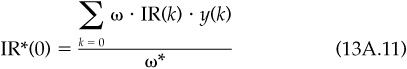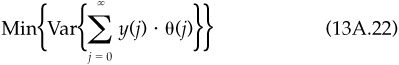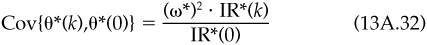There is a time dimension to information. Information arrives at different rates and is valuable over longer or shorter periods. For most signals, the arrival rate is fixed. The shelf life (or information horizon) is the main focus of interest. Is this a fast signal that fades in 3 or 4 days, or is it a slow signal that retains its value over the next year? The latest is not necessarily the greatest. In some cases, a mix of old and new information is more valuable than just the latest information.
Chapters 10 and 11 developed a methodology for processing information and described how to optimally combine sources of information. Chapter 12 presented an approach to analyzing the information content of signals. Chapter 13 will rely on both methodologies to tackle the special topic of the information horizon.
We will begin by applying information analysis at the “macro” level: looking at returns to multiasset strategies. These may be based on one or several sources of information, possibly but not necessarily optimally combined. The goal is to determine the information horizon, and whether the strategy is effectively using the information in a temporal sense, i.e., whether any time average or time difference of the information could improve performance. This analysis has the advantage of requiring only the returns, not a detailed knowledge of the inner workings of the strategy.
At the “micro” level, we will apply the methodology of Chap. 10 to the special case of optimal mixing of old and new signals. The in-depth analysis of simple cases provides insight into the phenomena we observe in more complicated and realistic cases. These micro results echo the macro results.
Insights in this chapter include the following:
■ The information horizon should be defined as the half-life of the information’s forecasting ability.
■ A strategy’s horizon is an intrinsic property. Time averages or time differences can change performance, but they will not change the horizon.
■ Lagged signals or scores and past returns can improve investment performance.
A natural definition of the information horizon, or shelf life, of a strategy is the decay rate of the information ratio. What does it cost us if a procrastinating investment committee forces a 1-month delay in implementing the recommendations? We use the May 1 portfolio in June, the June 1 portfolio in July, and so forth. What if there is a 2-month delay? Or a 6-month delay? In general, delays will lead to a reduction in the strategy’s potential as measured by its information ratio. A reasonable measure of the decay rate is the half-life, the time it takes for the information ratio to drop to one-half of its value when implemented with immediacy. In practice, this means that we approximate the decay in the information ratio as an exponential where a certain fraction of the information is lost in each period.
The half-life is a remarkably robust characteristic of the strategy. Attempts to improve the signal using its temporal dimensions may improve performance, but they will have little or no effect on the strategy’s half-life!
In Fig. 13.1, we see a gradual decay in the strategy’s realized information ratio as we delay implementation for more and more months. The half-life is 1.2 years.
The ability to add value is proportional to the square of the information ratio. Thus the half-life for adding value is one-half that of the information ratio. In the case illustrated in Fig. 13.1, we have a half-life of 0.6 year for value added as opposed to 1.2 years for the information ratio. This is a long-horizon strategy. We can delay implementation of the recommended trades for more than 6 months and still realize 50 percent of the value added.
Figure 13.2 shows a strategy with a very short half-life.
The interplay of information and time is as subtle as the interplay of food and time. “Fresh is best” is a good rule but not universally accurate: Vegetables and baked goods are best when fresh, fruit needs to ripen; wine and cheese improve with age, and sherry is best as a blend of several vintages. Is the information sherry, vegetables, or wine?
We can see if there is any value in the old information with a thought experiment. Suppose there are two investment managers, Manager Now and Manager Later. Manager Now employs an excellent strategy, with an information ratio of 1.5. Manager Later’s research consists of sifting through Manager Now’s trash to find a listing of last month’s portfolio. Thus Manager Later follows the same strategy as Manager Now, but with the portfolios 1 month behind. Manager Later has an information ratio of 1.20. Both managers have an active risk level of 4 percent.
