Dieses Kapitel behandelt die folgenden Themen:
 Funktionen und ihr Aufbau
Funktionen und ihr Aufbau
Die verschiedenen Arten der Parameterübergabe
Präprozessordirektiven
Modulare Gestaltung und Strukturierung von Programmen
Namespaces
Auswertung von Funktionen zur Compilierzeit
Funktionen mit parametrisierten Datentypen
Module
Große Programme müssen in übersichtliche Teile zerlegt werden. Sie werden dazu verschiedene Mechanismen kennenlernen. Sie erfahren, wie eine Funktion aufgebaut ist, wie Sie ihr die benötigten Daten mitteilen und auf welche Weise die Ergebnisse von Funktionen zurückgegeben werden können. Die Simulation eines Taschenrechners zeigt beispielhaft den wechselseitigen Einsatz von Funktionen. Makros (Präprozessordirektiven) erlauben unter anderem Textersetzungen. Ihre Bedeutung nimmt im modernen C++ ab, sie werden aber immer noch gebraucht. Anschließend werden Grundsätze der modularen Gestaltung behandelt, ohne deren Einhaltung große Programme oder Programmsysteme kaum mehr handhabbar sind. Der Einsatz von Funktionen mit parametrisierten Datentypen ermöglicht einen breiteren Einsatz von Funktionen ohne fehlerträchtige Vervielfachung des Programmcodes. Zum Ende des Kapitels werden die Module vorgestellt.
| 2.1 | Funktionen |
Eine Funktion erledigt eine abgeschlossene Teilaufgabe. Die Teilaufgabe kann einfach, aber auch sehr komplex sein. Die notwendigen Daten werden der Funktion mitgegeben. Das Ergebnis der erledigten Aufgabe gibt sie an den Aufrufer (Auftraggeber) zurück. Eine einfache mathematische Funktion ist zum Beispiel y = sin(x), wobei x der Funktion als notwendiges Datum übergeben und y das Ergebnis zugewiesen wird. In C++ können auch nicht-mathematische Funktionen programmiert oder benutzt werden.
Eine Funktion muss nur einmal definiert werden. Anschließend kann sie beliebig oft nur durch Nennung ihres Namens aufgerufen werden, um die ihr zugewiesene Teilaufgabe abzuarbeiten. Dieses Prinzip setzt sich in dem Sinne fort, dass Teilaufgaben selbst wieder in weitere Teilaufgaben unterteilt sein können, die durch Funktionen zu bearbeiten sind. Wie in einer großen Firma die Aufgaben nur durch Arbeitsteilung, Delegation und eine sich daraus ergebende hierarchische Struktur zu bewältigen sind, wird in der Informatik die Komplexität einer Aufgabe durch Zerlegung in Teilaufgaben auf mehreren Ebenen reduziert. Bereits vorhandene Standardlösungen von Teilaufgaben können aus Funktionsbibliotheken abgerufen werden – ebenso wie neu entwickelte Funktionen in Bibliotheken aufgenommen werden können.
| 2.1.1 | Aufbau und Prototypen |
Auf Seite 79 wird die Fakultät einer Zahl berechnet. Dies soll die Grundlage für eine einfache Funktion fakultaet() bilden, die diese Aufgabe ausführt. Die Fakultät n! ist definiert als das Produkt n(n – 1)(n – 2)...3 · 2 · 1. Dabei ist 0! = 1 festgelegt. Das Beispiel zeigt die Integration der Funktion in ein main-Programm:
Listing 2.1: Beispielprogramm mit einer Funktion (cppbuch/k2/fakultaet.cpp)
#include <iostream> long long fakultaet(int); // Funktionsprototyp (Deklaration) using namespace std; int main() // der Kürze wegen ohne Prüfung der Eingabe { cout << "Fakultät˽berechnen.˽Zahl˽>=˽0?˽:"; int n {0}; cin >> n; cout << "Das˽Ergebnis˽ist˽" << fakultaet(n) << ’\n’; // Aufruf } long long fakultaet(int zahl) // Funktionsimplementation (Definition) { long long fak {1}; for (int i = 2; i <= zahl; ++i) { fak *= i; } return fak; }
Eine Deklaration sagt dem Compiler, dass eine Funktion oder eine Variable mit diesem Aussehen irgendwo definiert ist. Damit kennt er den Namen bereits, wenn er auf einen Aufruf der Funktion stößt, und ist in der Lage, eine Syntaxprüfung vorzunehmen. Eine Definition veranlasst den Compiler, entsprechenden Code zu erzeugen und den notwendigen Speicherplatz anzulegen. Eine Funktionsdeklaration, die nicht gleichzeitig eine Definition ist, wird Funktionsprototyp genannt. Eine Vereinbarung einer Variablen mit int i; ist sowohl eine Deklaration als auch eine Definition. Auf die Begriffe Deklaration und Definition wird in Abschnitt 2.4.3 genauer eingegangen. Der Aufruf der Funktion geschieht einfach durch Namensnennung. Von der Funktion auszuwertende Daten werden in runden Klammern ( ) übergeben. Der Funktionstyp void bedeutet, dass nichts zurückgegeben wird. Wenn eine Funktion einen Rückgabetyp ungleich void hat, muss im Funktionskörper {...} irgendwo ein Ergebnis dieses Typs mit der Anweisung return zurückgegeben werden. Wenn eine Funktion etwas tut, ohne dass ein Funktionsergebnis zurückgegeben wird, wirkt sie nur durch sogenannte Seiteneffekte. Andere Möglichkeiten der Ergebnisrückgabe werden in Abschnitt 2.2 vorgestellt. Die Wirkung eines Funktionsaufrufs ist, dass das zurückgegebene Ergebnis an die Stelle des Aufrufs tritt! Abbildung 2.1 zeigt die (leicht vereinfachte) Syntax eines Funktionsprototyps (vergleiche obiges Beispiel).

Der Rückgabetyp kann ein nahezu beliebiger Datentyp sein. Ausnahmen sind die Rückgabe einer Funktion sowie die Rückgabe des bisher noch nicht besprochenen C-Arrays. Betrachten Sie die Zuordnung der einzelnen Teile der obigen Deklaration von fakultaet():

Die Parameterliste besteht in diesem Fall nur aus einem einzigen Parametertyp. Je nach Aufgabenstellung bestehen für den Aufbau einer Parameterliste folgende Möglichkeiten:
Beispiel: |
|
leere Liste: |
int func(); |
gleichwertig ist (nicht empfohlen): |
int func(void); |
Liste mit Parametertypen: |
int func(int, char); |
Liste mit Parametertypen und -namen: |
int func(int x, char y); |
Parameternamen wie x und y dienen der Erläuterung. Sie dürfen entfallen, was aber nur dann tolerierbar ist, wenn der Sinn unmissverständlich ist. In allen anderen Fällen ist es vorteilhafter, die Namen hinzuschreiben, damit später die Benutzung der Funktion sofort klar wird, ohne die Dokumentation bemühen zu müssen. Abbildung 2.2 zeigt die Syntax einer Funktionsdefinition. Der eigentliche Programmcode ist im Block der Funktionsdefinition enthalten. Betrachten wir auch jetzt die Zuordnung der einzelnen Teile der obigen Definition von fakultaet(), wobei der Programmcode durch »...« angedeutet ist:


Die Formalparameterliste enthält im Unterschied zur reinen Deklaration zwingend einen Parameternamen (hier zahl), wenn er innerhalb des Blocks verwendet wird und deshalb dort bekannt sein muss. Der Name ist frei wählbar und völlig unabhängig vom Aufruf, weil er nur als Platzhalter dient. Abbildung 2.3 zeigt die Syntax eines Funktionsaufrufs.

Die Aktualparameterliste enthält Ausdrücke und/oder Namen der Objekte oder Variablen, die an die Funktion übergeben werden sollen. Sie kann leer sein. In unserem Beispiel besteht die Aktualparameterliste nur aus n. Dass der Datentyp von n mit dem Datentyp in der Deklaration übereinstimmt, wird vom Compiler geprüft. Der Linker stellt fest, ob eine entsprechende Definition der Funktion mit dem richtigen Datentyp in der Formalparameterliste vorhanden ist. Der Aufruf der Funktion bewirkt, dass der Wert von n an die Stelle des Platzhalters zahl gesetzt und dann der Programmcode im Block durchgeführt wird. Am Schluss wird die berechnete Fakultät mit dem richtigen Ergebnisdatentyp zurückgegeben. Zurückgegeben wird nur der Wert von fak, nicht fak selbst. Die Variablen fak und zahl sind lokal, d.h. im Hauptprogramm nicht bekannt und nicht zugreifbar. Ergebnisrückgabe heißt einfach, dass an die Stelle des Aufrufs von fakultaet() im Hauptprogramm das Ergebnis eingesetzt wird. Das Prinzip der Ersetzung der Formalparameter durch die Aktualparameter ist eine wichtige Voraussetzung, um eine Funktion universell verwenden zu können. Es ist ganz gleichgültig, ob die Funktion in einem Programm mit fakultaet(zahl) oder in einem anderen Programm mit fakultaet(xyz) aufgerufen wird, wenn nur der Datentyp des Parameters mit dem vorgegebenen übereinstimmt oder in diesen umgewandelt werden kann.

Übung
2.1 Schreiben Sie eine Funktion summe(int von, int bis). Zurückgegeben werden soll die Summe der Zahlen des durch die Argumente definierten Bereichs, also (von + (von + 1) + ... usw. + (bis -1) + bis). Testen Sie die Funktion mit einem main-Programm.

| 2.1.2 | nodiscard |
Wie [[fallthrough]] von Seite 73 ist auch [[nodiscard]] ein hilfreiches Attribut. Es bewirkt eine Warnung des Compilers, wenn der Rückgabewert einer mit [[nodiscard]] markierten Funktion, einer Struktur oder eines Aufzählungstyps ignoriert wird. Versehentlich fehlerhafte Aufrufe werden so vom Compiler entdeckt. Das Attribut kann mit einem erklärenden String versehen werden. Beispiele sehen Sie in Listing 2.2.
Listing 2.2: Vergessene Rückgabewerte aufspüren (cppbuch/k2/nodiscard.cpp)
#include <iostream> [[nodiscard]] int summe(int a, int b) { return a + b; } // Alternativ mit Erklärung [[nodiscard("Produkt˽ignoriert!")]] int produkt(int a, int b) { return a * b; } struct [[nodiscard]] S { int wert = 42; }; S getStruct() { S s; return s; } enum class [[nodiscard]] Farbe{rot, gelb, gruen}; Farbe getRot() { return Farbe::rot; } int main() { // Kein Problem: Hier werden alle Rückgabewerte verwendet. std::cout << summe(3, 4) << ’˽’ << produkt(3, 4) << ’\n’; std::cout << getStruct().wert << ’\n’; if (getRot() == Farbe::rot) { std::cout << "Die˽Farbe˽ist˽rot\n"; } // Ohne Verwendung des Rückgabewerts sind die folgenden Aufrufe sinnlos. // Sie führen zu Warnungen des Compilers. summe(3, 4); produkt(3, 4); getRot(); getStruct(); }
Verwenden Sie [[nodiscard]] besonders dann, wenn das Ignorieren eines Funktionswerts ein schwerer oder schwer zu entdeckender Fehler ist. Das Attribut eignet sich für Funktionen, die nur einen Wert zurückgeben. Bei Funktionen, die noch etwas anderes tun, möchte man manchmal die Freiheit haben, den Rückgabewert zu ignorieren. Ein Beispiel wäre eine Funktion zur Ausgabe von Daten auf den Bildschirm, die einen Fehlercode zurückgibt. Diesen wird man meistens ignorieren wollen.
| 2.1.3 | Gültigkeitsbereiche und Sichtbarkeit in Funktionen |
In C++ gelten Gültigkeits- und Sichtbarkeitsregeln für Variablen (siehe Seite 61). Die gleichen Regeln gelten auch für Funktionen. Der Funktionskörper ist ein Block, also ein durch geschweifte Klammern { } begrenztes Programmstück. Danach sind alle Variablen einer Funktion nicht im Hauptprogramm gültig und auch nicht sichtbar. Eine Sonderstellung haben die in der Parameterliste aufgeführten Variablen: Sie werden innerhalb der Funktion wie lokale Variablen betrachtet. Von außen gesehen stellen sie die Datenschnittstelle zur Funktion dar. Die Datenschnittstelle ist ein Übergabepunkt für Daten. Eingabeparameter dienen zur Übermittlung von Daten an die Funktion. Über Ausgabeparameter (Abschnitt 2.2.2) sowie den return-Mechanismus gibt eine Funktion Daten an den Aufrufer zurück. Die Variable zahl aus fakultaet() ist also von main() aus nicht zugreifbar, wie umgekehrt alle in main() deklarierten Variablen in fakultaet() nicht benutzt werden können. Diese Variablen sind lokal. Ein Beispiel soll das verdeutlichen, wobei hier die Deklaration von f1() gleichzeitig eine Definition ist, weil sie nicht nur den Namen vor dem Aufruf von f1() einführt, sondern auch den Funktionskörper enthält. Dieses Vorgehen ist nur für sehr kleine Programme wie hier zu empfehlen.
Listing 2.3: Sichtbarkeitsbereich (cppbuch/k2/scope.cpp)
#include <iostream> using namespace std; int a{1}; // überall bekannt, also global void f1() { // Deklaration und Definition int c{3}; // nur in f1() bekannt, also lokal cout << "f1:˽c=˽" << c << ’\n’; cout << "f1:˽globales˽a=˽" << a << ’\n’; } int main() { cout << "main:˽globales˽a=˽" << a << ’\n’; // cout << "f1: c= "<< c; ist nicht compilierbar, weil c in main() unbekannt ist. f1(); // Aufruf von f1() }
Das Programm erzeugt folgende Ausgabe:
Beim Betreten eines Blocks wird für die innerhalb des Blocks deklarierten Variablen Speicherplatz beschafft; die Variablen werden gegebenenfalls initialisiert. Der Speicherplatz wird bei Verlassen des Blocks wieder freigegeben. Dies gilt auch für Variablen in Funktionen, wobei der Aufruf einer Funktion dem Betreten des Blocks entspricht. Die Rückkehr zum Aufrufer der Funktion wirkt wie das Verlassen des Blocks.
| 2.1.4 | Lokale static-Variable: Funktion mit Gedächtnis |
Die Ausnahme bildet eine Variable, die innerhalb eines Blocks oder einer Funktion als static definiert wird. Wenn sie mit einer Konstante, die schon zur Compilationszeit bekannt ist, initialisiert wird, geschieht die Initialisierung vor dem Aufruf jedweder Funktion. In allen anderen Fällen wird die Variable beim ersten Aufruf der Funktion initialisiert. Im Beispiel unten wird anz schon vor dem Aufruf von func() mit 0 initialisiert (zur Compilationszeit bekannte Konstante). Würde anz den Wert von einer anderen Funktion g() erhalten, zum Beispiel static int anz = g();, dann würde anz erst beim ersten Aufruf von func() initialisiert. Falls kein Initialisierungswert vorgegeben ist, werden static-Zahlen auf 0 gesetzt. static-Variablen wirken wie ein Gedächtnis für eine Funktion, weil sie zwischen Funktionsaufrufen ihren Wert nicht verlieren. Eine Funktion, die anzeigt, wie oft sie aufgerufen wurde, sieht so aus:
Die Ausgabe des Programms ist
Ohne das Schlüsselwort static würde drei Mal 1 ausgegeben werden, weil die Zählung stets bei 0 begänne. Lokale static-Variablen sind globalen Variablen vorzuziehen, weil unabsichtliche Änderungen in anderen Funktionen vermieden werden und mit diesen Variablen verbundene Fehler leichter lokalisiert werden können. Außerdem erfordert eine globale Variable eine Absprache unter allen Benutzern der Funktion über den Namen. Das soll aber vermieden werden, um eine Funktion universell einsetzbar zu machen.
| 2.2 | Schnittstellen zum Datentransfer |
Der Datentransfer in Funktionen hinein und aus Funktionen heraus kann unterschiedlich gestaltet werden. Er wird durch die Beschreibung der Schnittstelle festgelegt. Unter Schnittstelle ist eine formale Vereinbarung zwischen Aufrufer und Funktion über die Art und Weise des Datentransports zu verstehen und darüber, was die Funktion leistet. In diesem Zusammenhang sei nur der Datenfluss betrachtet. Die Schnittstelle wird durch den Funktionsprototyp eindeutig beschrieben und enthält
den Rückgabetyp der Funktion,
den Funktionsnamen,
Parametertypen, die der Funktion bekannt gemacht werden, und somit
die Art der Parameterübergabe.
