11 Interrupts
We have referred to the step-taking machinery as though it proceeded simply, smoothly, consistently forward. Most programs are written as though they run that way, but if we look at the activity of the underlying machinery we see something different. Instead of a steady flow of simple steps, a physical machine performs a combination of both smooth forward motion and abrupt unpredictable transitions called interrupts.
Figure 11.1 shows four abstract steps labeled with letters. This simple diagram reflects the way that an ordinary program is written and the way that a programmer would usually think about its execution.

Four steps as the programmer sees them.
Figure 11.2 takes the same four steps with the same labels and shows a possible view of the steps actually taken by the machine. Instead of simply proceeding directly from one step to the next in the original program, there are two deviations from the simple flow: one with the two steps x1 and x2, the other with the step y. Our task in this chapter is to understand why this more complex behavior is useful.

The same four steps, a possible execution.
Being interrupted is a familiar everyday experience. We can distinguish between what we were doing before being interrupted—some activity that we expected to continue further—and the event that prompts us to shift our attention and actions away from that former activity. Indeed, we could say that the dashes in the previous sentence effectively interrupt the flow of the sentence to insert a modifying subordinate clause, then return the reader to the original sentence. Likewise in computation, an interrupt changes the ordinary flow for a short period of time. (The more grammatical noun might well be “interruption,” but “interrupt” is well-established as the technical term—so that’s what we’ll use.)
The Unpredictable Environment
Why are interrupts necessary? They let the step-taking machinery achieve two hard-to-reconcile goals. With interrupts, the machinery can both deal with unpredictable outside events and support a fairly simple approach to programming for most processes. Let’s first look at why we might have to deal with unpredictable outside events, then see how that problem is awkward unless we bring in interrupts.
One source of unpredictable events is any interaction with the world outside the computer. In particular, there is an input/output (I/O) system that allows the step-taking machinery to read in or write out data that is somewhere outside the machine itself. The step-taking machinery can set and follow its own rules about how quickly steps happen, or what happens during each step. But the outside world doesn’t respect those rules. There is no necessary relationship between the timing of program steps and the timing of an I/O-related event such as the following:
• a user presses a key,
• a message arrives from across a network,
• a spinning disk reaches the right position to write information,
• a display is ready to be updated with new items, or
• a network is ready to accept a new message to be sent.
Any of these changes can happen at essentially any time.
In Figure 11.3, we have taken the same four-step program we considered previously and indicated with vertical arrows some of the places where an outside event could occur. It might happen:
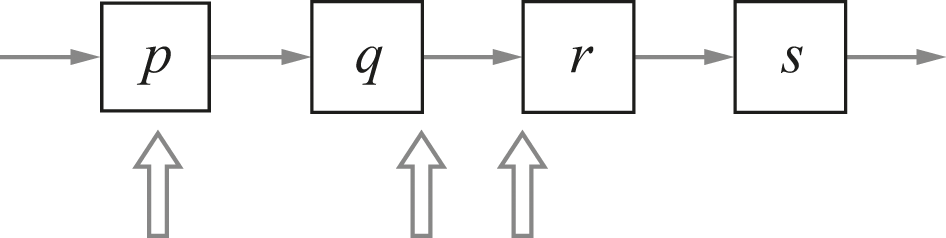
The same four steps with some possible interrupt times.
• in the middle of a step (left vertical arrow),
• as the machinery is moving from one step to another (middle vertical arrow), or
• at the very beginning of a step (right vertical arrow).
Although the machinery has a very regular, consistent, repetitive behavior, the outside world has no obligation to match its events to the machinery’s pace.
Check, Check, Check …
Let’s consider just the simple case of dealing with characters being typed on a keyboard. To the user, a keyboard is a collection of different keys that can be pressed one at a time or in certain combinations. But to a computer, a keyboard is just a mutable cell like the ones we considered previously (chapter 9). The physical keys of the keyboard are just the way that a user controls the value of that cell, and they don’t otherwise matter to the computer.
Some of the time the cell contains a single character, representing the key that’s currently being pressed. Each character value is actually represented as a short sequence of bits, but we’ll ignore that detail here. Some of the time the cell contains a special “nothing” value corresponding to “no key pressed.” Let’s assume for a moment that we could watch that cell, and that we had the ability to “see” the bit patterns there. It would look a little like figure 11.4. (Unfortunately, the cell doesn’t really display the character in a way that we could just look at it with our eyes and see a letter.)
