2
Data Analysis and Manipulation
In this chapter we are going to delve into list operations, essential for data manipulation and for understanding how Mathematica works; show how to import and export data and files in different formats; have our first contact with the statistical analysis of data; and see how to connect to big databases using ODBC.
2.1 Lists
The basic structure in Mathematica is the list. The elements of a list can be numbers, variables, functions, strings, other lists or any combination thereof; they are written inside braces {} and are separated by commas. If we feel comfortable with the classical terminology of mathematics we can interpret a simple list as a vector, a two-dimensional list (a list of sublists) as a matrix, and a list of three or more dimensions as a tensor, keeping in mind that the tensor elements can be sublists of any dimension.
Below we define a list consisting of three sublists.
list = {{2, 3, 6}, {3, 1, 5}, {4, 3, 7}};
The previous list can be shown in traditional notation as a matrix but we should not forget that internally Mathematica treats it as a list.
list // TraditionalForm
If the notebook has been configured to display outputs using the traditional format (as in this case), it’s not necessary to use //MatrixForm.
We generate a list of lists of sublists.
tensor = Table[i + j + k - l, {i, 2}, {j, 3}, {k, 4}, {1, 2}]
{{{{2, 1}, {3, 2}, {4, 3}, {5, 4}}, {{3, 2}, {4, 3}, {5, 4}, {6, 5}},
{{4, 3}, {5, 4}, {6, 5}, {7, 6}}}, {{{3, 2}, {4, 3}, {5, 4}, {6, 5}},
{{4, 3}, {5, 4}, {6, 5}, {7, 6}}, {{5, 4}, {6, 5}, {7, 6}, {8, 7}}}}
It’s important to distinguish operations between lists and note that they don’t behave in the same way as operations between matrices, especially with respect to multiplication.
This is an example of list multiplication. We write * to emphasize that it’s a multiplication, but if we leave an empty space instead, the result would be the same.
{{a, b}, {c, d}}*{x, y}
{{ax, bx}, {c y, d y}}Here we multiply matrices, or if you prefer, a matrix by a vector. To indicate that this is a matrix multiplication we use Dot (or “.” which is the same). Note that “*” and “.” are different operations.
{{a, b}, {c, d}} . {x, y}
{ax + b y, c x + dy}In the mathematical rule for multiplying matrices a row vector is multiplied by a column vector. Mathematica is less strict and allows the multiplication of two lists that do not meet the mathematical multiplication rule. It chooses the most appropriate way to perform the operation.
{x, y, z} . {a, b, c}
ax + by + cz
{x, y, z} . {{a}, {b}, {c}}
{ax + by + cz}In general, the sum of lists of equal dimension is another list of the same dimension whose elements are the sum of the elements of the initial lists based on their position.
{1, 2, 3} - {a, b, c} + {x, y, z}
{1 - a + x, 2 - b + y, 3 - c + z}If we multiply a list by a constant, each element of the list will be multiplied by it. The same happens if we add a constant to a list.
{{1, 2}, {3, 4}} k
{{k, 2 k}, {3 k, 4 k}}
{{1, 2}, {3, 4}} + c
{{1 + c, 2 + c}, {3 + c, 4 + c}}
To extract a list element based on its position i in the list we use Part[list, i] or, in compact form [[i]].
In this example we show two equivalent ways of extracting the second element of a list:
Part[{a, b, c}, 2]
b
{a, b, c}[[2]]
b
In the case of a list of sublists, first we identify the sublist and then the element within the sublist.
In the following example we extract element 3 from sublist 2:
{{a1, a2}, {b1, b2, b3}, {c1}}[[2, 3]]
b3In the example below we extract elements 2 to 4. Note that the syntax [[i;;j]] means to extract from i to j.
{a, b, c, d, e, f}[[2 ;; 4]]
{b, c, d}Here we extract elements 2 and 3 from sublists 1 and 2.
{{a1, a2, a3}, {b1, b2, b3}, {c1, c2, c3}}[[{1, 2}, {2, 3}]]
{{a2, a3}, {b2, b3}}In this case we use ReplacePart to replace a list element, specifically from sublist 2 we replace element 2 that is b2 with c2.
ReplacePart[{{a1, a2, a3}, {b1, b2, b3}}, {2, 2} → c2]
{{a1, a2, a3}, {b1, c2, b3}}Next, we use [[{ }]] to rearrange the elements in a list.
list = {a, b, c, d, e, f};
list[[{1, 4, 2, 5, 3, 6}]]
{a, d, b, e, c, f}
The solutions (out) are often displayed in list format. If we need a specific part of the solution, we can use the previous command to extract it.
To extract the second solution of this second degree equation:
sol = Solve[1.2 x^2 + 0.27 x - 0.3 == 0, x]
{{x → - 0.625}, {x → 0.4}}We can proceed as follows:
x /. sol[[2]]
0.4
Other functions very useful for list manipulation are Flatten, Take and Drop.
We apply Flatten . With Take [list, i] we extract the first i elements of the list, and with -i the last i. With Take [list, {i,j} ] we can extract elements i to j.
Take[Flatten[{{a, b}, {c, d, e}, f, g}], 5]
{a, b, c, d, e}With Drop [list, i] we remove the first i elements of the list, and with -i the last i. Drop [list, {i, j}] removes elements i to j.
Drop[{a, b, c, d, e, f, g}, - 3]
{a, b, c, d}
Some functions, when applied to lists, operate on the individual list elements, e.g. f[{a, b, ...] → {f[a], f[b], ...}. In this case the function is said to be Listable.
We can see below how a listable function operates. Sin in this case.
Sin[{a, b, c}]
{Sin [a], Sin [b], Sin [c]}Using Attributes, we can check that Sin is listable.
Attributes[Sin]
{Listable, NumericFunction, Protected}An alternative way to type the previous example is:
Sin@{a, b, c}
{Sin [a], Sin [b], Sin[c]}There are commands particularly useful when operating on lists. It’s easy to identify them since they generally contain List as part of their names. You can check using the help system:
?*List*
We omit the output due to space constraints.
There are many more functions used to manipulate lists. We recommend you consult the documentation: guide/ListManipulation.
The most recent versions of Mathematica, starting with Mathematica 10, include datasets (Dataset). These constructions can be considered an extension to the concept of lists. With this new addition, the program has a very powerful way to deal with structured data.
The example below shows a simple dataset with 2 rows and 3 columns. It consists of an association of associations. Most datasets are displayed in tabular form.
data = Dataset[<| "1" → < | "A" → 3, "B" → 4, "C" → 2|>,
"2" → <| "A" → 4, "B" → 1, "C" → 3|>|>]A
B
C
1
3
4
2
2
4
1
3
You can extract parts from datasets in a similar way to the one used with lists. To extract the element from “row 2” and “column C”:
data["2", "C"]
3In a later chapter we will see some examples using Datasets.