Der Compiler prüft, ob die Definition der Schnittstelle bei einem Funktionsaufruf eingehalten wird. Zusätzlich zur Rückgabe eines Funktionswerts gibt es die Möglichkeit, die an die Funktion über die Parameterliste gegebenen Daten zu modifizieren. Danach unterscheiden wir zwei Arten des Datentransports: die Übergabe per Wert und per Referenz.
| 2.2.1 | Übergabe per Wert |
Der Wert wird kopiert und der Funktion übergeben. Innerhalb der Funktion wird mit der Kopie weitergearbeitet, das Original beim Aufrufer bleibt unverändert erhalten. Im Beispiel wird beim Aufruf der Funktion addiere_5() der aktuelle Wert von i in die funktionslokale Variable x kopiert, die in der Funktion verändert wird. Der Rückgabewert wird der Variablen erg zugewiesen, i hat nach dem Aufruf denselben Wert wie zuvor. Abbildung 2.4 verdeutlicht den Ablauf.

Abbildung 2.4: Parameterübergabe per Wert. Bezug: Listing 2.5
Listing 2.5: Übergabe per Wert (cppbuch/k2/perWert.cpp)
#include <iostream> [[nodiscard]] int addiere_5(int); // Deklaration (Funktionsprototyp) int main() { int i{0}; std::cout << i << "˽=˽Wert˽von˽i\n"; auto erg = addiere_5(i); // Aufruf (auto statt int) std::cout << erg << "˽=˽Ergebnis˽von˽addiere_5\n"; std::cout << i << "˽=˽i˽unverändert!\n"; } int addiere_5(int x) // Definition { x += 5; return x; }
Die Übergabe per Wert soll generell bevorzugt werden, wenn ein Objekt aus Sicht des Aufrufers nicht geändert werden soll und es nicht viel Speicherplatz einnimmt. Es kann sein, dass das übergebene Objekt auch in der Funktion nicht geändert werden soll. Der Compiler kann eine versehentliche Änderung verhindern, wenn der Typ mit const gekennzeichnet wird:
Besonders bei längeren Programmen kann schon mal eine versehentliche Änderung vorkommen, die nicht sofort gesehen wird. Dann ist die Fehlermeldung des Compilers hilfreich. Bei den vielen kurzen Beispielen dieses Buchs wird bei der Übergabe per Wert meistens auf die Kennzeichnung mit const verzichtet.
Übungen
2.2 Schreiben Sie eine Funktion int dauerInSekunden(int stunden, int minuten, int sekunden), die die Gesamtzahl der Sekunden zurückgibt, berechnet aus den Parametern.
2.3 Schreiben Sie eine Funktion double power(double x, int y), die xy berechnen soll. Wenn Sie nicht mehr genau wissen sollten, was xy bedeutet – hier ein paar Beispiele: x3 = x · x · x, x–2 = 1/(x · x), x0 = 1.
Rekursion
Innerhalb von Funktionen können andere Funktionen aufgerufen werden, die wiederum andere Funktionen aufrufen. Die Verschachtelung kann beliebig tief sein. Der Aufruf einer Funktion durch sich selbst wird Rekursion genannt. Das Programm zur Berechnung der Quersumme einer Zahl zeigt die Rekursion:
Listing 2.6: Beispielprogramm mit Rekursion (cppbuch/k2/qsum.cpp)
#include <iostream> [[nodiscard]] int qsum(long z) // Parameter per Wert übergeben (Grunddatentyp) { if (z != 0) { int letzteZiffer = z % 10; return letzteZiffer + qsum(z / 10); // Rekursion } else { // Abbruchbedingung z == 0 return 0; } } int main() { std::cout << "Zahl:˽"; long zahl {0L}; std::cin >> zahl; std::cout << "Quersumme˽=˽" << qsum(zahl) << ’\n’; }
Die letzte Ziffer einer Zahl erhält man durch modulo 10 (Restbildung). Sie kann durch ganzzahlige Division durch 10 von der Zahl abgetrennt werden. Anstatt die Summation in einer Schleife vorzunehmen, lässt sich das Prinzip des Programms in zwei Sätzen zusammenfassen:
1. Die Quersumme der Zahl 0 ist 0.
2. Die Quersumme einer Zahl ist gleich der letzten Ziffer plus der Quersumme der Zahl, die um diese Ziffer gekürzt wurde.
Die Quersumme von 348156 ist also (6 + die Quersumme von 34815). Auf jede Quersumme wird Satz 2 angewendet, bis Satz 1 gilt. Durch das sukzessive Abtrennen wird die Zahl irgendwann 0, sodass Satz 1 erfüllt ist und die Rekursion anhält. In diesem Fall ist die Verschachtelungstiefe gleich der Anzahl der Ziffern. Eine Rekursion muss auf eine Abbruchbedingung zulaufen, damit keine unendlich tiefe Verschachtelung entsteht mit der Folge eines Stacküberlaufs. Zum Vergleich sei hier eine iterative Variante (= mit einer Schleife) gezeigt:
Übung
2.4 Schreiben Sie die Funktion zur Berechnung der Fakultät von Seite 116 als rekursive Funktion. Dabei gilt: 0! = 1, 1! = 1, n! = n · (n – 1)!
| 2.2.2 | Übergabe per Referenz |
Wenn ein übergebenes Objekt modifiziert werden soll, kann die Übergabe durch eine Referenz des Objekts geschehen. Aber was ist überhaupt eine Referenz?
Referenz
Eine Referenz ist ein Datentyp, der einen Verweis auf ein Objekt oder eine Funktion liefert. Eine Referenz bildet einen Alias (anderer Name) für ein Objekt, über den es ansprechbar ist. Ein Objekt hat damit zwei Namen! Der Compiler »weiß« aufgrund der Deklaration, dass es sich um eine Referenz handelt und nicht etwa um ein neues Objekt. Um eine Variable als Referenz zu deklarieren, wird das &-Zeichen benutzt, das neben dem bitweisen UND und dem (noch nicht benutzten) Adressoperator nun die dritte Bedeutung hat. Beispiele:
Wo das &-Zeichen zwischen int und r steht, ist unerheblich. Es bezieht sich nur auf den direkt folgenden Namen, weswegen r2 vom Typ int ist und nicht vom Typ int&. Pro Zeile nur eine Deklaration zu schreiben vermeidet dieses mögliche Missverständnis. In diesem Buch wird die Schreibweise int& r bevorzugt, um zu verdeutlichen, dass die Referenzeigenschaft zum Typ gehört. Eine Referenz wird genau wie eine Variable benutzt, der Compiler weiß, dass sie ein Alias ist. Referenzen müssen bei der Deklaration initialisiert werden. Es ist nicht möglich, eine Referenz nach der Initialisierung auf einen anderen Namen zu ändern. Die Deklaration int& s = r; könnte vordergründig so interpretiert werden, dass die Referenz s eine Referenz auf r wäre, weil sie ja mit r initialisiert wird. Der Compiler setzt aber, wie oben beschrieben, auf der rechten Seite für r das referenzierte Objekt i ein. s ist daher nur ein weiterer Alias-Name für i. Mit anderen Worten, wenn nach den obigen Deklarationen einer der Namen i, r oder s benutzt wird, könnte man ihn durch einen der anderen beiden ersetzen, ohne dass ein Programm in seiner Bedeutung geändert wird. Zusammengefasst:
Auf Objekte wird nur über symbolische Namen (Bezeichner) oder Zeiger zugegriffen. Zeiger (in Kapitel 4 beschrieben) seien hier ausgeklammert.
Die Bezeichner (Namen) von Referenzen sind nichts anderes als Aliasse. Für ein Objekt kann es keinen oder beliebig viele Aliasse geben, die wie andere Bezeichner auch verwendet werden.
Alle Bezeichner für dasselbe Objekt sind in der Verwendung gleichwertig. Die obige Deklaration int& s = r; hat daher dieselbe Wirkung wie int& s = i;.
Funktionsaufruf mit Referenzparametern
Die Syntax des Aufrufs ist die gleiche wie bei der Übergabe per Wert. Anstatt mit einer Kopie wird jedoch mit dem Original gearbeitet, wenn auch unter anderem Namen. Der Name ist lokal bezüglich der Funktion und bezieht sich auf das übergebene Objekt. Es wird also keine Kopie angelegt. Daher ergibt sich bei großen Objekten ein Laufzeitvorteil. Änderungen innerhalb der Funktion wirken sich direkt auf das Original aus. Das Prinzip der Übergabe per Referenz zeigt das folgende Beispielprogramm.
Listing 2.8: Übergabe per Referenz (cppbuch/k2/perRef.cpp)
#include <iostream> using namespace std; void addiere_7 (int& zahl); // int& = Referenz auf int int main() { int i{0}; cout << i << "˽=˽alter˽Wert˽von˽i\n"; addiere_7(i); // Syntax wie bei Übergabe per Wert cout << i << "˽=˽neuer˽Wert˽von˽i˽nach˽addiere_7\n"; } void addiere_7(int& x) // int& = Referenz auf int { x += 7; // Original des Aufrufers wird geändert! }
Abbildung 2.5 zeigt, dass dasselbe Objekt unter verschiedenen Namen vom aufrufenden Programm und von der Funktion zugreifbar ist.

Abbildung 2.5: Parameterübergabe per Referenz. Bezug: Listing 2.8
Die Stellung des &-Zeichens in der Parameterliste ist beliebig. (int& x) ist genauso richtig wie (int &x) oder (int & x). Bei der Diskussion über Laufzeitvorteile durch Referenzparameter darf nicht vergessen werden, dass es häufig Fälle gibt, in denen bewusst die Kopie eines Parameters ohne Auswirkung auf das Original geändert werden soll, sodass nur eine Übergabe per Wert in Frage kommt. Ein Beispiel ist der Parameter z der iterativen Funktion qsum() von Seite 124.
Es wurde darauf hingewiesen, dass die Übergabe von nicht zu verändernden Objekten generell per Wert erfolgen soll, mit der Ausnahme großer Objekte aus Effizienz- und Speicherplatzgründen. Wenn zwar der Laufzeitvorteil, aber keine Änderung des Originals erwünscht ist, kommt die Übergabe eines Objekts als Referenz auf const in Frage. Die Angabe in der Parameterliste könnte etwa const TYP& unveraenderliches_grosses_Objekt lauten. Innerhalb der Funktion darf auf das übergebene Objekt natürlich nur lesend zugegriffen werden; dies wird vom Compiler geprüft.
| 2.2.3 | Gefahren bei der Rückgabe von Referenzen |
Achten Sie bei der Rückgabe von Referenzen darauf, dass das zugehörige Objekt tatsächlich noch existiert. Das folgende Beispiel zeigt, wie man es nicht machen soll:
Listing 2.9: Fehlerhafte max-Funktion
int& maxwert(int a, int b) // Rückgabetyp ist Referenz { // a und b sind lokale Kopien der übergebenen Daten! if (a > b) return a; // Fehler! else return b; // Fehler! } int main() { int x = 17; int y = 4; int& z = maxwert(x, y); cout << z << ’\n’; // z ist undefiniert int x1 = maxwert(y, x); // Anweisung enthält kein z! cout << z << ’\n’; // vermutlich anderer Wert! }
Fehler! Begründung: Es wird eine Referenz auf eine lokale Variable zurückgegeben, die nicht mehr definiert ist und deren Speicherplatz früher oder später überschrieben wird. Korrekt wäre es, nicht die Referenz, sondern eine Kopie des Objekts zurückzugeben (Rückgabetyp int statt int&):
Eine weitere Möglichkeit int& maxwert(int& a, int& b) {...} ist nicht empfehlenswert. Sie funktioniert zwar im obigen Programmbeispiel, erlaubt aber keine konstanten Argumente wie zum Beispiel in einem Aufruf z = maxwert(23, y). Eine literale Konstante hat nicht unbedingt eine Adresse, weil der Compiler den Wert direkt in das Compilationsergebnis eintragen kann, ohne sich auf eine Speicherstelle zu beziehen. int maxwert(const int& a, const int& b) {...} hingegen würde vom Compiler akzeptiert. Bei der Übergabe eines Literals würde ein temporäres int-Objekt erzeugt werden, das in der Funktion zum Vergleich herangezogen wird. Weil int-Objekte sehr klein sind, ist die Erzeugung einer Kopie viel schneller als die Bearbeitung einer Referenz. Deswegen: Statt const int& einfach nur int schreiben!
Übungen
2.5 Referenzparameter können zur Ergebnisrückgabe verwendet werden. Schreiben Sie eine Funktion void maxwert(int x, int y, int& erg), die den Maximalwert der beiden ersten Argumente im Parameter erg zurückgibt.
