Building a data warehouse in a new organization can be challenging. While we tend to conceive of technology initiatives as mostly the hard technical decisions, anything involving data becomes far more investigative. You will want to use a lot of different skills aside from your ability to rationalize and normalize data structures. We’ll talk extensively about how to frame that discovery and learn how to “right-size” your warehouse for the environment. You’ll also want to figure out where you can make trade-offs and where you will want to invest your time to improve things in the future.
A major part of a successful warehouse project is business acceptance and understanding. Gartner estimated in 2005 that 50% of data warehouse projects failed.1 Even with paradigm shifts provided by BigQuery, Amazon Redshift, Snowflake, and so on, the largest problem ahead of you is having a solid foundation to build upon. This chapter will help you to answer the key questions about your project, present a charter to stakeholders, and prepare you for the journey before you write even a single line of code.
Where to Start
In the previous chapter, we talked about the highest-level questions you should answer. These are things like overall scope, who your stakeholders are, the size of your organization and its data, and who the user group will be, at least initially. You should be able to do most of that groundwork yourself. In some cases, you will even get to define those parameters for yourself. That’s a good deal—most engineers would be jealous of a greenfield project. Now let’s go one level deeper and talk about the data itself.
If you are new to this practice, you may want to open an empty document or grab a piece of paper and start taking notes on the answers. I’ll also provide a worksheet { LINK: APPENDIX B } that you can print or download if you prefer to work that way. There’s no right answer on how formal to be—it depends on your organization, the maturity of its project management, and your own particular work style.
Key Questions
What Are My Finite Resources?
In all projects, you will have constraints on time, money, and people. Figuring out what those bounds are will inform both how much you can build off the bat and how much margin of error you’ll have as a result. You may not know these answers concretely, but at minimum, imagine a radar chart along these three axes. Do you have plenty of time but no money? Do you have a budget but no one to work with you? (Can you hire some people?) Do you have a team that can do this work, but they’re stuck on other initiatives? Knowing what your limitations are will help you take a very technical problem and bring it into the real world.
You may recognize this as the project management iron triangle, and we’ll be revisiting these concepts from a number of different angles throughout the book.
What Is My Business Domain?
Let’s start with the easiest one. You probably know what your organization does. But let’s pair it with the last chapter’s key question—“What problem am I trying to solve?” I can’t really think of an organization that, given the technical and logistical challenges had been solved, would not benefit from a data warehouse. Nonetheless, this question gets at a couple of important points. If you know your domain, you might know where you can go for help answering business questions. You can also avoid reinventing the wheel if there are off-the-shelf datasets that could save you time. For instance, if you run a pharmacy chain, there’s no reason to collect your own information about drug names and dosages. You could find or buy a dataset for this purpose. We’ll cover this in several other chapters (Chapters 5, 6, 19), but this is something you can file away for now.
What Differentiates My Business from Others in Its Domain?
This resembles a typical business question, namely, what do you do that your competitors don’t. However, I would also challenge you to think about ways in which your business has a peculiar style of doing things which is not easily changed. You may or may not be interested in changing that part of your company’s culture, but you must understand it in order to build an effective warehouse that people will use. Let’s say you run a consignment shop. A customer brings items in and sells them to you—you record this, process them, and add them to your inventory. Later, another customer comes in and buys the same item, hopefully at a higher price. Simple. But let’s say your employees don’t record any information about the customer when they come in to sell. Is a “seller” entity important for your business? If it is, you’ll face the obstacle of suggesting a business process change to collect it. These scenarios can be pitfalls if you design a completely standard model but find the business priorities are incompatible. Not unsolvable problems, of course, but a good callback to the finiteness of your resources.
Who Knows What Data I Need?
