1 Suggested course syllabi.
1.1 A credit scoring dataset.
1.2 A more complex credit scoring dataset.
1.3 A simple retail dataset
1.4 Potential prediction models (a) before and (b) after training data becomes available.
1.5 The age-income dataset.
2.1 The basic structure of an analytics base table—descriptive features and a target feature.
2.2 The ABT for the motor insurance claims fraud detection solution.
3.1 The structures of the tables included in a data quality report to describe (a) continuous features and (b) categorical features.
3.2 Portions of the ABT for the motor insurance claims fraud detection problem discussed in Section 2.4.6[43].
3.3 A data quality report for the motor insurance claims fraud detection ABT displayed in Table 3.2[58].
3.4 The structure of a data quality plan.
3.5 The data quality plan for the motor insurance fraud prediction ABT.
3.6 The data quality plan with potential handling strategies for the motor insurance fraud prediction ABT.
3.7 The details of a professional basketball team.
3.8 Calculating covariance.
3.9 A small sample of the HEIGHT and SPONSORSHIP EARNINGS features from the professional basketball team dataset in Table 3.7[78], showing the result of range normalization and standardization.
4.1 A dataset that represents the characters in the Guess Who game.
4.2 An email spam prediction dataset.
4.3 The vegetation classification dataset.
4.4 Partition sets (Part.), entropy, remainder (Rem.), and information gain (Info. Gain) by feature for the dataset in Table 4.3[138].
4.5 Partition sets (Part.), entropy, remainder (Rem.), and information gain (Info. Gain) by feature for the dataset 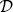 7 in Figure 4.8[140].
7 in Figure 4.8[140].
4.6 Partition sets (Part.), entropy, remainder (Rem.), and information gain (Info. Gain) by feature for the dataset 8 in Figure 4.9[141].
4.7 Partition sets (Part.), entropy, Gini index, remainder (Rem.), and information gain (Info. Gain) by feature for the dataset in Table 4.3[138].
4.8 Dataset for predicting the vegetation in an area with a continuous ELEVATION feature (measured in feet).
4.9 Dataset for predicting the vegetation in an area sorted by the continuous ELEVATION feature.
4.10 Partition sets (Part.), entropy, remainder (Rem.), and information gain (Info. Gain) for the candidate ELEVATION thresholds: ≥750, ≥1,350, ≥2,250 and ≥4,175.
4.11 A dataset listing the number of bike rentals per day.
4.12 The partitioning of the dataset in Table 4.11[156] based on SEASON and WORK DAY features and the computation of the weighted variance for each partitioning.
4.13 An example validation set for the post-operative patient routing task.
5.1 Matching animals you remember to the features of the unknown animal described by the sailor.
5.2 The SPEED and AGILITY ratings for 20 college athletes and whether they were drafted by a professional team.
5.3 The distances (Dist.) between the query instance with SPEED = 6.75 and AGILITY = 3.00 and each instance in Table 5.2[182].
5.4 The extended version of the college athletes dataset.
5.5 A dataset listing salary and age information for customers and whether they purchased a product.
5.6 The dataset from Table 5.5[204] with the Euclidean distance between each instance and the query SALARY = 56,000, AGE = 35 when we use both the SALARY and AGE features, just the SALARY feature, and just the AGE feature.
5.7 The updated version of Table 5.6[207] once we have applied range normalization to the SALARY and AGE features in the dataset and to the query instance.
5.8 A dataset of whiskeys listing the age (in years), the rating (between 1 and 5, with 5 being the best), and the bottle price of each whiskey.
5.9 The whiskey dataset after the descriptive features have been normalized.
5.10 The calculations for the weighted k nearest neighbor prediction.
5.11 A binary dataset listing the behavior of two individuals on a website during a trial period and whether they subsequently signed up for the website.
5.12 The similarity between the current trial user, q, and the two users in the dataset, d1 and d2, in terms of co-presence (CP), co-absence (CA), presence-absence (PA), and absence-presence (AP).
6.1 A simple dataset for MENINGITIS diagnosis with descriptive features that describe the presence or absence of three common symptoms of the disease: HEADACHE, FEVER, and VOMITING.
