
A cuneiform tablet. Roughly translated, it says that party A rents his house to party B yearly, for a rent of 18 silver shekels. The renter is responsible for reroofing the house and fixing the drain
Twenty-five hundred years later, humans are still renting houses and haggling with landlords about their repair responsibilities. It would certainly not be out of place to find a BigQuery table describing exactly the same kind of data today.1
“It’s a tedious challenge to gather data and send it all to your business intelligence system. That’s where [DataCorp] saves the day.”
“It’s simple! While you kick back, [DataCorp] will get the data and deliver it to your destination.”
One company provided a list of the top 20 reporting solutions. Then they ranked themselves first, beating out the likes of Google Analytics and Salesforce. (Unlikely.)
Another company praised Google’s data solutions and then claimed that they were inferior to their own. The reasoning for this was riddled with obvious mathematical and factual errors. Talk about destroying confidence in a company that sells data.
What Is Reporting Now?
The lines have blurred among reporting, business intelligence, dashboarding, visualization, analysis, and data science. Most solutions do a number of these things well, at varying degrees of scale and price. To name a notable example, Salesforce does many of these things well. Consultants will happily fill any gap in their off-the-shelf solutions so you can get what you want and you will. You’ll also pay for that privilege—Salesforce’s professional services revenue alone approached $900MM in 2019.2 The reason that it’s worth talking about Google BigQuery as a data warehousing system is that the pay-as-you-go model allows your usage to scale with your budget. It will be some time before you hit a scale limit, and at that scale you will have substantial latitude in price negotiation with Google or any other vendor.
Here’s a disambiguation for the context of this chapter. “Reporting” is any thing that can show you reports. The intention is to avoid dragging along all of the baggage and blurry lines associated with the marketing speak. Your existing reporting suite, a BI tool, BigQuery saved queries, a cuneiform tablet—these all qualify. At the most basic level, your users need to be able to see reports about their data. How will you accomplish that?
Do We Still Need Reporting?
Occasionally, someone asks if traditional report suites have been outmoded by live analysis or real-time dashboarding and visualization. I usually say that it depends on what you think a report is. There is certainly a stigma from decades past that reporting is done at the end of the day, and no one can go home until the report run succeeds. In that model, reports fail frequently because of bad data or because something has timed out. Yes, I’d say that type of reporting is the bare minimum a modern business should accept. Lots of companies still do things that way, of course. The amount of time spent covering the people and process side of the equation is strong evidence for that. Most of those steps will apply no matter what data warehouse solution you’re moving to.
While I wouldn’t like to wait minutes or hours for a basic report anymore, other factors aren’t especially relevant to what constitutes a “report.” For instance, the speed at which a report refreshes doesn’t matter. A real-time view of data structured in the format of an old report is still a report. Furthermore, historical performance data is fixed. Last month’s sales report isn’t going to change. (Okay, shouldn’t change.) For historical reports, the major advantage BigQuery brings is the ability to connect it to the current data to see ongoing trends quickly.
A lot of the low-quality marketing literature out there will play upon the stigmatization of the word “reporting.” Many suggest that the mere existence of “reporting” means the data will be stale or different people will be looking at different data. Between BigQuery and your data governance program, you’ve already solved those problems. Now, when we speak about reporting, we’re talking about an analysis and UI layer on top of a solid system. We also want to make sure that business stakeholders can interact with the data and place it into their specific systems of choice. Even better is if we can both leave those stakeholder systems as authoritative and maintain the golden record in BigQuery.
This also opens the possibility that stakeholders can continue to use whatever systems they already have, while enterprise data analysis occurs from the warehouse. We’ll come back to that in a minute.
The challenge now, for reporting and for the next couple chapters on visualization and Google Data Studio, is delivering good, accessible reports. If you’re going to freshen up those key reports, you’ll need substance and style.
Reporting and Data Democratization
Let’s tackle this head-on. A primary theme of this book is to promote a collaborative, cross-organizational approach to data warehousing and the programs they fuel. I firmly believe that the success of such a program relies on these factors at least as much as the technology. As a result, there hasn’t been much coverage of the history of business intelligence programs nor why this sort of collaboration is fairly recent for a lot of organizations.
Another key theme has been the ease with which cloud platforms can tie together colossal amounts of disparate data. The technical and financial barriers are much lower as well. So why might collaboration be an issue? The answer lies on the flip side, before the cloud.
Historical Context
When a data warehousing program needed to be hosted on-site or in a data center, huge front-loaded investment was required. The technical know-how required to stand up such a program was present only within IT departments. IT departments became the owners of data programs by necessity. The existence of the warehouse depended entirely on them, thereby driving a priority where mere existence superseded useful output. Many projects failed before even getting launched, so this was actually a pretty practical use of resources.
