Most programmers have seen them, and most good programmers realize they’ve written at least one. They are huge, messy, ugly programs that should have been short, clean, beautiful programs. I’ve seen several programs that boil down to code like this
if (k == 1) c001++
if (k == 2) c002++
...
if (k == 500) c500++
Although the programs actually accomplished slightly more complicated tasks, it isn’t misleading to view them as counting how many times each integer between 1 and 500 was found in a file. Each program contained over 1000 lines of code. Most programmers today instantly realize that they could accomplish the task with a program just a tiny fraction of the size by using a different data structure — a 500-element array to replace the 500 individual variables.
Hence the title of this column: a proper view of data does indeed structure programs. This column describes a variety of programs that were made smaller (and better) by restructuring their internal data.
The next program we’ll study summarized about twenty thousand questionnaires filled out by students at a particular college. Part of the output looked like this:
Total US Perm Temp Male Female
Citi Visa Visa
African American 1289 1239 17 2 684 593
Mexican American 675 577 80 11 448 219
Native American 198 182 5 3 132 64
Spanish Surname 411 223 152 20 224 179
Asian American 519 312 152 41 247 270
Caucasian 16272 15663 355 33 9367 6836
Other 225 123 78 19 129 92
Totals 19589 18319 839 129 11231 8253
For each ethnic group, the number of males plus the number of females is a little less than the total because some people didn’t answer some questions. The real output was more complicated. I’ve shown all seven rows plus the total row, but only the six columns that represent the totals and two other categories, citizenship status and sex. In the real problem there were twenty-five columns that represented eight categories and three similar pages of output: one apiece for two separate campuses, and one for the sum of the two. There were also a few other closely related tables to be printed, such as the number of students that declined to answer each question. Each questionnaire was represented by a record in which entry 0 contained the ethnic group encoded as an integer between 0 and 7 (for the seven categories and “refused”), entry 1 contained the campus (an integer between 0 and 2), entry 2 contained citizenship status, and so on through entry 8.
The programmer coded the program from the systems analyst’s high-level design; after working on it for two months and producing a thousand lines of code, he estimated that he was half done. I understood his predicament after I saw the design: the program was built around 350 distinct variables — 25 columns times 7 rows times 2 pages. After variable declarations, the program consisted of a rat’s nest of logic that decided which variables to increment as each input record was read. Think for a minute about how you would write the program.
The crucial decision is that the numbers should be stored as an array. The next decision is harder: should the array be laid out according to its output structure (along the three dimensions of campus, ethnic group and the twenty-five columns) or its input structure (along the four dimensions of campus, ethnic group, category and value within category)? Ignoring the campus dimension, the approaches can be viewed as
Both approaches work; the three-dimensional (left) view in my program resulted in a little more work when the data was read and a little less work when it was written. The program took 150 lines of code: 80 to build tables, 30 to produce the output I described, and 40 to produce other tables.
The count program and the survey program were two needlessly big programs; both contained numerous variables that were replaced by a single array. Reducing the length of the code by an order of magnitude led to correct programs that were developed quickly and could be easily tested and maintained. And although it didn’t matter much in either application, both small programs were more efficient in run time and space than the big programs.
Why do programmers write big programs when small ones will do? One reason is that they lack the important laziness mentioned in Section 2.5; they rush ahead to code their first idea. But in both cases I’ve described, there was a deeper problem: the programmers thought about their problems in languages in which arrays are typically used as fixed tables that are initialized at the beginning of a program and never altered. In his book described in Section 1.7, James Adams would say that the programmers had “conceptual blocks” against using a dynamic array of counters.