6.2 A dataset from a loan application fraud detection domain.
6.3 The probabilities needed by a naive Bayes prediction model, calculated from the data in Table 6.2[270].
6.4 The relevant probabilities, from Table 6.3[271], needed by the naive Bayes prediction model to make a prediction for a query with CH = paid, GC = none, and ACC = rent, and the calculation of the scores for each target level.
6.5 The relevant probabilities, from Table 6.3[271], needed by the naive Bayes prediction model to make a prediction for the query with CH = paid, GC = guarantor, and ACC = free, and the calculation of the scores for each possible target level.
6.6 The posterior probability distribution for the GUARANTOR/-COAPPLICANT feature under the condition that FRAUD = false.
6.7 Smoothing the posterior probabilities for the GUARANTOR/-COAPPLICANT feature conditioned on FRAUD = false.
6.8 The Laplace smoothed (with k = 3) probabilities needed by a naive Bayes prediction model, calculated from the dataset in Table 6.2[270].
6.9 The relevant smoothed probabilities, from Table 6.8[276], needed by the naive Bayes prediction model to make a prediction for the query with CH = paid, GC = guarantor, and ACC = free, and the calculation of the scores for each target levels.
6.10 Definitions of some standard probability distributions.
6.11 The dataset from the loan application fraud detection domain (from Table 6.2[270]) with two continuous descriptive features added: ACCOUNT BALANCE and LOAN AMOUNT.
6.12 Partitioning the dataset based on the value of the target feature and fitting the parameters of a statistical distribution to model the ACCOUNT BALANCE feature in each partition.
6.13 The Laplace smoothed (with k = 3) probabilities needed by a naive Bayes prediction model, calculated from the dataset in Table 6.11[286], extended to include the conditional probabilities for the new ACCOUNT BALANCE feature, which are defined in terms of PDFs.
6.14 The probabilities, from Table 6.13[289], needed by the naive Bayes prediction model to make a prediction for the query with CH = paid, GC = guarantor, ACC = free, and AB=false, and the calculation of the scores for each candidate prediction.
6.15 The LOAN AMOUNT continuous feature discretized into 4 equal-frequency bins.
6.16 The Laplace smoothed (with k = 3) probabilities needed by a naive Bayes prediction model, calculated from the data in Tables 6.11[286] and 6.15[291].
6.17 The relevant smoothed probabilities, from Table 6.16[293], needed by the naive Bayes model to make a prediction for the query with CH = paid, GC = guarantor, ACC = free, AB=759.07, and LA=8,000, and the calculation of the scores for each candidate prediction.
6.18 Some socio-economic data for a set of countries, and a version of the data after equal-frequency binning has been applied.
6.19 Examples of the samples generated using Gibbs sampling.
7.1 A dataset that includes office rental prices and a number of descriptive features for 10 Dublin city-center offices.
7.2 Calculating the sum of squared errors for the candidate model (with w [0] = 6.47 and w [1] = 0.62) to make predictions for the office rentals dataset.
7.3 Details of the first two iterations when the gradient descent algorithm is used to train a multivariable linear regression model for the office rentals dataset (using only the continuous descriptive features).
7.4 Weights and standard errors for each feature in the office rentals model.
7.5 The office rentals dataset from Table 7.1[325] adjusted to handle the categorical ENERGY RATING descriptive feature in linear regression models.
7.6 A dataset listing features for a number of generators.
7.7 An extended version of the generators dataset from Table 7.6[354].
7.8 Details of the first two iterations when the gradient descent algorithm is used to train a logistic regression model for the extended generators dataset given in Table 7.7[362].
7.9 A dataset describing grass growth on Irish farms during July 2012.
7.10 A dataset showing participants’ responses to viewing positive and negative images measured on the EEG P20 and P45 potentials.
7.11 A dataset of customers of a large national retail chain.
8.1 A sample test set with model predictions.
8.2 The structure of a confusion matrix.
8.3 A confusion matrix for the set of predictions shown in Table 8.1[401].
8.4 The performance measures from the five individual evaluation experiments and an overall aggregate from the 5-fold cross validation performed on the chest X ray classification dataset.