Regardless, friction often developed almost immediately between “users” of the warehouse and the IT department. The reasons are all of the things we have been consciously avoiding—to name a few, mismatched expectations, technology failures, and poorly (or no) coordinated change management. Each led swiftly to conflict. The “business” began to see IT as a bottleneck preventing them from getting at their data.
This generalization was often completely unfair. Technical process is delicate and inscrutable. Without rational guardrails, data teams were often forced into inadvisable solutions. When data teams would ask business stakeholders what needed reports, the answer was usually “everything.” To an engineer, making all things highest priority is equivalent to saying “Here, you choose.” Poor structural decisions were made with insufficient information and no accountability on either side. An odd silver lining of BigQuery here is that it allows you to compensate to some degree for earlier bad decisions. But even that won’t matter without mutual investment and accountability.
Of course, if IT truly were a bottleneck, this would present a grave risk to the business. As SaaS solutions began to mature, business leaders realized that they could simply go around IT to get what they needed. Undoubtedly many of these leaders recognized this approach as risky, but lightning will find a way to the ground. In turn, many software-as-a-service vendors realized that they could print money by descending upon unsuspecting corporations and convincing them that their internal IT shops were incompetent. And thus “democratization of data” arose: freeing data from the prison of IT teams who just “didn’t get it.” This was also unfair. The expectation of an internal department is often that everything will stay the same while also getting better. A SaaS solution can require sweeping adaptation to integrate, but it’s couched as, say, a “digital transformation.” Internal departments rarely get the leniency to interrupt business like that. Furthermore, SaaS vendors have their own sales teams—who is responsible for selling a company’s own data program? (Sorry—you are.)
Integration as a Service
This created a patchwork of internal and external data systems vying for centrality. Information was indeed fragmented, yielding different results and leading to unsupportable actions. Since these programs ran outside of IT governance, there was no way to corral them. Many of these systems weren’t even in the IT inventory, or IT had been excluded from procurement and couldn’t say what they were paying for.
A new market need soon arose: tying all of those systems together into a master data management solution. As the pendulum swung back the other way, IT teams were often brought back into the fold and told to unite all of these ungoverned systems into one unholy mess. (Compare the IT arguments around bring-your-own-device as smartphones arrived.) A lot of these integration projects failed too,3 but at least this concept has some features of a successful data program. Data warehousing functions the way it should, and single views of data are possible. Unfortunately, drawbacks included a whole new round of chicanery about who had the best integration solution.
Gray Market Data
With the advent of cloud solutions, anyone can create a data program with no involvement from the IT department. This is what I mean by “gray market data”: if the internal solutions are not sufficient, people will begin taking whatever data they can get access to and doing their own analyses. The data started out coming from an official source, but now runs through an application somewhere that people have begun to depend on. Before, that meant some pivot tables in Excel. Now, your organization may already have a shadow data program that’s working better than the official one: but critically, it only works unevenly across the organization and can only serve the needs of the people using it. The business can’t get the full potential out of a program like this, and both the internal solution and its informal competitors will suffer. This also results in a lot of cost duplication and data silos, since more than one person will create gray market data.
“Democratization of data” does not exclude “single source of truth.” The purpose of promoting cross-functional collaboration is so that the best solutions can be chosen thoughtfully by representatives of each function and then implemented in a way that benefits the whole. Financial reporting solutions A, B, and C may be equivalent to the point that the department doesn’t care greatly which is selected—but technology knows that only C integrates with BigQuery. When all stakeholders have the same picture, these issues can be easily avoided. This prevents both integration pain and future pain as the two connected systems slowly grow apart.