This question is somewhat like finding out who your stakeholders are, but it’s taking the information that they would provide you and finding the person or people who know the actual attributes associated with it. For instance, you may have a stakeholder in your finance department who needs to know monthly revenue. Great! You note that you need revenue numbers. That’s aggregate data though; you have to calculate that number from underlying data. Do you sell widgets? You’ll need to know how many widgets you’ve sold and how much they cost. Do you provide consulting services? You might need to know the names of your consultants, their current engagements, and their blended rate. First, you have to figure out who knows the business domain well enough to tell you the formal definitions of this data.
Who Already Knows What Data They Need?
The difference between this question and the previous question is subtle but important. Stakeholders may not know how to generate their data, how to obtain it, or how to keep it up-to-date. However, some stakeholders will have very specific requests for reports or types of data. You’ll want to know these requests in advance. You could certainly build something general-purpose and then build out these specific requests, and you may choose to do that. But answering this question gives you two specific insights. Firstly, it will tell you who is likely to be a power user of the system and which things you may want to invest in optimizing. Secondly, it will be an early hint about the layout of your data marts. As we discussed in the previous chapter, you may wish to align data marts to departments. Here you may learn that the data needs of each department overlap slightly or that different people in the same department have different interpretations of the data. It turns out that matching the organization of people to the organization of data isn’t often clear. Asking this question and the previous question together can help you tease that apart before you get too far down the road to adapt.
What Are My Key Entities?
A customer purchases a product.
An employee clocks in to begin a shift.
A chef cooks three meals a day.
A chatbot can answer several kinds of questions.
Families can reserve cabins all summer long.
Again, you may recognize a user story structure emerging here (as an x, I want to y so that I can z). The similarity to functional requirements is obviously intentional. With a few of these, we can start taking these concepts into the real world.
What Are My Key Relationships?
Once you’ve established the most basic concepts for your warehouse, you can take it one step further and begin to determine relationships between data. In an operational store, you would design these using relational models that describe common functionality or are architected for performance. In a microservice architecture, the practice is to have a single data source for each service, which is too restrictive for our purposes. We are trying to make information from this data. You can think far more broadly in the data warehouse model about how things might be related. Once they understand the potential, your users will probably be even more creative combining data than you can be.
What Role Does Time Play in My Model?
This question has a couple of components. If your business cares about change over time (and most do), you’ll want to know the range of relevant data and the interval that matters. For example, if your business operates on a monthly cycle, a lot of your reporting is going to look at a monthly range or a month-to-date value. If you’re ingesting and storing logs, you may only care about the last seven days. You will have other use cases that might be major decision points for you. In the daily case, you can use BigQuery partitioned tables, which automatically structure the data on a daily basis.
What Role Does Cost Play in My Model?
A large mindset change to managed services is the idea of availability vs. cost. In the old days, if you miscalculated your resource needs, your system would fall over and stop responding to requests. In the world of Internet-scale cloud providers, if you don’t set a limit, your system will respond to everything, and you will incur unwanted costs. BigQuery allows you to set custom quotas (we’ll discuss this in Chapter 4) so you get the same effect, but you obviously don’t want to design a system that’s hitting its limits all the time either.
General Considerations
If you’ve designed or worked in a relational database before, you will be familiar with Data Definition Language, or DDL. If you’ve created tables and views, you will also know Data Manipulation Language, or DML. DDL and DML are both supported in BigQuery, but there are some things to keep in mind.
As a reminder, you should not be doing frequent UPDATEs or DELETEs on rows inside of BigQuery. As it is not designed as a transactional database, you should focus on loading data to it and then leaving it there. You can certainly do this work as part of maintenance, but your warehouse shouldn’t rely on table modification to work properly. Google considers using BigQuery as a transactional store (OLTP) to be an anti-pattern. In fact, in contrast to traditional data warehouses, Google sets no age limit on data. It is designed for indefinite scale, and you can keep inserting/streaming new data without hitting disk space or compute limits. Of course, you may care for cost or compliance reasons. While you don’t have to consider it as a primary design consideration, you will want to keep data age in your mind moving forward.