Should we hire Manager Now, Manager Later, or a mix of Now and Later? This decision hinges on the correlation of the active returns. If the correlation between Manager Now’s and Manager Later’s active returns is less than 0.80 = 1.2/1.5, the decay rate of the information ratio, then we can add value by hiring both Now and Later. If the correlation is more than 0.80, we want to hedge Manager Now’s performance by going short manager Later. Figure 13.3 shows the mix of Now and Later that we would want as a function of the correlation between their active returns. At a correlation of 0.7 between the active returns of Managers Now and Later, the best mix is 18.5 percent to Manager Later and 81.5 percent to Manager Now. If we presume a correlation of 0.85 in the active returns of Managers Now and Later, then the optimal mix is a 118.5 percent long position with Manager Now offset by an 18.5 percent short position with Manager Later.

We will show in the technical appendix that given a decay rate of γ and a correlation of ρ, the optimal weight on Now is
where
Figure 13.4 shows the change in the overall information ratio that results from combining Managers Now and Later. We see that there is no gain if the active return correlation is 0.8 and that there are modest gains if the active return correlation strays above or below that key level. The algebraic result here is
We will show more generally in the technical appendix that the optimal combination of past portfolios mixes them so that the correlation between the time t and the time t − 1 portfolios equals the decay rate of the information ratio. For example, if the l-period lagged information ratio is IRl = γl · IR0 and the portfolios at each time t are denoted h(t), h(t −1),..., h(t − l),..., then the combination with the best information ratio will be
The correlation of active returns for the holdings h*(t) and h*(t − 1) will be γ. Note that h* is a weighted average of innovations, with h(t − l) − ρ · h(t − l − 1) capturing the new information in h(t − 1).1
This application of information analysis can quickly help a manager determine if she or he is leaving any information on the table, since a real manager can easily combine managers Now and Later merely by combining the most recently recommended portfolio with the portfolio recommended in the previous period. For example, if the active return correlation is 0.5, then a mix of 33 percent of the lagged portfolio and 67 percent of the current portfolio would produce an information ratio of 1.59. Combining the portfolios is combining the outputs of the investment management process. If there is a process where it is possible to link inputs with outputs, then we could also proceed by mixing the lagged inputs and the current inputs in the same 33 percent and 67 percent ratios.
This optimal mix of Now and Later will improve performance although it will not change the horizon. If we make an optimal mixture of the old portfolios, the information ratio will increase, but the horizon (half-life) of the resulting strategy will be exactly the same as the horizon of the original strategy.
We will now apply our information processing methodology to analyzing the information horizon at the micro level. We will focus on the case of one asset, or, more precisely, one time series.2 This asset has return r(0,Δt) over a period between time 0 and time Δt. For convenience, we assume that the expected return is 0. The volatility of the return is σ times the square root of Δt. We assume, in general, that the asset returns are uncorrelated.
Information arrives periodically, in bundles that we’ll call scores, at time intervals of length Δt—perhaps an hour, a day, a week, a month, a quarter, or a year. These scores have mean 0 and standard deviation 1, as described in Chap. 10.
The special information contained in the scores may allow us to predict the return r(0,Δt). This prediction, or alpha, depends on the arrival rate and shelf life of that information.
In the simplest case, “just-in-time” signals, the signal is of value in forecasting return during the interval until the next one arrives, but it is of no value in forecasting the return in subsequent periods. For example, a signal that arrives on April 30 helps in forecasting the May return but is of no use for June, July, etc. The next signal, which arrives May 31, helps with the June return.
Let IC(Δt) be the correlation of the score with the return over the period {0,Δt}. Given a score s(0), the standardized signal at time 0, the conditional expectation of r(0,Δt)is
The information coefficient IC(Δt) is a measure of forecast accuracy over the period. The first goal is to determine the value of the information. Here we will use the information ratio. We can use the fundamental law of active management to determine the information ratio as a function of the forecast interval:
where we measure the breadth BR as simply the inverse of the period, i.e., 1/Δt. For example, a signal that arrives once per month has a breadth of 12. We can see immediately that there is a tradeoff between the arrival rate, captured by Δt, and the accuracy, captured by IC(Δt).