There are many other reasons that programmers make these mistakes. When I prepared to write this column I found a similar example in my own code for the survey program. The main input loop had forty lines of code in eight five-statement blocks, the first two of which could be expressed as
ethnicgroup = entry[0]
campus = entry[l]
if entry[2] == refused
declined[ethnicgroup, 2]++
else
j = 1 + entry[2]
count[campus, ethnicgroup, j]++
if entry[3] == refused
declined[ethnicgroup, 3]++
else
j = 4 + entry[3]
count[campus, ethnicgroup, j]++
I could have replaced forty of those lines with six, after initializing the array offset to contain 0, 0, 1, 4, 6, ...
for i = [2, 8]
if entry[i] == refused
declined[ethnicgroup, i]++
else
j = offset[i] + entry[i]
count[campus, ethnicgroup, j]++
I had been so satisfied to get one order-of-magnitude reduction in code length that I missed another one staring me in the face.
You’ve just typed your name and password to log in to the web site of your favorite store. The next page you see looks something like
Welcome back, Jane!
We hope that you and all the members
of the Public family are constantly
reminding your neighbors there
on Maple Street to shop with us.
As usual, we will ship your order to
Ms. Jane Q. Public
600 Maple Street
Your Town, Iowa 12345
...
As a programmer, you realize that behind the scenes a computer looked up your user name in a database and retrieved fields like
Public|Jane|Q|Ms.|600|Maple Street|Your Town|Iowa|12345
But how exactly did the program construct that customized web page from your database record? The hasty programmer may be tempted to write a program that begins something like
read lastname, firstname, init, title, streetnum,
streetname, town, state, zip
print "Welcome back,", firstname, "!"
print "We hope that you and all the members"
print "of the", lastname, "family are constantly"
print "reminding your neighbors there"
print "on", streetname, "to shop with us."
print "As usual, we will ship your order to"
print " ", title, firstname, init ".", lastname
print " ", streetnum, streetname
print " ", town ",", state, zip
...
Such a program is tempting but tedious.
A more elegant approach involves writing a form letter generator that relies on a form letter schema like
Welcome back, $1!
We hope that you and all the members
of the $0 family are constantly
reminding your neighbors there
on $5 to shop with us.
As usual, we will ship your order to
$3 $1 $2. $0
$4 $5
$6, $7 $8
...
The notation $i refers to the ith field in the record, so $0 is the last name, and so on. The schema is interpreted by the following pseudocode, which assumes that a literal $ character is written in the input schema as $$.
read fields from database
loop from start to end of schema
c = next character in schema
if c != '$'
printchar c
else
c = next character in schema
case c of
'$': printchar '$'
'0' - '9': printstring field[c]
default: error("bad schema")
The schema is represented in the program as one long array of characters in which text lines are ended by newline characters. (Perl and other scripting languages make this even easier; we can use variables like $lastname.)
Writing the generator and the schema will probably be easier than writing the obvious program. Separating the data from the control will pay off handsomely: if the letter is redesigned then the schema can be manipulated with a text editor, and the second specialized page will be simple indeed to prepare.
The concept of a report schema could have greatly simplified a 5300-line Cobol program I once maintained. The program’s input was a description of a family’s financial status; its output was a booklet summarizing the status and recommending future policy. Some numbers: 120 input fields; 400 output lines on 18 pages; 300 lines of code to clean the input data, 800 lines for computation, and 4200 lines to write the output. I estimate that the 4200 lines of output code could have been replaced by an interpreter of at most a few dozen lines of code and a schema of 400 lines; the computational code would have remain unchanged. Originally writing the program in that form would have resulted in Cobol code that was at most one-third the size and much easier to maintain.
Menus. I wanted the user of my Visual Basic program to be able to choose one of several possibilities by clicking a menu item. I browsed through an excellent collection of sample programs, and found one that allowed the user to select one of eight options. When I inspected the code behind the menu, item 0 looked like this:
sub menuitem0_click()
menuitem0.checked = 1
menuiteml.checked = 0
menuitem2.checked = 0
menuitem3.checked = 0
menuitem4.checked = 0
menuitem5.checked = 0
menuitem6.checked = 0
menuitem7.checked = 0
Item 1 was almost the same, with the following changes:
sub menuitem1_click()
menuitem0.checked = 0
menuitem1.checked = 1
...