One other note on time: Please do generally use Coordinated Universal Time (UTC). All of Google Cloud operates this way, and you should prefer storing datetimes in universal time and converting to a user’s local time for display. Even if your business operates in a single timezone and all data collected is in that timezone, you should still use UTC. You can also store the user’s UTC offset or the local time in another column for local analysis. For instance, if you want to know how often employees clock in late, it would be useful to look at all rows where their local time is later than the start of the shift, even though the UTC will vary by location and time of year.
Making the Case
Hopefully you see the value of having done the groundwork to answer the basic design questions ahead of time. If you have concerns about the next step—creating the model in your BigQuery project—try doing the worksheet exercise. If you feel you need additional help to understand the domain model itself, try searching for a glossary of terms for your industry and use it to form sentences about your business. It is often said that naming things is one of the hardest problems in computer science, and I am inclined to agree. With any luck, someone will have done this hard work for you already.
Even if you have an existing structure, you may still want to restructure your data to take maximum advantage of BigQuery’s strengths at scaling to massive levels. This requires resources, obviously, and you may not have or want to spend them. So we’ll talk primarily about the from-scratch implementation in this chapter and then revisit this question from the perspective of your existing data in the next chapter.
The focus on the project and the process for completing it is very intentional. A successful data warehouse requires broad support from the organization and an understanding of its politics. The theoretical knowledge and hard work to do the project is necessary, but it is only a prerequisite. If rallying troops and building consensus may not be your strong suit, now is the time to partner with an empowered project manager or a committed executive sponsor.
Interviewing Stakeholders
You should have an idea of who these people may be based on the questions in the previous section. Find out (or ask your partner) what the best way to get their attention is and get a meeting on their calendar. Busy people will undoubtedly deprioritize this exercise, since they may not understand its value until they are getting meaningful insight. If you have an idea what their data needs are, bring that outline to your meeting and use it to ask directed questions. If they receive existing dashboards or reports from you, those terms are probably front and center. You’re liable to only get blank stares if you ask an open-ended question like “What data do you need?” Well, there will probably be a couple stakeholders who came from an organization with good data practices, and they’ll just be thrilled you’re asking at all.
Take detailed notes. Pay special attention if you hear a term you’ve heard in other contexts, but when you ask for a definition, it doesn’t seem to agree. Start drilling down on what a given metric means, especially if it’s custom to your business. How is something like “likelihood to repurchase” calculated? Does everyone agree?
You may realize that this exercise has never been undertaken before. It may have simply been unnecessary for two stakeholders to share the same context. Or, when they communicated with each other previously, they were careful to use more specific terms to disambiguate the scenario. Unfortunately for your blood pressure, one of our true needs as engineers is clarity—we can’t build a system with inconsistent definitions or one that returns different answers to the same questions each time you ask. (Technically, BigQuery does support the RAND() function, but self-sabotage isn’t really my style.)
Resolving Conflicts
By conflicts, I don’t mean physical altercations. What I’m referring to is that different stakeholders will inevitably have different interpretations of the same piece of data. Your job here is to create a single, unified terminology, so that when people across the business use a term, it means the same thing to everyone. This may not be totally possible due to ingrained process, but you will at least be able to untangle domain-specific meanings of a word like “customer.”
There are two straightforward ways to handle a terminology conflict like this. One is to apply the context to the term to differentiate them—for example, a “prospect” might become a “prospective customer” and a “prospective employee,” since those two terms are not actually the same thing. The other is to unify the terms and apply the facets of both to the term. A marketing person and an operations person will both care about a “product,” but the operations person would be concerned with its gross weight, size, shipping restrictions, and so on. The marketing person would care about the price, the marketing copy, the number of calories, and so forth. You’ll pretty clearly need an entity with the name “product,” but you can combine its attributes in the data warehouse, even if the source systems are totally disjunct.