2.2 Importing/Exporting
As mentioned before, we will often use as a precaution the command Clear [“Global`*”] at the beginning of a section to avoid problems with variables previously defined:
Clear["Global` *"]
A fundamental feature of Mathematica is its capability for importing and exporting files in different formats. The commands we need for that are Import and Export. They enable us to import or export many different types: XLS, CSV, TSV, DBF, MDB, ...
In this section we are going to use, among others, the files available as examples in a subdirectory named ExampleData created during the program installation. Some of these examples are downloaded from www.wolfram.com (Internet connection required).
A file can be imported or exported by typing the complete source or destination path.
In Windows, to type the file location for import or export purposes use the following syntax:
“...\\directory\\file.ext”, as shown in the following example:
Import["C:\\Users\\guill\\Google Drive\\Mathbeyond\\Data\\file.xls"]
If we want to use the working directory in which the files are located for importing or exporting purposes, normally the easiest way will be to create a subdirectory inside the directory where the notebook is.
The following function checks the directory of the active notebook.
NotebookDirectory[]
C:\Users\guill\Google Drive\Mathbeyond\
In the directory above, create a subdirectory named Data.
With the following command we set the subdirectory Data as our default working directory, the one that the Import and Export functions will use during this session.
SetDirectory[FileNameJoin [{NotebookDirectory[], "Data"}]]
C:\Users\guill\Google Drive\Mathbeyond\Data
We make the previous cell an Initialization Cell to ensure its evaluation before any other cell in the notebook by clicking on the cell marker and choosing from the menu bar: Cell ▶Properties ▶Initialization Cell). This means that all the data will be imported/exported from the Data subdirectory. We may even consider “hiding” the initialization cell by moving it to the end of the notebook. Remember that the order of operations is not the same as it appears on screen. It is the order in which the cells are evaluated. Therefore, even if an initialization cell is located at the end it will still be the first one to be executed.
The total number of available formats can be seen using $ImportFormats and $ExportFormats.
{$ImportFormats // Length, $ExportFormats // Length}
{178, 148}
2.2.1 Importing
If your computer uses a non-American configuration remember that Mathematica uses the dot “.” as a decimal separator and the comma “,” to distinguish between list elements. If you have another configuration you may have problems when importing files. The program enables the configuration of the format in Edit ▶ Preferences... ▶ Appearance to suit the user needs. Nevertheless, it is better to modify the operating system global settings so that all programs use the same setup. In Windows that can be done by selecting in the Control Panel “.” as decimal separator and the comma “,” as list separator. In OS X, the same can be done by going to System Preferences... ▶ Language & Region ▶ Advanced...
Next, we import an xls file containing data about the atomic elements. Note that the program can figure out the type of file from its extension. In this case it’s an xls file, and the program identifies it as a Microsoft® Excel file.
Import ["ExampleData/elements.xls"]
{{{AtomicNumber, Abbreviation, Name, AtomicWeight},
{1., H, Hydrogen, 1.00793}, {2., He, Helium, 4.00259},
{3., Li, Lithium, 6.94141}, {4., Be, Beryllium, 9.01218},
{5., B, Boron, 10.8086}, {6., C, Carbon, 12.0107},
{7., N, Nitrogen, 14.0067}, {8., O, Oxygen, 15.9961},
{9., F, Fluorine, 18.9984}}}Notice that the previous output has the following structure {{{...}}}. The reason is that Mathematica assumes the file is an Excel spreadsheet that may contain several worksheets. Using {“Data”, 1} we tell the program to import the data from worksheet 1 (do not confuse this Data with the working subdirectory Data that we have created earlier):
examplexls=Import["ExampleData/elements.xls", {"Data", 1}]
{{AtomicNumber, Abbreviation, Name, AtomicWeight},
{1., H, Hydrogen, 1.00793},
{2., He, Helium, 4.00259}, {3., Li, Lithium, 6.94141},
{4., Be, Beryllium, 9.01218}, {5., B, Boron, 10.8086},
{6., C, Carbon, 12.0107}, {7., N, Nitrogen, 14.0067},
{8., O, Oxygen, 15.9961}, {9., F, Fluorine, 18.9984}}We show below two ways to extract the first 5 rows of the worksheet and display them in a table format.
TableForm[Take[examplexls, 5]]
AtomicNumber Abbreviation Name AtomicWeight
1. H Hydrogen 1.00793
2. He Helium 4.00259
3. Li Lithium 6.94141
4. Be Beryllium 9.01218
TableForm[examplexls [[;;5]]]
AtomicNumber Abbreviation Name AtomicWeight
1. H Hydrogen 1.00793
2. He Helium 4.00259
3. Li Lithium 6.94141
4. Be Beryllium 9.01218Here we see how to import a single column. In this example, we get the fourth column containing the atomic weights.
Import["ExampleData/elements.xls", {"Data", 1, All, 4}]
{AtomicWeight, 1.00793, 4.00259, 6.94141,
9.01218, 10.8086, 12.0107, 14.0067, 15.9961, 18.9984}We use Rest to remove the first sublist containing the headings (the same could have been done using Drop [data, 1 ]).
data = Rest[Import["ExampleData/elements.xls", {"Data", 1}]];
We show the imported data. Tooltip is included so that when the cursor is over a point in the graphic, its corresponding atomic weight can be seen.
ListPlot[Tooltip[data[[All, 4]]],
Filling → Axis, PlotLabel → "Atomic Weight"]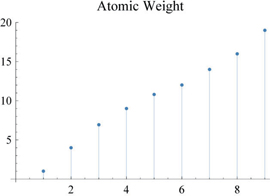
In our next example we find out the elements available in general for this type of format. It refers to all the possible elements. It doesn’t mean that this file contains all of them.
Import["ExampleData/elements.xls", "Elements"]
{Data, FormattedData, Formulas, Images, Sheets}We choose “Sheets” that returns the number of sheets that the file contains including the labels for each one. In this case it only contains one.
Import["ExampleData/elements.xls", "Sheets"]
{Spreadsheet1}To display data in a typical spreadsheet format, like Excel, we can use TableView, a builtin function that as of Mathematica 11.0 remains undocumented.
TableView[Import["ExampleData/elements.xls", {"Data", 1}]]
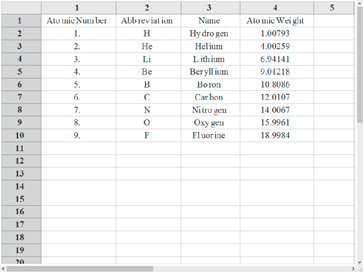
Note: Undocumented functions in Mathematica are not guaranteed to be included in future releases of the program. Additionally, some users might experience software stability issues when evaluating them. For these reasons, we recommend caution when using them.
