One reason you’re probably interested in this topic is that you agree with me that organizations run on data. Regardless of the maturity of the organization and any data collection practices you may already have in place, the purpose of a data warehouse is to centralize how users can access data accurately and reliably. Prior to the data lake concept, it was also to put all that data in a central place. With BigQuery, that last step is not always necessary. However, your job includes making that decision based on the nature of the data. The centrality in any warehouse model served the larger purpose of accurate and reliable data, and that consideration is unchanged regardless of this or any future model.
In this chapter, we’ll discuss the nuts and bolts of building your datasets and other database objects. We’ll also cover the other part of the process: satisfying your stakeholders and making sure that your execution satisfies the charter you’ve written. By the end of this chapter, you should have a shiny, new, and empty BigQuery project in which to begin loading or migrating your data.
If you don’t have a charter, I strongly recommend you go back to Chapter 2 or Appendix B and sketch one out. Even if your organization is very small, projects have a tendency to “scope creep” and never quite get finished. A data warehouse is useless without users, and everyone’s satisfaction level will be much higher if you can declare a start and an end to the project. Once your first phase is complete and the organization improves, I promise you will have more requests than you know how to deal with.
You may have the opposite problem, that is, you already have more requests than you know how to deal with. If this is the case, writing a charter should be even easier. However, finding the time to write one may be the challenge. As the venerable Admiral Jean-Luc Picard once admitted doing, don’t make perfect the enemy of the good. Okay, lecture time over.
The Data Model
If you want to climb the ladder from data to information to insight, the first real rung is data modeling. Decisions made about the model are easy and malleable when you have nothing loaded, but once you’re operating in the terabyte or higher range, it won’t be as easy to make fundamental modifications. I’m hopeful that advances in technology will eventually eliminate that hurdle as well, but for now it’s still a good practice to think about the model first.
In Chapter 2, we discussed these questions as relevant to project planning. As a result, you should have a pretty good idea what your key entities are, their relationships, and the relevant grain of time. Here, I’m going to revisit one additional concern: speed of event creation and value of historical data.
Intake Rates
When I talk about intake rate, I’m speaking generally about orders of magnitude. I typically use a brief rule of thumb to estimate based on how many people or things can generate the data. For example, if you need to insert a new row every time one of your salespeople signs a new client, that’s a heavily manual process with a bounded maximum in the billions (conservatively, if you could sign up every human on the planet). If the event is a new order that any website user can input, that could move much faster. If it’s an event per user click or keyboard stroke, you could see billions of records a day. And if it’s something other machines are generating, like error or health logs, it could be trillions or more. Your model should take this into account.
Value of Historical Data
This principle tends to operate in inverse to the intake rate. Using the preceding examples, you are going to want to know about a client for the entire life of the organization. On the other hand, a server event log is rarely persisted for more than 30 days. Essentially this question informs your data model by helping you understand if the important property of a particular data point is recency, ease of analytics, or only in combination with other data.
Creating the Data Model
Armed with your charter and a rough idea of the entities and relationships that are important to you, it’s time to get down to business. To start, we’re going to make sure that you have a dataset to put all of your objects into. Throughout this book, we’re going to stick to working mostly within a single dataset. At moderate scale, one dataset should be enough. However, if you need operations at the dataset level such as control of geographic location of the data or you want a permissions scheme that requires multiple datasets, there’s no reason not to do that as well.
