
FILES: INPUT AND OUTPUT
5.1 What Is a File? A Little “Theory”
5.2 Keyboard Input
5.3 Using Files in Python: Less Theory, More Practice
5.4 Writing To Files
5.5 Summary
In this chapter
In the early days of computing, when a respectable machine would fill a room, the file was invented. It was an obvious thing, really: a package in which to place data on a tape or disk drive. Storage that was not memory, which was pretty fast, was called secondary storage, and was terribly slow compared to how fast a computer could execute instructions (which is terribly slow compared to how fast a modern computer can execute instructions).
Files still exist, and a typical PC has hundreds of thousands of them. The details of how files are implemented is interesting, but unimportant to the discussion of how to use them in Python. The focus will be on how and why to use them effectively.
The first thing to know about a file is that it is a collection of bytes stored on a disk or similar device. One set of bytes can look very much like another, and unless the format of the file (i.e., the way the bytes are ordered) and its basic contents (i.e., what kind of thing the bytes represent) is known ahead of time, the information stored there is unusable. Computer programs are written assuming that the files they will read have a particular nature; if given a file that does not have that nature, the program will not function properly.
What kinds of files are there? Here is a short list:
1. Text files. These contain characters that a person can read, and can be thought of as documents.
2. Executable files. These hold instructions that a computer can execute. Such a file is a program or an “app.”
3. Data files. It could also be a text file if it is stored as characters, but it could be a set of bytes that represent integers or real numbers.
4. Image files. There are many types of image files, and they contain pictures in digital format. Many digital cameras use a format called JPEG, but GIF or PNG are two of many others. Not only are images stored in such a file, but also data about how large the image is, when it was taken, and other details.
5. Sound files. The more common sound file is the MP3, but there are many others.
6. Video. MPEG and AVI are standard formats for video, and there are a great many files of this sort available on the Internet.
7. Web pages. These are a special kind of text file. They can be examined and modified using basic text editors, but can’t be viewed properly (i.e., as a web page) except through a browser, which is really a special kind of display utility that can both draw images and connect to the Internet to download more information.
All of these files, and indeed all files, have certain things in common. Some of these things can be ignored when writing Python programs, but others cannot.
Files have names. The first way to access a file is usually by specifying its name. In human folklore, knowledge of a true name allows one to affect another person or being; knowing something’s true name gives the person power over that thing. So it is with files. Knowing the name of a file is the way to access the information within.
Files have a size. It is usually expressed in bytes, which is to say simple characters. One byte is one traditional alphabetic character, although there are now many standards for characters in German and Swedish and Chinese that break that rule. Knowing how large a file is helps when using it as input, and when writing a file its size grows.
Basic operations on a file are read and write. To read from a file means to examine a byte (at least); usually bytes are read in large blocks for efficiency. This means moving a copy of the bytes from the disk into memory, because a program can only examine data that is in memory. Writing is the reverse process: a byte or bytes are copied from memory onto disk.
Files must be open before they can be used. To open a file a program must know its name, and then invoke the open function or program. If the true name of the file gives you power over it, then open is the spell used to wield that power. Whether a file will be read or written is normally decided at the time the file is opened. The open function and many other file-related operations belong to the operating system of the computer, and not normally to the language. It’s one reason why so much software is not portable.
Only one program at a time can write to a file. Many programs can read a file simultaneously, but only one can write to it, and not while anyone else is reading it. Many computers can have more than one user accessing a file at a time, and the Internet certainly allows many users to access a web page at one time, and a web page is a file. However, chaos ensues if more than one user can change a file at the same moment.
Another thing to consider is that text, and therefore text files, are a principal means for communication between humans and computers. It is critical that any scheme for writing text to a file takes into account the human aspects of text: sentences, lines, paragraphs, special characters, numbers, and so on. This chapter will be concerned with the way in which Python can use files, with files as a concept in general, and with how humans think of data and files.
5.1 WHAT IS A FILE? A LITTLE “THEORY”
The claim in the previous section was that a file is “a collection of bytes stored on a disk or similar device.” This is correct, but it does not have enough detail to enable a programmer to take advantage of the way a file is implemented to create a good program. What is needed is an understanding of the devices that contain files and their advantages and limitations. This information will begin to explain the traditional mechanisms that have evolved for using files from programming languages generally and Python in particular.
The file as a data structure was devised for storing information on tapes and disks. Together with some other devices that are used rarely (e.g., cram files) these are referred to as secondary storage, where primary storage would be computer memory. Memory was (and still is) too expensive to store everything that is needed on a computer, so secondary storage has the advantages of being cheaper than memory and can contain a much larger amount of data. Modern disks can contain Terabytes of data, where one Terabyte (Tb) is 1012 bytes. It has been estimated that a human being’s functional memory is about 1.25 Tb. A Terabyte is a lot of storage.