In the simplest case described above, we had “just-in-time” information. The interarrival time Δt matched the shelf life Δt. Now we’ll consider cases where the interarrival time is shorter than the shelf life.3 In particular, we receive scores each period, and a score’s shelf life is two periods long. The April 30 score predicts the returns for May and June. The May 31 score predicts the returns for June and July. We can measure the IC of the score on a period-by-period basis. The term IC1 measures the correlation between the score and the first period’s return, and the term IC2 measures the correlation between the score and the second period’s return. The information coefficient IC1&2 is the correlation between the score and the two-period return. The relation between these information coefficients is
For example, a correlation of IC1 = 0.15 for the first period’s return and IC2 = 0.075 for the second period’s return would imply a correlation of  for the two periods. We are blessed with a longer shelf life. It remains to see how we handle this blessing.
for the two periods. We are blessed with a longer shelf life. It remains to see how we handle this blessing.
We want to make a one-period forecast based on the most recent score, s(0), and the previous score, s(-Δt). In the monthly example, we combine the April 30 score and the May 31 score to produce a forecast for June. The critical variable in producing a best forecast will be the correlation ρ between s(0) and s(-Δt).
In Chap. 10, we derived how to optimally combine two separate signals. That result applies here as well, with the second signal being simply the lag of the first signal:
The modified information coefficients  and
and  correct for the correlation between the signals:
correct for the correlation between the signals:
The IC of the combined signal is
Figure 13.5 shows how the modified information coefficients change as the correlation between the signals varies, assuming IC1 = 0.15 and IC2 = 0.075.
The combined forecast dominates using either the first or the second score in isolation. Figure 13.6 demonstrates this for our example.
The lagged score, s(−Δt), can help improve the forecast in one of two ways:
■ Diversification, as a second predictor of the return r(0,Δt)
■ Hedging, as a way of reducing the noise in s(0)
The scores are part truth and part noise. The truth portion is perfectly correlated with future return. The noise component is uncorrelated with future return. By adding a fraction of the previous score to the current score, we can reinforce the known facts and diversify the noise. This is a good idea if IC2 > ρ · IC1, i.e., when there is a relatively strong remaining signal and relatively low correlation. The alternative is to subtract a fraction of the second score from the first. This loses some signal, but if the scores are strongly correlated, it will hedge the noise. Hedging is the most beneficial path to follow if IC2 < ρ · IC1, i.e., when there is a relatively weak signal and strong correlation. In the intermediate case, when IC2 = ρ · IC1, then  and
and  . In effect, we ignore the previous score.4 We can see this critical point in Figs. 13.5 and 13.6 where the correlation reaches 0.5, exactly the ratio of the information coefficients.
. In effect, we ignore the previous score.4 We can see this critical point in Figs. 13.5 and 13.6 where the correlation reaches 0.5, exactly the ratio of the information coefficients.

This result for optimally combining new and old information closely matches our results from the macroanalysis. In fact, Figs. 13.5 and 13.6 from the microanalysis resemble Figs. 13.3 and 13.4 from the macroanalysis. This is quite reassuring. We will now see, however, that we can drill considerably deeper in microanalysis.
Prior to the 1967 Arab-Israeli war, then private citizen Richard Nixon predicted that
1. There would not be a war.
2. If a war started, it would be a long war.
The war started within days, making Mr. Nixon’s first prediction no longer operative. When the war was over a week later, the second prediction went nonoperative. You don’t receive such dramatic and immediate feedback when you’re predicting asset returns.
Suppose that we have, as above, alphas arriving each month that are useful in predicting returns over the next 2 months. Suppose further that our signal produces an alpha prediction of 2 percent at the beginning of March, and make a third supposition that the realized alpha in March is 2 percent, as predicted. It would seem that the prediction has come true and we can ignore the old information; all the juice has been squeezed out of it. Not so! Many people find it hard to believe, but they may be right for the wrong reasons.5 That 2 percent return may have been incidental.
To deal with this possibility, we can use the previous period’s return, r(−Δt,0) as another possible variable in the prediction of next period’s return, r(0,Δt). We turn r(−Δt,0) into a score by dividing it by its standard deviation; the score is  .