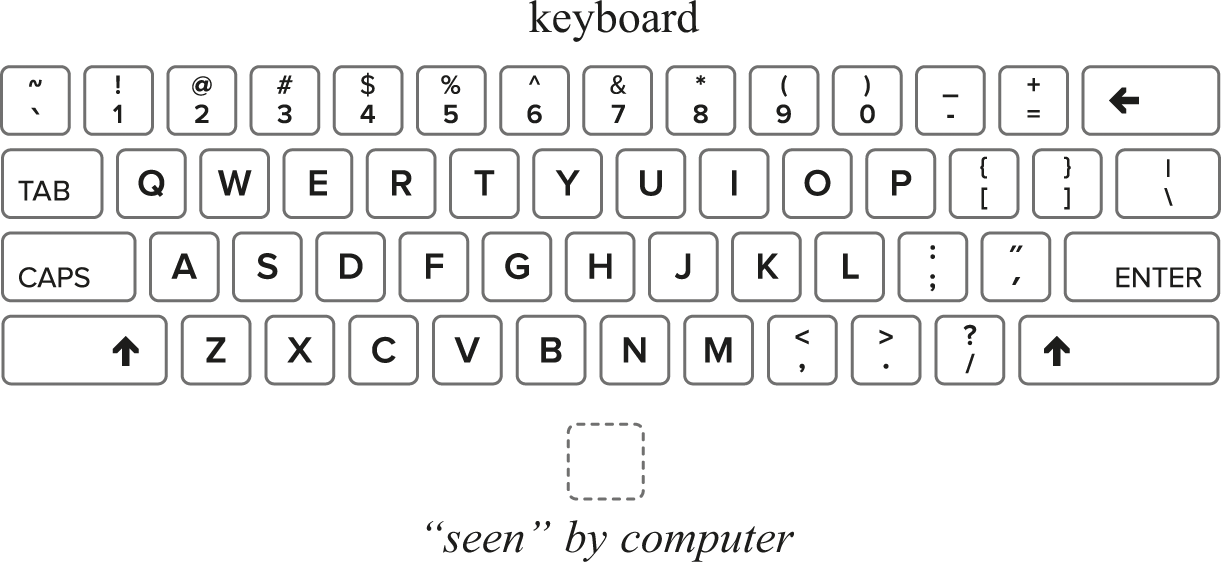
A keyboard and its associated cell.
If someone types a piece of text like a speech from Shakespeare, we would see the cell successively changing values as different characters were pressed. So typing the phrase, “To be or not to be” would first show up as the character “T” (see figure 11.5).
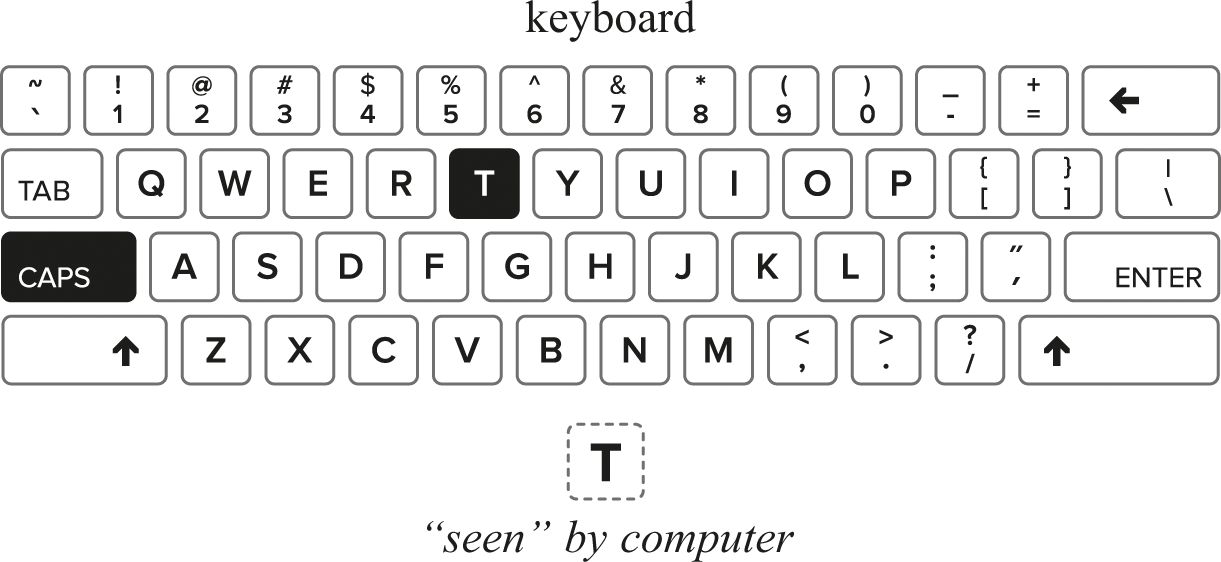
Typing the letter “T”
Likewise, we could see something similar for “o” and “ ” (that is, a space) and “b” and “e,” and so on.