Reporting as Democratization
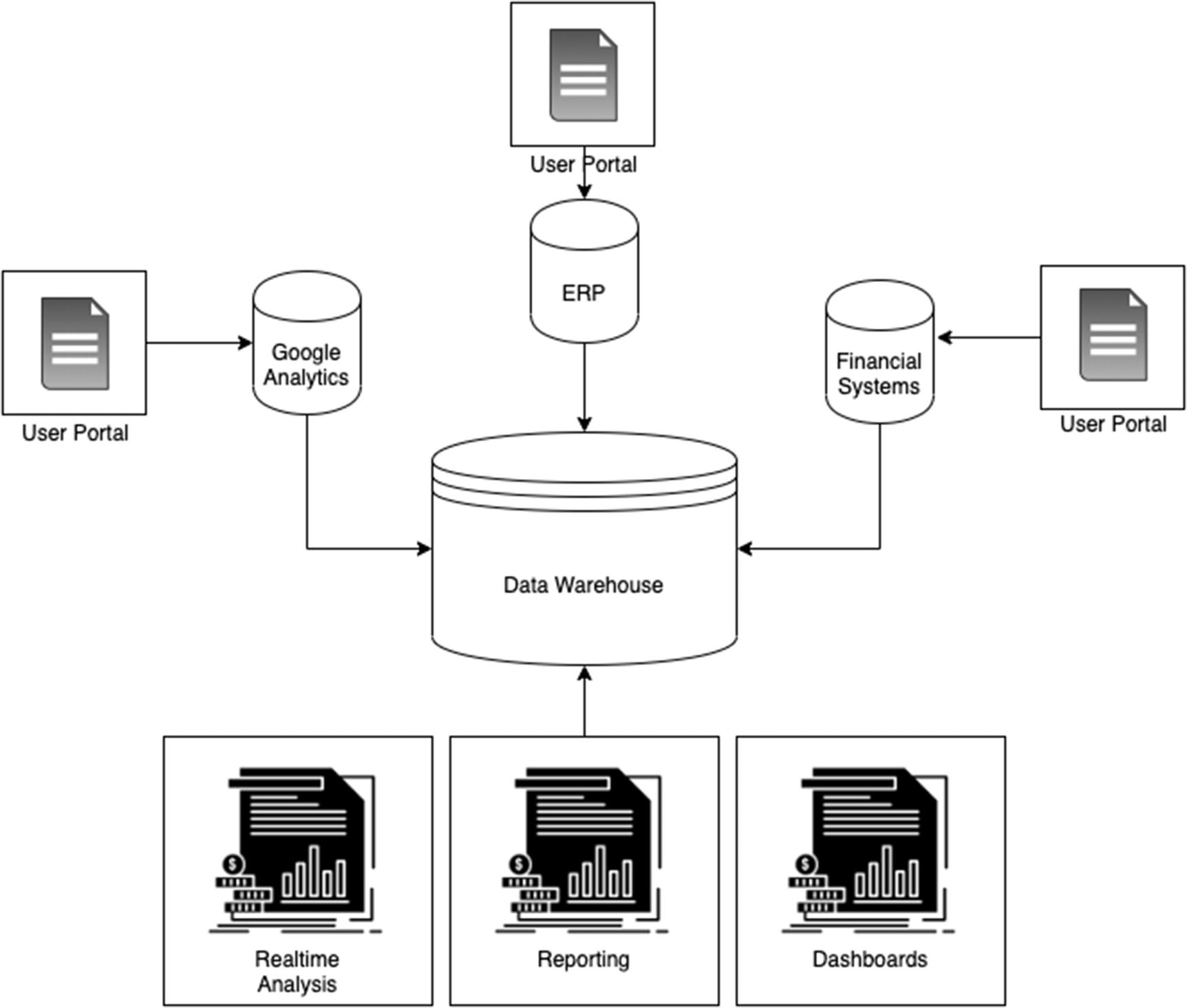
Architectural diagram of systems
In this model, the data is freely available to all parties. Finance can run its own reports on its own system; the SEO team can examine website conversion rates for its experiments and proceed accordingly. No one is bottlenecked by anyone.
But here is the critical difference—when someone wants to know if recent A/B test experiments are leading customers to purchase products with a lower profit margin, they go to the data warehouse. When they read the daily report on sales performance, it came from the data warehouse. The data program is in the middle without being in the way. When your teams and cross-functional organization look like this, your software solution will too. If you see the value of this model and want to build it from the inside out to resolve existing deficiencies, the answer is good old reporting.
History Repeats Itself
The latest iteration of the data democratization tug of war is that the data scientists are the only ones who can access the analyses and all of the custom reporting has to run through them. New decade, new bottleneck. There are two good reasons why a business leader might say this. One, the data scientists are legitimately afraid that someone will produce a bogus analysis on bad data and drive the business into the ground. (It has happened.) Two, the data is readily available for reporting and analysis, but no one knows how. Both come down to the same root cause—data literacy.
Reporting is the gateway drug to data literacy. If everyone in an organization is data-literate, then democratization of data will truly work. The data governance steering committee empowers people across the business to champion data literacy in their areas. Reviewing reports, their sources, and their statistical methods begins to create the data-driven culture. People begin to recognize data scientists not as bottlenecks, but as partners. (Feedback loops!) At that point, the quality of the data can sell itself. Vendors can only break in if they are truly offering something new and useful to the corporate data program. And most importantly, your data steering committee has the collective ability to understand and decide. The organization trusts the committee. Everyone has the reports they need. That is data democratization.
Reporting as a Product
It follows from the preceding text that the reporting function should be considered a formal product supported by the organization. In fact, it’s one of the least outsource-able products the company maintains outside of its core business. It represents access specifically to the corpus of data that only your organization possesses.
