Dieses Kapitel behandelt die folgenden Themen:
 Was sind Zeiger und wie benutze ich sie?
Was sind Zeiger und wie benutze ich sie?
C-Arrays und C-Strings
Dynamisches Erzeugen von Objekten
Parameterübergabe mit Zeigern
Mehrdimensionale C-Arrays
Binärdaten in Dateien schreiben und lesen
Zeiger auf Funktionen
Lesen komplexer Deklarationen
Alternative zu »rohen« Zeigern, new und delete
Zeiger entsprechen Adressen im Speicher. Nach ihrer Einführung werden C-Arrays beschrieben und ihre Anwendung gezeigt. Verwandt mit Zeigern und C-Arrays sind C-Strings, eine andere Form von Zeichenketten. Mithilfe von Zeigern werden dynamisch, das heißt zur Laufzeit, erzeugte Objekte verwaltet. Zeiger werden auch im Zusammenhang mit Funktionen behandelt.

Hinweis
Sie müssen Zeiger kennen, weil sie in vielen bestehenden Programmen vorkommen und Sie vielleicht einige dieser Programme verstehen müssen. Manche Klassen sind in C++ ohne Zeiger nicht realisierbar, auch werden Zeiger in vielen Anwendungsschnittstellen (englisch application programming interface), abgekürzt API, verlangt. Zeiger erlauben große Freiheiten, haben aber auch ihre Tücken. In eigenen Programmen werden Sie Zeiger kaum brauchen, weil es fast immer bessere Möglichkeiten gibt.

| 4.1 | Zeiger und Adressen |
Zeiger sind ähnlich wie andere Variablen: Sie haben einen Namen, einen Wert und können mit Operatoren verändert werden. Der Unterschied besteht darin, dass der Wert als Adresse behandelt wird. Ein Beispiel dafür sind Seitenangaben in einem Inhaltsverzeichnis, die »Adressen« für verschiedene Kapitel darstellen.
Die Namen können konventionell ein p oder ptr (für »pointer«) enthalten. Zeiger wurden in C++ verwendet, weil sie eine große Flexibilität gestatten. Sie müssen sie also kennen. Allerdings kommen Sie mit den heutigen modernen Sprachmitteln von C++ meistens ohne Zeiger aus und vermeiden damit deren Nachteile. Mithilfe von Zeigern kann dynamisch, das heißt zur Laufzeit eines Programms, Speicher beschafft werden. Anwendungen werden Sie noch kennenlernen. In Deklarationen bedeutet ein * »Zeiger auf«:
ip ist ein Zeiger auf einen int-Wert oder anders ausgedrückt: An der Stelle im Speicher, deren Adresse in ip gespeichert ist, befindet sich ein int-Wert. In anderen Anweisungen bedeutet * eine Dereferenzierung, das heißt, dass der Wert an der Stelle betrachtet wird, auf die der Zeiger verweist. *ip = 100; setzt den Wert an der Stelle, auf die ip zeigt, auf 100. Insofern kann man die obige Deklaration lesen als: (*ip) ist vom Datentyp int.
Zeiger erhalten bei der Deklaration zunächst eine beliebige Adresse, genau wie andere nicht-initialisierte Variablen zunächst beliebige Werte annehmen (Ausnahme: static-Variablen, siehe Seite 120). Daher muss vor Benutzung des Zeigers in einem Ausdruck erst eine sinnvolle Adresse zugewiesen werden, um nicht den Inhalt anderer Speicherstellen zu zerstören! Zur Verdeutlichung definieren und initialisieren wir zunächst eine Variable i mit der Anweisung int i = 99;. Wir legen damit einen Speicherplatz mit dem symbolischen Namen i an und tragen die Zahl 99 ein. Die uns unbekannte, vom Compiler für i festgelegte Speicherplatzadresse sei 10125 (Abbildung 4.1).

Nun wird mit int *ip; ein Zeiger ip definiert, aber nicht initialisiert. Die Speicherplatzadresse des Zeigers selbst sei 27890 und er zeigt auf eine unbekannte Adresse. Der Inhalt an der Speicheradresse, auf die ip verweist, ist undefiniert, also nicht automatisch 0. Jetzt wird ip die Adresse von i zugewiesen. Dabei kommt der Operator & zur Anwendung, der hier als Adressoperator wirkt. In einem anderen Kontext hatten wir das Zeichen & bereits als Operator für die bitweise UND-Operation kennengelernt. Weisen wir nun ip die Adresse von i zu:
Jetzt zeigt ip auf i. Das heißt nichts anderes, als dass die Adresse von i, hier 10125, bei ip eingetragen wird (Abbildung 4.1). Als Nächstes definieren wir einen Zeiger ip2, der ebenfalls auf i gerichtet wird. Durch die Initialisierung gleichzeitig mit der Definition durchläuft ip2 keinen undefinierten Zustand:

Der Wert von i ist jetzt über mehrere Namen beziehungsweise Zeiger zugreifbar (Abbildung 4.2). Die Anweisungen
bewirken alle dasselbe. *ip und *ip2 sind Alias (andere Namen) für i.
Hinweis zur Schreibweise von Zeigerdeklarationen
Die folgenden drei Schreibweisen sind äquivalent:
Besser: Nur eine Variable pro Deklaration – dann ist eine Verwechslung nicht möglich.
Die Variable x ist vom Typ int, die Variable ip ist vom Typ »Zeiger auf int«. Der Stern * bezieht sich also nur auf den direkt folgenden Namen. Um die Zuordnung beim Lesen leichter treffen zu können, sollte deshalb nur die vierte Schreibweise benutzt werden.
Null-Zeiger / nullptr
Um sich zu merken, dass ein Zeiger noch nicht oder nicht mehr auf ein definiertes Objekt zeigt, kann ein Null-Zeiger verwendet werden. C++ sieht dafür das Schlüsselwort nullptr vor. ptr sei irgendein Zeiger. Dann bedeutet die Anweisung ptr = nullptr;, dass der Zeiger ptr nicht »irgendwo« hin, sondern definitiv auf »nichts« zeigt.
In C++ gibt es aus historischen Gründen auch NULL als speziellen Wert, um einen Null-Zeiger zu realisieren. NULL ist ein im Header <cstddef> definiertes Makro. Sowohl nullptr als auch NULL sind als logischer Wert abfragbar. Wie NULL intern realisiert wird, ist implementationsabhängig. Typischerweise wird NULL in C++ als Zahlenwert 0 oder 0L (long) dargestellt.
Tipp
Verwenden Sie nach Möglichkeit nullptr als Null-Zeiger und nicht NULL oder die Zahl 0. nullptr erhöht die Typsicherheit und Lesbarkeit an den Stellen, wo eine 0 übergeben wird, aber nicht unbedingt klar ist, ob ein Null-Zeiger oder eine Zahl 0 gemeint ist, zum Beispiel in der Parameterliste eines Funktionsaufrufs.
Typprüfung
Im Gegensatz zu C wird der Typ eines Zeigers in C++ geprüft. Gegeben seien die Definitionen:
void hat die Bedeutung »undefinierter Datentyp«. vp ist also ein Zeiger auf ein Objekt, über dessen Typ nichts gesagt wird. Eine Deklaration für ein void-Objekt kann es nicht geben, weil der benötigte Speicherplatz nicht angebbar ist, sehr wohl aber die Deklaration eines Zeigers, der auf ein Objekt unbekannten Typs gerichtet werden soll. Aus dem Typ des Zeigers geht der Typ des Objekts nicht hervor. Ein Zeiger auf void hat den Typ void*. Ein void*-Zeiger kann zum Beispiel auf ein char-Objekt gerichtet werden. Das Umgekehrte geht nicht.
Die Zuweisung kann jedoch durch eine Typumwandlung ermöglicht werden:
Nutzen Sie solche Typumwandlungen nur, wenn Sie einen wichtigen Grund haben, weil die Typkontrolle des Compilers umgangen wird.
Kein Zeigerzugriff auf blocklokale Variablen!
Der Speicherplatz für die innerhalb eines Blocks deklarierten Variablen wird bei Verlassen des Blocks wieder freigegeben. Der nachträgliche Zugriff auf diese Speicherplätze kann zu Dateninkonsistenzen und zum Systemabsturz führen:
Listing 4.1: Problem: Zeiger auf Variable eines anderen Gültigkeitsbereichs
int i {9}; int *ip {&i}; // Zeiger ip zeigt auf i *ip = 8; // i erhält den Wert 8 { // neuer Block beginnt int j {7}; ip = &j; // Zeiger ip zeigt auf j // weiterer Programmcode ... } // Blockende, j wird ungültig *ip = 8; // gefährlich!
Die letzte Anweisung versucht, j über den Alias *ip den Wert 8 zuzuweisen. Da j aber nicht mehr existiert, ist die Speicherstelle, auf die ip zeigt, möglicherweise vom Betriebssystem bereits für andere Zwecke vergeben worden. Durch diese Zuweisung werden daher gegebenenfalls andere Daten zerstört. Es gibt keine Warnung durch den Compiler oder das Laufzeitsystem! Verzichten Sie also darauf, Zeiger auf lokale Objekte mit gegenüber den Zeigern eingeschränkter Gültigkeit zu verwenden. Stattdessen nehmen Sie besser Zeiger desselben Gültigkeitsbereichs. Weil ip auf j zeigt, wäre in diesem Beispiel als letzte Anweisung j = 8; »günstiger« gewesen: Der Compiler hätte sie sofort als falsch erkannt und somit einen Hinweis auf einen Fehler im Programm gegeben.
Konstante Zeiger auf konstante Werte
Die Bedeutung von const char* ist »Zeiger auf konstante Zeichen« und ist nicht zu verwechseln mit »konstanter Zeiger auf Zeichen« (char *const). Solche Deklarationen sind von rechts nach links zu lesen, wobei die Reihenfolge (const char) auch (char const) lauten kann. Ein konstanter Zeiger auf konstante Zeichen ist demnach vom Typ const char* const oder gleichwertig char const* const.
Dereferenzierung mit dem Pfeiloperator
Die Dereferenzierung eines Zeigers mit dem *-Symbol kennen Sie. Für den Zugriff auf die inneren Elemene von Strukturen und Unions über Zeiger gibt es den Pfeiloperator ->. Ein Beispiel:
| 4.2 | C-Arrays |
Vektoren sind von Seite 89 bekannt. C-Arrays genannte Felder sind etwas Ähnliches, nur viel primitiver: Es sind Bereiche im Speicher, die (eingeschränkt) ähnlich wie ein Vektor benutzt werden können.
Tipp
Wegen der C++-Standardklassen vector und array haben C-Arrays stark an Bedeutung verloren. Weil sie in älteren Programmen noch viel verwendet werden, sollten Sie sie kennen, die Anwendung aber vermeiden. In den meisten Fällen ist die Verwendung von C++-vector- oder array-Objekten bequemer und sicherer!
Der Zugriff auf ein einzelnes Element eines C-Arrays geht über den von den Vektoren bekannten Indexoperator [ ]. Bei einer zweidimensionalen Tabelle ist zusätzlich die Spaltennummer anzugeben, zum Beispiel [6][3]. AnzahlDerElemente in Abbildung 4.3 muss eine Konstante sein oder ein Ausdruck, der ein konstantes Ergebnis hat.

Es ist guter Programmierstil, die Größe eines C-Arrays als Konstante zu deklarieren und die Konstante in der Arraydeklaration und im restlichen Programm zu verwenden. Dadurch kann ein Programm an eine andere Arraygröße angepasst werden, indem nur der Wert der Konstanten geändert wird. Es kann auch direkt eine Zahl eingetragen werden. char a[10]; bezeichnet zum Beispiel ein Feld namens a mit 10 Zeichen.
Der Compiler reserviert für alle Elemente ausreichend Speicherplatz, die Anzahl der Tabellenelemente ist danach während des Programmlaufs nicht veränderbar. Die Anzahl der Elemente ist daher problemabhängig ausreichend groß zu wählen, auch wenn einige Tabellenplätze möglicherweise nicht ausgenutzt werden. Arrays, deren Größe erst zur Laufzeit festgelegt wird, lassen sich auch konstruieren, doch davon später mehr. Die Abbildung 4.4 zeigt ein Array mit 5 ganzen Zahlen.
Der Name des Felds (Tabelle) zeigt auf die Startadresse des Felds, d.h. auf das erste Element, und ist wie ein Zeiger einsetzbar. Anders ausgedrückt: Der Feldname ist wie ein Zeiger auf das erste Element (das Element mit dem Index 0) des Arrays. Ein Unterschied zu Zeigern besteht dennoch. Da dem Array bereits fest Speicherplatz zugewiesen ist, würde eine Änderung dieses »Zeigers« den Speicherplatz unzugänglich machen, weil die Information über die Adresse verloren geht. Der Feldname kann in einen konstanten Zeiger auf das erste Element des Felds (Arrays) umgewandelt werden. Der Zugriff auf ein Element ist durch den Indexoperator [ ] oder durch Zeigerarithmetik möglich, wie die Zuweisung eines Fragezeichens an das sechste Element zeigt (die Nummerierung beginnt bei 0!). Zwischen den eckigen Klammern wird die relative Tabellenposition eingetragen.
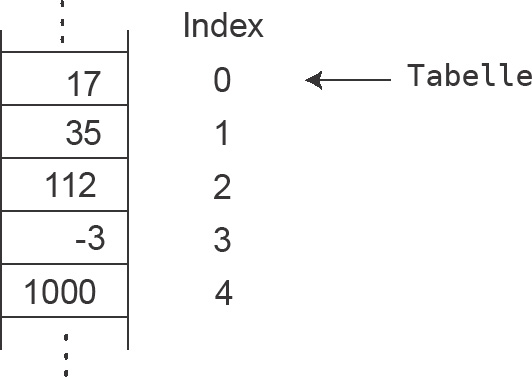
Zeigerarithmetik ist hier die Addition von 5 zu einem Zeiger mit der Bedeutung, dass das Ergebnis als ein um 5 Positionen verschobener Zeiger aufgefasst wird.
Zeiger und C-Arrays
Zeiger und C-Arrays sind im Gebrauch sehr ähnlich. Deswegen werden die Unterschiede hier zusammengefasst:
Ein Zeiger ist der symbolische Name für einen Speicherplatz, der einen Wert enthält, der als Adresse benutzt werden kann.
Ein C-Array ist ein symbolischer Name für die Anfangsadresse eines Bereichs im Speicher. Der Name wird wie ein konstanter Zeiger behandelt: Eine C-Array-Variable ist nicht änderbar, auch wenn der Bereich, auf den sie zeigt, veränderbar ist.
Der C-Arraytyp enthält die Größeninformation, das heißt, die Information über die Anzahl der Elemente. Diese Information ist jedoch nicht in einer Funktion sichtbar, wenn nur das C-Array als Parameter übergeben wird. Ein Beispiel werden Sie bald sehen (Listing 4.24 auf Seite 240).
| 4.2.1 | C-Array, std::size() und sizeof |
C-Arrays sind als »roher Speicher« (englisch raw memory) keine Objekte im bisherigen Sinn. Es gibt keine Elementfunktionen, die verwendet werden könnten. Die Größe eines C-Arrays kann nicht von ihm erfragt werden, sie muss vielmehr vorher bekannt oder mit ssize() , size() oder sizeof ermittelt werden:
sizeof ist ein Operator, der den Platzbedarf eines Ausdrucks oder Typs in Byte zurückgibt. Ein Ausdruck kann, ein Typ muss in runden Klammern eingeschlossen sein. Die Anzahl der Elemente eines C-Arrays ergibt sich einfach durch Division des Platzbedarfs für das ganze Feld durch den Platzbedarf für ein einzelnes Element, in diesem Fall das erste. Wenn der Datentyp wie hier eindeutig bekannt ist, kann statt sizeof tabelle[0] auch sizeof(int) geschrieben werden.
| 4.2.2 | Initialisierung von C-Arrays |
Ein C-Array kann bei der Definition bereits initialisiert werden. Trotz des ’=’-Zeichens in der Initialisierungszeile darf das C-Array auf der linken Seite stehen. Begründung: Eine Initialisierung ist keine Zuweisung. Das ’=’-Zeichen darf fehlen. Der Compiler entnimmt die Anzahl der Feldelemente aus der Initialisierungsliste, eine Zahlenangabe kann deshalb entfallen.
