
MANIPULATING DATA
8.1 Dictionaries
8.2 Arrays
8.3 Formatted Text, Formatted I/O
8.4 Advanced Data Files
8.5 Standard File Types
8.6 Summary
In this chapter
A fair definition of Computer Science would be the discipline that concerns itself with information. Computers are an enabling technology, but computer science is largely about how to store, retrieve, represent, compress, display, transmit, and otherwise handle information. Python happens to be pretty good at offering facilities for manipulating information or, at a lower level, data. Data becomes information when a person can interpret it, and information becomes knowledge once understood.
Repeating a theme of this book, data on a computer is stored as numbers no matter what its original form was. Computers can only operate on numbers, so an important aspect of using data is the representation of complex things as numbers. Based on many years of experience, it seems to be possible in all cases, and the manner in which the data is represented as numbers is reflected in the methods used to operate on them.
This chapter will be an examination of how certain kinds of data are represented and the consequences insofar as computer programs can use these data. Python in particular will be used for this examination, although some of the discussion is more general. Of course, the discussion will be driven by practical things and by how things can be accomplished using Python.
Most data consist of measurements of something, and as such are fundamentally numeric. Astronomers measure the brightness of stars, as an example, and note how they vary or not as a function of time. The data consists of a collection of numbers that represent brightness on some arbitrary scale; the units of measurements are always in some sense arbitrary. However, units can be converted from one kind to another quite simply, so this is not a problem. Biologists frequently count things, so again their data is fundamentally numeric. Social scientists ask questions and collect answers into groups, again a numeric result. What things are not?
Photographs are common enough in science and are not numeric values but are, instead, visual; they relate to a human sense that can be understood by other humans easily, rather than to an analytical approach. Of course most photographs are ultimately analyzed by a computer these days, so there must be a way to represent them digitally. Another human sense that is used to examine data is hearing. Birds make songs that indicate many things, including what they observe and their willingness to mate. Sounds are vibrations, and can indicate problems with machinery, the approach of a vehicle, the presence of a predator, or the current state of the weather. Touch is less often used, but is essential in the control of objects by humans. A person controlling a device at a great distance can profit from the ability to feel the touch of a tool across a computer network.
Then there are search engines, which can be thought of as an extension of human memory and reasoning. The ability of humans to access information has improved hugely over the past twenty years. If the phrase “python data manipulation” is entered into the Google search engine, over half a million results are returned. True, many may not directly relate to the query as it was intended, but part of the problem will be in the phrasing of the request. By the way, the first response to the query concerns the pandas module for data analysis, which may in fact have been the right answer.
How is all of this done? It does take some clever algorithms and good programming, but it also requires a language that offers the right facilities.
8.1 DICTIONARIES
A Python dictionary is an important structure for dealing with data, and is the only important language feature that has not been discussed until now. One reason is that a dictionary is more properly an advanced structure that is implemented in terms of more basic ones. A list, for example, is a collection of things (integers, reals, strings) that is accessed by using an index, where the index is an integer. If the integer is given, the contents of the list at that location can be retrieved or modified.
A dictionary allows a more complex, expensive, and useful indexing scheme: it is accessed by content. Well, by a description of content at least. A dictionary can be indexed by a string, which in general would be referred to as a key, and the information at that location in the dictionary is said to be associated with that key. An example: a dictionary that returns the value of a color given the name. A color, as described in Chapter 7, is specified by a red, green, and blue component. A tuple such as (100,200,100) can be used to represent a color. So in a dictionary named colors the value of colors[“red”] might be (255,0,0) and colors[“blue”] is (0,0,255). Naturally, it is important to know what names are possible or the index used will not be legal and will cause an error. So colors[“copper”] may result in an index error, which is called a KeyError for a dictionary.
The Python syntax for setting up a dictionary differs from anything that has been seen before. The dictionary colors could be created in this way:
colors = {'red':(255, 0, 0), 'blue':(0,0,255), 'green':(0,255,0)}
The braces { … } enclose all of the things being defined as part of the dictionary. Each entry is a pair, with a key followed by a “:” followed by a data element. The pair “red”:(255,0,0) means that the key “red” will be associated with the value (255,0,0) in this dictionary.
Now the name colors looks like a list, but is indexed by a string:
print (colors['blue'])
The index is called a key when referring to a dictionary. That’s because it is not really an index, in that the string can’t directly address a location. Instead the key is searched for, and if it is a legal key (i.e., has been defined) the corresponding
data element is selected. The definition of colors creates a list of keys and a list of data:

When the expression colors[“blue”] is seen, the key “blue” is searched for in the list of all keys. It is found at location 1, so the result of the expression is the data element at 1, which is (0,0,255). Python does all of this work each time a dictionary is accessed, so while it looks simple it really involves quite a bit of work.
New associations can be made in assignment statements:
colors['khaki'] = (240,230,140)
Indeed, a dictionary can be created with an empty pair of braces and then have values given using assignments:
colors = {}
colors['red'] = (255, 0, 0)
. . .
As with other variables, the value of an element in a dictionary can be changed. This would change the association with the key; there can only be one thing associated with a key. The assignment:
colors['red'] = (200.,0,0)
reassigns the value associated with the key “red.” To delete it altogether use the del() function:
del(colors['blue'])
Other types can be used as keys in a dictionary. In fact, any immutable type can be used. Hence it is possible to create a dictionary that reverses the association of name to its RGB color, allowing the color to be used as the key and the name to be retrieved. For example:
names = {}
names[(255,0,0)] = 'red'
names[(0,255,0)] = 'green'
This dictionary uses tuples as keys. Lists can’t be used because they are not immutable.
8.1.1 Example: A Naive Latin – English Translation
A successful language translation program is difficult to implement. Human languages are unlike computer languages in that they have nuances. Words have more than one meaning, and many words mean essentially the same thing. Some words mean one thing in a particular context and a different thing in another context. Sometimes a word can be a noun and a verb. It is very confusing. What this program will do is substitute English words for Latin ones, using a Python dictionary as the basis.
From various sites on the Internet a collection of Latin words with their English counterparts has been collected. This is a text file named “latin.txt.” It has the Latin word, a space, and the English equivalent on single lines in the file. The program will accept text from the keyboard and translate it into English, word by word, assuming that it originally consisted of Latin words. The file of Latin words has 3129 items, but it should be understood that one word in any language has many forms depending on how it is used. Many words are missing in one form or another.
The way the program works is pretty simple. The file of words is read in and converted into a dictionary. The file has a Latin word, a comma, and an English word, so a line is read, converted to a tuple using split(), and the Latin word is used as a key to store the English word into the dictionary.