Through the B2B Lens
Of specific interest to business-to-business (B2B) organizations, the reporting system can also be sold to customers. Somewhere along the way, Microsoft popularized the term “dogfooding” for this practice. The sentiment goes: if it’s good enough for the customers, it should be good enough for you. Many organizations subscribe to this practice fully, Google included. Almost all products on GCP are tested by internal user groups before release.
Tenancy/permissions: Users must only see the data they have permission to see. This can be segregated at the customer level, immediately implying a permissions hierarchy for the data.
Accessibility/security: In order to make the product available for customers, it must be regularly available and accessible from customer locations. This implies creating a standard security model.
Logging: You will certainly want to know what customers are looking at, and customers may want to know the same about you. You will need a way to monitor data retrieval and audit history.
Integration with core product: The reporting system will need its own build and deploy process that corresponds with core product releases, causing internal teams to remember that it’s part of their portfolio.
Legitimacy: Adding a revenue stream to the product puts to rest any arguments about its relative importance for the purpose of resourcing and budget.
Customer feedback: Another critical feedback loop. Understanding how your internal users work with the system vs. how customers interact with it improves everyone’s experience. Sometimes these use cases are almost totally disparate.
Value proposition support: Customers using the reporting system will be able to see for themselves how much value your product adds to theirs. Discussions about additional business can be managed in a data-driven fashion, because all parties have access to the data. Forestall unhappy customers by acknowledging a shortcoming in one area, but bolstering the value of another. This also encourages customers to notify you before unceremoniously terminating.
Flipping the script: Now you can go to customers and suggest how your product might do something better than their internal group. Even better, you can sell something the internal group doesn’t even want to do. By selling into both the relevant department and technology, you turn the internal group to your side.
Case study: As a corollary to customer feedback and value proposition support, customers are more likely to be referenceable and will also collaborate on joint case studies. This is where all the successful quotes on B2B tools saying “DataCorp helped improve my efficiency by 73%!” come from. (Results may vary on whether pull quotes actually increase your sales.)
Chartering a Reporting Product
You may have thought to include reporting in your original data warehouse charter. If not, this is a good time to do that. Many of the considerations in your charter overlap with that for the general data warehouse. Accessibility of underlying warehouse data leads to easier report construction.
It isn’t necessary to rely on generating revenue as a function of the charter. Selling reporting to customers is an extra incentive on a necessary product. In fact, if you tie the product’s success to revenue generation, people may assume that an internal-only version is a failed product, when this is not the case. By the same token, don’t confuse this product with an argument to sell it—you may force yourself into a situation where the product doesn’t even get approved because of the additional hurdles. An unapproved reporting product is worse than no reporting product at all. (This is because you will still have reports; you have to. But all of the budget and resourcing and requirements will come from unallocated sources.)
However, you can use the criteria specified earlier to create an internal charter that conforms to your needs as well. Even if it won’t deliver straight revenue, it will deliver cost savings. With the warehouse populated, those savings can even be measured, in a statement of the form “If business leaders had ready access to data X, they could optimize decision Y to save $Z.”
Also, don’t write any checks you can’t cash. The data warehouse was a massive undertaking and solved many problems a reporting system would face, but there are still significant technical challenges in the reporting arm. Building in-house means wrestling with everything alone, but buying a solution means both figuring out how to integrate and being at the mercy of the vendor’s default implementation timeline. Even if your internal team is pretty sure they can do it in, say, a week, the vendor is likely to have a much longer default timeline to account for other clients and unexpected surprises.
Speaking of bounced checks, one parameter you have to consider with BigQuery is cost control. While you may look to move to a slot reservation model to avoid this, your solution should also include some method of ensuring that individual users can’t inadvertently bill thousands of dollars of queries. The most basic way is to run only static reports and cache them, which means only the report runner incurs cost. Some third-party solutions, like Looker, have their own support for cost controls as part of the reporting offering.
This solution (will/will not) replace our existing reporting solution.
The executive (will/will not) need to change location, process, or cadence of reports when this solution launches.
The following reports (list them) from the existing suite (will/will not) be ported over.
For reports that are moved over, they (will/will not) use the same raw data source.
For reports that are moved over, they (will/will not) use equivalent reporting logic.
The following reports (list any) will be improved versions of existing reports.
These reports (will/will not) be intended to replace original reports, but both versions can coexist side-by-side for a time.
The new reports (will/will not) match the old ones in the following areas (or just say “some areas,” if you don’t know yet).
Phase 1 of this project (will/will not) produce user-readable reports at its conclusion.
Phase 1 will include the following reports (list any).
This solution (will/will not) include real-time reports.
This solution (will/will not) include data visualization or dashboards.