8.5 A confusion matrix for a k-NN model trained on a churn prediction problem.
8.6 A confusion matrix for a naive Bayes model trained on a churn prediction problem.
8.7 The structure of a profit matrix.
8.8 The profit matrix for the pay-day loan credit scoring problem.
8.9 (a) The confusion matrix for a k-NN model trained on the pay-day loan credit scoring problem (average class accuracyHM= 83.824%); (b) the confusion matrix for a decision tree model trained on the pay-day loan credit scoring problem (average class accuracyHM= 80.761%).
8.10 (a) Overall profit for the k-NN model using the profit matrix in Table 8.8[420] and the confusion matrix in Table 8.9(a)[421]; (b) overall profit for the decision tree model using the profit matrix in Table 8.8[420] and the confusion matrix in Table 8.9(b)[421].
8.11 A sample test set with model predictions and scores.
8.12 Confusion matrices for the set of predictions shown in Table 8.11[424] using (a) a prediction score threshold of 0.75 and (b) a prediction score threshold of 0.25.
8.13 A sample test set with prediction scores and resulting predictions based on different threshold values.
8.14 Tabulating the workings required to generate a K-S statistic.
8.15 The test set with model predictions and scores from Table 8.11[424] extended to include deciles.
8.16 Tabulating the workings required to calculate gain, cumulative gain, lift, and cumulative lift for the data given in Table 8.11[424].
8.17 The structure of a confusion matrix for a multinomial prediction problem with l target levels.
8.18 A sample test set with model predictions for a bacterial species identification problem.
8.19 A confusion matrix for a model trained on the bacterial species identification problem.
8.20 The expected target values for a test set, the predictions made by a model, and the resulting errors based on these predictions for a blood thinning drug dosage prediction problem.
8.21 Calculating the stability index for the bacterial species identification problem given new test data for two periods after model deployment.
8.22 The number of customers who left the mobile phone network operator each week during the comparative experiment from both the control group (random selection) and the treatment group (model selection).
9.1 The descriptive features in the ABT developed for the Acme Telephonica churn prediction task.
9.2 A data quality report for the Acme Telephonic ABT.
9.3 The confusion matrix from the test of the AT churn prediction stratified hold-out test set using the pruned decision tree in Figure 9.5[478].
9.4 The confusion matrix from the test of the AT churn prediction non-stratified hold-out test set.
10.1 The structure of the SDSS and Galaxy Zoo combined dataset.
10.2 Analysis of a subset of the features in the SDSS dataset.
10.3 Features from the ABT for the SDSS galaxy classification problem.
10.4 A data quality report for a subset of the features in the SDSS ABT.
10.5 The confusion matrices for the baseline models.
10.6 The confusion matrices showing the performance of models on the under-sampled training set.
10.7 The confusion matrices for the models after feature selection.
10.8 The confusion matrix for the 5-level logistic regression model (classification accuracy: 77.528%, average class accuracy: 43.018%).
10.9 The confusion matrix for the logistic regression model that distinguished between only the spiral galaxy types (classification accuracy: 68.225%, average class accuracy: 56.621%).
10.10 The confusion matrix for the 5-level two-stage model (classification accuracy: 79.410%, average class accuracy: 53.118%).
10.11 The confusion matrix for the final logistic regression model on the large hold-out test set (classification accuracy: 87.979%, average class accuracy: 67.305%).
11.1 The alignment between the phases of CRISP-DM, key questions for analytics projects, and the chapters and sections of this book.
11.2 A taxonomy of models based on the parametric versus nonparametric and generative versus discriminative distinctions.
A.1 A dataset showing the positions and monthly training expenses of a school basketball team.
A.2 A frequency table for the POSITION feature from the school basketball team dataset in Table A.1[531].
A.3 A number of poll results from the run-up to the 2012 US presidential election.
A.4 The density calculation for the TRAINING EXPENSES feature from Table A.1[531] using (a) ten 200-unit intervals and (b) four 500-unit intervals.
B.1 A dataset of instances from the sample space in Figure B.1[542].
B.2 A simple dataset for MENINGITIS with three common symptoms of the disease listed as descriptive features: HEADACHE, FEVER, and VOMITING.