Making a Dataset
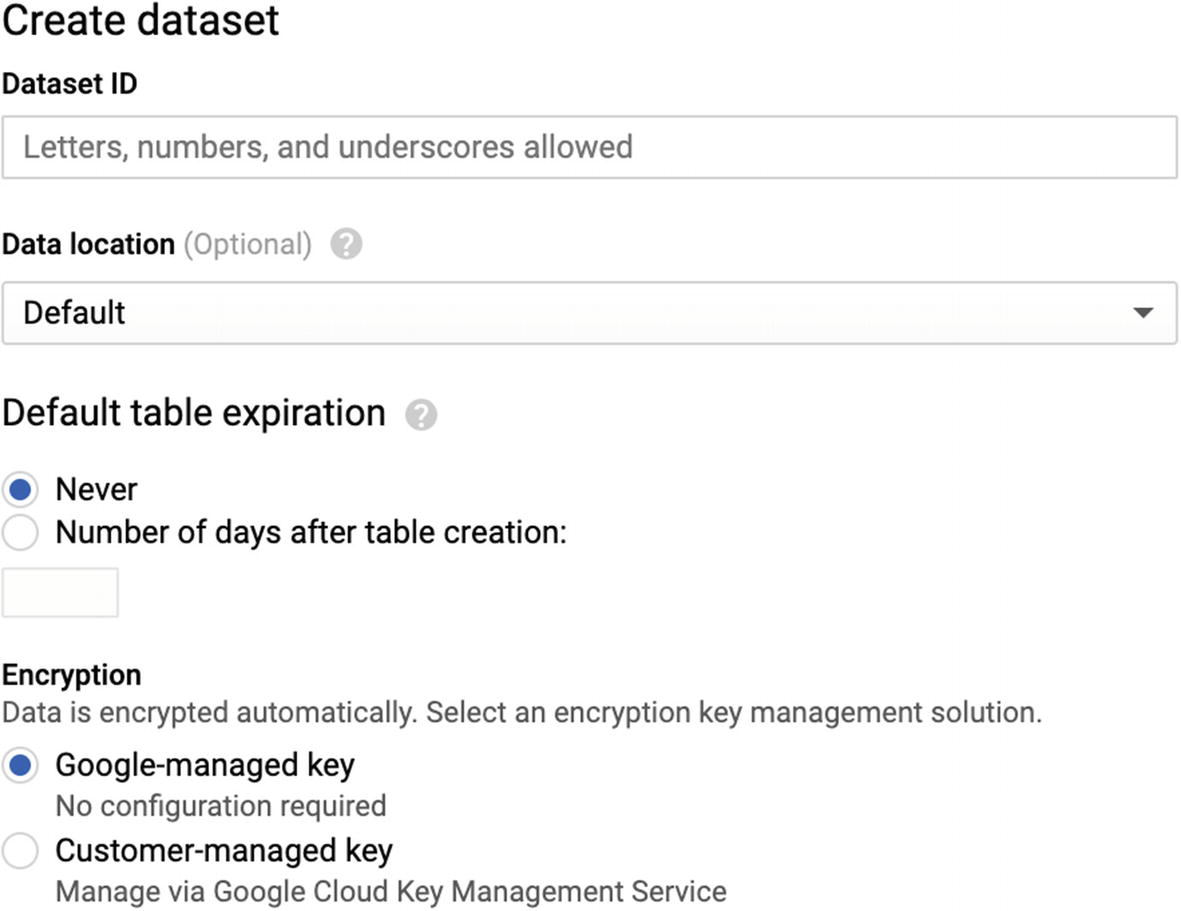
Create Dataset View
There isn’t much configuration to do here. Enter a relevant dataset name (i.e., “companyname_data_warehouse” or “main” or whatever). For some reason, despite Google’s typical convention being hyphenation, the only punctuation allowed in dataset names is underscores. That has deterred me somewhat from using overly complicated names, which is probably okay. You don’t need to set a data location, but if you have legal or compliance reasons to do so, you can do that here too. You also likely do not want tables to expire in your data warehouse, so leave that set to “Never.” Click Create, and you should immediately get a new entry in your project.
Another thing to consider when deciding how to create your datasets is you can copy a whole dataset from one project to another, but only one at a time. Similarly, if you want to make a dataset public, you can do that easily too. Google’s order of magnitude for how many datasets you can have in a project is something like “thousands,” so you don’t need to worry about that limitation too much. Google also puts the maximum number of tables in a dataset at thousands too, so depending on how much you’re going to store, this could be more or less important to you.
Creating Tables
Again, we’ll start this through the UI to show all the available basic options. In this chapter, we’re also focused on setting up your warehouse from scratch, so we’ll stick to the basic methods of table creation. In later chapters, I’ll go into greater detail about streaming from existing sources and setting up syncs from live data.
It’s also worth noting that you don’t even need to create a table if you’re going to be loading data from an external source. You’ll be able to supply the schema for that data (or in some cases, to auto-detect it) when you begin loading.
Open the dataset you just created and click “Create Table.” A sidebar will slide open. Let’s go over the options.
Source
One of BigQuery’s strengths is its ability to create tables from many different sources and formats. The most basic way to make a table, of course, is to create it empty. The three following methods are variations on a theme: you can take a file from Google Cloud Storage (GCS), your local computer, or Google (G Suite) Drive and create a table from it.