We can use DateListPlot, a very useful function when the values in the x-axis are dates.
DateListPlot[
Import["ExampleData/financialtimeseries.csv"], Filling → Axis,
PlotLabel → "Financial Data Time Series", ImageSize → Medium]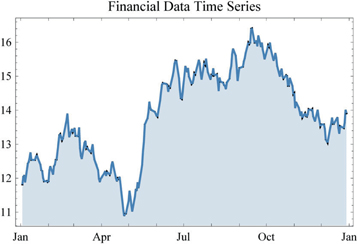
Try to copy and paste links to any of the numerous images available in: earthobservatory.nasa.gov/Features/BlueMarble/.
Import[
"http://earthobservatory.nasa.gov/Features/BlueMarble/Images/BlueMarble_
2005_SAm_09_1024.jpg"]
This function returns the size of an image.
Import[
"http://earthobservatory.nasa.gov/Features/BlueMarble/Images/BlueMarble_
2005_SAm_09_1024.jpg", "ImageSize"]
{1024, 1024}Note: The examples using files imported from the Internet may not work if their web addresses have been changed or the files themselves deleted.
Importing from databases is a frequent data import operation. For example: importing from an Access mdb file.
We import the complete structure of the database:
Import[ "ExampleData/buildings.mdb", {"Datasets", "Buildings", "Labels"}]
{Rank, Name, City, Country, Year, Stories, Height}We use Short or Shallow to display just a few data elements after importing the entire database (this is practical if there’s only one table and it’s not very big).
Import[ "ExampleData/buildings.mdb" ] // Short
{{{1, Taipei 101, Taipei, Taiwan, 2004, 101, 508}, ≪19≫}}We import the records associated to several fields and display them in a table format:
Text[Style[Grid[Transpose[Import[
"ExampleData/buildings.mdb", {"Datasets", "Buildings", "LabeledData",
{"Rank", "Name", "City", "Height"}} ]], Frame → All], Small]]
For big databases (ORACLE, SQLServer, etc.), with a multitude of tables and a large number of records, it’s better to access them with an ODBC connection as we will show later.
From the URL address of a website we can limit the information selected to only what we are interested in. A good practice is to first open the URL in a browser and see what information suits our needs. After importing the web page you will notice that it will appear in Mathematica as a list of lists. Analyze how the information is structured. You need to find out what lists contain the information you want and then use [[...]] to extract it.
The following command opens the specified URL using the default browser on your system.
SystemOpen["http://www.uxc.com/review/UxCPrices.aspx"]
From the previous web page (http://www.uxc.com/review/UxCPrices.aspx) we only import the information included in the frame: Ux Month-End Spot Prices as of MM, YYYY (Month-end spot price data), in US dollars and euros. The change from the previous month is included between parentheses. The following command was created after trial and error by downloading the entire web page and trying different combinations until getting the desired results. We tell Mathematica to show the results using small fonts with the command Style.
Style[
TableForm[Import["http://www.uxc.com/review/UxCPrices.aspx", "Data"][[
2, 2]]], Small]
Ux Month-End Prices as of November 28, 2016 [Change from previous month]
1 US$= 0.94226 €‡
U 3 O 8 Price (lb) $18.25 ( -0.50 )
NA Conv. (kgU) $5.85 ( Unch. )
EU Conv. (kgU) $6.40 ( Unch. )
NA UF 6 Price (kgU) $53.40 ( -1.45 )
NA UF 6 Value § (kgU) $53.53 ( -1.31 )
EU UF 6 Value § (kgU) $54.08 ( -1.31 )
SWU (SWU) $47.00 ( -2.00 )The previous command will work as long as the web page keeps the same structure as when we accessed it (December 7, 2016).
If you know HTML then you might be interested in accessing the contents of a web page by using the function: URLFetch.
You can also import data through WolframAlfa using the free-form input.
In this example we analyze the evolution of the temperatures in Mexico City.


We can expand the output by clicking on the
 that appears in the upper right-hand corner. It will show us several sections available for selection. Here we have chosen the plot with the historical evolution of the average monthly temperatures by selecting from the contextual menu: Paste input for ▶ Subpod Content.
that appears in the upper right-hand corner. It will show us several sections available for selection. Here we have chosen the plot with the historical evolution of the average monthly temperatures by selecting from the contextual menu: Paste input for ▶ Subpod Content.WolframAlpha ["Temperatures in Mexico City since 1980 to today",
{{"TemperatureChart:WeatherData", 1}, "Content"}]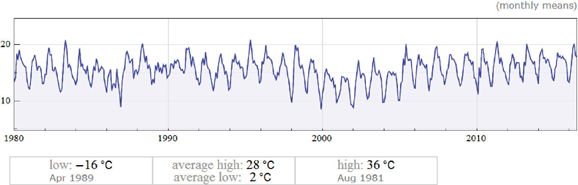
To access multiple data from several fields is better to use the computable data functions that we will discuss in Chapter 5. These functions will always return the same output structure, while WolframAlpha outputs to the same question do not always return the data in the same format.
In this example we download and display the average temperature in a weather station (LESA) located in the province of Salamanca in Spain during a specific time period. We use the computable data function WeatherData combined with DateListPlot.
DateListPlot[WeatherData["LESA", "MeanTemperature",
{{2014, 8, 1}, {2016, 7, 31}, "Day"}], Joined → True]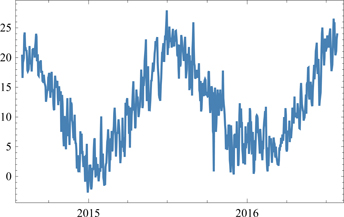
2.2.2 Semantic Import
Since Mathematica 10 there’s a new function named SemanticImport that detects and interprets the type of objects imported.
We import sales data for different cities and dates.
sales = SemanticImport["ExampleData/RetailSales.tsv"]
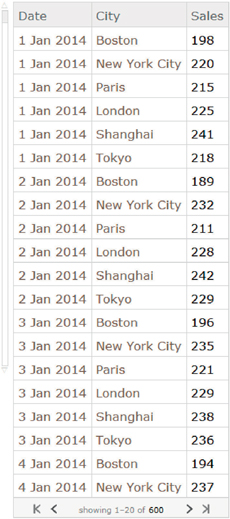
If you move the cursor over the table above, you will see that the program identifies whether the data points are dates or cities, with the later ones displaying additional information. In Mathematica, objects with these properties are called entities (Entity) and have certain characteristics that we will explore later on. For example: If you hover the mouse over Boston, the following message will appear on the screen: Entity[“City”, “Boston”, “Massachusetts”, “UnitedStates”], that is, the data point refers to the city located in Massachusetts (USA) and not to other less famous Boston cities that might exist. To find the first city in the table type the following:

Since it’s a city you can directly obtain information about it, e.g. its population (Remember that % refers to the last output).