Wie eine Struktur ist auch ein C-Array ein Aggregat und wird mit einer Liste in geschweiften Klammern initialisiert. Falls zu wenige Elemente in der Initialisierungsliste angegeben sind, werden die restlichen mit 0 initialisiert. int feld[3] {1}; ist identisch mit int feld[3] {1, 0, 0};.
| 4.2.3 | Zeigerarithmetik |
Wenn ein Zeiger inkrementiert oder dekrementiert wird, zeigt er nicht auf die nächste Speicheradresse, sondern auf die Adresse des nächsten Werts. Der Abstand der Speicheradressen ist gleich der Größe, die der Wert beansprucht, zum Beispiel 8 Byte bei einem Datentyp double. Gegeben seien folgende Deklarationen (hier gleichzeitig Definitionen):
Wenn nun dp2 = dp1 + 1; gesetzt wird (oder dp2 = dp1; ++dp2;), ergibt sich als Differenz dp2 - dp1 der Wert 1. dp2 zeigt also auf das nächste double-Element des C-Arrays. Aufgrund des notwendigen Platzbedarfs für eine double-Zahl im Speicher von angenommen 8 Byte (die Zahl mag in Ihrem System anders sein) ist die nächste double-Zahl also 8 Byte entfernt. Das wird ermittelt, indem man die Zeigerwerte in long umwandelt und dann die Differenz berechnet:
Dabei ist ptrdiff_t ein im Header <cstddef> definierter Ganzzahltyp, der für das Rechnen mit Adressen gedacht ist. Sie kennen ihn von Seite 40. Zur Wandlung des Zeigers wird der reinterpret_cast-Operator verwendet. Dieser Operator verzichtet im Gegensatz zum static_cast-Operator auf jegliche Typ-Verträglichkeitsprüfung. Mit Zeigern kann also auch ohne Umwandlung in eine Ganzzahl gerechnet werden. Die Einheit ist dabei nicht Byte, sondern sie ergibt sich aus dem Datentyp des Zeigers.
An dieser Stelle wird die Suche eines Werts in einer Tabelle von Seite 93 aufgegriffen, nur dass jetzt ein C-Array mit Zeigeroperationen anstelle eines Vektors eingesetzt wird. Diese Variante erlaubt die kürzeste Formulierung der Schleife, setzt aber wie die vierte Variante in Abschnitt 1.9.3 voraus, dass das Feld um einen Eintrag erweitert wird, der als »Wächter« (englisch sentinel) dazu dient, die Schleife abzubrechen. Das (n+1). Element dient als »Wächter«. Der Zeiger p wird auf das C-Array gerichtet. Der Abbruch der Schleife ist durch a[n] als »Wächterelement« garantiert.
Listing 4.4: key in einem C-Array suchen
// Definitionen const int n = ... int a[n + 1]; // C-Array int key = ... // gesuchtes Element int i {n}; // Ergebnisvariable: i = 0..n – 1 : gefunden, i = n : nicht gefunden! // ... // Ausführung a[n] = key; int *p {a}; while (*p++ != key); i = p - a - 1; // Zeigerarithmetik
*p++ bedeutet, erst den Wert an der Stelle p zu nehmen und dann p hochzuzählen. *p++ ist also identisch mit *(p++), wohingegen (*p)++ den Wert an der Stelle p anstelle des Zeigers p hochzählt. Diese kompakte Schreibweise trägt nicht unbedingt zum schnellen Verständnis eines Programms bei, insbesondere bei fehlenden erläuternden Kommentaren. Machen Sie sich die Wirkungsweise jedoch klar, weil viele diese Schreibweise bevorzugen und Sie deren Programme verstehen können sollten. Am Ende zeigt p auf die Stelle nach der Stelle, wo key liegt, wenn es im Bereich 0 .. (n-1) vorhanden ist. a ist der Anfang des C-Arrays, sodass p - a - 1 auf die gesuchte Stelle zeigt bzw. n ergibt, wenn key nicht im Bereich 0 .. (n-1) vorkommt.
| 4.2.4 | Indexoperator bei C-Arrays |
Der Zugriff über den Indexoperator [ ] wird nicht auf seine Grenzen überprüft! Er kann durch das entsprechende Zeigeräquivalent ersetzt werden. Man kann genauso gut *(tabelle + i) anstatt tabelle[i] verwenden. Der Grund dafür liegt darin, dass der Compiler ohnehin jeden Zugriff über [ ] in die Zeigerform übersetzt, so lange nicht ein benutzerdefinierter Operator [ ] verwendet wird. Letzterer ist nur bei Klassen möglich, siehe Kapitel 8. Mit (tabelle+i) ist die Adresse gemeint, die um i Positionen (nicht Bytes) weiter liegt als der Feldanfang, auf den tabelle zeigt. Der Stern ’*’ sorgt dafür, dass der Wert genommen wird, der an dieser Adresse eingetragen ist.
| 4.2.5 | C-Array durchlaufen |
begin() und end()
Oben wird gezeigt, wie eine for-Schleife ein C-Array durchläuft. Der Indexoperator [] dient zum Zugriff auf das Element. Eine andere Methode benutzt Zeiger und die Funktionen begin() und end():
Listing 4.5: Werte eines C-Arrays mit begin() und end() aufsuchen (cppbuch/k4/carrayIterieren.cpp)
#include <iostream> #include <iterator> // begin() und end() int main() { int carray[]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}; auto anfang{std::begin(carray)}; while (anfang != std::end(carray)) { std::cout << *anfang++ << ’\n’; } }
Die Aufrufe von begin() und end() müssen im Definitionsbereich des C-Arrays liegen. Dabei entspricht end(carray) dem Ausdruck (begin(carray) + size(carray)). Der Zeiger end(carray) zeigt also auf die Position nach dem letzten Element. end(carray) darf nicht dereferenziert werden. Dies wird durch die while-Bedingung sichergestellt. Für die freien Funktionen begin() und end() muss der Header <iterator> inkludiert werden.
Auch der bekannte Container vector kennt begin() und end(), und zwar als Elementfunktionen. Sie geben ein zeigerähnliches Objekt zurück, Iterator genannt. begin() verweist auf den Anfang des Containers. end() zeigt auf die Position nach dem letzten Element. Diese Art der Bereichsangabe ist in C++ üblich und wird häufig verwendet. In der Praxis spielt es keine Rolle, ob die freien Funktionen begin() und end() genommen werden oder die gleichnamigen Elementfunktionen. Ein Beispiel finden Sie in der Datei cppbuch/k4/vectorIterieren.cpp.
range based for
Eleganter und kürzer zu formulieren ist die von Seite 99 bekannte Kurzform der for-Schleife, die auch für C-Arrays funktioniert:
| 4.3 | C-Zeichenketten |
Eine C-Zeichenkette (englisch string) ist ein Spezialfall eines C-Arrays. Mit C-String meint man eine Folge von Zeichen des Typs char, die mit ’\0’ abgeschlossen wird. Diese C-Strings sind nicht zu verwechseln mit den C++-String-Objekten, deren Basis sie bilden.
Hinweis
Wegen der C++-Standardklasse string haben C-Strings stark an Bedeutung verloren. Sie sollen C-Strings kennen, die Anwendung aber vermeiden, wenn es nicht nur um Literale geht. Die Verwendung von C++-string-Objekten ist bequemer und sicherer!
Umgangssprachlich kann »String« sowohl ein C++-String-Objekt wie auch einen C-String meinen. ’\0’ ist das ASCII-Zeichen mit dem Wert 0, nicht das Ziffernzeichen ’0’. Der Datentyp für einen C-String ist char* und stellt einen Zeiger auf den Beginn der Zeichenfolge dar, über den auf den C-String zugegriffen wird. Bei der Ausgabe einer Zeichenkette »weiß« der zu cout gehörende Ausgabeoperator <<, dass char* nicht als Zeiger, sondern als mit ’\0’ terminierter C-String aufzufassen ist:
Hier wird str gleichzeitig definiert und initialisiert. ’\0’ muss an dieser Stelle nicht hingeschrieben werden, weil es vom Compiler ergänzt wird. Der Compiler erkennt einen C-String am Datentyp char*. Eine Zeichenkettenkonstante, auch Literal genannt, erkennt er daran, dass sie in Anführungszeichen eingeschlossen ist. Der vom Compiler für den C-String »ABC« reservierte Speicherplatz beträgt 4 Byte, ein Byte pro Zeichen und ein Byte für ’\0’. Der Zugriff auf einzelne Zeichen ist auf die Arten möglich, die wir schon von den C-Arrays her kennen. cout << str[0]; zeigt das erste Zeichen, welches an der Position 0 steht (die interne Zählung läuft auch hier ab 0). Das Zeichen mit der Nummer i ist ansprechbar mit str[i] oder *(str+i). Im Gegensatz zu char-C-Arrays werden Stringliterale im schreibgeschützten, also unveränderlichen Speicher angelegt. Zeiger auf Textliterale müssen daher stets als const char* deklariert werden!
Eine neue Zuweisung str = "neuer Text"; ist möglich, wobei die Information über die vorherige Stelle verloren geht (siehe Abbildung 4.5). Zur Bearbeitung von C-Strings gibt es eine Menge vordefinierter Funktionen, die in der Datei string.h (Header <cstring>) deklariert sind. #include<cstring> veranlasst den Compiler, diese Datei zu lesen, anschließend kennt er die Funktionen. Die Funktionen sind in Abschnitt 33.6 beschrieben.

Hier sei beispielhaft nur die Funktion strlen() gezeigt, die die Anzahl der Zeichen eines C-Strings (ohne ’\0’) zurückgibt. Zeichen wie ’\n’ zählen als einzelne Zeichen mit, wie auch ’\"’, wodurch das Anführungszeichen als zum C-String zugehörig erscheint und eine vorzeitige Interpretation als C-String-Ende verhindert wird.
Listing 4.7: Zusammengesetzter C-String (cppbuch/k4/langstr.cpp)
#include <cstring> // strlen() #include <iostream> using namespace std; int main() { const char* const text = "Bei˽Initialisierung,˽Zuweisung,˽oder˽" "Ausgabe˽kann˽ein˽Stringliteral˽wie˽hier˽auch˽aus˽" "einzelnen˽Teilstrings˽zusammengesetzt˽werden."; cout << text << "\nenthält˽" << strlen(text) << "˽Zeichen\n"; }
Es gibt auch eine constexpr-Funktion zur Berechnung der Länge eines C-Strings:
Sie ist im Header <string> definiert. Der Speicherplatz für ein Literal, also eine durch Anführungszeichen begrenzte Zeichenfolge, wird zur Compilierzeit festgelegt und kann während der Ausführung des Programms nicht verändert werden. Ein nicht initialisierter C-String besitzt keinen Speicherplatz außer für den Zeiger selbst – dies wird gelegentlich vergessen. Bei der Eingabe mit cin muss darauf geachtet werden, dass genügend Platz zur Verfügung steht, andernfalls ist das Programmverhalten unvorhersehbar.
Im ersten Fall zeigt x auf eine undefinierte Stelle irgendwo im Speicher, an die die eingelesenen Zeichen geschrieben werden, wobei die vorher dort gespeicherten Informationen vernichtet werden! Führende sogenannte Zwischenraumzeichen (englisch whitespace) werden von dem >>-Operator ignoriert. Zwischenraumzeichen ist ein Sammelbegriff für Leerzeichen, Tabulatorzeichen usw. Mit Zwischenraumzeichen wird die Eingabe für cin beendet, wie Sie aus Abschnitt 1.10.1 wissen. Wenn Sie einen definierten Platz bereitstellen wollen, deklarieren Sie ein char-Array ausreichender Größe als Eingabepuffer:
Wie eine ganze Zeile inklusive aller Zwischenraumzeichen und gleichzeitig sehr sicher eingelesen wird, sehen Sie im dritten Beispiel:
Die Konstante zmax muss nur groß genug gewählt werden. Günstiger ist es in der Regel, string-Objekte einzulesen, wie auf Seite 107 beschrieben.
char-Arrays
Eine Art Zwitterstellung nehmen die char-Arrays ein. Genau wie bei C-Arrays wird Speicherplatz zur Compilierzeit reserviert. Wie bei C-Strings nimmt der Ausgabeoperator << bei cout an, dass mit dem char-Array eine Zeichenkette gemeint ist, die mit ’\0’ abschließt. Die Initialisierung kann wie bei C-Strings geschehen oder wie bei C-Arrays vorgenommen werden. Im Folgenden werden einige Beispiele für die verschiedenen Fälle aufgelistet.
Listing 4.8: Umgang mit char-Arrays
// Definition und Initialisierung char str_a [ ]{"noch˽ein˽C-String"}; char str_b [9]; // 9 Byte reservieren, d.h. 8 Zeichen 0 bis 7 sowie ’\0’ char str_c [9] {"ABC"}; // 9 Byte, ABC und 6 mal ’\0’ cin >> str_b; // Eingabe wie bei C-Strings. Länge beachten! // Aliasing, d.h. mehr als einen Namen für nur eine Sache const char* str1{"Guten˽Morgen!\n"}; const char* str2{str1}; // str2 zeigt auf dieselbe Stelle wie str1. cout << str2; // Beweis: Guten Morgen! // erlaubte Zuweisung char charArray1[ ]{"hallo\n"}; str1 = charArray1; // Zeiger str1 zeigt nun auf Array-Anfang ++str1; // str1 zeigt jetzt auf das nächste Zeichen // nicht erlaubt, weil ein C-Array als const-Zeiger interpretiert wird: charArray1 = str1; // Fehler! ++charArray1; // Fehler! // Definition char buchstaben0[3]{"abc"}; // Fehler! (kein Platz für ’\0’). Richtig ist: char buchstaben1[4]{"abc"}; // oder char buchstaben2[ ]{"abc"}; // Compiler zählen lassen oder char buchstaben3[3]{’a’,’b’,’c’}; // ohne ’\0’-Terminierung!
C-String-Arrays
Die Elemente eines C-Arrays können auch Zeiger auf C-Strings sein. Abbildung 4.6 und das Listing 4.9 verdeutlichen die Datenstruktur.
Listing 4.9: Beispiel für Zugriff auf ein C-String-Array. Bezug: Abbildung 4.6 (cppbuch/k4/cstrarray.cpp)
#include <iostream> using namespace std; int main() { const char* sa[] {"eins",˽"zwei"}; // Array const char** sp{sa}; // Zeiger auf const char*. // gleichwertig ist auto sp {sa}; // Programmausgabe: cout << sa[0] << ’\n’; // eins cout << *sa << ’\n’; // eins cout << sa[1] << ’\n’; // zwei cout << sa[1][0] << ’\n’; // z cout << *sp << ’\n’; // eins cout << sp[1] << ’\n’; // zwei }

Die Abbildung zeigt ein C-String-Array sa und einen Zeiger sp auf den Anfang des Felds. sa ist ein symbolischer Name für den Feldanfang und wird syntaktisch wie ein nichtveränderbarer Zeiger auf den Feldanfang behandelt. Der Zugriff auf Feldelemente über Array-Indizes oder Zeiger ist äquivalent.
| 4.3.1 | Schleifen und C-Strings |
Trotz vorhandener Funktionen für die Bearbeitung werden hier einige Operationen mit C-Strings diskutiert, weil sie in ihrer Art typisch sind und unterschiedliche Gestaltungsmöglichkeiten für Schleifen aufzeigen. Als Erstes soll die Länge einer Zeichenkette auf verschiedene Weisen bestimmt werden. Nach jeder Variante enthält sl die C-String-Länge.