Empty
Your table will be created with no data in it. If you are in fact starting from scratch, this is your only option!
Google Cloud Storage
Google Cloud Storage is the underlying file storage system for Google Cloud. If you’re familiar with Amazon S3, this is an equivalent concept. You can load files of arbitrary size into buckets and then access them with a URI in the form gs://bucket-name/filename.
Upload
You can also upload a file from your local machine. Local uploads are limited to 10 MB. If you’re uploading larger files, Google Cloud Storage is the best option.
Drive
Drive is Google Drive, the consumer G Suite product for storing and organizing files. You can load a file directly from its Drive URI. This includes things like Google Sheets, which actually create a live federated source against the Drive file.
Google Cloud Bigtable
The last method, Bigtable, is a little different. Bigtable is Google’s NoSQL database solution, closely resembling Apache HBase (think Hadoop). When you link your BigQuery project to Bigtable, the data remains stored in Bigtable and uses its CPU cycles, but you can access and link it via BigQuery. This process is more involved than the others. If you have existing Bigtable implementations, it is worth considering.
Format
Let’s cover the formats in which you can instantiate BigQuery tables.
CSV
Good old comma-separated value (CSV) files are probably the best way to intake your data if your current business intelligence tool of choice happens to be Excel (or Lotus 1-2-3, dBase, Notepad, etc.). It’s suboptimal because CSV doesn’t support nested or repeated fields. On the bright side, pretty much any tool can output it. If you’re interfacing with older systems and need to load data periodically, it might be the only format that they can agree on.
When you choose CSV as an option, you will get several advanced options to do some basic data transformation on the file, such as setting the field delimiter, skipping header rows, and allowing jagged rows (i.e., rows that have empty data in trailing fields and don’t use commas). You’ll be familiar with all of these if you’ve ever used a standard SQL bulk import/export tool.
JSONL

JSONL vs. regular JSON
Avro
Avro is an Apache data system used for serialization. It has some substantial advantages over plain JSON, namely, that it uses a compact binary format that takes up much less space than JSON. It also defines the schema for the data internally, which means you won’t have to figure out what each column is supposed to be. It’s supported by Kafka and other data streaming technologies, so if you’re using one of those, you probably already have some Avro somewhere in your organization.
The format is not human-readable, so if you want to work with the data, loading it directly to BigQuery is probably even more convenient than converting it to JSON and trying to work with it that way.
Parquet/ORC
Parquet and ORC are similar Apache columnar storage formats used by Hadoop. If you’re running a Hadoop cluster and want to pull data out of it for analysis in BigQuery, one of these two formats should work.
Destination
The project and dataset will be populated by default with the context you were in when you clicked Create Table. Ensure that’s what you want and pick a name for the table. No hyphens!
A Little Aside on Naming Things

Table name with blinking cursor
Not to add to the pressure, but your task here is even more daunting than your average programmer trying to name a loop variable. If you do this right, your entire organization will align on your names and definitions, and it will literally become the glossary for the business. Like I said, no pressure.
The reason the first two chapters of this book were so focused on understanding your business, building consensus, and getting ready is that by the time you reach this step, you shouldn’t have that abyssal dread looking into the empty text box. You already know what your table names should be. They’re things like “accounts” or “users” or “sales” or “clients” or whatever terms you’ve heard your stakeholders using. Where those terms overlap, you’ve teased out the difference between sales orders and invoices.
If everything is messy and people can’t align on terms, you have an even bigger responsibility here, which is to disambiguate the names for them. If sales calls harvested email addresses “captures” and finance calls credit card charges “captures,” you know they’re not the same thing. You’ll get it right.
Schema
Some of the source formats have schemas built in. If you use a format that does not, like CSV or JSON, you can have BigQuery attempt to auto-detect the schema. This works fairly well, so if you’re in a hurry to get your data loaded, go ahead. For any critical (or basic warehousing) tables, I’d recommend manually specifying your schemas so you can be sure the data fits the schema and not the other way around.
Auto-detection works by randomly sampling entries from your source files and using them to extrapolate the likely type. In the case of CSVs, it can also auto-detect your delimiter and name columns according to header rows. If you attempt to load conflicting data into the same table, you will get unexpected and likely unwelcome results. In these cases, you could load raw JSON as a STRING type and use the EXTRACT_JSON() method to pull it out on-demand, but this is unconventional and you’ll forfeit some of the performance and structural benefits of stronger typing.