%["Population"]
655 884 peopleIn this example we import rows 3 to 5:
SemanticImport["ExampleData/RetailSales.tsv", Automatic, "Rows"][[3 ;; 5]]

2.2.3 Export
The variety of export formats is quite extensive: $ExportFormats. We can even export in compression formats such as zip.
As it is the case when importing, if we don’t specify the export path, the files will be copied to our working directory (Data in this case).
Generate a 3D graph:
gr = BarChart3D[{RandomInteger[7, {4}], RandomInteger[{-7, -1}, {4}]},
ChartElementFunction → "Cone"]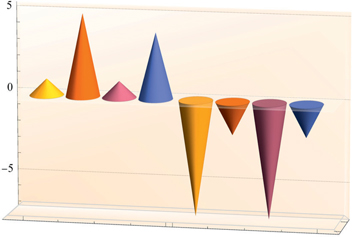
Export the graph as a file named “cones.tif” in tiff format.
Export["cones.tif", gr, "TIFF"];
You can then import the image previously exported with: Import[“cones.tif”].
We are going to show how to export an animation.
First, we create an animation using Manipulate. In later chapters we will see this interesting function in more detail.
example3DAnimation = Manipulate[
Plot3D[{Cos[k x y], Sin[k x y]}, {x, 0, Pi},
{y, 0, Pi}, Filling -> Automatic, PlotRange -> 1], {k, 0, 2}]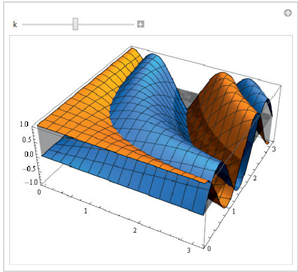
Then, we export it to a video format, in this case avi. (Normally this operation may last a few minutes).
Export["example3DAnimation.avi", example3DAnimation]
example3DAnimation.aviNow we can either manually locate the exported file and open it or call it directly from Mathematica and have the system open it using the default application for avi files.
SystemOpen["example3DAnimation.avi"]
2.3 Descriptive Statistics
When working with big volumes of data, it’s very common to perform a preliminary exploratory data analysis. In this section we are going to see how to do it in Mathematica: tutorial/BasicStatistics.
The command RandomReal[] generates real random numbers that follow a uniform distribution (a distribution returning a fixed value when min < x < max, and 0 when x < min or x > max). In the example below, after clearing the variables from memory as indicated in Section 2.2, we generate two lists with 20 numbers between 0 and 10. To ensure the replicability of the example, we have used SeedRandom [n], with n representing the seed used by the algorithm to generate the random numbers.
Clear["Global` *"]
{data1, data2} = {SeedRandom[314];
RandomReal[10, 20], SeedRandom [312];
RandomReal[10, 20]}
{{9.58927, 8.7557, 5.10411, 3.65071, 3.134, 4.89832,
2.67417, 8.43079, 9.80874, 9.33524, 4.4242, 0.633763, 4.19604,
5.94988, 9.71835, 9.58623, 6.54041, 3.65745, 0.774322, 7.91849},
{4.89057, 9.35402, 2.60879, 3.08132, 7.56905, 9.79594, 4.21418,
8.11898, 9.11195, 0.125038, 4.03004, 2.59509, 7.25321,
2.69409, 3.61778, 9.64948, 3.1916, 2.63862, 3.13724, 6.11095}}
Strictly speaking, we should be talking about pseudorandom numbers since they are generated by algorithms. However, for most practical applications they can be considered in all respects random numbers.
We compute some of the most frequent statistics from the first list (data1). Notice the use of the syntax {f1 [#], ..., fn[#]} &[data1] equivalent to {f1[data1], ..., fn[data1]} to simplify writing. We will learn more about this type of functions, known as pure functions, in the next chapter.
{Mean[#], Variance[#], Skewness[#], Kurtosis[#],
StandardDeviation[#], MeanDeviation[#], MedianDeviation[#],
Quantile[#, .6], InterquartileRange[#]} &[data1]
{5.93901, 9.30229, -0.160336, 1.78156,
3.04997, 2.6243, 2.62292, 6.54041, 5.39139}We calculate the covariance and correlation between the two lists created previously.
{Covariance [data1, data2], Correlation [data1, data2]}
{2.83559, 0.317937}We visualize data1 using Histogram. If you position the cursor inside any of the bars, its value will be displayed.
Histogram[data1, 5]
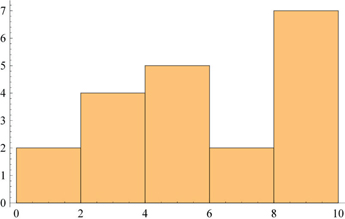
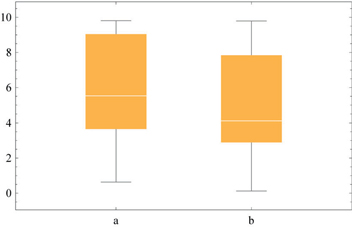
We can also visualize the data using BoxWhiskerChart. When placing the cursor on the boxes you will see the statistical information associated with them.
BoxWhiskerChart[{data1, data2}, ChartLabels →{"a", "b"}]
To create stem-and-leaf plots (StemLeafPlot) we need to load the StatisticalPlots package.
Needs["StatisticalPlots`"]
We create a stem-and-leaf plot to compare both lists.
StemLeafPlot[data1, data2]
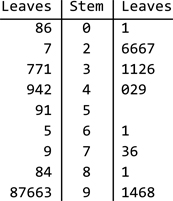
Stem units: 1
Here is an example of data visualization using a bar chart and a pie chart. We display them next to each other horizontally using GraphicsRow.
data3={5, 2, 10, 4, 6};
GraphicsRow[{BarChart[data3], PieChart[data3]}, ImageSize → Small]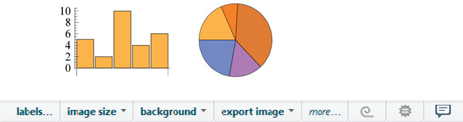
Using the suggestions bar, located below the output, we can assign a light blue background to the previous result:
Show[%, Background → RGBColor[0.84, 0.92, 1.]]
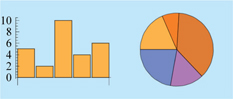
We can also create customized charts as shown next.
We add a label to each bar and choose a color palette (in this case “DarkRainbow”). We also rotate the chart vertically so the frequencies are now displayed in the x-axis.