If neither of these approaches applies, you probably have a “level” issue. What I mean by that is one person may be describing a thing that is a part of a whole that the other person is describing. To illustrate, the word “truck” may describe the physical object, with its attributes being size of gas tank, mileage on the odometer, radio frequency, and so on. But to a shipping person, it may refer to its contents—in reality, the truckload, not the truck. Those attributes would be internal size, number of packages contained, bill of lading, and so on. In this case, “truckload” could actually be an attribute of “truck” itself. To resolve, you can make a nested schema of truck which contains another business term, such as “manifest” or “pallet” or whatever it is that’s actually being described. The data warehouse is then properly equipped to answer questions on either or both sets of attributes, for example, “How much gas did we use today?”, “How many trucks (truckloads) reached their destinations today?”, or “Are trucks on CB frequency 23 less likely to deliver on time?” It’s always worth at least attempting to merge the sense of two terms, because there is almost certainly useful information to be found in the intersection. (Now as to how a particular CB frequency would affect truckers reaching their destinations, I’ll leave to your imagination.)
Compiling Documentation
Once you’ve completed talking to your stakeholders and reconciling your terminology, you will want to produce three key artifacts. These will both help you prove the value of your case and serve as your template documentation for creating the warehouse in the next section. They’ll also serve as guideposts if you lose track of (or others drift from) the original definition of a term over time.
Sources of Truth
You will need to understand all of the possible places your data can come from. This will obviously change over time, but you’ll also get a sense of the level of effort that will be required to load up and maintain the data warehouse. Additionally, you’ll get a sense of the kinds of attributes you need—once you get at this data, you’ll know what’s important or at least what’s available.
You may see the same data point comes from multiple places, and that’s okay. If it literally tracks the exact same data, then choose one and note it. If it tracks its own interpretation of the same data, you’ll want to use nesting or aggregation to resolve and designate each piece of data as a source. Best example: Google Analytics, Facebook, and other marketing pixels are never going to match on exact number of impressions (for reasons beyond the scope of this book). It’s fine to label “Google hit count,” “Facebook hit count,” and so on as separate metrics and deal with this in the transformation phase. They track the same thing in theory, but in practice they’re never going to agree.
This will also bring to light another frequent and important problem—namely, that certain data points have no source of truth. It’s common for finance to track to monthly or quarterly targets, but those targets may not exist anywhere outside of a spreadsheet or email, even though it is literally the most important metric. Forecasting, reforecasting, optimism, pessimism, random chance—all of these things can cause different people to have completely different numbers in mind. A stretch goal and what gets reported to Wall Street are totally misaligned. Take note of these and decide how much responsibility you can take for dealing with them. From a political standpoint, your warehouse function will suffer significant credibility loss if someone claims “the revenue target is wrong.”
Data Dictionary
The data dictionary represents your clean, reconciled version of the terminology your business uses. This will become the bible for what any particular term actually represents. Remember that you can always change how data is visualized in an individual data mart, but the underlying warehouse definition must be pure. Don’t compromise on this step. This is the nexus of your entire business intelligence operation, and without this to rely on, you will be lost.
If you have legacy BI solutions, they will stop agreeing with your solution in any place you have redefined a term. Make it clear to everyone that when the new system goes live, the legacy system will be deprecated. This will happen even if it’s still receiving data and appears to be functional. Otherwise, stakeholders won’t trust either set of data, and you will be constantly explaining that while they name the same metric, they are not measuring the same thing, and the data dictionary you published clearly states that this metric measures this, but in the legacy system it didn’t account for this, and… Well, you get my point. It doesn’t matter what the measurement did before; all that matters is that everyone will agree on the new measurement and that that measurement works properly.
The Charter
Now it’s time to take the answer to the very first question—“What problem am I trying to solve?”—and formalize it in a charter. You can adapt this to your organization’s particular work style and project management office requirements. It may just be a single-page document outlining the rough goals, or I hope not, but you could produce 200 pages of boilerplate to serve the same purpose. Ultimately the purpose of this part of the process is to give the business something to see and to sign off on.
