of a word (such as un-), and suffixes (like -able and -ed) that go on the back end. Some languages can shoehorn infixes right into the middle of a stem morpheme. For example, in English, we express the infinitive form of a verb like write by adding the word to, as in She wants to write. But in Tagalog, to express the infinitive form, you split your verb stem for write, which is sulat, and you wind up with the two parts of the word straddling the infix -um-: sumulat. Likewise, bili (“buy”) becomes bumili (“to buy”).
Although both (B) and (C) in Table 5.1 show examples of forming new words through affixation, there are some important differences. The affixes in (B) are called derivational affixes, while those in (C) are given the name inflectional affixes. You might have noticed that attaching a derivational affix to the stems in (B) often involves not just altering some aspect of meaning, but also transforming a word of one category into a word of a different category. For example, the verb own becomes the noun owner, and the adjective sad becomes the noun sadness. Often, transforming the grammatical category of a concept is a derivational morpheme’s entire reason for being, as in the following examples:
| nation-al | femin-ism | fus-ion |
| national-ize | man-hood | sens-ation |
| dual-ity | child-ish | warm-ly |
| clear-ance | sens-ory | son-ic |
| syllab-ify | cooperat-ive | acre-age |
Having such suffixes on hand can be quite convenient. It would seem a shame to have to coin a brand new morpheme—let’s say, flug—to express the concept of doing something “in a warm manner.” Derivational morphemes like-ly in warmly do a wonderful job of efficiently building a new vocabulary on the foundations of an existing one, while keeping the connections between related words nice and transparent.
Inflectional affixes (actually, in English, we only have inflectional suffixes) have a different flavor. Their job is not so much to create new words by mooching off existing ones. Rather, you might think of them as grammatical reflexes or markers. For example, you can’t say I ate three juicy pear or The pear are ripe; you have to say I ate three juicy pears or The pears are ripe because the noun has to bear the right marker for number (plural versus singular) and agree with other elements in the sentence. The presence of such markers is dictated by the grammatical rules of a language. In English, the requirements on such markers are few—number marking, for example, only needs to appear on the noun itself. In some other languages, the marker also has to turn up on the adjective and even the definite or indefinite article. Consider Spanish: the juicy pears are las peras jugosas, and to eliminate any one of the three plural markers would be as ungrammatical as saying three pear in English.
In English, we have a fairly paltry set of inflectional morphemes, limited to plural markers on nouns and three types of markers on verbs:
1. The present progressive suffix -ing (walking)
2. The past-tense suffix -ed (walked)
3. The marker -s to signal the third person present tense (I walk, but he walks)
But some languages systematically mark not only person and number on many words, but also encode notions such as case, which signal what role a noun is involved in—that is, the noun stems (and often adjectives and articles) will have different endings depending on whether they’re part of the subject, direct object, indirect object, and so on (see Box 5.3).
In English, bare stems like eat, water, and red can occur on their own as words. This is not the case for some other languages, where a stem can never be stripped of its inflectional morphemes. In these languages, the hypothetical gavagai could never refer to just one meaning unit. Obviously, in languages like these, the sense of what a word is can be quite different, and children have to learn to decompose many words into their component parts. This seems to be done with impressive ease. For example, Turkish nouns may have a plural and/or a possessive marker, and they must be tagged with a case marker. Meanwhile, Turkish verbs never show up without a full morphological regalia of three suffixes marking tense, number, and person (among other things). Yet among Turkish-speaking children, the whole system is pretty much mastered and error-free by the time they are 2 years of age (Aksu-Koc & Slobin, 1985). And, while the first word of a baby growing up in an English-speaking household almost always consists of a single morpheme, that’s not true for Turkish children, whose earliest words already snap inflectional morphemes onto the stem.

Figure 5.12 The “wug test” has its own line of merchandise. Here, the original test is affixed to a “wug mug,” allowing language enthusiasts to spontaneously test for the generalization of the English plural at home and at the office. (Courtesy of Jean Berko Gleason. Adapted from The Wug Test © Jean Berko Gleason 2006.)
Words versus rules
In a famous experiment, Jean Berko Gleason (Berko, 1958) showed young children a picture of a bluebird-like creature, saying, “This is a wug.” Then she showed them a picture of two of the creatures, saying, “Now there is another one. There are two of them. There are two ____” (see Figure 5.12). Often, the children obligingly produced the missing word wugs (pronounced with a [z] sound at the end, not [s]).
This simple result was hailed as an important early finding in research on language acquisition. It showed that when faced with a new word that they couldn’t possibly have heard before, kids were able to tag on the right plural morpheme. Since they couldn’t have memorized the right form, they must have been generalizing on the basis of forms that they had heard: dogs, birds, etc. It turns out that children were able to do similar things with novel possessive forms (the bik’s hat) and past-tense forms (he ricked yesterday).