Most secondary storage devices store data magnetically. Since tapes are rarely seen anymore, the example presented here will be that of a disk. A disk is a circular platter made of glass or ceramic material and coated with a thin layer of magnetic material, often a compound of iron. That’s why they look brown: iron oxide or rust is that color. The disk is mounted on a spindle that is connected to a motor, which spins it at a high rate of speed.
A device called a read/write head is made to sit above the moving disk but very near to it. This device is basically a small piece of magnetizable metal wrapped in a fine wire, not unlike the read/write heads in an old video tape recorder (VCR) or cassette machine. It is a property of magnets and coils that a moving magnet will create (induce) an electric current in a nearby coil, and a coil with a current flowing through it can create a magnetic field.
So, to write data to the moving disk, a current is sent to the read/write head, which creates a small magnetic mark on the disk below the head. Magnets have two orientations; they have a North Pole and a South Pole. Current flowing one way will create a magnet in the disk that has a North Pole appearing before the South Pole, or an N-S mark. Current flowing the other direction through the head will create a magnet on the disk that has the South Pole appearing before the North Pole, or an S-N mark. One orientation, say N-S, will represent a binary number “1,” and the other (S-N) will represent a “0.” In this way, binary numbers can be written to the surface of the moving disk.
Reading numbers involved the magnetic regions of the disk passing quickly past the read/write head and inducing small currents in the coil. These are amplified and classified by a simple electronic circuit that will detect current flow one way as N-S and another way as S-N, thus allowing binary numbers to be read from the disk.

There are some very complicated physics involved in a disk drive. The read/write head must be very close to the surface of a rapidly rotating disk, as close as 3 nanometers. To accomplish this, the head is actually aerodynamically
flying above the disk. If it ever actually touches the disk surface the result is catastrophic. At the speeds involved a large section of the magnetic material on the disk’s surface will be scraped away, and all data there will be lost. In addition, the read/write head will almost certainly be damaged. This event is called a head crash, and normally results in the entire disk drive being ruined. It’s one reason that frequent backup copies of all data should be made.
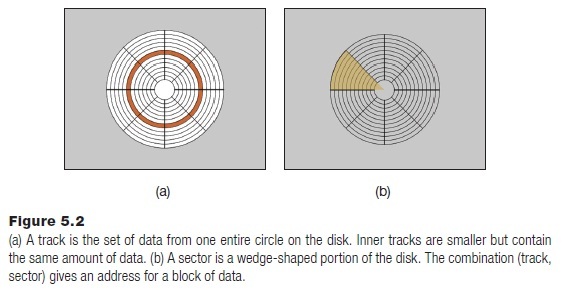
The picture that is developing is that of a device that returns data as a stream of bits. To make best use of the area of the disk, the read/write head can move from the outer edge of the disk to nearly the center. Imagine a set of concentric circles on the disk’s surface: the moving read head can position itself over any of them and read the data that had been written there.
The disk is divided into a set of concentric circles called tracks, each of which corresponds to one position of the read/write head (Figure 5.2a). The head can move across the disk surface, but for obvious reasons the positions are quantized: position 0-Ntracks can be reached through commands to a controller that change the head position. The outermost track is numbered 0, and numbers increase as the head moves inward to the center. The disk is also divided into sectors, each of which is a wedge-shaped portion of the disk (Figure 5.2b). These are again numbered 0 to Nsectors, and create an address for a set of bits. Data can be read from sector 3 track 12 by positioning the read head over track 12 and waiting for sector 3 to rotate into position under the head. The data takes as long to read as the sector takes to pass under the read head.
This description answers two important questions. First, data can be accessed by using the <track, sector> address. The data in a single track and sector is a block, and all blocks are the same size in terms of bits for the sake of convenience, traditionally 512 bytes (4096 bytes for AF drives). Second, it explains why
accessing data takes so long when reading from a disk. Disks rotate at 7200 RPM or 120 revolutions per second; this is one rotation every 8.3 milliseconds.
5.1.1 How Are Files Stored on a Disk?
A file can be thought of as a set of blocks. If blocks are 512 bytes in size and some data to be stored in a file consists of N bytes, then that file will need blocks, the next larger integer than N/512; it’s not possible to have two files share a single block.
It gets more complicated, though, because it will not always be possible to have all of the blocks that belong to a file lie next to each other. A file might consist of many blocks, all of which are some distance apart in terms of their track and sector. There is a need for a data structure to connect these blocks in the correct order to make a file. It’s not very hard to do but is another step. This data structure is written to the disk also. The result is that reading a file means finding the location of this data structure on the disk, getting the track and sector values, and then reading the data from those and copying it into memory. The data structure containing the sectors is usually found through a file name that the user has provided. There is a list of file names and the track/sector address of their index sectors in a special file someplace on the drive, or in many places. File systems tend to be organized hierarchically, so that one main name is accessed to find the files within that part of the disk (directory), and within that directory are names of more files and directories. It is a significant part of the function of an operating system like Linux or Windows to provide a convenient way to access files.
