14.5Performance Recommendations for Native Implementations in SAP HANA
Now that we’ve discussed performance recommendations for working with Open SQL, we’ll provide some recommendations for working with Native SQL, modeled and implemented SAP HANA views, and SQLScript.
14.5.1Recommendations for Native SQL
In connection with the use of Native SQL via ADBC, we’ll refer—in addition to the recommendations for Open SQL, which apply in the same way as Native SQL—to two topics separately. This involves the use of prepared statements and mass operations. We’ve presented both in Chapter 3, Section 3.2.4, so we only want to discuss the performance aspects here. For the topics presented here (and for others), there is an example in the INSERT_ROWS and INSERT_ITAB subroutines in ABAP test Program ADBC_DEMO, which is provided with the standard SAP.
Prepared Statements
Unlike Open SQL, which is optimized for performance by the SAP Kernel, the programmer must ensure optimal use when using Native SQL via ADBC. If the CL_SQL_STATEMENT class is used, this involves a dynamic statement that is transferred to the database for each execution with the EXECUTE_QUERY method, which analyzes the SQL statement in turn as a character string. The parameters are included in the analysis. The following two SQL statements are thus different for the database because two different character strings are involved:
SELECT * FROM scarr WHERE carrid = 'UA';
For each of these two statements, the database must perform, among other things, the following steps:
-
Parse the statement (e.g., for the syntax).
-
Reserve memory for the statement and the execution plan.
-
Create the execution plan and store it in the SQL cache.
These steps are known as the prepare phase because the statement for execution is prepared here. If a very large number of SQL statements is sent to the database, which differ only in the parameters that are used, the database has to make a relatively large effort in preparing each statement. The time required can lie in the mid-three-digit microsecond range and thus may be as high as the time required for actually executing the statement. Frequent executions therefore quickly involve additional effort, which can constitute a significant part of the runtime.
If only the parameters of an SQL statement change, the statement can be transferred to the database using the CL_PREPARED_STATEMENT class with a parameter marker. The transferred statement looks, for example, as follows:
This statement is prepared once only and is stored in the SQL cache. Immediately before execution, the parameters that were set with the SET_PARAM method are used instead of the parameter marker when you call the EXECUTE_QUERY method of the CL_PREPARED_STATEMENT class. That means you can reduce the effort in preparing the SQL statements to the bare minimum. After you no longer require the prepared SQL statement, you should use the CLOSE method to close the CL_PREPARED_STATEMENT class, so you can release the resources required by the SQL statement as soon as possible.
You should use the CL_SQL_STATEMENT class to execute statements that are executed only once. For SQL statements that you want to execute several times, you should use the CL_PREPARED_STATEMENT class and pass the different parameters separately. That helps keep the effort in preparing SQL statements as low as possible and contributes to relieving the database.
Mass Operations
As of SAP NetWeaver AS ABAP 7.4, an array interface is available for modifying SQL statements via ADBC. You can add, for example, multiple rows at once, and you don’t have to proceed row by row. Because a reduced number of statements has a positive effect on the performance of an application, we recommend that you use this option not only for read accesses but also for write accesses. As discussed in Section 14.1.6, however, you should modify data via the ADBC interface only in exceptional situations.
14.5.2Recommendations for SAP HANA Views
Chapter 4 introduced you to various view types. When modeling and implementing SAP HANA views, you can make certain errors that have a particularly adverse effect on performance. We’ll provide a few basic recommendations for modeling SAP HANA views.
Selecting the Correct View Type
First, it’s incredibly important to select the correct view type when modeling in SAP HANA Studio. Your options are shown in Figure 14.3, which is derived from the SAP HANA SQLScript Reference that supports you in decision making.
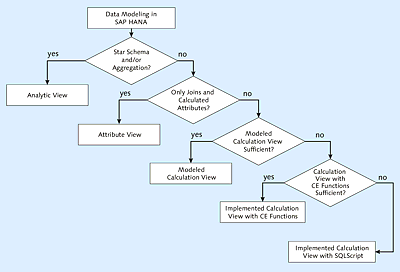
Figure 14.3Selecting the View Type in SAP HANA
When selecting the view type, you should first check whether you need a star schema to map a given requirement and/or want to aggregate a large number of data records. If this is the case, we recommend that you use an analytic view. Otherwise, you can first use an attribute view. An attribute view allows you to relate multiple tables to each other using joins. If necessary, you can also define calculated fields.