BarChart[data3, BarOrigin → Left, ChartStyle → "DarkRainbow",
ChartLabels → {"John", "Mary", "Peter", "Michael", "Paula"}]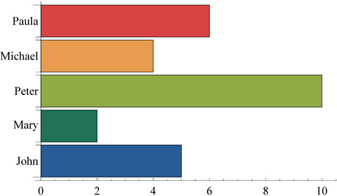
Any image can be used to represent a bar chart.
BarChart[data3, ChartElements →
 ,
,
ChartLabels → {"a", "b", "c", "d", "e"}]
Here we use a figure known as the “Utah Teapot”, included in ExampleData, to make a 3D bar chart.
g = ExampleData[{"Geometry3D", "UtahTeapot"}];
BarChart3D[data3, ChartElements → g, BoxRatios → {4, 1, 1}]
2.4 Application: Analysis of the Evolution of Two Cell Populations
Let’s analyze the evolution over time of two cell populations.
After clearing all the variables from memory (see Section 2.2.), we import the data dropping the extra set of braces {} that we don’t need.
Clear["Global` *"]
cells = Import["cells.xlsx"][[1]]
{{Time, Population 1, Population 2}, {0.5, 0.7, 0.1}, {1., 1.3, 0.2},
{1.5, 1.9, 0.3}, {2., 2.3, 0.4}, {2.5, 2.7, 0.5}, {3., 3., 0.6},
{3.5, 3.3, 0.7}, {4., 3.6, 0.7}, {4.5, 3.8, 0.8}, {5., 4., 0.8},
{5.5, 4.2, 0.9}, {6., 4.3, 1.}, {6.5, 4.4, 1.}, {7., 4.5, 1.1},
{7.5, 4.6, 1.1}, {8., 4.6, 1.2}, {8.5, 4.7, 1.2}, {9., 4.8, 1.3}}We remove the headings and reorganize the data to get two separate lists representing the evolution of the two cell populations.
data = Drop[cells, 1];
{ti, p1, p2} = Transpose[data];
{population1, population2}={Transpose[{ti, p1}], Transpose[{ti, p2}]}
{{{0.5, 0.7}, {1., 1.3}, {1.5, 1.9}, {2., 2.3}, {2.5, 2.7}, {3., 3.},
{3.5, 3.3}, {4., 3.6}, {4.5, 3.8}, {5., 4.}, {5.5, 4.2}, {6., 4.3},
{6.5, 4.4}, {7., 4.5}, {7.5, 4.6}, {8., 4.6}, {8.5, 4.7}, {9., 4.8}},
{{0.5, 0.1}, {1., 0.2}, {1.5, 0.3}, {2., 0.4}, {2.5, 0.5}, {3., 0.6},
{3.5, 0.7}, {4., 0.7}, {4.5, 0.8}, {5., 0.8}, {5.5, 0.9}, {6., 1.},
{6.5, 1.}, {7., 1.1}, {7.5, 1.1}, {8., 1.2}, {8.5, 1.2}, {9., 1.3}}}We plot the evolution of both populations.
ListPlot[{population1, population2}, Joined → True,
PlotLabel -> Style["Cell Populations Evolution", Bold]]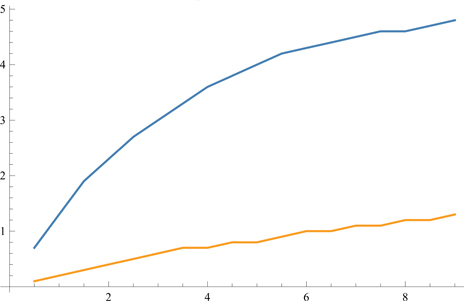
The shape of the curves suggests that they could be approximated by functions of the form: a + b Exp[-kt]. We use the function FindFit to find the best-fit parameters for the fitting functions.
fitpopulation1 = FindFit[population1, a1 + b1 Exp[-k1*t], {a1, b1, k1}, t]
{a1 → 5.11361, b1 → -5.14107, k1 → 0.303326}
fitpopulation2 = FindFit[population2, a2 + b2 Exp[-k2*t], {a2, b2, k2}, t]
{a2 → 1.9681, b2 → -1.9703, k2 → 0.114289}
The next example, showing how to customize a graph, includes options that we haven’t covered yet (we will explain them later in the book). As usual, if any of the instructions is not clear, consult the help by selecting the command and pressing F1. You can use this code as a template for similar cases. Alternatively, you might find it easier to create the labels and plot legends with the drawing tools 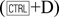 .
.
We display the fitted curves along with the original data after having replaced the symbolic parameters in the curves with the values obtained from FindFit. We also customize the size of the points representing the experimental data. (If you use a version prior to Mathematica 9 you need to load the PlotLegends package first).
fitsol1 = a1 + b1 Exp[-k1*t] /. fitpopulation1;
fitsol2 = a2 + b2 Exp[-k2*t] /. fitpopulation2;
Plot[{fitsol1, fitsol2}, {t, 0, 10}, AxesLabel → {"t( hours)",
"Concentration"}, PlotLegends → Placed[{"Population 1", "Population 2"},
Center], Epilog → {{Hue[0.3], PointSize[0.02], Map[Point,
population1]}, {Hue[0], PointSize[0.02], Map[Point, population2]}},
PlotLabel → Style[Framed["Evolution of 2 cell populations"],
12, Blue, Background → Lighter[Cyan]]]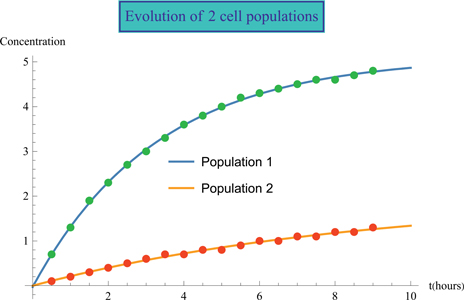
2.5 Application: Global Energy Consumption Analysis
We are going to use what we have learned so far to analyze the evolution of energy consumption globally.
We clear all the variables from memory (see Section 2.2):
Clear ["Global`*"]
The following command will take you to a website that contains the file with historical production data for different types of energy by country and region.
SystemOpen[
"http://www.bp.com/en/global/corporate/energy-economics/statistical-
review-of-world-energy.html"]Download it by clicking on “Statistical Review - Data workbook” and save it without changing its name in the subdirectory Data. The file that we are going to use corresponds to the 2016 (the last one available when this was written) report containing data until the end 2015.
We are going to conduct several studies using this xlsx file. In principle we could directly modify the data using Microsoft® Excel and create a new workbook with only the required information for our analyses. This method would probably be the most suitable one but here, for educational purposes, we will perform all the required transformations in Mathematica. This will help us to have a better understanding of the file manipulation capabilities of the program, although it will require a careful attention to detail.