Next, the program asks the user for a phrase in Latin, and the user types it in. The phrase is split into individual words and each one is looked up in the dictionary and the English version is printed. This will not work very well in general, but is a first step in creating a translation program. The code looks like this:
def load_words (name, dict): | # Read the file of words |
f = open (name, "r") | |
s = f.readline() | # Read one word pair |
while s != "": | # exit when the file has been |
| # read |
c = s.split (",") | # Split at the comma |
if len(c)<2: | # Possible error: no words? |
s = f.readline() | # Read next and continue |
continue | |
sw = c[0].strip() | # Get the latin and English |
| # words. |
ew = c[1].strip() | |
if len(ew) <=0: | # OK? |
s = f.readline() | # Nope. Just skip it. |
continue | |
if ew[-1] == "\n": | # Get ride of the endline |
ew = ew[0:-2] | |
dict[sw] = ew | # Place in dictionary |
s = f.readline() | # Next word pair from the file |
f.close() | # Always close when done |
| |
dict = {} | |
load_words("latin.txt", dict) | # Read all of the word pairs |
| |
inp = input("Enter a latin phrase ") | # Get the Latin text |
while inp != "": | # Done? |
book = inp.split(" ") | # Split at words |
for i in range(0,len(book)): | # For each word this line |
sword = book[i].lower() | # Lower case |
try: | |
enword = dict[sword] | # Look up Latin word |
print (enword, end="") | # Print English version |
except: | |
print (sword, end="") | # Latin not in |
| # dictionary |
print (" ", end="") | # Print the Latin |
print (".") | |
inp = input("Enter a latin phrase ") | # Do it again |
Of course translation is more complex than just changing words, and that’s all this program does. Still, sometimes it does not do too badly. A favorite Latin phrase from the TV program The West Wing is “Post hoc ergo propter hoc.” Given this phrase the program produced:
after this therefore because of this.
which is a pretty fair translation. Trying another, “All dogs go to heaven” was sent to an online translation program and it gave
omnes canes ad caelum ire conspexerit
This program here translates it back into English as:
“all dogs to sky go conspexerit.”
The word ‘conspexerit’ was not successfully translated, so it was left as it was (the online program translates that word as “glance”). This is still not terrible.
Sadly, it makes a complete hash of the Lord’s Prayer:
Pater noster qui es in caelis sanctificetur nomen tuum.
Adveniat regnum tuum.
Fiat voluntas tua sicut in caelo et in terra.
Panem nostrum quotidianum da nobis hodie et dimitte nobis debita nostra sicut et nos dimittimus debitoribus.
Fiat voluntas tua sicut in caelo et in terra.
Amen
Is turned into:
father our that you are against heavens holy name your.
down rule your.
becomes last your as against heaven and against earth.
bread our daily da us day and dimitte us debita our as and us forgive debtors.
becomes last your as in heaven and in earth.
amen
A useful addition to the code would be to permit the user to add new words into the dictionary. In particular, it could prompt the user for words that it could not find, and perhaps even ask whether similar words were related to the unknown one, such as “dimittimus” and “dimitte.” Of course, being able to have some basic understanding of the grammar would be better still.
8.1.2 Functions for Dictionaries
The power of the store-fetch scheme in the dictionary is impressive. There are some methods that apply mainly to dictionaries and that can be useful in more complex programs. The method keys() returns the collection of all of the keys that can be used with a dictionary. So:
list(dict.keys())
is a list of all of the keys, and this can be searched before doing any complex
operations on the dictionary. The list of keys is not in any specific order, and if they need to be sorted then:
sorted(dict.keys())
will do the job. The del() method has been used to remove specific keys but dict.clear() will remove all of them.
The method setdefault() can establish a default value for a key that has not been defined. When an attempt is made to access a dictionary using a key, an error occurs if the key has not been defined for that dictionary. This method makes the key known so that no error will occur and a value can be returned for it; None, perhaps.
dict.setdefault(key, default=None)
Other useful functions include:
| dict.copy() | returns a (shallow) copy of dictionary |
| dict.fromkeys() | creates a new dictionary setting keys and values; e.g., dict.fromkeys( (“one”, “two”), 3) creates {(“one”, 3), (“two”, 3)} |
| dict.items() | returns a list of dict’s (key, value) tuple pairs. |
| dict.values() | returns list of dictionary dict’s values |
| dict.update(dict2) | adds the key-value pairs from dictionary dict2 to dict |
The expression key in dict is True if the key specified exists in the dictionary dict.
8.1.3 Dictionaries and Loops
Dictionaries are intended for random access, but on occasion it is necessary to scan through parts or all of one. The trick is to create a list from the pairs in the dictionary and then loop through the list. For example:
for (key,value) in dict.items():
print (key, " has the value ", value)
The keys are given in an internal order which is not alphabetical. It is a simple matter to sort them, though:
for (key,value) in sorted(dict.items()):
print (key, " has the value ", value)
By converting the dictionary pairs in a list, any of the operations on lists can be applied to a dictionary as well. It is even possible to use comprehensions to initialize a dictionary. For example
d = {angle:sin(radians(angle)) for angle in (0,45.,90., 135., 180.)}
creates a dictionary of the sines of some angles indexed by the angle.
8.2 ARRAYS
For programmers who have used other languages, Python lists have many of the properties of an array, which in C++ or Java is a collection of consecutive memory locations that contain the same type of value. Lists may be designed to make operations such as concatenation efficient, which means that a list may not be the most efficient way to store things. A Python array is a class that mimics the array type of other languages and offers efficiency in storage, exchanging that for flexibility.
Only certain types can be stored in an array, and the type of the array is specified when it is created. For example:
data = array('f', [12.8, 5.4, 8.0, 8.0, 9.21, 3.14])
creates an array of 6 floating point numbers; the type is indicated by the “f” as the first parameter to the constructor. This concept is unlike the Python norm of types being dynamic and malleable. An array is an array of one kind of thing, and an array can only hold a restricted set of types.
The type code, the first parameter to the constructor, can have one of 13 values, but the most commonly used ones will be:
“b” A C++ char type
“B” A C++ unsigned char type
“i”: A C++ int type
“l”: A C++ long type
“f ”: A C++ float type
“d”: A C++ double type
Arrays are class objects and are provided in the built-in module array, which must be imported:
from array import array
An array is a sequence type, and has the basic properties and operations that Python provides all sequence types. Array elements can be assigned to and can be used in expressions, and arrays can be searched and extended like other sequences. There are some features of arrays that are unique:
| frombytes (s) | The string argument s is converted into byte sequences and appended to the array. |
| fromfile(f, num) | Read num items from the file object f and append them. An integer, for example, is one item. |
| fromlist (x) | Append the elements from the list x to the array. |
| tobytes() | Convert the array into a sequence of bytes in machine representation. |
| tofile(f) | Write the array as a sequence of bytes to the file f. |
In most cases arrays are used to speed up numerical operations, but they can also be used (and will be in the next section) to access the underlying
representations of numbers.