2.6 Schreiben Sie eine Funktion void str_umkehr(string& s), die die Reihenfolge der Zeichen im String s umkehrt.
| 2.2.4 | Vorgegebene Parameterwerte und unterschiedliche Parameterzahl |
Funktionen können mit unterschiedlicher Parameteranzahl aufgerufen werden. In der Deklaration des Prototyps werden für die nicht angegebenen Parameter vorgegebene Werte (englisch default values) spezifiziert. Der Vorteil liegt nicht in der ersparten Schreibarbeit, weil die Standardparameter nicht angegeben werden müssen! Eine Funktion kann um verschiedene Eigenschaften erweitert werden, die durch weitere Parameter nutzbar gemacht werden. Die Programme, die die alte Version der Funktion benutzen, sollen aber weiterhin wartbar und übersetzbar sein, ohne dass jeder Funktionsaufruf geändert werden muss. Nehmen wir an, dass ein Programm eine Funktion adressenSortieren() zum Beispiel aus einer firmenspezifischen Bibliothek benutzt. Die Funktion sortiert eine Adressendatei alphabetisch nach Nachnamen. Der Aufruf sei:
Die Sortierung nach Postleitzahlen und Telefonnummern wurde später benötigt und nachträglich eingebaut. Der Aufruf in einer neuen Anwendung könnte lauten:
Das alte Programm1 soll ohne Änderung übersetzbar sein. Durch den Funktionsaufruf mit unterschiedlicher Parameterzahl ist dies möglich. Der Vorgabewert wäre hier Nachname. Die Parameter mit Vorgabewerten erscheinen in der Deklaration nach den anderen Parametern. Programmbeispiel:
Listing 2.10: Vorgegebene Parameter (cppbuch/k2/preis.cpp)
#include <iostream> #include <string> // Funktionsprototyp, 2. Parameter mit Vorgabewert: void preisAnzeige(double preis, const std::string& waehrung = "Euro"); // Hauptprogramm int main() { // zwei Aufrufe mit unterschiedlicher Parameterzahl : preisAnzeige(12.35); // vorgegebener Parameter wird eingesetzt preisAnzeige(99.99, "US-Dollar"); } // Funktionsimplementation void preisAnzeige(double preis, const std::string& waehrung) { std::cout << preis << ’˽’ << waehrung << ’\n’; }
Ausgabe des Programms: 12.35 Euro und 99.99 US-Dollar
Falls der Preis in Euro angezeigt werden soll, braucht keine Währung genannt zu werden. Dies ist der Normalfall. Andernfalls ist die Währungsbezeichnung als Zeichenkette als zweites Argument zu übergeben.
| 2.2.5 | Überladen von Funktionen |
Funktionen können überladen werden. Deswegen darf für eine gleichartige Operation mit Daten eines anderen Typs derselbe Funktionsname verwendet werden, obwohl es sich nicht um dieselbe Funktion handelt. Ein Programm wird dadurch besser lesbar. Die Entscheidung, welche Funktion von mehreren Funktionen gleichen Namens ausgewählt wird, hängt vom Kontext, also der Umgebungsinformation ab: Der Compiler trifft die richtige Zuordnung anhand der Signatur der Funktion, die er mit dem Aufruf vergleicht. Die Signatur besteht aus der Kombination des Funktionsnamens mit Reihenfolge und Typen der Parameter. Beispiel:
Listing 2.11: Überladen von Funktionen (cppbuch/k2/ueberlad.cpp)
#include <iostream> using namespace std; [[nodiscard]] double maximum(double x, double y) { return x > y ? x : y; // Bedingungsoperator siehe Seite 70 } // zweite Funktion gleichen Namens, aber unterschiedlicher Signatur [[nodiscard]] int maximum(int x, int y) { return x > y ? x : y; } int main() { double a{100.2}; double b{333.777}; int c{1700}; int d{1000}; cout << maximum(a, b) << ’\n’; // Aufruf von maximum(double, double) cout << maximum(c, d) << ’\n’; // Aufruf von maximum(int, int) }
Der Compiler versucht, nach bestimmten Regeln immer die beste Übereinstimmung mit den Parametertypen zu finden:
führt zum Aufruf von maximum(double, double) im obigen Programm. Dagegen führt maximum(31,’A’) zum Aufruf von maximum(int, int). Der Grund: float-Werte werden in double-Werte konvertiert und der Datentyp char wird auf int abgebildet. Dies gelingt nur bei einfachen und zueinander passenden Datentypen und eindeutigen Zuordnungen. Der Aufruf maximum(3.1, 7) ist nicht eindeutig interpretierbar. Das erste Argument spricht für maximum(double, double), das zweite für maximum(int, int). Der Compiler kann sich nicht entscheiden und erzeugt eine Fehlermeldung. Es bleibt einem natürlich unbenommen, selbst eine Typumwandlung vorzunehmen. Die Aufrufe
sind daher zulässig und unproblematisch, abgesehen vom Informationsverlust durch die Typumwandlung in der letzten Zeile. Die Umwandlung nach int schneidet die Nachkommaziffern ab. Der Typ char kann vorzeichenbehaftet (signed) sein. In diesem Fall ergibt die interne Umwandlung von int in char nur dann ein positives Ergebnis, wenn nach dem Abschneiden der höherwertigen Bits das Bit Nr. 7 nicht gesetzt ist, wobei die Zählung mit dem niedrigstwertigen Bit beginnt, das die Nr. 0 trägt:
Das Abschneiden der höherwertigen Bits wird deutlich, wenn zum Beispiel 600 als 29+88 geschrieben wird.
Gemäß der Regel, dass ein C++-Name, gleichgültig ob Funktions- oder Variablenname, alle gleichen Namen eines äußeren Gültigkeitsbereichs überdeckt, funktioniert das oben beschriebene Überladen nur innerhalb desselben Gültigkeitsbereichs.
| 2.2.6 | Funktion main() |
main() ist eine spezielle Funktion. Jedes C++-Programm startet definitionsgemäß mit main(), sodass main() in jedem C++-Programm genau einmal vorhanden sein muss. Die Funktion ist nicht vom Compiler vordefiniert, ihr Rückgabetyp soll int sein und ist ansonsten aber implementationsabhängig. main() kann nicht überladen oder von einer anderen Funktion aufgerufen werden. Die zwei folgenden Varianten sind mindestens gefordert und werden daher von jedem Compilerhersteller zur Verfügung gestellt:
argc gibt die Anzahl der main() übergebenen Arumente an, wobei der Aufruf des Programms mitzählt. Die zweite Variante verwendet mit argv Zeiger (char*) und C-Arrays, die in Kapitel 4 besprochen werden. Die Auswertung der Argumente wird bis dahin zurückgestellt.
Es bleibt dem Hersteller eines Compilers überlassen, ob er weitere Versionen mit erweiterten Parameterlisten anbietet. Die mit return zurückgegebene Zahl wird an die aufrufende Umgebung des Programms übergeben. Damit kann bei einer Abfolge von Programmen ein Programm den Rückgabewert des Vorgängers abfragen, zum Beispiel zur gezielten Reaktion auf Fehler. Wenn irgendwo im Programm die im Header <cstdlib> deklarierte Funktion void exit(int) aufgerufen wird, ist die Wirkung dieselbe, wobei jedoch der aktuelle Block verlassen wird, ohne automatische Objekte (Stackvariablen) freizugeben. Der Argumentwert von exit() ist dann der Rückgabewert des Programms. return darf in main() weggelassen werden; dann wird automatisch 0 zurückgegeben.
| 2.2.7 | Beispiel Taschenrechnersimulation1 |
Um ein etwas umfangreicheres Beispiel mit Funktionen zu geben, wird ein Taschenrechner simuliert, eine beliebte Aufgabe. Die hier verwendete und nur kurz beschriebene Methode des rekursiven Abstiegs ermöglicht es, auf elegante und einfache Art beliebig verschachtelte Ausdrücke auszuwerten. In [ALSU] können fortgeschrittene Interessierte ausführliche Erläuterungen der Methode finden.
Syntax eines mathematischen Ausdrucks
Zunächst sei die Syntax eines mathematischen Ausdrucks wie zum Beispiel (13 + 7) ∗ 5 – (2 ∗ 3 + 7)/(–8) beschrieben, wobei der Schrägstrich das Zeichen für die ganzzahlige Division sein soll. Ein Ausdruck wird als Summand oder Summe von Summanden aufgefasst, die sich ihrerseits aus Faktoren zusammensetzen. Durch die zuerst auszuführende Berechnung der Faktoren ist die Prioritätsreihenfolge »Punktrechnung vor Strichrechnung« gewährleistet. Ein Faktor kann eine Zahl oder ein Ausdruck in Klammern sein. Die Verschachtelung mit Klammern sei beliebig möglich. Eine Zahl besteht aus einer oder mehreren Ziffern. Eine Ziffer ist eines der Zeichen 0 bis 9. Zur Vereinfachung sei ein mathematischer Ausdruck auf ganze Zahlen und die vier Grundrechenarten beschränkt. Leerzeichen sind im Ausdruck nicht erlaubt. Abbildung 2.6 zeigt die Syntax eines Ausdrucks.
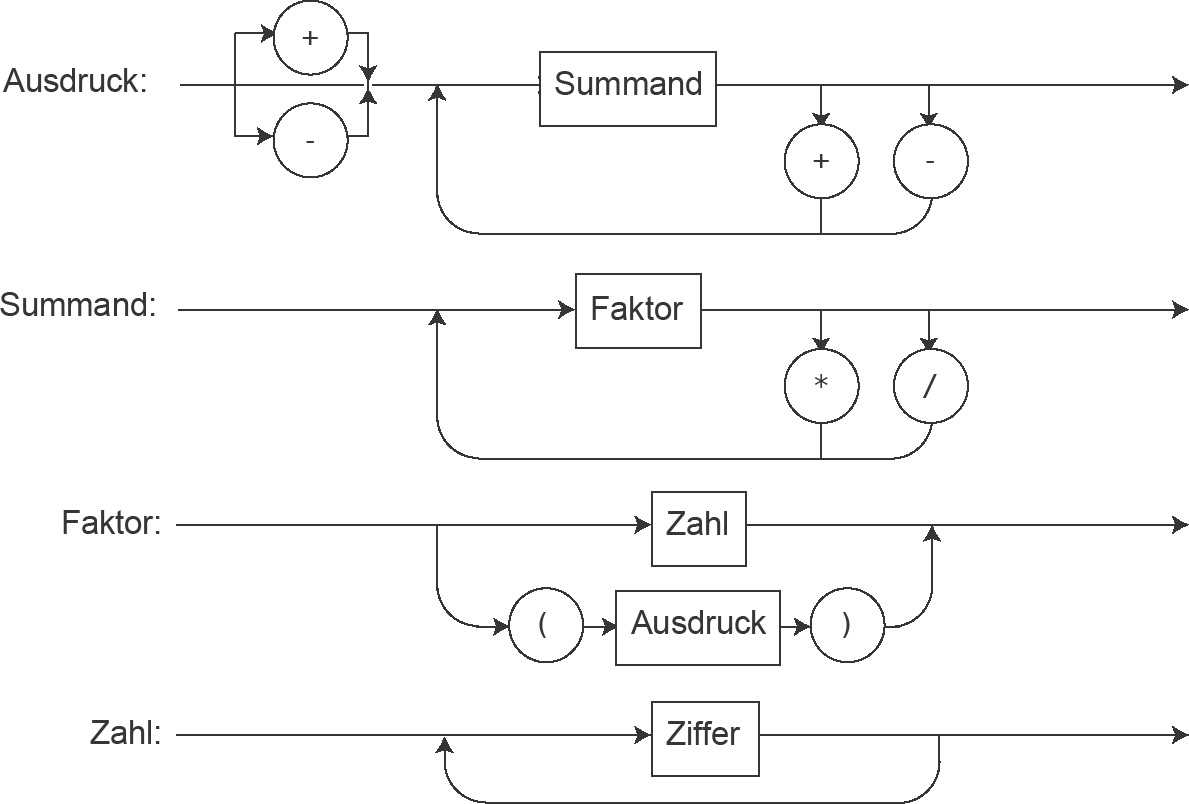
Aus dem Syntaxdiagramm wird die indirekte Rekursion deutlich: Ausdruck ruft Summand, Summand ruft Faktor, Faktor ruft Ausdruck etc. Da jeder arithmetische Ausdruck endlich ist, endet die Rekursion irgendwann. Die Auflösung eines Ausdrucks bis zum Rekursionsende heißt rekursiver Abstieg. Abbildung 2.7 zeigt den Ableitungsbaum des Ausdrucks (12 + 3) ∗ 4, in dem die äußeren Elemente (die »Blätter« des »Baums«) die Zahl- oder Operatorzeichen sind. Die inneren Elemente, durch Kästen dargestellt, sind noch aufzulösen.
Abbildung 2.7 ist wie folgt zu interpretieren: Der Ausdruck ist ein Summand, nämlich (12 + 3) ∗ 4, bestehend aus dem Faktor (12 + 3), dem Multiplikationszeichen * und dem Faktor 4. Die Faktoren werden dem Syntaxdiagramm entsprechend weiter ausgewertet. Der erste Faktor zum Beispiel ist ein durch runde Klammern () begrenzter Ausdruck usw.

Wir gehen so vor, dass wir das obige Syntaxdiagramm 2.6 direkt in ein Programm transformieren. Rekursive Syntaxstrukturen werden dabei auf rekursive Strukturen im Programm abgebildet. Ziel:
Berechnung beliebig verschachtelter arithmetischer Ausdrücke, wobei hier zur Vereinfachung nur ganze Zahlen zugelassen sein sollen.
Leerzeichen sind nicht erlaubt; keine aufwendige Syntaxprüfung.
Vorrangregeln sollen beachtet werden.
Wie kann man nun ein Programm schreiben, das die gewünschte Berechnung liefert? Zunächst ein paar Vorgaben:
a) Das Programm soll ein Promptzeichen >> ausgeben und dann die Eingabe des Ausdrucks erwarten.
b) Der Ausdruck wird mit  abgeschlossen. Anschließend wird das Ergebnis ausgegeben.
abgeschlossen. Anschließend wird das Ergebnis ausgegeben.
c) a) und b) sollen wiederholt werden, bis ’e’ als Endekennung eingegeben wird.
Damit kann das Hauptprogramm geschrieben werden:
cin.get(ch) ist eine vordefinierte Prozedur, die das nächste Zeichen aus dem Tastaturpuffer, in den das Betriebssystem die eingegebenen Zeichen der Reihe nach abgelegt hat, einliest, wie auf Seite 105 beschrieben. Mit jedem weiteren Aufruf von cin.get() wird ein weiteres Zeichen geholt. cin >> ch wird nicht gewählt, weil  dann ignoriert wird. Nachdem der Rahmen abgesteckt ist, geht es nun an den Kern des Problems: ausdruck() ist offensichtlich eine Funktion, die das eingegebene Zeichen auswertet und einen int-Wert, nämlich das Ergebnis, zurückgibt. Wir haben es uns einfach gemacht und die ganze Arbeit an die Funktion delegiert. Wie kann die Funktion ausdruck() aussehen?
dann ignoriert wird. Nachdem der Rahmen abgesteckt ist, geht es nun an den Kern des Problems: ausdruck() ist offensichtlich eine Funktion, die das eingegebene Zeichen auswertet und einen int-Wert, nämlich das Ergebnis, zurückgibt. Wir haben es uns einfach gemacht und die ganze Arbeit an die Funktion delegiert. Wie kann die Funktion ausdruck() aussehen?
Dazu ein paar Vorüberlegungen: Laut Syntaxdiagramm ist Ausdruck entweder
a) –Summand
b) +Summand oder einfach nur
c) Summand
sowie mögliche zusätzliche, durch + oder – getrennte Summanden. Man kann also die Zeichen + oder – gegebenenfalls überlesen und dann ausdruck() den Wert einer Funktion summand() zuweisen, die den Rest der Zeichenkette auswertet und ein int-Ergebnis zurückgibt. Das ermöglicht ausdruck(), seinerseits einen Teil der Arbeit an summand() zu delegieren. Einer schiebt es auf den anderen, wie im richtigen Leben! Daraus ergibt sich die Vorgehensweise:
Aus dem Syntaxdiagramm leitet sich die folgende syntaktische Konstruktion ab, wobei das aktuelle Zeichen überlesen wird, wenn es nicht zu dieser Konstruktion gehört. Andernfalls ist das Zeichen das erste zu analysierende Zeichen der syntaktischen Folgekonstruktion und wird der zugehörigen Funktion übergeben.
Die Folgekonstruktion wird als Funktion aufgerufen und verhält sich wie der Aufrufer. Wenn die Funktion auf ein Zeichen stößt, das nicht zu der zugehörigen syntaktischen Konstruktion passt, wird es an den Aufrufer zurückgegeben.