Depending on how fast the user was typing, the special “no key” value might be appearing between some or all of those letters and punctuation. If we wanted a program to just watch the keyboard, that program would be pretty simple to write. The program just repeatedly looks at the incoming values in the cell, much like the program we saw earlier that prints out “Hi” endlessly in figure 3.5.
From the computer’s perspective, a keyboard is basically a means for a cell to take on a sequence of values. But as a user of a computer, our view is a little different. When we type that Shakespearean phrase at the keyboard, we want the whole sequence of characters to be recorded. How would that work? Let’s first figure out how something even simpler works without interrupts.
We’ll start by assuming that we have a step-taking machine running some program. It doesn’t much matter what that particular program is doing, but we know roughly what’s happening for any program: the machinery is repeatedly fetching instructions and data, and performing the instructions on the data. The program doesn’t initially interact with the keyboard at all.
Now assume that we actually want an improved version of that program to read input—perhaps it is drawing patterns on the screen, and pressing different keys changes the color of the current pattern. We have to modify the program so that it periodically checks to see if a key has been pressed (computer scientists refer to such an event as a keystroke). If a program has to repeatedly check the keyboard’s cell to collect each keystroke, the timing constraint may be fairly tight: to notice the keystroke correctly, the program has to “look at” the keyboard often enough so that it “looks” during the time that the key is down and providing a signal. So whatever the program used to do before, now it has to repeatedly check the keyboard. Previously, the program looked like this:
Do tiny step 1
Do tiny step 2
Do tiny step 3
Now the program has to look like this:
Do tiny step 1
CHECK KEYBOARD
Do tiny step 2
CHECK KEYBOARD
Do tiny step 3
CHECK KEYBOARD
So even this tiny simple sketch of a program got twice as long and annoyingly repetitive. The changes are actually even worse if the program is longer or more complex. Why is it necessary to do this repeated checking?
Let’s suppose that we check less often. If the program doesn’t check the keyboard often enough, it might miss some keystroke, and the experience of typing something into the computer would become frustrating—some keystrokes would be missed if we were typing quickly, which might prompt us to slow down and press the keys for longer times, or we might get frustrated and find some other way of entering the information.
The problem of “looking” often enough to catch transient events like keystrokes becomes more difficult as both the number and complexity of devices increase. And even if we set aside this risk of missing characters, consider the task facing programmers who want to use the keyboard to communicate with their program. They don’t want to have to write their program mostly about the keyboard.
If each program has to check on various devices for possible changes, it’s hard to tell what the program is really doing. The problem of interacting with those devices dominates the problem of whatever real work we wanted the program to accomplish. Effectively, “the tail is wagging the dog” and even the simplest program ends up being affected by the need to check for inputs. In addition, every change to the computer’s collection of devices potentially requires every program to adapt. This approach seems unattractive and unworkable.
Interrupts and Handlers
Interrupts allow a different approach to this problem. With interrupts, an “ordinary” program—one that’s trying to accomplish some task unrelated to the devices and machinery—no longer has to check each of the various devices itself. Instead, a change of state on any one of those devices causes an interrupt. Effectively, the checking on each step becomes part of how the step-taking machine works. When the interrupt occurs, the execution of the ordinary program is halted temporarily—that is, steps are no longer allocated to executing that program, so it pauses. Instead, the machinery’s steps are allocated to a different, specialized program designed exactly for this purpose: an interrupt handler. After the interrupt handler has done whatever work is required, control returns to the interrupted program and it resumes execution as though nothing had happened.
The interrupt handler typically takes the new input (such as which key was pressed) and puts it into a safe place for subsequent processing. The intermediate storage—the safe place—is usually called a buffer.
The interrupt handler for a keystroke interrupt can be a very simple program: it knows the location of a buffer to be used for keyboard characters, and it puts the current keyboard character into the next available cell of that buffer. Later, when the program is ready to look at one or more characters from the keyboard, it actually reads them from the buffer. For example, our pattern-drawing program might be either in the middle of actually interacting with the screen (so that it’s impossible to change the color that was just used) or in the middle of some calculation unrelated to color (so that there’s no need to deal with color yet). So when do we want to check? The place we want to check for keyboard input that might affect the color displayed is just before the program next starts to interact with the screen.