If you can’t map a given requirement through an analytic view nor an attribute view, use a calculation view. You can use a modeled calculation view if you want to use only the operations JOIN, PROJECTION, AGGREGATION, and UNION. Otherwise, you must implement the calculation view and either use only calculation engine (CE) functions or rely on the additional options of SQLScript.
Modeling/Implementation
In addition to selecting the correct view type, you should consider some other recommendations for modeling and implementing SAP HANA views to achieve optimum performance.
You very often need several SAP HANA views (see Figure 14.4) to solve a given requirement, as in the following situation:
-
You aggregate various key figures with different analytic views (e.g., an analytic view based on table SFLIGHT and a second analytic view based on table SBOOK; the first analytic view determines the load, while the second determines the sum of baggage weights per flight connection).
-
You then combine the interim results of the analytic views for the final result (by using the UNION operation within a calculation view).
-
Finally, you can enrich the final result with additional master data (e.g., by using the JOIN operation and an attribute view based on table SPFLI within the calculation view to read the master data of the flight connections).

Figure 14.4Combination of SAP HANA Views
In such a case, several engines (see Chapter 1, Section 1.3) are involved in calculating the final result. This is illustrated schematically in Figure 14.4.
You can support the engine involved in solving a given task by following some rules:
-
Keeping datasets small
As when using Open SQL within ABAP applications, we recommend that you minimize the dataset that is read and exchanged between the engines for modeling SAP HANA views. You achieve this by filtering data as soon as possible (by defining a suitable filter or WHERE conditions) and aggregating (especially via analytic views). In addition, you should read only the columns that are actually required. -
Aggregating data as soon as possible and performing calculations on aggregated data
By aggregating data as soon as possible and performing calculations on aggregated data, you achieve two things: First, you reduce the dataset for further processing and thus also the dataset, which must, for example, be transferred from the OLAP engine to the Calculation Engine. Secondly, you minimize the number of calculations under certain circumstances (e.g., for currency conversions). -
Avoiding complex joins
Avoid complex joins, that is, long concatenations of JOIN operations and joins between very large database tables. These can be very expensive. Alternatively, in some cases, you can first aggregate key figures from different fact tables independently of each other via different analytic views, and then combine the interim results via the UNION operation. -
Reading master data as late as possible
Read master data as late as possible, if it isn’t required for the previous calculation steps. -
Following recommendations for SQLScript
When using implemented calculation views, also note the following recommendations for SQLScript.
14.5.3Recommendations for SQLScript
If you have to use SQLScript to implement a requirement (because the requirement can’t be mapped by modeling an SAP HANA view), note the following rules (already discussed to some extent in Chapter 4, Section 4.2):
-
Minimizing complexity of SQL statements
You can break down complex SQL statements using table variables. This makes it easier for you to read the code and also facilitates the work of the SAP HANA database optimizer. It makes it easier in some cases, for example, by decomposing complex database queries, to identify redundant subqueries and to avoid calculating them several times. -
Avoiding dependency of SQL statements
As described in Chapter 4, multiple SQL statements within a database procedure or a calculation view are executed in parallel by the database as often as possible. However, this assumes that these statements are independent of each other. Thus, avoid unnecessary dependencies between SQL statements. -
Avoiding usage of CE functions
As we’ve already mentioned in Chapter 4, Section 4.2.2, it’s no longer recommended to use CE functions for implementing database procedures, so you should avoid them. -
Avoiding imperative programming
Imperative language elements (especially loops and cursor processing) make the parallelization more difficult or may prevent it completely. Try to work with declarative language elements. For data-intensive calculations, use loops and cursors in particular only if you can’t solve a requirement in a different way. -
Using strengths of OLAP and the join engine
If you need SQLScript to implement a requirement, it doesn’t necessarily mean that you have to implement the requirement solely with SQLScript. You can often delegate parts of the task within a database procedure or a calculation view to analytic views and attribute views. Check this option because it allows you to use the strengths of Online Application Processing (OLAP) and the join engine. -
Avoiding dynamic SQL
The optimization options of dynamic SQL are restricted. Dynamic SQL must be recompiled for each call under certain circumstances. Avoid dynamic SQL where it isn’t necessarily required. -
Using ABAP database procedures systematically
If you use ABAP database procedures, you should ensure that you only call further ABAP database procedures in your SQLScript code. Only then can you benefit from ABAP Lifecycle Management.
For more information, refer to SAP HANA SQLScript Reference in the SAP online help.