Beispiel:
Ausdruck: Aus dem Syntaxdiagramm ergibt sich Summand als folgende syntaktische Konstruktion. ’–’ oder ’+’ müssen gegebenenfalls übersprungen werden, weil sie kein Element von Summand sind.
Summand wird anschließend genauso behandelt wie Ausdruck usw. Die Rekursion muss wegen der endlichen Länge eines Ausdrucks irgendwann ein Ende haben.
Nach diesen Vorbemerkungen bilden wir das Syntaxdiagramm direkt auf ein C++-Programm ab, wobei dem syntaktischen Term Ausdruck eine Funktion mit dem Namen ausdruck() zugeordnet wird. Eine Schleife wird im Diagramm in eine while ()-Anweisung transformiert. Die Entsprechung zwischen dem Syntaxdiagramm auf Seite 131 und dem Programmcode ist offensichtlich. Die Variable c wird als Referenz übergeben, damit bei Ende der Funktion der neue Wert der aufrufenden Funktion zur weiteren Analyse zur Verfügung steht.
Listing 2.13: Funktion ausdruck()
[[nodiscard]] long ausdruck(char& c) // Übergabe per Referenz! { long a{0L}; // Hilfsvariable für Ausdruck if (c == ’-’) { std::cin.get(c); // - im Eingabestrom überspringen a = -summand(c); // Rest an summand() übergeben } else { if (c == ’+’) { std::cin.get(c); // + überspringen } a = summand(c); } while (c == ’+’ || c == ’-’) if (c == ’+’) { std::cin.get(c); // + überspringen a += summand(c); } else { std::cin.get(c); // - überspringen a -= summand(c); } return a; }
summand() wird auf die gleiche Art wie ausdruck() gebildet:
Auch faktor() wird auf ähnliche Art konstruiert:
Nun bleibt nur noch die Funktion zur Analyse einer Ziffernfolge:
[[nodiscard]] long zahl(char& c) { long z{0L}; // isdigit() ist eine Funktion, das zu true ausgewertet wird, // falls c ein Ziffernzeichen ist. Die Verwendung setzt #include <cctype> voraus. while (isdigit(c)) { // d.h. c >= ’0’ && c <= ’9’ // Zur Subtraktion von ’0’ siehe Seite 56. z = 10L*z + long(c-’0’); // implizite Typumwandlung cin.get(c); } return z; }

Hinweis
Das Verhalten von isdigit(c) ist undefiniert, wenn das Zeichen c nicht als unsigned char dargestellt werden kann und ungleich EOF ist, einem besonderen Zeichen für end of file, d.h. Ende einer Datei. Mit ASCII gibt es jedoch keine Probleme, weil die Werte der Zeichen ≥ 0 sind. Das Verhalten bei anderen Zeichensätzen ist nicht Thema dieses Buchs. Im Zweifel hilft eine Typumwandlung: isdigit(static_cast<unsigned char>(c)).
Letztlich ist die Umsetzung einer Syntax in ein Programm reine Fleißarbeit, wenn man weiß, wie es geht. Deswegen gibt es dafür Werkzeuge wie die Programme flex oder bison. Nun haben wir alle Bausteine zusammen, die zur Auswertung eines beliebig verschachtelten arithmetischen Ausdrucks nötig sind. Es bleibt Ihnen überlassen, das Programm zu vervollständigen, einschließlich Trennung von Prototypen und Definitionen, und es zum Laufen zu bringen. Erweiterungen können leicht eingebaut werden, um Leerzeichen an syntaktisch sinnvollen Stellen zu erlauben oder Hinweise auf Syntaxfehler auszugeben, wie in der Funktion faktor() (»Rechte Klammer fehlt!«). Falls doch noch Verständnisschwierigkeiten auftreten sollten, spielen Sie am besten selbst Computer, indem Sie einen Ausdruck Schritt für Schritt am Schreibtisch dem Programm folgend abarbeiten.
Übungen
2.7 Vervollständigen Sie das Beispiel in Abschnitt 2.2.7 (sofern Sie es bearbeitet haben) und bringen Sie es zum Laufen.
2.8 Schreiben Sie eine Funktion istAlphanumerisch(const string& text), die true zurückgibt, wenn text nur Buchstaben und Ziffern enthält, andernfalls false.
| 2.2.8 | Spezifikation von Funktionen |
Eine Funktion erledigt eine Teilaufgabe. Es ist sinnvoll, diese Teilaufgabe im Funktionskopf als Kommentar zu spezifizieren. Dazu gehören Annahmen über die Importschnittstelle (Eingabedaten, zum Beispiel Wertebereich), die Fehlerbedingungen, die Exportschnittstelle (Ausgabedaten). Die Bedingung, die ein Eingabeparameter erfüllen muss, damit die Funktion richtig arbeitet, nennt man Vorbedingung. Der Zustand eines Programms nach Abarbeitung der Funktion wird Nachbedingung genannt. Die Spezifikation ist für den Benutzer einer Funktion von Interesse. Wie die Aufgabe gelöst wird, soll im Funktionskopf nicht beschrieben werden, um die Möglichkeit einer späteren Änderung der Implementierung nicht einzuschränken, zum Beispiel einen langsamen durch einen schnelleren Algorithmus zu ersetzen. Das schließt nicht aus, dass innerhalb der Funktion manche Stellen kommentierend erklärt werden. Die Interna einer Funktion sind für diejenigen, die die Funktion nur benutzen, nicht von Interesse.
| 2.2.9 | Reihenfolge der Auswertung von Argumenten |
Die Reihenfolge der Auswertung und Initialisierung von Argumenten ist undefiniert! Betrachten Sie den Aufruf der Funktion g(), deren Argumente Aufrufe der Funktion f() sind: g( f(1), f(2));
Bevor g() ausgeführt wird, werden f(1) und f(2) berechnet – aber es bleibt dem Compiler überlassen, ob er erst f(1) berechnet und dann f(2), oder umgekehrt. Für das Ergebnis der Funktion g() spielt das nur dann eine Rolle, wenn der erste Aufruf von f() das Ergebnis des zweiten beeinflusst, etwa über eine gemeinsam benutzte globale Variable. Gute Programmierung vermeidet solche Seiteneffekte. Ähnliches gilt für einen Ausdruck der Art int ergebnis = f(1) + f(2) - f(3). Zuerst werden die Funktionswerte in undefinierter Reihenfolge berechnet. Dann erst wird das Gesamtergebnis aus den Teilergebnissen bestimmt, wobei der mathematische Ausdruck von links nach rechts ausgewertet wird.
| 2.3 | Präprozessordirektiven |
Präprozessordirektiven, auch Makros genannt, werden von dem Präprozessor ausgewertet, der dem Compiler vorgeschaltet ist. Makros können Textersetzungen sein oder dafür sorgen, dass eine Datei eingelesen wird. Der Präprozessor blendet auch alle Kommentare aus. Der Compiler bekommt nur das fertige Ergebnis zu sehen, nicht das erzeugende Makro und nicht die Kommentare. Das bedeutet, dass die Fehlersuche mit Werkzeugen erschwert sein kann. Es ist die Absicht des C++-Standardkomitees, nach und nach ohne Makros auszukommen. Zurzeit werden sie jedoch noch gebraucht. Präprozessordirektiven beginnen stets mit # am Zeilenanfang.
| 2.3.1 | #include |
Damit eine Datei einzeln für sich übersetzbar ist, müssen Konstanten und Funktionsprototypen bekannt sein. Das wird erreicht durch das Einschließen der Header-Dateien mit der Präprozessordirektive #include "filename.h". Anstelle von filename.h ist natürlich der tatsächliche Name einzutragen. Die Datei filename.h wird im aktuellen Verzeichnis gesucht und an dieser Stelle eingelesen. Die Wirkung ist, als ob an der Stelle der Include-Anweisung die Datei filename.h selbst hingeschrieben worden wäre. Die eingelesene Datei kann selbst auch #include-Direktiven enthalten, die genauso verarbeitet werden. Die Form ohne Anführungszeichen, aber mit spitzen Klammern (#include <iostream>) bedeutet, dass es sich um eine Datei in einem vordefinierten Verzeichnis handelt, zum Beispiel eine Systemdatei. Die Dateispezifikation kann außer dem Dateinamen den vollständigen Pfad enthalten, wobei Verzeichnisnamen durch einen Schrägstrich / zu trennen sind. In der MS-Windows-Welt ist auch der \ (Backslash) möglich, der Schrägstrich ist aber aus Portabilitätsgründen zu bevorzugen. Beispiele:
Listing 2.17: #include und Pfade
// relativer Pfad #include "dateiname.h" #include "../include/dateiname.h" // .. kennzeichnet das übergeordnete Verzeichnis // absoluter Pfad #include "/home/users/IhrName/cppbuch/include/dateiname.h" // Unix #include "C:/Users/IhrName/Documents/cppbuch/include/dateiname.h" // Windows
Wird die Datei im aktuellen Verzeichnis nicht gefunden, wird in den voreingestellten include-Verzeichnissen gesucht. Falls auch diese Suche fehlschlägt, wird versucht, die Direktive in der Standard-Header-Form zu interpretieren.
Die Standard-Header-Form ist #include <header>. Der Platzhalter header muss nicht unbedingt eine Datei sein. Die bisher gängigen Implementierungen fassen header jedoch als Datei auf, und es wird in den voreingestellten include-Verzeichnissen gesucht, die Suche im aktuellen Verzeichnis entfällt. Die voreingestellten include-Verzeichnisse sind die zum System gehörenden include-Verzeichnisse, in denen zum Beispiel mit #include <iostream> alles Nötige zur Ein- und Ausgabe gefunden wird. Sie können aber auch selbst include-Verzeichnisse als voreingestellte definieren, indem Sie die Option I übergeben.
bewirkt, dass der Compiler auch das Verzeichnis IncludeVerzeichnis als voreingestelltes auffasst. Wenn es in diesem Verzeichnis eine Datei meinHeader.h gibt, können Sie sie mit #include <meinHeader.h> einschließen, anstatt Anführungszeichen und ggf. den Pfad anzugeben.
| 2.3.2 | #define, #if, #ifdef, #ifndef, #elif, #else, #endif, #elifdef, #elifndef |
Mit diesen Makros kann der Compilationsablauf gesteuert werden: #define, #if defined (Abkürzung #ifdef), #if !defined (Abkürzung #ifndef), #else und #else if (Abkürzung #elif).
#define X definiert ein Symbol X.
#if B lässt den Compiler die nächste Zeile verarbeiten, falls der konstante Ausdruck B wahr ist.
#ifdef X fragt ab, ob X definiert ist.
#ifndef X fragt ab, ob X undefiniert ist.
#else gibt eine Alternative an.
#elif entspricht #else #if.
#endif beschließt jede mit #if beginnende Konstruktion.
#elifdef entspricht #elif defined (seit C++23).
#elifndef entspricht #elif !defined (seit C++23).
Das folgende Programm zeigt einige Möglichkeiten. Zum Ausprobieren kommentieren Sie am besten mal die eine mit #define beginnende Zeile aus, mal die andere und schließlich beide.
Listing 2.18: Beispiel für einfache Makros (cppbuch/k2/makros1.cpp)
#include <iostream> // Zum Testen eines oder beide der folgenden Makros auskommentieren #define zweig #define konstante 42 int main() { #ifdef zweig std::cout << "zweig˽ist˽definiert\n"; #elifdef konstante // Prüfung nur, wenn zweig undefiniert ist std::cout << "zweig˽undefiniert,˽konstante˽ist˽definiert\n"; #if konstante == 42 std::cout << "konstante˽ist˽42\n"; #endif #else std::cout << "zweig˽undefiniert,˽konstante˽undefiniert\n"; #endif }
In der Praxis verwenden Sie bitte keine Makros zur Definition von Konstanten! Nehmen Sie constexpr. Das Programm cppbuch/k2/compilerversion.cpp (hier nicht abgedruckt) zeigt die Abfrage vordefinierter Makros, um die Compilerart und -version des g++-Compilers abzufragen.
| 2.3.3 | Vermeiden mehrfacher Inkludierung |
Es kann zu Problemen beim Übersetzen führen, wenn Header-Dateien mehrfach eingebunden sind, sodass sich mehrfache Definitionen ergäben. Wenn zum Beispiel die Dateien a.h und b.h beide eine Datei c.h benötigen, enthalten beide Dateien die Anweisung #include "c.h". Wenn nun eine andere Datei sowohl a.h als auch b.h inkludiert, wird wegen der #include-Anweisungen c.h zweimal eingelesen. Abhilfe schafft die Makro-Kombination mit #ifndef, #define und #endif. So eine Kombination wird »Include-Guard« genannt.
Bedeutung:
Falls der (beliebige) Name C_H nicht definiert ist,
dann definiere C_H und akzeptiere alles bis #endif.
Die Wirkung des ersten Lesens von c.h als indirekte Folge von #include "a.h" ist:
#ifndef C_H liefert true, weil C_H noch nicht definiert ist.
#define C_H definiert C_H.
Alles bis #endif wird gelesen.
Die Wirkung des zweiten Durchlaufs von c.h als indirekte Folge von #include "b.h" ist:
#ifndef C_H liefert false (d.h. 0), weil C_H bereits definiert ist.
Alles bis #endif wird ignoriert.
#if-Blöcke erstrecken sich nicht über Dateigrenzen. Nach #endif in derselben Zeile stehender Text zur Dokumentation ist nur erlaubt, wenn er als Kommentar markiert ist (siehe oben: // C_H). Mit #undef kann eine Definition rückgängig gemacht werden.
Empfehlung für den Aufbau von Header-Dateien
Eine Möglichkeit für den Aufbau von Header-Dateien ist das folgende Schema:
Um stets eindeutige Namen zu gewährleisten, empfiehlt sich die Ableitung aus dem Dateinamen. Üblich ist auch das Hervorheben durch Großschreibung – so wird es in diesem Buch gehandhabt. Um die Wahrscheinlichkeit einer zufälligen Namensgleichheit weiter zu reduzieren, wird bei professionellen Projekten gelegentlich der Name des Projekts oder Teilprojekts aufgenommen.
| 2.3.4 | __has_include |
Es kann den Fall geben, dass eine andere Include-Datei genommen werden soll, wenn die eigentlich gewünschte nicht vorhanden ist. Mit __has_include lässt sich das erreichen. Ein einfaches Beispiel:
Listing 2.22: Verwendung von __has_include (cppbuch/k2/hasinclude.cpp)
#include <iostream> #include <string> #if __has_include(<filesystem>) #include <filesystem> const std::string meldung = "<filesystem>˽inkludiert."; #elif __has_include(<experimental/filesystem>) #include <experimental/filesystem> const std::string meldung = "<experimental/filesystem>˽inkludiert."; #else const std::string meldung = "filesystem-Header˽nicht˽gefunden"; #endif int main() { std::cout << meldung << ’\n’; }
| 2.3.5 | Textersetzung mit #define |
Es gibt eine weitere Bedeutung von #define, nämlich das Ersetzen von Makros durch Zeichenketten, wobei Parameter erlaubt sind. Mehrere Parameter werden durch Kommas getrennt. Die Makrodefinitionen
erlauben in einem Programm den Text
und würden interpretiert werden als:
Wenn ein Makro durch einen sehr langen Text ersetzt werden soll, der über mehrere Zeilen geht, ist jede Zeile mit Ausnahme der letzten mit einem \ (Backslash) abzuschließen. Zwischenraumzeichen wie Leerzeichen, Tabulatorzeichen usw. nach einem Backslash werden bis zum Beginn der neuen Zeile ignoriert. Es ist möglich, mit einem Makro ganze Unterprogramme für verschiedene Datentypen zu schreiben, wobei der Datentyp der Parameter ist, der dem Makro übergeben wird. Eine bessere Möglichkeit dafür sind jedoch Funktionsschablonen oder -templates, die in Abschnitt 2.9 besprochen werden.