C-String-Länge berechnen
Die Variable temp, die ebenfalls auf die Zeichenfolge zeigt, ist notwendig, damit str1 nicht geändert zu werden braucht und am Ende weiterhin auf den Beginn der Zeichenkette zeigt. Die mit 0 initialisierte Variable sl steht für die C-String-Länge. Was geschieht nun in der Schleife? Zunächst wird der Wert an der Stelle temp geprüft. Die Auswertung der Bedingung ergibt wahr, weil der erste Wert *temp mit dem ersten Zeichen ’e’ der Zeichenkette identisch und damit ungleich 0 ist. sl wird daher um 1 erhöht, und temp wird auf das nächste Zeichen (’i’) gerichtet. Dieser Ablauf wird so lange wiederholt, bis *temp == ’\0’ gilt, also temp auf das Ende des C-Strings zeigt. sl enthält jetzt die Anzahl der Zeichen in str1.
Die while-Schleife ist etwas kürzer durch den Seiteneffekt, dass temp nach Auswerten in der Bedingung inkrementiert wird. Zur Bedeutung von *temp++ siehe die Erläuterung am Ende von Abschnitt 4.2.3.
Diese while-Schleife hat keine Anweisung mehr im Schleifenkörper, weil alles Nötige bereits innerhalb der Bedingung getan wird. Ein temporärer Zeiger ist nicht notwendig, weil über den Indexoperator auf die Elemente der Zeichenkette zugegriffen wird. Weil sl in jedem Fall beim Auswerten der Bedingung inkrementiert wird, also auch am Ende des C-Strings, muss die letzte Inkrementierung wieder rückgängig gemacht werden. Durch eine Inkrementierung noch vor Auswertung der Bedingung lässt sich das vermeiden:
Diese Formulierung lässt einfach den Zeiger temp bis zum terminierenden Zeichen ’\0’ laufen. Die C-String-Länge entspricht dann der Differenz der Zeiger, korrigiert um das ’\0’-Zeichen. Nachdem nun bekannt ist, wie die Länge einer C-Zeichenkette ermittelt wird, empfiehlt sich für den weiteren Gebrauch die Funktion strlen(const char*) oder die constexpr-Funktion char_traits<char>::length(const char*).
C-Strings kopieren
Nehmen wir an, wir hätten zwei C-Strings deklariert und der zweite soll ein Duplikat des ersten werden.
Die Zuweisung duplikat = original; hätte hier nicht den gewünschten Effekt, denn es wird nur der Zeiger kopiert, das heißt, duplikat zeigt auf denselben Speicherbereich wie original. Wenn eine C-Zeichenkette dupliziert werden soll, muss man sie elementweise in einen vordefinierten Speicherbereich kopieren. In diesem Fall ist keine Zieladresse definiert und nicht genügend Speicher vorhanden, weil duplikat bei der Definition nicht entsprechend initialisiert wurde. Es muss also zusätzlich Sorge getragen werden, dass der duplikat zur Verfügung stehende Speicherplatz mindestens so groß ist wie der von original. Es gibt für Kopierzwecke ebenfalls vordefinierte Funktionen, auf die später noch eingegangen wird. Das Kopieren eines C-Strings wird auf vier Arten mit while gezeigt (do while-Varianten sind natürlich auch möglich). Vorangestellt sind die allen Varianten gemeinsamen Definitionen, wobei sichergestellt sein muss, dass der Speicherplatz des Zielbereichs dest ausreichend ist.
Definitionen:
In der Schleife wird jedem Element von dest das entsprechende von source zugewiesen. Weil die Zuweisung wegen der Schleifenbedingung nicht mehr für ’\0’ durchgeführt wird, wird die Endekennung anschließend eingetragen.
Dieses Beispiel unterscheidet sich vom vorhergehenden nur dadurch, dass die Inkrementierung von i als Seiteneffekt in die Bedingung verlegt und auf den Vergleich mit ’\0’ verzichtet wird. Es wird der Wert von source[++i] ausgewertet.
Die Hilfszeiger s und d werden auf die Anfänge des Quell- und Zielbereichs gesetzt. In der Bedingung wird das Zeichen, auf das s zeigt, geprüft. Die Bedingung ist so lange wahr, bis s auf ’\0’ zeigt. Wenn die Bedingung wahr ist, wird jedes Mal mit *d=*s; der Wert an der Stelle d gleich dem Wert an der Stelle s gesetzt, anschließend werden s und d um 1 weitergezählt. Auch hier wird die Zuweisung von ’\0’ nicht mehr innerhalb der Schleife vorgenommen, sodass sie nachgeholt wird. s wird eingeführt, damit source nicht verändert werden muss. Der Hilfszeiger d ist notwendig, weil dest als C-Array nicht veränderbar ist.
Noch kürzer geht es nicht! Der Unterschied zur vorangehenden Variante liegt darin, dass sämtliche Aktivitäten in die Bedingung verlegt werden. Alle Seiteneffekte werden ausgeführt einschließlich der Bedingung, die die Schleife zum Abbruch bringt. Die Anweisung *d=’\0’; ist nun nicht mehr gesondert notwendig, weil sie die letzte während der Bedingungsauswertung ist. Am Ende der Schleife zeigen s und d auf die Stellen direkt nach den ’\0’-Zeichen. Die sehr kompakte Schreibweise ist auf den ersten Blick vielleicht schwer zu verstehen. Andererseits ist diese Art der Formulierung ein gebräuchliches Idiom in C und C++. Deswegen sollten auch Sie sich damit vertraut machen. Die Anweisung while (*d++=*s++) kann als Abkürzung einer do while-Schleife aufgefasst werden. Zur Erläuterung wird der Ablauf dieser kurzen Anweisung in Einzelschritte aufgelöst formuliert:
Nachdem bekannt ist, wie eine C-Zeichenkette kopiert wird, empfiehlt sich für den weiteren Gebrauch die Funktion strncpy(char* ziel, const char* quelle, size_t n), die höchstens n Zeichen kopiert.
| 4.4 | Dynamische Datenobjekte |
Bisher wurden nur Datentypen behandelt, deren Speicherplatzbedarf bereits zur Compilierzeit berechnet und damit vom Compiler eingeplant werden konnte. Nicht immer ist es jedoch möglich, den Speicherplatz exakt vorherzuplanen, und es ist unökonomisch, jedes Mal mit großen Arrays sicherheitshalber den maximalen Speicherplatz zu reservieren. C++ bietet daher die Möglichkeit, mit dem Operator new Speicherplatz genau in der richtigen Menge und zum richtigen Zeitpunkt bereitzustellen und diesen Speicherplatz mit delete wieder freizugeben, wenn er nicht mehr benötigt wird. Damit unterliegen die mit new erzeugten Objekte nicht den Gültigkeitsbereichsregeln für Variablen.
Tipp
Sie sollten new und delete kennen, weil sie in existierenden Programmen, die Sie vielleicht verstehen müssen, noch vorkommen. Verwenden Sie aber new und delete nicht selbst (außer zur Übung), um die damit oft verbundenen Fehler zu vermeiden. Am Ende des Kapitels lernen Sie einfachere und sichere Möglichkeiten kennen, Speicher zu beschaffen.
new erkennt die benötigte Menge Speicher am Datentyp, sie muss also nicht explizit angegeben werden. Es gibt einen vom Betriebs- oder Laufzeitsystem verwalteten großen zusammenhängenden Adressbereich, der free store, dynamic store oder heap genannt wird. Ich verwende im Folgenden durchgängig die letzte Bezeichnung, die deutsch Halde oder Haufen bedeutet. Innerhalb des Heaps wird mit new der Platz für ein Objekt reserviert. Der Zugriff auf die neu auf dem Heap erzeugten Objekte geschieht ausschließlich über Zeiger. Abbildung 4.7 visualisiert das folgende Code-Beispiel.

Nur der Platz für p wird zur Compilierzeit eingeplant. Mit p = new int; wird Speicherplatz in der Größe von sizeof(int) Byte erst zur Laufzeit des Programms bereitgestellt, und p zeigt nach dieser Operation auf diesen Platz. *p (Wert an der Stelle p) kann als Name für das Objekt interpretiert werden. Die ersten zwei bzw. drei Zeilen können zusammengefasst werden:
Mit new kann dynamisch ein C-Array erzeugt werden, wobei dann eckige Klammern [ ] angegeben werden. Der Operator new [ ] zur Erzeugung von C-Arrays wird in C++ vom new-Operator für einzelne Objekte unterschieden. Hier wird ein Feld von vier int-Zahlen bereitgestellt (siehe auch Abbildung 4.8).

Der Zugriff auf die Elemente geschieht wie bei dem statisch deklarierten C-Array. Im Beispiel enthalten die Arrayelemente 0 und 3 undefinierte Werte. Das Programmstück zeigt beispielhaft den Gebrauch von Zeigern für Objekte, die mit new erzeugt wurden:
Listing 4.21: Etwas komplizierteres Beispiel zur Übung, siehe Abbildung 4.9.
int** pp = new int*[4]; // C-Array von Zeigern auf int-Zahlen pp[0] = p; // pp[0] zeigt auf *p pp[1] = &pa[2]; // pp[1] zeigt auf pa[2] (s.o.) cout << *pp[0] << ’\n’; // 15 cout << **pp << ’\n’; // 15 cout << *pp[1] << ’\n’; // 45
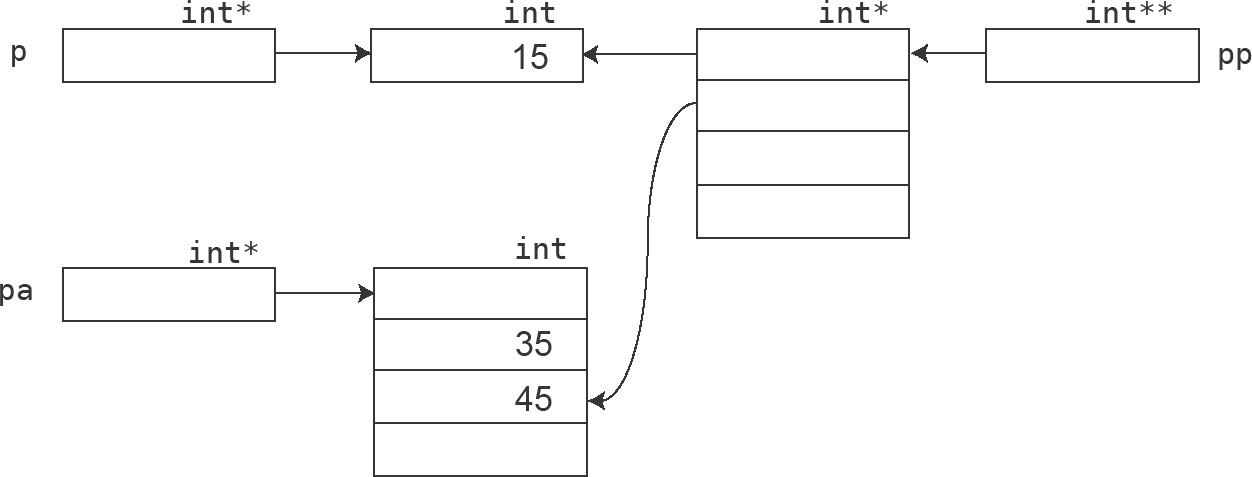
Das zweifache Sternchen bei der Deklaration mag etwas ungewohnt erscheinen. int** pp ist gleichbedeutend mit (int*)* pp, das heißt, pp ist ein »Zeiger auf Zeiger auf int«, weil die Array-Elemente selbst Zeiger sind. Sie sind nach der Deklaration alle noch undefiniert, verweisen also nicht auf bestimmte Speicherplätze. Das ändert sich nur für die ersten beiden Elemente, die nach den Zuweisungen auf die oben definierten Plätze *p und pa[2] verweisen.
Dynamisch erzeugte Struktur
Die Struktur test_struct enthält eine int- und eine double-Variable und außerdem einen Zeiger next auf ein gleichartiges Objekt.
Der Zeiger sp verweist auf ein neu erzeugtes Objekt der Größe sizeof(test_struct), der Summe sizeof(int) + sizeof(double) + sizeof(test_struct*) entsprechend. Der Zugriff auf die Elemente geschieht über den Pfeil-Operator ->:
Dem Zeiger sp->next wird mit sp->next = new test_struct; ein weiteres neu erzeugtes Objekt zugewiesen, sodass jetzt zwei miteinander verkettete Objekte vorliegen, die beide über den Zeiger sp erreichbar sind (Abbildung 4.10).

Interne Datenelemente des zweiten Objekts können durch entsprechende Anweisungen der Art sp->next->a = 144; erreicht werden. Der beschriebene Verkettungsmechanismus wird zum Aufbau von Listen verwendet.
| 4.4.1 | Freigeben dynamischer Objekte |
Der delete-Operator gibt den reservierten Platz wieder frei, damit er von Neuem belegt oder anderen Programmen zur Verfügung gestellt werden kann. Nach delete wird der Zeiger angegeben, der auf das zu löschende Objekt verweist. Im Folgenden werden alle oben erzeugten Objekte der Reihe nach gelöscht. Dabei könnte man anstatt delete p auch delete pp[0] schreiben, weil pp[0] auf dasselbe Objekt verweist, aber nicht beides. Das Löschen des Objekts, auf das sp->next zeigt, muss vor dem Löschen von *sp erfolgen, weil sonst mit der Vernichtung von *sp die Information über den Ort des über next verketteten Objekts verloren wäre. In Entsprechung zu den Operatoren new und new [ ] wird zwischen den Operatoren delete und delete [ ] unterschieden.
Falls es nicht gelingt, mit new Speicher zu beschaffen, zum Beispiel weil schon zu viel verbraucht und nicht wieder freigegeben wurde, wird das Programm mit einer Fehlermeldung abgebrochen. Einige Dinge sind bei der Verwendung von new und delete zu beachten, deren Missachtung oder Unkenntnis in manchen Fällen ein unvorhersehbares Programmverhalten nach sich zieht, leider ohne Fehlermeldung seitens des Compilers oder des Laufzeitsystems.
delete darf ausschließlich auf Objekte angewendet werden, die mit new erzeugt worden sind.
Für jedes new darf es nur exakt ein delete geben. Der Wert eines Zeigers, auf den delete angewendet wurde, ist danach undefiniert, er entspricht also leider nicht dem nullptr. Falls zwei oder mehr Zeiger auf ein Heap-Objekt zeigen, bewirkt ein delete auf nur einen von diesen Zeigern die Zerstörung des Objekts. Die anderen Zeiger verweisen danach nicht mehr auf einen Speicherbereich mit Bedeutung, sie heißen dann »hängende Zeiger« (englisch dangling pointer).
delete auf einen Null-Zeiger angewendet, bewirkt nichts und ist unschädlich.
Wenn ein mit new erzeugtes Objekt mit dem delete-Operator gelöscht wird, wird automatisch der Destruktor für das Objekt aufgerufen.
Mit new erzeugte Objekte unterliegen nicht den Gültigkeitsbereichsregeln für Variablen. Sie existieren so lange, bis sie mit delete gelöscht werden oder das Programm beendet wird. Dies gilt nicht für die statisch deklarierten Zeiger auf diese Objekte, für die die normalen Gültigkeitsbereichsregeln gelten. Als Konsequenz ist darauf zu achten, dass ein Zeiger auf ein Heap-Objekt mindestens bis zu dessen Löschung existiert, damit überhaupt eine Chance besteht, das Objekt zu löschen. Das folgende Programmfragment verdeutlicht das Problem:
Nach Verlassen des Blocks existiert p nicht mehr; das Objekt mit dem ehemaligen Namen *p existiert noch, ist aber nicht mehr erreichbar. In Schleifen angewendet, kann diese Methode schnell zu Speicherknappheit führen. Es kommt vor, dass ein rund um die Uhr laufendes Programm nach einer Woche plötzlich ohne erkennbare Ursache stehenbleibt, wofür wir nun einen möglichen Grund kennen. Ein nicht mehr zugänglicher Bereich wird »verwitwetes« Objekt genannt, im Englischen memory leak (»Speicherleck«). Richtig ist:
oder:
Die Freigabe von C-Arrays erfordert die Angabe der eckigen Klammern (siehe obiges Beispiel). Ohne [ ] gäbe delete pa; nur ein einziges Element frei! Der Rest des Arrays wäre danach nicht mehr zugänglich (verwitwetes Objekt). Merkregel: delete [] dann (und nur dann) benutzen, wenn die Objekte mit new [] erzeugt worden sind.