And so on for items 2 through 7. Altogether, the selection menu items used about 100 lines of code.
I’ve written code like that myself. I started off with two items on the menu, and the code was reasonable. As I added the third, fourth and later items, I was so excited about the functionality behind the code that I didn’t stop to clean up the mess.
With a little perspective, we can move most of that code into the single function uncheckall that sets each checked field to 0. The first function then becomes:
sub menuitem0_click()
uncheckall
menuitem0.checked = 1
But we are still left with seven other similar functions.
Fortunately, Visual Basic supports arrays of menu items, so we can replace the eight similar functions with one:
sub menuitem_click(int choice)
for i = [0, numchoices)
menuitem[i].checked = 0
menuitem[choice].checked = 1
Gathering repeated code into a common function reduced 100 lines of code to 25, and judicious use of arrays dropped that to 4 lines. The next selection is much simpler to add, and potentially buggy code is now crystal clear. This approach solved my problem in just a few lines of code.
Error Messages. Dirty systems have hundreds of error messages scattered throughout the code, mixed in with other output statements; clean systems have them accessed through a single function. Consider the difficulty of performing the following requests under the “dirty” and “clean” organizations: produce a list of all possible error messages, change each “serious” error message to sound an alarm, and translate the error messages into French or German.
Date Functions. Given a year and day of the year, return the month and day of the month; for instance, the 61st day of 2004 is the 1st day of the 3rd month. In their Elements of Programming Style, Kernighan and Plauger present a fifty-five line program for this task taken straight from someone else’s programming text. They then give a five-line program for the task, using an array of twenty-six integers. Problem 4 introduces the representation issues that abound in date functions.
Word Analysis. Many computing problems arise in the analysis of English words. We’ll see in Section 13.8 how spelling checkers use “suffix stripping” to condense their dictionaries: they store the single word “laugh” without storing all its various endings (“-ing”, “-s”, “-ed”, etc.). Linguists have developed a substantial body of rules for such tasks. Doug McIlroy knew that code was the wrong vessel for such rules when he built the first real-time text-to-speech synthesizer in 1973; he instead wrote it using 1000 lines of code and a 400-line table. When someone modified the program without adding to the tables, that resulted in 2500 extra lines of code to do twenty percent more work. McIlroy asserts that he could probably do the expanded task now using fewer than 1000 lines by adding even more tables. To try your own hand on a similar set of rules, see Problem 5.
What is well-structured data? The standards have risen steadily over time. In the early years, structured data meant well-chosen variable names. Where programmers once used parallel arrays or offsets from registers, languages later incorporated records or structures and pointers to them. We learned to replace code for manipulating data with functions with names like insert or search; that helped us to change representations without damaging the rest of the program. David Parnas extended that approach to observe that the data a system is to process gives deep insight into a good module structure.
“Object-Oriented Programming” took the next step. Programmers learned to identify the fundamental objects in their design, publish to the world an abstraction and the essential operations on it, and hide the implementation details from view. Languages like Smalltalk and C++ allowed us to encapsulate those objects in classes; we’ll study this approach in detail as we investigate set abstractions and implementations in Column 13.
In the bad old days, programmers built each application from scratch. Modern tools allow programmers (and others) to build applications with minimal effort. The little list of tools in this section is indicative, not exhaustive. Each tool exploits one view of data to solve a particular but common problem. Languages such as Visual Basic, Tcl and various shells provide the “glue” for joining these objects.
Hypertext. In the early 1990’s, when web sites were numbered in the thousands, I was entranced by the reference books that were just coming out on CD-ROMs. The collection of data was stunning: encyclopedias, dictionaries, almanacs, telephone directories, classical literature, textbooks, system reference manuals, and more, all in the palm of my hand. The user interfaces for the various data sets were, unfortunately, equally stunning: every program had its own quirks. Today, I have access to all that data (and more) on CDs and the web, and the interface is usually the web browser of my choice. That makes life better for user and implementer alike.