5.1.2 File Access is Slow
How long does it take to access a block of data on the disk? It depends on where the disk head is and where the disk rotation has placed the target block at the time the request is made. There will be only a statistical answer, but for a random block it could take an average of 10 mS to move the head to the correct track (seek time), and will take half of a rotation (4.15 mS). Add to this the time needed to read the block, which is 8.3*1/ Nsectors mS, or about 0.008 mS for a disk with 1024 sectors. This can be ignored, and the time to access a random block can be estimated as 14.15 milliseconds.
As a comparison, fast computer memory can access data within 8 nanoseconds. If a person could write the word “Gigabyte” on a whiteboard in 8 nanoseconds, then what could they do in 14 milliseconds? They could copy the entire Bible onto the board over 16 times. Disk is vastly slower than memory, and in order to use the data it must be copied into memory. This is a bottleneck in many computer systems.
5.2 KEYBOARD INPUT
Reading data from the keyboard is very different from reading data from a file. Files exist before being read, and normally have a fixed size that is known in advance. It is common to know the format of a file, so that the fact that the next datum is an integer and the one following that is a float is often known. When a user is entering data at a keyboard there is no such information available.
In fact, the user may be making up the data as they go along. Before getting too far into file input it is important to understand the kind of errors that can happen interactively.
These are using type errors, where the user enters data that is the wrong type for the programmer to use: a string instead of an integer, for example. This kind of error can arise in file input also if the format is not known in advance.
5.2.1 Problem: Read a Number from the Keyboard and Divide It by 2
In this instance the problem is one of type: how to treat integers like integers and floats like floats. When the string s is read in it’s just a string, and it is supposed to contain an integer. However, users will be users, and some may type in a float by mistake. The program should not crash just because of a simple input mistake. How is this situation handled?
The problem is that when the string is converted into an integer, if there is a decimal point or other non-digit character that does not belong, then an error will occur. It seems that an answer would be to put the conversion into a try statement block and if the string has a decimal point then convert the string to float within the except part. Something like this:
s = input("Input an integer: ")
try:
k = int(s)
ks = k//2
except:
z = float(s)
k = int(z/2)
print (k)
If the user types “12” in response to the prompt “Input an integer:” then the program prints “6.” If the user types “12.5” then the program catches a ValueError, because 12.5 is not a legal integer. The except part is executed, converting the number to floating point, dividing by 2, then finally converting to an integer.
One problem is that the except part is not part of the try, so errors that happen there will not be caught. Imagine that the user types “one” in response to the prompt. The call to int(s) results in a ValueError, and the except part is executed. The statement:
z = float(s)
will result in another ValueError. This one will not be caught and the program will stop executing, giving a message like:
ValueError: could not convert string to float: 'one'
s = input("Input an integer: ")
try:
k = int(s)
k = k//2
except ValueError:
try:
z = float(s)
k = int(z/2)
except ValueError:
k = 0
print (s, k)
5.3 USING FILES IN PYTHON: LESS THEORY, MORE PRACTICE
The general paradigm for reading and writing files is the same in Python as it is in most other languages. The steps for reading or writing a file are these:
1. Open the file. This involves calling a function, usually named open, and passing the name of the file to be used. Sometimes the mode for opening is passed; that is, a file can be opened for input, output, update (both input and output) and in binary modes. The function locates the file using the name and returns a variable that keeps track of the current state of input from the file. A special case exists if there is no file having the given name.
2. Read data from the file. Using the variable returned by open, a function is called to read data. The function might read a character, or a number, or a line, or the whole file. The function is often called read, and can be called multiple times. The next call to read will read from where the last call ended. A special case exists when all of the data has been read from the file (called the end of file condition).
OR
3. Write data to the file. Using the variable returned by open, a function is called to write data to the file. The function might write a character, or a number, or a line, or many lines. The function is often called write, and can be called multiple times. The next call to write will continue writing data from where the last call ended. Writing data most frequently appends data to the end of the file.
4. Close the file. Closing a file is also accomplished using a call to a function (yes, it is usually named close). This function frees storage associated with the input process and in some cases unlocks the file so it can be used by other programs. A variable returned by open is passed to close, and afterwards that variable can’t be used for input anymore. The file is no longer open.