Die Textersetzung mit #define soll im Allgemeinen nicht verwendet werden, wenn es Alternativen gibt. Wie gefährlich Makros sein können, lässt sich schon an dem einfachen QUAD-Makro zeigen. Der Aufruf
soll y das Quadrat von z zuweisen, nachdem z um 1 erhöht wurde – oder? In Wirklichkeit wird z zweimal erhöht:
und das Ergebnis ist falsch. Makronamen sind zudem einem symbolischen Debugger nicht zugänglich, wie die Pseudo-Konstante PI im obigen Beispiel. Ferner kann auf PI kein Zeiger (siehe Kapitel 4) gerichtet werden. Ein weiterer Nachteil von Makros besteht in der Umgehung der Typkontrolle:
Der Compiler bekommt das Makro durch den vorgeschalteten Präprozessor gar nicht erst zu sehen, sondern nur das Ergebnis der Makroexpansion (= Textersetzung) vorgesetzt. Deshalb sind Compilerfehlermeldungen bei Fehlern innerhalb großer Makros manchmal nicht ohne Weiteres nachvollziehbar. Eine übliche Anwendung des Makros #define zur Textersetzung mit Parametern ist die gezielte Ein- und Ausblendung von Testsequenzen in einem Programm. Beispiel:
Listing 2.23: Ein- und Ausblendung von Testsequenzen
#define TEST_EIN #ifdef TEST_EIN #define TESTANWEISUNG(irgendwas) irgendwas #else #define TESTANWEISUNG(irgendwas) /* nichts */ #endif // ... irgendwelcher Programmcode // nur im Test soll bei Fehlern eine Meldung ausgegeben werden: TESTANWEISUNG(if (x < 0) cout << "sqrt(negative˽Zahl)!\n";) y = sqrt(x); // ... mehr Programmcode
Der Parameter ist irgendwas. Falls TEST_EIN gesetzt ist, wird beim Compilieren durch den Präprozessor überall im Programm TESTANWEISUNG(irgendwas) durch irgendwas ersetzt. Wenn nach erfolgreichem Testen des Programms alle Testanweisungen verschwinden sollen, genügt es, die Zeile #define TEST_EIN zu löschen oder mit // in einen Kommentar zu verwandeln, mit der Wirkung, dass der Präprozessor jede TESTANWEISUNG() durch einen Kommentar /*nichts*/ ersetzt, der schlicht ignoriert wird. #define-Makros können mehrere durch Kommas getrennte Parameter enthalten. In irgendwas darf kein Komma enthalten sein, weil der Präprozessor sich sonst über die falsche Parameteranzahl beschwert. Zusammengefasst hat dieses Vorgehen zwei Vorteile:
Nach Testabschluss wird das lauffähige Programm schneller und benötigt weniger Speicher durch die fehlenden Testanweisungen.
Die Testanweisungen können im Programm zum späteren Gebrauch stehen bleiben. Sie müssen nicht einzeln auskommentiert oder gelöscht werden.
Die Technik, durch Makros gesteuert verschiedene Dinge ein- oder auszuschließen, wird sehr gut in den Header-Dateien des include-Verzeichnisses des Compilers sichtbar. Schauen Sie mal nach! Diese Art der Makrobenutzung ist weit verbreitet und hat ihre Vorteile. Es gibt jedoch eine Lösung, die nur mit den Sprachelementen von C++ auskommt (also ohne Makros, die vom Präprozessor verarbeitet werden). if constexpr wertet nur eine Bedingung aus, die schon zur Compilationszeit bekannt ist:
Diese Lösung hat die gleichen oben genannten Vorteile. Der Compiler ignoriert »toten« Programmcode von vornherein, falls nämlich nach Abschluss der Testphase test_ein zu false geändert und dadurch die if constexpr-Anweisung überflüssig wird.
Übung
2.9 Warum sollten Sie das oben vorgestellte Makro QUAD(x) nicht viel einfacher so formulieren: #define QUAD(x) x*x ?
| 2.3.6 | Umwandlung von Parametern in Zeichenketten |
Speziell für Testausgaben ist das Makro PRINT nützlich, das den Parameter mit vorangestelltem # in eine Zeichenkette wandelt. Ohne einen Namen oder einen Ausdruck doppelt schreiben zu müssen, sind Text und Ergebnis auf dem Bildschirm:
Damit kann kurz zum Beispiel
geschrieben werden, anstatt
mit dem möglichen Ergebnis int(xptr)-int(xptr2) = 4 auf dem Bildschirm.
| 2.3.7 | Verifizieren logischer Annahmen zur Laufzeit |
Ein weiteres nützliches Makro ist assert() zur Überprüfung logischer Annahmen, die an der Stelle des Makros gültig sein sollen. Insbesondere lassen sich die in Abschnitt 2.2.8 beschriebenen Vor- und Nachbedingungen verifizieren. Das Wort assert() leitet sich vom englischen Wort assertion ab, das auf Deutsch »Zusicherung« heißt. Zusicherungen werden mit dem Header <cassert> eingebunden. Beispiel:
Wenn die Annahme (index >= 0 && index < grenze) nicht stimmt, wird das Programm mit einer Fehlermeldung abgebrochen, die die zu verifizierende logische Annahme, die Datei und die Nummer der Zeile enthält, in der der Fehler aufgetreten ist. Eine andere Möglichkeit wäre das »Werfen einer Ausnahme« (Abschnitt 7.1). assert() ist wirkungslos, falls NDEBUG vor #include <cassert> definiert wurde, entweder durch die Präprozessordirektive #define NDEBUG oder durch Setzen des Compilerschalters –D, mit dem Makrodefinitionen voreingestellt werden. Anwendungsbeispiel: g++ -DNDEBUG meinProgramm.cpp. Übrigens: Weil assert() ein vom Präprozessor (nicht vom Compiler!) bearbeitetes Makro ist, sind Namespace-Vorsätze sinnlos (falsch: std::assert(..)).
Tipp
Vermeiden Sie Seiteneffekte in assert() und anderen Makros!
Eine in der Zusicherung aufgerufene Funktion wird bei gesetztem NDEBUG nicht ausgeführt! Falls NDEBUG definiert ist, wird die Datei nicht geöffnet, und weder wird das Maximum von x und y berechnet noch grenze ein Wert zugewiesen:
| 2.3.8 | Verifizieren logischer Annahmen zur Compilationszeit |
Die Prüfung mit assert geschieht zur Laufzeit. Manchmal möchte man aber bereits zur Compilationszeit bekannte Annahmen prüfen. Zum Beispiel soll long statt int eingesetzt werden, um den Zahlenbereich zu erweitern. Es ist aber systemabhängig und nicht garantiert, dass die Anzahl der Bits für long größer als die für int ist. Die Prüfung wird mit static_assert durchgeführt:
Wenn die Behauptung sizeof(long) > sizeof(int) falsch ist, gibt schon der Compiler die Fehlermeldung »long hat nicht mehr Bits als int!« aus. In diesem Fall bringt der Ersatz von int durch long gar nichts. static_assert ist kein Makro, sondern ein Schlüsselwort. Der zweite Parameter mit dem erklärenden Text kann weggelassen werden. static_assert(Bedingung) genügt.
| 2.3.9 | Fehler- und Warnmeldungen |
gibt an der betreffenden Stelle eine Warnung mit dem Meldungstext aus. Die Compilation wird fortgesetzt.
gibt an der betreffenden Stelle eine Fehlermeldung mit dem Meldungstext aus. Es wird davon ausgegangen, dass das Programm grundsätzlich fehlerhaft ist. Die Compilation wird abgebrochen.
| 2.3.10 | Fehler ohne Programmabbruch lokalisieren |
Das oben beschriebene assert() bricht das Programm im Fehlerfall ab. Manchmal möchte man ein Programm weiterlaufen lassen, aber dennoch unerwünschte Zustände dokumentieren. Dabei ist es hilfreich, wenn die betreffende Datei, die Funktion und die Zeilennummer bekannt sind. Dazu muss der Header <source_location> eingebunden werden. Das Listing 2.26 zeigt die Anwendung. Nehmen Sie bitte einfach das Beispiel als Rezept, weil hier nicht auf die Interna von source_location eingegangen werden kann.
Listing 2.26: Stelle im Programm ausgeben (cppbuch/k2/sourcelocation.cpp)
1 #include <iostream> 2 #include <source_location> 3 #include <string> 4 5 void log(const std::string& text, 6 const std::source_location& wo = std::source_location::current()) { 7 std::cout << text << "˽in˽Datei˽" << wo.file_name() 8 << ".˽Zeile˽" << wo.line() 9 << ",˽Funktion˽" << wo.function_name() << ’\n’; 10 } 11 12 int main() 13 { 14 int a {0}; 15 // ... Berechnungen, bei denen a > 0 werden soll 16 if (a <= 0) { // hat nicht geklappt 17 log("a˽<=˽0˽!˽Fehler"); 18 } 19 }
Das Programm gibt aus:
Es wird die Stelle des Aufrufs von log() ausgegeben, ermittelt durch die Funktion current(). Wenn es nur um die aktuelle Zeile geht, die in einem Programm ausgegeben werden soll, könnte man schreiben:
Einen ähnlichen Effekt kann man mit den Makros __FILE__, __func__ und __LINE__ erreichen, wie in Listing 2.27 gezeigt.
| 2.4 | Modulare Programmgestaltung |
C++ bietet eine große Flexibilität in der Organisierung eines Softwaresystems. Die Erfahrung lehrt, dass die Aufteilung eines großen Programms in einzelne, getrennt übersetzbare Dateien, die zusammengehörige Programmteile enthalten, sinnvoll ist. Zunächst geht es um die bisher übliche Art der Aufteilung von Programmen, und erst am Ende des Kapitels werden in Abschnitt 2.11 die seit C++20 möglichen Module beschrieben. Der Grund für diese Reihenfolge ist, dass Module mit der bisher üblichen Art der Modularisierung gemeinsam vorkommen können. Auch müssen sie mit existierenden Bibliotheken zusammenarbeiten, und es muss ein allmählicher Übergang möglich sein. Folgender Aufbau empfiehlt sich:
Die Standard-Header haben die uns bekannte Form <headername>. Darüber hinaus kann es eigene (oder andere) Header-Dateien geben, die typischerweise die Endung *.h im Dateinamen haben (oder auch *.hpp, *.hxx, je nach Computer- oder Entwicklungssystem). Sie enthalten Konstanten, Schnittstellenbeschreibungen wie Klassendeklarationen, Deklarationen globaler Daten und Funktionsprototypen.
Implementationsdateien enthalten die Implementation der Klassen und den Programmcode der Funktionen (Endung im Dateinamen: *.cpp, auch *.cxx, *.cc).
Main-Datei. Sie enthält das Hauptprogramm main().
| 2.4.1 | Projekt: Mehrere cpp-Dateien bilden ein Programm |
In der Praxis besteht ein Programm aus vielen Header- und Implementationsdateien. Meistens ist es sinnvoll, Schnittstellen (Funktionsprototypen und Klassen) und Implementationen (Programmcode) zu trennen (Ausnahme: Templates). Um die automatische Prüfung der Schnittstellen durch den Compiler zu ermöglichen, werden die Header-Dateien mit #include in allen Dateien eingeschlossen, die diese Schnittstellen verwenden.
Mit den Header-Dateien kann jede Datei einzeln übersetzt werden. Wenn es Änderungen gibt, müssen nur noch die davon betroffenen Dateien neu compiliert werden.
Die Steuerung der Übersetzung und des Bindens ist je nach System unterschiedlich. Üblich sind Make-Dateien, auch Makefiles genannt, in denen die Reihenfolge und die Abhängigkeiten der Dateien beschrieben sind, sodass bei Änderungen nur die davon betroffenen neu übersetzt werden müssen. Make-Dateien werden in Kapitel 19 beschrieben. Eine andere Methode mit gleicher Wirkung sind sogenannte »Projekte«, in denen die zu übersetzenden und zu bindenden Dateien angegeben werden. Wenn eine ganze Reihe gut getesteter Programmbausteine zu einem Thema vorliegen, können die zugehörigen *.o-(oder *.obj)-Dateien in einer Bibliotheks- oder *.a- (oder *.lib)-Datei zusammengefasst werden. Die Konzepte
Trennung von Schnittstellen und Implementation und
Gruppierung zusammengehöriger Funktionen und Klassen zu Bibliotheksmodulen
sind Standard in Programmierprojekten.
Hinweis
cpp-Dateien sollen nicht mit #include eingeschlossen werden! Der Grund ist Ineffizienz: Wenn main.cpp viele cpp-Dateien einschließen würde, müsste der Compiler bei jeder Übersetzung von main.cpp alle diese Dateien lesen und übersetzen, selbst wenn sie bereits compiliert worden sind.
Im Folgenden wird ein minimales Projekt als Beispiel genommen: Es besteht aus nur zwei cpp-Dateien. Eine ist das Hauptprogramm (main.cpp), die andere enthält eine Funktion zur Mittelwertberechnung (mittelwert.cpp). Die Schnittstelle ist in der Datei mittelwert.h festgelegt (Listing 2.28).
Die Berechnung des Mittelwerts ist nur dann sinnvoll, wenn der Vektor mindestens ein Element enthält. Falls nicht, wird das Programm mit exit() abgebrochen. Später werden Sie andere Möglichkeiten der Fehlerbehandlung kennenlernen.
Damit kann das main-Programm in Listing 2.29 schon einzeln übersetzt werden. Dabei wird die Datei main.o erzeugt.
Listing 2.30: Programmcode der Funktion mittelwert() (cppbuch/k2/mittelwert/mittelwert.cpp)
#include "mittelwert.h" #include <iostream> double mittelwert(const std::vector<double>& vec) { if (vec.size() < 1) { std::cerr << "Vektor˽ist˽leer!˽Abbruch!\n"; std::exit(1); } double ergebnis = 0; for (auto summand : vec) { ergebnis += summand; } return ergebnis / static_cast<double>(vec.size()); }
Die Datei mittelwert.cpp wird auf die gleiche Art übersetzt. Abschließend müssen die Objektdateien zum ausführbaren Programm gebunden werden – eine Tätigkeit, die auch linken heißt:
Wenn Sie nur eine der cpp-Dateien ändern, müssen Sie nur noch diese neu übersetzen, bevor Sie neu linken. Wenn ein späteres Projekt von Ihnen viele cpp-Dateien umfasst, freuen Sie sich über die gesparte Wartezeit. Nur der Link-Schritt muss in jedem Fall nach dem Compilieren ausgeführt werden. Wenn Sie in der Konsole in das Verzeichnis cppbuch/k1/mittelwert gehen und dort make zweimal aufrufen, wird beim ersten Mal übersetzt und gelinkt und beim zweiten Mal gibt es eine Meldung, dass nichts mehr zu tun ist.