If auto-detect is unchecked, you will see the view for adding columns manually. There are two ways to do this, using the UI or using text. The text mode is a JSON format for describing columns, and it’s also what you would use for the command-line or API modes. You can switch freely between the two modes to see what the current JSON output for your column definition is.
Now’s as good a time as any to go over the data types and their meanings. These will all be familiar to you if you have worked in SQL before, with the possible exception of RECORD, so skip over this if you’ve done it before. Google’s own reference is far more exhaustive1 so I won’t reinvent the wheel here.
In addition to the value ranges specified here, all data types except ARRAY are nullable.
STRING
Strings are your garden-variety character data. Note that by default, these strings are all UTF-8 encoded. Unlike regular SQL, no size specification is necessary—any character-based data will get mapped to a UTF-8 string. There’s no predefined maximum size; you’ll just have the regular quotas on query length and record length to deal with. If you need a UUID, this would also be of STRING type. (Google supports UUID generation with the GENERATE_UUID() function.)
BYTES
Variable-length binary data. While the BYTES data type has most of the same functions as STRING, this is the raw byte array vs. the Unicode version stored by a string. This is good for things like password hashes, for example.
INTEGER
Your standard 8-byte integer storage.
FLOAT
8-byte, double-precision floating-point numbers. Conforms to the IEEE-754 standard and thus is not the preferred data type for encoding currency.
NUMERIC
16-byte, exact numerical values. This is the type to use for money and other financial calculations where you don’t want to deal with IEEE-754 floating-point errors.
BOOLEAN
In this particular flavor, a two-value type represented by the keywords “TRUE” and “FALSE.”
TIMESTAMP
Timestamps are your invariant, absolute point-in-time, microsecond precise types. Pretty much every row you store in BigQuery should have a timestamp on it somewhere. Additionally, it’s the natural partition for any tables you are going to partition. When you view it in a table, it will show as a UTC date/time. Internally, it looks like a seconds offset from the UNIX epoch, that is, January 1, 1970, at midnight UTC. (As an aside, you can verify this with the simple command SELECT TIMESTAMP_SECONDS(0), to convert from epoch time to a timestamp.)
DATE
It gets a bit tricky here. Unlike the canonical TIMESTAMP, the DATE type describes a calendar date without a particular timezone. As such, it doesn’t mark a specific period in time, but rather the date as a user would see it on a calendar. The canonical format here is simply YYYY-[M]M-[D]D.
TIME
This is the same thing: a time independent of a date. I may look at my clock and see it is 1:30 PM. This would be relevant for things like “Do customers purchase more frequently in the afternoon?” “Afternoon” is a subjective term based on where the user is located, so we would want to look at the civil time in all cases. On the other hand, what about looking at behaviors during a fixed event, such as a big football game in early February? In that case we’d want to look at the absolute TIMESTAMP in all timezones.
I’m going into detail here because this sort of nuance turns out to be really important in data warehouse construction. Granted, as long as you have the absolute point in time that an event occurred, you can reconstruct these other values, but non-technical users don’t like being made to think in UTC, even if it is the most logical storage format. Just a thing to keep in mind as you continue building things out.
GEOGRAPHY
The GEOGRAPHY type is an extremely powerful addition to a dataset. Consider the days before GEOGRAPHY: designers had to encode latitude and longitude in separate floating-point values. Calculation of distance or a bounding box was an intensive trigonometric operation that was easy to get wrong. However, using the GEOGRAPHY data type, we eliminate all of that complexity. Now we can create deep insights against the specific location or area at which an event occurred. This helps us easily answer questions about the closest store to a customer or the density of spatial events. For now, it’s best to remember that a single GEOGRAPHY value is not simply a latitude/longitude coordinate: it is in fact a collection of points, lines, and polygons describing topologies on the oblate spheroid better known as Earth.
ARRAY
An array is an ordered list of zero or more elements. Note that ARRAYs cannot contain ARRAYs—the Google documentation cheekily includes it as an invalid example since I suppose it’s a common question. If you want to nest ARRAYs, you have to store an ARRAY of STRUCTs that themselves contain ARRAYs. Nothing like giving your data types a workout. But this is all critical to the discussion around using nested elements whenever possible; this is one way you are going to achieve that. ARRAYs can also not be NULL.