5.3.1 Open a File
Python provides a function named open that will open a file and return a value that can be used to read from or write to the file. That value actually refers to a complex collection of values that refers to the file status and is called a handle or a file descriptor in the computing literature, although knowledge of the details is not needed to use it. It can be thought of as something of type file, and must be assigned to a variable or the file can’t be accessed. The open function is given the name of the file to be opened and a flag that indicates whether the file is to be read from or written to. Both of these are strings. A simple example of a call to open is:
infile = open ("datafile.txt", "r")
This will open a file named “datafile.txt” that resides in the same directory as does the Python program, and opens it for input: the “r” flag means read. It returns the handle to the variable infile, which can now be used to read data from the file.
There are some details that are crucial. The name of the file on most computer
systems can be a path name, which is to say the name including all directory names that are used to find it on your computer. For example, on some computers the name “datafile.txt” might have the complete path name “C:/parker/introProgramming/chapter05/datafile.txt.” If path names are used, the file can be opened from any directory on the computer. This is handy for large data sets that are used by multiple programs, such as names of customers or suppliers.
The read flag “r” that is the second parameter is what was called the mode in the previous discussion. The “r” flag means that the file will be open for reading only, and starts reading at the beginning of the file. The default is to read characters from the file, which is presumed to be a text file. Opening with the mode “rb” opens the file in binary format, and allows reading non-text files, such as MP3 and video files.
Passing the mode “w” means that the file is to be written to. If the file exists, then it will be overwritten; if not, the file will be created. Using “wb” means that a binary file is to be written.
Append mode is indicated by the mode parameter “a,” and it means that the file will be opened for writing; if the file exists, then writing will begin at the end of the existing file. In other words, the file will not start over as being empty but will be added to, at the end of the file. The mode “ab” appends data to a binary file. There are a few other modes that will be discussed when they are needed.
If the file does not exist and it is being opened for input, there is a problem. It’s an error, of course; a nonexistent file can’t be read from. There are ways to tell whether a file exists, and the error caused by a nonexistent file can be caught and handled from within Python. This involves an exception. It is always a bad idea to assume that everything works properly, and when dealing with files it is especially important to check for all likely problems.
File Not Found Exceptions
The proper way to open a file is within a try-except pair of statements. This will ensure that nonexistent files or permission errors are caught rather than causing
the program to terminate. The basic scheme is simple:
try:
infile = open ("datafile.txt", "r")
except FileNotFoundError:
print ("There is no file named ꞌdatafile.txt'. Please try again")
return # end program or abort this
# section of code
The exception FileNotFoundError will be thrown if the file name can’t be found. What to do in that case depends on the program: if the file name was typed in by the user, then perhaps they should get another chance. In any case the file is not open and data can’t be read.
There are multiple versions of Python on computers around the world, and some versions have different names for things. The examples here all use Python 3.4. In other versions the FileNotFoundError exception has another name; it may be IOError or even OSError. The documentation for the version being used should be consulted if a compilation error occurs when using exceptions and some built-in functions. For the 3.4 compiler version, all three seem to work with a missing file.
All attempts to open a file should take place while catching the FileNotFoundError exception.
5.3.2 Reading from Files
After a file is opened with a read mode, the file descriptor returned can be used to read data from the file. Using the variable infile returned from the call to open () above, a call to the method read() can get a character from the file:
s = infile.read(1)
Reading one character at a time is always good enough, but is inefficient. If a block on disk is 512 characters (bytes) then that should be a good number of bytes to read at one time, or a multiple of that. Reading more data than you need and saving it is called buffering, and buffers are used in many instances: live video and audio streaming, audio players, and even in programming language compilers. The idea is to read a larger block of data than is needed at the moment and to hand it out as needed. Reading a buffer could be done as:
s = infile.read(512)
and then dealing characters from the strings one at a time as needed. A buffer is a collection of memory locations that is temporary storage for data that was recently on secondary store.
Text files, those that contain printable characters that humans can read, are normally arranged as lines separated by a carriage return or a linefeed character, something usually called a newline. An entire line can be read using the readline() function:
s = infile.readline()
A line is not usually a sentence, so many lines might be needed to read one sentence, or perhaps only half of a line. Computer text files are structured so that humans can read them, but the structure of human language and convention is not understood by the computer, nor it is built into the file structure. However, it is normal for people to make data files that contain data for a particular item or event on one line, followed by data for the next item. If this is true then one call to readline() will return all of the information for a particular thing.
End of File
When there are no more characters in the file, read() will return the empty string: “”. This is called the end of file condition, and it is important that it be detected. There are many ways to open and read files, but for reading characters in this way the end of file is checked as follows:
infile = open("data.txt", "r")
while True:
c = infile.read(1)
if c == '':
print ("End of file")
exit()
else:
c = infile.read(1)
When reading a file in a for statement, the end of file is handled automatically. In this case the loop runs from the first line to the final line and then stops.
for c in f:
print ("'", c, "'")
Oddly an exception can’t be used in an obvious way for handling the end of file on file input. However, when reading from the console using the input() function the exception EOFError can be caught:
while True:
try:
c = input()
print (c)
except EOFError:
print ("Endfile")
break
There are many errors that could occur for any set of statements. It is possible to determine what specific exception has been thrown in the following manner:
while True:
try:
c = input()
print (c)
except Exception as x:
print (x)
break
This code prints “EOF when reading a line” when the end of file is encountered.