Hinweis
Wenn es um die Demonstration einfacher Beispiele geht, wird in diesem Buch oft auf die Trennung von Schnittstelle und Implementierung verzichtet. Andernfalls hätte man bei Funktionen und Klassen mindestens drei Dateien statt einer und damit einen beträchtlichen zusätzlichen Bedarf an zu bedruckender Papierfläche. Auch würde die Lesbarkeit erschwert, weil nicht mehr alles auf einen Blick erfasst werden kann.
| 2.4.2 | Projekt in der IDE anlegen |
Die Beschreibung bezieht sich auf Geany. Bei anderen IDEs ist das Vorgehen ähnlich. Rufen Sie Geany auf und klicken Sie in der Menüleiste bei Projekt »Neu« an. Vergeben Sie einen Namen und klicken auf »Erstellen«. Bestätigen Sie das Anlegen des Verzeichnisses. In dem erscheinenden Fenster schreiben Sie die Datei mittelwert.h und speichern sie unter diesem Namen. Verfahren Sie ebenso für mittelwert.cpp und main.cpp. Sie können natürlich den Inhalt der Dateien aus dem Verzeichnis cppbuch/k2/mittelwert/ übernehmen. Wenn Sie nun in der Menüleiste unter »Erstellen« auf »Build Projekt ohne make« klicken, wird das Programm erzeugt. Klicken unter »Erstellen« auf »Execute Projekt« führt das Programm aus.
Die Übersetzung mit make ist effizienter, weil nach einer Bearbeitung nur die geänderten cpp-Dateien übersetzt werden. Voraussetzung ist, dass eine Datei zur Steuerung der Übersetzung vorhanden ist. Sie können ein Projekt direkt in cppbuch/k2/mittelwert/ erzeugen, indem Sie dieses Verzeichnis als Basisverzeichnis angeben (vollständiger Pfad). Wenn Sie dann z.B. main.cpp öffnen, können Sie unter »Erstellen« »make« anklicken. Bei den kleinen Beispielen dieses Buchs ist es gleichgültig, ob Sie »Build Projekt ohne make« oder »make« wählen. Bei großen Projekten spielt es eine große Rolle, um die Übersetzungszeit zu minimieren.
| 2.4.3 | Übersetzungseinheit, Deklaration, Definition |
Der Text, den der Compiler in einem Durchgang verarbeiten muss, heißt Übersetzungseinheit. Große Programme werden in viele Übersetzungseinheiten gegliedert, um sie handhabbar zu machen. Insbesondere müssen bereits übersetzte und funktionstüchtige Teile nicht immer wieder neu übersetzt werden. Zum Verständnis wird klar zwischen den Begriffen Deklaration und Definition unterschieden:
Eine Deklaration führt einen Namen in ein Programm ein und gibt dem Namen eine Bedeutung.
Eine Deklaration ist auch eine Definition, wenn mehr als nur der Name eingeführt wird, zum Beispiel wenn Speicherplatz für Daten oder Code angelegt wird.
Die Beispiele verdeutlichen, was gemeint ist. Folgende Deklarationen sind gleichzeitig Definitionen:
Einzelheiten zu extern bei Konstanten finden Sie am Ende von Abschnitt 2.4.4. Die folgenden Zeilen sind Deklarationen, aber keine Definitionen:
One Definition Rule
Die unter dem englischen Namen one definition rule bekannte Regel ist bei der Strukturierung von Programmen zu beachten: Jede Variable, Funktion, Struktur,2 Konstante und so weiter in einem Programm hat genau eine Definition. Dabei spielt es keine Rolle, ob das Programm aus vielen oder wenigen Übersetzungseinheiten besteht, ob die Definition selbst geschrieben wurde oder von einer Programmbibliothek (englisch library) zur Verfügung gestellt wird. Aus der one definition rule ergibt sich, was in den verschiedenen Dateitypen enthalten sein soll (mit Beispielen):
Header-Dateien (*.h)
Funktionsprototypen (Schnittstellen)
reine Deklaration (nicht Definition) globaler Variablen
Deklaration globaler Konstanten (nicht Definition, das heißt ohne Initialisierung)
Definition von Konstanten, die nur in der Übersetzungseinheit sichtbar sind
Definition von Datentypen wie enum oder struct (weil die *.cpp-Dateien die Größe von Objekten dieser Datentypen kennen müssen)
Implementationsdateien (*.cpp)
Funktionsdefinitionen (Implementation)
Definition globaler Objekte (nur einmal im ganzen Programm)
Definition und Initialisierung globaler Konstanten (nur einmal im Programm)
Variablen, die ohne das Schlüsselwort extern in der Header-Datei auftreten, sind global. Wenn dieselbe Header-Datei von mehreren Implementationsdateien eingebunden wird, werden diese Variablen mehrfach angelegt – im Widerspruch zur »one definition rule«. Der Linker kann diese mehrfach angelegten Variablen gleichen Namens stillschweigend zusammenlegen oder er gibt eine Warnung oder Fehlermeldung aus, dass die Variable doppelt oder mehrfach definiert ist. Globale Variablen sollen also immer extern deklariert werden und die Definition soll nur in einer Übersetzungseinheit vorkommen.
Konstanten, die ohne das Schlüsselwort extern in der Header-Datei auftreten, sind nicht global und beziehen sich nur auf die Übersetzungseinheit. Wenn dieselbe Header-Datei von mehreren Implementationsdateien eingebunden wird, werden diese Konstanten entsprechend mehrfach angelegt. Falls der Compiler die Konstanten in besonderen Speicherplätzen ablegt (was durchaus nicht sein muss), bedeutet das Mehrfachanlegen zugleich Speicherplatzverschwendung.
| 2.4.4 | Dateiübergreifende Gültigkeit und Sichtbarkeit |
Die Speicherklasse einer Variablen wird unter anderem durch die Worte static und extern bestimmt. Mit static und extern werden Sichtbarkeit und Lebensdauer von Variablen eingestellt. Die erste Bedeutung (von mehreren) von static haben Sie in Abschnitt 2.1.4 gesehen. Alle nicht globalen und nicht-static-Variablen sind sogenannte automatische Variablen. Automatische Variablen werden bei Betreten eines Blocks mit undefiniertem Inhalt angelegt, sofern sie nicht explizit initialisiert werden. Sie haben dann also nicht den Wert 0. Bei Verlassen des Blocks werden sie wieder zerstört.
extern bei Variablen
Variablen, die außerhalb von main() und jeglicher anderer Funktion definiert sind, heißen global. Sie sind in allen Teilen eines Programms gültig, auch in anderen Dateien. Eine globale Variable muss nur in einer anderen Datei als extern deklariert werden, um dort benutzbar zu sein.
datei2.cpp ist für sich allein übersetzbar. Das Schlüsselwort extern sagt dem Compiler, dass eine Variable irgendwo anders definiert ist. Erst beim Binden, auch Linken genannt, wird die Referenz aufgelöst.
Tipp
Globale Variablen und Objekte sollen vermieden werden, weil sie für alle zugreifbar sind. Ursachen von mit ihnen verbundenen Fehlern sind daher schwer lokalisierbar.
extern bei Konstanten
Auf Dateiebene (außerhalb von main()) definierte Variablen sind global und in anderen Dateien benutzbar, wenn sie dort als extern deklariert sind. Bei Konstanten (const) ist es jedoch anders: Konstanten sind nur in der Definitionsdatei sichtbar! Sollen Konstanten anderen Dateien zugänglich gemacht werden, müssen sie als extern deklariert und initialisiert werden:
Ohne extern in datei1.cpp wäre der Geltungsbereich von konstante auf datei1.cpp beschränkt. Eine Alternative sind globale constexpr oder inline-Konstanten. Sie werden in einer Header-Datei definiert und sind in allen Übersetzungseinheiten, die diese Header-Datei einbinden, bekannt. Ein Beispiel:
Übung
2.10 Strukturieren Sie die Lösung der Taschenrechneraufgabe 2.7 von Seite 135 entsprechend den Empfehlungen dieses Abschnitts zur modularen Gestaltung.
| 2.5 | Namensräume |
Ein Namensraum (englisch namespace) ist ein mit Namen gekennzeichneter Sichtbarkeitsbereich (scope). Er erlaubt die Gruppierung zusammengehöriger Programmteile. Namespaces sind auch eingeführt worden, damit verschiedene Programmteile zusammenarbeiten können, die vorher (ohne Namespaces) aufgrund von Namenskonflikten im globalen Sichtbarkeitsbereich nicht zusammen verwendet werden konnten. Beispiele:
Es ist so nicht möglich, die Funktionsbibliotheken beider Firmen gleichzeitig zu benutzen. Die Lösung besteht in der Einführung von zusätzlichen, übergeordneten Sichtbarkeitsbereichen, den Namespaces. Ein Beispiel für eine Deklaration:
Klassen und Funktionen werden durch Using-Direktiven nutzbar gemacht:
Eine andere Möglichkeit ist der gezielte Zugriff auf Teile eines Namespace durch eine Using-Deklaration oder einen qualifizierten Namen, der die Funktion oder Klasse über den Bereichsoperator :: anspricht.
Alle Klassen und Funktionen der C++-Standardbibliothek sind im Namespace std. Aus diesem Grund wird in den cpp-Dateien dieses Buchs häufig using namespace std; benutzt. Alternativ ist der Zugriff über einen qualifizierten Namen möglich, zum Beispiel:
Bei langen Namen besteht die Möglichkeit der Abkürzung:
Namespaces können geschachtelt werden. Die in diesem Kapitel behandelten Funktionen heißen freie Funktionen. Ist eine Funktion außerhalb eines jeden Namespace deklariert, ist sie gleichzeitig global. Listing 2.42 zeigt die geschachtelten Namespaces A und B und die qualifizierte Ansprache der dort definierten Funktionen und einer globalen Funktion:
Listing 2.42: Geschachtelte Namespaces (cppbuch/k2/namespaces.cpp)
#include <iostream> void print() // freie und globale Funktion { std::cout << "globales˽print()\n"; } namespace A { void print() // freie Funktion in Namespace A { std::cout << "A::print()\n"; } namespace B { // innerhalb von A void print() // freie Funktion in Namespace B { std::cout << "A::B::print()\n"; } } // Ende von Namespace B } // Ende von Namespace A int main() { // Aufgerufen wird: print(); // globale Funktion ::print(); // globale Funktion A::print(); // A::print() A::B::print(); // A::B::print() using namespace A; // Namespace Voreinstellung B::print(); // A::B::print() ::print(); // globale Funktion // print(); // Fehler, weil nicht eindeutig: A::print() oder ::print()? }
Tipp
In einer Header-Datei sollen Namespaces nicht mit using eingeführt werden, weil sie damit in allen Dateien bekannt werden, die diese Header-Datei verwenden. Dann sind Namenskonflikte möglich. Besser ist die qualifizierte Ansprache. Beispiel: In einer Header-Datei soll cout weder mit using std::cout;, noch mit using namespace std; eingeführt, sondern qualifiziert als std::cout benannt werden. In cpp-Dateien kann in der Regel using namespace std; verwendet werden, aber auch die qualifizierte Nennung mit std::.
| 2.5.1 | Gültigkeitsbereich auf Datei beschränken |
Die Gültigkeit einer Variable oder Funktion wird mithilfe eines anonymen Namespace auf eine Datei beschränkt.
Anonyme Namespaces sind nur innerhalb der Übersetzungseinheit bekannt, also nicht von außen zugreifbar. Mit einer entsprechenden Änderung in datei1.cpp (siehe Seite 150) würden beide Dateien anstandslos übersetzt, aber es würde einen Linker-Fehler bei datei2.o geben, weil jetzt die Gültigkeit von global nur auf datei1.cpp beschränkt ist. Man sagt, dass die nur innerhalb einer Übersetzungseinheit gültigen Variablen und Funktionen intern gebunden werden (internes Linken (englisch internal linkage)), während globale Variablen und Funktionen extern gebunden werden (externes Linken (englisch external linkage)).
| 2.6 | inline-Funktionen und -Variablen |
Ein Funktionsaufruf kostet Zeit. Der Zustand des Aufrufers muss gesichert und Parameter müssen eventuell kopiert werden. Das Programm springt an eine andere Stelle und nach Ende der Funktion zur Anweisung nach dem Aufruf. Der relative Aufwand fällt umso stärker ins Gewicht, je weniger Zeit die Abarbeitung des Funktionskörpers selbst verbraucht. Der absolute Aufwand macht sich mit steigender Anzahl der Aufrufe bemerkbar, zum Beispiel in Schleifen. Um diesen Aufwand zu vermeiden, können Funktionen als inline deklariert werden. inline bewirkt, dass bei der Compilation der Aufruf durch den Funktionskörper ersetzt werden kann und gar kein Funktionsaufruf erfolgt. Die Parameter werden entsprechend ersetzt, auch die Syntaxprüfung bleibt erhalten. Betrachten wir die einfache Funktion quadrat(), die das Quadrat einer Zahl zurückgibt:
Der Aufruf z = quadrat(100); wird wegen des Schlüsselworts inline vom Compiler durch z = 100*100; ersetzt. Gute Compiler würden darüber hinaus den konstanten Ausdruck berechnen und z = 10000; einsetzen. Der Verwaltungsaufwand für den Aufruf einer Funktion entfällt, das Programm wird schneller. Es ist nicht sinnvoll, die Ersetzung von vornherein selbst vorzunehmen, weil bei einer Änderung der Funktion alle betroffenen Stellen geändert werden müssten anstatt nur die Funktion selbst. inline-Deklarationen empfehlen sich ausschließlich für Funktionen mit einem Funktionskörper kurzer Ausführungszeit im Vergleich zum Verwaltungsaufwand für den Aufruf. inline ist nur eine Empfehlung an den Compiler, die Ersetzung vorzunehmen.
Tipp
Eine kurze, nicht nur lokal verwendete Funktion kann als inline-Definition in eine Header-Datei geschrieben werden.
inline-Variablen
inline-Variablen sind eine einfachere Möglichkeit, globale Variablen zu definieren, als die in Abschnitt 2.4.4 beschriebene. Die Definition ist gleichzeitig eine Deklaration. Sie erscheint ausschließlich in einer Header-Datei. Das Schlüsselwort extern ist nicht notwendig. Eine beispielhafte Deklaration:
| 2.7 | constexpr-Funktionen |
Wie bekannt, dient das Schlüsselwort const dazu, Änderungen zu vermeiden:
Die Funktion fakultaet0() wird zur Laufzeit ausgeführt, die Konstante erg0 wird mit dem Ergebnis initialisiert. Die Variable arg ist keine Konstante. anzahl hingegen wird schon zur Compilationszeit festgelegt, weil der Compiler das Literal »1000« liest. Es bleibt dem Compiler überlassen, ob er für anzahl eine schreibgeschützte Speicherzelle anlegt. Er könnte alternativ jedes Vorkommen von anzahl in derselben Übersetzungseinheit direkt durch 1000 ersetzen.
Eine Analyse zur Compilationszeit kann Laufzeit sparen. Wenn bekannt wäre, dass arg stets 3 ist, könnte erg0 = 6 (= 1 · 2 · 3) gesetzt werden, ohne Berechnungen zur Laufzeit. Für die Fälle, in denen eine Analyse durch den Compiler vorgenommen werden kann, gibt es das Schlüsselwort constexpr (für constant expression):
Eine vollständige Datenflussanalyse durchzuführen, ist eine sehr komplexe Aufgabe. Aus diesem Grund werden an konstante Ausdrücke einige Anforderungen gestellt, um dem Compiler die Arbeit zu erleichtern:
Die Deklaration const sagt dem Compiler, dass die betreffende Größe nicht verändert werden soll.