Hinweis
Eine fehlerhafte delete-Anweisung für ein C-Array resultiert nach dem C++-Standard in »undefiniertem Verhalten« (englisch undefined behaviour).
Das bedeutet nicht unbedingt Programmabsturz, sondern dass der Hersteller des Compilers selbst entscheiden kann, was zu tun ist: Fehler selbsttätig korrigieren, Warnung ausgeben, Speicherleck akzeptieren oder was auch immer. Das bedeutet aber auch, dass ein Programm der Art
nicht portabel1 ist! Bei einem System wird der Fehler toleriert, beim anderen kracht es, weil der Speicher ausgeht. Beides wäre im Sinn des C++-Standards »legal«. Manche Programmiersprachen kennen kein delete. Dafür gibt es ein parallel laufendes Programm zur Speicherbereinigung, garbage collector genannt (englisch für »Müllsammler«). Die Speicherverwaltung vieler C++-Systeme enthält aus Effizienzgründen keine Speicherbereinigung – es gibt ja delete. C++ erlaubt es jedoch, eine eigene Speicherverwaltung zu schreiben. Es gibt auch entsprechende Bibliotheken. Neben mangelndem Speicher liegt ein weiterer Grund für das plötzliche unerwartete Stehenbleiben von sehr lange laufenden Programmen in der Zerstückelung (Fragmentierung) des Speichers durch viele new- und delete-Operationen. Damit ist gemeint, dass sich kleinere belegte und freie Plätze abwechseln, sodass die plötzliche Anforderung eines größeren zusammenhängenden Bereichs für ein großes Datenobjekt nicht mehr erfüllbar ist, obwohl die Summe aller einzelnen freien Plätze ausreichen würde. Dieses Problem verlangt ein Zusammenschieben aller belegten Plätze, sodass ein großer freier Bereich entsteht. Programme zur garbage collection erledigen diese Aufgabe meistens gleich mit.
| 4.5 | Zeiger und Funktionen |
| 4.5.1 | Parameterübergabe mit Zeigern |
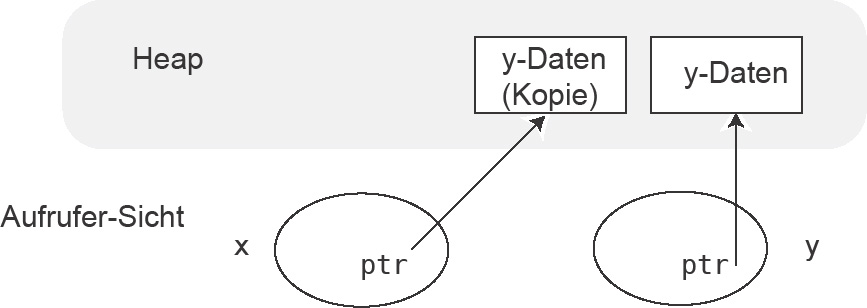
Wenn ein Objekt modifiziert werden soll, kann die Übergabe per Zeiger auf das Objekt geschehen. Dies ist ein Spezialfall der Übergabe per Wert, es wird nämlich mit einer Kopie des Zeigers weitergearbeitet. Die Kopie zeigt auf dasselbe Objekt wie das Original. Die Übergabe per Zeiger ist kein Sprachmittel von C++, sondern zeigt nur eine andere Art der Benutzung der Übergabe per Wert. Eine Modifikation des Zeigers in der Funktion ändert also nicht den Wert des Zeigers für den Aufrufer. Je nach Anwendung kann auch ein unveränderlicher Zeiger übergeben werden.
Das Objekt, auf das der Zeiger verweist, kann in der Funktion gleichwohl geändert werden, sodass der Zeiger beim Aufrufer zwar auf dieselbe Adresse zeigt, unter dieser Adresse jedoch ein verändertes Objekt zu finden ist. Im Beispiel ist beides zu sehen: Die lokale Kopie s des Zeigers str wird verändert, ohne dass str verändert wird, aber das Objekt an der Stelle str ändert sich, weil alle Klein- durch Großbuchstaben ersetzt werden. Abbildung 4.11 zeigt in Ergänzung zum Programmbeispiel, dass ein Objekt über die Kopie eines Zeigers zugreifbar und modifizierbar ist.
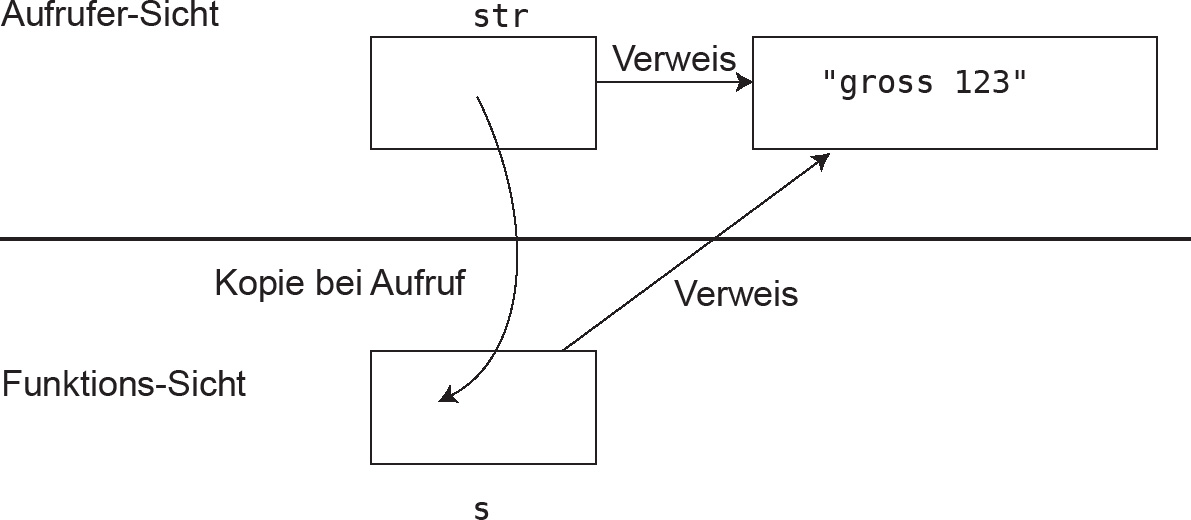
Abbildung 4.11: Parameterübergabe per Zeiger. Bezug: Listing 4.23
Listing 4.23: Parameterübergabe per Zeiger (cppbuch/k4/perzeiger.cpp)
#include <iostream> using namespace std; void upcase(char*); // Prototyp int main() { char str[]{"gross˽123"}; cout << str << ’\n’; upcase(str); cout << str << ’\n’; // GROSS 123 } void upcase(char* s) { constexpr int differenz = ’a’ - ’A’; // In der ASCII-Tabelle sind die Platznummern // der Kleinbuchstaben um ’a’-’A’ = 32 gegenüber den Großbuchstaben verschoben. while (*s) { if (*s >= ’a’ && *s <= ’z’) { *s -= differenz; } ++s; } }
Weil ein char vom Compiler bei der Umwandlung als eine Ein-Byte-int-Zahl interpretiert wird, ist das Rechnen ohne explizite Typumwandlung möglich. Um von der internen Darstellung der Zeichen unabhängig zu sein, wird ’a’-’A’ anstatt 32 benutzt. Auch ist es schwierig, bei fehlendem Kommentar die Bedeutung der Zahl 32 zu erraten. Die Umlaute und andere Sonderzeichen werden auf verschiedenen Maschinen mit anderen Betriebssystemen durch andere Codierungen repräsentiert, darunter auch Multi-Byte-Codierungen wie Unicode. Das Programm verarbeitet daher keine Umlaute. Alle Zeichen außerhalb des ASCII-Bereichs müssen ihrer Codierung entsprechend verarbeitet werden. Die Datei cppbuch/k4/perzeigerISO8859.cpp (nicht abgedruckt) enthält Umlaute und ist ISO 8859-1 codiert. Das damit erzeugte Programm funktioniert nur unter bestimmten Bedingungen (siehe Kommentar im Programmcode).
| 4.5.2 | C-Array als Funktionsparameter |
Wie schon in Abschnitt 4.2 erwähnt, sind C-Arrays syntaktisch mit konstanten Zeigern gleichzusetzen, obwohl es Unterschiede gibt. Die Parameterliste (int tabelle[]) einer Funktion ist daher dasselbe wie (int* tabelle). Damit kann sizeof nicht zur Größenermittlung eines C-Arrays benutzt werden, wie das folgende Beispiel zeigt:
Listing 4.24: Fehlerhaftes Beispiel
void carray_ausgeben(int arr[]) // C-Array-Deklaration { int anzahlBytes {sizeof arr}; // Fehler! Dasselbe wie sizeof(int*) int n = anzahlBytes / sizeof(int); // Anzahl der Elemente? for (int i = 0; i < n; ++i) { std::cout << arr[i] << ’˽’; } std::cout << ’\n’; } int main() { int carray[]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}; // C-Array-Definition carray_ausgeben(carray); // leider falsch ... }
sizeof arr innerhalb der Funktion carrayausgeben gibt nur den Platzbedarf für einen Zeiger zurück, weil syntaktisch int arr[] dasselbe wie int* arr ist! sizeof kann den benötigten Speicherplatz nur im Sichtbarkeitsbereich der Definition eines C-Arrays erkennen, also dort, wo Speicherplatz tatsächlich beschafft wird (wie etwa auf Seite 224). Das folgende Listing zeigt die Korrektur.
Listing 4.25: Korrigiertes Beispiel (cppbuch/k4/carrayFunk.cpp)
#include <iostream> void carrayausgeben(int* arr, int n) { // keine Prüfung, ob arr überhaupt n Elemente hat! for (int i = 0; i < n; ++i) { std::cout << arr[i] << ’˽’; } std::cout << ’\n’; } int main() { int carray[]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}; carrayausgeben(carray, std::size(carray)); }
Besser ist die Verwendung eines array-Objekts. Der Vergleich von Listing 4.26 mit Listing 4.25 zeigt, dass im Vergleich zum C-Array die Übergabe an eine Funktion einfacher ist, weil die Größe des Arrays nicht explizit übergeben werden muss. Noch einfacher ist die Formulierung der Funktion als Template, sodass sie für verschiedene Array-Typen gilt.
Listing 4.26: Übergabe von std::array an eine Funktion (cppbuch/k4/stdarrayFunk.cpp)
#include <array> #include <iostream> void arrayausgeben(const std::array<int, 10>& arr) { for (auto wert : arr) { std::cout << wert << ’˽’; } std::cout << ’\n’; } template <typename Array> // als Template void arrayausgeben1(const Array& arr) { for (auto wert : arr) { std::cout << wert << ’˽’; } std::cout << ’\n’; } int main() { constexpr std::array arr{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}; arrayausgeben(arr); arrayausgeben1(arr); std::cout << "Zugriff˽wie˽bei˽C-Arrays,˽z.B.˽arr[9]:˽" << arr[9] << "\nGroesse˽des˽Arrays=˽" << ssize(arr) << ’\n’; }
C++ bietet mit span eine weitere sichere Möglichkeit. span ist eine Sicht auf ein Array oder Container, die als Kombination von Zeiger und Länge aufgefasst werden kann. Ein span<T>-Objekt kann wie ein vector<T> benutzt werden, ohne einer zu sein. Es hält intern nur einen Verweis auf den zugrunde liegenden Container und seine Größe, benötigt also kaum Speicherplatz. Es kennt die Methoden begin() und end() des Containers. Einzelheiten zu span finden Sie in Abschnitt 27.5. Die Anwendung ist einfach, wie die nicht abgedruckte Datei cppbuch/k4/carrayFunkSpan.cpp zeigt. Die Fehlerquelle, eine falsche Zahl zu übergeben, ist eliminiert.
Merke:
Wenn nicht span oder array eingesetzt wird, muss die Anzahl der Array-Elemente (Zeilen) einer Funktion übergeben werden! Dies gilt auch für mehrdimensionale C-Arrays (für die span nicht gedacht ist). Nur im Sichtbarkeitsbereich der Definition eines C-Arrays kann die Anzahl mithilfe von std::size(), std::ssize(), sizeof oder einer Template-Funktion (siehe Abschnitt 4.7 unten) ermittelt werden. Diesen Ärger können Sie sich sparen, wenn Sie statt C-Arrays Objekte der Klassen vector oder array nehmen.
| 4.5.3 | const und Zeiger-Parameter |
Hier seien verschiedene Möglichkeiten der Verwendung von const in einer Parameterliste aufgezeigt. Es liegt ein C-Array mit int-Werten zugrunde. Die Anzahl der Elemente wird der Funktion beim Aufruf übergeben, damit das Ende des C-Arrays in der Funktion bestimmt werden kann.
void tabellenfunktion(int* tabelle, int anzahl)
Nichts ist konstant, das heißt, in der Funktion können sowohl die Tabellenwerte wie auch der Zeiger tabelle geändert werden. Ersteres wirkt sich beim Aufrufer aus, Letzteres nicht, weil in der Funktion eine Kopie des Zeigers angelegt wird (Übergabe des Zeigers per Wert).
void tabellenfunktion(const int* tabelle, int anzahl)
tabelle zeigt auf nicht veränderbare Elemente. Eine Anweisung der Art tabelle[0] = 3; innerhalb der Funktion würde vom Compiler nicht akzeptiert werden, ++tabelle wäre hingegen ok.
void tabellenfunktion(int* const tabelle, int anzahl)
tabelle ist selbst konstant. Eine Anweisung tabelle = nullptr; würde vom Compiler nicht akzeptiert werden, tabelle[10] = 17; schon.
void tabellenfunktion(const int* const tabelle, int anzahl)
Kombiniert die beiden vorhergehenden Möglichkeiten: Ein konstanter Zeiger zeigt auf unveränderliche Werte.
Ein konstanter Zeiger verbietet eine Änderung des Zeigers innerhalb der Funktion. Diese Änderung hätte aber ohnehin keine Auswirkung auf das aufrufende Programm, wie oben erläutert. In der Praxis sind daher nur die ersten beiden Fälle von Bedeutung bzw. deren ungefähre Entsprechungen mit span.
void tabellenfunktion(span<int>)
Wenn ein C-Array tabelle mit int-Werten übergeben wird, können diese Werte in der Funktion geändert werden. In einer for-Schleife der Funktion müsste ggf. auto durch auto& ersetzt werden.
void tabellenfunktion(span<const int>)
In diesem Fall können die Werte des C-Arrays nur lesend verwendet werden.
| 4.5.4 | Parameter des main-Programms |
main() kann über Parameter verfügen, siehe Seite 130. Sie sind innerhalb des Programms auswertbar, wie es in vielen Dienstprogrammen gehandhabt wird. Die Parameter werden beim Aufruf des Programms auf Betriebssystemebene nach dem Programmnamen angegeben, daher der Name »Kommandozeilenparameter«. Der Compilerhersteller kann weitere Parameter nach char* argv[] zulassen. Üblich ist ein weiteres C-String-Array char* env[] zum Abfragen von Umgebungsvariablen (englisch environment variables):
argc ist die Anzahl der Kommandozeilenparameter einschließlich des Programmaufrufs, argv[] ein C-String-Array mit den Kommandozeilenparametern. Das letzte Element von env[] ist 0, und es gilt argv[argc] == 0 (entspricht Null-Zeiger). argv[0] enthält den Programmaufruf. Das Programm mainpar.cpp demonstriert die Benutzung der Parameter. Auf Betriebssystemebene kann es zum Beispiel mit mainpar 1 par2 /3 5 5 A6 aufgerufen werden. Die Werte haben hier keine Bedeutung und dienen nur zur Demonstration.