Shared Services
Without interrupts, we had a difficult trade-off between responsiveness and simple programming. If we wanted a program to be responsive to transient conditions, we had to make that program a mess of frequent checks; or if we wanted the program to be simple, we had to accept that it would miss some transient events. An interrupt mechanism lets us have both responsiveness to transient conditions and a simpler programming model most of the time.
However, if our only concern is programming simplicity then interrupts are not the right solution. The mechanisms for handling interrupts and buffers are admittedly more complex than simply exposing the keyboard directly to a program. It was kind of stupid to repeatedly check the keyboard for a possible character, but it had the merit of being straightforward, as compared to this convoluted business of transferring to a different program, storing a character away, then resuming the original program. Interrupts are appealing when we want to balance responsiveness and simple programming.
The good news here is that the extra complexity of interrupts is not really a problem in practice. Once we’ve built those interrupt handlers and buffer managers, we can reuse them for lots of different programs that want to interact with a keyboard. Even more important, we no longer need for all those different programs to be written in terms of a particular keyboard arrangement. Instead, we’ve achieved a separation of concerns: the program can deal with its main purpose, while the interrupt handlers and buffer managers can deal with the details of the hardware. The program doesn’t really need to know much about how the keyboard works; likewise, the interrupt handlers and buffer managers don’t really need to know much about how any other programs work.
The interrupt handling and buffer management are examples of shared services for ordinary programs, making the step-taking machinery easier to use. Another name for a collection of those shared services is an operating system. We’ve previously mentioned some examples of popular operating systems, but this is the first time that we’ve considered a possible definition for the term. Another helpful way of thinking about an operating system is that it’s a program for running other programs. There’s no contradiction between these two definitions—they just emphasize different aspects of what an operating system does.
Ordinary (non-operating system) programs are typically called application programs, or applications. An application usually runs “on top of” some operating system. The operating system uses buffers to isolate smooth-running processes from the unpredictable peculiarities of the outside world, allowing each program to deal with keyboard input and other unpredictable events in a sensible way. With support from the operating system, applications don’t need to obsessively check the keyboard for fear of possibly missing a keystroke.
An aside: we can see an interesting perspective embedded in computer science terminology if we notice that input and output devices are collectively referred to as peripherals, as though they were somehow unimportant to the more central task of computation.
In reality, a computational device without I/O is completely irrelevant. Indeed, an old computer-science joke says that ordinary rocks have extremely fast computers inside—but the I/O system is really bad.
Frequent Check, Rare Problem
The same arrangement of using an interrupt and an interrupt-handler is also useful for handling problematic situations that could occur frequently, but only actually occur rarely.
For example, there is a potential problem with overflow of numbers. Many physical step-taking machines have instructions to perform arithmetic on integers, and every one of those machines has some limit on how big a number it can use. One possible (and relatively easy to understand) limit is related to 32 bits, and is either a little bigger than 4 billion (roughly what you can represent with 32 bits) or a little bigger than 2 billion (roughly what you can represent with 31 bits). Every single addition operation on that machine has at least the theoretical possibility of producing a result that exceeds that maximum size—an overflow. However, in most programs the vast majority of additions don’t cause an overflow. Even if we write a program that deliberately triggers an overflow by starting at zero and repeatedly adding 1, it will perform literally billions of additions before triggering the overflow.
Just as it was foolish to write program steps to check the keyboard in between every “real” action, so it would be foolish to wrap every single addition operation in a tiny program that checks to see if an overflow occurred. It makes more sense to leave all of those overflow checkers out of the program’s text, and instead write an overflow handler that is called only when an overflow does occur. The common pattern that we are starting to see here is that we can separate out something that is logically checked very frequently, when there is a strong skew to the expected results of the check—we expect the common case to be that nothing is wrong and nothing needs to be done, but occasionally we have to do some kind of fix-up. We also notice that because this checking is done very often, it makes sense to build it into the step-taking machinery rather than asking the programmer to do it over and over again.