Make sure all the key stakeholders sign off on this! Take it as high in the organization as you feel necessary. Even when all parties are acting with good intentions, standards can slip and internal sentiment can change. Once you get rolling, people will see the value in what you’re doing, and acceptance will come more easily. Set a strong foundation now so that you have the chance to make that happen.
Understanding Business Acceptance
I can only approach this in a very general fashion, because it depends so highly on your particular culture. It also depends on you or your business partner’s clout in the organization. A scenario where you would want to change the culture of the business in the process of gaining its acceptance would not be uncommon. Style yourself as a champion for data in your organization and see where it takes you.

Rubric for organizational data maturity
Recording Decisions
You’re all set now. You just need a way to ensure all the documentation and consensus you’ve produced can be recorded. You also want this as a safeguard for when things inevitably change. It’s fine if they do and (agile hat on) probably desirable, but you’ll want to keep a record of those changes.
You may opt to combine the data dictionary and the sources of truth at this point, but if you have a lot of hairy examples like the marketing tracker one I used earlier, you may not wish to do this. At the very least, define the sources of truth themselves and make sure you know who the owners are, should something change or you need additional clarification.
Regardless, I recommend keeping the three documents (charter, data dictionary, and sources of truth, if you haven’t combined them) in an easily accessible location such as your intranet. You must be diligent about keeping them up-to-date as the organization evolves. In reality, these definitions shouldn’t change too much if you have properly captured your business domain, but the sources of truth might.
The documents themselves should also have a version history, however you choose to track that. Here’s that note again: all data models should be extensible, but they should not be modified. This includes the descriptions of those models. Changing the data dictionary to modify the definition of a certain term is a big deal, and all relevant parties should at least acknowledge the change. Failure to close the loop on this will get you more “my data is wrong” complaints.
By the way, this note applies as the “open-closed principle” across many areas of software engineering. We’ll come back to it as we explore the evolution of schemas over time and how to handle what could be a design error.
You may also opt to keep tally of where you think your organization scores on the rubric. This could help you choose the correct pace of change and the level of formality your organization may require for success.
Choosing a Design
Google suggests that you can use nested and repeated fields to obviate the need for traditional OLAP data organization. Using partitioning can also eliminate some of the need for time-based dimension tables. However, if you have an existing model, you will probably also already have an OLTP database or an OLAP schema such as star or snowflake. You can revisit the question about your finite resources to decide how much work you can do when loading and transforming data into your database. We’ll also discuss these considerations more in the next couple of chapters.
Transactional Store
If you have an existing transactional database using Microsoft SQL Server, MySQL, PostgresSQL, and so on , then your data is already structured. If you have dedicated database administrators, you may find this data is actually too normalized for use with BigQuery. We’ll cover this use case in Chapter 5. If your dataset is small and does not frequently change, you can replicate it over to BigQuery directly, but in most applications this would only be a first step.
Star/Snowflake Schemas

A simplified star schema
If you’re migrating from an existing OLAP warehouse, this arrangement is perfectly viable in BigQuery. However, you may find2 that BigQuery in a single denormalized table with nesting outperforms the star schema significantly. Two other advantages often cited are that analysts are more easily able to navigate this schema type and that it is optimal for disk space. In most cases, disk space will not be a consideration for you on BigQuery. As for navigation, this is a discussion you will need to have (see the “Making the Case” section). You may not be willing or able to restructure your existing schema.
A snowflake schema is essentially a star schema extended with normalized dimension tables. While with the preceding star schema there were no separate lookups for the dimension tables, the snowflake schema has additional tables to track lookups for dimensions. This makes changing dimensions a lot easier and the representation more compact, with a trade-off in performance.