8.3 Formatted Text, Formatted I/O
There is a generally believed theory among many users of data, including some engineers and financial analysts, that if numbers line up in nice columns then they must be correct. This is obviously not true, but appearances can matter a great deal, and numbers that do not line up properly for easy reading look sloppy and give people the impression that they may not be as carefully prepared as they should have been. The Python print() function as used so far simply prints a collection of variables and constants with no real attention to a format. Each one is printed in the order specified with a space between them. Sometimes that’s good enough.
The Python versions since 2.7 have incorporated a string format() method that allows a programmer to specify how values should be placed within a string. The idea is to create a string that contains the formatted output, and then print the string. A simple example is:
s = "x={} y={}"
fs = s.format (121.2, 6)
The string fs now contains “x=121.2 y=6.” The braces within the format string s hold the place for a value. The format() method lists values to be placed into the string, and with no other information given it does so in order of appearance, in this case 121.2 followed by 6. The first pair of braces is replaced by the first value, 121.2, and the second pair of braces is replaced by the second value, which is 6. Now the string fs can be printed.
This is not how it is usually done, though. Because this is usually part of the output process, it is often placed within the print() call:
print ("x={} y={}".format(121.2, 6) )
where the format() method is referenced from the string constant. No actual formatting is done by this particular call, merely a conversion to string and a substitution of values. The way formatting is done depends on the type of the value being formatted, the most common types being strings, integers, and floats. An example will be illuminating.
8.3.1 Example: NASA Meteorite Landing Data
NASA publishes a huge amount of data on its web sites, and one of these is a collection of meteorite landings. It covers many years and has over 4800 entries. The task assigned here is to print a nicely formatted report on selected parts of the data. The data on the file has its fields separated by commas, and there are ten of them: name, id, nametype, recclass, mass, Fall, year, reclat, reclong, and GeoLocation. The report requires that the name, recclass, mass, reclat and reclong be arranged in a nicely formatted set of columns.
Reading the data is a matter of opening the file, which is named “met.txt,” and calling readline(), then creating a list of the fields using split(“,”). If this is done and the fields are simply printed using print(), the result is messy. An abbreviated example is (simulated data):
infile = open ("met.txt", "r")
inline = infile.readline()
inlist = inline.split(",")
mass = float(inlist[4])
lat = float(inlist[7])
long = float(inlist[8])
print (inlist[0], inlist[3], inlist[4], inlist[7],
inlist[8])
inline = infile.readline()
infile.close()
The result is, as predicted, messy:
Ashdon H5 121.13519985254874 89.85924301385958 -126.27404435776049
Arbol Solo H6 66.94777134343516 25.567048824444797 160.58088365396014
Baldwyn L6 47.6388587105465 -7.708508536783924 -81.22266156597777
Ankober L6 15.265523451122064 -32.01862330869428 102.31244557598723
Ankober LL6 57.584802700693885 -84.85880091616322 106.31130649523368
Ash Creek L6 62.130089525516155 76.02832670618457 -140.03422105516938
Almahata Sitta LL5 30.476879105555653 -12.906745404586 47.411816322674
Nothing lines up in columns, and the numbers show an impossible degree of precision. Also there should be headings.
The first field to be printed is called name, and is a string; it is the name of the location where the observation was made. The print statement simply adds a space after printing it, and so the next thing is printed immediately following it. Things do not line up. Formatting a string for output involves specifying how much space to allow and whether the string should be centered or aligned to the left or right side of the area where it will be printed. Applying a left alignment to the string variable named placename in a field of 16 characters would be done as follows:
ꞌ{:16s}ꞌ.format(placename)
The braces, which have previously been empty, contain formatting directives. Empty braces mean no formatting, and simply hold the place for a value. A full format could contain a name, a conversion part, and a specification:
{ [name] [‘!’ conversion] [‘:’ specification] }
where optional parts are in square brackets. Thus, the minimal format specification is ‘“{}.” In the example “{:16s}” there is no name and no conversion parts, only a specification. After the “:” is ‘16s,’ meaning that the data to be placed here is a string, and that 16 characters should be allowed for it. It will be left aligned by default, so if placename was “Atlanta,” the result of the formatting would be the string “Atlanta ,” left aligned in a 16-character string. Unfortunately, if the original string is longer than 16 characters it will not be truncated, and all of the characters will be placed in the resulting string even if it makes it too long.
To right align a string, simply place a “>” character immediately following the “:”. So:
“{:>16s}”.format(“Atlanta”)
would be “ Atlanta.” Placing a “<” character there does a left alignment (the default) and “^” means to center it in the available space. The alignment specifications apply to numbers as well as strings.
The first two values to be printed in the example are the city name, which is in inlist[0] and the meteorite class which is inlist[3]. Formatting these is done as follows:
s = '{:16s} {:10s}'.format(inlist[0], inlist[3])
Both strings will be left aligned.
Numeric formats are more complicated. For integers there is the total space to allow, and also how to align it and what to do with the sign and leading zeros. The formatting letter for an integer is “d”, so the following are legal directives and their meaning:
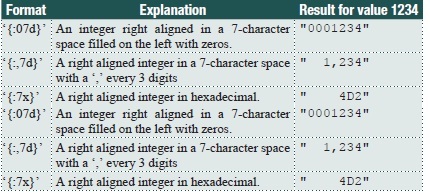
Floating point numbers have the extra issue of the decimal place. The format character is often “f,” but it can be “e” for exponential format or “g” for general format, meaning the system decides whether to use “f ” or “e.” Otherwise, the formatting of a floating point is like that of previous versions of Python and like that of C and C++:

The next three values to be printed are floating point: the mass of the meteorite and the location, as latitude and longitude. Printing each of these as 7 places, 2 to the right of the decimal, would seem to work. Or, as a format: “{:7.2f}.”