Another interesting property of BigQuery ARRAYs is they are neither zero- nor one-based. If you want to index into an array, you can use the OFFSET function for a zero-based offset and ORDINAL for a one-based offset.
STRUCT (RECORD)
You will see this referred to and used in standard SQL as a STRUCT, but BigQuery also calls it a RECORD. Creating and using STRUCTs, in general, creates anonymous types using the internal fields. This is how you will nest data inside rows. Remember that your internal fields should also be named if you want to use them in comparisons. You can’t do much comparison on the STRUCT itself. Similarly, you can opt not to apply types to the fields of the STRUCT, but you will generally want to do this for any data with sufficient structure. Since this is such a crucial concept in BigQuery design, we’ll come back to it again later in the chapter.
Mode
You will also have to specify the mode of each column. The options are nullable, required, and repeated. Nullable means the field doesn’t need to be specified for every row, as with regular SQL. Required, predictably, means the field is required.
Specifying a column as repeated essentially means that you get an array for the column where you can have many values for the same field. You can use this instead of a standard outer join to get information about related data directly into the same table. We’ll go deeper on this in the following section.
Once you’ve finished specifying your columns, switch back over to the text view so you can see the formal representation of your table schema. It’s fairly easy to read, so you can also use this as a quick way to spot-check your design. (As a side note, the current quota for column count is 10,000. I can’t personally think of a well-designed use case that would require more than 10,000 columns, but you never know.)
Partition and Cluster Settings
Next up are the partition and cluster settings. We’ll cover these topics in more detail in the following. There are definitely trade-offs to using either, but in terms of cost savings and maintenance, they are each a huge benefit.
Advanced Options
The advanced options will change based on your other settings. Most notably, for the CSV format, you’ll see the settings for delimiter and header row skipping, so configure those if necessary (and you’re not using schema auto-detection).
There are also options here, as with most object creation, around key management. Don’t worry too much about that; we’ll cover key management in a later chapter as part of permissions and security.
Lastly, this is where you specify the behavior you want the import to take. The three options are Write if Empty, Append, and Overwrite. Write if Empty will only load data if the table is empty. Appending will add the data to the table at its end. Overwrite will wipe any data stored in the table. In this case, since we’re making a new table, it’s going to be empty, so you can leave the setting as is.
Partitioning
Partitioning is pretty basic to understand: imagine that if a BigQuery table were stored as a file (which sort of is), partitioning would split that file by date, creating many smaller files. This would be great if you tend to look over a small number of files (date ranges) at a time, but more intensive if you query across huge ranges. On the flip side, if you have a torrential amount of data going into this table, you can partition to prevent the table from growing arbitrarily large. Small tables won’t benefit much from this optimization.
While you can continue to modify the underlying schema of the partitioned table, you can’t rename the table or change the partitioning itself. The best way to handle this scenario when it arises is to create a new structure and copy the existing data to it.
BigQuery limits the number of partitions in a table to 4,000, which works out to a little under 11 years if you’re partitioning by day. Luckily, you can also use other date grains to create partitions, such as months or years.
The value of this feature is in lowering query cost. If you have gigabytes of data coming in every day, using a partition will make sure that BigQuery only needs to scan some of the files to get you the data you need.
Let’s say you have a log file storing data for the past year, and I want to see log entries from last Thursday. In a partitioned table, BigQuery is only going to search that single date’s file to get me the data. In an unpartitioned table, it’s going to search the entire year to find matching records, which is potentially 365 times more expensive. (Clustering might help; we’ll get to that.)
A secondary benefit is that you can automatically set partitions to expire. In the case of storing logging or error messages, you might only need to keep a few days’ worth of data. Setting the expiration date will cause BigQuery to automatically delete the data at the specified time, saving you money and query time across the full range of partitions.
Partitioning by Integer
The newest feature in this space is the ability to partition by integer. This opens up all kinds of other options to partition your tables by the right value. You could partition by other primary keys in your system, if the same pattern of thought applies. Translated into integers, it comes down to knowing the query pattern. Will you want to frequently access specific ranges of this integer? Is there enough data per integer range to make the effort of partitioning worthwhile?
