Better methods of deterring webbots are ones that make it difficult for a webbot to operate on a website. Just remember, however, that a determined webbot designer may overcome these obstacles.
Some developers may be tempted to detect their visitors’ web agent names and only serve pages to specific browsers like Internet Explorer or Firefox. This is largely ineffective because a webbot can pose as any web agent it chooses.[85] However, if you insist on implementing this strategy, make sure you use a server-side method of detecting the agent, since you can’t trust a webbot to interpret JavaScript.
As you learned in Chapter 19, obfuscation is the practice of hiding something through confusion. For example, you could use HTML special characters to obfuscate an email link, as shown in Example 30-2.
Example 30-2. Obfuscating the email address me@addr.com with HTML special characters
Please email me at:
<a href="mailto:me@<s></s>addr.com">
me<b></b>@addr <u></u>.com
</a>While the special characters are hard for a person to read, a browser has no problem rendering them, as you can see in Figure 30-2.
You shouldn’t rely on obfuscation to protect data because once it is discovered, it is usually easily defeated. For example, in the previous illustration, the PHP function htmlspecialchars() can be used to convert the codes into characters. There is no effective way to protect HTML through obfuscation. Obfuscation will slow determined webbot developers, but it is not apt to stop them, because obfuscation is not the same as encryption. Sooner or later, a determined webbot designer is bound to decode any obfuscated text.[86]
Lesser webbots and spiders have trouble handling cookies, encryption, and page redirection, so attempts to deter webbots by employing these methods may be effective in some cases. While PHP/CURL resolves most of these issues, webbots still stumble when interpreting cookies and page redirections written in JavaScript, since most webbots lack JavaScript interpreters. Extensive use of JavaScript can often effectively deter webbots, especially if JavaScript creates links to other pages or if it is used to create HTML content. Most of these issues, however, can be overcome using the browser macro techniques discussed in Chapter 24 and Chapter 25.
Where possible, place all confidential information in password-protected areas. This is your best defense against webbots and spiders. However, authentication only affects people without login credentials; it does not prevent authorized users from developing webbots and spiders to harvest information and use services within password-protected areas of a website. You can learn about writing webbots that access password-protected websites in Chapter 20.
Possibly the single most effective way to confuse a webbot is to change your site on a regular basis. A website that changes frequently is more difficult for a webbot to parse than a static site. The challenge is to change the things that foul up webbot behavior without making your site hard for people to use. For example, you may choose to randomly take one of the following actions:
Change the order of form elements.
Change form methods.
Rename files in your website.
Alter text that may serve as convenient parsing reference points, like form variables.
These techniques may be easy to implement if you’re using a high-quality content management system (CMS). Without a CMS, though, it will take a more deliberate effort. Some websites have become very good at this. Craigslist, for example, constantly changes the names of forms and field elements. This doesn’t make the website impossible for a webbot to use, but you will either need to employ smarter scripts that specifically track form element names or use browser macros.
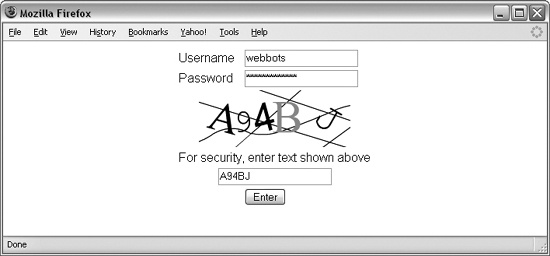
Webbots and spiders rely on text represented by HTML codes, which are nothing more than numbers capable of being matched, compared, or manipulated with mathematical precision. However, if you place important text inside images or other non-textual media like Flash, movies, or Java applets, that text is hidden from automated agents. This is different from the obfuscation method discussed earlier, because embedding relies on the reasoning power of a human to react to his or her environment. For example, it is now common for authentication forms to display text embedded in an image and ask a user to type that text into a field before it allows access to a secure page. While it’s possible for a webbot to process text within an image, it is quite difficult. This is especially true when the text is varied and on a busy background, as shown in Figure 30-3. This technique is called a Completely Automated Public Turing test to tell Computers and Humans Apart (CAPTCHA).[87] CAPTCHAs, like many online obstacles, are easily overcome with services like the CAPTCHA-reading APIs found at http://decaptcher.com. These APIs employ people who read the CAPTCHA image sent to them through the API.
Before embedding all your website’s text in images, however, you need to recognize the downside. When you put text in images, beneficial spiders, like those used by search engines, will not be able to index your web pages. Placing text within images is also a very inefficient way to render text.
[86] To learn the difference between obfuscation and encryption, read Chapter 19.
[87] Completely Automated Public Turing test to tell Computers and Humans Apart (CAPTCHA) is a registered trademark of Carnegie Mellon University.