Common File Input Operations
There are a few common ways to use files that should be mentioned as patterns. Although one should never use a pattern if it is not understood, it’s sometimes handy to have a few simple snippets of code that are known to perform basic tasks correctly. For example, one common operation to use with files is to read each line from a file, followed by some processing step. This looks like:
f = open ("data.txt", "r")
for c in f:
print ("'", c, "'")
f.close()
The expression c in f results in consecutive lines being read from the files into a string variable c, and this stops when no more data can be read from the file.
Another way to do the same thing would be to use the readline() function:
f = open ("data.txt", "r")
c = f.readline()
while c != '':
print ("'", c, "'")
c = f.readline()
f.close()
In this case the end of file has to be determined explicitly, by checking the string value that was read to see if it is null.
Another common file operation is to copy a file to another, character by character. A file is opened for input and another for output. The basic “read a file” pattern is used, with the addition of a file output after each character is read:
f = open ("data.txt", "r")
g = open ("copy.txt", "w")
c = f.read(1)
while c != '':
g.write(c)
c = f.readline(1)
f.close()
g.close()
A filter is a program that reads data from a file and converts it to some other form, then writes it out. This is often done from standard input and output, but can be done in the middle of a file copy. For example, to convert a text file to all lowercase, the pattern above is used with a small modification:
f = open ("data.txt", "r")
g = open ("copy.txt", "w")
c = f.read(1)
while c != '':
g.write(c.lower())
c = f.readline(1)
f.close()
g.close()
This filter can be done in less code if the entire file can be read in at once. The read() function can read all data into a string.
f = open ("data.txt", "r")
g = open ("copy.txt", "w")
c = f.read()
g.write(c.lower())
f.close()
g.close()
Two files can be merged into a single file in many ways: one file after another, a line from one file followed by a line from another, character by character, and so on. A simple merging of two files where one is copied first followed by the other is:
f = open ("data1.txt", "r")
outfile = open ("copy.txt", "w")
c = f.read()
outfile.write(c)
f.close()
g = open ("data2.txt", "r")
c = g.read()
outfile.write(c)
g.close()
outfile.close()
A more complex problem occurs when both files are sorted and are to remain sorted after the merge. If each line is in alphabetical order in each file then merging them means reading a line from each and writing the one that is smallest. When one file is complete, the remainder of the second file is written and all files are closed.
f = open ("data1.txt", "r")
g = open ("data2.txt", "r")
outfile = open ("copy.txt", "w")
cf = f.readline()
cg = g.readline()
while cf!="" and cg!="":
if cf<cg:
outfile.write(cf)
cf = f.readline()
else:
outfile.write(cg)
cg = g.readline()
if cf == "":
outfile.write(cg)
cg = g.read()
outfile.write(cg)
else:
outfile.write(cf)
cf = f.read()
outfile.write (cf)
f.close()
g.close()
outfile.close()
Copying the input from console to a file means reading each line using input() and writing it to the file. This code assumes that an empty input line implies that the copying is complete.
outfile = open ("copy.txt", "w")
line = input ("! ")
while len(line)>1 or line[0]!="!":
outfile.write(line)
outfile.write ("\n")
line = input("! ")
outfile.close()
The end of the line is indicated by a character, which is represented by the string “\n.” Reading characters from a file will read the end of line character also, and detecting it can be very important.
f = open ("data.txt", "r")
c = f.read(1)
while c != '':
print ("'", c, "'")
c = f.read(1)
if c == '\n':
print ("Newline")
CSV Files
A very common format for storing data is called Comma Separated Variable (CSV) format, named for the fact that each pair of data items have a comma between them. CSV files can be used directly by spreadsheets such as Excel and by a large collection of data analysis tools, so it is important to be able to read them correctly.
A simple CSV file named planets.txt is provided for experimenting with reading CSV files. It contains some basic data for the planets in Earth’s solar system, and while there is no actual standard for how CSV files must look, this one is typical of what is usually seen. The first line in the file contains headings for each of the variables or columns, separated by commas. This is followed by nine lines of data, one for each planet. It’s a small data file as these things are counted, but illustrative for the purpose. Here it is:
Problem: Print the Names of Planets Having Fewer Than Ten Moons
This is not a very profound problem, and uses the raw data as it appears on the file. The file must be opened and then each line of data is read, the value of the 11th data element (i.e., index 10) retrieved and compared against 10. If larger, the name of the planet (index 0) is printed. The plan is:
Open the file
Read (skip over) the header line
For each planet
Read a line as string s
Break s into components based on commas giving list P
If P[10] < 10 print the planet name, which is P[0]
It is all something that has been done before except for breaking the string into parts based on the comma. Fortunately, the designers of Python anticipated this kind of problem and have provided a very useful function: split(). This function breaks up a string into parts using a specified delimiter character or string and returns a list in which each component is one section of the fractured string. For example:
s = "This is a string"
z = s.split(" ")
yields the list z = [“This”, “is”, “a”, “string”]. It splits the string s into substrings at each space character. A call like s.split(“,”) should give substrings that are separated by a comma. Given the above sketch and the split() function, the code now pretty much writes itself.