Listing 4.27: Kommandozeilenparameter anzeigen (cppbuch/k4/mainpar.cpp)
#include <iostream> using namespace std; int main(int argc, char* argv[], char* env[]) { cout << "Aufruf˽des˽Programms˽=˽" << argv[0] << ’\n’; cout << (argc - 1) << "˽weitere˽Argumente˽wurden˽main()˽übergeben:\n"; int i {1}; while (argv[i]) { cout << argv[i++] << ’\n’; } cout << "\n***˽Umgebungs-Variablen:˽***\n"; i = 0; while (env[i]) { cout << env[i++] << ’\n’; } }
| 4.5.5 | Gefahren bei der Rückgabe von Zeigern |
Wie bei der Rückgabe von Referenzen (Seite 126) muss auch bei Zeigern darauf geachtet werden, dass sie nicht auf lokale Objekte verweisen, die nach dem Funktionsaufruf verschwunden sind. Das folgende Beispiel zeigt diesen Fehler.
Listing 4.28: Fehlerhafte Kopierfunktion
#include <iostream> char* murks(const char* text) { char neu[100]; // Speicherplatz besorgen char* n = neu; while (*n++ = *text++); // text wird nach neu kopiert return neu; // Fehler! } int main() { char* sp3 = murks("Oh˽je!"); std::cout << sp3; // nicht existierendes Objekt! }
Ferner soll kein Objekt per return zurückgegeben werden, das mit dem new-Operator in einer Funktion erzeugt wurde. Der Grund liegt darin, dass bei der Rückgabe mit return ein Objekt kopiert wird. Das Original wäre für ein notwendiges delete nicht mehr erreichbar. Es darf also nur der Zeiger auf ein mit new erzeugtes Objekt zurückgegeben werden, wobei der Aufrufer die Verantwortung hat, das Objekt irgendwann zu löschen. Am besten verzichtet man aber ganz auf das Verwalten von Speicher mit Zeigern, weil es unsicher und fehleranfällig ist. In den meisten Fällen sind vector oder array die bessere Alternative.
| 4.6 | this-Zeiger |
this ist ein Schlüsselwort, das innerhalb einer Elementfunktion einen Zeiger auf das Objekt darstellt. Weil this der Zeiger auf das Objekt ist, wird das Objekt selbst durch *this benannt, ganz in Analogie zu den Zeigern, die wir schon kennen: *ptr = 3; weist den Wert 3 dem Objekt zu, auf das ptr zeigt.
Ein Objekt bekommt mit der Deklaration einen Namen. Verschiedene Objekte desselben Typs haben verschiedene Namen. Der Name eines speziellen Objekts kann innerhalb einer Elementfunktion, die ja für alle Objekte dieses Typs gilt, nicht bekannt sein. Mit *this kann das Objekt dennoch innerhalb einer Elementfunktionen angesprochen werden. *this ist ein anderer Name (Alias) des Objekts für die objektinterne Nutzung.
Merke:
Innerhalb einer Methode bezeichnet this einen Zeiger auf das aktuelle Objekt und *this das Objekt selbst, für das die Methode aufgerufen wird.
Wenn Sie innerhalb einer Elementfunktion *this lesen, ist also das Objekt gemeint, für das diese Funktion aufgerufen wird. Typisch ist die Rückgabe per Referenz. Weil das Ergebnis eines Funktionsaufrufs an die Stelle des Aufrufs tritt, steht damit letztlich das Objekt selbst an der Stelle des Aufrufs, ggf. durch die Funktion verändert. Das Programm zeigt zwei Funktionen, die *this zurückgeben, und deren Anwendung.
Listing 4.29: Rückgabe von *this (cppbuch/k4/thisdemo.cpp)
#include <iostream> class ThisDemo { public: [[nodiscard]] int get() const { return wert; } // Addition von w auf das Attribut wert: ThisDemo& add(int w) // Rückgabe per Referenz! { wert += w; return *this; // Rückgabe des Objekts } // Zuweisung von td (Ersatz für =-Operator): ThisDemo& assign(const ThisDemo& td) // Rückgabe per Referenz! { wert = td.wert; return *this; } private: int wert = 0; }; int main() { ThisDemo td; td.add(1); // Rückgabewert wird ignoriert std::cout << td.get() << ’\n’; // 1 td.add(2).add(3); // *** Verkettung von Aufrufen std::cout << td.get() << ’\n’; // 6 ThisDemo a; ThisDemo b; a.assign(b.assign(td)); // entspricht a = b = td; std::cout << a.get() << ’\n’; // 6 }
Auswertung von links ...
In der mit // *** markierten Zeile wird erst td.add(2) aufgerufen. Das veränderte Objekt tritt an die Stelle des Aufrufs und für dieses Objekt wird add(3) aufgerufen. Die interne Variable wert erhält damit den Wert 6. Die zusätzlichen runden Klammern verdeutlichen die Aufrufreihenfolge: (td.add(2)).add(3);
Sie sehen, dass mit der Rückgabe von *this per Referenz eine Verkettung von Aufrufen möglich ist. Wäre die Funktion add() vom Typ void, wäre die Verkettung nicht möglich.
Ein void-Objekt gibt es nicht. Eine Rückgabe von *this als Kopie (d.h. Weglassen des &-Zeichens in der Funktionsdeklaration) funktioniert nicht, weil Änderungen an der Kopie sich im Original nicht auswirken.
... oder von rechts
Eine Verkettung von Funktionsaufrufen wird von links nach rechts abgearbeitet (linksassoziativ). Eine Zuweisung hingegen wird von rechts nach links abgearbeitet (rechtsassoziativ):
ist dasselbe wie
beziehungsweise
Der Aufruf a.assign(b); bewirkt dasselbe wie die Zuweisung a = b;. Um a = b = td; nachzubilden, ist
zu schreiben. Auch hier ist zu sehen, dass diese Art Verkettung scheitern würde, wenn assign() den Rückgabetyp void hätte. In allen Funktionen, die eine Verkettung ermöglichen sollen – und die gibt es häufig in C++ –, wird daher *this als Referenz zurückgegeben.
| 4.7 | Mehrdimensionale C-Arrays |
| 4.7.1 | Statische mehrdimensionale C-Arrays |
Empfehlung
C-Arrays haben an Bedeutung verloren. Deshalb wird empfohlen, diesen und den folgenden Abschnitt nur bei Interesse oder Bedarf zu lesen, etwa wenn Sie fremde Programme verstehen müssen, und bei Abschnitt 4.8 auf Seite 251 fortzufahren.
Gelegentlich hat man es mit mehrdimensionalen Feldern zu tun, am häufigsten mit zweidimensionalen. Eine zweidimensionale Tabelle besteht aus Zeilen und Spalten, eine dreidimensionale aus mehreren zweidimensionalen Tabellen. In C++ wird eine Tabelle linear auf den Speicher abgebildet. Im Fall der zweidimensionalen Tabelle kommen zunächst alle Elemente der ersten Zeile, dann alle Elemente der zweiten Zeile usw. Ein zweidimensionales Array ist ein Array von Arrays. Das folgende Beispiel zeigt eine statisch angelegte zweidimensionale Tabelle.
Listing 4.30: Zweidimensionale C-Matrix (cppbuch/k4/matrix2d.cpp)
#include <iostream> int main() { constexpr int zeilen{2}; constexpr int spalten{3}; int matrix[zeilen][spalten] = {{1, 2, 3}, {4, 5, 6}}; for (int i = 0; i < zeilen; ++i) { for (int j = 0; j < spalten; ++j) { std::cout << matrix[i][j] << ’˽’; } std::cout << ’\n’; } std::cout << ’\n’; // alternativ ohne Indexvariablen i,j: for (const auto& zeile : matrix) { for (auto wert : zeile) { std::cout << wert << ’˽’; } std::cout << ’\n’; } }
Ergebnis des Programmbeispiels:
Die Matrix besteht aus zwei Zeilen und drei Spalten. Die Struktur wird auch in der Initialisierungsliste deutlich. Das Weglassen der inneren geschweiften Klammern, das heißt {1,2,3,4,5,6}, hätte die gleiche Wirkung. Auch hier gilt, dass nicht aufgeführte Elemente der Liste mit 0 initialisiert werden. {{1},{4}} ist gleichbedeutend mit {{1,0,0},{4,0,0}}, also Initialisierung der ersten Spalte und Nullsetzen des Rests.
zeilen und spalten müssen zur Compilationszeit bekannt sein. Mehrdimensionale C-Arrays haben für jede Dimension ein Klammerpaar [].
In C++ darf der Zugriff auf ein Element eines mehrdimensionalen C-Arrays nicht mit einem Komma abgekürzt werden, wie es in anderen Programmiersprachen manchmal der Fall ist. Es darf nicht a[2,3] statt a[2][3] geschrieben werden. Der Compiler meldet die falsche Schreibweise nicht unbedingt, weil das Komma einen besonderen Operator darstellt und der aus semantischer Sicht falsche Ausdruck syntaktisch erlaubt sein kann.
Der Kommaoperator gibt eine Reihenfolge von links nach rechts vor. Das Ergebnis eines Ausdrucks ist das Ergebnis des Teilausdrucks nach dem letzten Komma. Im obigen Fall würde falsch a[2,3] als a[3] interpretiert werden.
| 4.7.2 | Mehrdimensionales C-Array als Funktionsparameter |
Wie funktioniert die Übergabe eines zwei- oder mehrdimensionalen C-Arrays an eine Funktion? Ein zwei- oder mehrdimensionales C-Array ist ein Array von Arrays, das heißt, hier gibt es eine zu übergebende Anzahl von Arrays (statt Werten wie im eindimensionalen Fall). Wie erfährt die Funktion von der Größe der C-Arrays? Bei C-Arrays geht ein Teil der Größeninformation mit in den Typ ein. Beispiel:
ist ein Array, das zwei Elemente enthält, nämlich zwei int[3]-Arrays zu je drei int-Werten (zwei Zeilen, drei Spalten). Der Typ der zuletzt genannten C-Arrays ist Bestandteil des Arraytyps von feld1. Dies gilt entsprechend für Zeiger:
Die Funktion zur Ausgabe dieses Felds benötigt diese Typinformation. Dass die Zahl 3 in Listing 4.31 zweimal hingeschrieben werden muss, ist weniger schön (siehe Stichwort »magic number« im Glossar), wenn auch hier nicht ohne weiteres vermeidbar.
Listing 4.31: Funktion zur Ausgabe eines zweidimensionalen C-Arrays mit drei Spalten (Auszug aus cppbuch/k4/tabellenausgabe.cpp)
void tabellenausgabe2D(int (*T)[3], int n) { // alternativ: void tabellenausgabe(int T[][3], int n) for (int i = 0; i < n; ++i) { for (int j = 0; j < 3; ++j) { std::cout << T[i][j] << ’˽’; } std::cout << ’\n’; } std::cout << ’\n’; }
Mit dieser Typinformation weiß der Compiler, wo jede Zeile anfängt. Innerhalb der Funktion ist sizeof T[0] gleich 3 mal sizeof(int). Die Funktion kann für das Array oder den Zeiger gleichermaßen aufgerufen werden:
Dieses Schema setzt sich für mehrere Dimensionen fort. Die Information [3][4] gehört zum Typ einer dreidimensionalen Matrix int Matrix3D[2][3][4]. Die Funktion zur Ausgabe dieser Matrix hat die Schnittstelle
Wie ist eine Funktion beschaffen, die für statische zweidimensionale C-Arrays geeignet ist, egal wie groß die Spaltenanzahl ist? Die Lösung ist ein Template. Der Compiler leitet dann den Feldtyp bei Aufruf der Funktion aus dem Argument ab.
Listing 4.32: Template-Funktion zur Ausgabe eines zweidimensionalen C-Arrays (Auszug aus cppbuch/k4/tabellenausgabe.cpp)
template<typename Feldtyp> void tabellenausgabe2DT(Feldtyp tabelle, int zeilen) // int (*)[3] { constexpr int spalten{sizeof tabelle[0] / sizeof tabelle[0][0]}; for (int i = 0; i < zeilen; ++i) { for (int j = 0; j < spalten; ++j) { std::cout << tabelle[i][j] << ’˽’; } std::cout << ’\n’; } std::cout << ’\n’; }
Feldtyp wird zu int (*)[3] ausgewertet, also zu einem Zeiger, der auf ein Array verweist, das aus Zeilen vom Typ int[3] besteht. Wenn nun das Array als Referenz übergeben wird, ergibt sich als Typ int[2][3]. Weil dann die Anzahl der Zeilen mit sizeof berechnet werden kann, wird der Parameter zeilen nicht mehr gebraucht:
Listing 4.33: Template-Funktion zur Ausgabe eines zweidimensionalen C-Arrays mit nur einem Parameter (Auszug aus cppbuch/k4/tabellenausgabe.cpp)
template<typename Feldtyp> void tabellenausgabe2DT(Feldtyp &tabelle) // Übergabe per Referenz { constexpr int zeilen{sizeof(Feldtyp) / sizeof(tabelle[0])}; constexpr int spalten{sizeof tabelle[0] / sizeof tabelle[0][0]}; for (int i = 0; i < zeilen; ++i) { for (int j = 0; j < spalten; ++j) { std::cout << tabelle[i][j] << ’˽’; } std::cout << ’\n’; } std::cout << ’\n’; }
Leider ist die Funktion nicht ganz typsicher. Der Indexoperator scheint sicherzustellen, dass das übergebene Objekt ein C-Array ist. Er würde aber auch für einen Vektor von Vektoren (z.B. std::vector<std::vector<int>> v{{1,2,3},{4,5,6}};) funktionieren – in dem Fall wäre aber die sizeof-Operation sinnlos und das Ergebnis wäre falsch, auch wenn der Compiler sich nicht beschwert. Mit einer etwas schlechter lesbaren Syntax lässt sich garantieren, dass nur C-Arrays übergeben werden:
Listing 4.34: Typsichere Template-Funktion zur Ausgabe eines zweidimensionalen C-Arrays (Auszug aus cppbuch/k4/tabellenausgabe.cpp)
template<typename Elementtyp, int zeilen, int spalten> void tabellenausgabe2DTx(const Elementtyp(&tabelle)[zeilen][spalten]) { for (int i = 0; i < zeilen; ++i) { for (int j = 0; j < spalten; ++j) { std::cout << tabelle[i][j] << ’˽’; } std::cout << ’\n’; } std::cout << ’\n’; } // Aufruf int main() { int feld1[][3] = {{1,2,3},{4,5,6}}; tabellenausgabe2DT(feld1, 2); tabellenausgabe2DT(feld1); tabellenausgabe2DTx(feld1); }
array/stdarrayausgabe2D.cpp und vector/stdvectorausgabe2D.cpp im Verzeichnis cppbuch/k27 zeigen die sympathischeren Lösungen auf Basis der Klassen array und vector.
Interpretation von [ ], [ ][ ] usw.
Der Compiler wandelt die Indexoperatoren mehrdimensionaler C-Arrays wie bei den eindimensionalen C-Arrays in die Zeigerdarstellung um. Wenn wir mit X alles bezeichnen, was vor dem letzten Klammerpaar steht, und mit Y den Inhalt des letzten Klammerpaars, so wird vom Compiler X[Y] in *((X)+(Y)) umgesetzt. Auf X wird das Verfahren wiederum angewendet, bis alle Indexoperatoren aufgelöst sind. Sie können daher statt matrix[i][j] ebenso *(matrix[i]+j) oder *(*(matrix+i)+j) schreiben. matrix[i] ist als Zeiger auf den Beginn der i-ten Zeile zu interpretieren. Durch die Zeigerarithmetik wird die dahinterstehende Berechnung der tatsächlichen Adresse verborgen, die ja noch die Größe der Datenelemente eines Arrays berücksichtigen muss. Die Position (matrix + i) liegt daher (i mal sizeof(matrix[0])) Bytes von der Stelle matrix entfernt. Dies wird bei der Ermittlung der Anzahl der Spalten im obigen Funktions-Template ausgenutzt.

Übungen
4.1 Auf Seite 225 wird über die Äquivalenz von *(kosten+i) und kosten[i] gesprochen. Anstatt (kosten+i) könnte man genauso gut (i+kosten) schreiben, das Ergebnis der Addition wäre das gleiche. Ist es dann richtig, dass die Schreibweise i[kosten] äquivalent ist zu kosten[i]?