This ability to generalize to new forms on the basis of previously known forms is a powerful mechanism. To some language scientists, it is the essential hallmark of human natural language. One way to view the whole process is that children must be forming rules that involve variables—that is, they’re manipulating symbols whose value is indeterminate and can be filled by anything that meets the required properties for that variable. So, a rule for creating the plural form for a noun might be stated as: Nstem + s where Nstem is the variable for any stem morpheme that is a noun. No need for children to memorize the plural forms—and for that matter, an adult learner of English could be spared a fair bit of trouble by being told up front, “Look, here’s how you make plural nouns in English.” The other inflectional morphemes in English can also be applied by rule. For example, to form the past tense of a verb: Vstem + ed.
Of course, that’s not the whole story, because in addition to dogs, birds, and bottles, we also have children, men, mice, and deer, none of which are formed by applying the plural rule, as well as irregular verb forms like rang, brought, and drove. These just have to be memorized as exceptions. Moreover, they have to be memorized as whole units, without being mentally broken down into stems plus affixes. For instance, what part of children, mice, or deer corresponds to the plural morpheme, and what part of rang or brought would you say conveys the past? In these examples, the meanings of the two morphemes are fused into one seamless whole.
It’s especially interesting to see how children cope with the rule-like forms, compared with the exceptional ones. Very early on, they tend to correctly produce the common exceptional forms—they might produce went rather than goed. But this stage is short-lived. They soon catch on to the pattern of attaching -ed to verb stems and apply it liberally, peppering their speech with lots of errors like bringed, feeded, weared, and so on. Once entrenched, this attachment to the rule-like forms can be hard to dislodge, even in the face of parental correction. Here’s a well-known interaction reported by psycholinguist Courtney Cazden (1972) involving a child oblivious to a mother’s repeated hints about the correct past-tense form of the verb to hold:
Child: My teacher holded the baby rabbits and we patted them.
Mother: Did you say your teacher held the baby rabbits?
Child: Yes.
Mother: What did you say she did?
Child: She holded the baby rabbits and we patted them.
Mother: Did you say she held them tightly?
Child: No, she holded them loosely.
Paradoxically, errors due to overgeneralizations like these actually reflect an advance in learning—they’re evidence that the child has abstracted the generalization for how to form the past tense.
One system or two?
To some researchers, there’s a stark separation between the knowledge that underlies the regular forms of the past tense and the knowledge that underlies the irregular forms: the regulars involve the assembly of language from its parts, while the irregular forms, which have to be memorized, hinge on the retrieval of stored forms from memory. These are seen as two fundamentally distinct mental processes—rules versus words. Researchers who argue for this view often point to evidence for two distinct psychological mechanisms, including some evidence suggesting that different brain regions may be involved in processing regular versus irregular verbs (see Box 5.4). But others claim that the two don’t involve truly distinct processes at all. They suggest that children could simply be memorizing even the regular forms, and then extending the past-tense forms to new verbs by analogy.
Using analogy is quite different from applying an abstract rule. An abstract rule involves actively combining a certain tag—say, the regular past tense form -ed—with anything that matches the variable specified within the rule—in this case, a verb stem. But analogy involves finding similarities across different memorized words. Here’s an example that may remind you of questions you’ve likely seen on aptitude tests:
Hen is to rooster as aunt is to ____.
Getting the right answer to this question (uncle) involves figuring out what’s different between hens and roost ers and then applying that same difference to the concept of aunt. The argument is that analogy can also apply to the sounds that make up words in the present and past tense. For example:
Slip is to slipped as wrap is to ____.
To fill in the blank via analogy, you don’t need to decompose the word slipped into a verb stem and a separate past-tense morpheme. All you need to do is notice that there’s a certain difference in meaning between slip and slipped, and that the difference in meaning is accompanied by a certain difference in sounds, and then apply this sound difference to the word wrap.
Unlike a combinatorial rule, the same analogical processes could be applied to both regular and irregular forms:
Ring is to rang as sing is to ____.
