Best practices play an important role, especially when using new technologies. Even if something is technically possible, it may not be practical or useful in each scenario. You should review old rules and explore new design patterns.
14Practical Tips
We’ve presented a variety of options within this book for calling functions in SAP HANA from ABAP systems. In addition to normal database access, we’ve discussed modeling views, SQLScript-based views, and database procedures, as well as some advanced technologies such as text analysis, function libraries, and decision tables. Moreover, you’ve learned a lot about the new options of database programming using ABAP 7.4 (Core Data Services [CDS] views and ABAP database procedures).
In this chapter, we’ll present some practical tips on topics that are particularly important when developing ABAP applications on SAP HANA. These are subdivided into the following topic areas:
-
General recommendations
We’ll first provide you with some general recommendations for developing ABAP on SAP HANA. We primarily discuss details that you should consider for the migration and optimization of ABAP programs. -
Conventions
We present some conventions that, from our perspective, are useful but optional. These include naming conventions, encapsulating and packaging conventions, distributed development guidelines, and similar topics. -
Quality aspects
For implementations in the database, nonfunctional criteria such as robustness, testability, and security should play an important role in addition to performance. We introduce some measures that will help ensure high quality in development. -
Performance guidelines
The execution speed of programs naturally plays a crucial role in the context of SAP HANA. Many usage scenarios involve access to large datasets in real time. A solid understanding of the guidelines and techniques for achieving optimal performance is essential here. We provide an overview of existing and new recommendations, and we particularly discuss changes in comparison to traditional databases.
We’ll also enhance programming recommendations via positive and negative examples.
14.1General Recommendations
In this first section, we’ve compiled some general recommendations that you should follow for migration and development on SAP HANA. This involves functional aspects in particular. We’ll return to nonfunctional topics such as conventions, quality aspects, and performance in subsequent sections.
We’ll start with recommendations for the use of column stores or row stores in SAP HANA. We’ll then discuss possible design patterns for the encapsulation of SAP HANA-specific implementations and provide a checklist for relocating calculations to SAP HANA.
14.1.1Recommendations for Column Stores and Row Stores
You can look in the technical settings of the ABAP Data Dictionary (DDIC) to see whether a table should be created in the row store or column store of SAP HANA (see Chapter 3, Section 3.2.1). The column store is the default setting here.
You can analyze large datasets more efficiently in the column store. Thus, SAP recommends that you store every table in the column store, as long as there is no dedicated reason for storing it in the row store. Tables that contain application data are always stored in the column store because it’s very likely that this data are will also be used in analysis scenarios. This applies particularly to tables that contain a large number of data records because the column store provides better compression properties. This also applies to tables that are will be used for text searches (see Chapter 10, Section 10.3).
Still, you have reason to use the row store if, for example, a table is accessed predominantly by time-critical data manipulation language (DML) statements (i.e., UPDATE, INSERT, or DELETE). In addition, this can’t be an application table on which you subsequently want to perform analyses. Therefore, primarily technical, internal SAP tables are eligible for the row store. Examples include tables for update processing (STSK package) or for Remote Function Call (RFC) processing (SRFC package). These tables are typically accessed with a SELECT SINGLE.
[+]Use the Column Store!
In general, you should store all tables in the column store for SAP HANA unless more technical tables are involved, as just described.
14.1.2SAP HANA-Specific Implementations
With the ABAP development on SAP HANA, we must distinguish between two scenarios:
-
Database-independent implementations (e.g., Open SQL or CDS views)
-
Implementations using SAP HANA-specific functions (e.g., Native SQL, column views, and database procedures)
In the first case, you don’t have to consider anything special from a software logistics perspective. You use SAP HANA like any other database, but you benefit directly from the high processing speed of SAP HANA in many scenarios. Your developments are executable on all database systems supported by SAP.
When using native SAP HANA functions, the same implications as usual initially apply if you define parts of an application specifically for a database system (e.g., via Native SQL, hints, or other techniques). When designing the application, you should consider the following questions:
-
Are there systems with a different database system in your landscape or in your customers’ landscapes? Is an alternative implementation of the functions required for other database systems?
-
How fundamental are database-specific functions to your application scenario? Is the central quality of the application involved, or is it just the “teasing out” of the optimal performance?
-
Is the development in SAP HANA to be called solely via ABAP-based applications or via other channels as well (e.g., SAP BusinessObjects tools)?