The file contains many sheets. Before importing it, open the spreadsheet in Excel or any other similar program and examine its contents. Note that each worksheet has a label describing its contents. This is normally very useful.
With the help of the following functions we are going to import part of the file.
We can see the labels for the worksheets by using the argument "Sheets".
Import[
"bp-statistical-review-of-world-energy-2016-workbook.xlsx", {"Sheets"}]
{Contents, Oil – Proved reserves, Oil - Proved reserves history,
Oil Production – Barrels, Oil Production – Tonnes,
Oil Consumption – Barrels, Oil Consumption – Tonnes,
Oil - Regional Consumption, Oil – Spot crude prices,
Oil - Crude prices since 1861, Oil - Refinery throughput,
Oil - Refinery capacities, Oil - Regional refining margins,
Oil - Trade movements, Oil - Inter-area movements,
Oil - Trade 2014 - 2015, Gas – Proved reserves,
Gas - Proved reserves history, Gas Production – Bcm,
Gas Production – Bcf, Gas Production – tonnes, Gas Consumption – Bcm,
Gas Consumption – Bcf, Gas Consumption – tonnes, Gas - Trade - pipeline,
Gas – Trade movements LNG, Gas - Trade 2014-2015, Gas - Prices,
Coal - Reserves, Coal - Prices, Coal Production - Tonnes,
Coal Production - Mtoe, Coal Consumption - Mtoe,
Nuclear Consumption - TWh, Nuclear Consumption - Mtoe,
Hydro Consumption - TWh, Hydro Consumption - Mtoe,
Other renewables - TWh, Other renewables - Mtoe, Solar Consumption - TWh,
Solar Consumption - Mtoe, Wind Consumption - TWh,
Wind Consumption - Mtoe, Geo Biomass Other - TWh,
Geo Biomass Other - Mtoe, Biofuels Production - Kboed,
Biofuels Production - Ktoe, Primary Energy Consumption,
Primary Energy - Cons by fuel, Electricity Generation,
Carbon Dioxide Emissions, Geothermal capacity, Solar capacity,
Wind capacity, Approximate conversion factors, Definitions}
2.5.1 Global Primary Energy Consumption by Source
We analyze the global consumption of primary energy (including all types: electricity, transportation, etc.) in 2015, the last available year in the file, from different sources (oil, gas, hydropower, nuclear, etc.)
From the sheet labels we conclude that the information we want is in the sheet “Primary Energy - Cons by fuel”.
primaryenergyDatabyFuel =
Import["bp-statistical-review-of-world-energy-2016-workbook.xlsx",
{"Sheets", "Primary Energy - Cons by fuel"}];We use TableView to see the imported data. You can either increase the number of visible rows with ImageSize or explore the data like in a spreadsheet, using the slide bars on the right and at the bottom to move around the sheet and clicking on specific cells.
TableView[primaryenergyDatabyFuel]

Notice that the information we want is in row 3 (energy types) and row 89 (the total global consumption, in Million-ton equivalent of petroleum (MTEP) or Million tons of oil equivalent (MTOE)).
{energytype1, mtoe}=
{primaryenergyDatabyFuel[[3]], primaryenergyDatabyFuel[[89]]}
{{Million tonnes oil equivalent, Oil, Natural Gas, Coal,
Nuclear Energy, Hydro electric, Renew- ables, Total, Oil, Natural Gas,
Coal, Nuclear Energy, Hydro electric, Renew - ables, Total},
{Total World, 4251.59, 3081.46, 3911.18, 575.47, 884.288, 316.605,
13 020.6, 4331.34, 3135.21, 3839.85, 583.135, 892.938, 364.861, 13 147.3}}We store the 2015 data, located in columns 9 to 14 and replace the words “Renew- ables” and “Hydro electric” with “Renewables” and “Hydroelectric” respectively.
{energytype, mtoe2015}={energytype1[[9 ;; 14]], mtoe[[9 ;; 14]]}
{{Oil, Natural Gas, Coal, Nuclear Energy, Hydro electric, Renew- ables},
{4331.34, 3135.21, 3839.85, 583.135, 892.938, 364.861}}
{energytype [[5]], energytype[[6]]} = {"Hydroelectric", "Renewables"};We represent the previous data in a bar chart. To see the actual consumption by source, in Mtep, place the cursor in the corresponding bar.
BarChart[mtoe2015, BarOrigin → Left, BarSpacing → None,
ChartStyle → "DarkRainbow", ChartLabels → energytype,
AxesLabel → {Style[ "Energy Type", Bold], Style[ "MTEP", Bold]}]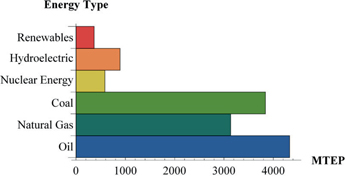
We display the same data in a pie chart including the percentage share of the total for each energy source. Notice that fossil fuels represent the vast majority of the world primary energy consumption with renewables (excluding hydroelectric) playing a very small role (wind, sun, biomass, etc.)
PieChart[mtoe2015/Total[mtoe2015], ChartStyle -> "DarkRainbow",
ChartLabels -> energytype, LabelingFunction →
(Placed [Row[{NumberForm[100#, {3, 1}], "%"}], "RadialCallout"] &),
PlotLabel → Style["Sources of Energy (%)", Bold]]
To highlight an individual source of energy just click on its wedge.
2.5.2 Global Primary Energy Consumption Temporal Evolution
In this section we are going to analyze the evolution of the global primary energy consumption and look for a function that will enable us to extrapolate energy consumption over the coming years.
We import the worksheet “Primary Energy - Consumption ”:
primaryenergyDataYear =
Import["bp-statistical-review-of-world-energy-2016-workbook.xlsx",
{"Sheets", "Primary Energy Consumption "}] ;Below we show the imported data:
TableView[primaryenergyDataYear]
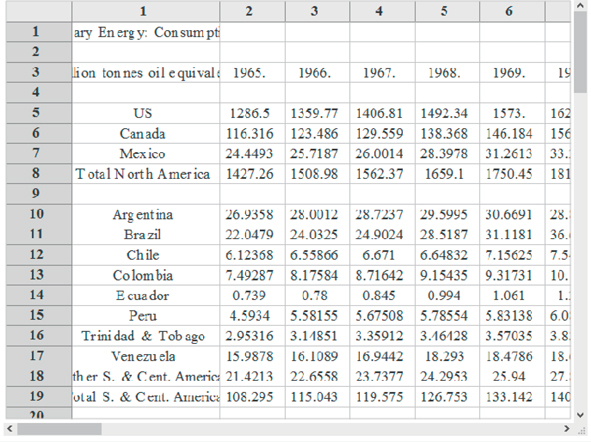
Notice that the desired information is in row 3 (year) and row 90 (Total World, in Mtep). We also eliminate the first and the last two rows since they are not relevant.