try:
# Open the file
infile = open ("planets.txt", "r")
# Read (skip over) the header line
s =infile.readline()
# For each planet
for i in range (0, 8):
# Read a line as string s
s = infile.readline()
# Break s into components based on commas giving list P
P = s.split (",")
# If P[10] < 10 print the planet name, which is P[0]
if int(P[10])<10:
print (P[0], " has fewer than 10 moons.")
except FileNotFoundError:
print ("There is no file named 'planets.txt'. Please try again")
Things to notice: almost the entire program resides within a try statement, so that if the file does not exist, then a message will be printed and the program will end normally. Also note that P[10] has to be converted into an integer, because all components of the list P are strings. Strings are what has been read from the file.
CSV files are common enough so that Python provides a module for manipulating them. The module contains quite a large collection of material, and for the purposes of the planets.py program only the basics are needed. To avoid the details of a general package, a simpler version is included with this book: simpleCSV has the essentials needed to read most CSV files while being written in such a way that a beginning programmer should be able to read and understand it.
To use it, the simpleCSV module is first imported. This makes two important functions available: nextRecord() and getData(). The nextRecord() function reads one entire line of CSV data. It allows skipping lines without examining them in detail (like headers). The function getData() will parse one line of data, the last one read, into a tuple, each element of which is one of the comma-separated fields.

The simpleCSV library needs to be in the same directory as the program that uses it, or be in the standard Python directory for installed modules. The source code resides on the accompanying disc
and is called simpleCSV.py. The program above can be rewritten to use the simpleCSV module as follows:
import simpleCSV
try: # Read (skip over) the header line
infile = open ("planets.txt", "r")# Open the file
simpleCSV.nextRecord(infile) # Read the header
for i in range (0, 8): # For each planet
simpleCSV.nextRecord(infile) # Read a line and
# collect substrings
# in a list
p = simpleCSV.getData(infile)
if int(P[10])<10: # If number of moons less
# than 10
print (P[0], " has fewer than 10 moons.")
# print the planet name
except FileNotFoundError:
print ("There is no file named 'planets.txt'. Please try again")
Problem: Play Jeopardy Using a CSV Data Set
The television game show Jeopardy has been on the air for 35 years in one of its two incarnations, and is perhaps the best known such program on television. Players select a topic and a point value and are asked a trivia question that they must answer in the form of a question. There are sets of questions that have been used in Jeopardy over the years, some in CSV form, so it should be possible to stage a simulated game using Python as the moderator.
A simple version of the game could work like this: read a bunch of questions and answers, and select questions at random to ask. Questions that have single word unambiguous answers would be best. The player types in an answer and wins if they answer ten correctly before getting three wrong.
A single line of data from the file might look like this:
5957,2010-07-06,Jeopardy!,"LETꞌS BOUNCE","$600","In this kid’s game, you bounce a small rubber ball while picking up 6-pronged metal objects","jacks"
There are 7 different data fields here separated by commas. They are: Show Number, Air Date, Round, Category, Value, Question, and Answer; all are strings, but some questions may contain commas. The CSV module can deal with that.
There are many ways that a random question can be chosen. One would be to read all of the data into a list, but that would require a lot of memory. One way would be to randomly read a question from the file, but that would be hard to do because each line has a different length. What could be done relatively easily would be to pick a random number of questions to skip over before reading one to use. So, select a random number K between N and M, read K questions, and the read the next one and ask the user that question. When the end of the file is reached, it can be read again from the beginning. If the file is large enough it would be unlikely to ask the same question twice in a short time period.
Here is a sketch of how this might work:
Open infile as the file of questions to be used
While game continues:
Select a random number K between N and M
For I = N to M:
Read a line from the file
If no more lines:
Close infile and reopen
Read a question and print it, ask the user for an answer
Read the user’s answer from the keyboard
If the user’s answer is correct:
Count right answers
Else:
Count wrong answers
If the CSV module is used, the parsing of the input file is dealt with. What is new about this? When all of the data in the file has been used, the program may not be complete. What is done then is new: close the file, reopen it, and start again from the beginning. This is an unusual action for a Python program, but illustrates the flexibility of the file system. There is a nested try-except pair, the outer one that checks the existence of the file of questions and the inner one that checks for the end of the file. When the file is reopened a new reader has to be created, because the old one is connected to a closed file. The file on the disk is the same, but when it is opened again a new handle is built; the old CSV reader is linked to the old handle.