NoSQL
This use case is increasingly common and covered in depth in Chapter 6. Essentially, the architecture is that you receive data live from your application and use a document-based storage system such as MongoDB or Google Cloud Datastore to store in a semi-structured format. Then, using an event-based architecture, you transform and load the data into a more structured format. BigQuery can serve as that structure, and you can even load your documents directly into it. However, unless you have a single NoSQL store and a single BigQuery dataset, and both are in the gigabyte range, you will still need to create a proper design.
BigQuery
Since the purpose of this book is to use BigQuery for your warehouse, I’m going to promote best practices for this wherever possible while also flagging alternatives or specific constraints. The pure BigQuery model encourages you to set aside these questions of normalization and other OLAP schemas. The message is clear: use nested and repeated data, and you can avoid these decisions altogether.
Obviously, your project won’t have unlimited budget, and thus there will be some practical limitations to the amount of disk space you want to consume. But if you did have infinite storage and compute, how many of these trade-offs would go away? If your warehouse is likely to remain smaller than a petabyte throughout its lifetime, will you ever hit this theoretical limit? Again, if you’re lucky enough to be starting from scratch, you can perhaps sidestep this entire part of the discussion. (You will probably still want to read Chapter 3 or 4 depending on where your live data sources currently are, though.)
Understanding the BigQuery Model
By now, if you have a reasonable sense of all of the preceding considerations, you’re ready to get going. If you’re itching to get started and you still aren’t sure about everything, don’t let that stop you. As much as I like to whiteboard all day, perfect is the enemy of the good when it comes down to these things. So do your best with the information you have available. You can always change it up when it becomes a runaway success.
I’ll make this note many times: remember that, in general, all data models should be extensible, but they should not be modified. Changing the name of a dataset, table, column, or data type may have side effects that are extremely difficult to predict. You may have one or many brittle consumers of the data that are expecting a certain schema or response. Worse yet, they may be hiding in poorly written code (pesky developers) with no unit tests. This is not to say you can never modify anything—but as soon as your system is at a level of maturity where you cannot know all of its entry points, think carefully before you do.
Projects
In the last chapter, we created a Google Cloud Platform project to work with BigQuery. Google allows you to unify billing across projects, and you can also reach data stored in other projects if the owner allows it.
In principle, you probably only need a single project for your data warehouse. Unless you have a compelling reason to incur the overhead of maintaining multiple sets of services, you will have a much easier time if your permissions and other compute resources are all located in the same project.
If you are creating a warehouse that aggregates data over multiple tenants in a software-as-a-service environment, your clients may each have their own projects. However, your clients may also have their own clouds, on-premise installations, version issues, and so on. This consideration is best addressed as an abstraction over how you intake the data into the warehouse. From this perspective, it may be best to avoid reaching into client data sources directly and instead provide a unified interface for ingesting data.
If you have multiple GCP projects in your organization already, find out how they are administered and whether you will need direct access to them. For the remainder of this book, except when discussing public datasets and permissions, I will operate under the assumption that your warehouse lives inside a single project.
Datasets
The top level of organization in your project is a dataset. You can have multiple datasets inside the same project, and each of those datasets can contain tables, views, stored procedures, functions, and so on.
Hierarchical organization of data is a highly arbitrary subject. The two primary options are to use a single dataset in your project or to use many datasets. There are pros and cons to each approach. Storing everything in a single dataset makes it easy to query across any table without remembering which dataset it belongs to. However, you’ll have to think more about permissioning, and if you are mixing sensitive and nonsensitive data, it may be easier to lose track. On the other hand, making many datasets for a small number of tables can be unnecessary overhead. Ultimately, you will want to refer to the answers to how big your data is now and how big it will become before making this decision.
Be wary of lining up your dataset definitions to data source. The place the data comes from may not be the most relevant structure for analysis. For example, you may take orders both in-store and online. Your in-store systems may be an antiquated point-of-sale using cash registers and Electronic Data Interchange (EDI) to send data to BigQuery. Meanwhile, the online systems send real-time order information directly to you. This doesn’t necessarily mean they should go in two different datasets. The most relevant question your stakeholders might ask is how much money you’ve made in a particular day. If in-store outweighs online by a lot, and will continue to do so, put the data close together and unify the schema as best you can. Of course, this is only an example! I’m just trying to give some clarity around the kinds of questions you can ask yourself to help answer this question.