Name-Value Pairs. A bibliographic database might have entries like this:
%title The C++ Programming Language, Third Edition
%author Bjarne Stroustrup
%publisher Addison-Wesley
%city Reading, Massachusetts
%year 1997
Visual Basic takes this approach to describe controls in an interface. A text box in the upper-left corner of a form can be described with the following properties (names) and settings (values):
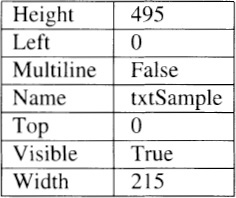
(The complete text box contains three dozen pairs.) To widen the text box, for example, I might drag the right edge with the mouse, or enter a larger integer to replace 215, or use the run-time assignment
txtSample.Width = 400
The programmer may choose the most convenient way to manipulate this simple but powerful structure.
Spreadsheets. Keeping track of our organization’s budget looked difficult to me. Out of habit, I would have built a large program for the job, with a clunky user interface. The next programmer took a broader view, and implemented the program as a spreadsheet, supplemented by a few functions in Visual Basic. The interface was totally natural for the accounting people who were the main users. (If I had to write the college survey program today, the fact that it is an array of numbers would encourage me to try to put it into a spreadsheet.)
Databases. Many years ago, after scribbling details about his first dozen jumps in a paper log book, a programmer decided that he wanted to automate his skydiving records. A few years earlier, that would have involved laying out a complex record format, and then building by hand (or by a “Report Program Generator”) programs to enter, update and retrieve the data. At the time, he and I were both awe-struck by his use of a new-fangled commercial database package for the job: he was able to define new screens for database operations in minutes rather than days.
Domain-Specific Languages. Graphical user interfaces (GUIs) have fortunately replaced many old, clunky textual languages. But special-purpose languages are still useful in certain applications. I despise having to use a mouse to poke at a faux calculator on the screen when I really want to type straightforward mathematics like
n = 1000000
47 * n * log(n)/log(2)
Rather than specifying a query with baroque combinations of text boxes and operator buttons, I prefer to write in a language like
(design or architecture) and not building
Windows that were formerly specified by hundreds of lines of executable code are now described in dozens of lines of Hypertext Markup Language (HTML). Languages may be out of vogue for general user input, but they are still potent devices in some applications.
While the stories in this column span several decades and a dozen languages, the moral of each is the same: don’t write a big program when a little one will do. Most of the structures exemplify what Polya calls the Inventor’s Paradox in his How to Solve It: “the more general problem may be easier to solve”. In programming this means that it may be harder to solve a 23-case problem directly than to write a general program to handle the n-case version, and then apply it to the case that n = 23.
This column has concentrated on just one contribution that data structures can make to software: reducing big programs to small programs. Data structure design can have many other positive impacts, including time and space reduction and increased portability and maintainability. Fred Brooks’s comment in Chapter 9 of his Mythical Man Month is stated for space reduction, but it is good advice for programmers who desire the other attributes as well:
The programmer at wit’s end for lack of space can often do best by disentangling himself from his code, rearing back, and contemplating his data. Representation is the essence of programming.
Here are a few principles for you to ponder as you rear back.
Rework repeated code into arrays. A long stretch of similar code is often best expressed by the simplest of data structures, the array.
Encapsulate complex structures. When you need a sophisticated data structure, define it in abstract terms, and express those operations as a class.
Use advanced tools when possible. Hypertext, name-value pairs, spreadsheets, databases, languages and the like are powerful tools within their specialized problem domains.
Let the data structure the program. The theme of this column is that data can structure a program by replacing complicated code with an appropriate data structure. Although the particulars change, the theme remains: before writing code, good programmers thoroughly understand the input, the output and the intermediate data structures around which their programs are built.