This solution (will/will not) allow interaction with the results.
As a group who knows the organization’s senior leadership team, also explicitly head off questions about the characteristics of the solution. Since they’re not formal product requirements yet, say “We expect, but cannot yet guarantee, that…” For instance, you can say that you expect a daily report to run in 10 seconds “given current volume trends.” You need only specify this sort of detail at the charter level if you think that without it, you may lose the support of the executive sponsor(s).
Lastly, don’t lean in too heavily on past failures, if you have them. Prefer positive language and things the reporting solution can do, even if those statements are obvious callbacks to previous problems. Reporting is the basic interface most users have with your data warehouse, and you want to avoid accidentally undermining the credibility of the whole program by talking too much about failures specific to its front end.
In short, utilize the strengths of your data governance teams and plans. You know what needs to be said—go in and say it, and come away with assurance that each person commits to what you said.
Product Management
Your organization may very well lack the particular skill set needed to manage a high-quality reporting system. More precisely, those individuals who have that skill set are likely to be occupied with other products. This is another area in which SaaS solutions easily outpace internal teams; by definition, their product management teams are all skilled in this area.
Small organizations won’t even have dedicated product management for software tools, let alone anything to spare for a data warehouse or reporting system. That’s okay; we’ve been discussing all of the interdisciplinary skills required to make the data program a success. So let’s talk about why reporting is a product unto itself.
What’s unique to reporting and visualization is the front-end interface. Even if you use another provider exclusively, they will have a certain look and feel common to their tools. (Honestly, if they don’t and can’t explain it by rapid growth/acquisition/extremely diverse product portfolio, run away.) Furthermore, if you are looking to sell your reporting solution, the tool will have to match the look and feel of your own products. Regardless, it’s a consideration the data warehouse doesn’t have.
If you do have a product manager on your team, ensure they’re familiar with the capabilities of the data warehouse and the road map. Even better is if the product manager for the first phase of reporting happens to already be on your steering committee and has been looped into all of the previous discussions.
Defining Requirements
As a software product, the requirements for the reporting solution will take a slightly different form. Take care to cleanly separate the line between reporting and the underlying data warehouse: the reporting solution will use BigQuery as its source, and it can’t do anything that you haven’t built BigQuery to do. You’ll still be writing SQL queries to create the reports, but something like “build a real-time Dataflow from System X we forgot about” is either a predecessor task or out of scope.
If those requirements are popping up frequently, ensure that you’ve actually built the data warehouse appropriately to meet users’ needs. Go back to the original charter and your warehouse schema design; that should have prevented this kind of mismatch. If the warehouse matches the signed-off schemas, then this sort of requirements shouldn’t arise; if it doesn’t, figure out where the discrepancy occurred. A remedial project may be necessary to update the warehouse to serve effectively as the back end for this reporting solution. Be sure to run this as a separate dependency project rather than mixing in reporting solution requirements.
The charter can serve as the top-level information about how to construct this product. There are two primary areas in this interaction, even if you are wearing both hats: the “what,” as specified by the product manager, and the “how,” as specified by the engineering and/or integration teams.
The Platforms
The biggest “how” is what software systems comprise this solution. BigQuery, obviously, but this is also where you define external providers and connections to legacy systems and outline phased approaches to transition from one state to another.
You may need to draw out the multiphased approach so you can quickly specify what comprises the charter’s “phase 1.” Take it down the road as far as you can using optimistic extensibility, and then think about the minimum viable product for this phase (even if you hate that term). If you need help with the thought exercise, show the product manager the drawn-out phases and ask them to help you scope a minimum viable product (even if they hate that term). You don’t have to call it that; it’s a compact definition of what is required in phase 1 to meet your specific definition for “reporting solution.” It’s also intended to highlight scope creep, either in the form of extra requirements or in the form of requirements that are secretly data warehouse structural requirements and may not belong in this workstream at all.
The Reports
Of course, the primary functional requirement of this solution will be the reports themselves. How much effort defining this scope will require is a function of how many existing reports you have and how closely you can or want to adhere to their structure. The charter already has the list of what you need. In the simplest model, you’ve defined the framework and the front end, and anyone can do a translation from old format to new format. That’s pretty unlikely though and belies the reason for chartering a project.
This may also be the first time that you’re really testing your schema quality against the business problem. While you followed a consistent path from the initial warehouse sign-off to here, things change. The business may have even modified its way of doing things while you were building the warehouse. (Someone should have told you, yes.)
Prior to an official data glossary, the names of data points may have meant something else. This especially applies to department-specific definitions of things like “sales” and “conversions.” The best solution is to change the names. The second-best solution is to add a tooltip or description in the new report to indicate the changed meaning and the new term.