How plausible is it that analogy plays a key role in learning the past tense for both regular and irregular forms? This hypothesis is bolstered by the fact that overgeneralization isn’t limited to the regular, supposedly rule-based forms—kids often over-extend irregular patterns as well, as in the examples below (from Pinker, 1999):
It was neat—you should have sawn it! (seen)
Doggie bat me. (bit)
I know how to do that. I truck myself. (tricked)
He could have brang his socks and shoes down quick. (brought)
Elsa could have been shotten by the hunter, right? (shot)
So I took his coat and I shuck it. (shook)
You mean just a little itty bit is dranken? (drunk)
Why do these kinds of errors turn up in children’s speech? Because even irregular forms don’t show a completely random relationship between the present and past forms. It would be odd, to say the least, to have stap be the past tense of a verb like frond. Instead, irregulars tend to show up in pockets of semiregular patterns. So we get, among others:
| lie/lay | give/gave | forgive/forgave | bid/bade |
| hang/hung | fling/flung | sling/slung | sting/stung |
| blow/blew | grow/grew | throw/threw | know/knew |
| find/found | bind/bound | grind/ground | wind/wound |
If irregular forms show some principled patterning in their sound structure, and if children over-extend these patterns as they do with regular forms, then the line between memorized words and rule-based assembly becomes blurred. It seems tricky to account for the irregulars by means of a general rule; if these were in fact formed by rule, we’d have no way of explaining why the past tense of snow isn’t snew, for instance. But the regularities inherent in the preceding examples suggest that there must be some way for the human mind to detect and generalize patterns that don’t result from the application of a rule.
In a famous paper published in 1986, Dave Rumelhart and Jay McClelland set out to build a computer model that does exactly that. Their connectionist model of the past tense treats verb stems and past-tense forms as bundles of sound that are associatively linked together in memory. The model’s job is to learn to predict which sounds make up the past-tense form, given a particular verb stem. So, if the model receives as input the set of sounds that make up the stem grind, it should ideally be able to come up with the sounds contained in ground, even though it has never before been presented with the past form ground. It should be able to do this based on its exposure to many other pairs of verb stems and past-tense forms; assuming there are systematic statistical patterns to be found in the relationships between the stems and past-tense forms, the model is designed to detect them and store them as probabilistic associations.
In the early stages of “learning,” the model’s predictions are pretty random. Since it’s had minimal exposure to examples, any set of sounds is as likely as another to be associated with the sounds of grind. But after it’s been exposed to many examples of stems and past-tense forms, it begins to adjust the connections between the sounds of the verb stem and the sounds for the past-tense form. For example, the model begins to “notice” that most of the consonants that appear in the uninflected form also turn up in the past-tense form, so it is able to predict that a pair like stap/frond would be extremely unlikely to show up, while grind/ground is quite likely. It also begins to “notice” that there are similarities in sound between words that belong to the same subclass of irregular past-tense forms—for example, it notices that there’s something the same in words that have the vowel sound “ay” (as in find) in the verb stem but the sound “ow” (as in found) in the past-tense form: the word-final consonants -nd tend to be present in these words. The gradual tweaking of connections between the verb stem sounds and the past-tense sounds reflects the gradual learning of irregular past-tense forms through a form of statistical analogy. Naturally, the more frequently a word occurs, the more opportunities the model has to associate the correct past-tense form with the verb stem, which might account for the fact that children’s earliest past-tense forms tend to be high-frequency ones like went, came, got, and so on.
Language researchers agree that something like this is probably needed to account for the non-accidental patterns that irregular forms fall into. But Rumelhart and McClelland made the stronger claim that exactly the same kind of mechanism can be used to account for how the regular forms are learned, dispensing entirely with the notion that these are formed by a rule that manipulates abstract symbols. This claim has generated a great deal of controversy, and an outsider looking in might be surprised at the charged and passionate nature of the debate over regular and irregular verb forms. But what’s at issue is, in part, two general, conflicting views of how children learn the systematic patterns of their language.
One view emphasizes that language is at heart an intricate system of rules, and that children come into the world prepared to extract rules out of their linguistic input. As we’ll see in the next chapter, whatever arguments might be made for treating the past-tense formation as rule-based, they are fairly mild compared with the arguments for using rules to account for the regularities governing how entire sentences get assembled. Some researchers take an additional step and claim that kids rely on innate biases that allow them to extract just the right rules out of the input with remarkable efficiency, while managing to avoid coming up with rules that would lead them to dead ends. Under this scenario, nothing could be more natural than for children to seize on a regularity like the English regular plural or past-tense forms and represent the pattern by means of a rule that any new form can then be cranked through.
The opposing view takes the stand that children can get away with very little in the way of innate expectations about rules and what they might look like, and that in fact there is enough information available in the linguistic input for children to be able to notice generalizations and extend them to new situations quite readily. All that’s needed is a sensitivity to statistical regularity, just like the one built into Rumelhart and McClelland’s connectionist model. Proponents of this view tend to emphasize that, as we saw in the last chapter, even young babies are exquisitely sensitive to statistical regularities in linguistic input. They argue that regular morphemes simply reflect statistical regularities that are somewhat more regular than the less regular forms, and there is no need to formulate an actual rule in either case.
GO TO
 for web activities, further readings, research updates, and other features
for web activities, further readings, research updates, and other features