1. As the second edition of this book goes to press, individual income in the United States is taxed at five different rates, the maximum of which is around forty percent. The situation was formerly more complicated, and more expensive. A programming text gave the following twenty-five if statements as a reasonable approach for calculating the 1978 United States Federal Income Tax. The rate sequence .14, .15, .16, .17, .18, ... exhibits jumps larger than .01 later in the sequence. Any comments?
if income <= 2200
tax = 0
else if income <= 2700
tax = .14 * (income – 2200)
else if income <= 3200
tax = 70 + .15 * (income – 2700)
else if income <= 3700
tax = 145 + .16 * (income – 3200)
else if income <= 4200
tax = 225 + .17 * (income – 3700)
...
else
tax = 53090 + .70 * (income – 102200)
2. A kth-order linear recurrence with constant coefficients defines a series as
an = c1an – 1 + c2an – 2 + ... + ckan–k + ck + 1,
where c1, ..., ck + 1 are real numbers. Write a program that with input k, a1 ..., ak, c1, ..., ck+1, and m produces the output a1 through am. How difficult is that program compared to a program that evaluates one particular fifth-order recurrence, but does so without using arrays?
3. Write a “banner” function that is given a capital letter as input and produces as output an array of characters that graphically depicts that letter.
4. Write functions for the following date problems: given two dates, compute the number of days between them; given a date, return its day of the week; given a month and year, produce a calendar for the month as an array of characters.
5. This problem deals with a small part of the problem of hyphenating English words. The following list of rules describes some legal hyphenations of words that end in the letter “c”:
et-ic al-is-tic s-tic p-tic -lyt-ic ot-ic an-tic n-tic c-tic at-ic h-nic n-ic m-ic l-lic b-lic -clic l-ic h-ic f-ic d-ic -bic a-ic -mac i-ac
The rules must be applied in the above order; thus the hyphenations “eth-nic” (which is caught by the rule “h-nic”) and “clinic” (which fails that test and falls through to “n-ic”). How would you represent such rules in a function that is given a word and must return suffix hyphenations?
6. Build a “form-letter generator” that can prepare a customized document for each record in a database (this is often referred to as a “mail-merge” feature). Design small schemas and input files to test the correctness of your program.
7. Typical dictionaries allow one to look up the definition of a word, and Problem 2.1 describes a dictionary that allows one to look up the anagrams of a word. Design dictionaries for looking up the proper spelling of a word and for looking up the rhymes of a word. Discuss dictionaries for looking up an integer sequence (such as 1, 1, 2, 3, 5, 8, 13, 21, ...), a chemical structure, or the metrical structure of a song.
8. [S. C. Johnson] Seven-segment devices provide an inexpensive display of the ten decimal digits:
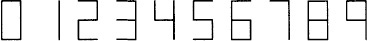
The seven segments are usually numbered as
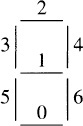
Write a program that displays a 16-bit positive integer in five seven-segment digits. The output is an array of five bytes; bit i of byte j is one if and only if the ith segment of digit j should be on.
Data may structure programs, but only wise programmers structure large software systems. Steve McConnell’s Code Complete was published by Microsoft Press in 1993. The subtitle accurately describes this 860-page volume: A Practical Handbook of Software Construction. It provides a fast track to wisdom for programmers.
Chapters 8 through 12 on “Data” are most relevant to this column. McConnell moves from basics such as declaring data and choosing data names to advanced topics including table-driven programs and abstract data types. His Chapters 4 through 7 on “Design” elaborate on the theme of this column.
The knowledge required to build a software project spans a wide range, from tasteful construction of small functions to managing big software projects. Especially when combined with his Rapid Development (Microsoft Press, 1996) and Software Project Survival Guide (Microsoft Press, 1998), McConnell’s work covers the two extremes, and most of the territory in between. His books are fun to read, but you never forget that he is speaking from hard-won personal experience.