4.2 Geben Sie den für matrix[2][3] benötigten Speicherplatz in Bytes an, wenn der Wert von sizeof(int) als 4 angenommen wird. An welcher Bytenummer beginnt das Element matrix[i][j] relativ zum Beginn des C-Arrays?
4.3 Schreiben Sie die Multiplikation zweier Matrizen a[n][m] * b[p][q]. Das Ergebnis soll in einer Matrix c[r][s] stehen. Welche Voraussetzungen gelten für die Zeilen- und Spaltenzahlen n, m, p, q, r, s?
| 4.8 | Dynamisches 2D-Array |
Man kann mehrdimensionale C-Arrays dynamisch erzeugen. Praktikabler sind allerdings C-Arrays, die in einer Klasse gekapselt werden, Thema dieses Abschnitts. Es geht darum, ein zweidimensionales Array zu konstruieren, dessen Größe zur Laufzeit, also dynamisch, festgelegt werden kann. Wer professionell mit zwei- oder mehrdimensionalen Arrays (Matrizen) arbeiten möchte, sieht sich am besten entsprechende Bibliotheken an, z.B. Boost. C++ bietet selbst eine Klasse valarray (Header <valarray), die zur Konstruktion von Matrizen geeignet ist. Sie hat sich aber nicht durchsetzen können und wird in diesem Buch daher nicht behandelt. Eine kurze Einführung nebst Beispielen finden Interessierte im Verzeichnis cppbuch/k4/valarrays.
Jedes Mal Speicher zuzuweisen und für ein korrektes delete zu sorgen, ist umständlich. Hier wird gezeigt, wie diese Vorgänge in einer Klasse gekapselt werden, wobei Objekte dieser Klasse ohne Performance-Verlust benutzt werden können, so wie hier gezeigt:
Listing 4.35: Anwendung für Array2d (cppbuch/k4/array2d/main.cpp)
#include "Array2d.h" // Klasse Array2d #include <iostream> using namespace std; int main() { Array2d<int> arr(5, 7); arr.init(0); printArray(arr); // Ausgabe mit Hilfsfunktion for (int z = 0; z < arr.getZeilen(); ++z) { for (int s = 0; s < arr.getSpalten(); ++s) { arr.at(z, s) = 10 * z + s; // Benutzung, schreibend und ... cout << arr.at(z, s) << "˽"; // lesend (siehe Text) } cout << ’\n’; } printArray(arr); Array2d<int> arr1(arr); // Kopierkonstruktor printArray(arr1); arr1.init(3); // Neuinitialisierung arr.assign(arr1); // Zuweisung printArray(arr); Array2d<double> arrd(3, 4, 99.013); // double-Array printArray(arrd); Array2d<string> arrs(2, 5, "hello"); // string-Array printArray(arrs); }
Wie zu sehen, dürfen die Array-Elemente nicht nur int- oder double-Zahlen sein, sondern auch Strings. In der Datei cppbuch/k4/array2d/Array2d.h übernimmt der Konstruktor die Speicherallokation, der Destruktor sorgt für die Freigabe.
Warum hier new und delete?
Intern einen vector<T> zum Abspeichern der Daten zu verwenden, wäre einfacher, anstatt den Speicher mit new und delete zu verwalten. Kopierkonstruktor, Zuweisungsmethode und Destruktor könnten eingespart werden. Es geht in diesem Kapitel aber gerade darum, die Kapselung von new und delete in einer Klasse zu zeigen. Wie new und delete vermieden werden, zeigt die String-Klasse des nächsten Kapitels 5. Eine Klasse für ein zweidimensionales Array ohne eigene Speicherverwaltung finden Sie in Abschnitt 8.10.2.
Weil das Überladen von Operatoren erst in Kapitel 8 behandelt wird, gibt es hier noch einige Einschränkungen:
Anstelle der Schreibweise arr = arr1; für die Zuweisung wird arr.assign(arr1); geschrieben.
Der Zugriff auf ein Array-Element über den Indexoperator wird durch einen Funktionsaufruf ersetzt, also etwa arr.at(z, s) statt arr[z][s].
Entwurfsüberlegungen
Da der schreibende Funktionsaufruf auf der linken Seite der Zuweisung steht, ergibt sich, dass er eine Referenz auf das zu ändernde Array-Element zurückgeben muss. Bei dem lesenden Funktionsaufruf, der das Array-Objekt arr nicht ändert, genügt eine Kopie des Werts oder eine const-Referenz. Falls das Array innerhalb der Klasse als C-Array von C-Arrays konstruiert wird, also etwa mit auto ptr = new int [zeilen][spalten], könnte at(i,j) wie folgt realisiert werden, wobei T der Typ der Array-Elemente und ptr der Zeiger auf den Beginn des internen Arrays ist:
Konstruktor und Destruktor wären wegen der Schleifen etwas umständlich. Aus diesem Grund kann die Beschaffung des Speichers als ein Block erwogen werden, zum Beispiel T* ptr = new T[zeilen*spalten];. ptr wäre dann vom Typ T* und nicht mehr T**. Im Destruktor genügte ein einziges delete []. Das bedeutet allerdings, dass ein Zugriff wie ptr[z][s] nicht möglich ist. Die Adresse müsste anders berechnet werden – wie, das zeigt die Lösung der Aufgabe 4.2 von Seite 250. Damit wird die Funktion at() wie folgt realisiert (spalten ist die Anzahl der Spalten):
Der Compiler würde im ersten Fall ptr[z][s] in *(*(ptr+z)+s) umwandeln, wie auf Seite 250 erläutert. Weil Konstruktor und Destruktor einfacher werden und die Berechnung der Adresse etwa ebenso schnell ist wie die Berechnung von *(*(ptr+z)+s), wird der zweiten Variante, also der Beschaffung des Speichers in einem einzigen Schritt, der Vorzug gegeben. Das Listing 4.36 zeigt die dazu passende Klasse. Der Zuweisungsoperator wird darin verboten. Das Verbot verhindert, dass arr = arr1; geschrieben werden kann. Der ansonsten systemgenerierte Zuweisungsoperator würde den Zeiger ptr kopieren, also eine flache Kopie erzeugen. Dann würde der Destruktor beim Original und der Kopie auf denselben Speicherbereich wirken – ein schwerer Fehler.
Listing 4.36: Klasse Array2d mit zusammenhängendem Memory-Bereich (cppbuch/k4/array2d/Array2d.h)
#ifndef ARRAY2D_H #define ARRAY2D_H #include <cassert> #include <iostream> template <typename T> class Array2d { public: Array2d(int z, int s) : zeilen{z}, spalten{s}, ptr{new T[z * s]} {} Array2d(int z, int s, const T& wert) : Array2d(z, s) // an obigen Konstruktor delegieren { init(wert); } Array2d(const Array2d& a) : Array2d(a.zeilen, a.spalten) // an obigen Konstruktor delegieren { int anzahl = zeilen * spalten; for (int i = 0; i < anzahl; ++i) { ptr[i] = a.ptr[i]; } } ~Array2d() { delete[] ptr; } Array2d& operator=(const Array2d& arr) = delete; // (noch) verbieten auto& assign(Array2d tmp) { swap(tmp); return *this; } [[nodiscard]] auto getZeilen() const { return zeilen; } [[nodiscard]] auto getSpalten() const { return spalten; } void init(const T& wert) // Alle Elemente mit wert initialisieren { int anzahl = zeilen * spalten; for (int i = 0; i < anzahl; ++i) { ptr[i] = wert; } } const T& at(int z, int s) const // für lesenden Zugriff { assert(z < zeilen && s < spalten); return ptr[z * spalten + s]; } T& at(int z, int s) // für verändernden Zugriff { assert(z < zeilen && s < spalten); return ptr[z * spalten + s]; } void swap(Array2d& rhs) // Daten von *this mit denen von rhs vertauschen { int temp = zeilen; zeilen = rhs.zeilen; rhs.zeilen = temp; temp = spalten; spalten = rhs.spalten; rhs.spalten = temp; T* tempPtr = ptr; ptr = rhs.ptr; rhs.ptr = tempPtr; } private: int zeilen; int spalten; T* ptr; }; template <typename T> void printArray(const Array2d<T>& a) // Freie Funktion zur Ausgabe { for (int z = 0; z < a.getZeilen(); ++z) { for (int s = 0; s < a.getSpalten(); ++s) { std::cout << a.at(z, s) << "˽"; } std::cout << ’\n’; } } #endif
Der obige Kopierkonstruktor benutzt indirekt new zur Speicherbeschaffung. Indirekt, weil er diese Aufgabe an den Konstruktor delegiert. Die Verwendung von new begründet die Notwendigkeit eines eigenen Kopierkonstruktors für die Klasse. Der bei Abwesenheit dieses Konstruktors durch das System erzeugte Kopierkonstruktor würde nur die Länge und den Zeiger kopieren, nicht aber ein echtes Duplikat erzeugen! Es wird nur eine sogenannte »flache« Kopie (englisch shallow copy) erzeugt. Die Datenbereiche (wie Arrays, Strings oder andere Objekte), auf die die Zeiger verweisen, werden nicht kopiert. Gebraucht wird aber eine »tiefe« Kopie (englisch deep copy). Der Unterschied wird in Abbildung 4.12 sichtbar.

Der obige Kopierkonstruktor erzeugt also eine »tiefe Kopie«. Vergleichen Sie dazu den Abschnitt »C-Strings kopieren« auf Seite 231. Dieselbe Problematik tritt natürlich auch bei Zuweisungen auf (siehe assign()-Methode unten).
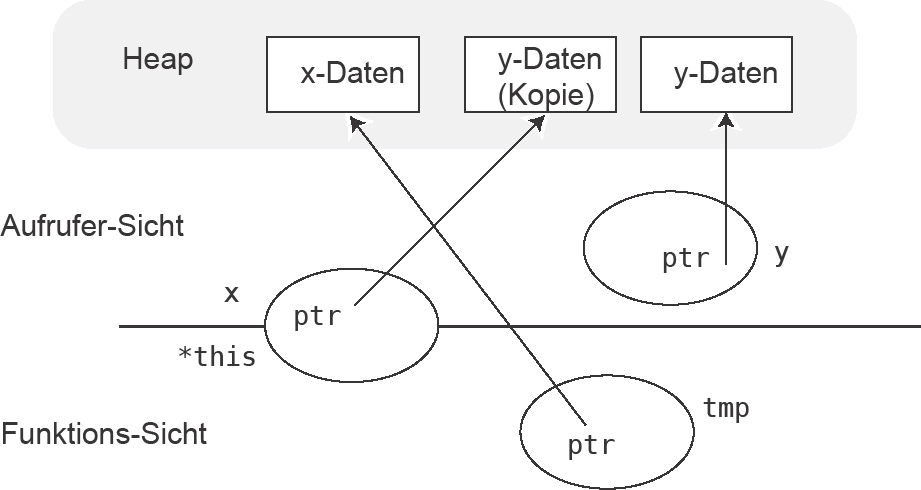
Es gibt verschiedene Möglichkeiten für die Bedeutung einer Kopie: Es ist ein Unterschied, ob nach einer Zuweisung a = b; das Objekt a einen Zeiger enthält, der auf denselben Speicherbereich wie der entsprechende Zeiger des Objekts b zeigt (Referenzsemantik, Abbildung 4.12 links), oder ob der Zeiger von a auf ein neu erzeugtes Duplikat des Speicherbereichs verweist (Wertsemantik, siehe Abbildung 4.12 rechts). Wie der Zuweisungsoperator korrekt realisiert werden kann, erfahren Sie in Kapitel 8. In der Funktion assign(arr) müsste der Ablauf die folgenden Schritte umfassen: 1. Speicher beschaffen, 2. Werte kopieren, 3. alten Speicher freigeben, 4. Verwaltungsdaten aktualisieren.
Zu den ersten beiden Schritten findet sich Code im Kopierkonstruktor, zum dritten Schritt im Destruktor. Um eine Codeduplikation zu vermeiden, wird in assign() eine lokale Kopie durch die Übergabe des Parameters per Wert angelegt. Durch die lokale Kopie statt einer Referenz wird erreicht, dass sie ohne Auswirkung auf das Original verändert werden kann. Die Funktion swap() sorgt für die Vertauschung der Objektinhalte (es gibt auch eine swap()-Bibliotheksfunktion, dazu später). Danach hat *this den Inhalt von arr (= Sinn der Zuweisung) und arr den von *this. Letzteres wird zurückgegeben, und der Destruktor von tmp sorgt für die Speicherfreigabe.
Regel der großen Drei
Wenn auch nur eine der drei Funktionen Kopierkonstruktor, Destruktor und Zuweisung geschrieben wird, sollen die beiden anderen auch deklariert werden (Regel der »großen Drei«)! Wenn z.B. für eine Klasse X ein eigener Destruktor ~X() existiert und der Kopierkonstruktor sich wie ein systemgenerierter verhalten soll, ist zu schreiben:
Wenn Objekte ausschließlich per Referenz übergeben werden sollen, eine Kopie also zu verhindern ist, schreibt man
Wenn die zu ergänzenden Funktionen fehlen, werden sie vom Compiler ergänzt – aber vielleicht nicht mehr in zukünftigen C++-Varianten. Die zu ergänzenden Funktionen wegzulassen wird daher nicht empfohlen. In Kapitel 11 wird die Regel auf »die großen Fünf« erweitert.
Die Abbildungen 4.13 bis 4.15 zeigen die Schritte für eine hypothetische Anweisung x.assign(y);. Die Ellipsen stehen für die Array2d-Objekte. Das Objekt x kann innerhalb der Funktion mit *this angesprochen werden. Nach dieser Anweisung gilt x == y.

| 4.9 | Binäre Ein-/Ausgabe |
Im Gegensatz zur formatierten Ein-/Ausgabe mit den Operatoren << und >> ist der binäre Datentransfer unformatiert. Unformatiert heißt, dass die Daten in der internen Darstellung direkt geschrieben beziehungsweise gelesen werden, eine Umwandlung zum Beispiel einer float-Zahl in eine Folge von ASCII-Ziffernzeichen also unterbleibt. Auf diese Art beschriebene Dateien können nicht sinnvoll mit einem Texteditor bearbeitet oder direkt ausgedruckt werden. Die zum binären Datentransfer geeigneten Funktionen in C++ sind read() und write().
Das Prinzip: Es wird ein Zeiger auf den Beginn des Datenbereichs angegeben, also die Adresse des Bereichs. Dabei wird der Zeiger in den Datentyp char* umgewandelt. write() verlangt an dieser Stelle char*, weil ein char einem Byte entspricht. Zusätzlich wird die Anzahl der zu transferierenden Bytes angegeben. Zur Wandlung des Zeigers wird der reinterpret_cast-Operator verwendet. Dieser Operator verzichtet im Gegensatz zum static_cast-Operator auf jegliche Verträglichkeitsprüfung, weil hier Zeiger auf beliebige, das heißt auch selbst geschriebene Datentypen in den Typ char* umgewandelt werden sollen.
Das Beispiel zeigt das unformatierte Schreiben und Lesen von double-Zahlen als Vorlage für eigene Versuche. Der Dateiname wurde nur deswegen fest vorgegeben, um die Programme nicht so lang werden zu lassen. Das Schema lässt sich sinngemäß auf beliebige Datentypen und Mengen übertragen. Die for-Schleife im ersten Beispielprogramm zeigt eine typische Anwendung des Kommaoperators. Die zu schreibenden Zahlen werden nur als Beispiel nach der Vorschrift 1.1i, i = 0..19 berechnet.