The solution to the problem is now at hand. The data is read line by line, converted into a list, and then the fields are formatted and printed in two steps:
infile = open ("met.txt", "r")
inline = infile.readline()
print (" Place Class Mass Latitude
Longitude")
while inline !="":
inlist = inline.split(",")
mass = float(inlist[4])
lat = float(inlist[7])
long = float(inlist[8])
print('{:16s} {:14s} {:7.2f}'.format(inlist[0],
inlist[3],mass),end="")
print (' {:7.2f} {:7.2f}'.format(lat, long))
inline = infile.readline()
infile.close()
The result is:
|
Place |
Class |
Mass |
Latitude |
Longitude |
|
Bloomington |
L5 |
13.58 |
9.53 |
-150.85 |
|
Bogou |
LL6 |
121.09 |
-66.28 |
-53.08 |
|
Alessandria |
L4 |
106.11 |
63.68 |
10.96 |
|
Bo Xian |
L5 |
85.92 |
0.33 |
-50.28 |
|
Ashdon |
Eucrite-mmict |
6.59 |
-88.22 |
-178.84 |
|
Berduc |
L6 |
111.76 |
-64.20 |
107.10 |
|
. . . |
||||
There are many more formatting directives, and a huge number of their combinations.
8.4 ADVANCED DATA FILES
File operations were discussed Chapter 5, but the discussion was limited to files containing text. Text is crucial because it is how humans communicate with the computer; people are unhappy about having to enter binary numbers. On the other hand, text files take up more space than needed to hold the information they do. Each character requires at least one byte. The number 3.1415926535 thus takes up 12 bytes, but if stored as a floating point number it needs only 4 or 8 depending on precision.
The file system on most computers also permits a variety of operations that have not been discussed. This includes reading from any point in a file, appending data to files, and modifying data. The need for processing data effectively is a main reason for computers to exist at all, so it is important to know as much as possible about how to program a computer for these purposes.
8.4.1 Binary Files
A binary file is one that does not contain text, but instead holds the raw, internal representation of its data. Of course, all files on a computer disk are binary in the strict sense, because they all contain numbers in binary form, but a binary file in this discussion does not contain information that can be read by a human. Binary files can be more efficient that other kinds, both in file size (smaller) and the time it takes to read and write them (less). Many standard files types, such as MP3, exist as binary files, so it is important to understand how to manipulate them.
Example: Create a File of Integers
The array type holds data in a form that is more natural for most computers than a list, and also has the tofile() method built in. If a collection of integers is to be written as a binary file, a first step is to place them into an array. If a set of 10000 consecutive integers are to be written to a file named “ints,” the first step is to import the array class and open the output file. Notice that the file is open in “wb” mode, which means “write binary”:
from array import array
output_file = open('ints', 'wb')
Now create an array to hold the elements and fill the array with the consecutive integers:
arr = array('i')
for k in range (10000, 20000):
arr.append(k)
Finally, write the data in the array to the file:
arr.tofile(out)
out.close()
This file has a size listed as 40kb on a Windows PC. A file having the same integers written as text is 49kb. This is not exactly a huge saving of space, but it does add up.
Reading these values back is just as simple:
inf = open ('ints', 'rb')
arrin = array('i')
for k in range (0, 10001):
try:
arrin.fromfile(inf, 1)
except:
break
print (arrin[k])
inf.close()
The try is used to catch an end of file error in cases where the number of items on the file is not known in advance. Or just because always doing so is a good idea.
Sometimes a binary file will contain data that is all of the same type, but that situation is not very common. It is more likely that the file will have strings, integers, and floats intermixed. Imagine a file of data for bank accounts or magazine subscriptions; the information included will be names and addresses, dates, financial values, and optional data, depending on the specific situation. Some customers have multiple accounts, for example. How can binary files be created that contain more than one kind of information? By using structs.
8.4.2 The Struct Module
The struct module permits variables and objects of various types to be converted into what amounts to a sequence of bytes. It is a common claim that this is in order to convert between Python forms and C forms, because C has a struct type (short for structure). However, many files exist that consist of mixed-type data in raw (i.e., machine compatible) form that have been created by many programs in many languages. It is possible that C is singled out because the name struct was used.
Example: A Video Game High Score File
Video game players need little incentive to try hard to win a game, but for many years a special reward has been given to the better players. The game
“remembers” the best players and lists them at the beginning and end of the game. This kind of ego boost is a part of the reward system of the game. The game program stores the information on a file in descending order of score. The data that is saved is usually the player’s name or initials, the score, and the date. This mixes string with numeric data.
Consider that the player’s name is held in a variable name, the score is an integer score, and the date is a set of three strings year, month, and day. In this situation the size of each value needs to be fixed, so allow 32 characters for the name, 4 for year, 2 for month, and 2 for day. The file was created with the name first, then the score, then the year, month, and day. The order matters because it will be read in the same order that it was written. On the file the data will look like this:
| cccccccccccccccccccccccccccccccc | iiii | cccc | cc | cc |
| Player’s name | Score | Year | Month | Day |
Each letter in the first string represents a byte in the data for this entry. The ‘c’s represent characters; the ‘i’s represent bytes that are part of an integer. There are 44 bytes in all, which is the size of one data record, which is what one set of related data is generally called. A file contains the records for all of the elements in the data set, and in this case a record is the data for one player, or at least one time that the player played the game. There can be multiple entries for a player.
One way to convert mixed data like this into a struct is to use the pack() method. It takes a format parameter first, which indicates what the struct will consist of in terms of bytes. Then the values are passed that will be converted into components of the final struct. For the example here the call to pack() would be:
s = pack ("32si4s2s2s", name, score, year, month, day)
The format string is “32si4s2s2s”; there are 5 parts to this, one for each of the values to be packed:
32s is a 32-character long string. It should be of type bytes.
i is one integer. However, 2i would be two integers, and 12i is 12 integers.
4s is a 4-character long string.
2s is a 2-character long string.
Other important format items are:
c is a character
f is a float
d is a double precision float
The value returned from pack() has type bytes, and in this case is 44 bytes long. The high score file consists of many of these records, all of which are the same size. A record can be written to a file using write(). So, a program that writes just one such record would be:
from struct import *
f = open ("hiscores", "wb")
name = bytes("Jim Parker", 'UTF-8')
score = 109800
year = b"2015"
month = b"12"
day = b"26"
s = pack ("32si4s2s2s", name, score, year, month, day)
f.write(s)
Reading this file involves first reading the string of bytes that represented a data record. Then it is unpacked, which is the reverse of what pack() does, and the variables are passed to the unpack() function to be filled with data. The unpack() method takes a format string as the first parameter, the same kind of format string as pack() uses. It will return a tuple. An example that reads the record in the above code would be:
from struct import *
f = open("hiscores", "rb")
s = f.read(44)
name,score,year,month,day = unpack("32si4s2s2s", s)
name = name.decode("UTF-8")
year = year.decode("UTF-8")
month = month.decode("UTF-8")
day = day.decode("UTF-8")
The data returned by unpack are bytes, and need to be converted into strings before being used in most cases. Note the input mode on the open() call is “rb,” read binary.