In case it matters to you, my personal preference is to make multiple datasets to contain logically distinct areas. For example, you might put your monitoring logs in a different dataset than your order information.3 You might occasionally want to correlate logs to orders, perhaps to troubleshoot an issue, but BigQuery supports this, and you can take advantage of it when you need to.
Tables
The primary object in a dataset is the table. Your dataset will generally contain many tables, all of which you pull together in various ways for analysis. Tables also look a little different in BigQuery for a few different reasons. As mentioned earlier, Google considers OLTP to be an anti-pattern. So we’ll be working primarily using OLAP concepts. That being said, there are still some BigQuery-specific patterns worth knowing.
Normalization/Denormalization
Favored by data engineer interviewers everywhere, this topic has decades of academic texts and research articles attached to it. If you’re not familiar, the underlying question is this. Normalization is optimizing toward against redundancy of data and dividing the data into multiple tables which are then joined together. Denormalization goes the opposite direction, favoring performance and putting all of the data in as few tables as possible.
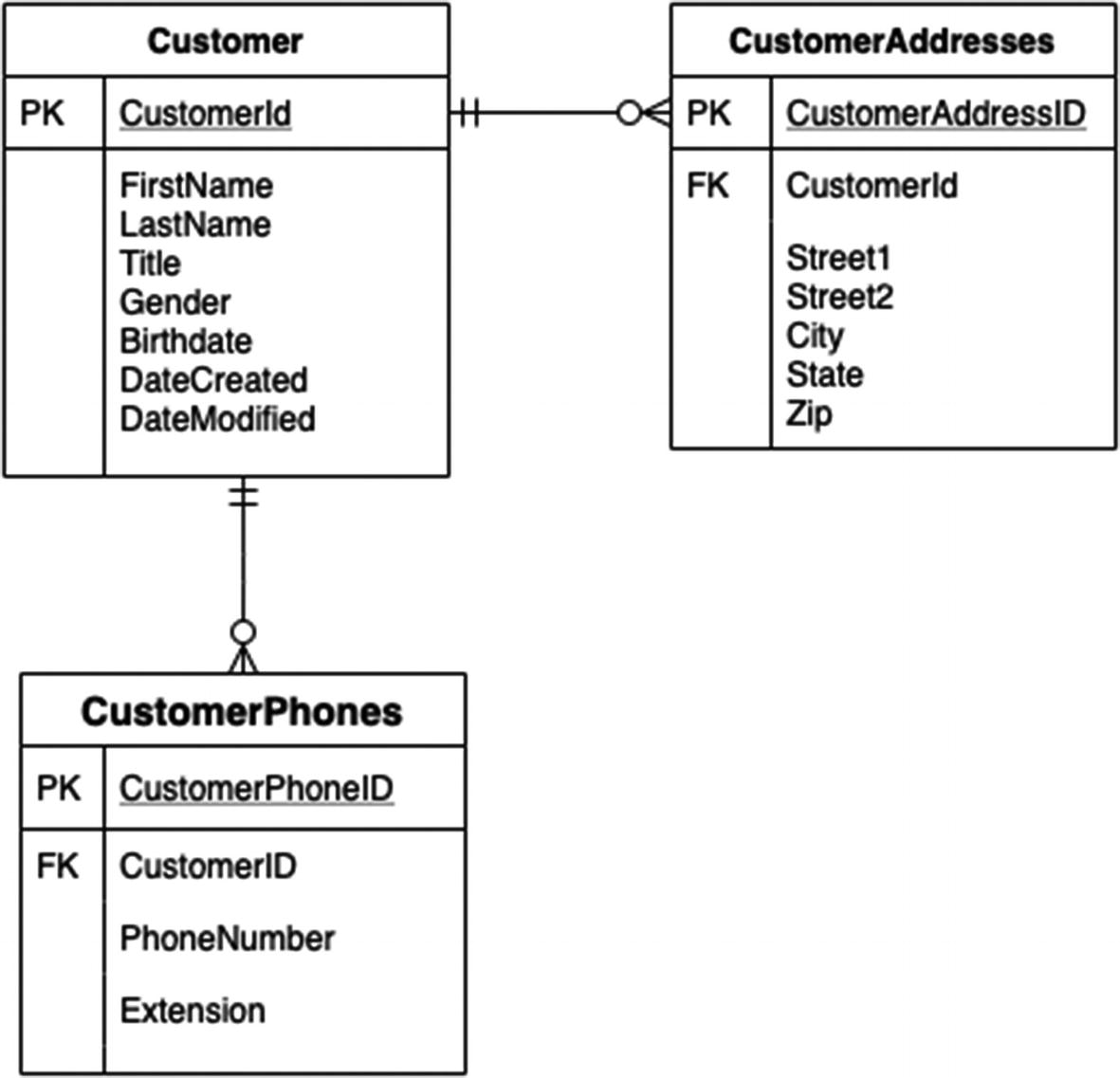
A classic customer entity relationship diagram

The same data, denormalized
This is a pretty succinct rule of thumb. You can override it based on the frequency and importance of UPDATE and DELETE operations. Remember, in general, you will want to primarily insert data into tables rather than overwriting or removing it. If you need to do this a lot, though, you may decide (and Google suggests) that it’s better to have a normalized schema and take the performance penalty.
What if you don’t have much data now, but you expect it to grow tremendously over time? Generally, you want to stick with standard procedure here and go ahead and denormalize the structure for future growth. The interesting implication is that if you know your datasets are going to stay relatively small, you could opt for minimal transformation on top of your existing transactional schemas. Generally, you would also care about data storage and costs due to the redundancy of denormalized data. In a managed environment, that’s not going to pose any substantial risk. The other risk—loss of data consistency—is real. Data can lose synchronization among locations if it’s stored in multiple places. Especially with rapidly changing data, you might deal with some inconsistency. This may or may not be a significant factor for your environment.