Listing 4.37: Schreiben einer binären Datei (cppbuch/k4/wdouble.cpp)
#include <fstream> #include <iostream> using namespace std; // Erzeugen einer Datei double.dat mit 20 double-Zahlen int main() { ofstream ziel("double.dat", ios::binary); if (!ziel) { cerr << "Datei˽kann˽nicht˽geöffnet˽werden!\n"; return -1; // Fehler } double d {1.0}; for (int i = 0; i < 20; ++i, d *= 1.1) { // Schreiben von 20 Zahlen ziel.write(reinterpret_cast<const char*>(&d), sizeof(d)); } } // ziel.close() wird vom Destruktor durchgeführt
Listing 4.38: Lesen einer binären Datei (cppbuch/k4/rdouble.cpp)
#include <fstream> #include <iostream> using namespace std; // Lesen einer Datei double.dat mit double-Zahlen int main() { ifstream quelle("double.dat", ios::binary); if (!quelle) { // muss existieren cerr << "Datei˽kann˽nicht˽geöffnet˽werden!\n"; return -1; // Fehler } double d {0.0}; while (quelle.read(reinterpret_cast<char*>(&d), sizeof(d))) { // lesen cout << "˽˽" << d << ’\n’; } } // quelle.close() wird vom Destruktor durchgeführt
Im Listing 4.38 wird beim Lesen die Variable d verändert. Deswegen fehlt im Vergleich zum ersten Programm das const in der Typumwandlung.
ASCII oder binär?
Um den Unterschied zu verdeutlichen, folgt ein Beispiel, in dem eine Matrix einmal als ASCII-Datei und einmal als binäre Datei ausgegeben wird. Die Merkmale der Dateitypen sind im Wesentlichen:
ASCII-Datei
ASCII-Dateien sind mit einem Texteditor lesbar.
Schreiben und Lesen von ASCII-Dateien mit einem Programm dauert im Allgemeinen länger als binäres Schreiben oder Lesen von binären Dateien, weil implizit Umformatierungen vom internen Format nach ASCII (oder umgekehrt) vorgenommen werden.
Anstelle der Funktionen get() und put() für zeichenweise Verarbeitung können auch die Operatoren >> und << zur Ein- und Ausgabe verwendet werden. In der Anwendung besteht kein Unterschied zur Standardein- und -ausgabe.
Die Dateigröße bestimmt sich aus der Anzahl der ausgegebenen Zeichen und hängt damit von der Formatierung ab. Die Ausgabe soll so formatiert sein, dass ein problemloses Einlesen möglich ist, zum Beispiel durch Angabe einer genügenden Ausgabeweite oder Einfügen von Leerzeichen zur Trennung.
Durch die Formatierung kann es zu Wertänderungen kommen, zum Beispiel durch Abschneiden von Nachkommastellen.
Das Listing 4.39 zeigt, wie ein zweidimensionales C-Array als lesbare Datei matrix.asc und als binäre Datei matrix.bin geschrieben wird.
Listing 4.39: Dateiausgabe eines zweidimensionalen C-Arrays (cppbuch/k4/wmatrix.cpp)
#include <fstream> #include <iostream> using namespace std; int main() { constexpr int zeilen{10}; constexpr int spalten{8}; double matrix[zeilen][spalten]; for (int i = 0; i < zeilen; ++i) // Matrix mit (beliebigen) Werten füllen for (int j = 0; j < spalten; ++j) matrix[i][j] = i + 1 + (j + 1) / 1000.0; // Schreiben als ASCII-Datei (lesbar mit Editor) ofstream ziel("matrix.asc"); if (!ziel) { cerr << "Datei˽kann˽nicht˽geöffnet˽werden!\n"; return -1; // Fehler } // formatiertes Schreiben for (int i = 0; i < zeilen; ++i) { for (int j = 0; j < spalten; ++j) { ziel.width(8); // Breite 8 Zeichen ziel << matrix[i][j]; } ziel << ’\n’; } ziel.close(); // Datei schließen, damit ziel wiederverwendet werden kann: // Schreiben als binäre Datei ziel.open("matrix.bin", ios::binary); if (!ziel) { cerr << "Datei˽kann˽nicht˽geöffnet˽werden!\n"; exit(-1); } ziel.write(reinterpret_cast<const char*>(matrix), sizeof(matrix)); } // automatisches close()
Das Einlesen binärer Daten in eine C-Matrix geht dementsprechend mit read():
Dabei ist quelle das ifstream-Objekt (einzulesende Binärdatei) und daten ist ein C-Array, das die Daten aufnimmt. Es muss natürlich groß genug sein.
Binärdatei
Binärdateien sind nicht mit einem Texteditor lesbar und auch nicht druckbar.
Schreiben und Lesen von Binärdateien sind schnell, weil Umformatierungen nicht notwendig sind. Voraussetzung des korrekten Lesens ist, dass das lesende Programm die Struktur der geschriebenen Daten kennt.
Die Dateigröße bestimmt sich aus der Größe und Anzahl der ausgegebenen Daten und hat nichts mit ihrer ASCII-Darstellung zu tun, die je nach Formatierung auf verschiedene Art möglich ist. Im Programm oben ist die Dateigröße in Bytes gleich der Matrixgröße sizeof(double)·(Anzahl der Zeilen)·(Anzahl der Spalten).
Große Dateistrukturen können ohne Benutzung von Schleifen mit einer einzigen Anweisung ausgegeben werden (matrix im Beispiel).
Zwar können auch Zeiger in eine Datei geschrieben werden, sie sind aber nach dem Wiedereinlesen nicht mehr nutzbar.
| 4.10 | Zeiger auf Funktionen |
Zeiger auf Funktionen ermöglichen es, erst zur Laufzeit zu bestimmen, welche Funktion ausgeführt werden soll (englisch late binding, dynamic binding). Im Beispielprogramm wird entweder das Maximum oder das Minimum der Zahlen 1700 und 1000 ausgegeben. Welche Funktion tatsächlich gewählt wird, entscheidet sich erst zur Laufzeit, sodass zur Compilationszeit nicht bekannt sein kann, ob mit (*fp)(a,b) im Beispielprogramm max() oder min() aufgerufen wird.
Zur Deklaration: fp ist ein Zeiger auf eine Funktion, die einen int-Wert zurückgibt und zwei int-Parameter verlangt. Dabei ist (*fp) statt *fp notwendig, um eine Verwechslung mit einer Funktionsdeklaration int *fp(int, int) zu vermeiden.
Zeiger auf Funktionen können wie andere Variablen anderen Funktionen als Parameter übergeben werden. Zum Beispiel kann einer Funktion, die mathematische Graphen zeichnet, wahlweise ein Zeiger auf die Sinus-Funktion oder auf eine Hyperbel-Funktion übergeben werden. Das folgende Beispiel zeigt, wie wir eine vordefinierte Funktion mithilfe von Zeigern auf Funktionen nutzen.
Listing 4.40: Funktionszeiger (cppbuch/k4/funkptr.cpp)
#include <iostream> using namespace std; // Funktionen, auf die ein Zeiger gerichtet wird: [[nodiscard]] int min(int x, int y) { return y < x ? y : x; } [[nodiscard]] int max(int x, int y) { return y < x ? x : y; } int main() { int a {1700}; int b {1000}; int (*fp)(int, int){nullptr}; // fp ist Zeiger auf eine Funktion do { char c {’x’}; cout << "max˽(1)˽oder˽min˽(0)˽ausgeben˽(andere˽Zahl˽=˽Ende)˽?"; cin >> c; // Zuweisung von max() oder min() (ohne Angabe von Klammern nach dem Funktionsnamen) switch (c) { case ’0’: fp = &::min; // Funktionsadresse zuweisen break; // :: bedeutet: die obige globale Funktion nehmen // Damit wird die Verwechslung mit der Standardfunktion std::min() // verhindert, falls später mal der Header <algorithm> eingebunden werden sollte. // Ohne den Adressoperator & wandelt der Compiler den // Funktionsnamen automatisch in die Adresse um: case ’1’: fp = ::max; break; default: fp = nullptr; } if (fp) { // d.h if (fp != nullptr) // Dereferenzierung des Funktionszeigers und Aufruf cout << (*fp)(a, b) << ’\n’; // oder auch direkte Verwendung des Namens (implizite Typumwandlung) cout << fp(a, b) << ’\n’; } } while (fp); }
Wenn wir ein C-Array sortieren wollen, müssen wir keine eigene Funktion schreiben, sondern können die Funktion qsort() verwenden, die in jedem C++-System vorhanden und deren Prototyp im Header <cstdlib> deklariert ist. Die hier vorgestellte Bibliotheksfunktion qsort() stellt die Allgemeinheit der Funktion über ihre Realisierung mit Zeigern auf void her.
Hinweis
Hier geht es um die Wirkungsweise von Funktionszeigern, nicht um das Sortieren. Wenn sortiert werden soll, wird am besten die Funktion std::sort() benutzt, die an anderer Stelle beschrieben wird (Abschnitt 23.4.2).
Der letzte Parameter ist ein Zeiger auf eine Funktion, die einen int-Wert zurückgibt und zwei Zeiger auf const void als Parameter verlangt, hier a und b genannt. Der Name cmp steht für »compare« und ist hier nur zu Dokumentationszwecken vorhanden; er kann auch weggelassen werden. qsort() soll als Standardfunktion für beliebige Arrays geeignet sein, daher der Datentyp void*. Die Funktion mit dem Platzhalternamen cmp ist von uns zu schreiben. Sie hat die Aufgabe, zu entscheiden, welches von den beiden Arrayelementen, auf die die Zeiger a und b zeigen, größer ist. Als Ergebnis für eine aufsteigende Sortierung wird verlangt, dass ein Wert kleiner 0 zurückgegeben wird, falls *a < *b ist, ein Wert größer 0, falls *a > *b ist, und 0 bei *a == *b. Bei absteigender Sortierung sind die Vorzeichen zu vertauschen. Die Funktion zum Vergleich und ihr Aufruf sind unten am Beispiel des Sortierens eines int-Felds beschrieben. Die Schnittstelle muss zu qsort() passen, deshalb wird in der Funktion eine Typumwandlung vorgenommen. Dies geschieht dadurch, dass der Zeiger auf void in einen Zeiger auf int umgewandelt wird, über den durch Dereferenzierung (*) die zu vergleichenden Zahlenwerte ia und ib gewonnen werden. Ein Umweg der Art
ist nicht notwendig; der Name der Funktion icmp kann direkt eingesetzt werden. Die Bedeutung der Parameterliste im Aufruf ergibt sich durch Vergleich mit dem oben angegebenen Prototypen. Den Quellcode von qsort() kennen wir nicht und brauchen ihn auch nicht zu kennen, um qsort() benutzen zu können. Es genügt ausschließlich die Kenntnis der Schnittstelle und natürlich die Kenntnis dessen, was qsort() tut. Wie in qsort() die Funktion icmp angesprochen wird, ist letztlich nicht wichtig zu wissen und wird hier nur zur Erläuterung beschrieben. Innerhalb von qsort() steht an irgendeiner Stelle etwa sinngemäß (wobei die Namen im uns unbekannten tatsächlichen Quellcode natürlich ganz anders lauten können):
Durch die Übergabe des Funktionszeigers »weiß« qsort(), welche Funktion zu nehmen ist, ganz in Analogie zum oben aufgeführten min-max-Beispiel. Dieser Mechanismus wird callback genannt und immer dann eingesetzt, wenn ein Server eine Dienstleistung erbringen soll und dazu eine Funktion oder Methode des Clients benötigt, die er nicht automatisch zur Verfügung hat. Der Server ist in diesem Fall die Funktion qsort(), die die Dienstleistung (= das Sortieren) nur erbringen kann, wenn der Client mitteilt, wie die Objekte zu vergleichen sind. Der Server kann dann die ihm (hier über einen Funktionszeiger) mitgeteilte Funktion aufrufen (= callback), ohne ihre Details zu kennen.
Listing 4.41: Quicksort und Funktionszeiger (cppbuch/k4/qsort.cpp)
#include <cstdlib> // qsort() #include <cstring> #include <iostream> using namespace std; // Definition der Vergleichsfunktion: [[nodiscard]] int icmp(const void* a, const void* b) { // Typumwandlung der Zeiger auf void in Zeiger auf int und anschließende Dereferenzierung // (von rechts lesen). Die Typumwandlung meint, dass die Speicherinhalte, auf die a bzw. // b verweisen, als int zu interpretieren sind. int ia {*static_cast<const int*>(a)}; int ib {*static_cast<const int*>(b)}; // Vergleich und Ergebnisrückgabe ( > 0, = 0 oder < 0) if (ia == ib) { return 0; } return ia > ib ? 1 : -1; } int main() { int ifeld[]{100, 22, 3, 44, 6, 9, 2, 1, 8, 9}; constexpr int anzahlElemente{size(ifeld)}; qsort(ifeld, anzahlElemente, sizeof(ifeld[0]), icmp); // sortieren for (int i : ifeld) { // Ausgabe cout << "˽" << i; } cout << ’\n’; }
Übungen
4.4 Schreiben Sie eine Funktion strcopy(char* ziel, const char* quelle). Sie soll den Rückgabetyp void haben und den Inhalt des C-Strings quelle in den C-String ziel kopieren, wobei der vorherige Inhalt von ziel überschrieben wird. Es sei vorausgesetzt, dass ziel ausreichend groß ist, um quelle aufzunehmen.
4.5 Schreiben Sie eine Funktion char* strduplikat(const char* s), die den C-String s dupliziert, indem neuer Speicherplatz mit new beschafft und s mit der Funktion strncpy() in diesen Bereich hineinkopiert wird. Ein Zeiger auf den Beginn des Duplikats soll zurückgegeben werden.
4.6 Auf Seite 262 wurde gezeigt, wie Quicksort auf ein Ganzzahlen-Feld angewendet werden kann. Gegeben sei nun ein alphabetisch zu sortierendes C-String-Array.
Schreiben Sie ein Programm, das dieses Array mit qsort() sortiert. Wie sieht die benötigte Vergleichsfunktion aus, die hier scmp() genannt sei? Wie ist qsort() aufzurufen?
Hinweise:
a) Diese Aufgabe ist nur für diejenigen, die ihr Wissen über den Einsatz von Funktionszeigern bei einer C-Bibliotheksfunktion vertiefen möchten – C ist schließlich eine Untermenge von C++. Die anderen benutzen besser std::sort(). Ein Beispiel für die Alternative mit std::sort(): cppbuch/loesungen/k4/6alternativ.cpp
b) Innerhalb von scmp() kann strcmp() aus <cstring> benutzt werden. strcmp(a,b) gibt eine Zahl kleiner 0 zurück, falls C-String a < C-String b ist, größer 0, falls a > b ist, und 0 bei Gleichheit.
4.7 Schreiben Sie eine Funktion void leerzeichenEntfernen(char* s), die alle Leerzeichen im C-String entfernt. Zum Beispiel soll aus »a bb ccc d« die Zeichenkette »abbcccd« werden. Verwenden Sie dabei Zeiger und denken Sie daran, dass ein C-String mit ’\0’ abschließt.
4.8 Schreiben Sie ein Programm, das Dateien, deren Namen in der Kommandozeile angegeben werden, auf der Standardausgabe ausgibt. Zum Beispiel könnte der Befehl
dazu führen, dass die Dateien datei1.cpp und datei2.cpp auf dem Bildschirm angezeigt werden. Wenn eine Datei nicht vorhanden ist, soll es eine Fehlermeldung »Datei (Dateiname) nicht gefunden!« geben.
4.9 Schreiben Sie ein Programm, das alle in einer Datei vorkommenden Namen ausgibt. Ein Name ist dabei so definiert: Er beginnt mit einem Buchstaben, anschließend folgen beliebig viele Buchstaben und Ziffern. Der Unterstrich zählt auch als Buchstabe.
| 4.11 | Typumwandlungen für Zeiger |
Die Typumwandlungen dieses Abschnitts gelten nicht für die im folgenden Abschnitt 4.12 beschriebenen Zeiger auf Elementfunktionen und -daten.
nullptr kann zu einem Null-Zeiger auf ein Objekt eines beliebigen Typs T konvertiert werden: T* ptr = nullptr;
Integer-Literale mit dem Wert 0 können zu einem Zeiger auf ein Objekt eines beliebigen Typs T konvertiert werden: T* ptr = 0; (Null-Zeiger)
Jeder Zeiger ist nach bool konvertierbar. Dabei wird ein Null-Zeiger stets zu false und ein anderer Zeiger stets zu true ausgewertet.