Reports have data points you can’t find in your warehouse. If this happens, first check the old report source to see if it’s a calculated column. Then decide based on its importance if it can remain a calculated column or if it should actually be a data point available to the warehouse directly.
There are data points that are missing from your warehouse. Put on your product hat and go figure out if anyone still needs those data points. If they weren’t captured in your schema, they may not be important anymore.
Multiple reports capture what seems to be the same piece of data, but they do it in different ways. It’s unclear whether they’re actually doing the same thing. Unfortunately, you’ll have to reverse-engineer the old report to understand how it got its data. Often, you’ll often find that the unexplainable values in the old report are actually just bugs no one caught.
A new report performs very poorly. This is usually one of two things. One, the report may hold way too much data in the default view. Stakeholders may insist they need all of that data on the page at the same time. You can either talk them out of it (product hat) or build a materialized view to create the report (engineering hat). Two, the report depends on an unusual query structure that doesn’t perform well in BigQuery. In that case, use an optimization strategy to improve the performance; don’t try to talk a user out of a report that already worked fine.
Several reports all do basically the same thing with minor variation. Most organizations don’t do this on purpose, so find a user of each of these reports, sit them down, and see if you can hammer out a new version that meets everyone’s needs. Here you may find that the person who insisted on bizarre variation #3 is no longer with the company.
You will encounter problems that aren’t on this list. If the answer isn’t a BigQuery technique found somewhere else in this book, use product management principles. If it were possible to capture all of those solutions in a single list, the next section of this book would be about training a machine learning model to be a product manager.4
Road Map
Following the first phase of reporting implementation, you can incorporate it as a product timeline inside of your program road map. Someone should own the role of product owner for reporting as well.
As part of your governance plan for adapting to long-term change, each significant enhancement or onboarding to the warehouse should have a reporting and visualization section indicating what support will be required. If the reporting solution is part of your core product offering to customers, this exercise needs to be repeated across each significant business feature across the entire organization.
As with the initial charter, don’t let reporting drive the data warehouse structure. Analyzing reports is a good way to learn what people are looking at and care about. Driving requirements down from report definitions into warehouse functionality is like signing a greeting card after it has been put in the envelope. It might work, but it won’t be pretty.
The Solution Spectrum
Somehow, you’ll have to answer the questions about which systems you need to construct your reporting solution. There are as many answers to this question as there are organizations. If a company has two employees, a founder and a CTO, the reporting solution might be “Hey, Andy, come take a look at this.”
Google Cloud Platform
You can use several combinations of GCP services to build a reporting function using BigQuery as the data repository. These solutions should have a similar lifetime as BigQuery itself. And as Google releases new tools for reporting and visualization, they will likely work with BigQuery right out of the gate. Upgrading to a better solution may get easier over time. You could also choose another solution and go back to GCP if/when that happens, but that means another project…
Roll Your Own
You’ve seen what can be accomplished with Cloud Functions, Cloud Scheduler, and saved queries. To build a simple reporting system this way, you could save and schedule a few queries to be delivered by email or to Pub/Sub where they’re picked up by a cloud function for distribution.
This wouldn’t take very long to build, but it would have a few disadvantages. Changing the schedule or running reports on-demand would require GCP access. Changing anything about the reports would require SQL knowledge. It would be fairly difficult for anyone besides the author to know if the reporting job had failed for some reason, and it could fail for basic reasons.
Use plain English for the subject and body of the email. Provide a table or some summary detail in the body so people can derive some information at a glance without looking at the report.
In addition to the plain English, you can include a tag at the end to make troubleshooting and searching easier. For example, “3/14/2015 Daily Sales Report [DSR_20150314]” is readable but still has a tag you can correlate.
If the full report is less than a certain size (choose based on your own environment’s parameters, say, 10 KB, 100 KB, or 1 MB), then attach the full report as a CSV.
If the report exceeds this size, or if you have any raw report data that is protected by regulations, do not place it in the body or attach it to the email. Provide a secure link requiring authentication. (You can use your data classification rules to decide this.)
Set an appropriate cadence for reports. Most people will quickly relegate reports to junk if they arrive too frequently. Or they’ll just reply “unsubscribe” to the unmonitored email, and nothing will happen.
If the report is only actionable when the data is anomalous, consider providing it only ad hoc when those conditions are met. For example, you can send daily emails about the performance of a sales promotion only while a promotion is ongoing. (We’ll talk about special occasion dashboards in the next chapter.)
Endeavor to give reports a consistent style and appearance. This helps to create an unconscious sense of trust that the data is coming from the “same” place.
That last one applies to every kind of reporting and visualization. It also applies to any reporting front end you may build or buy.