A file in this format has been provided, and is named simply ‘hiscore.’ When a player plays the game they will enter their name; the computer knows their score and the date. A new entry must be made in the ‘hiscore’ file with this new score in it. How is that done?
Start with the new player data for Karl Holter, with a score of 100000. To update the file it is opened and records are read and written to a new temporary file (named “tmp”) until one is found that has a smaller score than the 100000 that Karl achieved. Then Karl’s record is written to the temporary file, and the remainder of ‘hiscores’ is copied there. This creates a new file named “tmp” that has Karl’s data added to it, and in the correct place. Now that file can be copied to “hiscores” replacing the old file, or the file named “tmp” can be renamed as “hiscores.” This is called a sequential file update.
Renaming the file requires access to some of the operating system functions in the module os; in particular:
os.rename ("tmp", "hiscores")
8.4.3 Random Access
It seems natural to begin reading a file from the beginning, but that is not always necessary. If the data that is desired is located at a known place in the file, then the location being read from can be set to that point. This is a natural consequence of the fact that disk devices can be positioned at any location at any time. Why not files too?
The function that positions the file at a specific byte location is seek():
f.seek(44) # Position the file at byte 44,
# which is the second record in the hiscores
# file.
It’s also possible to position the file relative to the current location:
f.seek(44, 1) # Position the file 44 bytes from this
# location,
# which skips over the next record in
# hiscores.
A file can be rewound so that it can be read over again by calling f.seek(0), positioning the file at the beginning. It is otherwise difficult to make use of this feature unless the records on the file are of a fixed size, as they are in the file ‘hiscores,’ or the information on record sizes is saved in the file. Some files are intended from the outset to be used as random access files. Those files have an index that allows specific records to be read on demand. This is very much like a dictionary, but on a file. Assuming that the score for player Arlen Franks is needed, the name is searched for in the index. The result is the byte offset for Arlen’s high score entry in the file.
Arlen’s record starts at byte 352 (8th record * 44 bytes). He just played the game again and improved his score. Why not update his record on the file? The file needs to be open for input and output, so mode “rb+,” meaning open a binary file for input and output, would work in this case. Then position the file to Arlen’s record, create a new record, and write that one record. This is new—being able to both read and write the same file seems odd, but if the data being written is exactly the same size as the record on the file then no harm should come from it. The program is:
# read and print hiscore file
from struct import *
f = open ("hiscores", "r+b") # Open binary file,input and
# output
pos = 44*8 # Desired record is 8, 44
# bytes per
f.seek(pos) # Seek to that position one
# the file
s = f.read(44) # Read the target record
name = bꞌArlen Franksꞌ # Make a new one with a new
# score
score = 100300
year = bꞌ2015ꞌ
month = bꞌ12ꞌ
day = bꞌ26ꞌ # Pack the new data
ss = pack("32si4s2s2s", name,score, year,month,day)
f.seek (44*8) # Seek the original position
# again!
f.write(ss) # Write the new data over
# the old
f.close () # Close the file
This works fine, provided that the position of Arlen’s data in the file is known. It does not maintain the file in descending order, though.
Example: Maintaining the High Score File in Order
The circumstances of the new problem are that a player only appears in the high score file once and the file is maintained in descending order of score. If a player improves their score, then their entry should move closer to the beginning of the file. This is a more difficult problem than before, but one that is still practical. So, presume that a player has achieved a new score. The entire process should be:
|
Get the player’s old score. |
Read the file, get the player’s record, unpack it. |
|
Is the new score larger? |
If not, close the file. Done. |
|
Yes, so find out where the score |
Look at successively preceding records until one is found that has a larger score. |
|
Place the new record where it belongs. |
Copy the records from the new position for the record ahead one position until the old position is reached. |
The process is like moving a playing card closer to the top of the deck while leaving the other cards in the same order. It’s probably more efficient to move the record while searching for the correct position, though. Each time the previous record is examined, if it does not have a larger score then the record being placed is copied ahead one position. This results in a pretty compact program, given the nature of the problem, but it is a bit tricky to get right. For example, what if the new score is the highest? What if the current high score gets a higher score? (See: Exercise 11)
8.5 STANDARD FILE TYPES
Everyone’s computer has files on it that the owner did not create. Some have been downloaded; some merely came with the machine. It is common practice to associate specific kinds of files, as indicated initially by some letters at the end of the file name, with certain applications. A file that ends in “.doc,” for example, is usually a file created by Microsoft Word, and a file ending in “.mp3” is usually a sound file, often music. Such files have a format that is understood by existing software packages, and some of them (“.gif”) have been around for thirty years.
Each file type has been designed to make certain operations easy, and to pass certain information to the application. Over the years a set of de facto standards have evolved for how these files are laid out, and for what data are provided for what kinds of file. And yet most users and many programmers do not understand how these files are structured or why. Many users do not care, of course, and some programmers too, but opening up these files to some scrutiny is an educational experience.
8.5.1 Image Files
Images have been processed using computers since the 1960s when NASA started processing images at the Jet Propulsion Laboratory. After some years people (scientists, mainly) decided that having standards for computer images would be useful. The first formats were ad hoc, and based essentially on raw pixel data. Raw data means knowing what the image size is in advance, so headers were introduced providing at least that information, leading to the TARGA format (.tga) and tiff (Tagged Image File Format) in the mid-1980s. When the Internet and the World Wide Web became popular, the GIF was invented, which compressed the image data. This was followed by JPEG and other formats that could be used by web designers and rendered by browsers, and each had a specific advantage. After all, reducing size meant reducing the time it took to download an image.
Once a file format has been around for a few years and has become successful it tends to stick around, so many of the image file formats created in the 1980s are still here in one form or another. There are new ones too, like PNG (Portable Network Graphics), which have been specifically designed for the Internet. Older ones (like JPEG) have found common uses in new technologies, like digital cameras. A programmer/computer scientist needs to know about the nature of the various formats, their pros and cons as it were.