Jeder Zeiger auf ein Objekt eines beliebigen Typs T kann in einen Zeiger auf void konvertiert werden:
Jeder Zeiger auf ein Objekt einer Klasse B kann in einen Zeiger auf Klasse A umgewandelt werden, wenn A eine Oberklasse von B ist und (bei Mehrfachvererbung) eindeutig ermittelt werden kann (die Begriffe Oberklasse und Vererbung werden in Kapitel 6 erläutert).
Arrays können zu Zeigern konvertiert werden. Beispiel:
Funktionszeiger
Eine Funktion kann in einen Zeiger auf eine Funktion oder umgekehrt umgewandelt werden. Ein Beispiel verdeutlicht die beiden Fälle:
Listing 4.42: Typumwandlung Funktion ↔ Funktionszeiger (cppbuch/k4/funkptr2.cpp)
#include <iostream> void drucke(int x) { std::cout << x << ’\n’; } // Funktion int main() { void (*f1)(int){&drucke}; // keine Umwandlung void (*f2)(int){drucke}; // Funktion → Zeiger f1(1); // Zeiger → Funktion (*f1)(13); // explizit: Zeiger→ Funktion (*f2)(23); // explizit: Zeiger→ Funktion }
Bei der Deklaration der Funktion drucke() und der Funktionszeiger f1 und f2 kann auto statt void geschrieben werden.
| 4.12 | Zeiger auf Elementfunktionen und -daten2 |
C++ erlaubt es, Zeiger auf Elementdaten (englisch data members) und -funktionen (englisch member functions) zu richten. Deklaration und Zugriff auf Elemente werden mit den Operatoren ::*, .* und ->* bewerkstelligt. Diese Zeiger unterliegen einer Typprüfung durch den Compiler, die die Klassenzugehörigkeit berücksichtigt, im Unterschied zu den Zeigern auf freie Funktionen. Eine große Flexibilität wird erreicht, weil Zeiger zur Laufzeit auf verschiedene Elementfunktionen (bzw. Attribute) gerichtet werden können. Diese Zeiger können wiederum mit Zeigern kombiniert werden, die zur Laufzeit auf verschiedene Objekte verweisen.
Zeiger auf Elementfunktionen
Die von Seite 187 bekannte Klasse Ort hat einige Elementfunktionen, auf die im folgenden Beispielprogramm über Zeiger zugegriffen wird. Bei der Initialisierung von Zeigern auf nicht-statische Elementfunktionen und -daten darf im Gegensatz zu Zeigern auf andere Funktionen (siehe Beispiel auf Seite 260) der Adressoperator & nicht weggelassen werden.
Listing 4.43: Zeiger auf Elementfunktionen (cppbuch/k4/elfunptr.cpp)
#include <Ort.h> // in cppbuch/include int main() { Ort einOrt(100, 200); int (Ort::*fp)() const {&Ort::getX}; // Zeiger auf Ort::getX() richten std::cout << (einOrt.*fp)() << ’\n’; // dasselbe wie einOrt.getX() fp = &Ort::getY; // Funktionszeiger umschalten std::cout << (einOrt.*fp)() << ’\n’; // jetzt dasselbe wie einOrt.getY() Ort* derZeiger = new Ort(300, 400); std::cout << (derZeiger->*fp)() << ’\n’; // dasselbe wie derZeiger->getY() void (Ort::*fpAendern)(int, int){&Ort::aendern}; (derZeiger->*fpAendern)(500, 600); // d.h. derZeiger->aendern(500, 600) anzeigen(*derZeiger); // geänderter Ort delete derZeiger; }
Zeiger auf Elementdaten
Sicher kommt es kaum vor, dass auf Elementdaten über Zeiger zugegriffen werden soll, weil Attribute in der Regel privat sind. Das folgende Beispielprogramm zeigt, wie der Zugriff bei öffentlichen Attributen möglich ist. Es ist dabei zu sehen, dass das Umschalten auf ein neues Objekt nicht die Zuordnung zum Attribut b zerstört.
Listing 4.44: Zeiger auf Elementdaten (cppbuch/k4/eldatptr.cpp)
#include <iostream> struct Datensatz { // öffentliche Klasse Datensatz(int x, int y) : a{x}, b{y} { } int a; int b; }; int main() { Datensatz einDatensatz(1, 2); int Datensatz::*dp{&Datensatz::a}; // Zeiger auf Elementattribut std::cout << einDatensatz.*dp << ’\n’; // 1 dp = &Datensatz::b; // Zeiger umschalten std::cout << einDatensatz.*dp << ’\n’; // 2 // neues Objekt erzeugen Datensatz* dPtr{new Datensatz(1000, 2000)}; std::cout << dPtr->*dp << ’\n’; // 2000 delete dPtr; }
| 4.13 | Komplexe Deklarationen lesen |
Komplexe Deklarationen sind manchmal schwer zu lesen. Es gibt dafür ein Rezept, das hier etwas vereinfacht dargestellt wird: Man löst die Deklaration vom Namen her auf und schaut dann nach rechts und links in Abhängigkeit vom Vorrang der Syntaxelemente. Beginnend bei den wichtigen Elementen ist die Reihenfolge (nach [vdL]):
runde Klammern ( ), die Teile der Deklaration zusammenfassen (gruppieren);
runde Klammern ( ), die eine Funktion anzeigen;
eckige Klammern [ ], die ein Array anzeigen;
Sternsymbol *, das »Zeiger auf« bedeutet.
Beispiel:
Name: seltsam
Klammer: Die Klammer dient zur Gruppierung, das nächste Zeichen ist daher *.
*: seltsam ist ein Zeiger. Nun haben wir die Auswahl zwischen einer Funktion (Klammer rechts) oder einem Zeiger (Sternchen links). Die Klammer hat Vorrang.
(double, int): seltsam ist ein Zeiger auf eine Funktion, die über einen double- und einen int-Parameter verfügt.
Klammer: Die Klammer dient zur Gruppierung, das nächste Zeichen ist *. Die Funktion gibt also einen Zeiger zurück.
eckige Klammer: Vorrang gegenüber *. Der Zeiger zeigt auf ein Array mit 3 Elementen, *, links: die Zeiger auf const char sind.
Zusammengefasst: seltsam ist ein Zeiger auf eine Funktion mit einem double- und einem int-Parameter, die einen Zeiger auf ein Array von Zeigern auf const char zurückgibt. Ein weiteres Beispiel: int** was[2][3];: was ist ein Array von Arrays (= zweidimensionales Array), dessen Elemente Zeiger auf Zeiger auf int sind. Eine gut lesbare und ausführliche Behandlung des Themas ist in [vdL] zu finden.
| 4.13.1 | Lesbarkeit mit typedef und using verbessern |
Komplizierte Deklarationen sollen der schlechten Lesbarkeit wegen vermieden werden. Manchmal sind sie jedoch unumgänglich. Für diesen Fall bieten die Schlüsselwörter typedef und using die Möglichkeit, die Lesbarkeit durch neue Namen zu verbessern. Betrachten wir zunächst ein einfaches Beispiel: In einem Programm wollen wir die Unterschiede in der Genauigkeit der Ergebnisse je nach Datentyp float oder double untersuchen. Dazu können wir uns einen anderen Namen für den Datentyp schaffen:
Listing 4.45: typedef und using (cppbuch/k4/using.cpp)
#include <iostream> typedef float real; // neuer Name mit typedef using REAL = double; // neuer Name mit using int main() { real zahl1 {1.7353f}; // zahl1 ist vom Typ float REAL zahl2 {3.1415}; // zahl2 ist vom Typ double std::cout << zahl1 << ’\n’; std::cout << zahl2 << ’\n’; }
Wenn wir in einem Programm alle real-Zahlen als double-Zahlen interpretiert haben wollen, brauchen wir nur die typedef-Zeile durch
zu ersetzen und neu zu compilieren. Alle Vorkommen von real bleiben unverändert, haben aber nun die Bedeutung von double. Für using gilt Entsprechendes. Die Syntax einer Alias-Deklaration mit using ist meiner Meinung nach leichter zu lesen. using hat noch einen weiteren Vorteil gegenüber typedef. Es lässt sich ein Template-Alias bilden:
Listing 4.46: Template-Alias mit using (cppbuch/k4/templateAlias.cpp)
#include <deque> #include <iostream> template <typename T> using Container = std::deque<T>; // double ended queue int main() { Container<int> cont; cont.push_back(1); // Container weiterverwenden: std::cout << cont.at(0) << ’\n’; }
Der Typ Container lässt sich leicht zum Beispiel auf den Typ std::vector<T> ändern. Die einzige Voraussetzung ist, dass der neue Typ die verwendeten Schnittstellen bereitstellt, etwa push_back() und at() in diesem Fall. Seit C++23 lässt sich using auch in Initialisierungsanweisungen anwenden, zum Beispiel
Komplexe Deklarationen lassen sich durch typedef bzw. using lesbarer gestalten, weil neue Typnamen zur Strukturierung benutzt werden können. Das obige seltsame Beispiel sei wieder aufgegriffen, indem ein neuer Datentyp ArrayVon3CharZeigern definiert wird:
Der Rückgabetyp der Funktion, die zum Funktionszeiger seltsam der Vorseite passt, ist ein Zeiger auf den neuen Datentyp:
Der Datentyp des Funktionszeigers seltsam kann so beschrieben werden:
oder lesbarer mit
In [vdL] ist ein C-Programm abgedruckt, das in der Unix-Welt unter dem Namen cdecl bekannt ist. Es übersetzt komplizierte Deklarationen in verständlichen Text. Das Programm ist auch in den herunterladbaren Beispielen zum Buch vorhanden (siehe cppbuch/k4/cdecl.cpp). Das Programm wartet nach dem Start auf die Eingabe einer Deklaration, zum Beispiel char* A[3], und gibt danach die Auswertung aus (»A is array 0..2 of pointer to char«). Alternativ können Sie die Internetseite https://cdecl.org aufsuchen und dort eine Deklaration eingeben.
Das Bestimmen von Typen kann schwierig sein. Es erleichtert die Arbeit, wenn der Compiler diese Arbeit übernimmt. Das Schlüsselwort auto hilft dabei, wie Sie schon gesehen haben.
| 4.14 | Alternative zu rohen Zeigern, new und delete |
Die Alternative zu C-Arrays, ob statisch oder dynamisch angelegt, ist die Verwendung von Objekten der Klasse vector oder array. Sie stellen mehr Funktionen als C-Arrays zur Verfügung. Sie müssen sich nicht um das Speichermanagement kümmern und gewinnen Bequemlichkeit und Sicherheit. Dank des inline-Mechanismus gibt es keine Geschwindigkeitseinbußen.
Die Alternative zu anderen rohen Zeigern, new und delete ist die Benutzung sogenannter smarter Zeiger (englisch smart pointer), mit denen Objekte auf dem Heap angelegt werden können. Sie können wie ein Zeiger benutzt werden, man braucht aber weder new noch delete. Die Anwendung setzt #include <memory> voraus. Ein wesentlicher Vorteil dieser Art von Zeigern ist, dass delete überflüssig ist – der Destruktor wird automatisch aufgerufen. Der Grund ist, dass sie normale Objekte sind, die einen rohen Zeiger kapseln. Auf den wird vom unique_ptr- bzw. shared_ptr-Destruktor delete angewendet.
Es gibt in C++
unique_ptr für den exklusiven Besitz eines Objekts, das heißt, dass nur exakt ein unique_ptr-Zeiger auf das Objekt verweist. Das bedeutet auch, dass die Kopie eines unique_ptr-Zeigers nicht möglich ist.
shared_ptr für den Fall, dass mehrere Zeiger auf ein Objekt verweisen können sollen. Eine Kopie ist daher möglich. Ein interner Zähler sorgt dafür, dass der Destruktor des Objekts erst dann aufgerufen wird, wenn der letzte auf dieses Objekt zeigende shared_ptr ungültig wird.
Hinweis
Die dieser Art von Zeigern intern zugrunde liegenden Mechanismen werden erst in Abschnitt 8.5 behandelt. Deswegen gibt es an dieser Stelle nur eine kurze Einführung, um die Alternativen früh aufzuzeigen und erste Versuche zu ermöglichen.
Im folgenden Programm werden dynamisch Objekte der aus Kapitel 3 bekannten Klasse Ort angelegt. Ein Ort-Objekt, auf das ein unique_ptr zeigt, wird am besten mit der Funktion make_unique angelegt:
uptr ist vom Typ std::unique_ptr<Ort> und zeigt auf das erzeugte Ort-Objekt. Der Typ des Objekts wird in den spitzen Klammern angegeben. Achtung: In den runden Klammern wird kein Ort-Objekt notiert, sondern es werden genau die Parameter übergeben, die ein Ort-Konstruktor erwartet! Das folgende Programm zeigt typische Anwendungsarten:
Verwendung in einem Block ohne Aufruf von delete.
Nutzung wie ein normaler roher Zeiger.
Ablegen von unique_ptr-Zeigern in einem Vektor und ihre Benutzung.
Übergabe an eine Funktion. Weil eine Kopie nicht möglich ist, wird eine Referenz übergeben.
Listing 4.47: std::unique_ptr statt roher Zeiger (cppbuch/k4/uniqueptr.cpp)
#include <iostream> #include <memory> #include <Ort.h> #include <vector> void f(const std::unique_ptr<Ort>& up) // per Referenz! { std::cout << "f()˽aufgerufen:˽" << up->getX() << ’˽’ << up->getY() << ’\n’; } int main() { { // neuer Block auto uptr{std::make_unique<Ort>(1, 2)}; // Benutzung wie Zeiger std::cout << "(x,˽y)˽=˽" << uptr->getX() << ’˽’ << uptr->getY() << ’\n’; // Benutzung wie Referenz std::cout << "(x,˽y)˽=˽" << (*uptr).getX() << ’˽’ << (*uptr).getY() << ’\n’; Ort einOrt{*uptr}; // Kopie des Orts, nicht des Zeigers std::cout << "x˽=˽" << einOrt.getX() << ’\n’; } // Blockende. Automatischer Destruktoraufruf! // Vektor std::vector<std::unique_ptr<Ort>> vec(2); // 2 Elemente vec[0] = std::make_unique<Ort>(3, 4); // initialisieren vec[1] = std::make_unique<Ort>(5, 6); // initialisieren vec.push_back(std::make_unique<Ort>(7, 8)); // jetzt 3 Elemente // Alle anzeigen: for (const auto& ortptr : vec) { // Referenz! std::cout << ortptr->getX() << ’˽’ << ortptr->getY() << ’\n’; } f(vec[2]); // oben definierte Funktion f() aufrufen }
Am Ende des Programms werden der Destruktor für den Vektor vec und die Destruktoren für alle Elemente des Vektors aufgerufen. Die Verwendung von shared_ptr ist genau so einfach, wie das Listing 4.48 zeigt. Im Listing zeigen vec[0] und sharedptr2 auf dasselbe Objekt.
Listing 4.48: std::shared_ptr statt roher Zeiger (cppbuch/k4/sharedptr.cpp)
#include <iostream> #include <memory> #include <Ort.h> #include <vector> int main() { std::vector<std::shared_ptr<Ort>> vec; vec.push_back(std::make_shared<Ort>(3, 4)); vec.push_back(std::make_shared<Ort>(5, 6)); vec.push_back(std::make_shared<Ort>(7, 8)); auto sharedptr2{vec[0]}; // Kopie eines shared_ptr, zeigt auf // dasselbe Objekt wie vec[0] sharedptr2->aendern(1, 2); // ändert das Objekt // Alle anzeigen: for (auto ortptr : vec) { // Kopie ist möglich, da shared_ptr std::cout << ortptr->getX() << ’˽’ << ortptr->getY() << ’\n’; } }
1 Ein Programmcode ist dann portabel, wenn sich das damit erzeugte ausführbare Programm auf allen Systemen gleich verhält.
2 Dieser Abschnitt kann beim ersten Lesen übersprungen werden.