primaryevolution =
Drop[Drop[Transpose[primaryenergyDataYear[[{3, 90}]]], 1], -2];We plot the data. Using Tooltip, if you click on a curve point, its value will be shown:
dataplot = ListLinePlot[Tooltip[ primaryevolution],
PlotStyle → PointSize[.01], Mesh → All, AxesLabel → {"Year", "MTEP"},
PlotLabel → Style["Energy Consumption Evolution", Bold]]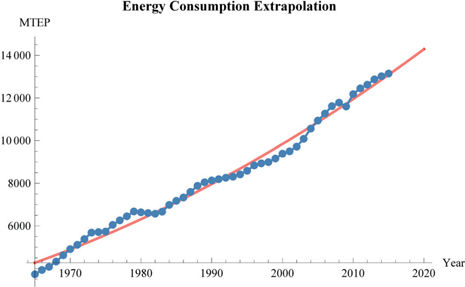
The shape of the data suggests that the growth has been approximately linear, although a polynomial fit could probably generate better results. Here we use Fit (Later, in Section 6.4, we will explain more about fitting). In this case, a polynomial with degree 2 is an appropriate choice.
model = Fit[primaryevolution, {1, t, t^2}, t]
4.20076×106 - 4390.21 t + 1.14738 t2We show both the real data and the fitted curved extrapolated until the year 2020:
Show[
Plot[model, {t, 1965, 2020}, PlotStyle → {Pink, Thick}, PlotRange → All],
dataplot, AxesLabel → {"Year", "MTEP"},
PlotLabel → Style["Energy Consumption Extrapolation", Bold]]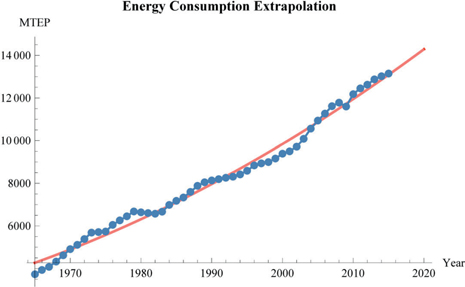
We generate a table that includes: year (t), real consumption (r(t)) and fitted consumption (f(t)). This is done by applying the replacement rule {a, b} → {t, r(t), f(t)} to the data from primaryevolution. We replace t in the object model with a obtaining the fitted value f(t) for each year. We also apply Round to avoid the decimal separator in the last year.
exportData = primaryevolution /. {a_, b_} -> {Round[a], b, model /. t -> a};
We include the data from 2000, that we extract with:
TableForm[exportData [[36 ;; 51]]
, TableHeadings → {None, {"Year", "Consumption\n (MTEP)", "Fit\n(MTEP)"}}]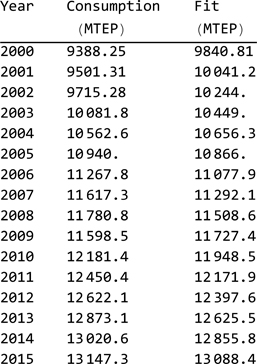
We export, in Excel format, all the data included in exportData to a file named “primaryenergy.xlsx”.
Export["primaryenergy.xlsx", exportData, "XLSX"];
Finally, we open the file we just created (you need to have Excel or other similar application that can open xlsx files).
SystemOpen["primaryenergy.xlsx"]
2.5.3 China Population Forecast
We can use the free-form input to import data. In this example, we use it to forecast China’s population.


Time series data can be fitted using TimeSeriesModelFit.
tsm = TimeSeriesModelFit[%]

Now, the evolution of China’s population over the next 10 years can be estimated using TimeSeriesForecast.
DateListPlot[{tsm["TemporalData"], TimeSeriesForecast[tsm, {10}]},
PlotLegends → {"Historical", "Forecast"},
PlotLabel → Style["Chinese Population", Bold]]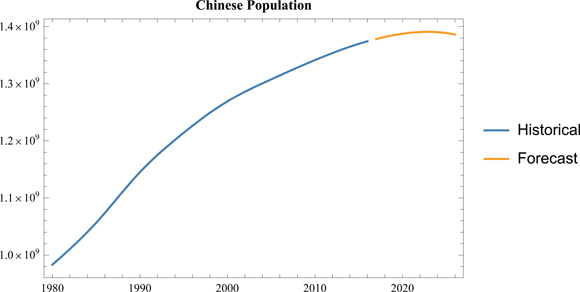
2.6 Database Access with Open Database Connectivity (ODBC)
In this section we are going to learn how to access big databases such as the ones usually found in large organizations nowadays.
To avoid potential problems is better to start a new session by doing any of the following: Close and open Mathematica again; or choose in the menu bar: Evaluation ▶ Quit Kernel ▶ Local; or execute the command below:
Quit []
Access to big databases (ORACLE, SQLServer, etc) installed in servers is usually done through ODBC connections. Mathematica offers the possibility of making such connections using the DatabaseLink package (see help: DatabaseLink/tutorial/Overview).
We are going to use the examples normally found in the Mathematica installation directory. The directory with these examples can be found with FileNameJoin.
FileNameJoin[ {$InstallationDirectory,
"SystemFiles", "Links", "DatabaseLink", "Examples"}]
C:\Program Files\Wolfram
Research\Mathematica\11.0\SystemFiles\Links\DatabaseLink\ExamplesBefore using these examples for the first time they must be installed in:
FileNameJoin[ {$UserBaseDirectory, "DatabaseResources", "Examples"}]
C:\Users\guill\AppData\Roaming\Mathematica\DatabaseResources\ExamplesTo proceed, execute the following instructions. The first one installs them and the second one resets them in case they have been previously modified. Normally you will only have to do this once.
<<DatabaseLink`DatabaseExamples`;
DatabaseExamplesBuild[]
2.6.1 A Basic Example
First we load the package for ODBC connections, containing the JDBC variant:
Needs["DatabaseLink`"]
Then we establish the connection to the desired database.
In this case we are going to connect to the publisher.mdb database included in DatabaseResources /Examples (we write down the complete path to the database for demonstration purposes although it can also be done just by typing: OpenSQLConnection [“publisher”]).
conn =
OpenSQLConnection[ JDBC["hsqldb", FileNameJoin[ {$UserBaseDirectory,
"DatabaseResources", "Examples", "publisher" }] ],
"Name" -> "manualA", "Username" -> "sa"]
Here we show the name of the tables in the database.