8.5.2 GIF
The Graphics Interchange Format is interesting from many perspectives. First, it uses compression to reduce the size of the file, but the compression method is not lossy, meaning that the image does not change after being compressed and then decompressed. The compression algorithm used is called LZW, and will be discussed in Chapter 10. GIF uses a color map representation, so an element in the image is not a color, but instead is an index into an array that holds the color. That is, if v = image[row][column] then the color of that pixel is (red[v], green[v], blue[v]). The color itself could be a full 24 bits, but the value v is a byte, and so in a GIF there can only be 256 distinct colors. GIF uses a little-endian representation, meaning that the least significant byte of multi-byte objects comes first on the file.
One advantage of the GIF is that one of the colors can be made transparent. This means that when this color is drawn over another, the color below shows through. It is essentially a “do not draw this pixel” value. It is important for things like sprites in computer games. Another advantage of GIF is that multiple images can be stored in a single file, allowing an animation to be saved in a single file. GIF animations have been common on the Internet for many years, and while they usually represent small, brief animations such as Christmas trees with flashing lights, they can be as long and complex as television programs. Still, the fact that there can only be 256 different colors can be a problem.
A GIF is a binary file, but the first six characters are a header block containing what is called a magic number, or an identifying label. For a GIF file the three characters are always “GIF” and the next three represent the version; for the 1989 standard the first six characters are “GIF89a.” Magic numbers are common in binary files, and are used to identify the file type. The file name suffix does not always tell the truth.
Following the header is the logical screen descriptor, which explains how much screen space the image requires. This is seven bytes:
| Canvas width | 2 bytes |
| Canvas height | 2 bytes |
| Packed byte | 1 byte |
A set of flags and small values
| Bit | 8 | 7 6 5 | 4 | 3 2 1 |
| Global | color | sort | size of | |
| Color | resolution | flag | global color | |
| Table? | table |
| Background color index | 1 byte |
| Pixel aspect ratio | 1 byte |
This is followed by the global color table, other descriptors, and the image data. The details can be found in manuals and online. The information in the first few bytes is critical, though, and the knowledge that LZW compression is used means that the pixels are not immediately available. Decompression is done to the image as a whole.
from struct import *
f = open ("test.gif", "rb")
s = f.read (13) # Read the header
id, ht, wd, flags, bci,par = unpack('6shhBBB', s)
#6s h h B B B
f.close()
id = id.decode("utf-8")
print (id)
print ("Height", ht, "Width", wd)
print("Flags:", flags)
print ("Background color index: ", bci)
print ("Pixel aspect ratio:", par)
8.5.3 JPEG
A JPEG image uses a lossy compression scheme, and so the image is not the same after compression as it was before compression. For this reason it should never be used for scientific or forensic purposes when measurements will be made using the image. It should never be used for astronomy, for example,
although it is perfectly fine for portraits and landscape photographs.
The name JPEG is an acronym for the Joint Photographic Experts Group, and actually refers to the nature of the compression algorithm. The file format is an envelope that contains the image, and is referred to as JFIF (JPEG File Interchange Format). The file header contains 20 bytes: the magic number is the first 4 and bytes 6–10. The first 4 bytes are hex FF, D8, FF, and E0. Bytes 6–10 should be “JFIF\0,” and this is followed by a revision number. A short program that decodes the header is:
from struct import *
f = open ("test.jpg", "rb")
s = f.read (20) # Read the header
b1, b2,a1,a2,sz,id,v1, v2,unit,xd,yd, xt,yt = unpack('BBBBh5sBBBhhBB', s)
#B B B B h 5s B B B h h B B
f.close()
id = id.decode("utf-8")
print (id, "revision", v1, v2)
if b1==0xff and b2==0xd8:
print ("SOI checks.")
else:
print ("SOI fails.")
if a1==0xff and a2==0xe0:
print ("Application marker checks.")
else:
print("Application marker fails.")
print ("App 0 segment is", sz, "bytes long.")
if unit == 0:
print ("No units given.")
elif unit == 1:
print ("Units are dots per inch.")
elif unit == 2:
print ("Units are dots per centimeter.")
if unit==0:
print ("Aspect ratio is ", xd, ":", yd)
else:
print ("Xdensity: ", xd, " Ydensity: ", yd)
if xt==0 and yt==0:
print ("No thumbnail")
else:
print ("Thumbnail image is ", xt, "x", yt)
The compression scheme used in JPEG is very involved, but is does cause certain identifiable artifacts in an image. In particular, pixels near edges and boundaries are smeared, essentially averaging values across small regions
(Figure 8.1). This can cause problems if a JPEG image is to be edited, for example in Photoshop or Paint.

8.5.4 TIFF
The Tagged Image File Format has a potentially huge amount of metadata associated with it, and that is all in text form in the file. It’s a favorite among scientists because of that: the device used to capture the image, the focal length of the lens, time, subject, and scores of other information can accompany the image. In fact, the TIFF has been seconded for use with numeric non-image data as well. The other reason it is popular is that is can be used with uncompressed (raw) data.
The word Tagged comes from the fact that information is stored in the file using tags, such as might be found in an HTML file—except that the tags in a TIFF are not in text form. A tag has four components: an ID (2 bytes, what tag is this?), a data type (2 bytes, what type are the items in this tag?), a data count
(4 bytes, how many items?), and a byte offset (4 bytes, where are these items?). Tags are identified by number, and each tag has a specific meaning. Tag 257 means Image Height and 256 is Image Width; 315 is the code meaning Artist, 306 means Date/Time, and 270 is the Image Description. They can be in any order. In fact, the whole file structure is flexible because all components are referenced using a byte offset into the file.
A TIFF begins with an 8-byte Image File Header (IFH):
Byte order: This is 2 bytes, and is “II” if data is in little-endian form and “MM” if it is big-endian.
Version Number: Always 42.
First Image File Directory offset: 4 bytes, the offset in the file of the first
image.
The other important part of a TIFF is the Image File Directory (IFD), which contains information about the specific image, including the descriptive tags and data. The IFH is always 8 bytes long and is at the beginning of the file. An IFD can be almost any size and can be anywhere in the file; there can be more than one, as well. The first IFD is found by positioning the file to the offset found in the IFH. Subsequent ones are indicated in the IFD. The IFD stricture is:
Number of tags: 2 bytes
Tags: Array of tags, size unknown
Next IFD offset: 4 bytes. File offset of the next IFD. If there are no more,
then =0.
The structure of a tag was given previously, so a TIF is now defined. The image data can be, and frequently is, raw pixels, but can also be compressed in many ways as defined by the tags.