.
We now have three predictors of r(0,Δt): s(0), s(−Δt), and  . When there is no serial correlation in the returns and no correlation between past returns and current scores, the rule for adapting to the observed return changes the previous score and is thus called “settling old scores.” The settled score6 is
. When there is no serial correlation in the returns and no correlation between past returns and current scores, the rule for adapting to the observed return changes the previous score and is thus called “settling old scores.” The settled score6 is
The “correction” in the previous score, the term IC1 · r(−Δt,0)/ , is the part of the score that has been used up. The greater the ability to predict, the more we discount from the score.
, is the part of the score that has been used up. The greater the ability to predict, the more we discount from the score.
In general, the settling score effect is small, since the impact depends on the product of IC1 and  . However, there can be a considerable effect in extreme situations. For example, consider an asset allocation model with a stock minus bond score of −2.16 on October 1, 1987. The October return was a 6.5 standard deviation event; i.e.,
. However, there can be a considerable effect in extreme situations. For example, consider an asset allocation model with a stock minus bond score of −2.16 on October 1, 1987. The October return was a 6.5 standard deviation event; i.e.,  . With a first period IC1 = 0.15, the corrected score is s*(−1) = −1.18. This is an extraordinary change reflecting the extraordinary event. In a typical month with, say, a 1 standard deviation event in the return, we would make a small change of 0.15 to the score.
. With a first period IC1 = 0.15, the corrected score is s*(−1) = −1.18. This is an extraordinary change reflecting the extraordinary event. In a typical month with, say, a 1 standard deviation event in the return, we would make a small change of 0.15 to the score.
In this analysis, we have ignored some complicating features. For example, if returns are autocorrelated, past returns play a double role by settling old scores, as described above, and bringing information about next period’s return. It also often happens that past returns have an impact on future scores. The causality flows from return to score, as well as from score to return. With a momentum signal, higher past returns generally mean higher future scores. With a value signal, large past returns tend to imply lower future scores.7 The microanalysis methodology can handle both of these situations. The technical appendix treats one special case, using the binary model.
The one- and two-period models described above are easy to analyze but lack realism. A more sensible information model is one of gradual decline in forecasting power. The information coefficient decays as we move more and more periods away from the arrival of the information. A score available at time June 30 has a correlation with July return of IC. The correlation with August return is IC · δ. In general, the correlation with return in month n + 1 is IC · δn. We can relate this continuous decay to the half-life:
or
Figure 13.7 shows a gradual attrition of the information’s power. In this case, monthly intervals, the half-life is one quarter; HL = 0.25, δ = 0.7937. We can see the exponential decay in the monthly information coefficient over time.8 As the score and the return move farther apart, the information coefficient decreases.
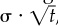
A different cut at this is to look at the correlation of the signal with returns over longer and longer periods. Instead of lagging the scores, we can lead the returns. We can examine the correlation of a monthly score with the monthly return, 2-month return, quarterly return, annual return, etc.
What will influence the information coefficient for longer and longer return horizons? On the positive side, the longer return horizons should more completely reflect the signal’s information. On the negative side, increasing volatility,  accompanies the longer time periods. We will show in the technical appendix that the correlation of the returns with the signal over longer and longer periods is
accompanies the longer time periods. We will show in the technical appendix that the correlation of the returns with the signal over longer and longer periods is
where the IC in Eq. (13.15) is the information coefficient over the initial period of length Δt. Figure 13.8 illustrates this relationship. The signal has its highest predictive power when the horizon is about twice the half-life of the signal.9

As the signals arrive, we can use the most recent, or we can attempt to combine new and old in order to get a more powerful forecast. The ability to improve will still hinge on two parameters:
■ The decay factor δ
■ The correlation ρ between the adjacent scores
If δ = ρ, then the most recent score has all the information that we need. If δ > ρ, we can diversify by using past scores to reinforce the information. Finally, if δ < ρ, we can use past signals to hedge the noise in the most recent signal. This is a message we’ve seen before, in the macroanalysis and in the two-period case.