It’s difficult to give a general recommendation as to when exactly it makes sense to use a database-specific implementation. For pure performance optimization of an existing ABAP application, we recommend that you initially proceed by using standard tools. The following guidelines provide help here:
-
First open, then native
Preferably use Open SQL and CDS views before you deploy Native SQL, SAP HANA views, or database procedures. Open features are integrated optimally with the ABAP development environment and the ABAP runtime. The ABAP application server comprehensively checks your development objects, and you don’t need any additional user for the SAP HANA database. Client handling is also automatic. -
First ABAP managed, then database managed
Use ABAP database procedures instead of SAP HANA database procedures. Development objects that are managed by ABAP AS are optimally linked with ABAP Lifecycle Management. You can easily synchronize ABAP database procedures with other ABAP objects and transport them. You also benefit from the strengths of the ABAP enhancement concept.
In Section 14.4, we provide special performance recommendations for the use of Open SQL on SAP HANA.
If you use the techniques in this book to relocate operations to SAP HANA and ensure that they can be called via ABAP, it’s often useful to encapsulate access to these functions via an interface in ABAP (thus, an ABAP interface). This enables the use of the factory pattern—a standard design pattern in software development—which is used for decoupling. Listing 14.1 shows sample code in which data retrieval was abstracted via the lif_data_provider interface (the exact appearance of this interface is irrelevant to understanding this example). The factory class provides a method that transfers an instance of an SAP HANA-specific implementation (lcl_hana_provider) to an SAP HANA system, while an alternative implementation is created in systems with a classic database. The test on SAP HANA is done via the CL_DB_SYS class, which has advantages over a test on the sy-db system field because you can easily make a where-used list for a class to find all parts of the program that perform such a distinction.
CLASS lcl_factory DEFINITION.
PUBLIC SECTION.
CLASS-METHODS: get_instance
RETURNING VALUE(ro_instance)
TYPE REF TO lif_data_provider.
ENDCLASS.
" Implementation of the factory class
CLASS lcl_factory IMPLEMENTATION.
METHOD get_instance.
IF ( cl_db_sys=>is_in_memory_db = abap_true ).
ro_instance = NEW lcl_hana_provider( ).
ELSE.
ro_instance = NEW lcl_standard_provider( ).
ENDIF.
ENDMETHOD.
ENDCLASS.
Listing 14.1Example of Factory Design Pattern Use for Decoupling SAP HANA-Specific Implementations
This approach can also be combined with Business Add-Ins (BAdIs) because the concept of an (abstract) factory class is also used in this case.
[+]Optimization Procedure
Try to implement local performance optimization initially via Open SQL and CDS views. For major program changes and relocation of operations to SAP HANA, invest in decoupling, for example, via the aforementioned factory approach.
14.1.3Checklist for Database-Specific Implementations
In this section, we’ll provide a checklist of what you should consider when relocating program code to the database. This helps you avoid errors related to internationalization or localization.
Dates play an important role in business data and processes (e.g., when a booking was made). You must of course pay attention to using the respective time zones correctly. If you use the time zone to which the server is set, you must note that the database server’s time zone is used for SQLScript, while the time zone of AS ABAP is crucial in ABAP implementations. SAP recommends that you always make sure these time zones are identical during the installation.
To determine the period between two calendar dates, there are special calculation rules for some business processes and in some global regions (e.g., using a fiscal year with 360 days or combining the days of a weekend into one day). Depending on the context, you must ensure that such calculations are interpreted correctly from a business perspective. The days_between SQL function supported by SAP HANA doesn’t know these specifics.
When handling currencies, you must ensure that some amounts are stored in the database with displaced decimal places (e.g., for Japanese yen). When calculating with such values, you must ensure that this displacement is taken into account before an output for an end user. This takes place in ABAP, for example, via specific conversion functions or the WRITE statement. If you work with currencies in analytical models in SAP HANA and want to consume them externally, you should mark these key figures as such and specify that the decimal displacement is taken into account (see Chapter 4, Section 4.4). In SQLScript procedures, you should clearly define whether you’re working with internal or external formats in the definition of the interface, so each user knows how to interpret the values.
There may be differences between internal and external presentations for other data types also. An example of this is the flight time in the flight plan of our sample data model (FLTIME column in table SPFLI). The flight time is stored internally in minutes as an INTEGER in the database, while it’s presented externally via a conversion exit as a character string consisting of hours and minutes. If you’re thus using a data model in different user interfaces (UIs), we recommend you ensure that it’s treated uniformly.
When calculating with decimals, rounding behavior plays an important role, especially for monetary amounts. Small rounding differences can have a major impact on totals, so you should make sure to minimize rounding errors. When converting a currency, you should, if possible, only perform the conversion after an aggregation, which is also advantageous from a runtime perspective.