The program below reads the IFH and the first IFD, dumping the information to the screen:
# TIFF
from struct import *
f = open ("test.tif", "rb")
s = f.read (8) # Read the IFH
id, ver, off = unpack('2shL', s)
#2s h L
id = id.decode("utf-8")
print ("TIFF ID is ", id, end="")
if id == "II":
print ("which means little-endian.")
elif id == "mm":
print ("which means big-endian")
else:
print ("which means this is not a TIFF.")
print ("Version", ver)
print("Offset", off)
f.seek(off) # Get the first IFD
n = 0
b = f.read (2) # Number of tags
n = b[0] + b[1]*256
#n = int(s.decode(“utf-8”))
for i in range(0,n):
s = f.read (12) # Read a tag
id,dt,dc,do = unpack ("hhLL", s)
print ("Tag ", id, "type", dt, "count", dc, "Offset", do)
f.close()
When this program executes using “test.tif” as the input file, the first two tags in the IFD are 256 and 257 (width and height) which are correct.
8.5.5 PNG
A PNG (Portable Network Graphics) file consists of a magic number, which in this context is called a signature and consists of 8 bytes, and a collection of chunks, which resemble TIFF tags. There are 18 different kinds of chunk, the first of which is an image header. The Signature is always: 137 80 78 71 13 10 26 10. The bytes 80 78 71 are the letters “PNG.”
A chunk has either 3 or 4 fields: a length field, a chunk type, an optional chunk data field, and a check code based on all previous bytes in the chunk that is used to detect errors (called a cyclic redundancy check, or CRC).
The image header chink (IHDR) has the following structure:
| Image width: | 4 bytes |
| Image height: | 4 bytes |
| Bit depth: | 1 byte. Number of bits per sample (1,2,4,8, or 16). |
| Color type: | 1 byte. 0 (grey), 2 (RGB), 3 (color map), 4 (greyscale with transparency) or 6 (RGB with transparency) |
| Compression method: | 1 byte. Always 0. |
| Filter method: | 1 byte. Always 0. |
| Interlace method: | 1 byte. 0=no interlace. 1=Adam7 interlace (See: references) |
This file has compression, but it is non-lossy. It also, like GIF, allows transparency, but allows full RGB color. It does not have an option for animations, though. Reading the signature and the first (IHDR) chunk is done in the following way:
# PNG
from struct import *
b2 = (137, 80, 78, 71, 13, 10, 26, 10) # Correct header
types = ("Grey", "", "RGB", "Color map",
"Grey with alpha", "", "RGBA") # Color types
f = open ("test.png", "rb")
s = f.read (8) # Read the header
b1 = unpack('8B', s)
if b1 == b2:
print ("Header OK")
else:
print ("Bad header")
s = f.read(8) # The next chunk must be the IHDR
length, type = unpack (">I4s", s) # Unpack the first
8 bytes print ("First chunk: Length is", length, "Type:", type)
s = f.read (length) # We know the length, read the chunk
wd,ht,dep,ctype,compress, filter, interlace = unpack(">ii5B", s)
#I I B B B B B
print ("PNG Image width=", wd, "Height=", ht)
print ("Image has ", dep, "bytes per sample.")
print ("Color type is ", types[ctype])
if compress == 0:
print ("Compression OK")
else:
print ("Compression should be 0 but is", compress)
if filter==0:
print ("Filter is OK")
else:
print ("Filter should be 0 but is", filter)
if interlace==0:
print ("No interlace")
elif interlace == 1:
print ("Adam7 interlace")
else:
print ("Bad interlace specified: ", interlace)
f.close()
8.5.6 Sound Files
A sound file can be a lot more complex than an image file, and substantially larger. To properly play back a sound, it is critical to know how it was sampled: how many bits per sample, how many channels, how many samples per second, compression schemes, and so on. The file must be readable in real time or the sound can’t be played without a separate decoding step. All that is really needed to display an image is its size pixel format and compression.
There are, once again, many existing audio file formats. MP3 is quite complex, too much so to discuss here. The usual option on a PC would be “.wav” and, as it happens, that format is not especially complicated.
WAV
A WAV file has three parts: the initial header, used to identify the file type; the format sub-chunk, which specifies the parameters of the sound file; and the data sub-chunk, which holds the sound data.
The initial header should contain the string “RIFF” followed by the size of the file minus 8 bytes (i.e., the size from this point forward), and the string “WAVE.” This is 12 bytes in size.
The next “sub-chunk” has the following form:
A program that reads the first two sub-chunks is:
# WAV
from struct import *
f = open("test.wav", "rb")
s = f.read (12)
riff,sz,fmt = unpack ("4si4s", s)
riff = riff.decode("utf-8")
fmt = fmt.decode("utf-8")
print (riff, sz, "bytes ", fmt)
s = f.read (24)
id, sz1, fmt,nchan,rate,bytes,algn, bps = unpack
("4sihhiihh", s)
#4s i h h i i h h
id = id.decode ("utf-8)")
print ("ID is", id, "Channels ", nchan, "Sample rate is ", rate)
print ("Bits per sample is ", bps)
if fmt==1:
print ("File is PCM")
else:
print ("File is compressed ", fmt)
print ("Byterate was ", bytes, "should be ", rate*nchan*bps/8)
8.5.7 Other Files
Every type of file has a specific purpose and a format that is appropriate for that purpose. For that reason the nature of the headers and the file contents differ, but the fact that the headers and other specific fields exist should by now make some sense. When a program is asked to open a file there should be some way to confirm that the contents of the file can be read by the program. The code that has been presented so far is only sufficient to determine the file type and some of its basic parameters. The code needed to read and display a GIF, for example, would likely be over 1000 lines long. It is important, for someone who wishes to be a programmer, to see how to construct a file so that it can be used effectively by others and so that other programmers can create code that can identify that file and use it.
With that in mind, some other file types will be described briefly and considered as examples of how to organize data into a file.
HTML
An HTML (HyperText Markup Language) file is one that is recognized by a browser and can be displayed as a web page. It is a text file, and can be edited, saved, and redisplayed using simple tools; the fancy web editors are useful, but not necessary.
The first line of text in an HTML file should be either a variation on:
<!DOCTYPE html>
or a variation on:
<html>
The problem is that these are text files, so spaces and tabs and newlines can appear without affecting the meaning. Browsers are also supposed to be somewhat forgiving about errors, displaying the page if at all possible. A simple example that shows some of the problems while being largely correct is:
import webbrowser
f = open ("other.html")
html = False
while True: # Look at many lines
s = f.readline() # Read
s = s.strip() # Remove white space
# (blanks, tabs)
s = s.lower() # Convert to lower case for
# compare
k = (s.find("doctype")) # doctype found?
if k>0: # Yes
kk = s.find("html") # Look also for 'html'
if kk >= k+7: # Found it, after DOCTYPE
html = True # Close enough
break
else:
k = s.find("html") # No 'doctype'. 'html'?
if k>0 and s[k-1] == "<": # Yes. Preceded by '<'?
html = True # Yes, Close enough.
break
if len(s) > 0: # is the string non-blank?
html = False # Yes. So it is not HTML
# probably
break
if html:
webbrowser.open_new_tab('other.html')
else:
print ("This is not an HTML file.")