To use the information in an optimal way, mix the past signals so that the new mix has an autocorrelation equal to δ. The recipe is
This is effectively the same result we saw in Eq. (13.4). This optimally repackaged information will have the same half-life as the original information. For example, in Fig. 13.9 we show the original and repacked information coefficients. The half-life is one quarter, and the correlation between signals is 0.5.
The information horizon (half-life) is a critical characteristic of a signal or strategy. The horizon can help us see if we are using information efficiently in a temporal sense. Macroanalysis can fairly easily tell you if your strategy is temporally efficient. Microanalysis provides insight into how this works, and can handle many important cases. Past information—signals and returns—can help the current forecast.
Investment horizon is a term generally used in a strategic sense for either the individual or the institutional investor. The horizon metaphor is apt for an institutional investor, since an ongoing institution’s investment horizon will continually precede the institution into the future. The long view is used to set a strategic asset allocation and investment policy.
In the individual investor’s case, the horizon metaphor is not particularly appropriate; there is no receding horizon. We have an uncertain, but finite, term until retirement and another, also uncertain, interval until death. This is one of life’s cruel jokes. Samuelson (1994) has more to say in this regard.
For another, more technical horizon topic, see Goetzmann and Edwards (1994) and Ferguson and Simaan (1996). They tackle the question of horizon as it relates to a single-period portfolio mean/variance optimization. The questions are: How long a period should we consider? and, Does it matter? This analysis hinges on the interaction between the compounding nature of returns and the additive nature of a buy and hold portfolio. It can get complicated, and it does. Some of the difficulty goes away when you consider multiperiod investing or continuous rebalancing. If you assume lognormal returns, continuous rebalancing, and a power utility function for cumulative return at the horizon, the portfolio selected will be independent of the horizon. See Merton (1990), pp. 137-145.
1. Your research has identified a monthly signal with IR = 1. You notice that delaying its implementation by one quarter reduces the IR to 0.75. What is the signal’s half-life? What is the half-life of the value added?
2. In further researching the signal in Problem 1, you discover that the correlation of active returns to this signal and this signal implemented 1 month late is 0.75. What is the optimal combination of current and lagged portfolios?
3. You forecast α = 2 percent for a stock with ω = 25 percent, based on a signal with IC = 0.05. Suddenly the stock moves, with θ = 10 percent. How should you adjust your alpha? Is it now positive or negative?
Atkins, Allen B., and Edward A. Dyl. “Transactions Costs and Holding Periods for Common Stocks.” Journal of Finance, vol. 52, no. 1, 1997, pp. 309-325.
Ferguson, Robert, and Yusif Simaan. “Portfolio Composition and the Investment Horizon Revisited.” Journal of Portfolio Management, vol. 22, no. 4, 1996, pp. 62-68.
Goetzmann, William N., and F. R. Edwards. “Short Horizon Inputs and Long Horizon Portfolio Choice.” Journal of Portfolio Management, vol. 20, no. 4, 1994, pp. 76-81.
Grinold, Richard C. “Alpha Is Volatility Times IC Times Score,” Journal of Portfolio Management, vol. 20, no. 4, 1994, pp. 9-16.
_____. “The Information Horizon.” Journal of Portfolio Management, vol. 24, no. 1, 1997, pp. 57-67.
Merton, Robert C. Continuous Time Finance, (Cambridge, MA: Blackwell, 1990).
Samuelson, Paul A. “The Long Term Case for Equities.” Journal of Portfolio Management, vol. 21, no. 1, 1994, pp. 15-24.
We will use this technical appendix to derive several results presented in the main text. We will show that mixtures of past strategies cannot change the half-life of the strategy. We will analyze the optimal mixture of past strategies. We will show how the correlation of a signal with returns of varying horizons depends on that horizon. Finally, we include an explicit optimal combination of current and past signals and past returns, in the context of the binary model.