The program counts the number of right answers (CORRECT) and the number of wrong ones (INCORRECT). When there are 10 correct answers or 3 incorrect ones, the game is over; a variable again is set to False and the main while loop exits. A break could have been used, but having the condition become False is the polite way to exit from a while loop.
The entire program looks like this:
# Jeopardy!
import simpleCSV, random
try:
infile = open ("q.txt", "r") # Open the file
simpleCSV.nextRecord(infile) # Read (skip over) the
# header line
CORRECT = 0
INCORRECT = 0
again = True
while again:
k = random.randint (5, 10) # How many questions to
# skip?
for i in range (0, k):
if not simpleCSV.nextRecord(infile):
# Skip this question
infile.close()
print ("Reopening")
infile = open ("JEOPARDY_small.txt", "r")
simpleCSV.nextRecord(infile)
s = simpleCSV.getData(infile) # Read the question
# to be asked.
print (s[5]) # Print the question
a = input () # Read the answer
if a.lower() == s[6].lower(): # Does player answer
# agree?
CORRECT = CORRECT + 1 # Yes. count to 10.
if CORRECT >= 10:
print ("You win!")
again = False
else:
INCORRECT = INCORRECT + 1 # No. Count to 3
print ("Sorry. The answer is ", s[6])
if INCORRECT > 12:
print ("You lose.")
again = False
except FileNotFoundError:
print ("There is no question file. We can't play.")
The With Statement
A difficulty with the code presented so far is that it does not clean up after itself. A file should be closed after input from it or output to it is finished; none of the programs written so far do that, at least not after the file operations are complete. There has been no significant discussion of the close() operation, but what it does has been described. Normally when a program terminates, its resources are returned to the system, including the closing of any open files. Intentionally closing a file is important for three reasons: first, if the program aborts for some reason, open files should be closed by the system but may not be, and file problems can be the result. Second, as in the Jeopardy program, closing a file can be used as a step in re-using it. Opening it again starts reading it at the beginning. Third, closing a file frees its resources. Programs that use many files and/or many resources will profit from freeing them when they are no longer needed.
The Python with statement, in its simplest form, takes care of many of the details surrounding file access. An example of its use is:
try:
with open ("planets.txt") as infile: # Open the file
simpleCSV.nextRecord(infile) # Read the header
for i in range (0, 9): # For each planet
simpleCSV.nextRecord(infile) # Read a line,
# make a list
P = simpleCSV.getData(infile)
if int(P[10])<10: # If number of moons
# less than 10
print (P[0], " has fewer than 10 moons.")
# print the name
except FileNotFoundError:
print ("There is no file named 'planets.txt'. Please try again")
Once the file is open, the with statement guarantees that certain errors will be dealt with and the file will be closed. The problem is that the file has to be open first, so the FileNotFound error should still be caught as an exception.
5.4 WRITING TO FILES
The first step in writing to a file is opening it, but this time for output:
outfile = open ("out.txt", "w")
The “w” as the second parameter to open() means to open the file for writing. When writing to a file it is important to note that opening it will create a new file by default. If a file with the given name already exists it will be rewritten, and the previous contents will be gone.
The basic file output function is write(); it takes a parameter, a string to be written to the file. It only writes strings, so numbers and other types have to be converted into strings before being written. Also, there is no concept of a line. This function simply moves characters to a file, one at a time, in the order given. In order to write a line, an end of line character has to be written. This is usually specified in a string as “\n,” spoken as “backslash n.” The “n” stands for newline.
Example: Write a Table of Squares to a File
This will illustrate the typical code involved in writing to a file. The file must be opened, then a loop from 0 to 25 is constructed. Each number in that range is written to the file, as is that number multiplied by itself. Each output string represents a line, and so must have a newline character added to the end.
outfile = open ("out.txt", "w")
outfile.write (" X X squared \n")
for i in range (0, 25):
sout = " "+str(i)+" "+str(i*i)+"\n"
outfile.write (sout)
outfile.close()
Note that the integers are explicitly converted into strings and concatenated into a line to be written. The elements of the line could be written in separate calls to write:
outfile = open ("out.txt", "w")
outfile.write (" X X squared \n")
for i in range (0, 25):
outfile.write (" ")
outfile.write (str(i))
outfile.write (" ")
outfile.write (str(i*i))
outfile.write ("\n")
outfile.close()
The output file is closed after all data has been written.
5.4.1 Appending Data to a File
Opening the file in “w” mode starts writing at the beginning of the file, and will result in existing data being lost. This is not always desirable. For example, what if a log file is being created? The log should contain a record of everything that has happened, not just the most recent thing.