Die Deklaration constexpr sagt, dass die betreffende Größe schon zur Compilationszeit bestimmt werden kann und der Compiler die Analyse vornehmen soll.
Da der Compiler das Programm auswertet, aber nicht ausführt, muss der konstante Ausdruck sich letztlich auf Literale zurückführen lassen. Eine constexpr-Variable ist damit immer auch const (nicht veränderbar). Das Umgekehrte gilt nicht: const-Werte sind nicht immer schon durch den Compiler bestimmbar, weil sie möglicherweise erst zur Laufzeit bestimmt werden. Zum Beispiel könnte eine const-Größe in einer Funktion ihren Wert von einer Variablen beziehen:
Eine constexpr-Funktion darf keine Anweisungen enthalten, die ein Ausführen des Programms erfordern, wie etwa Ein- oder Ausgabe. Mehr als ein return ist erlaubt. Auch if, switch und Schleifen sind möglich.
Eine constexpr-Funktion gibt keinen constexpr-Wert zurück, wenn sich das übergebene Argument nicht auf ein Literal zurückführen lässt.
Rekursion ist möglich.
Objekte, die einen Programmablauf voraussetzen (zum Beispiel Speicherplatzbeschaffung), können nicht schon zur Compilationszeit ausgewertet werden. Sie können const, aber nicht constexpr sein.
Die Fälle des folgenden Beispiels zeigen die verschiedenen Möglichkeiten. Entscheidend ist, ob das übergebene Argument ein konstanter Ausdruck ist und ob constexpr auf der linken Seite vor long long verwendet werden kann.
Listing 2.44: Nicht-constexpr-Funktion fakultaet0() und constexpr-Funktion fakultaet1() (cppbuch/k2/constexpr.cpp)
#include <iostream> [[nodiscard]] long long fakultaet0(int zahl) // nicht constexpr { long long fak{1uL}; while (zahl > 1) { fak *= zahl--; } return fak; } [[nodiscard]] constexpr long long fakultaet1(int zahl) // constexpr { long long fak{1uL}; while (zahl > 1) { fak *= zahl--; } return fak; // rekursiv: return zahl < 2 ? 1 : zahl * fakultaet1(zahl - 1); } [[nodiscard]] int getWert() // nicht-constexpr { return 3; } int main() { const long long erg0{fakultaet0(3)}; // const, aber nicht constexpr std::cout << "Ergebnis˽=˽" << erg0 << ’\n’; // 1) constexpr-Funktion liefert nicht-constexpr Wert int zahl{4u}; // kein const long long erg1{fakultaet1(zahl)}; std::cout << "Ergebnis˽=˽" << erg1 << ’\n’; // 2) constexpr-Funktion liefert nicht-constexpr Wert const int czahl1{getWert()}; // nicht mit constexpr initialisiert long long erg2{fakultaet1(czahl1)}; std::cout << "Ergebnis˽=˽" << erg2 << ’\n’; // 3) constexpr-Funktion liefert constexpr Wert const int czahl2{3}; // 3 ist Literal, also constexpr constexpr long long erg3{fakultaet1(czahl2)}; std::cout << "Ergebnis˽=˽" << erg3 << ’\n’; // 4) constexpr-Funktion liefert constexpr Wert constexpr long long erg4{fakultaet1(3)}; // 3 ist Literal, also constexpr std::cout << "Ergebnis˽=˽" << erg4 << ’\n’; }
Wenn das Argument auf ein Literal zurückgeführt werden kann, kann der Compiler den Wert für den Aufruf einsetzen und berechnen. Eine Ausführung zur Laufzeit unterbleibt, was der Geschwindigkeit des Programms zugute kommt.
Hinweis
constexpr-Funktionen sind gleichzeitig inline. Das bedeutet, dass Deklaration und Definition in derselben Übersetzungeinheit sein müssen. Damit der Compiler die Funktion nutzen kann, muss die Definition vor dem Aufruf von ihm gelesen worden sein. Die Definition einer constexpr-Funktion, die von mehreren Übersetzungseinheiten genutzt werden soll, gehört daher in eine Header-Datei. Das Schlüsselwort inline entfällt.
Auswertung zur Compilationszeit? Prüfung mit if consteval
Manchmal möchte man wissen, ob eine constexpr-Funktion schon zur Compilationszeit ausgewertet wird. Ein Grund dafür kann sein, dass bei der Auswertung zur Laufzeit ein anderer Algorithmus gewählt werden soll. Mit if consteval kann die Prüfung vorgenommen werden, wie Listing 2.45 zeigt.
Listing 2.45: Berechnung zur Compilationszeit erzwingen (cppbuch/k2/ifconsteval.cpp)
#include <iostream> constexpr int f(int x) noexcept { if consteval { return x + 42; } return x; } int main() { const auto wert1 { f(10) }; // Auswertung zur Compilationszeit int w {10}; // nicht konstant const auto wert2 { f(w) }; // Auswertung zur Laufzeit std::cout << wert1 << "˽" << wert2 << ’\n’; }
Die geschweiften Klammern nach if consteval sind zwingend. Das gilt auch für einen möglichen else-Zweig. Das negierende Gegenstück ist if not consteval.
| 2.7.1 | Berechnung zur Compilationszeit mit consteval |
Eine constexpr-Funktion gibt keinen constexpr-Wert zurück, wenn die Auswertung zur Compilationszeit nicht möglich ist, siehe Fälle 1) und 2) in Listing 2.44. Wenn auf jeden Fall das Ergebnis zur Compilationszeit berechnet werden soll, muss das Schlüsselwort consteval statt constexpr verwendet werden. Eine consteval-Funktion wird »unmittelbare Funktion« (englisch immediate function) genannt. Das Ergebnis wird während der Compilation berechnet und sofort eingesetzt. Nach der Auswertung wird sie nicht mehr benötigt, muss also im Compilationsergebnis nicht mehr vorliegen. Sie können die Wirkung sehen, wenn Sie in Listing 2.46 das Wort const bei der Deklaration von n streichen. Die Übersetzung würde dann eine Fehlermeldung ergeben.
Listing 2.46: Berechnung zur Compilationszeit erzwingen (cppbuch/k2/consteval.cpp)
#include <iostream> [[nodiscard]] consteval long long fakultaet(int zahl) { long long fak {1}; for (int i = 2; i <= zahl; ++i) { fak *= i; } return fak; } int main() { const int n {10}; auto erg = fakultaet(n); std::cout << n <<"!˽=˽" << erg << ’\n’; }
| 2.8 | Rückgabetyp auto |
Bei constexpr- und anderen inline-Funktionen liest der Compiler den gesamten Funktionskörper vor der ersten Verwendung, einschließlich der return-Anweisung. Das ermöglicht dem Compiler, den Rückgabetyp zu ermitteln, sowohl in der Funktionsdefinition, als auch beim Aufruf der Funktion. In solchen Fällen muss man nicht den Datentyp erst nachsehen, sondern kann das bekannte Schlüsselwort auto verwenden. Im Listing 2.44 auf Seite 157 kann auto den Datentyp an vielen Stellen ersetzen. Das Ergebnis sehen Sie im Listing 2.47.
Listing 2.47: Datentyp mit auto vom Compiler ermitteln lassen (cppbuch/k2/constexprauto.cpp)
#include <iostream> [[nodiscard]] auto fakultaet0(int zahl) // nicht constexpr { long long fak{1uL}; while (zahl > 1) { fak *= zahl--; } return fak; } [[nodiscard]] constexpr long long fakultaet1(int zahl) // constexpr { return zahl < 2 ? 1 : zahl * fakultaet1(zahl - 1); } [[nodiscard]] auto getWert() // nicht-constexpr { return 3; } int main() { const auto erg0{fakultaet0(3)}; // const, aber nicht constexpr std::cout << "Ergebnis˽=˽" << erg0 << ’\n’; // constexpr-Funktion liefert nicht-constexpr Wert int zahl {4u}; // kein const auto erg1 {fakultaet1(zahl)}; std::cout << "Ergebnis˽=˽" << erg1 << ’\n’; // constexpr-Funktion liefert nicht-constexpr Wert const auto czahl1 {getWert()}; // nicht mit constexpr initialisiert auto erg2{fakultaet1(czahl1)}; std::cout << "Ergebnis˽=˽" << erg2 << ’\n’; // constexpr-Funktion liefert constexpr Wert const int czahl2 {3}; // 3 ist Literal constexpr auto erg3 {fakultaet1(czahl2)}; std::cout << "Ergebnis˽=˽" << erg3 << ’\n’; // constexpr-Funktion liefert constexpr Wert constexpr auto erg4 {fakultaet1(3)}; // 3 ist Literal std::cout << "Ergebnis˽=˽" << erg4 << ’\n’; }
Es ist nicht immer möglich, den Rückgabetyp durch auto zu ersetzen. Wenn Sie sich fragen, warum der Datentyp long long der rekursiven Funktion fakultaet1() nicht durch auto ersetzt werden kann:
Um den Typ des Funktionsergebnisses zu bestimmen, muss der Typ des Funktionsaufrufs fakultaet1(zahl - 1) in der return-Anweisung bekannt sein – aber der soll ja gerade erst bestimmt werden! Hier beißt sich die Katze in den Schwanz.
| 2.9 | Funktions-Templates |
Oft ist dieselbe Aufgabe für verschiedene Datentypen zu erledigen, zum Beispiel Sortieren eines int-Arrays, eines double-Arrays und eines String-Arrays. Man könnte den Quellcode natürlich kopieren. Das Problem ist aber, dass Änderungen in allen Versionen nachgezogen werden müssen. Dabei schleichen sich leicht Fehler ein. Mit Templates (deutsch Schablonen) kann man das vermeiden. Sie erlauben, Funktionen mit parametrisierten Datentypen zu schreiben. Mit »parametrisierten Datentypen« ist gemeint, dass eine Funktion für einen beliebigen, noch festzulegenden Datentyp geschrieben wird. Für den noch unbestimmten Datentyp wird ein Platzhalter (Parameter) eingefügt, der später durch den tatsächlich benötigten Datentyp ersetzt wird. Die allgemeine Form für Funktions-Templates zeigt Abbildung 2.8.

Anstatt class kann auch typename geschrieben werden. In diesem Buch wird in der Regel class verwendet, wenn das Template eher für Klassen-Objekte verwendet werden soll. Wenn sowohl Klassen wie auch Grunddatentypen wie int und double gemeint sind, wird meistens typename gewählt. Typbezeichner ist ein beliebiger Name, der in der Funktionsdefinition als Datentyp verwendet wird.
In Listing 2.48 wird aus einem int-, einem double- und einem string-Vektor der jeweils größte Wert ermittelt, obwohl nur eine einzige Funktion groessterWert() geschrieben wird, die hier den Datentypplatzhalter T benutzt. In der C++-Standardbibliothek gibt es eine Funktion max_element() mit anderer Parameterliste, aber für denselben Zweck. Die Funktion wird hier bewusst ignoriert, um den Template-Mechanismus an einem konkreten Beispiel zu zeigen. Damit ist groessterWert() leicht anwendbar für Vektoren von Objekten einer beliebigen Klasse. Die Begriffe Objekt und Klasse sind Ihnen schon im ersten Kapitel begegnet, mehr erfahren Sie im nächsten Kapitel.
Listing 2.48: Funktions-Templates (cppbuch/k2/groessterWert.cpp)
#include <cassert> #include <iostream> #include <string> #include <vector> // Die folgende Funktion würde auch mit einer Parameterliste (T a, T b) arbeiten, d.h. einer // Kopie per Wert. Da T aber für einen beliebigen Datentyp steht, wird eine Referenz bevorzugt, // um Kopien von möglicherweise sehr großen Objekten zu vermeiden. template <typename T> [[nodiscard]] bool kleiner(const T &a, const T &b) // Vergleich { return a < b; // zu < siehe auch Text am Abschnittsende } template <typename T> void drucke(const std::vector<T>& V) { for (const T &wert : V) { std::cout << wert << "˽"; } std::cout << ’\n’; } template <typename T> [[nodiscard]] T groessterWert(const std::vector<T> &vek) { assert(vek.size() > 0); // vek darf nicht leer sein! T max{vek[0]}; for (const auto &element : vek) { if (kleiner(max, element)) { max = element; } } return max; } int main() { std::vector iV {-100, 22, -3, 44, 6, -9, -2, 1, 8, 9}; // In den folgenden beiden Anweisungen werden vom Compiler, gesteuert durch den // Datentyp vector<int> des Parameters iV, aus den obigen // Templates die Funktionen groessterWert(const vector<int>&) und // drucke(const vector<int>&) erzeugt, ebenso wie die implizit // aufgerufene Funktion kleiner(const int&, const int&). std::cout << "Der˽größte˽Wert˽von˽"; drucke(iV); std::cout << "ist˽" << groessterWert(iV) << ’\n’; std::vector dV {1.09, 2.2, 79.6, -1.9, 2.7, 100.9, 18.8, 99.9}; // Generierung der überladenen Funktionen groessterWert(const vector<double>&) // und drucke(const vector<double>&) (und der // aufgerufenen Funktion kleiner(const double&, const double&)): std::cout << "Der˽größte˽Wert˽von˽"; drucke(dV); std::cout << "ist˽" << groessterWert(dV) << ’\n’; // Das funktioniert auch für Strings: std::vector<std::string> sV {"alpha",˽"beta",˽"zebra",˽"eins",˽"elf"}; std::cout << "Der˽größte˽Wert˽von˽"; drucke(sV); std::cout << "ist˽" << groessterWert(sV) << ’\n’; } // Ende von main()
Hinweis
In Listing 2.48 ist vector iV {-100, 22, -3, 44, 6, -9, -2, 1, 8, 9}; identisch mit einem vector<int> gleichen Inhalts, weil der Compiler den Typ des Vektors aus dem Typ der Elemente herleitet. Für den Vektor dV gilt Entsprechendes. Beim Vektor sV kann <std::string> nicht weggelassen werden, weil der Typ der Elemente const char* ist. Alternativ kann man die Elemente mit dem Suffix s kennzeichnen, damit sie als String interpretiert werden. Dann kann <std::string> entfallen. Voraussetzung ist die Einbindung des Namespace std, also
Innerhalb von main() stellt der Compiler anhand des Funktionsaufrufs fest, für welchen Datentyp die Funktion benötigt wird, und bildet die Definition mithilfe des Templates. Für jeden verwendeten Datentyp wird eine Funktion erzeugt – ebenso wie Sie mit einer Form einen Schokoladen- und einen Nusskuchen backen können.