Let’s start with some basic notation. We will need to explicitly keep track of lagged information:
hPA(j) = active portfolio lagged j periods
θ(j) = return to the j-lag active portfolio10
IR(j) = information ratio for the j-lag portfolio
We will further make the assumptions that
The first assumption is not remarkable. It just says that any old active position will have the same active risk as any other. Note that this implies that any decay in the information ratio over time must arise solely as a result of decay in the alpha:
The second assumption is stronger. It says that the covariance between lagged positions depends only on the time interval between them. Note that this is weaker than saying that there is a single parameter ρ such that ρ(|j − k|) = ρ(|j − k|).
We define a mixture of past strategies using weights y(j), j = 0,1,2,.... This mixture of past strategies will have an information ratio IR*(0). But we can also lag this mixture strategy, giving rise to a new sequence of lagged information ratios IR*(j), j = 0,1,2,....
If the strategy information ratios decay exponentially [as in Eq. (13A.3)], then any mixture strategy will exhibit information ratios which also decay exponentially, at the same rate:
Proof The active holdings for the j-lag mixture strategy are
with active returns
Our first step is to show that, while the risk of the mixture strategy does not generally equal the risk of the underlying strategy, the dependence on lag is the same. In fact, the risk of the mixture strategy is independent of lag.
The risk of the lagged mixture strategy is
But our assumptions, Eqs. (13A.1) and (13A.2), guarantee that
Hence
So the decay in the information ratio for the mixture strategy must depend entirely on the decay in the alpha for the mixture strategy. We can now show that this decays at the same rate as the alpha for as the underlying strategy.
The information ratio for the unlagged mixture strategy is
But we can relate these alphas to information ratios:
The information ratio for the lagged mixture strategy is
We can relate this too to the information ratios:
Finally, we can simply calculate the ratio of lagged to unlagged information ratios for the mixture strategy. Using Eqs. (13A.11) and (13A.13), this becomes
But using Eq. (13A.3), this becomes the desired result:
While we will not explicitly demonstrate this, the correlation structure of lags of a mixture strategy retains the structure exhibited by lags of the underlying strategy, namely, that the correlation depends only on the separation between the two lags of the mixture strategy
The main text presented two sets of results concerning optimal strategy mixtures First, it presented the optimal mix of Now and Later, the current and lagged portfolios It then stated a more general result, that optimal strategies should exhibit a correlation structure matched to the decay of the information We will calculate both results here. We begin with the combination of Now and Later.
Our goal is to combine current and past portfolios so as to maximize the resulting information ratio. We characterize the current portfolio with statistics αNow, ω, and IRNow, and the lagged portfolio with statistics αLater, ω, and IRLater Note that the current and lagged portfolios exhibit the same risk. We will also assume a correlation ρ between current and lagged active returns, and a decay factor γ between current and lagged information ratios. Using ωNow to express the weight on the current portfolio, the combined alpha is
Here we have explicitly used the decay factor to express the information ratio of the lagged portfolio. We can express the risk of the combined portfolio as
We can put this all together and express the combined information ratio as
To maximize the combined information ratio, we need to take the derivative of Eq. (13A.18) with respect to ωNOW, and set it equal to zero. The procedure is algebraically messy, but straightforward. The result is
where
as stated in the main text. Furthermore, we can take Eq. (13A.19) and substitute it back into Eq. (13A.18) to determine the maximum information ratio achieved. The result is
We will now treat the general optimality condition quoted in the main text. We will use the notation introduced at the beginning of this appendix. In this general case, we want to minimize the variance of the mixture strategy, subject to the constraint that the alpha remains constant (i.e., equal to the alpha of the current underlying strategy). Mathematically,
subject to the constraint
Note that the problem is feasible, since the case {y(0) = 1; y(i) = 0, i ≠ 0} satisfies the constraint. Using a Lagrange multiplier, we can rewrite the minimization problem as
The first-order conditions are
plus the constraint. Note that Eq. (13A.25) represents a set of equations, one for each lag j. Now, to solve for the Lagrange multiplier c, we can multiply the equation for each lag j by the weight y(j), and sum them. The covariance term becomes
The information ratio term becomes
Putting this together, we find that the term c is
and the covariance relationship (first-order condition) becomes
Here we have used the notation θ* for the active return to the mixture strategy.