The sorting of texts depends on the current language settings. In the ABAP SORT command, therefore, the AS TEXT addition sorts the character strings alphabetically according to the set text environment. If you sort content in an SQL statement via the ORDER BY addition, however, it’s sorted in a binary manner according to the internal presentation. Figure 14.1 shows an example using German umlauts. Here, the name “Möller” appears after “Muller,” although it should appear alphabetically after “Moller.” For this reason, we recommend that you usually sort texts, which you present in an ABAP application for an end user, in an application server.
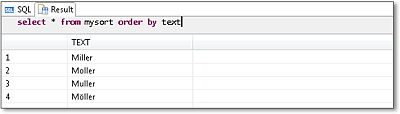
Figure 14.1Sorting Texts in the Database
[+]Handling Data Correctly from a Business Perspective
For time stamps, currencies, units, and texts, pay particular attention to the correct treatment of the business data in the context of native implementations in the database.
14.1.4Recommendations for Migration
In this section, we give you some tips to consider when migrating an existing system to SAP HANA. A basic rule is that ABAP applications are fully compatible. There are a few fine points to note, which we’ll discuss here:
-
Database-dependent ABAP code
If you use database-dependent ABAP code in existing developments, you must test it as with any data migration and adjust it for the SAP HANA database if necessary. -
Converting pool and cluster tables
When converting pool and cluster tables to transparent tables, problems may occur if you’ve relied on an implicit sort behavior in your developments or if you directly accessed the internal physical clusters or pools. -
Sort behavior
If no ORDER BY was specified in the SQL statement, the sequence in which the records are read is unpredictable.
Database-Dependent Code
If your existing applications have database-dependent code—for example, Native SQL via the EXEC SQL statement , the ABAP Database Connectivity (ADBC) interface, or database hints—these positions in the code must be checked. While database hints are no longer executed on the new platform when you migrate to another database, an exact check is always required for database-dependent SQL because errors may occur here unless you intervene.
Hints to the database (or also the database interface [DBI]) are given a database indicator in ABAP. This generally looks as follows:
The hint is sent only to the database specified instead of the <DB> placeholder. This means that when the additional statement to the optimizer of the old database platform is converted to the new platform, it’s no longer sent to the optimizer of the new database. This concerns not only hints for the database but also specific instructions to the DBI. For a conversion, you must thus check whether the desired behavior on the old database platform should also be defined again by a hint on the new database platform. This is generally unnecessary for SAP HANA due to the modified architecture. Usually, no adjustment is necessary for the hints to the DBI, either. Here, we recommend that you use the default values for SAP HANA for the DBI.
You must always check database-dependent code for a conversion, even if standard SQL is involved. For database-specific SQL, you must first clarify what the code is to achieve. An SQL statement must then be written to deliver the same result on SAP HANA. If possible, you should use Open SQL for this.
Sort Behavior
Access to former pool or cluster tables, which we’ve already discussed in Chapter 7, Section 7.3.1, is a point that should be emphasized separately. For pool and cluster tables, the DBI always performs an implicit sorting. This is lost after the conversion to a transparent table because no automatic ORDER BY is added here to the statement. Therefore, access to pool and cluster tables must be analyzed with regard to their sorting during a migration. In this case, the Code Inspector provides a separate check—Find Select for Pool/Cluster Tab without ORDER BY—so you can quickly and easily find such critical points in your own developments.
However, changes can also occur in the implicit sort behavior for existing transparent tables. Classic row-oriented databases are usually accessed via a primary or secondary index. Here, the data are often read in the desired sequence because they are read from the database in the sequence stored there when you use an index. However, this isn’t guaranteed, and this behavior isn’t a documented feature of Open SQL. The selected access path and the associated sorting can thus change at any time. You must use the ORDER BY addition instead if the data is to be selected in a specific sorting. This rule applies in particular to SAP HANA because the data are column-oriented, there is no secondary index, and the data can be read in parallel. Thus, such places involve a programming error that you should correct regardless of a migration to SAP HANA. The Code Inspector and the runtime check monitor (Transaction SRTCM) provide separate checks (see Chapter 7, Section 7.3.1 and Section 7.5.3).
Problems may occur if a certain sorting is assumed in program sequences. This is the case, for example, when working with searches in internal tables with the BINARY SEARCH addition because a relevant sorting is essential there. However, there may also be surprises with the output of data if it’s suddenly not appearing in the desired sort order.
[+]Don’t Rely on Implicit Sortings
If you require a specific sorting of data when you access a database, use the ORDER BY addition explicitly.