This program uses the webbrowser module of Python to display the web page if it is one. The call webbrowser.open_new_tab('other.html') opens the page in a new tab, if the browser is open. This module is not a browser itself. It simply opens an existing installed browser to do the work of displaying the page.
EXE
This is a Microsoft executable file. The details of the format are involved, and require a knowledge of computers and formats beyond a first-year level, but detecting one is relatively simple. The first two bytes that identify an EXE file are:
Byte 0: 0x4D
Byte 1: 0x5a
It is always possible that the first two bytes of a file will be these two by
accident, but it is unlikely. If the file being examined is, in fact, an EXE file, then a Python program can execute it. This uses the operating system interface module os:
import os
os.system ("program.exe")
8.6 SUMMARY
A fair definition of Computer Science would be the discipline that concerns itself with information. Computers can only operate on numbers, so an important aspect of using data is the representation of complex things as numbers. Most data consist of measurements of something, and as such are fundamentally
numeric.
A dictionary allows a more complex indexing scheme: it is accessed by content. A dictionary can be indexed by a string or tuple, which in general would be referred to as a key, and the information at that location in the dictionary is said to be associated with that key.
A Python array is a class that mimics the array type of other languages and offers efficiency in storage, exchanging that for flexibility. The struct module permits variables and objects of various types to be converted into what amounts to a sequence of bytes. It has a pack() and an unpack() method for converting Python variables into sequences of bytes.
The string format() method allows a programmer to specify how values should be placed within a string. The idea is to create a string that contains the formatted output, and then print the string.
Python data can be written to files in raw, binary form. It is also possible to position the file at any byte in a binary file, allowing the file to be read or written at any location.
Exercises
1. Ask the user for a file name. Extract the suffix and use it to look up the type of the file in a dictionary and print a short description of it. Recognized types include image files (jpg, gif, tiff, png), sound files (wav), and others (dll, exe).
2. Modify the Latin translation program so that it asks the user for a translation of any word it cannot find and adds that word to the dictionary.
3. Write a program that reads keys and values (strings) from the console and creates a dictionary from those data. When the user types the word “done” then the input is complete. City names are good examples of values, and could represent the city where the person named in the key lives.
4. Modify the answer to Exercise 3 so that after the data entry is complete, the user can enter a value and the program will print all of the keys associated with that value.
5. Given a dictionary, write a function writedict() that writes that dictionary to a file, and another function readdict() that will read that file and recreate the dictionary. For simplicity assume that the keys are simple numbers or strings.
6. The PNM file format for images has three types of image in two forms: monochrome, grey, and color, saved as text or in binary form. A binary grey level image is called a PGM (Pixel Grey Map) and has a short header followed by pixels. The header is text and consists of the identifying code “P5” followed by the width of the image in pixels (NC), followed by the height (NR), followed by the maximum value for a grey level (NGL) followed by an end of line. Now the data follows as rows of NC bytes:
P5
nc nr ngl
<image pixels, 1 byte each>
Write a program that will read an image file in this format and display it on the screen as an image using Glib.
http://netpbm.sourceforge.net/doc/pgm.html
7. Assume that the following variables exist and have the obvious meanings: year, month, day, hour, minute, second. All are integer except second, which is a float. The ISO 8601 standard for displaying dates uses the format:
YYYY-MM-DDThh:mm:ss.s
where the letter “T” ends the date portion and begins the time. An example would be
2015-12-27T10:38:12.3
Write a function that takes the given variables as parameters and prints the date in this format.
http://www.w3.org/TR/NOTE-datetime
8. Write a Python program that opens a file named by the user from the keyboard; the file has the suffix “.jpg,” “.gif,” or “.png.” Determine whether the file contents agree with the suffix, and print a message indicating the result.
9. A concordance is a list of words found in a text. Build a concordance using a dictionary that keeps track of the number of times that a word is used, in addition to its mere presence. Print the resulting list in alphabetical order.
10. Write a program that prints out checks. The date and the payee are entered as strings and the amount is entered as a floating point number, the maximum amount being 1000 dollars. The FOR field is always “Books.” The program formats the check according to the following image (Figure 8.2), where:
The date is line 3 starting at character 58
The pay to field is line 6 starting at character 20
The numeric amount is line 6 starting at character 57
The text amount is line 8 character 10
The FOR field is line 12 character 15

Notes and Other Resources
List of free datasets to download: https://r-dir.com/reference/datasets.html
NASA Meteorite Landing Database: https://data.nasa.gov/view/ak9y-cwf9
String Formatting: https://infohost.nmt.edu/tcc/help/pubs/python/web/format-spec.html
The Array type: https://docs.python.org/3/library/array.html
Image file formats: https://www.library.cornell.edu/preservation/tutorial/presentation/table7-1.html
http://www.scantips.com/basics09.html
Home page for MPEG: http://mpeg.chiariglione.org/
GIF 1989 specification: http://www.w3.org/Graphics/GIF/spec-gif89a.txt
Byte by byte GIF: http://www.matthewflickinger.com/lab/whatsinagif/bits_and_bytes.asp
TIFF Description: http://www.fileformat.info/format/tiff/egff.htm#TIFF.FO
PNG Specification: http://www.w3.org/TR/PNG/
Adam7 Interlacing: http://www.libpng.org/pub/png/pngpics.html
EXE file format: http://www.delorie.com/djgpp/doc/exe/
File Signatures: http://www.garykessler.net/library/file_sigs.html
Sample PGM Images: http://people.sc.fsu.edu/~jburkardt/data/pgmb/pgmb.html
1. Gunter Born. (1995). The File Formats Handbook, Cengage Learning EMEA, ISBN-13: 978-1850321170.
2. David Kay. (1994). Graphics File Formats, Windcrest, ISBN-13: 978-0070340251.
3. Dr. Charles R. Severance.Python for Informatics: Exploring InformationCreateSpace Independent Publishing Platform, ISBN-13: 978-1492339243.
4. Alan Tharp. (1988). File Organization and Processing, 1st edition, John Wiley & Sons, ISBN-13: 978-0471605218.
5. John Watkinson. (2001). MPEG Handbook, Focal Press, ISBN-13: 978-0240516561.