To configure this, you will need a min, a max, and a range. For instance, if you specify min of 0, max of 100, and range of 10, you will end up with partitions on {0, 10, 20, 30, … 90, 100}. If you can visualize your dataset being sliced in this way along some axis, then you have a good candidate for integer partitioning!
Another good use case for this is if you have an external system loading data that defines its own sequential identifiers and you can’t change them. Even if you add your own ingestion time to make it compatible with traditional partitioning, users are probably going to want to use the external ID as a reference into the data. This way you can let them do that and still gain the benefits of not having one massive table.
Clustering
Clustering is a very powerful tool to control cost and to give BigQuery some hints about how to execute your query. I can’t stress how important clustering is. Remember that BigQuery is column-oriented storage. Clustering tells BigQuery that you are likely to search tables by certain columns and applies some weak sorting so that it only needs to go look at those clusters when you run the query. Unlike partitioning, you don’t have to be aware of it behind the scenes; BigQuery will use the hints automatically to optimize your query. Additionally, it’s free, and it will recluster your data whenever you load more. Because of this automatic property, you don’t need to do any maintenance on your table’s clusters.
When you create your table, think about the columns users are likely to want to search by and specify them as clusters. For example, if you operate in the United States on a state-by-state basis, cluster on the state abbreviation to get additional efficiency when looking for rows that occurred in a specific state. If you’re familiar with relational SQL design, this is a similar exercise to specifying clusters (or index hints) there. The limit for clustering columns is four, and you can’t choose new cluster columns on a table after you create it, so this is a good time to go deep on design. To be fair, you will probably still get some benefits from clustering even if users mostly use other columns, but in the long run it will cost you more.
This also means you could in some cases use clustering as an alternative to partitioning. If you cluster by day, you get similar advantages to partitioning by day, but you don’t have to query across partitions. Google recommends this when partitioning would create less than 1 GB of data in each partition or when partitioning would exceed the maximum limit allowed (4,000 at this writing, as mentioned earlier).
To most effectively use both partitioning and clustering together, first partition by date or integer, and then inside of that, specify more finely the columns to cluster.
I know this is a lot, but at the terabyte or petabyte scale, we’re talking about a lot of data savings. Without any partitions or clusters, even a simple query to return the first row of your data is going to scan the entire table, adding up to a significant chunk of change over time. This is one thing worth getting right now as you design your models.
Reading from BigQuery
No doubt you will want to design methods by which your users will read data from BigQuery. In the later chapters, we will discuss all manner of methods for piping data in and out of the system, and ultimately in Chapter 16, we’ll talk about the ways in which you will surface data to users. But what about the day to day, when you need data in the system for your own purposes? There are a few ways to go about doing this, largely mirroring the ways in which we access BigQuery for other purposes.
BigQuery UI
It goes without saying, since it is our primary interface, but you can always just access data using the web console. Using the web UI, you can download a limited amount to file or just view it in your browser. You can also use the BigQuery UI to directly pipe it to Google Data Studio, which is covered in Chapter 18.
bq Command Line
The command-line tool allows you to perform all of the operations you can perform in the UI and then some. It’s also a way to retrieve data; you can run the query text directly, or you can refer to datasets and tables to retrieve them or send them to a file.
BigQuery API
The API is what the other two methods use to interact with BigQuery. You can also use it directly in your code to retrieve data. We’ll interact with the BigQuery API to do data processing in other chapters, but it can be a simple retrieval mechanism as well.
BigQuery Storage API
The BigQuery Storage API is not the same as the BigQuery API. It doesn’t provide a job construct, nor does it provide access to modify tables or datasets. What it does do is provide an extremely high-performance way of extracting data from BigQuery. It can export data in the Avro format or the Apache Arrow format, and you must write code to access it. There is a Storage API SDK for Python and other languages to facilitate access, but you can manage streams directly.
You can also initiate parallel streams over different ranges of data, allowing for efficient access to subsets of your tables for other purposes. One major use of the BigQuery Storage API is to allow fast connectors to third-party systems.
Summary
Understanding your data model is crucial to building a sustainable, extensible data warehouse. BigQuery has both familiar and unfamiliar patterns for those who have built a data warehouse in the past. Making good decisions about how to structure your data involves knowing its source, the relationships between your entities, and how to best store it following BigQuery practices. Use clustering and partitioning as much as possible to lower cost and optimize data loading. When it’s time to pull data back out of the database, there are multiple ways to do so depending on your needs.