14.1.5Development in Landscapes
In a standard SAP development scenario, multiple systems are generally used, and even entire landscapes are often included in larger developments. To ensure that no problems occur during the transition from a development system to another system (e.g., a test or production system), you should follow some guidelines for implementations in the database.
First, review the correct handling of schema names and the client field, which we discussed in Chapter 5, Section 5.1.4. During modeling or SQLScript implementation, avoid referencing schema names directly because these names are no longer valid after a transport to a different system. Thus, for procedures and calculation views, use the settings for a standard schema, and define appropriate schema mappings as described in Chapter 5, Section 5.3.1. As with SQLScript and Native SQL, you should always ensure that you handle the client field correctly. One option is to store different data configurations in various clients in the development or test system, and test them explicitly. For SAP HANA views, you should generally select the Dynamic Default Client setting to use the current client of the ABAP session (see Chapter 5, Section 5.1.4).
For the transport of ABAP applications that directly reference SAP HANA objects such as views or procedures, we recommend the techniques described in Chapter 5, Section 5.3. You should use a common transport to ensure that inconsistencies don’t occur in a target system (e.g., a missing database procedure that is accessed from ABAP). When using external views, database procedure proxies, and SAP HANA transport containers, you should also ensure that you’ve synchronized the content prior to a transport.
If you’ve mixed development landscapes in which some systems don’t run on SAP HANA (yet), you can transport ABAP developments on SAP HANA through these systems without any problems. We recommend you always ensure that SAP HANA-specific implementations—which can’t run in such systems—don’t lead to uncontrolled program terminations if they are called (also see Section 14.3.2).
[+]Development in System Landscapes
Avoid direct accesses to schema names in SQLScript, and ensure correct client handling. Dependent ABAP and SAP HANA developments should be transported together consistently.
14.1.6Modifying Data in SQLScript or Native SQL
We recommend in general that you largely avoid write operations on ABAP tables via SQLScript (including ABAP Managed Database Procedures [AMDPs]) or Native SQL EXEC SQL or ADBC). If you nevertheless modify database contents via these mechanisms, you should be particularly careful. We’ll give you some important relevant information in this section.
Such accesses are sent virtually unchanged via the DBI to the database, so the SAP services on the application server—for example, for locking (see Chapter 3, Section 3.1) and table buffering (see Chapter 3, Section 3.2)—and their synchronization are completely bypassed. Such changes may lead to inconsistent data, as the following examples show.
If, for example, data that is in the SAP table buffer is changed via SQLScript or Native SQL, the change is made only in the database. The data in the local table buffer (on the server on which the change was made) won’t be changed. Synchronization entries won’t be written in table DDLOG, where other application servers are informed of changes in buffered tables and then can synchronize them. The data in the table buffer are no longer consistent with the data in the database because the changes were made directly via Native SQL or SQLScript while bypassing the table buffer. Thus, tables that are in the SAP table buffer must always be changed via Open SQL; otherwise, the data can’t be changed or synchronized in the buffers.
In Figure 14.2, you can see the differences between changes via SQLScript (or Native SQL) and the standard variant via Open SQL statements. In the former case, the calls are forwarded directly via the DBI to the database while bypassing the table buffer, and the changes are made in the database.
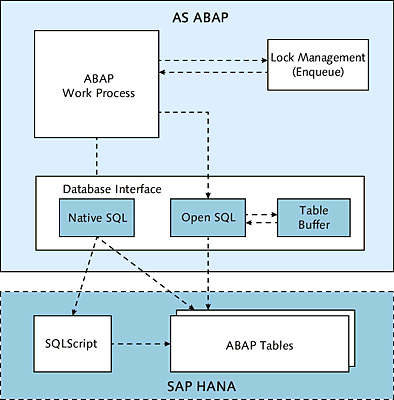
Figure 14.2Changing Accesses via SQLScript or Native SQL
The system behavior is similar for locks. Data protected from change in parallel in the ABAP system via the enqueue service can still be changed directly in the database if SAP lock management is bypassed. This can also lead to inconsistent data if, for example, an ABAP application has set a lock to perform consistent calculations while another application is covertly changing this data directly in the database. Changes that were already made may also be lost if a lock on data records is ignored.
[+]Avoiding Modification of ABAP Tables via SQLScript and Native SQL
You should avoid changing data via SQLScript or Native SQL if possible. If you can’t avoid this, ensure that the data isn’t subject to table buffering or protected via the SAP enqueue service. Otherwise, data inconsistencies may occur.