In fact, one way of thinking about I/O is to view it as a source of frequently checked but rarely triggered conditions. Because computers are so fast, even I/O that seems fast to a person is incredibly slow for a computer—there are typically many steps taken between any two I/O activities. To return to our keyboard example, you would be a very fast typist if you could type at 180 words per minute (wpm)—the fastest typists in the world are up around 212 wpm. A speed of 180 wpm is 15 keystrokes per second, which in terms of human speeds is amazingly fast. However, even relatively modest devices like mobile phones and tablets can have processors running at 1 GHz or more, which means they are taking a billion steps or more every second. So that amazingly fast typist is only affecting the next step taken by a computer roughly 0.00000015 percent of the time, or approximately never. An I/O event is something that could happen on any step but almost never does; if we think about the situation from the perspective of a smooth-running application, an I/O event is almost like an error.
Input/output and commonly possible but rarely occurring errors share the characteristic that they could all be handled explicitly by the program—but taking such an approach would lose the real meaning of the program under a mass of redundant detail. In all of these “check-often, fail-rarely” cases we have an argument for building the checking work into the step-taking machinery, and then using an interrupt to invoke a handler when the unusual case arises.
Protecting Memory
We’ve noticed that every integer addition potentially causes an overflow. In a similar fashion, every time a program reads or writes a memory location, that access potentially causes a different kind of error: a kind of trespassing within the computer’s storage.
We know that the operating system is a program. Like any other program, it uses some of the available space of the machine for its instructions and data. Those particular instructions and data should be reserved for the exclusive use of the operating system; no application program should be looking at or changing any of those locations. An application program using the wrong part of memory may violate limits that are set up to protect the operating system.
Protecting the operating system from the applications is a situation like overflow: it makes sense to check a condition frequently, but we expect the check to only fail occasionally. We expect that in the vast majority of cases, each access by an application is no hazard to the operating system. What should we do in the rare case where an application may be doing something it shouldn’t? That’s a situation where it’s important to stop the offending behavior as quickly as possible.
To protect the operating system from application programs, we need to designate some locations that are available only to the operating system. The operating system is allowed to read and write to those locations without limitations; but when an ordinary application attempts to read or write any of those locations, an interrupt occurs. Much as a check for overflow happens in hardware on every arithmetic operation, this boundary check happens in hardware on every read or write of memory. If there is an illegal use of memory, the interrupt occurs and transfers control to an interrupt handler, which in turn will stop or redirect the offending program.
In contrast to our previous examples (keystroke, arithmetic overflow), we simply can’t solve this protection problem without some kind of interrupt. Even as a thought experiment, there is no sensible way we can leave this problem to explicit checks by the application program. Why? Because the problem we need to solve is precisely an error or failure of the application. Whether the inappropriate access is accidental or intentional, we have to ensure that an application can’t interfere with the operating system—or else the operating system will be unable to reliably provide services to its users. If there is no protection mechanism and we’re simply trusting all of the applications to “play well together,” we are effectively running a kind of race to see which application can most quickly seize control of the operating system, and thus the machine.
System Calls
We’ve already seen that a real-world computing system needs to have interrupts, and the operating system needs to be involved in handling those interrupts. We could turn that observation inside out and note that the interrupt-handling system has to be able to handle all of the details required to transfer control from any application process to the operating system, and also transfer control back.
That’s a useful insight when we consider that there are also situations where an application program simply needs to ask the operating system to do something useful. These requests are collectively referred to as system calls. A system call is simply a request, and logically doesn’t require an interrupt—there’s nothing “unexpected” or “unusual” about it. However, in most cases system calls are implemented by reusing the interrupt mechanism. This leads to the slightly strange situation where a program requests an operating system activity by interrupting itself.
Is this kind of interrupt-based transfer the only way for one program to access another program? No. It’s far more common for one program to call another program, so that the second (called) program performs some activity and then returns to the original program. It’s the same kind of going-away (to the called program) and then coming-back (to the calling program), but there’s no interrupting happening—just ordinary steps, one after another.
So why can’t an ordinary program just call the operating system? In principle, it can; and in some systems, it does. Regardless, there is a collection of housekeeping that has to happen whenever there’s a transition from an ordinary program to the operating system, or vice versa. In particular, at the start of a system call the machine has to be tweaked so the operating system can use its (otherwise off-limits) resources; and at the end of a system call, the machine has to be tweaked back so that the operating system resources are put off-limits again.
The transition between application and operating system (in both directions) is crucial to handle correctly and efficiently on every interrupt. As a result, there is usually special hardware support for interrupt handling. Designers often find that it is both faster and more reliable to reuse the interrupt mechanism for system calls rather than develop a separate system-call mechanism, even though that approach does sometimes seem a little bit convoluted.