Opening the file in append mode, signified by the parameter “a,” opens the file for output and starts writing at the end of the file if it already exists. This means that data can be added to the end of an existing file.
Example: Append Another 20 Squares to the Table of Squares File
The previous example created a file named “out.txt” and wrote 26 lines to it. It was a table of squares, and the final one was 24. This example will therefore begin at 25 and add 20 more values to the table.
The main difference is the opening of the output file in append mode, and starting the loop at 25 instead of at 0:
outfile = open ("out.txt", "a")
for i in range (25, 45):
sout = " "+str(i)+" "+str(i*i)+"\n"
outfile.write (sout)
outfile.close()
The file “out.txt” will contain the squares of the integer between 0 and 44 inclusive after this program runs.
5.5 SUMMARY
Files are computer structures within which data are stored, and almost always reside on disk devices, tape devices, or other secondary storage. Files have some common properties: files have names; files have a size; basic operations on a file are read and write; files must be open before they can be used; only one program at a time can write to a file. Access to data on a file is much slower than access to data in memory, but file data has to be moved into memory before it can be manipulated.
Exceptions are events that occur while a program is executing, such as dividing by zero. Rather than check for all possible exceptions every time a statement is executed, Python provides a try-except statement that allows the programmer to provide code to run when an error occurs. Specific named exceptions exist in Python that can be specifically caught, like ValueError, or all exceptions can be caught by not specifying a particular one.
Files are opened using a call to open passing a file name and a mode. If the mode is “r” then the file will be read from; if it is “w” it will be written to. Example: x = open(“input.txt”, “r”). Reading from a file x is accomplished by a read call: x.read(n) will return a string of n characters; x.readline() will return one line from the file x. When there are no more characters in the file read() will return the empty string: “”. This is called the end of file condition, and it is important that it be detected.
A CSV (comma separated values) file is a specific format that is common for some kinds of data, including spreadsheets. The simpleCSV package provided on the accompanying disc can be helpful in reading these files.
Output to a file x is done with a call to write: x.write(s) writes the string s to the file represented by x. The string “\n” represents the end of a line.
|
NOTE |
This chapter will be extended in Chapter 8 to expand the kind of file operations and data that can be read from and written to a file. |
Exercises
1. Write a program that reads a file name from the user (console) and prints out how many characters belong to that file.
2. Write a program that opens a file containing a list of file names. For each one print the file name followed by YES if that file exists in the current directory and NO if it does not.
3. Create a file copy facility. The program to be written reads the name of a file from the user console and creates another file with the same contents. If the original file is named “xx.txt” then the new file will be named “xx-copy.txt.” The original file will always have a name ending in “.txt,” and so will the copy.
4. The CSV file “avatardata.csv” contains saved information concerning the preferred avatars for players of a video game. The fields are: player code (integer), avatar type (string, no quotes), number of times this avatar was played at this level (integer), a game level reached (integer, out of 12), and the highest score achieved on this level (integer); there is no header. Read this file and determine and print which player/avatar has the highest score on each level.
5. Using a Python program, create a CSV file from “avatardata.csv” that contains only information for level 10.
6. In an HTML file (i.e., a web page) an image to be displayed is usually identified in a source tag of the form: src=“name.jpg.” The quotes are a part of the tag, and the text between them is an image file name. Write a program that reads an HTML file and prints the names of all of the image files that it references.
7. A user will specify the name of an image file (i.e., a file name that ends in “.jpg,” “.gif,” or “.png”) from the console. Your program will read this name and create “disp.html,” an html file that, when opened by a browser, will display this image (requires a knowledge of basic HTML).
8. Two files, named sorted1.txt and sorted2.txt, contain numeric data that appear in the file in sorted ascending order (when looked at as a string). Merge these two files to create a single file having the data of both, also in sorted order.
Notes and Other Resources
Python CSV Library: https://docs.python.org/3/library/csv.html
1. Remzi Arpaci-Dusseau and Andrea Arpaci-Dusseau. (2015). Operating Systems: Three Easy Pieces, Amazon Digital Services, Inc.
2. Daniel P. Bovet and Marco Cesati. (2005). Understanding the Linux Kernel, O’Reilly Media.
3. Dominic Giampaolo. (1999). Practical Filesystem Design, Morgan Kaufmann Publishers, Inc., http://www.nobius.org/~dbg/practical-file-system-design.pdf, www.nobius.org/~dbg/practical-file-system-design.pdf
4. Robert Stetson. (2013). How Disk Drives Work, CreateSpace Independent Publishing Platform.
5. Jeopardy questions may be found at https://docs.google.com/uc?id=0BwT5wj_P7BKXUl9tOUJWYzVvUjA&export=download