In this scheme, the mixture strategy has a higher information ratio than the underlying strategy specifically because it has lower risk. We have constrained the alpha to remain constant. Hence the ratio of IR(0) to IR*(0) is just the ratio of ω* to ω. So we can rewrite Eq. (13A.29) as
This is close to the answer we are seeking. We now have the covariance structure between the underlying strategy and the optimal mixed strategy. We want the covariance structure between the optimal strategy and its lags. We can calculate this easily. The lagged optimal strategy active return is
We can calculate the covariance of this with θ*(0). Using Eq. (13A.30) and the definition of IR*(k), this becomes
This directly reduces to the result we want:
that the correlation between lagged optimal mixes falls off as the information ratio falls off between the lagged optimal mixes. In particular, focusing on just one lag, the information ratio decays by δ, and we have devised the optimal mix so that the correlation between the current and lagged optimal mix is also δ, according to Eq. (13A.33).
The result in Eq. (13A.33) plus the previous result [Eq. (13A.9)] that all lags of mixture strategies maintain the same risk allows us to directly verify Eq. (13.4). The optimal current mixture holdings are just γ times the lagged mixture holdings, plus the innovation in the current strategy. We can verify that the innovation term is uncorrelated with the lagged mixture strategy.
The main text states results concerning the correlation of a score with returns of increasing horizons, in the case where the information decays by a factor of δ each period. We derive the result here. We measure the return horizon as variable t, the sum of several periods of length Δt. The correlation of our score with returns over periods of length Δt out in the future decays by a factor of δ each period. The goal here is to sum up these effects for a return over a period from 0 to t. We need to calculate
Remember that the standard deviation of the score is 1. We can expand r(0,t) into a sum of returns over periods Δt:
Now we can use the decay relationship and an assumed orthogonality in returns over different periods to simplify this to
We can sum this finite power series to find
the result quoted in the main text.
Finally, we include an explicit analysis combining current and past signals and the past return, using the binary model.
Suppose we forecast the residual return each month, and that forecast contains information about the residual returns in the next 2 months. Assume that the expected residual return is 0 and the monthly volatility is 6 percent (annual 20.78 percent). In period t, we have
The forecasts have zero mean and a 4 percent standard deviation:
The forecast g(t), available at the beginning of period t, has four components:
■ Three signals about return in the coming period: {θ1(t),θ2(t),θ3(t)}
■ Two signals about return in the following period: {θ3(t + 1), θ4(t + 1)}
■ Seven elements of new noise: {η1(t),η2(t),...., η7(t)}
■ Four echoes of old noise: {η(t − 1), η2(t − 1),..., η4(t − 1) }
Of course, we observe only the sum of the elements in these four groups.
In forecasting the residual return in period t, both the current forecast and the previous forecast will be of use. The covariance of the most recent forecast with the return is 3, the covariance of the previous forecast with the return is 2, and the covariance between g(t) and g(t − 1) is 5, since they share one element of signal and four elements of noise. The basic forecasting rule therefore leads to
The IC of this refined forecast with the return is 0.1334. Note that the IC of g(t) alone is 0.125 and the IC of g(t − 1) is 0.0833.
We can actually do slightly better by adding a source of information that we have available: last period’s residual return r(t − 1). The covariance of g(t − 1) and r(t − 1) is 3. In this model, r(t − 1) is not correlated with g(t) or r(t), so r(t − 1) itself is useless as a predictor of r(t). However, r(t − 1) combined with g(t) and g(t − 1) is (oh, so slightly) useful. Working through the basic forecasting formula again, we now find
and the IC of the refined forecast is now 0.1335.
When the forecast horizon is shorter than the information horizon, treat the older forecasts like forecasts from a different source. Past realized returns may also improve the forecast.
1. Show that any mixture strategy obeys the same correlation structure we have assumed for the underlying strategies. Namely, show that
Corr{θ*(j),θ*(k)} = ρ*(|j − k|)
2. Show that the optimal combination of Now and Later leads to a mixture strategy with the correlation of the mixture and its first lag equal to the decay factor γ.