SQLTableNames[conn]
{AUTHORS, EDITORS, PUBLISHERS, ROYSCHED,
SALES, SALESDETAILS, TITLEAUTHORS, TITLEDITORS, TITLES}We display the entries in the PUBLISHERS table with their corresponding headings.
SQLSelect[conn, "publishers", "ShowColumnHeadings" → True] // TableForm
PUB_ID PUB_NAME ADDRESS CITY STATE
0736 Second Galaxy Books 100 1st St. Boston MA
0877 Boskone & Helmuth 201 2nd Ave. Washington DC
1389 NanoSoft Book Publishers 302 3rd Dr. Berkeley CA
2.6.2 The Database Explorer
The Database Explorer (Figure 2.1) is a graphical interface used to interact with databases. Sometimes, it may be useful to make a query and later on copy it to a notebook using its capabilities as shown later on in the section. However, we believe it is better in general to use the SQL functions included in DatabaseLink as seen in the previous section.
To launch it you need to use the command DatabaseExplorer[] and use the Connection Tool to select the database:
DatabaseExplorer[]

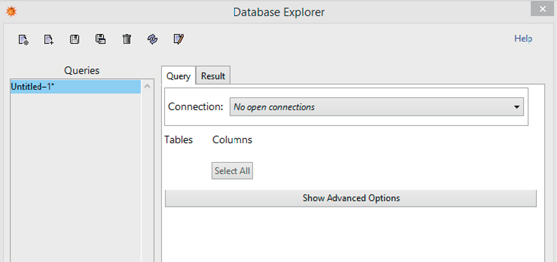
Figure 2.1 The Database Explorer.
After clicking on the icon, the databases available in our system will be shown (Figure 2.2).
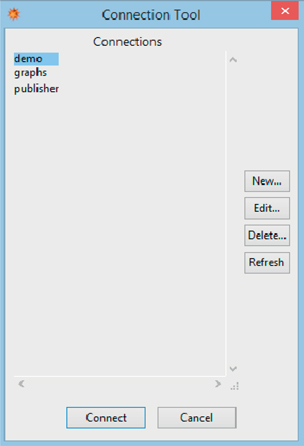
Figure 2.2 The Connection Tool displaying all the databases available in the system.
Once we connect to a database, we will see its tables and columns. In this case we choose publisher and press Connect (Figure 2.3).
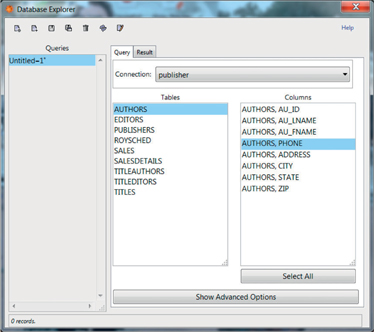
Figure 2.3 Tables and columns of the publisher database.
With Show Advanced Options (the horizontal bar at the bottom in the previous screenshot) you can build advanced queries. However, in this example, to keep things simple, we just select AUTHORS and PHONE in the Columns section and click on Result (Figure 2.4):
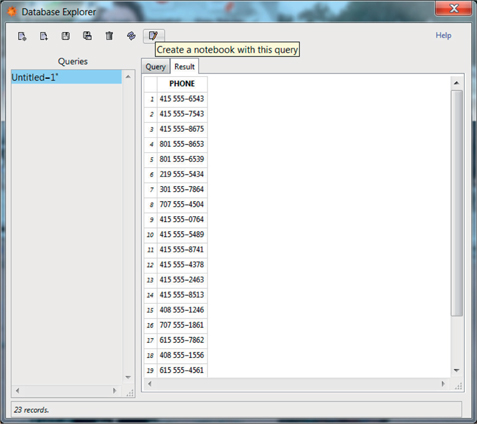
Figure 2.4 Query results.
The query and its result can be saved by clicking on the Create a notebook with this query icon (the right-most icon on the image above).
When pressed, a new Mathematica notebook is generated containing the SQL commands. We have copied the actual contents of the notebook in the next cell.
SQLExecute[SQLSelect["publisher", {"AUTHORS"},
{SQLColumn[{"AUTHORS", "PHONE"}]}, None, "SortingColumns" → None,
"MaxRows" → 100, "Timeout" → 10, "Distinct" → False,
"GetAsStrings" → False, "ShowColumnHeadings" → True]] // TableForm
PHONE
415 555–6543
415 555–7543
415 555–8675
801 555–8653
801 555–6539
219 555–5434
301 555–7864
707 555–4504
415 555–0764
415 555–5489
415 555–8741
415 555–4378
415 555–2463
415 555–8513
408 555–1246
707 555–1861
615 555–7862
408 555–1556
615 555–4561
415 555–4781
415 555–1568
503 555–7865
913 555–0156Finally we need to close the connection.
CloseSQLConnection [conn ];
2.6.3 Connecting to Database Servers
If you want to connect to a server, you will probably need to configure your ODBC connection tool to define the database location. This can be done in Windows XP/Vista/7/8 with: Control Panel ▶ Administrative Tools ▶ Data Sources ( ODBC) (Figure 2.5). If you have access to your organization’s database it should appear in the “User Data Sources:” window and you will be able to connect to it using this interface.

Figure 2.5 The Windows ODBC Data Source Administrator Tool.
In this example we configure the access to a local MS Access database (Figure 2.6).
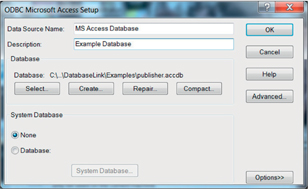
Figure 2.6 Configuring access to a local MS Access database.
Next you will be able to connect to it using Mathematica following a procedure similar to this one:
Needs["DatabaseLink`"]
conn = OpenSQLConnection[JDBC["odbc", "Your DATABASE name"],
"Username" → "Mylogin", "Password" → "Mypassword"]To see the tables in the database type:
SQLTableNames[conn]
Import them or make the necessary queries.
It’s recommended to close the connection at the end.
CloseSQLConnection [conn ];
2.7 Additional Resources
To access the following resources, if they refer to the help files, write their locations in a notebook (e.g., guide/ListManipulation), select them and press <F1>. In the case of external links, copy the web addresses in a browser:
List Manipulation: guide/ListManipulation
Importing and Exporting Data: tutorial/ImportingAndExportingData
Basic Statistics: tutorial/BasicStatistics
Descriptive Statistics: tutorial/DescriptiveStatistics
Continuous Distributions: tutorial/ContinuousDistributions
Discrete Distributions: tutorial/DiscreteDistributions
Convolutions and Correlations: tutorial/ConvolutionsAndCorrelations
How to Do Statistical Analysis: howto/DoStatisticalAnalysis
Curve Fitting: tutorial/CurveFitting
DatabaseLink Tutorial: DatabaseLink/tutorial/Overview