Google Data Studio
Google Data Studio is GCP’s reporting and dashboarding tool. It has native integration to BigQuery. Since it has similar characteristics to BigQuery, including management and scale, we’ll cover it separately in Chapter 18.
Other Third-Party Providers
There are endless reporting, analytics, and visualization solutions available. If your organization is of even moderate size, you might already have several. There really is no right answer, and the product requirements document is the best way to choose.
If you have no solutions at the moment, conduct a request for proposal (RFP) process with several providers. Evaluate them on all of the major areas of your requirements document and choose the best fit. Make sure that anything you need is captured contractually somewhere; after initial implementation, it can be hard to get that favor you were promised during the sales process. Actually, where did that person even go?
I looked at Google’s recommended BigQuery solution providers list5 and selected a few. You should visit the page or do other research yourself. This space changes on a quarterly basis; and each solution has its own ecosystem, blogs, and technical books.
Looker
Looker is a BI and data analytics platform that ticks most of the boxes in this space. While we’re focused on reporting at the moment, Looker also provides dashboards, application frameworks, and data science tools. Google acquired Looker in 2019, so it has deep integration with BigQuery while still being compatible with other systems like AWS Redshift and Snowflake. It can also connect directly to most of the data sources we’ve looked at for BigQuery, like Google Analytics and Salesforce.
Looker uses its own intermediate format, called LookML, to model relations and generate the appropriate SQL. Looker will actually use BigQuery as a repository for building temporary tables to improve data modeling performance and segmentation.
Intriguingly, its deep BigQuery relationship has a couple other benefits. For instance, it can generate input datasets for BigQuery ML (BQML) models, which we’ll use in Chapters 19 and 20. It also has cost controls to ensure users don’t go over a certain cost allotment when running reports.
Tableau
Tableau was founded in 2003 and helped establish the first wave of interactive reports and visualizations to replace traditional periodic reports. It’s a go-to solution for many organizations now and connects well with most data sources.
The BigQuery connector is native, and promisingly, the documentation is specific about which API calls it uses under what circumstances. It runs directly against BigQuery, meaning it handles large datasets well. On the flip side, since it also uses generated SQL, cost control could be a real concern. It’s also possible to extract static data from BigQuery, which lowers cost but raises latency.
If your organization is already using Tableau, the reporting product does not need to be a catalyst for changing that.
MicroStrategy
MicroStrategy is the oldest player, founded in 1989, and has been doing enterprise business intelligence since then. MicroStrategy does not use a native BigQuery connection and instead relies on the JDBC/ODBC drivers. Support was recently added for the Data Transfer service, so query reads should be reasonably fast.
MicroStrategy’s solutions are geared fairly high up the market at the enterprise level. It wouldn’t be a good choice for an organization just getting started, especially since BigQuery integration is not its first priority. However, if your organization already uses MicroStrategy, you will be able to run your reporting solution against BigQuery.
“DataCorp”
DataCorp is my catch-all name for a generic vendor. Many people are happy customers of “DataCorp,” or it wouldn’t be in business for very long. But is it right for you?
Do you integrate with BigQuery? If so, what method do you use to connect? Native API? ODBC/JDBC? Something unusual?
Which advanced BigQuery features does your connector support—for example, Data Storage API, STRUCTs and ARRAYs, results surfaced through views or stored procedures, and so on? Do you plan to support more?
Do you support reporting directly from BigQuery, or must the data be transferred into your system first?
How do you manage cost controls when performing BigQuery calls? Is there work on our side to set that up?
What is the support model for your solution and BigQuery? If we have issues with the connector, whom do we call?
Do you have referenceable clients whose primary data warehouse is BigQuery? May we speak with one?
If you work for a data analytics company not listed here, check again in the second edition.
Other Solutions
You may already have a reporting solution, and it’s not on the table for you to change it. There are still some options remaining to integrate data. However, also examine if it represents an organizational dynamic. An issue like that would be better addressed via people or process, rather than attempting to conform to a flawed way of doing things.
Here are three more solutions, ordered in decreasing order of desirability.
JDBC/ODBC Drivers
In Chapter 5, we discussed the idea of using the JDBC standard as an abstraction to connect to other systems and treat them as relational stores.
The same is possible in the reverse direction, using BigQuery as a JDBC or ODBC source . Google has partnered with Magnitude Simba to produce both drivers for BigQuery. You can find more information and download the drivers from the BigQuery site.6 ODBC drivers are available for Windows, Mac, and Linux. As long as you download the drivers from Google’s site, they’re free.
BigQuery loading, streaming, and Dataflow are unavailable.
You can use standard INSERT statements, but since OLTP is an anti-pattern, it will be slow and you will quickly hit quotas trying to use it like a regular database.