Hierarchical Data Structure
The other significant difference in storing data with BigQuery is using nested data. BigQuery can ingest native JSON and store each object as a row. This is the recommended method for schemas in BigQuery. BigQuery can also work with nested elements that repeat. This allows you to represent one-to-many relationships inside the row itself.

The same data, with a hierarchical model
Modeling data this way allows you to get some of the advantages of normalization without actually having to do it. Of course, the disadvantages of denormalization also apply, namely, that this data isn’t going to update as it would in a related table. This technique is fine whenever you are capturing point-in-time data, though.
Partitioning
Partitioning is a tool you can use when creating a table to automatically bucket rows by ingestion time, a timestamp, or an integer key. This is useful for two reasons: One, you get the range as a dimension without doing any extra work. This lets you more easily analyze data within or across those ranges. Two, you can set an expiration policy on partitioned tables. If you’re storing ephemeral data and only need to keep it around for a certain amount of time, you can have BigQuery automatically remove older data. This technique could also be used in combination with a larger source table to create deeper analysis for a limited time.
Summary
To successfully start a data warehouse project, you need two major ingredients. The first is your technical skill and understanding of how to undertake a project like this. The second is business understanding and acceptance. Both are equally important. There are several key questions you can ask yourself or stakeholders to understand their needs. Once you understand the business domain and charter a project, you have the foundation to start building. This information will help you choose a design. BigQuery has some best practices for how to structure data and some decisions you can make yourself with your knowledge of the business. With this chapter, you should now be prepared to go full speed ahead. In the next chapter, we’ll dive deep into construction to create a warehouse that handles all of your existing business cases and is prepared for new ones.