1.4Application Cases and Deployment Options for SAP HANA
This section provides an overview of the various application cases and deployment models for SAP HANA.
1.4.1Application Cases
The following describes four application cases for SAP HANA:
-
Real-time analyses
-
Accelerators
-
Data warehousing
-
New applications
Real-Time Analyses
Historically, the SAP HANA database was primarily used for analyzing large data volumes in real time. This application case is still widespread today. Here, SAP HANA serves as a data mart in which you store partial datasets for reporting and data analysis.
Frequently, the data that is required for real-time analysis is replicated from SAP systems and particularly from SAP Business Suite. SAP HANA is then used as a secondary database in addition to an existing traditional database (primary database of the SAP system), which is why this is often referred to as a side-by-side scenario.
Figure 1.8 shows the architecture of side-by-side scenarios and visualizes the accelerators that are described in the next section.
You can often achieve significant speed benefits by shifting the data analysis from a traditional database to the SAP HANA database.
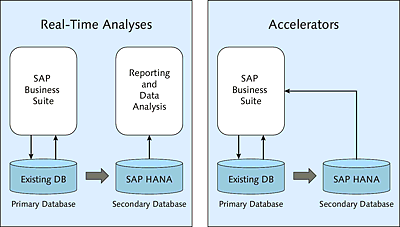
Figure 1.8Architecture of Side-by-Side Scenarios
[»]SAP HANA Live
SAP HANA Live is a virtual, multilevel data model in the database tables of SAP Business Suite for usage within the scope of a data mart. SAP provides predefined reports and analytical applications based on this data model. They enable enterprises to evaluate the data of SAP Business Suite in real time. Here it’s irrelevant whether SAP HANA is used as a primary or secondary database.
You can find more detailed information on SAP HANA Live at http://help.sap.com/hba.
Accelerators
Accelerators (which also represent a side-by-side scenario) are used to accelerate selected business processes. They are usually represented by ABAP programs or transactions within SAP Business Suite.
For acceleration—as in the previous application case—data are replicated from the traditional database to the SAP HANA database, and then selected reading database accesses within the application are redirected to SAP HANA (see Figure 1.8). The redirection of database accesses can be implemented using various procedures. In most cases, this redirection is done via separate database connections and small changes to the ABAP source code.
[Ex]SAP CO-PA Accelerator
The SAP Cost Profitability Analysis (CO-PA) accelerator is used to implement an accelerator scenario and is probably one of the best-known examples of a side-by-side scenario. However, there are more implementation examples. An overview can be found in SAP Note 1761546.
You can also accelerate customer-developed ABAP programs using an accelerator scenario. For the SAP Business Application Accelerator powered by SAP HANA (see Appendix D), redirection is done via a special SAP kernel and adjustments in Customizing. Note that it’s not necessary to change the ABAP source code for this accelerator.
Data Warehousing
The next important application case for the SAP HANA database is data warehousing. By using the SAP HANA database as a database for SAP BW, you can usually improve performance and simplify administration.
The performance of SAP BW benefits from the in-memory technology. By deploying SAP HANA, you can often accelerate not only queries but also load processes. The option of avoiding “unnecessary” database aggregates frequently simplifies the data modeling.
New Applications
The last application case involves applications that were developed specifically for SAP HANA or were migrated to SAP HANA and subsequently optimized.
First, we should mention SAP Business Suite. Since 2013, SAP Business Suite has been available on the basis of SAP HANA (SAP Business Suite on SAP HANA). Since then, SAP has incrementally optimized parts of the SAP Business Suite code for the in-memory technology. However, besides the SAP HANA database, SAP Business Suite also supports traditional databases as persistence storage.
This spring, SAP announced SAP S/4HANA (SAP Business Suite 4 SAP HANA). This is a new product that only supports SAP HANA as persistence storage. From the technical perspective, SAP S/4HANA corresponds to SAP Business Suite on SAP HANA and add-ons that are based on this suite. These add-ons are referred to as exchange innovations because they gradually replace and optimize the system’s entire code. Wherever possible, the data model of SAP S/4HANA waives aggregates and index tables. This results in significant simplification and reduces the memory required.
In addition to SAP Business Suite or SAP S/4HANA, SAP has developed numerous other applications based on the in-memory technology, such as the following two examples:
-
SAP Fraud Management for uncovering, examining, and preventing fraud
-
SAP Integrated Business Planning for Sales and Operations for planning the supply chain
In many cases, the completely new applications partially use data from SAP Business Suite and write results back to the suite. For this reason, this is often also referred to as a side-by-side scenario.
1.4.2Deployment Options
Roughly speaking, two deployment models can be distinguished for SAP HANA:
-
On-premise deployments
-
Cloud deployments
Both models are discussed next.
On-Premise Deployments
Enterprises can install and operate SAP HANA in their own datacenters. As described in Section 1.2.1, appliances, TDI, as well as virtualization are available for this purpose. On-premise deployments provide enterprises with maximum flexibility and control of their SAP HANA database.
Cloud Deployments
In simple terms, cloud computing enables enterprises to use “remote” datacenters for the installation and operation of SAP HANA. We won’t define cloud computing and particularly the various technical implementation at this point. Three cloud offers are relevant for SAP HANA:
-
SAP HANA Cloud Platform
SAP HANA Cloud Platform is a Platform-as-a-Service (PaaS). On this platform, enterprises can develop new applications or enhance existing applications (e.g., SAP Business Suite or SAP SuccessFactors). SAP HANA Cloud Platform provides most functions that SAP HANA also offers on-premise. In addition, it offers numerous application services, for example, a cloud-based portal, a cloud-based identity provider, and an integration service. -
SAP HANA Enterprise Cloud
SAP HANA Enterprise Cloud is a managed cloud offer where interested enterprises have SAP operate entire system landscapes that consist of SAP Business Suite, SAP BW, and customer-specific applications. They are provided with numerous services from which they can compile a “tailored” offer. -
Usage of Infrastructure-as-a-Service providers
Enterprises that don’t install SAP HANA on-premise and don’t want to use a PaaS or managed cloud offer either can operate the SAP HANA database at various Infrastructure-as-a-Service (IaaS) providers. In this context, we particularly want to mention the offers of Amazon Web Service s (AWS) and Microsoft Azure. More information is available on the websites of the respective providers.
This book focuses on the usage of SAP HANA in the context of ABAP-based applications, specifically SAP Business Suite on SAP HANA and SAP S/4HANA. We won’t discuss the specifics of deployment models, however.