Nested and repeated data will be output as pure JSON, so working with this data may be cumbersome.
You can get around the last of these limitations by flattening tables out into intermediate views, which you can query from the source system to avoid dealing with JSON. This obviously has its own problems though, so if you are using deeply nested data in your reports, it might warrant additional consideration.
The Simba drivers do support querying via the Storage API, so you can still get high throughput on reads.
Lastly, if you are purchasing a vendor solution and they have touted their integration with BigQuery, find out whether it is via a native connector or if they are just using the ODBC or JDBC drivers themselves. Most BI tools have ODBC/JDBC integrations, which is why I’m suggesting it in the first place. Make sure you understand the nature of the connection if it’s being used as a selling point.
This is currently the best way to get data into Amazon QuickSight too, as it has no native BigQuery connector.
Intermediate System(s)
This is the data equivalent of plugging a Bluetooth receiver into a cassette tape adapter, so you can connect your phone via Bluetooth and listen to Spotify in your late model vehicle. In other words, it may work, but it’s going to be hacky.
If your existing reporting solution can integrate with other platforms, and those platforms have JDBC/ODBC connectivity, you could use the intermediate system to forward the data. This has basically all of the disadvantages of a flat file option, except that the latency and possibly the performance will be better. The major disadvantage is that when something goes wrong in a chain of responsibility like this, it’s incredibly difficult to figure out what failed where.
Flat File
This isn’t referring to files you need to send to customers, vendors, or partners. Flat files are still a perfectly reasonable way to transmit data in a common format. This refers to using them to power your fully internal reporting system.
If you really have no better option, you can write a Cloud Function and schedule it to query tables and push out flat files to SFTP or a folder. (Or a Gopher server.) There are numerous disadvantages, including latency, performance on large tables, reliability… Actually, there aren’t really any advantages at all. This is really a choice of last resort if you need to ship data to an IBM AS/400 server powered by a hamster running in a wheel.
Cuneiform
First, purchase a substantial amount of raw clay and some reeds for fashioning into styluses. Then, learn ancient Sumerian, along with the cuneiform writing system, which consists of thousands of symbols and syllables. This will take somewhere between 8 and 12 years.
In the meantime, purchase an actual building to serve as your “warehouse.” To be clear, it will be literally a warehouse. You will need climate control and careful storage to ensure that the impressions on the clay don’t smudge and fade away within days. (However, this could be used as a form of automatic tablet expiration.)
Devise an education program for the thousands of scribes you will need to hire to imprint the clay. In addition to learning the cuneiform writing system , you will need to employ an anthropological linguist to create new symbols to represent modern technological concepts inexpressible by standard cuneiform. In order for the tablets to be readable to future generations, these symbols will have to fit naturally into the existing symbol corpus as well as ancient Sumerian, requiring substantial study of morphology and historical context.
Purchase one computer terminal per scribe. Make sure that your DevOps group creates a common image that will be able to call an API on GCP.
Then, write a custom Cloud Function that takes a BigQuery query as input and splits the output row by row. Employ parallel processing techniques to distribute the query as a workload across all scribes in the cluster. Each scribe reads a data row from their terminal screen and impresses it onto their clay. The scribes will also need a rudimentary task signaling system, like a button that they can press when their row has been transcribed. (Error checking is out of scope for this solution.)
If a scribe does not press the button indicating completion of the work unit after a predefined amount of time, return it to the work pool. Like commodity hardware, scribes will often fail; keep a training program running constantly so that you can easily swap in a new scribe when this happens. Appropriate water cooling systems can raise the mean time between failures (MTBF) of nodes/scribes.
Finally, you will need a transport system to load the completed tablet-rows into the warehouse. Calculate how much data your warehouse can store and provision a trucking fleet accordingly. Note that this can be difficult to manage in a scalable fashion. Eventually, you will need to purchase or construct additional warehouse locations, preferably in multiple regions for data redundancy. Organizing the tablets within each warehouse location for later access is a formidable logistics problem, but you made it this far.
This approach has a number of significant disadvantages, chiefly among them being its incomprehensible stupidity.
Summary
Reporting is a basic function of written communication and has taken on many different connotations. In an attempt to avoid a clash with marketing jargon, “reporting” is defined here simply as something that can produce reports. Many negative opinions of the reporting function are based on mismatched expectations or simply different definitions of the word. To avoid this, consider reporting to be its own product and follow a product lifecycle process for building it. Do this as formally as you are able. In terms of software solutions, the landscape is endless. Use your technical and product knowledge to select something that works for you. If you must integrate with an existing system, choose the highest-fidelity method available to bridge the two systems.
In the next chapter, we’ll cover a related topic with different implications for your data culture: visualization and dashboarding.