Mit groessterWert() liegt eine Funktion vor, die für Vektoren verschiedener Elementtypen geeignet ist. Auffällig ist, dass der Vergleich, welches Element kleiner ist, als Funktionsaufruf kleiner() innerhalb groessterWert() formuliert wurde, anstatt if (max < element) zu schreiben. Warum? Es ist nicht selbstverständlich, dass der Operator < für beliebige Klassen und Datentypen definiert ist. Durch Auslagern des Vergleichs braucht die Funktion groessterWert() nicht verändert zu werden, wenn der Operator < anders definiert werden muss.
| 2.9.1 | Spezialisierung von Templates |
Nehmen wir an, dass double-Zahlen wie bisher, int-Zahlen jedoch nach dem Absolutbetrag sortiert werden sollen. Der Vergleichsoperator < kann dann nicht mehr direkt auf die Zahlen angewendet werden. Zur Realisierung können wir aber ausnutzen, dass ein Template spezialisiert werden kann. Um den größten Absolutbetrag nur für int-Zahlen zu finden, muss das Template für die Funktion kleiner() spezialisiert werden. Spezialfälle von überladenen Funktionen werden nach den nicht-spezialisierten Templates eingefügt, so auch das spezialisierte Template kleiner<int>():
Listing 2.49: Spezialisiertes Template (Auszug aus cppbuch/k2/groessterWert1.cpp)
#include <cstdlib> // für abs() // ... template<> [[nodiscard]] bool kleiner<int>(const int& a, const int& b) { // Das <int> in kleiner<int> darf weggelassen werden (Typdeduktion). return abs(a) < abs(b); // Vergleich nach dem Absolutbetrag! }
Typdeduktion bedeutet, dass der Compiler den Typ aus den Parametern ermittelt. An die Stelle eines spezialisierten Templates kann auch eine gewöhnliche Funktion treten, die vom Compiler bevorzugt gewählt wird, wenn die Parametertypen passen, etwa:
Der Unterschied: In der Parameterliste einer gewöhnlichen Funktion sind weitgehende Typumwandlungen möglich, in einem spezialisierten Template jedoch nicht:
Weil schärfere Typprüfungen normalerweise erwünscht sind, sollen spezialisierte Templates anstelle von gewöhnlichen Funktionen eingesetzt werden.
| 2.9.2 | Einbinden von Templates |
In Abschnitt 2.4.1 auf Seite 147 wurde gezeigt, wie Funktionsimplementationen vorübersetzt und dann eingebunden werden können. Das gilt nicht für Funktions-Templates! Eine *.o- oder *.obj-Datei, die vom Compiler durch Übersetzen einer Datei nur mit einem Template erzeugt wird, ohne in der Datei einen konkreten Datentyp davon zu erzeugen, enthält keinen Programmcode und keine Daten. Ein Template ist keine Funktionsdefinition im bisherigen Sinne, sondern eben eine Schablone, nach der der Compiler erst bei Bedarf eine Funktion zu einem konkreten Datentyp erzeugt. Dateien mit Templates sind deswegen mit #include einzulesen. Demzufolge könnten die Template-Definitionen ebensogut in der Header-Datei stehen. Am Beispiel der Funktion drucke() seien hier drei verschiedene Möglichkeiten zur Integration gezeigt.
Trennung von Deklaration und Implementation. Die Datei drucke.h wird per #include eingelesen:
Listing 2.50: drucke.h: Trennung von Deklaration und Implementation
#ifndef DRUCKE_H #define DRUCKE_H #include <iostream> #include <vector> // Deklaration template <typename T> void drucke(const std::vector<T> &V); // Implementation (Definition) template <typename T> void drucke(const std::vector<T> &V) { for (const T &wert : V) { std::cout << wert << "˽"; } std::cout << ’\n’; } #endif
Aufspaltung von Deklaration und Implementation in zwei Dateien. Die Datei drucke.h wird per #include eingelesen. Anstelle der Implementation (siehe Listing 2.50) gibt es nur die Anweisung #include "drucke.h". Die inkludierte Datei drucke.h enthält dann nur die Implementation. Diese Art der Aufspaltung finden Sie mehrfach bei den Systemdateien des g++-Compilers, wobei die Implementation in einer Datei mit der Endung .tcc steckt. Sinn der Maßnahme ist, die .h-Dateien nicht so groß werden zu lassen, damit sie übersichtlich bleiben.
Die Datei drucke.h wird per #include eingelesen:
Diese Lösung wird in diesem Buch verwendet, weil sie die einfachste ist (weniger Dateien und keine Aufspaltung).
In allen drei Fällen handelt sich nur um organisatorische Maßnahmen zur Einbindung von Templates. Falls C++-Kenner hier etwas vermissen: Ein weiteres Template-Compilationsmodell wird in Abschnitt 5.6 diskutiert.
Übungen
2.11 Schreiben Sie eine Template-Funktion getType(T t) mit Template-Spezialisierungen, die den Typ des Parameters t als String zurückgibt. Eine mögliche Anwendung könnte so aussehen (Ausgabe des Programms siehe Kommentare //):
2.12 Schreiben Sie eine Template-Funktion betrag(T t), die wie abs() den Betrag von t zurückgibt. Für manche Grunddatentypen wie char oder bool ist der Begriff »Betrag« nicht sinnvoll. Wie können Sie durch eine spezialisierte Template-Funktion erreichen, dass eine fälschliche Verwendung von betrag() zur Ausgabe einer Fehlermeldung führt? Gehen Sie der Einfachheit halber davon aus, dass die Negation einer negativen Zahl den Betrag ergibt, obwohl diese Annahme nicht immer gültig ist (der Betrag einer komplexen Zahl ist anders definiert).
2.13 Die Funktion fastbubblesort() zum Sortieren eines int-Vektors ist schneller als der »normale« Bubble-Sort:
Warum soll diese Funktion schneller sein? Sie vergleicht wie üblich ein Vektor-Element mit dem vorhergehenden und vertauscht die Elemente, sofern das Element kleiner als der Vorgänger ist. Dieser Vorgang wird so lange wiederholt, bis das Element temp unverändert bleibt, also nichts mehr zu sortieren ist. Weil gegebenenfalls schnell erkannt wird, dass nichts mehr zu sortieren ist, ist dieser Bubble-Sort bei teilweise vorsortierten Feldern im Mittel etwas schneller als eine Variante mit zwei geschachtelten Schleifen fixer Durchlaufanzahl. Leider, leider, enthält die Funktion zwei schwere Fehler! Welche?
(Leider habe ich die Vorlage zu dieser Aufgabe, die ich nur abgewandelt habe, nicht mehr gefunden. Der Autor des Originals möge mir verzeihen.)
2.14 Nur für Mathematik-Interessierte: Schreiben Sie eine Funktion
double polynom(const vector<double>& k, double x), die den Wert des Polynoms
f (x) = knxn + kn–1xn–1 + · · · k1x + k0
zurückgibt. Vermeiden Sie unnötige Mehrfachberechnungen der Potenzen von x. Der Vektor k enthält die n + 1 Koeffizienten, das heißt, k[0]=k0, k[1]=k1 usw.
2.15 Eine Funktion soll prüfen, ob eine unsigned int-Zahl gültig ist. Dabei soll die Funkion numeric_limits<unsigned int>::max() verwendet werden, die die größtmögliche unsigned int-Zahl zurück gibt. Was ist an der folgenden Funktion falsch?
| 2.10 | C++-Header |
In C/C++ gibt es Bibliotheken mit verschiedenen Klassen und Funktionen. Die Funktionsbibliotheken entstammen teilweise der Sprache C. Beim Linken werden die benötigten Funktionen aus den Bibliotheksdateien dazugebunden. Die Header-Dateien sind im include-Verzeichnis zu finden. Auf die zu C++ gehörende Bibliothek wird in Kapitel 25 ab Seite 827 eingegangen. Ab Seite 951 werden die aus der Programmiersprache C kommenden Funktionen beschrieben.
Programme erhalten Zugriff zu Standardfunktionen und Klassen über das Einschließen der passenden Header mit #include. Diesen Headern können (müssen aber nicht) Dateien mit demselben oder ähnlichen Namen entsprechen. Die Namen der Header sind vom C++-Standard vorgeschrieben, die Implementierung durch die Compilerhersteller nicht. Alle Funktionsprototypen der C-Include-Dateien, deren Dateiname auf ».h« endet, gehören zum globalen Namensraum. Dieselben Funktionen werden unter C++ im Namensraum std zur Verfügung gestellt, aber unter neuen Namen, die sich durch ein vorangestelltes »c« und das Fehlen der Datei-Extension ».h« unterscheiden. Die Möglichkeit, Funktionen mit der Datei-Extension ».h« einzubinden, bleibt unberührt. Das folgende Beispiel zeigt die Einbindung der C-Funktionen zur Zeichenkettenverarbeitung mit dem Header <string.h> und mit dem Header <cstring>:
Besser ist es, den C++-Header einzubinden:
Ohne using namespace std; hätte in Beispiel 2 std::cout und std::strlen(text) geschrieben werden müssen. Außer den C-Funktionen gibt es natürlich die Standard-Header für die Klassen der C++-Standardbibliothek:
Um Namenskonflikte zu vermeiden, ist es grundsätzlich empfehlenswert, für ein Projekt oder Teilprojekt Namespaces zu definieren und zu benutzen. Besonders wichtig ist dies beim Schreiben von Bibliotheken.
Tipps
Vermeiden Sie using namespace std; in Header-Dateien, damit Benutzer dieser Dateien nicht gezwungenermaßen den Namensraum std per #include »erben«! In *.cpp-Dateien ist die Verwendung hingegen unproblematisch, da diese nicht mit #include eingebunden werden.
Nutzen Sie möglichst C++ anstelle der C-Funktionen, also zum Beispiel die string-Klasse. Wenn Sie C-Funktionen nicht vermeiden können, benutzen Sie stets die C++-Form für C-Header, also <cstring> statt <string.h> und <cstdlib> statt <stdlib.h> usw. Der Grund: In den mit c beginnenden Headern gibt es gelegentlich einige für C++ notwendige Anpassungen. Die Funktionen befinden sich im Namespace std.
Einbinden von C-Funktionen3
Für jeden Standard-C-Header <xxxx.h> gibt es eine C++-Entsprechung <cxxxx> (xxxx ist ein Platzhalter z.B. für string, siehe oben). Dieser Abschnitt ist für Sie nur von Bedeutung, wenn Sie reine C-Funktionen verwenden wollen (die vielleicht von anderen geschrieben wurden). Das Einbinden von C-Funktionen wird mit #include bewerkstelligt. C-Prototypen werden in der Header-Datei mit
eingebunden. Der Grund dafür liegt in der unterschiedlichen Behandlung von Funktionsnamen durch den C++-Compiler im Vergleich zu einem C-Compiler. Die korrekte Einbindung in C++-Header-Dateien wird in den C++-Header-Dateien über die Abfrage des Makros __cplusplus gesteuert. Damit werden extern "C"{ samt schließender Klammer } in eine Übersetzungseinheit integriert, wie unten zu sehen. Das Makro __cplusplus wird bei einer C++-Compilation automatisch gesetzt. Anstelle der Prototypen kann eine weitere #include-Anweisung stehen.
| 2.11 | Module |
Bisher besteht ein größeres Programm aus Header-Dateien, die Schnittstellen enthalten und deren Namen auf .h enden, und Implementationsdateien mit dem zugehörigen Programmcode und der Endung .cpp. Module sind Softwarekomponenten, die Schnittstelle und Implementation zusammenfassen. Sie werden unabhängig compiliert und sind danach benutzbar.
Hinweis
Module sind mit C++20 eingeführt worden. Sie können in eigenen Programmen genutzt werden, sofern der Compiler sie unterstützt. Solange das nicht der Fall ist und auch die C++-Standardbibliothek noch nicht auf Module umgestellt wurde, wird eine praktisch relevante Programmierung mit Modulen nicht möglich sein.
Ein Modul ist eine eigene Übersetzungseinheit. Das jetzt noch gültige Modell der Aufteilung in Header- und Implementationsdateien hat einige Nachteile:
Die Aufteilung führt zu doppelt so vielen Dateien im Vergleich zur Konzentration von Schnittstelle und Implementation in einem Modul.
Die Aufteilung kann zu Inkonsistenzen führen, wenn nämlich die Deklaration in der Header-Datei nicht mit derjenigen in der Implementationsdatei übereinstimmt. Bei Modulen kann dieses Problem nicht auftreten.
Header-interne Definitionen mit #define sind in allen nachfolgenden Übersetzungseinheiten sichtbar. Das kann Konflikte auslösen. Module vermeiden dieses Problem.
Das Inkludieren von Header-Dateien wird mit Makros gesteuert. Makros überwachen, dass der Inhalt einer Header-Datei nicht zweimal berücksichtigt wird. Aber auch wenn der Compiler den Inhalt ignoriert, muss er doch die zweite Datei bis zum Ende lesen. Unnötige längere Compilationszeiten sind die Folge.
Header-Dateien müssen bei jeder Übersetzung vom Compiler analysiert werden. Bei Modulen liegt das binäre Ergebnis nach deren einmaliger Übersetzung vor. Das spart Compilationszeit.
Es kann eine Rolle spielen, in welcher Reihenfolge Header-Dateien mit #include eingebunden werden. Module können in beliebiger Reihenfolge importiert werden.
In einer Header-Datei kann es mit private gekennzeichnete Bereiche geben, wie Sie in Kapitel 3 sehen werden. Die sind für die Benutzung einer Schnittstelle jedoch nicht von Bedeutung. In Modulen wären solche Bereiche nach außen nicht sichtbar.
Ein einfaches Beispiel
Das Listing 2.56 zeigt die Einbindung eines Moduls hello mit der import-Anweisung. Das Modul stellt die Funktion gruss() zur Verfügung. Ihr Aufruf in main() gibt »Hallo Welt!« auf der Standardausgabe cout aus. Dabei muss in main() keine #include-Anweisung stehen. Das Modul bringt alles Notwendige mit.
Das Modul selbst ist in diesem Fall ziemlich einfach, wie das Listing 2.57 zeigt. Das Schlüsselwort export entspricht einer Schnittstellendeklaration: Alles, was mit export deklariert wird, kann von demjenigen Programm, das dieses Modul importiert, genutzt werden, hier also die Funktion gruss().
module grussmodul; // Modul #include <iostream> // später import std.iostream? #include <string> // später import std.string? export module grussmodul; // importierbar als grussmodul // interne, nicht exportierte Funktion (weil ohne export-Qualifizierer) std::string getAnrede() { return "Hallo˽"; } export void gruss (const std::string& name) // exportierte Funktion { std::cout << getAnrede() << name <<’\n’; // Benutzung der internen Funktion }
Der Name des Moduls entspricht nicht grundsätzlich dem Dateinamen, wie das Beispiel zeigt, obwohl das oft sinnvoll sein wird. Module sind unabhängig von Namespaces.
Fazit
Die Unterstüzung von Modulen wird aktiv von den Compiler-Herstellern entwickelt. Es gibt dabei sehr viel zu tun. So müssen zum Beispiel die binären Formate für vorcompilierte Module festgelegt werden. Die aktuellen Header-Dateien, die zum System gehören, sind gespickt mit Makros. Das kann bei der Umstellung zu widersprüchlichen Definitionen führen. Es muss geklärt werden, wie die gleichzeitige Verwendung von Modulen, #include und dem Einbinden von Bibliotheken funktionieren kann. Und das sind nicht die einzigen Probleme. Die Werkzeugunterstützung ist zum derzeitigen Zeitpunkt (2023) kaum ausreichend, sodass das Thema nicht zufriedenstellend in einem Lehrbuch, das Wert auf die praktische Umsetzbarkeit legt, behandelt werden kann.
1 Vertiefendes Rekursions-Beispiel für Informatik-Interessierte – kann von anderen übersprungen werden.
2 Eine Struktur darf ausnahmsweise mehrfach definiert werden, sofern die Definitionen nicht in derselben Übersetzungseinheit vorkommen und darüber hinaus gleich sind.
3 Dieser Abschnitt kann beim ersten Lesen übersprungen werden.